
Apollo 리스트 쿼리를 최적화하는 건 단순히 “기술적으로 멋지게” 만드는 일이 아닙니다. 실시간 뉴스 데이터, 자동 뉴스 추출, 혹은 숨 돌릴 틈 없이 돌아가는 영업·운영 워크플로우에 기대어 일하는 사람들에겐 거의 ‘생존 스킬’에 가깝죠. 느린 리스트 쿼리 하나가 잘 만들어둔 대시보드를 그대로 병목으로 바꿔버리는 장면을 저는 정말 여러 번 봤습니다. 영업팀은 로딩 스피너만 멍하니 바라보고, 운영팀은 결국 스프레드시트로 우회로를 찾느라 정신이 없어요. 는 현실에서, 몇 밀리초도 대충 넘길 수 없습니다.

그럼 뉴스 스크래핑, 리드 추적, 핵심 대시보드 운영처럼 “진짜 중요한” 상황에서 Apollo Client 리스트 쿼리를 어떻게 더 빠르고, 더 안정적이고, 더 확장 가능하게 만들 수 있을까요? 이 가이드에서는 제가 직접 부딪히며(가끔은 시행착오로) 정리한 베스트 프랙티스를, 쿼리 설계부터 캐싱, 페이지네이션, 그리고 같은 노코드 도구로 뉴스 추출 반복 작업을 자동화하는 방법까지 차근차근 풀어볼게요. 개발자든, PM이든, “대시보드가 왜 이렇게 느려요?”라는 질문을 떠안는 사람이든, 이 글은 Apollo GraphQL 리스트 성능을 끌어올리는 실전 플레이북이 되어줄 겁니다.
왜 Apollo 리스트 쿼리를 최적화해야 할까요? (apollo client list performance, optimize apollo list queries)
