웹 데이터를 필요로 하는 사람들이 점점 늘어나면서, 2025년에는 가 효율적인 웹 스크래핑을 원하는 팀들에게 필수 도구로 자리 잡고 있어요. 영업, 이커머스, 혹은 저처럼 데이터에 진심인 분들이라면, 이제는 단순히 데이터를 긁어오는 것만으로는 부족하다는 걸 잘 아실 거예요. 얼마나 빠르고, 대규모로, 그리고 IP 차단 없이 데이터를 수집할 수 있느냐가 진짜 경쟁력입니다. 실제로 웹 스크래핑 시장은 2025년 74.8억 달러에서 2034년에는 무려 384억 달러까지 성장할 전망이라고 하니, 경쟁이 점점 더 치열해질 수밖에 없겠죠().
하지만 요즘 웹사이트들은 동적 콘텐츠, 봇 차단, 자주 바뀌는 레이아웃 등으로 무장한 ‘철옹성’이 되어버렸어요. 저 역시 많은 웹 스크래퍼들이 기본 원칙을 무시하거나, 사이트의 방어 기술을 얕잡아보다가 낭패를 보는 걸 수도 없이 봤습니다. 그래서 오늘은 Node.js로 웹 스크래핑 효율을 극대화하는 실전 노하우를, 제 경험을 곁들여 쉽고 재밌게 풀어보려고 해요.
Node.js가 웹 스크래핑에 딱 맞는 이유
수백, 수천 개의 페이지를 한 번에 긁어본 적 있다면, 속도와 동시처리가 얼마나 중요한지 몸소 느끼셨을 거예요. 바로 이 부분에서 Node.js가 진가를 발휘합니다. 비동기, 논블로킹 I/O 모델 덕분에 수많은 네트워크 요청을 동시에 처리할 수 있죠(). 다른 언어들은 요청이 끝날 때까지 기다리지만, Node.js는 이벤트 루프를 돌리며 요청을 마치 서커스 단원처럼 능숙하게 처리합니다.
실제로, 실시간 데이터 추출이나 대규모 크롤링이 필요한 상황, 특히 자바스크립트로 가득한 사이트에서는 Node.js가 Python이나 Java보다 훨씬 뛰어난 성능을 보여줍니다. 가 Node.js를 백엔드와 자동화에 사용하고 있을 정도로, 지금 가장 인기 있는 웹 기술입니다.
Node.js와 다른 웹 스크래핑 프레임워크 비교
조금 더 기술적으로 들어가 볼까요? Node.js와 주요 경쟁 프레임워크를 비교해보면 다음과 같습니다:
| 프레임워크 | 강점 | 약점 | 추천 사용 사례 |
|---|---|---|---|
| Node.js | 비동기 처리, 동시성 우수, 방대한 npm 생태계, 동적 사이트에 강함 | 메모리 사용량 높을 수 있음, 콜백 지옥(비동기/await 미사용 시) | 실시간 스크래핑, JS 기반 사이트, 확장성 높은 마이크로서비스 |
| Python | 다양한 스크래핑 라이브러리(BeautifulSoup, Scrapy), 쉬운 문법 | 대규모 동시성에 약함, JS 렌더링 사이트에 취약 | 정적 HTML, 연구, 프로토타입 |
| Java | 강한 타입, 엔터프라이즈에 적합 | 코드가 장황함, 빠른 스크립트에 비효율적 | 대규모, 기업용 스크래핑 |
| Go | 빠른 속도, 효율적인 동시성 | 생태계 작음, 학습 곡선 높음 | 고성능, 저지연 스크래핑 |
대부분의 비즈니스 사용자에게 Node.js는 빠르고 유연하며, 최신 자바스크립트 기반 웹에 최적화된 선택지입니다().
Node.js 웹 스크래핑 환경, 이렇게 세팅하세요
효율적인 웹 스크래퍼는 기본 세팅부터 다릅니다. 제가 추천하는 환경은 이렇습니다:
- 프로젝트 구조: 모듈화가 핵심이에요.
/src,/libs,/config등 폴더를 나누고, 민감 정보(API 키, 프록시)는dotenv로 환경 변수에 저장하세요(). - HTTP 클라이언트: , , 중 하나를 사용하세요.
