

웹에는 입력해야 할 폼, 확인해야 할 대시보드, 정리해야 할 데이터가 정말 많죠. 저처럼 똑같은 사이트를 수십 번 클릭하다가 ‘이거 좀 더 쉽게 할 수 없나?’ 고민해본 적 있으신가요? 저만 그런 게 아니더라고요. 2024년 기준, Python은 GitHub에서 JavaScript를 제치고 가장 인기 있는 언어로 등극했고, Python 개발자 중 약 4분의 1이 자동화와 웹 스크래핑에 Python을 활용하고 있습니다(GitHub Octoverse, JetBrains Survey). 그 이유는? Python 덕분에 python 웹사이트 자동화가 개발자가 아니어도 실전에서 쓸 만큼 쉬워졌기 때문입니다.
이 글에서는 python으로 웹 작업 자동화하는 방법을 단계별로 안내합니다. Python이 자동화에 딱 맞는 이유부터, 필수 도구 세팅법, Selenium으로 폼 자동 입력 및 사이트 탐색 팁, 그리고 Thunderbit 같은 AI 기반 도구로 자동화를 한 단계 업그레이드하는 방법까지 모두 다룹니다. 반복 작업에 지친 비즈니스 실무자든, 업무 효율을 높이고 싶은 개발자든, 바로 써먹을 수 있는 팁과 코드 예시, 그리고 제가 직접 겪은 시행착오까지 아낌없이 공유할게요.
왜 Python으로 웹사이트 자동화를 할까요?
AI로 어떤 웹사이트든 데이터 추출하기 Get Started Free
가장 먼저 드는 궁금증이죠. 왜 하필 Python일까요? 제 경험과 개발자 커뮤니티의 의견을 종합해보면, Python은 자동화 분야에서 거의 만능툴에 가깝습니다. 그 이유는 다음과 같아요.
- 가독성 & 접근성: Python은 문법이 직관적이라 초보자도 금방 읽고 고칠 수 있습니다. 개발 경험이 많지 않아도 Python 코드는 어렵지 않게 이해할 수 있죠(Monterail).
- 풍부한 라이브러리: 웹 자동화에 특화된 라이브러리가 정말 많아요. 대표적으로
- Selenium: 실제 브라우저에서 클릭, 입력, 이동 등 사용자의 행동을 그대로 재현합니다(BlazeMeter).
- Requests: 브라우저 없이 HTTP 요청으로 웹페이지나 API 데이터를 받아옵니다(Requests Docs).
- BeautifulSoup: HTML이나 XML에서 원하는 데이터를 쉽게 뽑아낼 수 있습니다(BeautifulSoup Docs).
- 커뮤니티 & 지원: 막히는 부분이 생기면 Stack Overflow나 블로그에서 이미 누군가 해결책을 공유했을 확률이 높아요.
- 크로스 플랫폼: Python 스크립트는 Windows, macOS, Linux 어디서든 거의 똑같이 돌아갑니다.
Java나 C# 같은 언어에 비해 Python은 훨씬 적은 코드로 빠르게 자동화를 구현할 수 있습니다. JavaScript도 브라우저 자동화가 가능하지만, Python의 라이브러리와 문서화 덕분에 비즈니스 자동화에는 Python이 더 잘 어울려요(ActiveBatch).
Python 자동화 환경 세팅하기
자동화를 시작하려면 환경부터 제대로 갖추는 게 중요합니다. Windows, macOS, Linux 어디서든 아래 순서대로 따라오세요.
1. Python과 Pip 설치
- Windows: python.org에서 Python 3을 다운받고, 설치할 때 "Add Python to PATH" 꼭 체크하세요.
- macOS: 공식 설치 프로그램을 쓰거나 Homebrew를 쓴다면
brew install python3명령어를 사용하세요. - Linux: 대부분 기본 설치되어 있지만, 없다면
sudo apt-get install python3 python3-pip로 설치하세요.
설치 확인은 아래처럼:
python3 --version
pip --version
pip이 없다면 따로 설치해야 할 수도 있습니다(Ubuntu는 sudo apt-get install python3-pip).