현실적으로, 누구도 뉴스 헤드라인이나 영업 리드가 뜨는 걸 하염없이 기다리고 싶진 않죠. 특히 처럼 실시간 데이터에 기대는 업무 환경에서는, 느린 Apollo 리스트 쿼리가 단순히 ‘불편한 정도’를 넘어 비용을 만들고 의사결정을 늦추고, 사람들을 다시 수작업으로 되돌려 놓습니다. 에 따르면 사무직 근로자는 하루의 약 3분의 1을 저부가가치 업무에 쓰는데, 느리거나 끊기는 도구가 그 원인인 경우가 많다고 해요.
리스트 쿼리가 최적화되지 않으면 이런 일이 벌어집니다:
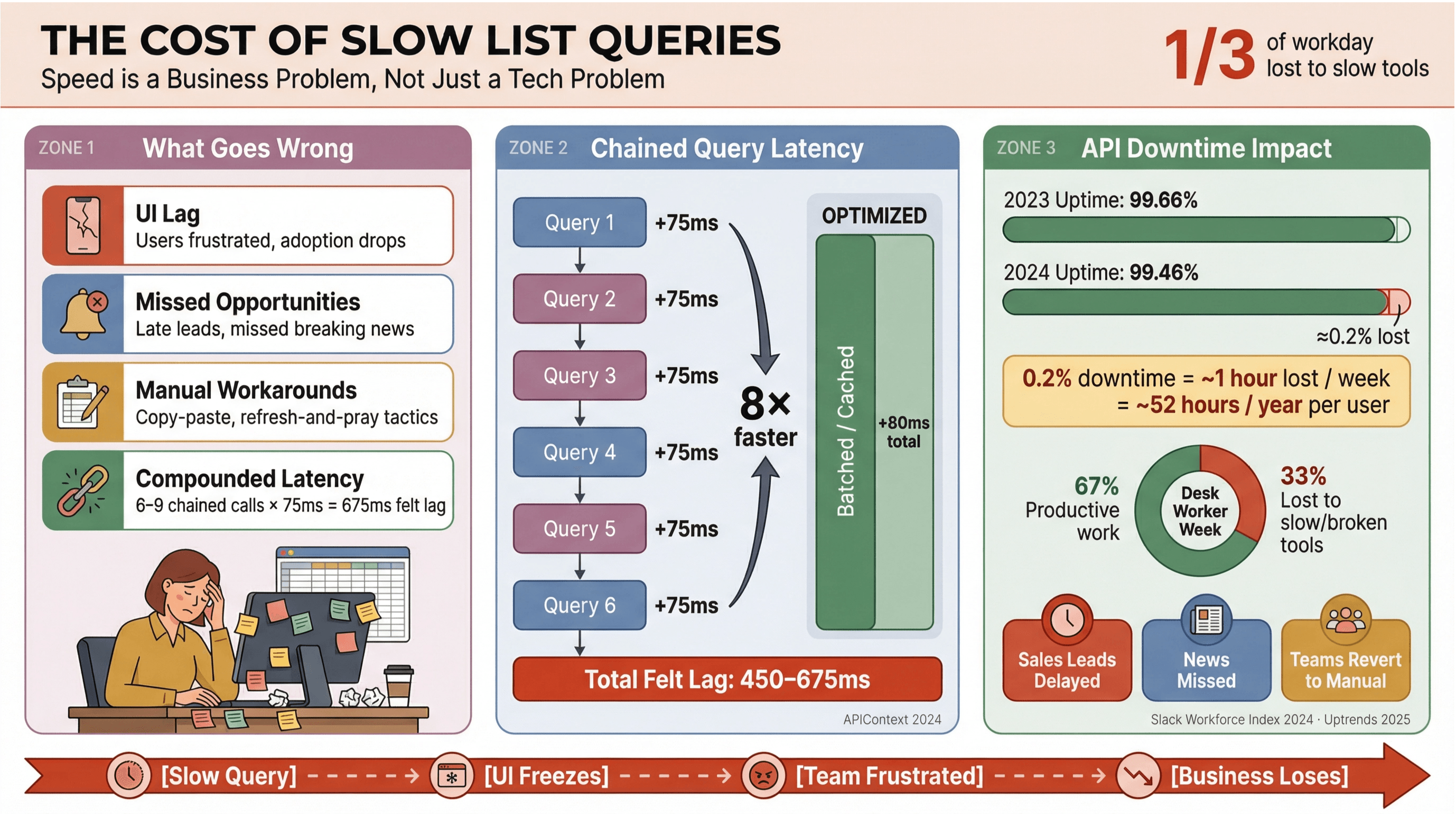
- UI 지연: 화면 반응이 굼떠져 사용자가 답답해하고, 결국 도구 채택률도 떨어집니다.
- 기회 손실: 영업이나 뉴스 모니터링은 몇 초 차이로 ‘뜨거운 리드’나 속보를 놓칠 수 있어요.
- 수작업 우회: 팀이 다시 복사-붙여넣기, 스프레드시트, “새로고침하고 기도하기” 같은 방식으로 회귀합니다.
- 지연의 누적: 느린 API 호출이 계속 쌓입니다. 워크플로우가 6~9개의 의존 쿼리를 연쇄로 실행한다면, 호출당 75ms의 작은 지연도 체감상 450~675ms까지 커질 수 있습니다().
이건 단순히 속도만의 문제가 아닙니다. 이고, 평균 가동률이 1년 사이 99.66%에서 99.46%로 떨어졌습니다. 리스트 중심 앱이라면 주당 거의 1시간 가까운 생산성 손실로 이어질 수도 있죠. 실시간 뉴스 데이터가 비즈니스의 핵심이라면, 이런 리스크는 솔직히 감당하기 어렵습니다.
