

경쟁사 가격을 끌어오겠다고 처음 Python 스크립트를 붙잡았던 날, 결과물은 빈칸투성이 CSV 한 장이었어요. 그날 이후 "Python으로 자동화하면 되잖아"라는 말을 가볍게 못 하게 됐죠. 2026년 현재 웹 스크래핑은 더 이상 개발자만의 영역이 아니에요. 영업, 이커머스, 마케팅, 운영팀 모두 손으로는 절대 못 모을 실시간 데이터를 스크래핑으로 확보하고 있어요. 데이터 중심으로 돌아가는 비즈니스의 기반이 된 셈이에요.
다만 짚고 갈 점이 있어요. Python 스크래핑이 강력해진 만큼, 판도 계속 바뀌고 있다는 거예요. 시장 자체가 빠르게 크고 있어요. 2023년 49억 달러 규모에 연 28% 성장 중이고, 조직의 97%가 빅데이터·AI에 투자하고 있죠. 그런데 진짜 어려운 건 코드를 짜는 일이 아니에요. 작업에 맞는 도구를 고르고, 규모를 키우고, 스크립트 수십 개를 돌보다 정신줄을 안 놓는 거예요. 이 가이드에서는 주요 Python 스크래핑 라이브러리를 코드 예시와 실제 활용 사례까지 하나씩 짚어볼게요. 그리고 Python을 무척 좋아하면서도, 2026년 대부분의 비즈니스 사용자에겐 Thunderbit 같은 노코드 방법이 더 현명한 이유도 설명할게요.
Python 웹 스크래핑이란? 비전문가를 위한 소개
쉽게 풀어볼게요. 웹 스크래핑은 "자동화된 복사-붙여넣기"예요. 제품 가격이나 연락처, 리뷰를 모으겠다고 인턴을 잔뜩 뽑는 대신, 소프트웨어가 웹페이지를 돌며 필요한 데이터를 뽑아내 스프레드시트나 데이터베이스로 내보내요. Python 웹 스크래핑은 이 일을 Python 스크립트로 한다는 뜻이에요. 페이지를 가져오고, HTML을 분석하고, 원하는 정보만 골라내는 거죠.
디지털 비서 하나를 웹사이트 탐색에 24시간 붙여 두는 셈이에요. 커피 브레이크도 없이요. 기업들이 가장 많이 긁어가는 데이터요? 가격, 제품 상세, 연락처, 리뷰, 이미지, 뉴스 기사, 심지어 부동산 매물까지 꽤 다양해요. API를 열어 둔 사이트도 있지만, 대부분은 없거나 접근을 막아 둬요. 그래서 스크래핑이 필요해요. 공식 "다운로드" 버튼이 없어도 공개 데이터를 대규모로 쓸 수 있게 해주니까요.
비즈니스 팀에게 Python 웹 스크래핑이 중요한 이유
직설적으로 말할게요. 2026년에도 스크래핑을 안 쓴다면 손에 쥘 수 있는 돈을 그냥 놓치는 거예요. 왜 그런지 보세요.
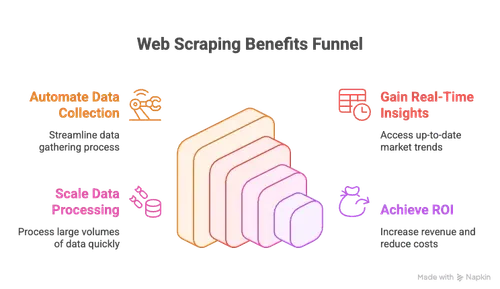
- 수동 작업 자동화: 경쟁사 사이트나 디렉터리를 행마다 복사할 일이 없어져요.
- 실시간 인사이트: 가격, 재고, 시장 흐름을 늘 최신 상태로 확인해요.
- 확장성: 점심 데우는 동안 수천 페이지를 긁을 수 있어요.
- ROI: 데이터 기반 전략을 쓰는 기업은 매출 8% 높고 비용 10% 낮다는 보고가 있어요.