- HTML 파싱: 정적 HTML은 , 동적 콘텐츠는 나 Playwright를 추천합니다.
- 유틸리티: 데이터 가공은 , 데이터 검증은 나 를 활용하세요.
- 테스트 & 린팅: Mocha(테스트), ESLint(코드 품질)로 관리하세요().
꼭 써야 할 Node.js 웹 스크래핑 라이브러리
- axios/got/node-fetch: HTTP 요청에 사용. axios는 Promise 기반 API와 JSON 처리로 인기가 높아요.
- Cheerio: 빠른 jQuery 스타일 HTML 파서. 정적 페이지에 최적, 약 0.5초 내 파싱().
- Puppeteer/Playwright: 동적, JS 기반 사이트를 위한 헤드리스 브라우저 자동화. 느리지만(~4초/페이지), 동적 콘텐츠에 필수().
- dotenv: 환경 변수 관리.
- csv-writer/jsonfile: 데이터 내보내기.
Node.js 웹 스크래핑, 이런 실수는 꼭 피하세요
웹 스크래퍼가 차단되거나, 오류로 멈추거나, 엉망인 데이터를 쏟아내는 경우를 정말 많이 봤어요. 주의해야 할 점은 다음과 같습니다:
- robots.txt와 이용약관 무시: 스크래핑 전 반드시 확인하세요. 위반 시 IP 차단, 심하면 법적 문제까지 발생할 수 있습니다().
- 서버 과부하: 무작정 요청을 쏘지 마세요. 1~3초 랜덤 딜레이, 동시성 제한 등으로 '봇'처럼 보이지 않게 하세요().
- 에러 미처리: 항상 try/catch로 감싸고, HTTP 에러와 실패 로그를 남기세요. 일시적 오류는 지수 백오프로 재시도하세요().
- 요청 헤더 누락: 실제 브라우저처럼 User-Agent, Accept-Language, Referer 등 헤더를 추가하고, 주기적으로 변경하세요().
안티 스크래핑 방어 우회법
요즘 웹사이트는 봇 차단 기술이 정말 정교해졌어요. 저만의 우회 팁을 공유합니다:
- 프록시/IP 회전: 프록시 풀을 사용해 IP를 주기적으로 바꾸세요().
- 헤더 랜덤화: User-Agent, Accept-Language 등 헤더를 요청마다 다르게 설정하세요.
- 헤드리스 브라우저 스텔스:
puppeteer-extra-plugin-stealth같은 플러그인으로 자동화 흔적을 감추세요. - 사람처럼 행동: 랜덤 딜레이, 마우스 이동, 스크롤, 오타 등 인간 행동을 흉내 내세요().
Node.js 스크래퍼에서 인간 행동 시뮬레이션하기
이 부분이 가장 재미있으면서도 효과적입니다. 즉각적으로 클릭/스크롤하지 말고, 다음과 같이 스크립트를 작성하세요:
- 동작 사이에 랜덤 대기(
await page.waitForTimeout(randomDelay)) - 마우스를 조금씩 불규칙하게 이동(
page.mouse.move(x, y)) - 타이핑 시 랜덤 딜레이와 오타 추가(
page.type(selector, text, {delay: random(100,200)})) - 스크롤도 일정하지 않게, 끝까지 한 번에 내리지 않기
이런 기법만으로도 보호된 사이트에서 성공률이 크게 올라갑니다().
Thunderbit로 복잡한 데이터 추출도 손쉽게
이제 본론입니다. 사실 웹 스크래핑은 쉽지 않아요. 그래서 Thunderbit를 만들었습니다.
Thunderbit는 AI 기반 웹 스크래퍼 크롬 확장 프로그램으로, 누구나 자연어로 원하는 데이터를 추출할 수 있습니다. "AI 필드 추천"을 클릭하면 AI가 페이지 구조를 파악해주고, "스크랩"만 누르면 끝! 마치 24시간 일하는 신입 개발자를 둔 느낌이죠.