올바른 데이터 구조와 필드 선택 (apollo graphql list best practices)
제가 가장 자주 보는 실수(저도 예전에 똑같이 했습니다)는, 모든 리스트 쿼리를 상세(디테일) 쿼리처럼 다루는 거예요. GraphQL의 강점은 ‘필요한 것만 정확히’ 가져오는 데 있으니, 그 장점을 제대로 써Apollo 리스트 쿼리를 최적화하는 건 단순히 “기술적으로 멋지게” 만드는 일이 아닙니다. 실시간 뉴스 데이터, 자동 뉴스 추출, 혹은 숨 돌릴 틈 없이 돌아가는 영업·운영 워크플로우에 기대서 일하는 사람들에겐 거의 ‘생존 스킬’에 가깝죠. 느린 리스트 쿼리 하나가 잘 굴러가던 대시보드를 병목으로 바꿔버리는 장면을 저는 정말 여러 번 봤습니다. 영업팀은 로딩 스피너만 멍하니 바라보고, 운영팀은 결국 스프레드시트로 우회로를 찾느라 정신이 없어요. 는 현실에서, 몇 밀리초도 그냥 넘길 수 없습니다.
그럼 뉴스 스크래핑, 리드 추적, 핵심 대시보드 운영처럼 “진짜 중요한” 상황에서 Apollo Client 리스트 쿼리를 어떻게 더 빠르고, 더 안정적이고, 더 확장 가능하게 만들 수 있을까요? 이 가이드에서는 제가 직접 부딪히며(가끔은 시행착오로) 정리한 베스트 프랙티스를, 쿼리 설계부터 캐싱, 페이지네이션, 그리고 같은 노코드 도구로 뉴스 추출 반복 작업을 자동화하는 방법까지 단계별로 풀어볼게요. 개발자든, PM이든, “대시보드가 왜 이렇게 느려요?”라는 질문을 떠안는 사람이든, 이 글은 Apollo GraphQL 리스트 성능을 끌어올리는 실전 플레이북이 될 겁니다.
왜 Apollo 리스트 쿼리를 최적화해야 할까요? (apollo client list performance, optimize apollo list queries)
현실적으로, 누구도 뉴스 헤드라인이나 영업 리드가 뜨길 하염없이 기다리고 싶지 않죠. 특히 처럼 실시간 데이터에 기대는 업무 환경에서는, 느린 Apollo 리스트 쿼리가 단순히 ‘불편’한 수준을 넘어 비용을 만들고 의사결정을 늦추고, 사람들을 다시 수작업으로 되돌려 놓습니다. 에 따르면 사무직 근로자는 하루의 약 3분의 1을 저부가가치 업무에 쓰는데, 느리거나 끊기는 도구가 그 원인인 경우가 많다고 해요.
리스트 쿼리가 최적화되지 않으면 이런 일이 벌어집니다:
- UI 지연: 화면 반응이 굼떠져 사용자가 답답해하고, 도구 채택률도 떨어집니다.
- 기회 손실: 영업이나 뉴스 모니터링은 몇 초 차이로 ‘뜨거운 리드’나 속보를 놓칠 수 있어요.
- 수작업 우회: 팀이 다시 복사-붙여넣기, 스프레드시트, “새로고침하고 기도하기” 같은 방식으로 회귀합니다.
- 지연의 누적: 느린 API 호출이 계속 쌓입니다. 워크플로우가 6~9개의 의존 쿼리를 연쇄로 실행한다면, 호출당 75ms의 작은 지연도 체감상 450~675ms까지 불어날 수 있습니다().
이건 단순히 “빠르냐 느리냐”의 문제가 아닙니다. 이고, 평균 가동률이 1년 사이 99.66%에서 99.46%로 내려갔습니다. 리스트 중심 앱에서는 주당 거의 1시간 가까운 생산성 손실로 이어질 수 있죠. 실시간 뉴스 데이터가 비즈니스의 핵심이라면, 이런 리스크는 솔직히 감당하기 어렵습니다.
올바른 데이터 구조와 필드 선택 (apollo graphql list best practices)
제가 가장 자주 보는 실수(저도 예전에 똑같이 했습니다)는, 모든 리스트 쿼리를 상세(디테일) 쿼리처럼 다루는 거예요. GraphQL의 장점은 ‘필요한 것만 정확히’ 가져오는 데 있으니, 그 강점을 제대로 써야 합니다. 특히 뉴스 스크래핑 도구나 실시간 대시보드에서는 과도한 데이터 요청(Overfetching)이 성능을 갉아먹는 주범입니다.
