

웹 스크래핑에 처음 발을 들이는 개발자들 보면, 대부분 "경쟁사 사이트에서 상품 정보를 한번 뽑아 볼까?" 하는 호기심에서 시작하더라고요. 그때 가장 먼저 만나게 되는 도구가 바로 BeautifulSoup이에요. 그런데 처음에는 설치나 사용법이 좀 막막하게 느껴지기 쉬워요. 몇 번 시도하다가 pip install beautifulsoup4 명령어로 설치를 끝내고, 간단하게 HTML 요소(예: 헤드라인) 하나를 뽑아 보는 순간 "아, 이거였구나" 하는 깨달음이 오거든요. 이 작은 성공 경험이 파이썬 입문자에게는 꽤 큰 자신감으로 이어지곤 해요.
웹 스크래핑을 막 시작했다면 BeautifulSoup이라는 이름은 거의 가장 먼저 듣게 될 거예요. 그만큼 쉽고 강력해서, 10년 넘게 파이썬 웹 스크래핑의 대표 라이브러리 자리를 지켜 오고 있거든요. 이번 글에서는 pip으로 BeautifulSoup을 설치하는 방법부터 실제 코드 예제까지, 그리고 지금도 많은 개발자와 데이터 분석가가 BeautifulSoup을 손에서 놓지 않는 이유를 하나씩 풀어 볼게요. 물론 BeautifulSoup의 한계, 그리고 최근 비개발자들이 AI 기반 도구(예: Thunderbit)로 옮겨 가는 흐름까지 솔직하게 같이 다룰게요.
BeautifulSoup이란? 그리고 여전히 많이 쓰이는 이유는?
BeautifulSoup vs. AI 웹 스크래퍼: 완벽 비교 Get Started Free
먼저 BeautifulSoup이 뭔지부터 짚고 갈게요. 한마디로, 파이썬에서 HTML이나 XML을 쉽게 다룰 수 있게 해 주는 'HTML 파서'예요. HTML 코드를 넣으면 BeautifulSoup이 트리 구조로 바꿔 주니까, 원하는 데이터를 파이썬 코드로 손쉽게 찾고, 탐색하고, 뽑아낼 수 있어요. 웹페이지의 내부 구조를 투명하게 들여다보는 도구라고 생각하면 감이 쉽게 잡혀요.
BeautifulSoup이 꾸준히 사랑받는 이유는요?
새 스크래핑 프레임워크가 계속 나와도, 파이썬 입문자들이 가장 먼저 찾는 도구는 여전히 BeautifulSoup이에요. 실제로 PyPI에서 월 1억 5천만 건 이상 다운로드되고 있고, Stack Overflow에는 3만 2천 개가 넘는 질문이 쌓여 있어서, 막힐 때 도움 받기도 어렵지 않아요.
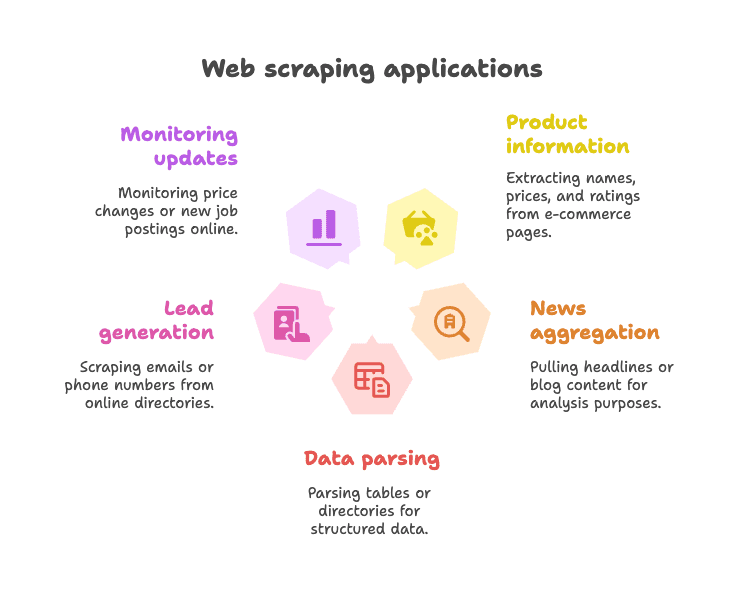
대표적인 활용 장면은요.