2. Selenium 등 필수 패키지 설치
Python과 pip이 준비됐다면 필요한 라이브러리를 설치하세요:
pip install selenium requests beautifulsoup4
- Selenium: 브라우저 자동화
- Requests: HTTP 요청
- BeautifulSoup: HTML 파싱
3. WebDriver 다운로드(Selenium용)
Selenium은 브라우저를 제어하려면 드라이버가 필요합니다. Chrome은 ChromeDriver, Firefox는 geckodriver를 받아주세요.
- 드라이버를 시스템 PATH에 두거나, 스크립트에서 경로를 지정할 수 있습니다:
from selenium import webdriver
driver = webdriver.Chrome(executable_path="/path/to/chromedriver")
최신 Selenium은 드라이버가 PATH에 있으면 자동으로 인식하기도 해요.
4. 가상환경(Virtual Environment) 설정
venv나 virtualenv를 쓰면 프로젝트별로 패키지 버전을 관리할 수 있어 충돌을 막을 수 있습니다(Real Python).
가상환경 만들고 활성화하기:
python3 -m venv myenv
source myenv/bin/activate # Windows는 myenv\Scripts\activate
이제 pip install은 이 프로젝트에만 적용됩니다.
5. 운영체제별 팁 & 문제 해결
- Windows:
python이나pip이 인식 안 되면 PATH 설정을 확인하거나py명령어를 써보세요. - macOS: 시스템 Python과 헷갈리지 않게
python3를 사용하세요. - Linux: 서버에서 Selenium을 쓸 땐 headless 모드나 Xvfb 설정이 필요할 수 있습니다.
드라이버 버전이나 패키지 문제로 에러가 나면 호환성을 다시 확인하고 업데이트하세요.
Selenium으로 웹 폼 자동 입력 및 사이트 탐색하기
이제 본격적으로 브라우저를 자동으로 조작해봅시다. Selenium을 활용하면 간단한 로그인부터 복잡한 다단계 작업까지 모두 자동화할 수 있습니다.
브라우저 열고 페이지 접속하기
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
이렇게 하면 Chrome이 열리고 로그인 페이지로 이동합니다.
요소 찾기 및 상호작용
Selenium은 ID, name, CSS selector, XPath 등 다양한 방법으로 요소를 찾을 수 있습니다:
username_box = driver.find_element(By.ID, "username")
password_box = driver.find_element(By.NAME, "pwd")
login_button = driver.find_element(By.XPATH, "//button[@type='submit']")
- 텍스트 입력:
username_box.send_keys("alice") - 버튼 클릭:
login_button.click() - 드롭다운 선택:
from selenium.webdriver.support.ui import Select
select_elem = Select(driver.find_element(By.ID, "country"))
select_elem.select_by_visible_text("Canada")
- 다른 페이지로 이동:
driver.get("https://example.com/profile")
요소 선택 시 베스트 프랙티스
- ID나 고유 속성을 우선 사용하세요.
- CSS selector가 간결하고 유지보수에 좋습니다.
- 절대 XPath는 페이지 구조가 바뀌면 쉽게 깨지니 피하세요(Medium).
동적 콘텐츠와 대기(Waits) 처리
요즘 웹사이트는 비동기로 데이터를 불러오는 경우가 많아, 요소가 준비되기 전에 클릭하면 에러가 납니다. **명시적 대기(Explicit Waits)**를 사용하세요:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.ID, "loginBtn")))
이렇게 하면 로그인 버튼이 클릭 가능해질 때까지 최대 10초 기다립니다. 무작정 time.sleep()을 쓰는 것보다 훨씬 안정적입니다(BrowserStack).
