제가 SaaS와 자동화 쪽에 처음 발을 들였을 때만 해도 ‘웹 크롤링’이라는 단어가 마치 거미가 한가롭게 웹을 기어다니는 모습처럼 느껴졌어요. 그런데 지금은 웹 크롤링이 구글 검색부터 가격 비교 사이트까지, 인터넷의 핵심 인프라로 자리 잡았습니다. 웹은 살아 숨 쉬는 생명체 같고, 개발자부터 영업팀까지 모두가 그 안의 데이터를 원하죠. 하지만 현실은 다릅니다. 파이썬 덕분에 웹 크롤러 만들기가 쉬워졌다고는 하지만, 대부분의 사람들은 HTTP 헤더나 자바스크립트 렌더링 같은 걸 배우고 싶지 않고, 그냥 빠르게 데이터를 얻고 싶을 뿐이에요.
여기서부터 이야기가 흥미로워집니다. 공동 창업자로서, 산업 전반에서 웹 데이터 수요가 폭발적으로 늘어나는 걸 직접 보고 있습니다. 영업팀은 새로운 리드를 원하고, 이커머스 매니저는 경쟁사 가격을 모니터링하며, 마케터는 콘텐츠 인사이트에 목말라 있죠. 하지만 모두가 파이썬 고수가 될 시간이나 의지가 있는 건 아니잖아요. 그래서 파이썬 웹 크롤러가 뭔지, 왜 중요한지, 그리고 Thunderbit 같은 AI 기반 도구가 어떻게 비즈니스 사용자와 개발자 모두의 판을 바꾸고 있는지 살펴보려고 합니다.
파이썬 웹 크롤러란? 왜 중요한가?
많은 분들이 헷갈려하는 부분부터 짚고 넘어갈게요. 웹 크롤러와 웹 스크래퍼는 다릅니다. 두 용어가 자주 섞여 쓰이지만, 로봇청소기와 진공청소기만큼이나 역할이 달라요.
- 웹 크롤러는 인터넷의 정찰병 같은 존재입니다. 한 페이지에서 다른 페이지로 링크를 따라가며 체계적으로 웹사이트를 탐색하고 색인하죠. 구글봇이 웹 전체를 지도화하는 것과 비슷해요.
- 웹 스크래퍼는 필요한 정보를 찾아내는 전문가입니다. 웹페이지에서 상품 가격, 연락처, 기사 내용 등 특정 데이터를 뽑아냅니다.

‘web crawler python’이라는 말을 들으면, 보통 파이썬으로 이런 자동화 봇을 만들어 웹을 탐색하거나 데이터를 추출하는 걸 의미합니다. 파이썬이 인기인 이유는 배우기 쉽고, 다양한 라이브러리가 많으며, 솔직히 어셈블리로 웹 크롤러 만들고 싶은 사람은 거의 없으니까요.
웹 크롤링과 웹 스크래핑의 비즈니스 가치
왜 이렇게 많은 팀이 웹 크롤링과 스크래핑에 관심을 가질까요? 웹 데이터는 이제 새로운 원유와도 같습니다. 땅을 파지 않아도, 코드 몇 줄(혹은 버튼 몇 번 클릭)로 얻을 수 있으니까요.