효과가 큰 활용처를 짧게 정리하면 이래요.
| 부서 | 활용 사례 예시 | 제공 가치 |
|---|---|---|
| 영업 | 디렉터리에서 리드 수집, 이메일로 정보 보강 | 더 많고 더 정교하게 타깃팅된 리드 목록 |
| 마케팅 | 경쟁사 가격, 프로모션, 리뷰 추적 | 더 똑똑한 캠페인, 더 빠른 방향 전환 |
| 이커머스 | 제품 가격, 재고, 리뷰 모니터링 | 동적 가격 책정, 재고 알림 |
| 운영 | 공급업체 데이터 통합, 보고 자동화 | 시간 절약, 수동 오류 감소 |
| 부동산 | 여러 사이트의 매물 정보 수집 | 더 많은 매물, 더 빠른 고객 응대 |
정리하면 이래요. 스크래핑은 더 똑똑하고 빠르고 경쟁력 있는 판단을 만드는 숨은 재료예요.
개요: 주요 Python 웹 스크래핑 라이브러리 모두 살펴보기(코드 스니펫 포함)
제대로 한 바퀴 돌아볼게요. Python 스크래핑 생태계는 정말 넓어요. 단순 페이지 다운로드부터 본격 브라우저 자동화까지, 거의 모든 유형을 위한 라이브러리가 있어요. 각각의 성격을 코드와 함께 짚어볼게요.
urllib와 urllib3: HTTP 요청의 기본기
Python에 내장된 HTTP 요청 도구예요. 저수준이라 조금 투박하지만, 기본 작업에는 안정적이에요.
import urllib3, urllib3.util
http = urllib3.PoolManager()
headers = urllib3.util.make_headers(user_agent="MyBot/1.0")
response = http.request('GET', "<https://httpbin.org/json>", headers=headers)
print(response.status) # HTTP 상태 코드
print(response.data[:100]) # 내용의 처음 100바이트
의존성을 전혀 안 두고 싶거나 세밀한 제어가 필요할 때 좋아요. 다만 보통은 requests처럼 더 편한 도구가 맞아요.
requests: 가장 인기 있는 Python 웹 스크래핑 라이브러리
Python 스크래핑의 마스코트를 꼽으라면 단연 requests예요. 간단하고 강력하고, HTTP 처리의 무거운 부분을 알아서 맡아줘요.
import requests
r = requests.get("<https://httpbin.org/json>", headers={"User-Agent": "MyBot/1.0"})
print(r.status_code) # 200
print(r.json()) # 파싱된 JSON 콘텐츠(응답이 JSON일 경우)
왜 이렇게 인기일까요? 쿠키, 세션, 리다이렉트를 알아서 처리하니까요. HTTP의 자잘한 부분은 잊고 데이터에만 집중하면 돼요. 단, requests는 HTML을 가져오기만 해요. 데이터를 뽑으려면 BeautifulSoup 같은 파서가 따로 필요해요.
BeautifulSoup: 쉬운 HTML 파싱과 데이터 추출
BeautifulSoup은 Python에서 HTML을 분석할 때 가장 많이 쓰는 도구예요. 너그럽고 초보자 친화적이고, requests와 합이 잘 맞아요.
from bs4 import BeautifulSoup
html = "<div class='product'><h2>Widget</h2><span class='price'>$19.99</span></div>"
soup = BeautifulSoup(html, 'html.parser')
title = soup.find('h2').text # "Widget"
price = soup.find('span', class_='price').text # "$19.99"
소규모에서 중간 규모 프로젝트에 딱이고, 막 시작한 분에게 좋아요. 데이터가 아주 많거나 쿼리가 복잡해지면 lxml로 한 단계 올라가고 싶어질 거예요.
lxml과 XPath: 빠르고 강력한 HTML/XML 파싱
속도가 중요하거나 XPath(XML/HTML용 쿼리 언어)를 쓰고 싶다면 lxml이 든든한 친구예요.
from lxml import html
doc = html.fromstring(page_content)
prices = doc.xpath("//span[@class='price']/text()")
XPath로는 데이터를 아주 정밀하게 집어낼 수 있어요. lxml은 빠르고 효율적이지만, 학습 곡선은 BeautifulSoup보다 조금 가팔라요.