자동 뉴스 추출에 맞춘 필드 설계
예를 들어 뉴스 피드를 만든다고 해볼게요. 리스트 쿼리에서 기사 본문 전체, 모든 태그, 댓글, 기자 소개까지 정말 다 필요할까요? 대부분은 아니죠. 아래처럼 차이가 확 납니다.
효율적인 리스트 쿼리:
1query NewsFeed($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 cursor
5 node {
6 id
7 title
8 url
9 sourceName
10 publishedAt
11 }
12 }
13 pageInfo { endCursor hasNextPage }
14 }
15}비효율적인 리스트 쿼리(이렇게 하지 마세요):
1query NewsFeedTooHeavy($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 node {
5 id title url publishedAt
6 fullText
7 summary
8 entities { ... }
9 relatedArticles { ... }
10 }
11 }
12 }
13}첫 번째 쿼리는 가볍고 핵심만 담아서 정렬·필터·행 렌더링에 딱 맞습니다. 반면 두 번째는 사실상 상세 쿼리를 리스트로 위장한 형태라 페이로드가 커지고, 결국 전체가 느려집니다(, ).
팁: 2단 구성으로 설계하세요. 리스트에서는 가벼운 필드만 가져오고, 본문/이미지/NLP 보강 같은 무거운 데이터는 사용자가 항목을 열거나(또는 hover) “필요해지는 순간”에만 상세 쿼리로 불러오면 됩니다.
Apollo Client 캐시로 리스트를 더 빠르게 (apollo client list performance)
Apollo Client의 캐시는 리스트 쿼리를 ‘즉시 반응’하게 만드는 핵심 무기입니다. 설정만 잘 잡아두면:
- 반복 쿼리를 즉시 응답(네트워크 왕복 없이)
- 서버 부하 및 API 비용 절감
- 뒤로/앞으로 이동, 필터 변경 시 부드러운 UX
다만 캐시는 알아서 만능으로 해결해주진 않아요. 약간의 설정과 규칙이 필요합니다.
효과적인 캐시 정책 설정
Apollo는 여러 를 지원합니다:
| Policy | 동작 방식 | 뉴스 리스트에 적합한 사용 시나리오 |
|---|---|---|
| cache-first | 캐시에서 읽고, 없으면 네트워크에서 가져옴 | 리스트 재방문, 필터 전환, 뒤로/앞으로 내비게이션 |
| network-only | 항상 네트워크에서 가져옴 | 수동 새로고침, “최신 헤드라인” |
| cache-and-network | 캐시를 먼저 보여주고, 네트워크 응답으로 백그라운드 업데이트 | 빠른 첫 화면 + 백그라운드 갱신(뉴스 피드에 특히 유용) |
| no-cache | 항상 네트워크에서 가져오며 캐시에 저장하지 않음 | 민감한 1회성 쿼리(리스트에서는 드묾) |
실시간 뉴스 데이터에는 cache-and-network를 추천합니다. 사용자는 일단 바로 결과를 보고, 뒤에서 최신 데이터로 자연스럽게 갱신되니까요. 다만 새로고침 시 정렬 순서가 바뀌면 UI가 깜빡이는 문제가 생길 수 있으니 이 부분은 조심해야 합니다().
캐시 설정 팁:
- 정규화(normalization)를 위해 안정적인 ID(
id또는_id)를 쓰세요(). - 대형 리스트에 맞춰 캐시 크기와 GC를 조정하세요().
ROOT_QUERY아래에 정규화되지 않은 거대한 덩어리를 저장하는 패턴은 피하세요. 앱이 순간 멈칫할 수 있습니다().
페이지네이션 적용과 아이템 수 제한 (apollo graphql list best practices)
뉴스 기사나 영업 리드를 한 번에 수백~수천 개씩 당겨오면, 문제 생기기 딱 좋습니다. 페이지네이션은 UX 옵션이 아니라 성능을 위한 필수 장치예요.