대표적인 비즈니스 활용 사례는 아래와 같습니다:
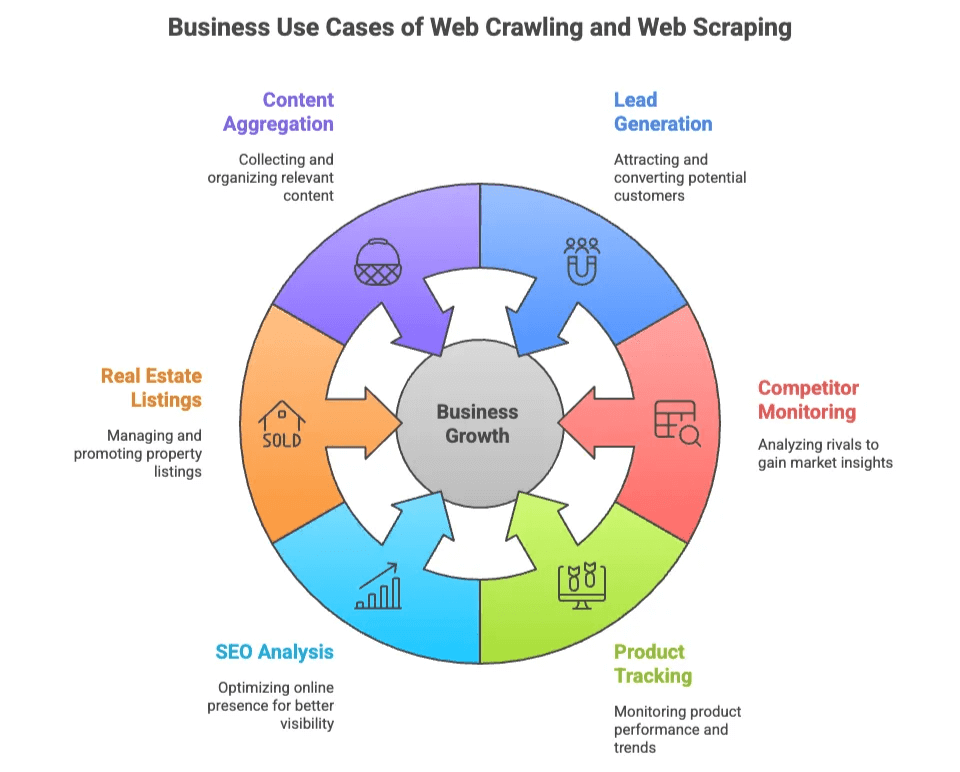
| 활용 사례 | 필요한 부서 | 얻는 가치 |
|---|---|---|
| 리드 발굴 | 영업, 마케팅 | 디렉터리, 소셜 사이트에서 타겟 고객 리스트 구축 |
| 경쟁사 모니터링 | 이커머스, 운영 | 경쟁사 사이트의 가격, 재고, 신상품 추적 |
| 상품 추적 | 이커머스, 소매 | 카탈로그 변경, 리뷰, 평점 모니터링 |
| SEO 분석 | 마케팅, 콘텐츠 | 키워드, 메타태그, 백링크 분석 및 최적화 |
| 부동산 매물 | 중개인, 투자자 | 다양한 소스에서 부동산 데이터 및 연락처 수집 |
| 콘텐츠 집계 | 리서치, 미디어 | 기사, 뉴스, 포럼 글 등 정보 수집 |
개발자는 대규모 프로젝트를 위해 맞춤형 크롤러를 만들 수 있고, 비개발자도 빠르고 정확한 데이터를 얻을 수 있습니다. CSS 셀렉터가 뭔지 몰라도 상관없죠.
파이썬 웹 크롤러 대표 라이브러리: Scrapy, BeautifulSoup, Selenium
파이썬이 웹 크롤링에서 인기인 이유는 대표적인 세 가지 라이브러리 덕분입니다. 각각의 장단점이 확실하죠.
| 라이브러리 | 사용 난이도 | 속도 | 동적 콘텐츠 지원 | 확장성 | 추천 용도 |
|---|---|---|---|---|---|
| Scrapy | 중간 | 빠름 | 제한적 | 높음 | 대규모 자동 크롤링 |
| BeautifulSoup | 쉬움 | 중간 | 없음 | 낮음 | 간단한 파싱, 소규모 프로젝트 |
| Selenium | 어려움 | 느림 | 우수 | 중~낮음 | 자바스크립트 많은 사이트 |
각 라이브러리의 특징을 간단히 살펴볼게요.