Scrapy: 대규모 웹 크롤링을 위한 프레임워크
Scrapy는 대규모 작업의 최강자예요. 완전한 프레임워크라, 스크래핑계의 Django라고 보면 돼요.
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = ["<http://quotes.toscrape.com/>"]
def parse(self, response):
for quote in response.css("div.quote"):
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("small.author::text").get(),
}
Scrapy는 비동기 요청을 처리하고, 링크를 따라가고, 파이프라인을 관리하고, 여러 형식으로 데이터를 내보내요. 작은 스크립트엔 과하지만, 수천 페이지를 크롤링할 땐 정말 강력해요.
Selenium, Playwright, Pyppeteer: 동적 웹사이트 스크래핑
자바스크립트로 데이터를 불러오는 사이트를 만나면 브라우저 자동화가 필요해요. 이 분야 대표는 Selenium과 Playwright예요.
Selenium 예시:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("<https://example.com/login>")
driver.find_element(By.NAME, "username").send_keys("user123")
driver.find_element(By.NAME, "password").send_keys("secret")
driver.find_element(By.ID, "submit-btn").click()
titles = [el.text for el in driver.find_elements(By.CLASS_NAME, "product-title")]
Playwright 예시:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto("<https://website.com>")
page.wait_for_selector(".item")
data = page.eval_on_selector(".item", "el => el.textContent")
사람이 다룰 수 있는 거의 모든 사이트를 처리하지만, 순수 HTTP 방식보다 느리고 무거워요. 꼭 필요할 때만 쓰세요. 할 수 있다고 무조건 써야 하는 건 아니니까요.
MechanicalSoup, RoboBrowser, PyQuery, Requests-HTML: 알아두면 좋은 다른 도구들
-
MechanicalSoup: Requests와 BeautifulSoup 위에 얹은 도구로, 폼 제출과 탐색을 자동화해요.
import mechanicalsoup browser = mechanicalsoup.StatefulBrowser() browser.open("<http://example.com/login>") browser.select_form('form#loginForm') browser["username"] = "user123" browser["password"] = "secret" browser.submit_selected() page = browser.get_current_page() print(page.title.text) -
RoboBrowser: API는 MechanicalSoup과 비슷하지만 유지보수가 끊겼어요. PyPI 새 릴리스도 한참 없었죠. 폼·세션 처리가 필요하면 MechanicalSoup이나
requests.Session()을 직접 쓰는 편이 나아요. -
PyQuery: jQuery 스타일의 HTML 파싱 도구예요.
from pyquery import PyQuery as pq doc = pq("<div><p class='title'>Hello</p><p>World</p></div>") print(doc("p.title").text()) # "Hello" print(doc("p").eq(1).text()) # "World" -
Requests-HTML: HTTP 요청, 파싱, 그리고 JavaScript 렌더링까지 한데 묶은 도구예요.
from requests_html import HTMLSession session = HTMLSession() r = session.get("<https://example.com>") r.html.render(timeout=20) links = [a.text for a in r.html.find("a.story-link")]
폼, CSS 선택자, 가벼운 JS 렌더링이 필요할 때 빠른 지름길로 쓰기 좋아요.
Asyncio와 Aiohttp: Python 웹 스크래핑 속도 높이기
수백, 수천 페이지를 긁을 땐 동기식 요청이 너무 느려요. 이럴 땐 동시 처리를 위한 aiohttp와 asyncio를 쓰면 돼요.
import aiohttp, asyncio
async def fetch_page(session, url):
async with session.get(url) as resp:
return await resp.text()
async def fetch_all(urls):
async with aiohttp.ClientSession() as session:
tasks = [fetch_page(session, url) for url in urls]
return await asyncio.gather(*tasks)
urls = ["<https://example.com/page1>", "<https://example.com/page2>"]
html_pages = asyncio.run(fetch_all(urls))
여러 페이지를 한꺼번에 가져오니 속도가 확 빨라져요.