Apollo는 과 페이지네이션을 모두 지원합니다. 차이는 아래처럼 정리할 수 있어요:
| 페이지네이션 방식 | 장점 | 단점 | 적합한 경우 |
|---|---|---|---|
| 오프셋 기반 | 단순하고 구현이 쉬움 | 데이터가 변하면 누락/중복이 생길 수 있음 | 변경이 거의 없거나 작은 리스트 |
| 커서 기반 | 안정적이며 데이터 변경에 강함 | 구현이 약간 더 복잡함 | 뉴스 피드, 대형 리스트 |
대부분의 실시간 뉴스/리드 리스트에는 커서 기반 페이지네이션이 거의 정답에 가깝습니다. 새 항목이 들어오거나 기존 항목이 삭제돼도 일관성을 유지하기가 훨씬 좋거든요().
Apollo 페이지네이션 팁:
- 페이지네이션 필드의 캐시 키를 제어하려면
keyArgs를 설정하세요(). - 캐시에서 페이지를 자연스럽게 합치도록
merge함수를 구현하세요. fetchMore로 기존 결과를 덮어쓰지 말고, 다음 페이지를 “이어 붙이듯” 가져오세요.
뉴스 스크래핑 도구에서 유용한 페이지네이션 패턴
일반적인 뉴스 스크래핑 UI는 보통 이렇게 굴러갑니다:
- 최신 20~50개 헤드라인만 표시(가벼운 필드만)
- 스크롤 또는 “다음” 클릭 시 추가 로드
- 상세 정보는 필요할 때만 요청
이렇게만 해도 UI는 훨씬 경쾌해지고, API는 안정적으로 버티고, 사용자는 더 생산적으로 움직일 수 있어요.
Thunderbit로 자동 뉴스 추출 연동하기
이제 핵심 질문으로 들어가 보죠. 애초에 이런 ‘구조화된 뉴스 데이터’는 어디서 오느냐는 겁니다. 여기서 가 역할을 합니다.
Thunderbit는 코딩 없이 쓸 수 있는 AI 웹 스크래퍼 크롬 확장 프로그램으로, 거의 모든 웹사이트에서 뉴스 헤드라인, URL, 출처, 작성자, 발행일, 요약, 이미지 등을 뽑아낼 수 있습니다. 팀이 Thunderbit로 뉴스 추출을 통째로 자동화해서, 비정형 웹페이지를 깔끔한 구조화 데이터로 바꾸고 이를 DB나 GraphQL API로 바로 흘려보내는 사례도 꽤 많이 봤어요.
Apollo와 Thunderbit를 결합해 실시간 뉴스 데이터 만들기
영업·운영팀이 최신 뉴스를 놓치지 않게 만들 때, 제가 특히 좋아하는 흐름은 이렇습니다:
- 추출 레이어: Thunderbit의 로 대상 사이트에서 구조화된 뉴스 데이터를 스케줄 기반으로 수집
- 저장 레이어: 빠른 조회에 최적화된 DB에 스크래핑 데이터를 저장
- GraphQL 레이어: API에서
newsFeed(리스트)와newsArticle(id)(상세) 필드를 제공 - 클라이언트 레이어: Apollo Client로 리스트는 가볍게·페이지네이션으로 가져오고, 상세는 필요할 때만 요청
이 “스크래핑 → 저장 → 쿼리” 파이프라인을 쓰면, Apollo 쿼리는 항상 최신의 구조화 데이터로 돌아갑니다. 수작업 복붙이나 조금만 환경이 바뀌어도 깨지는 스크립트에 매달릴 필요가 없죠.
추가로: Thunderbit의 AI 기반 필드 제안 기능을 쓰면 감성 분석, 카테고리 같은 추가 컬럼으로 리스트를 보강해서 뉴스 피드를 더 똑똑하게 만들 수도 있습니다.
단계별 가이드: Apollo 리스트 쿼리 최적화
이제 진짜로 적용해볼 차례입니다. 제가 자주 쓰는 Apollo 리스트 쿼리 최적화 체크리스트는 아래와 같아요:
-
쿼리를 가볍게 만들기
- 리스트 렌더링에 필요한 필드만 요청(제목, URL, 타임스탬프 등)
- 본문, 이미지, 보강 데이터 같은 무거운 필드는 상세 쿼리로 분리
-
페이지네이션 적용
- 크거나 자주 변하는 리스트에는 커서 기반 페이지네이션 사용
- 캐시 정합성을 위해
keyArgs와merge함수 설정
-
Apollo 캐시 활용
- 안정적인 ID로 엔티티 정규화
- 적절한 fetch policy 선택(뉴스에는
cache-and-network가 유용) - 데이터 규모에 맞춰 캐시 크기와 GC 튜닝
-
자동 추출 연동
- Thunderbit로 뉴스 스크래핑을 자동화해 데이터 최신 상태 유지
- 구조화 데이터를 DB나 스프레드시트로 바로 내보내기
-
모니터링 및 문제 해결
- 로 쿼리/캐시/성능을 점검
- 큰 캐시 쓰기, 과도한 watched query, UI 끊김 여부 확인
- p95/p99 지연과 에러율을 추적(, )
쿼리 성능 모니터링과 트러블슈팅
이럴 때 Apollo Devtools가 진짜 든든합니다. 이런 걸 바로 확인할 수 있거든요:
- 활성 쿼리와 캐시 상태 확인
- 중복 쿼리 또는 과도한 watcher 탐지
- 큰 캐시 블롭 또는 정규화 문제 파악
UI 지연이나 업데이트가 느리다면 아래를 체크해보세요:
- 리스트 쿼리가 너무 무거운지(필드 줄이기)
- 캐시 정규화가 제대로인지(ID 수정)
- 페이지네이션 merge가 꼬였는지(
keyArgs/merge감사)
그리고 평균만 보지 말고, 꼬리 지연(tail latency)도 꼭 측정하세요. 실제 사용자 고통은 보통 그 구간에 숨어 있습니다.
전통적 방식 vs AI 기반 뉴스 스크래핑 비교
솔직히 예전 뉴스 스크래핑은 커스텀 스크립트 짜고, 헤드리스 브라우저 만지고, 사이트 레이아웃이 밤새 안 바뀌길 비는 일이었죠. 그런데 이제는 Thunderbit 같은 AI 기반 도구를 쓰면, 코딩 없이도 전체 과정을 자동화할 수 있습니다.
| 접근 방식 | 강점 | 비즈니스 사용자 관점의 한계 |
|---|---|---|
| 스크립트 기반 스크래핑 | 완전한 커스터마이징, 대규모에서 비용 효율적 | 유지보수 부담 큼, 엔지니어링 리소스 필요 |
| 매니지드 스크래핑 플랫폼 | 빠르게 시작 가능, 안티봇 대응을 위임 | 여전히 설정 필요, 사용량에 따라 비용 증가 |
| AI 기반 추출(Thunderbit) | 복잡한 레이아웃도 대응, 노코드 | 결과 QA 필요, 스키마 연동 작업 필요 |
| 노코드 비주얼 스크래퍼 | 비개발자도 접근 쉬움 | UI 변경에 취약, 확장성 제한 |
| 프록시/언락커 인프라 | 차단 우회, 고처리량 지원 | 추출 로직은 별도 필요, 컴플라이언스 리스크 |
법적 참고: 공개 데이터 스크래핑은 일반적으로 합법인 경우가 많지만, 서비스 약관과 레이트 리밋은 반드시 지켜야 합니다().
Apollo GraphQL 리스트 베스트 프랙티스 핵심 정리
핵심만 다시 묶어보면:
- 속도와 명확성에 집중: 리스트 쿼리는 가볍게, 페이지네이션 적용, 캐시는 적극 활용
- 구조가 성능을 좌우: 필요한 것만 가져오고, 무거운 필드는 상세 쿼리로 분리
- 캐시는 든든한 아군: Apollo 정규화와 fetch policy로 즉시 응답을 만들기
- 추출 자동화: 같은 도구로 뉴스 스크래핑과 리스트 보강을 누구나 쉽게
- 모니터링 후 반복 개선: Devtools와 관측(Observability) 대시보드로 병목을 조기에 발견
영업·운영·뉴스 팀에게 이 베스트 프랙티스는 ‘기다리는 시간’을 줄이고 ‘행동하는 시간’을 늘려주며, “왜 이렇게 느려요?”라는 Slack 메시지도 확실히 줄여줍니다.
결론: Apollo 리스트 쿼리 최적화를 위한 다음 단계
아직도 무겁고, 페이지네이션이 없고, 캐시에 친화적이지 않은 리스트 쿼리를 쓰고 있다면 지금이 딱 점검하고 손볼 타이밍입니다. 큰 거부터가 아니라 작은 것부터 시작해도 좋아요. 필드를 줄이고, 페이지네이션을 붙이고, 캐시를 튜닝해보세요. 그다음 같은 자동 추출 도구까지 연동해서 데이터를 늘 최신·실행 가능한 상태로 유지하면, 한 단계 더 올라갈 수 있습니다.
더 깊게 파고 싶다면 , , 또는 실전 팁과 문제 해결 사례가 많은 를 참고해보세요. 그리고 자동 뉴스 추출을 바로 시작하고 싶다면 Thunderbit의 을 써보는 것도 추천합니다. 실시간 데이터는 필요하지만 번거로운 건 딱 질색인 분들에겐, 확실히 판을 바꿔줄 도구예요.
즐거운 쿼리 생활 되시길—그리고 커피가 식기 전에 리스트가 먼저 뜨길 바랍니다.
FAQs
1. 실시간 뉴스/영업 대시보드에서 Apollo 리스트 쿼리가 느려지는 이유는 무엇인가요?
리스트 쿼리가 과도한 데이터를 가져오거나, 페이지네이션이 없거나, 캐시 설정이 제대로 되어 있지 않으면 느려질 수 있습니다. 뉴스 모니터링처럼 호출 빈도가 높은 업무에서는 작은 지연도 누적되어 UI 지연과 생산성 저하로 이어집니다.
2. 자동 뉴스 추출에 적합한 Apollo 리스트 쿼리 구조는 어떻게 잡는 게 좋나요?
리스트 렌더링에 필요한 필드(예: 제목, URL, 타임스탬프)만 요청하세요. 기사 본문이나 이미지처럼 무거운 필드는 상세 쿼리로 분리하고, 결과는 페이지네이션으로 나눠 페이로드를 작게 유지하는 것이 좋습니다.
3. Apollo Client 캐시는 리스트 성능을 어떻게 개선하나요?
Apollo 캐시는 이전에 가져온 데이터를 저장해, 같은 쿼리를 다시 실행할 때 즉시 응답할 수 있게 해줍니다. 정규화와 fetch policy(예: cache-and-network)를 올바르게 설정하면 리스트 화면이 훨씬 빨라지고 서버 부하도 줄어듭니다.
4. Thunderbit는 뉴스 스크래핑과 Apollo 연동에 어떤 도움을 주나요?
Thunderbit는 코딩 없이 어떤 웹사이트에서든 구조화된 뉴스 데이터를 추출할 수 있는 AI 웹 스크래퍼입니다. 이를 통해 뉴스 추출을 자동화하고, 추출한 데이터를 DB나 GraphQL API로 흘려보내 Apollo Client에서 바로 활용할 수 있습니다.
5. Apollo 리스트 쿼리 성능을 모니터링하고 문제를 해결하려면 어떤 도구를 쓰면 좋나요?
로 쿼리, 캐시 상태, 성능을 실시간으로 점검할 수 있습니다. 여기에 New Relic이나 Uptrends 같은 관측 대시보드를 함께 사용하면 지연과 에러율을 추적하며 쿼리 설계를 지속적으로 개선할 수 있습니다.
웹 스크래핑, 자동화, 실시간 데이터 워크플로우에 대한 더 많은 팁이 필요하다면 에서 심층 가이드와 튜토리얼, AI 기반 생산성 최신 소식을 확인해보세요.
더 알아보기