Scrapy: 파이썬 웹 크롤러의 만능툴
Scrapy는 파이썬 웹 크롤링의 스위스 아미 나이프 같은 존재입니다. 수천 개의 페이지를 동시에 크롤링하고, 데이터 파이프라인으로 내보내는 등 대규모 자동화에 최적화된 프레임워크죠.
개발자들이 선호하는 이유:
- 크롤링, 파싱, 데이터 내보내기를 한 번에 처리
- 동시 요청, 스케줄링, 파이프라인 등 내장 지원
- 대규모 크롤링 및 스크래핑에 강점
단점: Scrapy는 진입장벽이 있습니다. 셀렉터, 비동기 처리, 프록시, 안티봇 우회 등 다양한 개념을 익혀야 하죠. ()
Scrapy 기본 흐름:
- Spider(크롤러 로직) 정의
- Item 파이프라인 설정(데이터 처리)
- 크롤링 실행 및 데이터 내보내기
구글처럼 웹 전체를 크롤링하려면 Scrapy가 제격입니다. 단순히 이메일 몇 개 추출하려면 오히려 과할 수 있어요.
BeautifulSoup: 가볍고 쉬운 웹 파싱
BeautifulSoup은 웹 파싱의 ‘헬로월드’입니다. HTML, XML 파싱에 특화되어 있어 입문자나 소규모 작업에 딱 맞아요.
사람들이 좋아하는 이유:
- 배우고 사용하기 매우 쉬움
- 정적 페이지 데이터 추출에 적합
- 빠른 스크립트 작성에 유용
단점: BeautifulSoup 자체는 크롤링 기능이 없습니다. requests 등으로 페이지를 직접 불러와야 하고, 링크 따라가기나 다중 페이지 처리도 직접 구현해야 하죠. ()
웹 크롤링을 처음 접한다면 좋은 출발점이지만, 자바스크립트 처리나 대규모 작업에는 한계가 있습니다.
Selenium: 동적·자바스크립트 페이지 완벽 대응
Selenium은 브라우저 자동화의 대표주자입니다. 크롬, 파이어폭스, 엣지 등 실제 브라우저를 제어하며, 버튼 클릭, 폼 입력, 자바스크립트 렌더링까지 가능합니다.

강점:
- 실제 사람처럼 페이지를 보고 상호작용 가능
- 동적 콘텐츠, AJAX 데이터 처리에 강함
- 로그인 등 사용자 행동 시뮬레이션 필수 사이트에 적합
단점: Selenium은 느리고 리소스를 많이 소모합니다. 페이지마다 브라우저를 띄우기 때문에 대규모 크롤링에는 부담이 큽니다. 드라이버 관리, 동적 콘텐츠 대기 등 유지보수도 번거롭죠. ()
Selenium은 일반 스크래퍼로는 접근이 어려운 사이트에 필요합니다.