더 좋은 점은, Thunderbit가 API도 제공해서 Node.js 워크플로우에 바로 연동할 수 있다는 것! 복잡한 코드 없이도 동적 콘텐츠, 하위 페이지, 페이지네이션까지 자동 처리합니다. 추출된 데이터는 CSV, JSON, Google Sheets, Airtable, Notion 등으로 바로 받을 수 있어 업무 효율이 극대화됩니다().
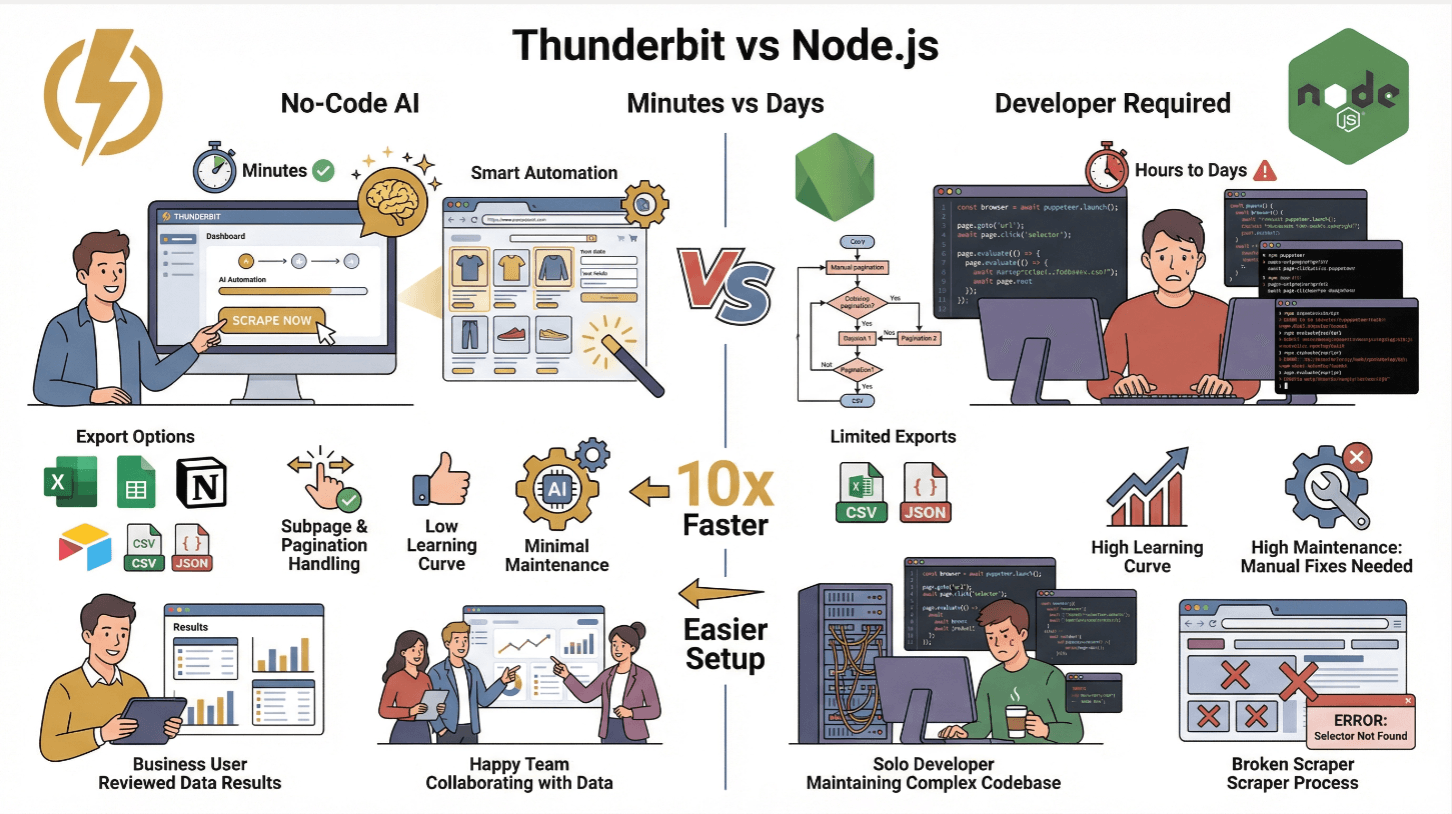
Thunderbit vs. 전통적인 Node.js 스크래핑
| 기능 | Thunderbit | 전통적 Node.js 스크래퍼 |
|---|---|---|
| 세팅 시간 | 몇 분(코딩 불필요) | 수 시간~수일(코딩, 테스트) |
| 동적 콘텐츠 처리 | 가능(AI+브라우저) | 가능(Puppeteer/Playwright 필요) |
| 하위 페이지/페이지네이션 | 1클릭 | 수동 코딩 필요 |
| 데이터 내보내기 | 엑셀, 시트, Notion, Airtable, CSV, JSON | CSV/JSON(직접 구현) |
| 학습 곡선 | 낮음(비즈니스 사용자) | 높음(개발자) |
| 유지보수 | 최소(AI가 자동 적응) | 높음(사이트 변경 시 직접 수정) |
Thunderbit는 비개발자나 반복 작업을 줄이고 싶은 분들에게 최적입니다. 고급 사용자는 Thunderbit API로 대규모 자동화도 가능합니다().
Cheerio와 Puppeteer 조합으로 동적 콘텐츠 완벽 대응
제가 가장 즐겨 쓰는 Node.js 스크래핑 조합입니다. 방법은 다음과 같습니다:
- Puppeteer로 페이지를 로드하고, 자바스크립트 실행(
networkidle까지 대기). - HTML 추출:
await page.content()로 HTML을 가져옵니다. - Cheerio로 파싱: HTML을 Cheerio에 넘겨 빠르고 간편하게 데이터 추출.
이렇게 하면 Puppeteer의 동적 처리력과 Cheerio의 빠른 파싱 속도를 모두 누릴 수 있습니다().
성능 팁: 필요한 요소만 선택하세요. Cheerio는 전체 DOM을 메모리에 올리므로, 범위가 넓은 선택자는 피하고, 반복 스크래핑 시 캐시를 활용하세요().
HTML 파싱과 데이터 추출 최적화
- 구체적인 선택자 사용:
$('body *')처럼 광범위하게 선택하지 말고, 필요한 부분만 타겟팅하세요. - 대용량 페이지는 스트리밍: HTML이 크면 스트리밍 처리나 작업 분할을 고려하세요.
- 렌더링된 HTML 캐싱: 같은 URL을 반복 방문한다면 HTML을 캐싱해 불필요한 요청을 줄이세요.
- 데이터 검증 및 정제: validator 라이브러리로 데이터 품질을 보장하세요().
클라우드에서 확장 가능한 Node.js 웹 스크래퍼 배포
대규모 스크래핑이 필요하다면, 클라우드 네이티브 환경이 답입니다.
- Docker로 패키징:
Dockerfile작성, 코드 복사, 의존성 설치, 엔트리포인트 지정. - 클라우드 배포: 간단한 작업은 AWS EC2, Google Cloud Compute, Azure VM. 대규모는 Kubernetes, AWS ECS/EKS, Google Cloud Run, Azure Kubernetes Service 활용().
- Kubernetes 오케스트레이션: 여러 pod로 분산 실행, 오토스케일링, 로드밸런서로 URL 분배.
- 작업 스케줄링: CloudWatch Events, Cloud Scheduler, cron 등으로 주기적 실행.
실제 사례로, Kubernetes pod를 5개에서 10개로 늘리니 400페이지 스크래핑 시간이 수 분에서 1분 미만으로 단축되었습니다().
스크래핑 인프라 모니터링 및 오토스케일링
- 로그 관리: CloudWatch, Stackdriver, Datadog 등으로 로그 스트리밍 및 에러/지연 알림 설정.
- 헬스 체크: Prometheus, Grafana로 분당 스크래핑 수, 에러율, pod 상태 등 모니터링.
- 오토스케일링: Kubernetes HPA로 CPU/요청량에 따라 pod 자동 확장.
네트워크 오류나 임시 차단에는 지수 백오프 재시도를 꼭 적용하세요.
데이터 저장 및 후처리 실전 팁
데이터를 수집했다면, 이제 저장과 정제가 중요합니다:
- 소규모 작업: CSV, JSON 내보내기 또는 Google Sheets, Airtable, Notion으로 바로 전송(Thunderbit는 기본 지원).
- 대규모 작업: 구조화 데이터는 SQL(MySQL/PostgreSQL), 반구조화/유동적 스키마는 NoSQL(MongoDB, DynamoDB) 추천().
- 클라우드 스토리지: S3, Google Cloud Storage로 원본 파일 및 백업 관리.
- 데이터 정제: 필드 검증, 포맷 통일(날짜, 숫자), 중복 제거, 스키마 검증으로 데이터 품질 확보().
원본과 정제 데이터를 모두 보관하세요. 재처리나 디버깅에 유용합니다.
결론: Node.js 웹 스크래핑 효율화 핵심 요약
핵심만 정리해보면:
- Node.js의 비동기 처리로 대규모, 동시 스크래핑을 실현하세요(JS 기반 사이트에 특히 강점).
- 도구 조합 활용: 요청은 axios/got, 정적 HTML은 Cheerio, 동적 콘텐츠는 Puppeteer, 두 가지를 섞어 속도와 유연성 모두 잡으세요.
- 안티봇 방어 우회: 프록시/헤더 회전, 인간 행동 시뮬레이션, robots.txt 준수.
- Thunderbit로 간소화: 비즈니스 사용자나 빠른 프로토타이핑에는 로 AI 기반 복잡 데이터 추출 및 Node.js API 연동.
- 대규모 배포: Docker, Kubernetes로 오케스트레이션, 모니터링까지 자동화.
- 데이터 저장/정제: 목적에 맞는 저장소 선택, 항상 데이터 검증 후 활용.
웹 환경은 점점 복잡해지지만, 이 원칙만 지키면 Node.js 스크래퍼는 빠르고 안정적으로, 그리고 안티봇 기술보다 한발 앞서 나갈 수 있습니다. 새벽 2시에 셀렉터 디버깅이 지겹다면, Thunderbit의 AI가 항상 대기 중이라는 점도 기억하세요.
더 배우고 싶으신가요? 에서 심층 가이드를 확인하거나, 으로 쉽고 빠른 스크래핑을 직접 경험해보세요.
자주 묻는 질문(FAQ)
1. 2025년 Node.js가 웹 스크래핑에 특히 강한 이유는?
Node.js의 비동기, 이벤트 기반 구조 덕분에 수천 개의 요청을 동시에 처리할 수 있어 대용량 데이터나 실시간 업데이트에 최적입니다. 방대한 npm 생태계와 자바스크립트 지원도 최신 웹사이트에 강점입니다().
2. Node.js로 스크래핑할 때 차단을 피하려면?
프록시 회전, 요청 헤더 랜덤화, 랜덤 딜레이로 요청 속도 조절, Puppeteer 등으로 인간 행동(마우스, 스크롤, 타이핑) 시뮬레이션이 필요합니다. robots.txt와 사이트 약관도 꼭 준수하세요().
3. Node.js 스크래퍼에서 Cheerio와 Puppeteer는 언제 써야 하나요?
정적 HTML(데이터가 원본 HTML에 있을 때)은 Cheerio로 빠르게 파싱하세요. 동적 콘텐츠는 Puppeteer로 렌더링 후 Cheerio로 파싱하면 효율적입니다().
4. Thunderbit는 Node.js 웹 스크래핑을 어떻게 간소화하나요?
Thunderbit는 AI와 자연어 프롬프트로 구조화 데이터를 추출할 수 있어 코딩이 필요 없습니다. 동적 콘텐츠, 하위 페이지, 페이지네이션도 자동 처리하며, Node.js API 연동 및 Excel, Google Sheets, Airtable, Notion 등으로 바로 내보내기가 가능합니다().
5. Node.js 스크래퍼를 클라우드에서 확장/모니터링하려면?
Docker로 패키징, Kubernetes 등 클라우드 서비스에 배포, 오토스케일링으로 트래픽 급증 대응. CloudWatch, Prometheus 등으로 로그/지표 모니터링 및 에러 알림 설정이 필요합니다().
웹 스크래핑 실력을 한 단계 업그레이드하고 싶다면, Thunderbit를 직접 사용해보세요. 여러분의 스크래퍼가 빠르고, 은밀하며, 언제나 한발 앞서길 바랍니다.
더 알아보기