특화 라이브러리: PRAW(Reddit), PyPDF2 등
-
PRAW: API로 Reddit을 스크래핑할 때 써요.
import praw reddit = praw.Reddit(client_id='XXX', client_secret='YYY', user_agent='myapp') for submission in reddit.subreddit("learnpython").hot(limit=5): print(submission.title, submission.score) -
PyPDF2: PDF에서 텍스트를 뽑을 때 써요.
from PyPDF2 import PdfReader reader = PdfReader("sample.pdf") num_pages = len(reader.pages) text = reader.pages[0].extract_text() -
기타: Instagram, Twitter, OCR(Tesseract)용 라이브러리도 많아요. 특이한 데이터 소스라도, 누군가 이미 그걸 위한 Python 라이브러리를 만들어 놨을 확률이 높아요.
비교표: Python 스크래핑 라이브러리
| 도구 / 라이브러리 | 사용 편의성 | 속도 및 규모 | 최적 용도 |
|---|---|---|---|
| Requests + BeautifulSoup | 쉬움 | 보통 | 초보자, 정적 사이트, 빠른 스크립트 |
| lxml(XPath 사용) | 보통 | 빠름 | 대규모, 복잡한 파싱 |
| Scrapy | 어려움 | 매우 빠름 | 엔터프라이즈, 대규모 크롤링, 파이프라인 |
| Selenium / Playwright | 보통 | 느림 | JavaScript가 많은 사이트, 인터랙티브 사이트 |
| aiohttp + asyncio | 보통 | 매우 빠름 | 대량 처리, 대부분 정적 페이지 |
| MechanicalSoup | 쉬움 | 보통 | 로그인, 폼, 세션 관리 |
| PyQuery | 보통 | 빠름 | CSS 선택자 선호 사용자, DOM 조작 |
| Requests-HTML | 쉬움 | 변동적 | 소규모 작업, 가벼운 JS 렌더링 |
AI를 사용해 어떤 웹사이트에서든 데이터 스크래핑 Get Started Free
단계별 가이드: Python 웹 스크래퍼를 만드는 방법(예시 포함)
실제 사례로 따라가 볼게요. 가상의 이커머스 사이트에서 제품 목록을 긁고, 페이지네이션을 처리한 뒤 CSV로 내보내는 예시예요.
import requests
from bs4 import BeautifulSoup
import csv
base_url = "<https://example.com/products>"
page_num = 1
all_products = []
while True:
url = base_url if page_num == 1 else f"{base_url}/page/{page_num}"
print(f"페이지 스크래핑 중: {url}")
response = requests.get(url, timeout=10)
if response.status_code != 200:
print(f"{page_num}페이지가 상태 코드 {response.status_code}를 반환했어요. 중단합니다.")
break
soup = BeautifulSoup(response.text, 'html.parser')
products = soup.find_all('div', class_='product-item')
if not products:
print("더 이상 제품을 찾지 못했어요. 중단합니다.")
break
for prod in products:
name_tag = prod.find('h2', class_='product-title')
price_tag = prod.find('span', class_='price')
name = name_tag.get_text(strip=True) if name_tag else "N/A"
price = price_tag.get_text(strip=True) if price_tag else "N/A"
all_products.append((name, price))
page_num += 1
print(f"총 {len(all_products)}개 제품을 수집했어요. CSV로 저장하는 중...")
with open('products_data.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(["제품명", "가격"])
writer.writerows(all_products)
print("데이터가 products_data.csv에 저장되었어요")
여기서 무슨 일이 일어나는 걸까요?
- 페이지를 돌면서 HTML을 가져오고, 제품을 파싱하고, 이름과 가격을 모은 뒤 더 이상 제품이 없으면 멈춰요.
- 결과를 CSV로 내보내 분석하기 쉽게 만들어요.
Excel로 내보내고 싶다면 pandas를 쓰면 돼요.
import pandas as pd
df = pd.DataFrame(all_products, columns=["제품명", "가격"])
df.to_excel("products_data.xlsx", index=False)
Python 웹 스크래핑에서 폼, 로그인, 세션 처리하기
로그인이나 폼 제출을 요구하는 사이트가 많아요. 이런 경우엔 이렇게 풀어요.
requests와 세션 사용:
session = requests.Session()
login_data = {"username": "user123", "password": "secret"}
session.post("<https://targetsite.com/login>", data=login_data)
resp = session.get("<https://targetsite.com/account/orders>")
MechanicalSoup 사용:
import mechanicalsoup
browser = mechanicalsoup.StatefulBrowser()
browser.open("<http://example.com/login>")
browser.select_form('form#login')
browser["user"] = "user123"
browser["pass"] = "secret"
browser.submit_selected()
세션을 쓰면 쿠키가 유지돼, 여러 페이지를 긁는 내내 로그인 상태가 살아 있어요.
동적 콘텐츠와 JavaScript 렌더링 페이지 스크래핑하기
데이터가 HTML에 없고(소스 보기에서 빈 div만 보인다면) 브라우저 자동화가 필요해요.
Selenium 예시:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver.get("<http://examplesite.com/dashboard>")
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, 'stats-table')))
html = driver.page_source
아니면 JavaScript가 호출하는 API 엔드포인트를 찾을 수 있다면, requests로 JSON을 바로 가져오는 게 훨씬 빨라요.
스크래핑한 데이터 내보내기: CSV, Excel, 데이터베이스 등
-
CSV: 위에서 본 Python
csv모듈을 쓰면 돼요. -
Excel: pandas나 openpyxl을 쓰세요.
-
Google Sheets:
gspread라이브러리를 쓰세요.import gspread gc = gspread.service_account(filename="credentials.json") sh = gc.open("My Data Sheet") worksheet = sh.sheet1 worksheet.clear() worksheet.append_row(["이름", "가격"]) for name, price in all_products: worksheet.append_row([name, price]) -
데이터베이스: SQL이라면
sqlite3,pymysql,psycopg2, 또는 SQLAlchemy를 쓰면 돼요. NoSQL이라면 MongoDB용pymongo를 쓰세요.
Python 웹 스크래핑과 최신 노코드 솔루션 비교: 왜 Thunderbit이 2025년 최고의 선택인가
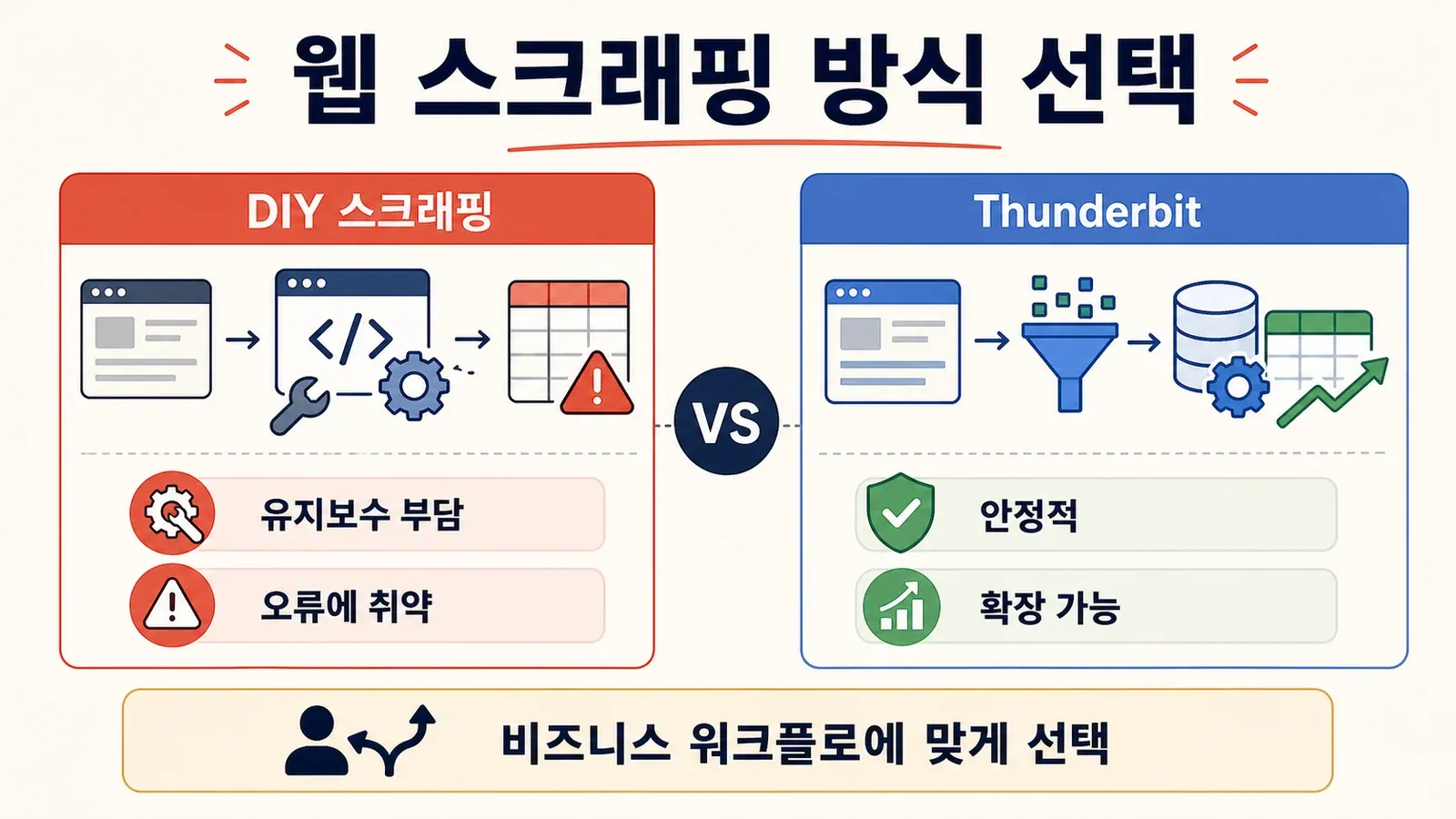
이제 다들 궁금해하는 부분이에요. 바로 유지보수죠. 직접 스크래퍼를 만드는 건 좋아요. 그런데 성격이 제각각인 사이트 100개를 긁어야 하고, 큰 보고서 마감 전날 밤에 그게 전부 깨진다면요? 저도 겪어봤고, 흰머리는 그때 생겼어요.
제가 Thunderbit를 이렇게 아끼는 이유예요. 2025년 비즈니스 사용자에게 Thunderbit이 최고의 선택인 까닭은 이래요.
- 코딩이 필요 없어요: Thunderbit은 시각적 인터페이스를 제공해요. "AI 필드 제안"을 누르고, 열을 조정한 뒤 "스크래핑"을 누르면 끝이에요. Python도, 디버깅도, 밤새 Stack Overflow를 뒤질 일도 없어요.
- 수천 페이지까지 확장: 제품 목록 10,000개를 긁어야 하나요? Thunderbit의 클라우드 엔진이 알아서 처리해요. 스크립트를 지켜볼 필요도 없죠.
- 유지보수 거의 없음: 이커머스 분석을 위해 경쟁사 사이트 100개를 추적한다고 해볼게요. Python 스크립트 100개를 관리하는 건 악몽이에요. Thunderbit은 템플릿을 고르거나 살짝 손보면 되고, AI가 레이아웃 변화에 알아서 적응해요.
- 하위 페이지와 페이지네이션 지원: Thunderbit은 하위 페이지 링크를 따라가고, 페이지네이션을 처리하고, 제품 상세 페이지까지 방문해 데이터를 풍부하게 채워요.
- 즉시 쓰는 템플릿: Amazon, Zillow, LinkedIn 같은 인기 사이트엔 미리 만든 템플릿이 있어요. 한 번 클릭하면 데이터가 바로 나와요.
- 무료 데이터 내보내기: Excel, Google Sheets, Airtable, Notion으로 추가 비용 없이 내보낼 수 있어요.
이렇게 생각해보세요. 그냥 데이터만 원하는 비즈니스 사용자라면 Thunderbit은 개인 데이터 집사 같은 존재예요. 개발자라서 이것저것 만지는 게 재밌다면 Python이 여전히 놀이터겠지만, 가끔은 그냥 일을 끝내고 싶을 때도 있잖아요.
Thunderbit AI 웹 스크래퍼를 무료로 사용해 보기
윤리적이고 합법적인 Python 웹 스크래핑을 위한 모범 사례
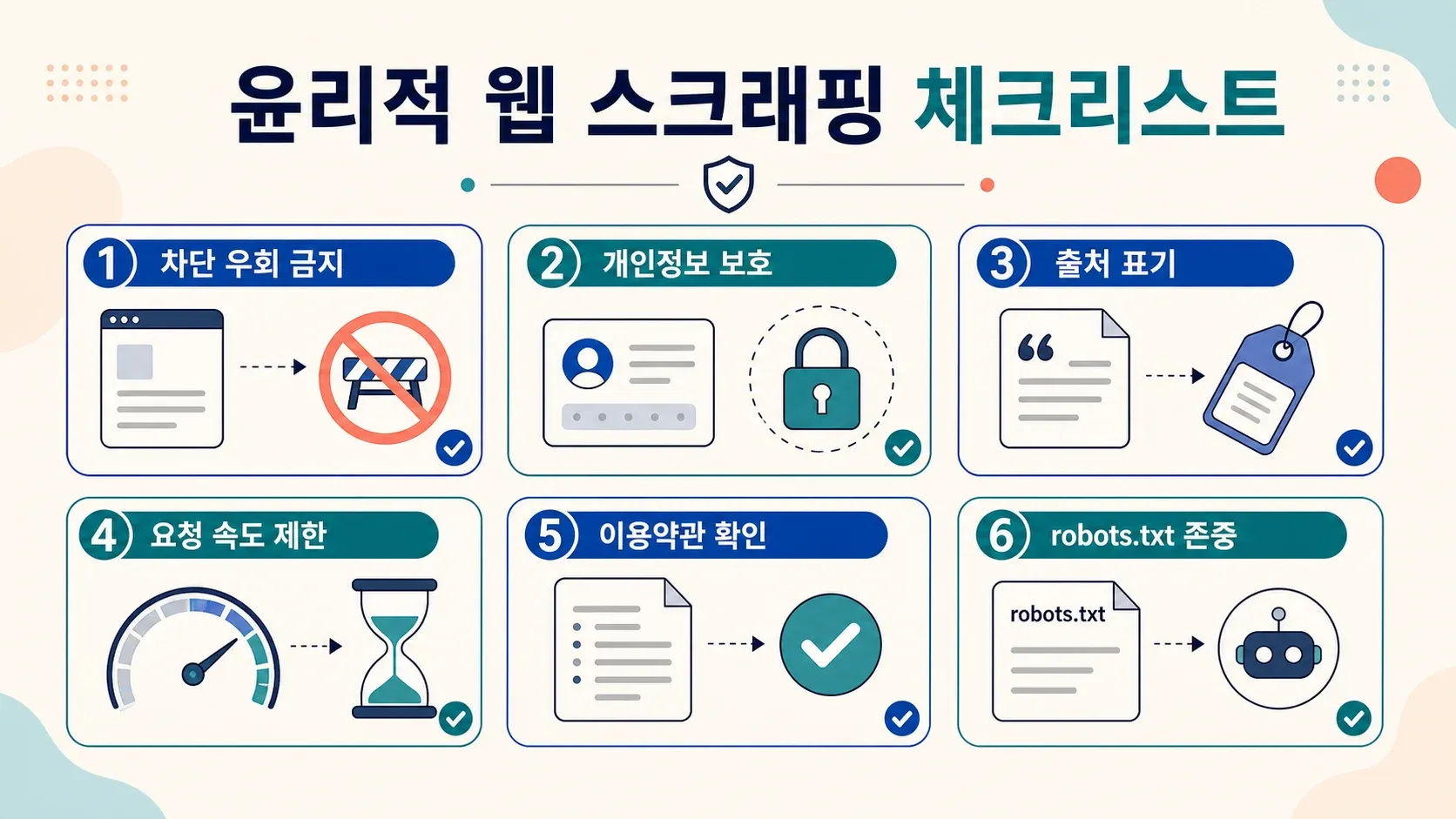
스크래핑은 강력한 만큼 책임도 따라와요. 법과 양심 모두 지키려면 이렇게 하세요.
- robots.txt 확인: 무엇을 긁어도 되는지, 사이트의 의도를 존중하세요.
- 서비스 약관 읽기: 스크래핑을 명시적으로 금지하는 사이트도 있어요. 약관을 어기면 차단되거나 소송에 휘말릴 수 있어요.
- 속도 제한 적용: 서버를 두들기지 말고, 요청 사이에 지연을 넣으세요.
- 개인 데이터 피하기: 개인정보보호법(PIPA)이나 GDPR, CCPA상 개인정보로 잡힐 수 있는 이메일, 전화번호는 특히 조심하세요.
- 안티봇 방어 우회 금지: CAPTCHA나 강한 차단을 쓰는 사이트라면 한 번 더 생각하세요.
- 출처 표기: 분석 결과를 공개한다면 데이터 출처를 밝혀 주세요.
법적 쟁점을 더 알고 싶다면 hiQ 대 LinkedIn 사건 분석과 GDPR 관련 시사점을 확인해 보세요.
더 알아보기: Python 웹 스크래핑 학습 자료(강의, 문서, 커뮤니티)
더 깊이 파고들고 싶으신가요? 제가 추려 둔 자료 목록이에요.
- 공식 문서:
- 도서:
- "Web Scraping with Python" by Ryan Mitchell
- "Automate the Boring Stuff with Python" by Al Sweigart
- 온라인 가이드:
- 영상 튜토리얼:
- freeCodeCamp BeautifulSoup 크래시 코스
- Corey Schafer의 YouTube 채널
- 커뮤니티:
물론 노코드 스크래핑이 어떻게 굴러가는지 보고 싶다면 Thunderbit YouTube 채널이나 Thunderbit 블로그도 확인해 보세요.
결론 및 핵심 요약: 2025년에 맞는 웹 스크래핑 솔루션 고르기
- Python 웹 스크래핑은 정말 강력하고 유연해요. 코드를 좋아하고, 완전한 제어권을 원하고, 약간의 유지보수도 괜찮다면 훌륭한 선택이에요.
- 정적 페이지, 동적 콘텐츠, 폼, API, PDF 등 어떤 작업이든 맞는 Python 라이브러리가 있어요.
- 하지만 대부분의 비즈니스 사용자에겐 스크립트 수십 개를 관리하는 일이 정말 고통스러워요. 데이터를 빠르게, 대규모로, 컴퓨터공학 학위 없이 얻고 싶다면 Thunderbit이 답이에요.
- Thunderbit의 AI 노코드 인터페이스를 쓰면 몇 번의 클릭만으로 어떤 사이트든 긁고, 하위 페이지와 페이지네이션을 처리하고, 필요한 곳으로 데이터를 내보낼 수 있어요. Python은 필요 없어요.
- 윤리와 합법성도 챙겨야 해요: 늘 사이트 정책을 확인하고, 개인정보를 존중하며, 책임 있게 긁으세요.
Python 고수든, 그냥 군말 없이 데이터만 얻고 싶은 분이든, 2026년의 도구는 그 어느 때보다 좋아졌어요. 제 조언은 이거예요. 두 방식 다 써보고, 내 워크플로우에 맞는 걸 고르세요. 지루한 일은 로봇한테 맡겨도 괜찮아요. 다만 예의는 지키게 해 주세요.
깨진 스크립트를 쫓아다니는 데 지쳤다면 Thunderbit의 Chrome 확장 프로그램을 한 번 써보세요. 미래의 나도, 커피 재고도 분명 고마워할 거예요.
더 보고 싶다면 데이터 스크래핑이란 무엇이고 어떻게 하는가 또는 AI를 사용해 웹사이트 데이터를 Excel로 스크래핑하는 방법도 확인해 보세요. 실전 가이드와 최신 스크래핑 전략을 담고 있어요.
AI 웹 스크래퍼 사용해 보기 Get Started Free