파이썬 웹 크롤러의 현실적인 어려움
이제 파이썬 웹 크롤링의 고충도 짚어볼게요. 저 역시 수많은 시간을 셀렉터 디버깅과 안티봇 우회에 쏟아부었습니다. 주요 난관은 다음과 같습니다:
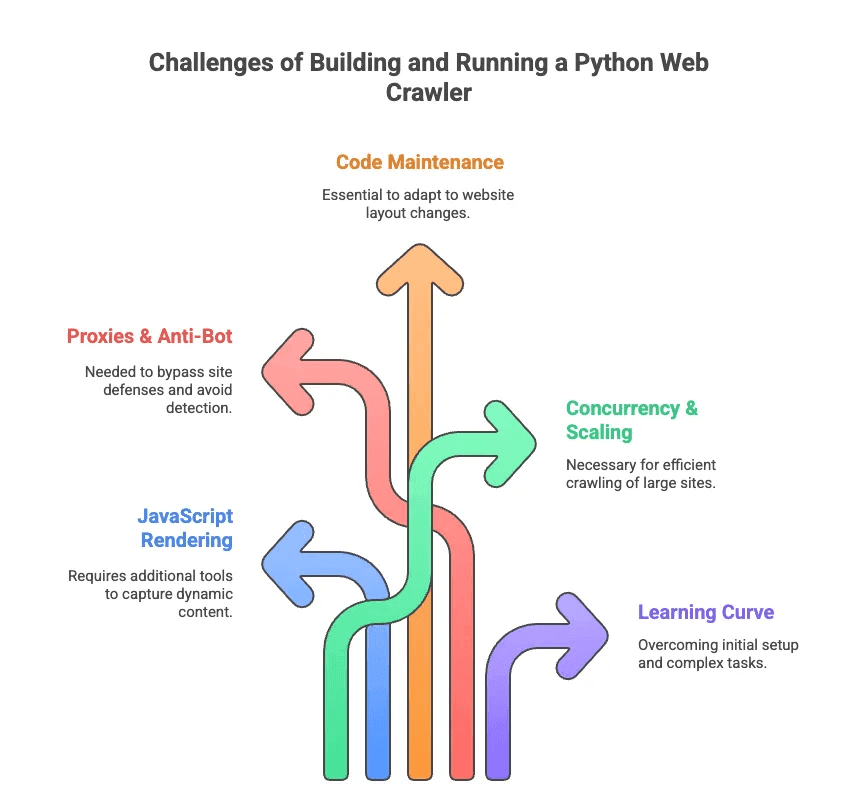
- 자바스크립트 렌더링: 최신 사이트는 대부분 동적으로 콘텐츠를 불러옵니다. Scrapy, BeautifulSoup만으론 데이터가 보이지 않아 추가 도구가 필요해요.
- 프록시 & 안티봇: 많은 사이트가 크롤링을 막습니다. 프록시 회전, 유저 에이전트 변경, CAPTCHA 해결 등 다양한 우회 기술이 필요하죠.
- 코드 유지보수: 웹사이트 레이아웃이 자주 바뀌어, 크롤러가 쉽게 망가집니다. 셀렉터나 로직을 계속 수정해야 해요.
- 동시성 & 확장성: 수천 페이지를 크롤링하려면 비동기 요청, 에러 처리, 데이터 파이프라인 관리가 필수입니다.
- 학습 곡선: 비개발자에게는 파이썬 설치부터 라이브러리 세팅까지도 벅찹니다. 페이지네이션, 로그인 처리 등은 더더욱 어렵죠.
한 엔지니어의 말처럼, 커스텀 스크래퍼를 짜는 건 ‘셀렉터 박사학위’가 필요한 느낌입니다. ()
AI 웹 스크래퍼 vs. 파이썬 웹 크롤러: 비즈니스 사용자를 위한 새로운 해법
데이터는 필요하지만, 복잡한 과정은 피하고 싶으신가요? 바로 AI 웹 스크래퍼가 답입니다. 같은 도구는 개발자가 아닌 비즈니스 사용자를 위해 만들어졌어요. AI가 웹페이지를 읽고, 추출할 데이터를 추천하며, 페이지네이션, 하위 페이지, 안티봇 우회 등 복잡한 작업을 자동으로 처리합니다.
간단 비교표를 보시죠:
| 기능 | 파이썬 웹 크롤러 | AI 웹 스크래퍼(Thunderbit) |
|---|---|---|
| 설치 | 코드, 라이브러리, 설정 필요 | 2번 클릭으로 크롬 확장 설치 |
| 유지보수 | 수동 업데이트, 디버깅 | AI가 사이트 변경 자동 대응 |
| 동적 콘텐츠 | Selenium 등 별도 필요 | 브라우저/클라우드 내장 지원 |
| 안티봇 우회 | 프록시, 유저에이전트 직접 설정 | AI·클라우드 기반 자동 우회 |
| 확장성 | 노력 필요, 직접 구현 | 클라우드·병렬 스크래핑 지원 |
| 사용 편의성 | 개발자용 | 누구나 사용 가능 |
| 데이터 내보내기 | 코드/스크립트 필요 | 1클릭으로 시트, Airtable, Notion |
Thunderbit를 사용하면 HTTP 요청, 자바스크립트, 프록시 걱정이 없습니다. ‘AI 필드 추천’을 클릭하면 AI가 중요한 데이터를 알아서 찾아주고, ‘스크랩’만 누르면 끝이에요. 마치 데이터 집사를 고용한 느낌이죠.