- 이커머스 상품 정보 추출 (상품명, 가격, 평점 등)
- 뉴스 헤드라인/블로그 콘텐츠 수집
- 테이블/디렉터리 같은 구조화된 데이터 파싱 (예: 업체 목록)
- 리드 발굴 (디렉터리에서 이메일·전화번호 등 추출)
- 가격 변동, 채용 공고 등 웹사이트 업데이트 모니터링
BeautifulSoup은 특히 정적인 웹페이지(HTML에 데이터가 그대로 노출돼 있는 사이트)에서 진가를 발휘해요. 유연한 데다 HTML이 좀 엉망이어도 잘 동작하고, 무거운 프레임워크에 얽매이지도 않아서 초보자도 부담 없이 들어올 수 있거든요. 그래서 2025년인 지금도 많은 파이썬 웹 스크래퍼들의 '첫사랑'으로 불리고 있어요. (인기 이유 더 알아보기)
pip으로 BeautifulSoup 설치하기: 가장 쉬운 시작법
pip이란? 왜 써야 할까?
파이썬을 처음 접한다면, pip은 PyPI(Python Package Index)에서 라이브러리를 받아 설치해 주는 패키지 매니저예요. 쉽게 말하면 파이썬용 앱스토어 같은 존재죠. pip으로 BeautifulSoup을 설치하는 게 가장 빠르고 확실한 방법이에요.
꿀팁: 패키지 이름은 꼭 beautifulsoup4로 적어야 최신 버전이 설치돼요. (beautifulsoup만 쓰면 옛날 패키지가 깔리니 주의!)
단계별 설치 방법
1. 파이썬 버전 확인
BeautifulSoup은 파이썬 3.7 이상에서 동작해요. 터미널에서 아래 명령어로 버전부터 확인해 보세요.
python --version
또는
python3 --version
2. pip으로 BeautifulSoup4 설치
터미널(명령 프롬프트)에서 아래 명령어를 입력해 주세요.
pip install beautifulsoup4
파이썬 버전이 여러 개 깔려 있다면 이 형태가 필요할 수도 있어요.
pip3 install beautifulsoup4
윈도우에서는 다음 명령어도 잘 통해요.
py -m pip install beautifulsoup4
3. (선택) 파서 추가 설치
BeautifulSoup은 기본적으로 파이썬 내장 "html.parser"를 쓰지만, 더 빠르고 정확한 파싱이 필요하면 lxml과 html5lib을 함께 깔아 두는 게 좋아요.
pip install lxml html5lib
4. (선택) Requests 라이브러리 설치
BeautifulSoup은 HTML 파싱만 담당하니까, 웹페이지를 직접 다운로드하려면 Requests 라이브러리가 따로 필요해요.
pip install requests
5. 설치 확인
파이썬에서 아래 코드를 한번 돌려 보세요.
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
<title>Example Domain</title>가 출력되면 설치가 잘 끝난 거예요.
가상환경에서 BeautifulSoup 설치하기
파이썬 프로젝트에서는 가상환경을 쓰는 걸 추천해요. 프로젝트별로 라이브러리를 따로 관리할 수 있어서 충돌도 줄여 주거든요.
설정 방법은 이래요.
python -m venv venv
# 윈도우:
venv\Scripts\activate
# macOS/Linux:
source venv/bin/activate
pip install beautifulsoup4 requests lxml html5lib
이제 설치한 라이브러리는 이 프로젝트 폴더 안에서만 적용돼요. 패키지가 꼬일 걱정도 한결 줄어요.
기타 설치 방법(Conda 등)
Anaconda를 쓰고 있다면 아래 명령어로 설치할 수 있어요.
conda install beautifulsoup4
파서까지 같이 깔고 싶다면요.
conda install lxml
설치 전에 conda 환경이 잘 활성화돼 있는지 꼭 한번 확인해 주세요.
BeautifulSoup 파이썬: 실전 코드 예제
이제 BeautifulSoup을 실제로 어떻게 쓰는지 함께 보고 갈게요.