예시: 다단계 웹 폼 자동화
공개 데모 사이트를 활용해 2단계 회원가입 폼을 자동화해봅니다:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://practicetestautomation.com/Practice-Signup")
# 1단계: 첫 번째 폼 입력
driver.find_element(By.ID, "name").send_keys("Alice")
driver.find_element(By.ID, "email").send_keys("alice@example.com")
driver.find_element(By.ID, "password").send_keys("SuperSecret123")
driver.find_element(By.ID, "nextBtn").click()
# 2단계: 두 번째 폼이 나타날 때까지 대기 후 입력
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.ID, "address")))
driver.find_element(By.ID, "address").send_keys("123 Maple St")
driver.find_element(By.ID, "phone").send_keys("5551234567")
driver.find_element(By.ID, "submitBtn").click()
# 3단계: 가입 완료 메시지 확인
WebDriverWait(driver, 5).until(EC.text_to_be_present_in_element((By.TAG_NAME, "h1"), "Welcome"))
print("회원가입 성공!")
driver.quit()
이 스크립트는 각 단계별로 폼을 입력하고, 폼이 준비될 때까지 기다린 뒤 성공 메시지를 확인합니다. 실무에서도 자주 쓰는 패턴이에요.
Thunderbit: 복잡한 웹사이트 자동화를 위한 AI 기반 솔루션
Thunderbit 크롬 확장 프로그램 사용해보기 AI로 웹 데이터 추출과 자동화 워크플로우를 몇 번의 클릭만으로 구현하세요. Get Started Free
이제 중요한 질문! 만약 복잡한 웹사이트, PDF나 이미지에서 데이터 추출, 혹은 코딩 없이 자동화를 하고 싶다면? 바로 Thunderbit가 답입니다.
Thunderbit는 AI 웹 스크래퍼 크롬 확장 프로그램으로, 클릭 몇 번만으로 데이터 추출과 웹 자동화를 할 수 있습니다. 코딩이 전혀 필요 없습니다. Thunderbit가 비즈니스 사용자에게 혁신적인 이유는 다음과 같습니다:
- 자연어 명령: 원하는 데이터를 자연스럽게 설명만 하면(예: "상품명, 가격, 평점"), Thunderbit의 AI가 알아서 추출 방법을 찾아줍니다(Futurepedia).
- 서브페이지 자동 추출: 각 상품 상세페이지 등 하위 페이지도 자동 방문해 데이터를 테이블에 추가합니다.
- 즉시 사용 가능한 템플릿: Amazon, Zillow 등 인기 사이트는 원클릭 템플릿으로 바로 추출 가능합니다.
- PDF/이미지 지원: PDF(스캔본 포함)와 이미지에서 텍스트 추출도 지원합니다. Python에서는 별도 라이브러리와 추가 설정이 필요하죠.
- 정기 스크래핑: "매주 월요일 오전 9시"처럼 반복 작업도 자연어로 예약할 수 있습니다.
- 무료 데이터 내보내기: Excel, Google Sheets, Airtable, Notion, CSV, JSON 등 다양한 포맷으로 무료로 내보낼 수 있습니다.
Thunderbit는 비정형 웹 콘텐츠를 구조화된 데이터로 바꾸거나, 비개발자 팀원도 직접 자동화를 할 수 있게 해줍니다. 마치 AI 리서치 어시스턴트가 반복 작업을 대신해주는 느낌이죠.
Thunderbit와 Python 스크립트, 언제 어떤 걸 써야 할까?
-
Python(Selenium/Requests/BeautifulSoup) 사용 추천:
- 커스텀 로직, 외부 시스템 연동, 세밀한 제어가 필요할 때
- 웹 스크래핑을 넘어 데이터 분석, API 호출, 복잡한 조건 처리 등 확장 작업이 필요할 때
- 코딩에 익숙하고 버전 관리가 필요한 경우
-
Thunderbit 사용 추천:
- 빠르고 간단한 데이터 추출, 반복적인 웹 작업을 코드 없이 처리하고 싶을 때
- 비정형/복잡한 사이트, PDF, 이미지 등 다양한 포맷을 다뤄야 할 때
- 비개발자도 직접 자동화하고 싶거나, 자주 반복되는 작업을 빠르게 처리하고 싶을 때
실제로 저도 두 가지를 병행합니다. Thunderbit로 빠르게 프로토타입을 만들거나 영업/운영팀이 직접 자동화할 때, Python 스크립트는 복잡한 통합이나 맞춤형 워크플로우에 활용합니다.
Python 자동화 스크립트의 안정성과 신뢰성 높이기
자동화는 신뢰성이 생명입니다. 웹 환경이 변해도 스크립트가 잘 동작하도록 다음 팁을 꼭 실천하세요:
에러 처리와 재시도
취약한 부분은 try/except로 감싸세요:
try:
element = driver.find_element(By.ID, "price")
except Exception as e:
print("가격 요소 찾기 오류:", e)
driver.save_screenshot("screenshot_error.png")
# 필요시 재시도 또는 건너뛰기
네트워크 불안정이나 요소 불안정에는 간단한 재시도 로직을 추가하세요:
import time
max_retries = 3
for attempt in range(max_retries):
try:
driver.get(url)
break
except Exception as e:
print(f"{attempt+1}번째 시도 실패, 재시도 중...")
time.sleep(5)
명시적 대기 적극 활용
모든 상호작용 전에 명시적 대기를 사용하세요:
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, "result"))).click()
로깅과 모니터링
장시간 실행되는 스크립트는 Python의 logging 모듈로 진행 상황과 에러를 기록하세요. 중요한 오류는 이메일이나 Slack 알림으로 받아보는 것도 좋습니다. 실패 시 스크린샷 저장은 디버깅에 큰 도움이 됩니다.
리소스 관리
스크립트 마지막에는 반드시 driver.quit()을 호출해 브라우저가 백그라운드에 남지 않게 하세요.
서버 부하 방지와 예의
많은 페이지를 스크래핑할 때는 time.sleep(random.uniform(1,3))처럼 랜덤 지연을 추가해 차단을 피하세요. robots.txt를 준수하고, 서버에 과도한 부하를 주지 않도록 주의하세요.
웹사이트 변경에 유연하게 대응
웹사이트는 자주 바뀝니다. ID가 바뀌거나 레이아웃이 달라질 수 있습니다. 다음 방법으로 스크립트를 미래지향적으로 관리하세요:
- 유연한 선택자 사용: XPath 대신 안정적인 속성이나
data-*속성을 활용하세요. - 선택자 중앙 관리: 모든 선택자를 스크립트 상단에 모아두면 수정이 쉽습니다.
- 정기 테스트: 주기적으로 스크립트를 실행해 문제를 조기에 발견하세요.
- 버전 관리: Git 등으로 변경 이력을 관리하세요.
내부 시스템을 자동화한다면, 웹 개발팀에 data-automation-id 같은 고정 속성 추가를 요청하는 것도 좋은 방법입니다.
Python 자동화 도구 비교: Selenium, Requests, BeautifulSoup, Thunderbit
작업에 맞는 도구를 고를 수 있도록 간단히 비교해봅니다:
| Tool | Strengths & Use Cases | Limitations & Notes |
|---|---|---|
| Selenium (WebDriver) | 실제 브라우저 자동화, 동적 JS 처리, 사용자 행동 재현, 복잡한 다단계 워크플로우에 적합 | 속도가 느리고 리소스 소모가 큼, 드라이버 설치 필요, 선택자 관리가 중요 |
| Requests + BeautifulSoup | 정적 페이지/API에 빠르고 가벼움, HTML 파싱이 쉬움, 대량 데이터 추출에 적합(JS 필요 없는 경우) | 동적 JS 처리 불가, 사용자 상호작용 불가, 파싱 로직 직접 작성 필요 |
| Thunderbit | 코드 없이 AI로 복잡/비정형 사이트, PDF, 이미지, 서브페이지까지 추출, 즉시 사용 템플릿, 무료 내보내기, 비개발자도 사용 가능 | 커스텀 로직 한계, 외부 서비스 의존, AI 추출 결과는 일부 조정 필요 |
실전 예시: Python으로 웹사이트 자동화 7단계 체크리스트
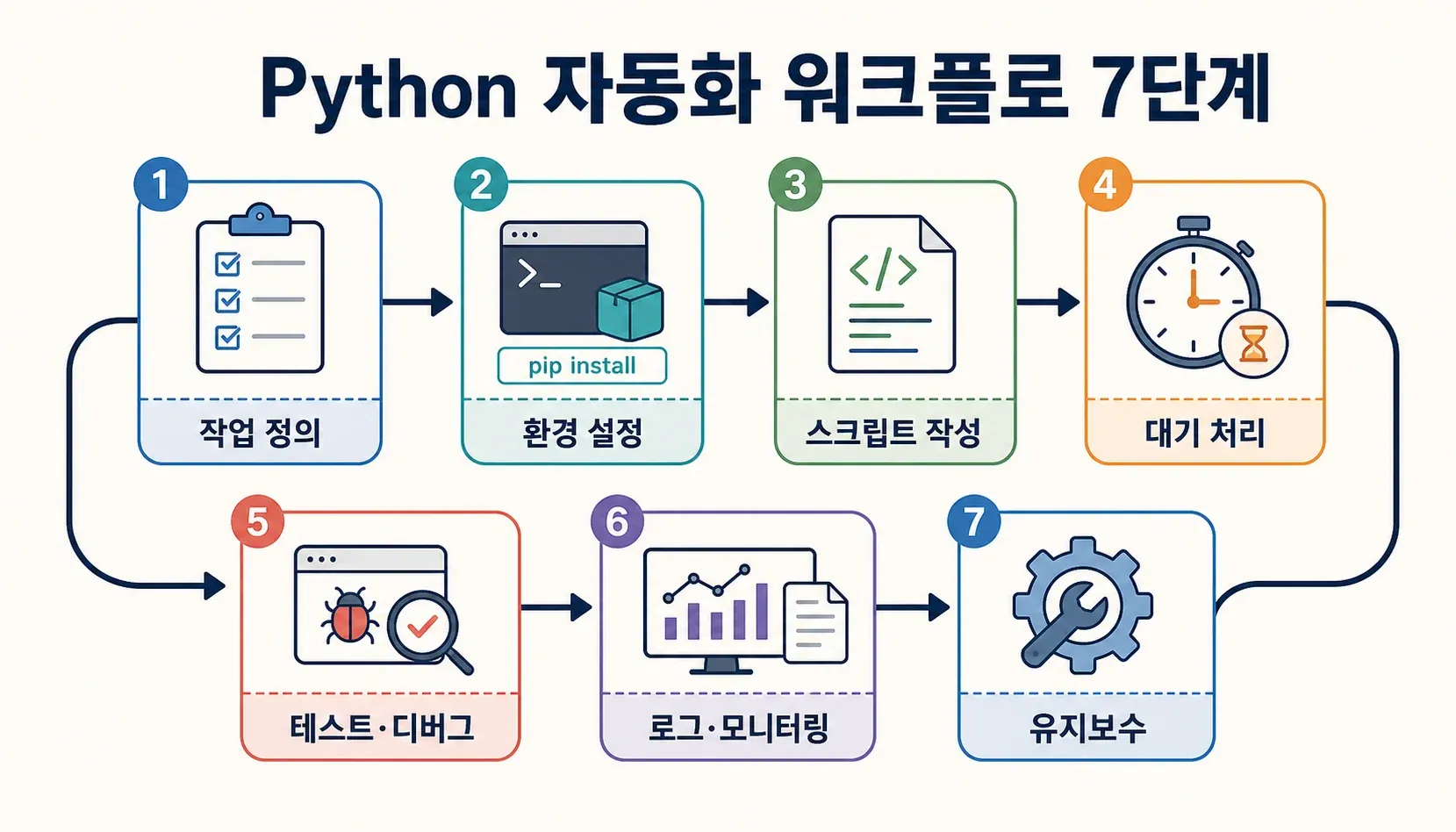 제가 실제로 사용하는 웹 자동화 체크리스트입니다:
제가 실제로 사용하는 웹 자동화 체크리스트입니다:
- 작업 정의: 수작업으로 할 때의 단계를 적어보고, 로그인/팝업/동적 콘텐츠 등 까다로운 부분을 파악합니다.
- 환경 세팅: Python, pip, 가상환경, Selenium, WebDriver를 설치합니다.
- 스크립트 점진적 작성: 기본 이동부터 시작해 단계별로 상호작용을 추가하며, 매 단계마다 테스트합니다.
- 대기와 에러 처리 추가: 명시적 대기와 try/except로 취약 구간을 보완합니다.
- 로깅 및 모니터링: 진행 상황과 에러를 기록하고, 실패 시 스크린샷을 남깁니다.
- 테스트 및 디버깅: 브라우저 개발자 도구로 선택자를 확인하고, 눈으로 직접 실행해 예기치 않은 팝업이나 리디렉션을 체크합니다.
- 유지보수: 선택자는 스크립트 상단에 모으고, 버전 관리로 변경 이력을 남기며, 정기적으로 스크립트를 점검합니다.
자동화가 처음이라면, 테스트 사이트 로그인이나 간단한 폼 자동 입력부터 시작해보세요. 작은 성공이 쌓이면 실력이 빠르게 늘어납니다.
결론 & 핵심 요약
python 웹사이트 자동화를 하면 반복 작업에서 해방될 수 있습니다. 읽기 쉬운 문법과 강력한 라이브러리 덕분에, 단순 폼 입력부터 복잡한 다단계 워크플로우까지 모두 자동화할 수 있습니다. 커뮤니티도 활발하고 자료도 풍부해, 하루 15분만 절약해도 1년에 90시간 가까이 아낄 수 있습니다(LinkedIn).
하지만 때로는 AI 기반 도구인 Thunderbit가 더 빠른 해결책이 될 수 있습니다. 비정형 사이트나 비개발자 팀원에게 자동화를 맡기고 싶을 때, Thunderbit는 클릭 몇 번으로 데이터 추출과 웹 자동화를 실현합니다.
제 조언은? 자주 반복하는 귀찮은 웹 작업 하나를 골라 Python이나 Thunderbit로 자동화에 도전해보세요. '또 이거 해야 해?'에서 '몇 초 만에 끝!'으로 바뀌는 경험을 하실 겁니다.
웹 스크래핑에 대해 더 배우고 싶다면 Thunderbit 블로그에서 다양한 가이드와 팁을 확인해보세요.
자주 묻는 질문(FAQ)
1. Python이 웹사이트 자동화에 인기 있는 이유는?
Python은 읽기 쉬운 문법, Selenium/Requests/BeautifulSoup 등 풍부한 라이브러리, 그리고 방대한 커뮤니티 지원 덕분에 웹 자동화와 스크립팅에 최적화되어 있습니다(GitHub Octoverse).
2. Selenium, Requests, BeautifulSoup의 차이점은?
Selenium은 동적 사이트와 사용자 행동 자동화에, Requests는 브라우저 없이 정적 페이지나 API 데이터 수집에, BeautifulSoup은 HTML 파싱 및 데이터 추출에 주로 사용됩니다.
3. Python 스크립트 대신 Thunderbit를 써야 할 때는?
비정형/복잡한 사이트, PDF/이미지 데이터 추출, 비개발자도 쉽게 쓸 수 있는 AI 기반 솔루션이 필요할 때 Thunderbit가 적합합니다. 커스텀 로직이나 통합이 필요하면 Python 스크립트가 더 유리합니다.
4. Python 자동화 스크립트를 더 안정적으로 만드는 방법은?
명시적 대기, try/except 에러 처리, 네트워크 재시도 로직, 로깅 등으로 신뢰성을 높이세요. 선택자는 한 곳에 모아두고, 사이트 변경 시 빠르게 수정할 수 있게 관리하세요.
5. Thunderbit와 Python을 함께 쓸 수 있나요?
물론입니다! Thunderbit로 빠르게 데이터 추출 후 Python으로 추가 분석/처리를 하거나, Python으로 복잡한 로직을 자동화하고 Thunderbit로 반복 스크래핑을 할 수 있습니다.
웹 자동화에 도전해보고 싶으신가요? Thunderbit 무료 크롬 확장 프로그램을 사용해보거나, Python으로 직접 스크립트를 작성해보세요. 어떤 방법이든, 곧 더 똑똑하게 일하게 될 거예요.
AI 웹 스크래퍼 사용해보기 Get Started Free
더 알아보기