Thunderbit: 모두를 위한 차세대 AI 웹 스크래퍼
Thunderbit는 으로, 웹 데이터 추출을 배달 주문만큼 쉽게 만들어줍니다. Thunderbit만의 강점은 다음과 같습니다:
- AI 필드 자동 감지: Thunderbit의 AI가 페이지를 읽고 추출할 필드(컬럼)를 추천합니다. CSS 셀렉터 고민 끝! ()
- 동적 페이지 완벽 지원: 정적·자바스크립트 페이지 모두 브라우저/클라우드 모드로 처리
- 하위 페이지·페이지네이션: 상품·프로필 등 상세 정보도 자동으로 클릭해 수집 ()
- 템플릿 유연성: 하나의 스크래퍼 템플릿으로 다양한 페이지 구조에 대응, 사이트가 바뀌어도 재설정 필요 없음
- 안티봇 우회: AI와 클라우드 인프라로 크롤링 방지 기술도 손쉽게 통과
- 데이터 내보내기: 구글 시트, Airtable, Notion, CSV/Excel로 바로 내보내기—무료 플랜도 제한 없음 ()
- AI 데이터 정제: 데이터 요약, 분류, 번역까지 실시간 처리—엉망진창 엑셀과 이별하세요.
실제 활용 예시:
- 영업팀: 디렉터리·링크드인에서 잠재 고객 리스트를 몇 분 만에 추출
- 이커머스 매니저: 경쟁사 가격·상품 변동을 자동 모니터링
- 부동산 중개인: 여러 사이트에서 매물·소유주 연락처 집계
- 마케팅팀: 콘텐츠, 키워드, 백링크 분석—코딩 없이 SEO 데이터 확보
Thunderbit의 워크플로우는 비개발자도 바로 쓸 만큼 쉽습니다. 확장 프로그램 설치, 타겟 사이트 접속, ‘AI 필드 추천’ 클릭만 하면 바로 시작! 아마존, 링크드인 등 인기 사이트는 즉시 사용할 수 있는 템플릿도 제공해 원클릭으로 끝낼 수 있습니다. ()
언제 파이썬 웹 크롤러, 언제 AI 웹 스크래퍼를 써야 할까?
파이썬 웹 크롤러를 직접 만들지, Thunderbit를 쓸지 고민된다면 아래 표를 참고하세요.
| 상황 | 파이썬 웹 크롤러 | AI 웹 스크래퍼(Thunderbit) |
|---|---|---|
| 맞춤 로직·대규모 작업 필요 | ✔️ | 경우에 따라(클라우드 모드) |
| 시스템과 깊은 연동 필요 | ✔️(코드로 가능) | 제한적(내보내기 위주) |
| 비개발자, 빠른 결과 필요 | ❌ | ✔️ |
| 사이트 레이아웃 자주 변경 | ❌(수동 수정) | ✔️(AI 자동 대응) |
| 동적/JS 많은 사이트 | ✔️(Selenium 필요) | ✔️(내장 지원) |
| 예산·소규모 프로젝트 | 경우에 따라(무료지만 시간 소요) | ✔️(무료 플랜, 제한 없음) |
파이썬 웹 크롤러가 적합한 경우:
- 개발자이고, 완전한 제어가 필요할 때
- 수백만 페이지 크롤링, 맞춤 데이터 파이프라인 구축 시
- 지속적인 유지보수와 디버깅이 괜찮을 때
Thunderbit가 적합한 경우:
- 데이터를 바로, 빠르고 깔끔하게 얻고 싶을 때
- 영업, 이커머스, 마케팅, 부동산 등 실무자가 결과만 필요할 때
- 프록시, 셀렉터, 안티봇 등 복잡한 설정을 피하고 싶을 때
아직도 고민된다면, 아래 체크리스트를 참고하세요:
- 파이썬과 웹 기술에 익숙하다면 Scrapy나 Selenium을 시도해보세요.