예제 1: 웹페이지 가져와서 제목 추출하기
from bs4 import BeautifulSoup
import requests
url = "https://en.wikipedia.org/wiki/Python_(programming_language)"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# 페이지 제목 추출
title_text = soup.title.string
print("Page title:", title_text)
위 코드를 돌리면 위키피디아 파이썬 페이지의 제목이 출력돼요.
예제 2: 모든 하이퍼링크 추출
links = soup.find_all('a')
for link in links[:10]: # 처음 10개만 출력
href = link.get('href')
text = link.get_text()
print(f"{text}: {href}")
페이지 안의 첫 10개 링크 텍스트와 URL을 보여 줘요.
예제 3: 헤드라인 추출
headings = soup.find_all('h2')
for h in headings:
print(h.get_text().strip())
페이지의 모든 <h2> 헤드라인을 한 번에 뽑아내요.
예제 4: CSS 선택자 사용
items = soup.select("ul.menu > li")
for item in items:
print(item.get_text())
select() 메서드를 쓰면 CSS 선택자도 그대로 활용할 수 있어요.
예제 5: 속성 및 중첩 태그 추출
first_link = soup.find('a')
print(first_link['href']) # 직접 접근(없으면 에러)
print(first_link.get('href')) # 안전하게 접근(없으면 None)
예제 6: 전체 텍스트 추출
text_content = soup.get_text()
print(text_content)
페이지 전체 텍스트를 한 번에 뽑고 싶을 때 딱 좋아요.
초보자를 위한 BeautifulSoup 주요 활용법
-
단일 요소 찾기:
soup.find('div', class_='price') -
여러 요소 찾기:
soup.find_all('p', class_='description') -
텍스트 추출:
element.get_text() -
속성값 추출:
element.get('href') -
CSS 선택자 사용:
soup.select('table.data > tr') -
요소가 없을 때 처리:
price = soup.find('span', class_='price') if price: print(price.get_text())
BeautifulSoup 문법은 직관적이라 초보자도 금세 손에 익어요. (공식 문서 보기)
BeautifulSoup의 한계: 최신 웹 스크래핑에서 주의할 점
이번엔 BeautifulSoup의 단점도 솔직하게 짚어 볼게요. 정적 페이지나 소규모 프로젝트에는 정말 든든한데, 모든 상황에 다 맞는 만능은 아니거든요.
대표적인 한계는 이래요.
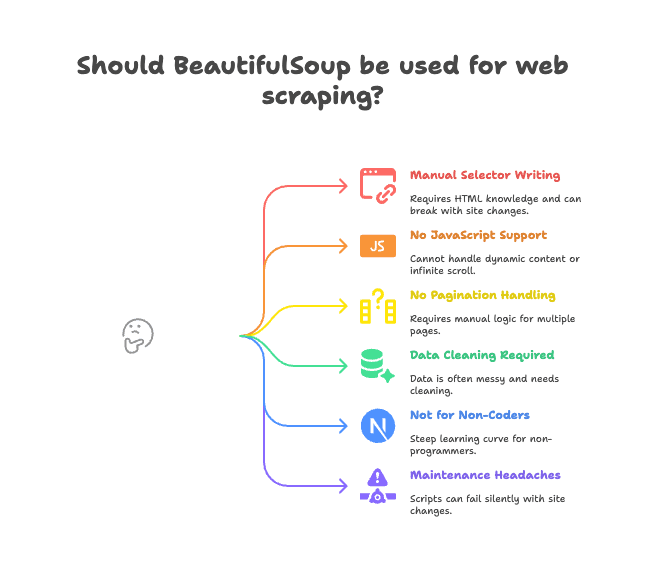
- 셀렉터 직접 작성: HTML 구조를 직접 뜯어보면서 태그·클래스 경로를 지정해야 하고, 사이트 구조가 바뀌면 코드가 깨질 수 있어요.
- 자바스크립트 미지원: BeautifulSoup은 서버에서 받은 HTML만 볼 수 있어요. JS로 동적으로 불러오는 데이터(무한 스크롤, 동적 콘텐츠 등)는 추출이 안 되거든요. (자세히 보기)
- 페이지네이션/서브페이지 자동화 없음: 여러 페이지를 넘기거나 상세 페이지로 들어가려면 매번 직접 코드를 짜야 해요.
- 데이터 정제 필요: 추출한 데이터에 불필요한 공백, 특수문자, 포맷 불일치 같은 잔재가 많아서 추가 정제가 거의 필수예요.
- 비개발자에겐 진입장벽: 코딩 경험이 없는 영업·마케팅·운영 담당자에겐 입구부터 부담이 커요.
- 유지보수 어려움: 사이트 구조가 바뀌면 코드가 조용히 실패하거나, 데이터가 누락되는 일이 자주 생겨요.
이런 '작은' 불편들이 모이면 실제 업무에서는 꽤 큰 비효율로 돌아오기도 해요. 실제로 스크래핑 코드 유지보수에 지쳐서 프로젝트 자체가 흐지부지되는 경우도 적지 않거든요.
Thunderbit로 웹 데이터 추출을 바꾸는 이유
Thunderbit AI 웹 스크래퍼 체험하기 AI로 어떤 웹사이트든 쉽게 추출하세요. 코딩 필요 없음. Get Started Free
그럼 대안은 뭐냐고요? 바로 Thunderbit이에요. Thunderbit은 단순한 파이썬 라이브러리가 아니라, AI가 내장된 크롬 확장 프로그램이라서 웹 데이터 추출 방식 자체를 바꿔 줘요.
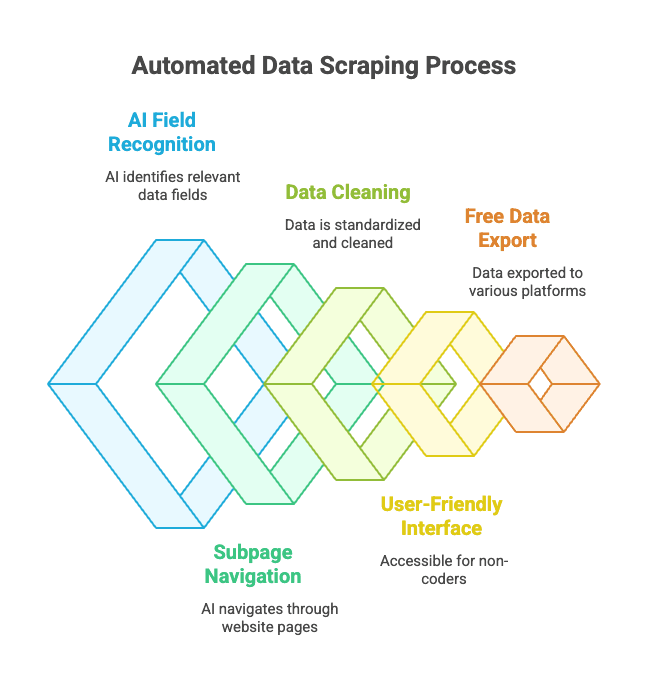
사용 흐름도 정말 단순해요.
- 원하는 웹사이트를 열고요,
- 'AI 필드 추천'을 누르면 Thunderbit AI가 페이지를 분석해서 '상품명', '가격', '위치' 같은 컬럼을 알아서 제안해 줘요.
- 필요하면 컬럼명이나 타입을 손으로 다듬을 수 있고요.
- '스크래핑' 버튼만 누르면 Thunderbit이 데이터를 추출해서 자동으로 정리해 줘요.
- 엑셀, 구글 시트, Notion, Airtable 등 원하는 곳으로 한 번에 내보낼 수 있어요.
코드도, 셀렉터도, 유지보수도 따로 신경 쓸 일이 없어요.
Thunderbit의 주요 강점이에요.
- AI 기반 필드 인식: HTML이 아무리 복잡해도 AI가 원하는 데이터를 알아서 짚어 줘요.
- 서브페이지/페이지네이션 지원: 상품 상세 페이지 클릭, '다음 페이지' 자동 이동 같은 흐름도 그대로 처리해요.
- 데이터 정제 및 포맷팅: 전화번호, 이메일, 이미지 같은 항목도 깔끔하게 정리돼요.
- 비개발자도 사용 가능: 브라우저만 다룰 줄 알면 누구나 쓸 수 있어요.
- 무료 데이터 내보내기: 엑셀, 구글 시트, Airtable, Notion 등으로 무료로 내보낼 수 있어요.
- 예약 스크래핑: 원하는 시간대에 자동으로 데이터를 추출해 두는 것도 가능해요.
비즈니스 사용자라면 이제 복잡한 파이썬 코드를 쓰지 않고도, 클릭 몇 번이면 원하는 데이터를 손에 쥘 수 있어요.
Thunderbit vs. BeautifulSoup: 어떤 도구가 나에게 맞을까?
두 도구를 비교해 보면 이렇게 차이가 나요.
| 기능 | BeautifulSoup (파이썬 코딩) | Thunderbit (노코드 AI) |
|---|---|---|
| 설치 | 파이썬, pip, 코드 필요 | 크롬 확장, 2번 클릭으로 설치 |
| 데이터 추출 속도 | 첫 스크립트까지 수 시간 | 사이트당 몇 분이면 완료 |
| 자바스크립트 지원 | 불가(추가 도구 필요) | 가능(브라우저에서 실행) |
| 페이지네이션/서브페이지 | 직접 코드 작성 | 내장, 옵션으로 지원 |
| 데이터 정제 | 직접 코드 작성 | AI가 자동 정리 |
| 내보내기 옵션 | CSV/엑셀 직접 구현 | 구글 시트, Notion 등 원클릭 |
| 추천 대상 | 개발자, 취미로 코딩하는 분 | 비즈니스 사용자, 비개발자 |
| 비용 | 무료(시간 소요) | 프리미엄(소규모 무료) |
BeautifulSoup이 잘 어울리는 상황은요.
- 파이썬에 익숙하고, 세밀한 제어가 필요할 때
- 정적 사이트나 커스텀 로직이 들어가야 할 때
- 파이썬 워크플로우 안에 스크래핑을 그대로 녹이고 싶을 때
Thunderbit이 잘 어울리는 상황은요.
- 결과가 빨리 필요한데 코딩이 부담스러울 때
- 동적(자바스크립트 기반) 사이트를 다뤄야 할 때
- 영업·마케팅·운영 같은 비개발자라서 추출한 데이터를 곧장 비즈니스 도구로 보내야 할 때
저도 개발자지만, 가볍게 데이터만 뽑고 싶을 땐 Thunderbit을 자주 써요. 브라우저에서 바로 데이터가 나오니까 손이 정말 편하거든요.
BeautifulSoup 설치 및 활용 꿀팁
BeautifulSoup을 계속 쓸 거라면 아래 팁을 챙겨 두면 좋아요.
- 가상환경 사용: 프로젝트별로 라이브러리를 따로 관리해서 충돌을 막아 주세요.
- pip 및 패키지 최신화:
pip install --upgrade pip와pip list --outdated로 가끔씩 정리해 주면 좋아요. - 추천 파서 설치:
pip install lxml html5lib로 성능과 안정성을 같이 챙기세요. - 코드 분리: 데이터 다운로드 로직과 파싱 로직을 분리해 두면 디버깅이 한결 수월해져요.
- robots.txt와 요청 간격 준수: 사이트에 과한 요청이 가지 않게
time.sleep()을 살짝 끼워 주세요. - 안정적인 셀렉터 사용: 너무 구체적인 경로는 피하고, 변경에 강한 셀렉터를 골라 쓰세요.
- HTML 저장 후 테스트: 페이지를 저장해 두고 오프라인에서 파싱 테스트를 해 보면 디버깅이 빨라져요.
- 커뮤니티 활용: Stack Overflow에서 비슷한 사례와 해결법을 잔뜩 찾을 수 있어요.
BeautifulSoup 설치 오류 해결법
설치하다 막혔다면 아래 체크리스트를 한번 훑어 보세요.
- "ModuleNotFoundError: No module named bs4"
- 올바른 환경에 beautifulsoup4를 깔았는지 확인해 보세요.
python -m pip install beautifulsoup4로 다시 설치하면 보통 해결돼요.
- 올바른 환경에 beautifulsoup4를 깔았는지 확인해 보세요.
- 잘못된 패키지 설치(beautifulsoup → beautifulsoup4)
- 기존 패키지 제거:
pip uninstall beautifulsoup - 올바른 패키지 설치:
pip install beautifulsoup4
- 기존 패키지 제거:
- 파서 경고/유니코드 오류
lxml,html5lib을 깐 뒤 파서를 명시:BeautifulSoup(html, "lxml")
- 요소를 못 찾는 경우
- 데이터가 자바스크립트로 로드되는 건 아닌지 점검해 보세요. BeautifulSoup은 렌더링된 DOM이 아니라 원본 HTML만 본답니다.
- pip 오류/권한 문제
- 가상환경을 쓰거나
pip install --user beautifulsoup4를 시도해 보세요. - pip 업그레이드:
pip install --upgrade pip
- 가상환경을 쓰거나
- Conda 관련 문제
conda install beautifulsoup4를 쓰거나, conda 환경 안에서 pip을 사용해 보세요.
그래도 풀리지 않는다면, BeautifulSoup 공식 문서와 Stack Overflow에서 거의 모든 상황의 해법을 찾을 수 있어요.
결론: BeautifulSoup 설치와 활용의 핵심 요약
-
BeautifulSoup은 파이썬 웹 스크래핑의 대표 라이브러리예요. 쉽고 유연해서 초보자에게 잘 맞아요.
-
pip으로 설치하면 끝이에요.
pip install beautifulsoup4 lxml html5lib requests -
가상환경을 써서 프로젝트별 환경을 깔끔하게 유지해 주세요.
-
정적 페이지, 소규모 프로젝트에 특히 강점이 있지만, 자바스크립트·페이지네이션·유지보수에는 한계가 있어요.
-
Thunderbit은 비개발자와 비즈니스 사용자를 위한 최신 AI 기반 대안이에요. 코드 없이, 복잡한 설정 없이 원하는 데이터를 바로 얻을 수 있어요.
-
상황에 맞게 도구를 골라 보세요.
- 개발자거나 코딩에 익숙하다면 BeautifulSoup이 자유도를 잘 살려 줘요.
- 비즈니스 사용자나 팀이라면 Thunderbit이 결과를 빠르게 안겨 줘요.
가능하면 두 가지를 다 한 번씩 써 보세요. 결국, 가장 효율적으로 결과가 나오는 쪽이 자신에게 맞는 도구거든요.
Thunderbit AI 웹 스크래퍼 무료 체험하기 Get Started Free
자주 묻는 질문: pip으로 BeautifulSoup 설치 및 활용
Q: beautifulsoup와 beautifulsoup4의 차이는 무엇인가요?
A: 항상 beautifulsoup4를 설치하세요. 최신 버전이며, 파이썬 3과 호환돼요. 예전 패키지(beautifulsoup)는 더 이상 지원되지 않습니다. 사용 시에는 from bs4 import BeautifulSoup로 불러와요. (자세히 보기)
Q: BeautifulSoup과 함께 lxml이나 html5lib도 꼭 설치해야 하나요?
A: 필수는 아니지만, 설치하면 파싱 속도와 안정성이 크게 향상돼요. pip install lxml html5lib로 설치하세요. (이유 자세히 보기)
Q: BeautifulSoup으로 자바스크립트 기반 사이트도 추출할 수 있나요?
A: 불가능해요. BeautifulSoup은 정적 HTML만 볼 수 있어요. 자바스크립트로 로드되는 데이터는 Selenium 같은 브라우저 자동화 도구나, Thunderbit 같은 AI 기반 브라우저 도구를 사용하세요. (자세히 보기)
Q: BeautifulSoup을 삭제하려면 어떻게 하나요?
A: 터미널에서 pip uninstall beautifulsoup4를 실행하세요. (단계별 안내)
Q: Thunderbit은 무료인가요?
A: Thunderbit은 소규모 작업은 무료, 대량 추출이나 고급 기능은 유료 플랜이 있어요. 브라우저에서 바로 무료로 체험할 수 있어요. (요금제 자세히 보기)
BeautifulSoup과 Thunderbit의 실제 비교가 궁금하다면 심층 비교글을 참고해 보세요. 웹 스크래핑을 더 깊이 파고 싶다면 데이터 스크래핑이란?, 아마존 상품 및 리뷰 스크래핑 방법 가이드도 함께 추천드려요.
즐거운 스크래핑 되세요. 파이썬 전문가든, 그저 데이터를 스프레드시트로 옮기고 싶은 분이든, 옆에서 도와줄 도구와 커뮤니티는 늘 준비돼 있어요.