- 빠르고 손쉬운 데이터가 필요하다면 Thunderbit가 정답입니다.
결론: 내게 맞는 웹 데이터 추출법 찾기
웹 크롤링과 스크래핑은 데이터 중심 시대에 필수 역량이 됐습니다. 하지만 모두가 웹 크롤링 전문가가 될 필요는 없어요. Scrapy, BeautifulSoup, Selenium 같은 파이썬 웹 크롤러는 강력하지만, 진입장벽과 유지보수 부담이 큽니다.
그래서 저는 같은 AI 웹 스크래퍼의 등장이 정말 반갑습니다. Thunderbit는 웹 데이터의 힘을 개발자뿐 아니라 누구에게나 제공합니다. AI 필드 감지, 동적 페이지 지원, 노코드 워크플로우로 누구나 몇 분 만에 원하는 데이터를 추출할 수 있죠.
코딩을 좋아하는 개발자든, 결과만 필요한 비즈니스 사용자든, 여러분에게 맞는 도구가 있습니다. 필요, 기술 수준, 시간에 따라 선택하세요. 그리고 웹 데이터 추출이 얼마나 쉬워질 수 있는지 직접 경험해보고 싶다면, . 미래의 나와 스프레드시트가 분명 고마워할 거예요.
더 깊이 알고 싶다면 에서 나 등 다양한 가이드를 참고하세요. 모두에게 성공적인 크롤링과 스크래핑을 기원합니다!
자주 묻는 질문(FAQ)
1. 파이썬 웹 크롤러와 웹 스크래퍼의 차이는 무엇인가요?
파이썬 웹 크롤러는 하이퍼링크를 따라가며 웹페이지를 체계적으로 탐색·색인하는 데 초점을 둡니다. 반면 웹 스크래퍼는 그 페이지에서 가격, 이메일 등 특정 데이터를 추출합니다. 크롤러는 인터넷 지도를 만들고, 스크래퍼는 필요한 정보를 수집하죠. 파이썬에서는 두 기능을 함께 활용해 데이터 추출 워크플로우를 완성할 수 있습니다.
2. 파이썬 웹 크롤러 구축에 가장 좋은 라이브러리는?
대표적으로 Scrapy, BeautifulSoup, Selenium이 있습니다. Scrapy는 대규모 프로젝트에 빠르고 확장성이 뛰어나며, BeautifulSoup은 입문자에게 쉽고 정적 페이지에 적합합니다. Selenium은 자바스크립트가 많은 사이트에 강하지만 속도는 느립니다. 기술 수준, 데이터 유형, 프로젝트 규모에 따라 선택하세요.
3. 파이썬 웹 크롤러 코딩 없이 웹 데이터를 쉽게 얻는 방법이 있나요?
네, Thunderbit는 AI 기반 크롬 확장 프로그램으로, 누구나 클릭 두 번이면 웹 데이터를 추출할 수 있습니다. 코드나 복잡한 설정 없이 필드 자동 감지, 페이지네이션·하위 페이지 처리, 시트·Airtable·Notion 내보내기까지 지원합니다. 영업, 마케팅, 이커머스, 부동산 등 실무자에게 빠르고 깔끔한 데이터가 필요할 때 딱 맞는 솔루션입니다.
더 알아보기: