

대부분의 Node.js fetch 튜토리얼은 await fetch(url) 한 줄을 보여주고 끝나요. 문제는 그다음이에요. 실제 서비스에 올리면 500 오류가 아무 소리 없이 묻히고, 응답 없는 요청이 90초씩 매달려 있고, 멀쩡했어야 할 코드를 금요일 밤 내내 붙잡고 디버깅하게 되죠.
저는 Thunderbit에서 내부 도구랑 데이터 파이프라인을 한참 만들어 왔어요. 확실하게 말씀드릴 수 있는 건, "튜토리얼에선 잘 되던 fetch"와 "운영에서도 잘 되는 fetch" 사이의 간극이 제일 아프다는 거예요. Reddit의 한 개발자가 딱 짚었죠. "운영에 올려 보면 기본 fetch보다 더 단단한 뭔가가 필요하다는 걸 알게 된다."
이런 고백도 있었어요. "웹 개발 3년 차에야 깨달았다. fetch의 catch 블록은 HTTP 오류를 잡는 자리가 아니다." 이 글은 대부분의 튜토리얼이 건너뛰는 다섯 가지를 다뤄요. 오류 처리 함정, AbortController 타임아웃, 재시도 로직, 연결 재사용, 그리고 구조화된 데이터 추출에서 언제 fetch를 벗어나야 하는지까지. 운영 중인 fetch가 조용히 실패한 경험이 있다면 딱 맞는 글이에요.
Node.js Fetch API란 무엇인가요?
Node.js Fetch API는 별도 패키지 없이 HTTP 요청(GET, POST, PUT, DELETE 등)을 보낼 수 있는 내장 기능이에요. 브라우저 표준과 호환돼서, Axios나 node-fetch를 따로 깔 필요가 없죠. 브라우저에서 fetch()를 써 보셨다면 문법은 이미 익숙하실 거예요. 같은 API를 서버에서도 그대로 쓰면 돼요.
버전별 흐름은 이렇게 정리돼요.
| 이정표 | Node 버전 | 변경 사항 |
|---|---|---|
| 실험적 fetch 플래그 | v17.5.0 / v16.15.0 | --experimental-fetch 뒤에 숨겨진 상태로 fetch 추가 |
| 기본 전역 fetch | v18.0.0 | Undici 기반의 실험적 fetch가 전역으로 제공됨 |
| 안정화된 fetch | v21.0.0 | 더 이상 실험 기능이 아님 |
| 2026 운영 기준선 | v22 LTS / v24 LTS | 운영 환경에 권장됨. v20은 이제 EOL |
Node의 fetch는 내부적으로 Undici가 돌려요. Node.js 전용으로 만든 고성능 HTTP 클라이언트죠. 예전 내장 http 모듈에 기대지 않아요. 덕분에 브라우저 코드든, Express 백엔드든, 서버리스 함수든, CLI 스크립트든 똑같은 방식으로 도는 현대적 Promise 기반 API를 쓸 수 있어요.
Node.js Fetch API가 프로젝트에서 중요한 이유
Node 18 전에는 새 프로젝트마다 늘 똑같은 일을 했어요. npm install axios나 npm install node-fetch. 2026년 지금은 관리되는 Node LTS만 쓴다면 기본적인 HTTP 요청에 의존성이 아예 필요 없어요. 번들 크기, 공급망 보안, 신규 팀원 온보딩 측면에서 전부 이득이에요. 프론트와 백엔드가 같은 API를 공유하니까요.
기본 fetch가 특히 잘 맞는 자리는 이런 곳이에요.
| 상황 | 기본 fetch가 잘 맞는 이유 | 운영 시 주의점 |
|---|---|---|
| REST API를 호출하는 Express/Fastify 백엔드 | 익숙한 async/await, 별도 의존성 없음 | 타임아웃과 response.ok 검사를 추가하세요 |
| 서버리스 함수(Lambda, Vercel 등) | 콜드 스타트 부담이 작고, 패키지 설치가 필요 없음 | 플랫폼 최대 실행 시간보다 짧게 타임아웃을 잡으세요 |
| CLI 스크립트와 자동화 작업 | 프로젝트 설정 없이 간단한 GET/POST 가능 | 불안정한 API에는 재시도/백오프를 추가하세요 |
| 웹훅 전송 또는 전달 | 표준 HTTP 메서드와 헤더 사용 | 멱등성이 없는 POST를 무작정 재시도하지 마세요 |
| 리포트와 대시보드 | API에서 JSON을 가져오기 좋음 | 반복 처리 시 페이지네이션과 연결 풀링을 사용하세요 |
| 마이크로서비스 간 통신 | 단순한 내부 HTTP 호출에 잘 맞음 | 재시도, 훅, HTTP/2가 필요하면 Got 또는 Undici를 직접 고려하세요 |
새 Node 22+ 프로젝트라면 기본 fetch가 가장 무난한 출발점이에요. 인터셉터나 내장 재시도, HTTP/2처럼 fetch에 없는 기능이 꼭 필요한 경우만 예외고요. npm 다운로드 수치만 봐도 판이 옮겨가는 게 보여요. node-fetch는 여전히 주간 약 1억 4,490만 다운로드지만 상당수가 레거시와 간접 의존성이고, Axios는 약 1억 860만, Undici는 약 1억 600만, Got는 약 3,600만, Ky는 약 560만 수준이에요. 방향은 분명해요. 기본 fetch가 새 기준선이 됐고, 서드파티 클라이언트는 특수 요구를 위한 도구로 남았어요.
2026년 기준: 기본 fetch vs node-fetch vs Axios vs Got vs Ky 의사결정표
개발자 포럼에서 제일 자주 보는 질문이 *"Node.js에선 어떤 HTTP 클라이언트를 써야 하나요?"*예요. 한 Reddit 사용자는 이렇게 받아쳤죠. "언어에 이미 기능이 들어있는데 왜 라이브러리를 끌어와요?" 일리 있어요. 답은 결국 뭐가 필요하냐에 달렸어요.
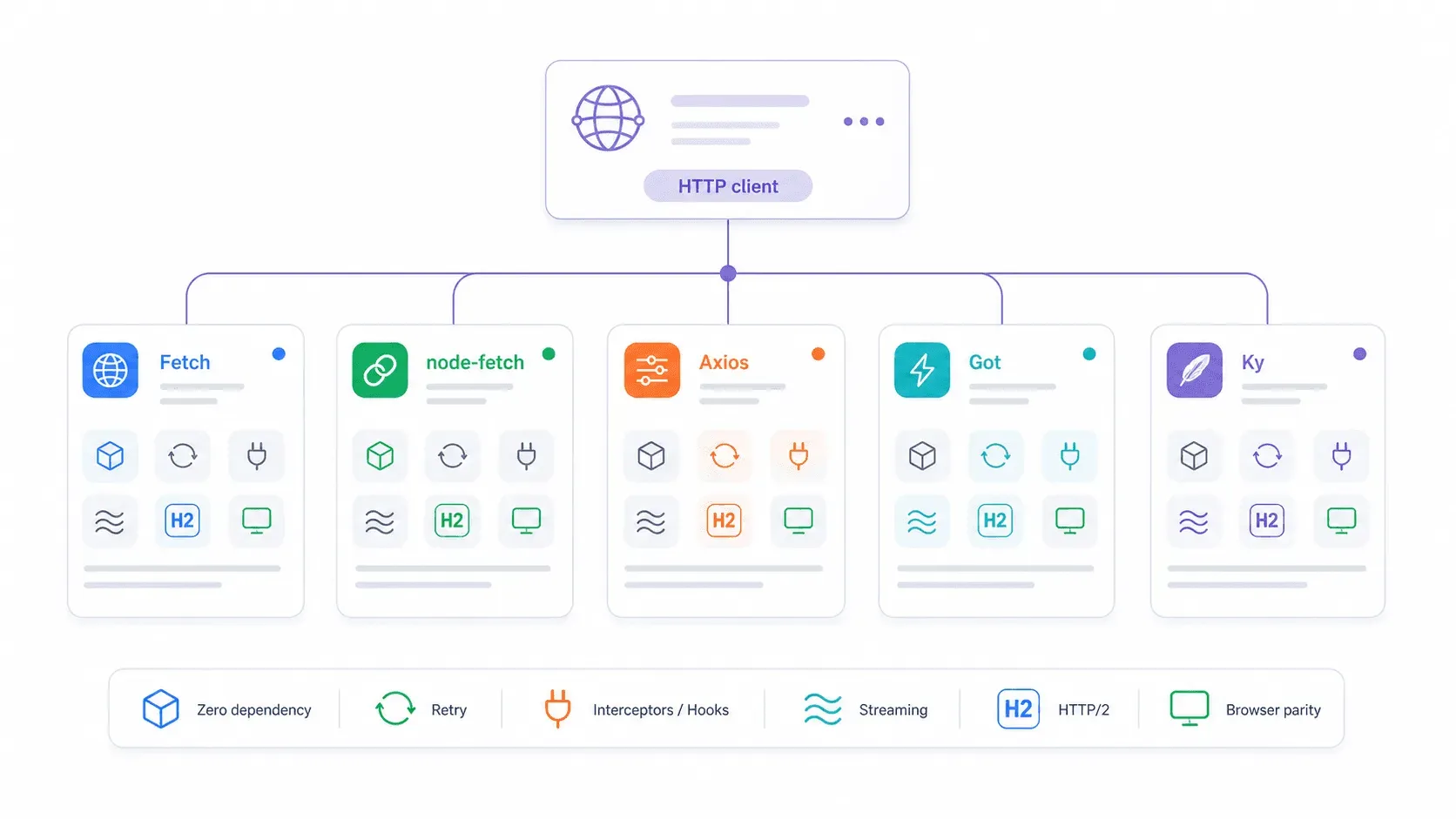
| 기능 | 기본 fetch | node-fetch v3 | axios | got v15 | ky v2 |
|---|---|---|---|---|---|
| Node.js 버전 | ≥18(22/24 LTS 권장) | ≥12.20 | 폭넓음 | ≥22 | ≥22 |
| 설치 필요 여부 | 아니요 | 예 | 예 | 예 | 예 |
| ESM + CJS 지원 | 둘 다(전역) | ESM 전용(v3) | 둘 다 | ESM 전용 | ESM 전용 |
| 4xx/5xx에서 자동 거부 | 아니요 | 아니요 | 예 | 예 | 예 |
| 내장 재시도 | 아니요 | 아니요 | 아니요 | 예 | 예 |
| 요청 인터셉터 | 아니요 | 아니요 | 예 | 예(hooks) | 예(hooks) |
| 스트리밍 지원 | Web ReadableStream | 예 | 제한적 | 강력한 Node streams | fetch 기반 |
| 번들/설치 용량 | 0 KB | 약 107 KB, 3개 의존성 | 약 2.8 MB, 4개 의존성 | 약 355 KB, 12개 의존성 | 약 405 KB, 0개 의존성 |
| HTTP/2 지원 | Undici dispatcher 통해 가능 | 아니요 | 아니요 | 예 | 아니요(fetch 래퍼) |
ESM/CJS 얘기를 하나 짚어요. node-fetch v3는 ESM 전용이라 require()를 쓰던 프로젝트가 우수수 깨졌어요. 기본 fetch는 전역으로 제공돼서 CJS든 ESM이든 import 없이 바로 써요. CommonJS 때문에 node-fetch v2에 묶여 있었다면 기본 fetch가 그 매듭을 깔끔히 풀어줘요.
초기 안정성 걱정도 있었죠. 맞아요, Node 18 초기 fetch엔 실제 버그가 있었어요. Reddit의 한 개발자는 *"최근 기본 Node 18 fetch에서 엄청난 버그를 만나 앱을 갈아엎어야 했다"*고 했어요. 그게 2023년 얘기예요. 2026년 Node 22, 24 LTS에선 다 해결됐어요. 기본 fetch, 운영에 써도 돼요.
기본 fetch를 계속 써도 좋은 경우
다음 상황이면 기본 fetch를 고르세요.
- 프로젝트가 Node 22 LTS나 Node 24 LTS에서 돌아가요.
- 요청이 단순한 REST 호출(GET, POST, PUT, DELETE)이에요.
response.ok, JSON 파싱, 타임아웃, 재시도용 작은 래퍼를 직접 얹을 마음이 있어요.- 의존성을 0에 가깝게 두고 공급망 위험을 줄이고 싶어요.
- 브라우저와 서버의 API 일관성이 중요해요.
- 서버리스나 엣지처럼 내장 API가 선호되는 환경에서 일해요.
Axios, Got, Ky가 더 적합한 경우
Axios는 요청/응답 인터셉터에 팀이 기대고 있을 때 좋아요. 인증 토큰 자동 갱신, 테넌트 헤더, 중앙 로깅 같은 거죠. HTTP 오류에서 기본으로 거부되길 원하거나, 더 오래된 Node 런타임과 호환이 필요할 때도 맞아요.
Got는 내장 재시도, hooks, 단계별 타임아웃, streams, 페이지네이션 헬퍼, Unix socket, 프록시/캐싱, HTTP/2가 다 필요한 고처리량 Node 서비스용이에요. Node 전용 HTTP 작업을 위한 만능 도구라고 보면 돼요.
Ky는 fetch의 단순함은 살리되 보일러플레이트는 덜고 싶을 때 잘 맞아요. 작은 패키지에 의존성 없이 재시도, 타임아웃, hooks, HTTPError를 기본으로 줘요.
Node.js Fetch API로 GET 요청 보내는 방법
async/await로 짠 GET 요청은 이렇게 생겼어요.
const response = await fetch('https://jsonplaceholder.typicode.com/posts/1');
const post = await response.json();
console.log(post.title);
// → "sunt aut facere repellat provident occaecati excepturi optio reprehenderit"
.then() 체인을 선호한다면 이런 식이고요.
fetch('https://jsonplaceholder.typicode.com/posts/1')
.then(response => response.json())
.then(post => console.log(post.title))
.catch(error => console.error(error));
둘 다 돌아가요. 다만 아직 운영에 안전하다고 보긴 어려워요(이유는 곧 나와요).
알아두면 좋은 response 읽기 메서드:
| 메서드 | 언제 사용할까 |
|---|---|
response.json() | 서버가 JSON을 반환할 때 |
response.text() | 서버가 HTML, 일반 텍스트, CSV, Markdown을 반환할 때 |
response.arrayBuffer() | 이미지나 파일 같은 바이너리 데이터가 필요할 때 |
response.body | 스트리밍/청크 단위 처리가 필요할 때 |
오류를 실제로 확인하는 더 나은 패턴은 이거예요.
async function getPost(id) {
const response = await fetch(`https://jsonplaceholder.typicode.com/posts/${id}`);
if (!response.ok) {
throw new Error(`HTTP ${response.status} ${response.statusText}`);
}
return response.json();
}
const post = await getPost(1);
console.log(post.title);
이 if (!response.ok) 한 줄이 튜토리얼 코드와 운영 코드를 가르는 선이에요. 그리고 여기서 가장 큰 함정으로 이어져요.
Node.js Fetch API로 POST 요청 보내는 방법
POST도 모양은 같아요. method, headers, body만 채워 주면 돼요.
const response = await fetch('https://jsonplaceholder.typicode.com/posts', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
title: 'Node fetch 가이드',
body: '운영 환경의 fetch에는 오류 처리가 필요합니다.',
userId: 1,
}),
});
if (!response.ok) {
throw new Error(`HTTP ${response.status}`);
}
const created = await response.json();
console.log(created.id); // → 101
다른 요청 타입 보내기(PUT, DELETE, PATCH)
PUT, PATCH, DELETE는 method 값만 바꾸면 구조가 똑같아요.
// PUT — 전체 교체
await fetch('https://jsonplaceholder.typicode.com/posts/1', {
method: 'PUT',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ id: 1, title: '교체됨', body: '전체 교체', userId: 1 }),
});
// PATCH — 부분 수정
await fetch('https://jsonplaceholder.typicode.com/posts/1', {
method: 'PATCH',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ title: '부분 수정' }),
});
// DELETE
await fetch('https://jsonplaceholder.typicode.com/posts/1', {
method: 'DELETE',
});
Express body-parser 함정: Express에 JSON을 POST했는데 req.body가 undefined로 나온다면, 거의 매번 답은 하나예요. express.urlencoded()가 아니라 express.json()을 써야 해요. Content-Type: application/json 본문을 파싱하려면 라우트 앞에 express.json() 미들웨어가 있어야 하거든요. Express 관련 Stack Overflow 질문 중에서도 손꼽히게 흔하고, 매번 사람을 헷갈리게 만들어요.
import express from 'express';
const app = express();
app.use(express.json()); // ← JSON POST 본문에 필요한 것은 이것입니다
app.post('/api/posts', (req, res) => {
res.json({ received: req.body });
});
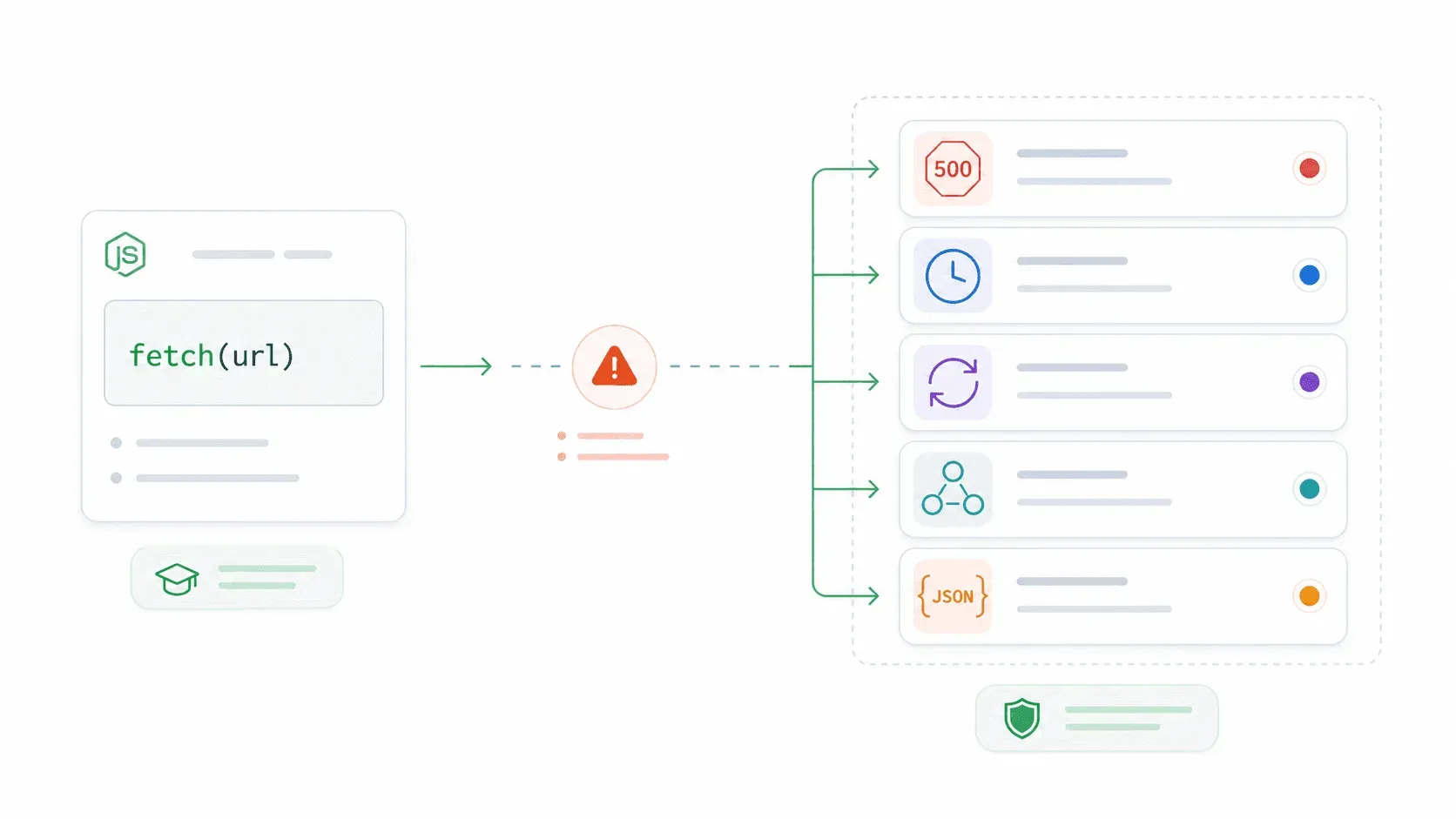
운영 환경을 망가뜨리는 fetch() 오류 함정
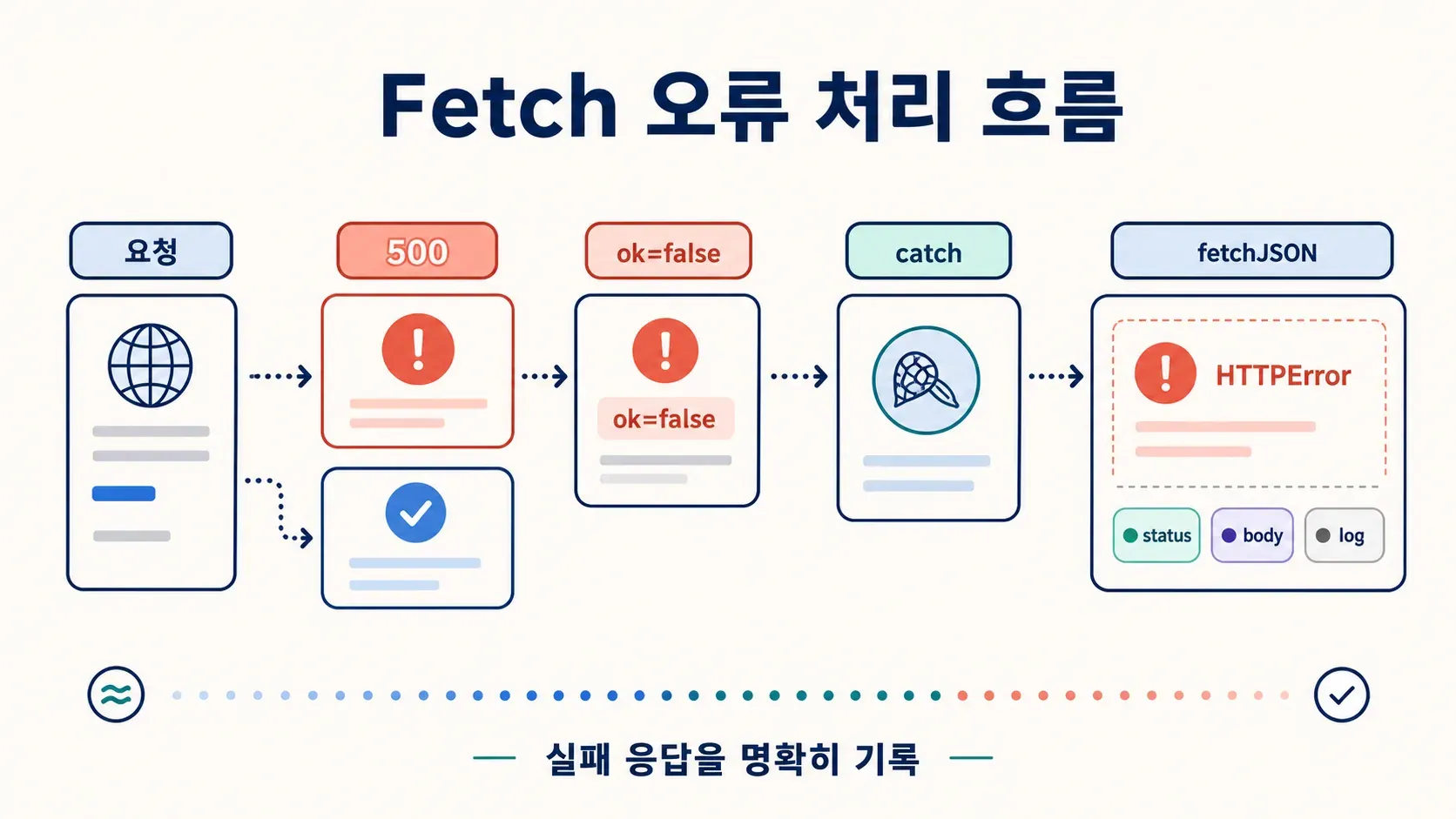
운영 fetch 버그는 대부분 여기서 터져요.
fetch()는 HTTP 4xx, 5xx 오류에선 promise를 reject하지 않아요. DNS 오류, 인터넷 끊김, 요청 취소 같은 네트워크 레벨 실패에서만 reject해요. 서버가 403 Forbidden이나 500을 돌려줘도 fetch는 그걸 성공한 응답으로 봐요. 그래서 .catch() 블록은 절대 안 돌고, try/catch로도 못 잡아요. 코드는 서버가 보낸 게 뭐든 그냥 처리해 버리죠.
MDN 문서는 이 점을 또렷이 설명하는데, 대부분의 튜토리얼은 슬쩍 넘어가요. 그래서 아래 코드는 멀쩡해 보여도 오류를 조용히 삼켜요.
try {
const response = await fetch('https://api.example.com/private');
const data = await response.json(); // ← 403이어도 여기까지 실행됩니다
console.log('성공한 것처럼 보임:', data);
} catch (error) {
// 여기에는 네트워크 수준 실패만 들어옵니다
console.error('잡힘:', error);
}
각 패턴이 실제로 뭘 잡는지 표로 정리하면 이래요.
| 패턴 | 네트워크 오류 포착 | 4xx/5xx 포착 | JSON 안전 파싱 | 재사용 가능성 |
|---|---|---|---|---|
원시 .then(res => res.json()) | 예(.catch() 통해) | 아니요 | content-type 가드 없음 | 아니요 |
await fetch()와 함께 쓰는 try/catch | 예 | 아니요 | content-type 가드 없음 | 아니요 |
호출마다 수동 if (!res.ok) 확인 | 예 | 예 | 호출마다 다름 | 부분적 |
커스텀 fetchJSON() 래퍼 | 예 | 예 | 예 | 예 |
재사용 가능한 fetchJSON() 래퍼 만들기
래퍼는 한 번만 만들어 두세요. 어디서든 import해서 쓰면 돼요. 파일마다 if (!response.ok)를 복붙하는 일은 이제 끝이에요.
export class HTTPError extends Error {
constructor(message, { status, statusText, url, body }) {
super(message);
this.name = 'HTTPError';
this.status = status;
this.statusText = statusText;
this.url = url;
this.body = body;
}
}
export async function fetchJSON(url, options = {}) {
const response = await fetch(url, {
headers: {
Accept: 'application/json',
...options.headers,
},
...options,
});
const contentType = response.headers.get('content-type') || '';
const isJSON = contentType.includes('application/json');
const body = isJSON ? await response.json().catch(() => null) : await response.text();
if (!response.ok) {
throw new HTTPError(`HTTP ${response.status} ${response.statusText}`, {
status: response.status,
statusText: response.statusText,
url: response.url,
body,
});
}
return body;
}
이제 서버가 403을 돌려주면:
try {
const data = await fetchJSON('https://api.example.com/private');
} catch (error) {
if (error instanceof HTTPError) {
console.error(`서버가 ${error.status}를 반환했습니다:`, error.body);
} else {
console.error('네트워크 또는 기타 실패:', error);
}
}
이 오류 객체엔 상태 코드, 응답 본문, URL이 다 들어 있어요. 로깅, 알림, 사용자 메시지에 필요한 게 전부 있는 셈이죠. 한 번 만들어서 어디서나 쓰세요.
AbortController와 타임아웃: Node.js Fetch API의 운영 패턴
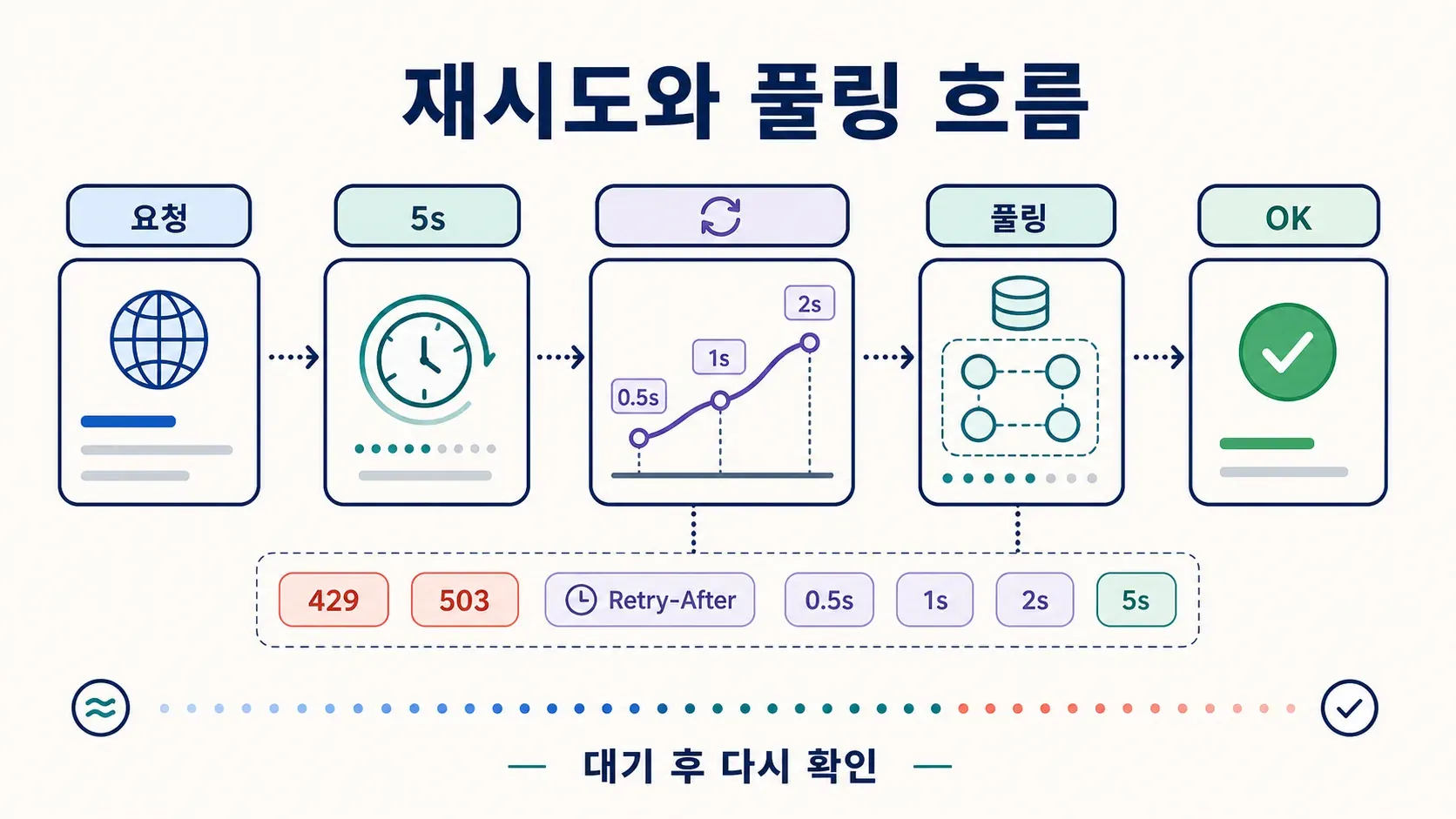
타임아웃이 없으면 원격 서버가 응답을 멈춘 순간 fetch는 끝없이 매달려 있어요. Express 라우트는 막히고, Lambda는 실행 시간을 다 태우고, 스크립트는 그냥... 그대로 멈춰 있죠.
상위 검색 결과를 쭉 훑어봤는데, Node.js 전용 fetch 튜토리얼 중 요청 취소나 타임아웃을 다루는 글이 하나도 없었어요. 그런데도 타임아웃은 개발자들이 Axios나 Got을 못 놓는 가장 큰 이유 중 하나예요. *"Node fetch does not timeout"*이라는 제목의 Reddit 스레드가 있을 정도니까요.
AbortSignal.timeout() 사용하기(Node 18.11+)
가장 간단한 길은 옵션 하나를 더 넣는 거예요.
try {
const response = await fetch('https://api.example.com/data', {
signal: AbortSignal.timeout(5000), // 5초
});
if (!response.ok) throw new Error(`HTTP ${response.status}`);
const data = await response.json();
console.log(data);
} catch (error) {
if (error.name === 'TimeoutError') {
console.error('요청이 5초 후 타임아웃되었습니다.');
} else {
throw error;
}
}
참고로 AbortSignal.timeout()은 AbortError가 아니라 TimeoutError를 던져요. 경력 있는 개발자도 가끔 여기서 헷갈려요.
AbortController로 수동 타임아웃 걸기
더 세밀하게 제어하거나, 단순 타이머가 아니라 사용자 동작에 맞춰 요청을 취소해야 한다면 이렇게 해요.
const controller = new AbortController();
const timeout = setTimeout(() => controller.abort(), 5000);
try {
const response = await fetch('https://api.example.com/data', {
signal: controller.signal,
});
const data = await response.json();
console.log(data);
} catch (error) {
if (error.name === 'AbortError') {
console.error('요청이 수동으로 중단되었습니다.');
} else {
throw error;
}
} finally {
clearTimeout(timeout);
}
AbortError와 TimeoutError 구분하기
이 구분은 로깅과 사용자 메시지에서 꽤 중요해요.
| 중단 경로 | catch 블록의 오류 이름 |
|---|---|
AbortSignal.timeout(ms) | TimeoutError |
controller.abort() | AbortError |
| DNS/네트워크 실패 | 보통 TypeError: fetch failed |
실무 예시를 볼게요. Express 라우트가 외부 API를 부르고 3초 안에 응답해야 하는 상황이에요.
app.get('/dashboard', async (req, res, next) => {
try {
const data = await fetchJSON('https://api.example.com/report', {
signal: AbortSignal.timeout(3000),
});
res.json(data);
} catch (error) {
if (error.name === 'TimeoutError') {
res.status(504).json({ error: '상위 API가 타임아웃되었습니다' });
return;
}
next(error);
}
});
이 패턴이 없으면 상위 API가 느려질 때 클라이언트가 포기할 때까지 라우트 전체가 묶여 버려요.
재시도 로직과 연결 재사용: Node.js Fetch API를 운영 수준으로 끌어올리기
기본 fetch엔 재시도가 안 들어 있어요. 네트워크 순간 장애나 일시적 503이 뜨면 요청은 그냥 실패하죠. 운영의 대부분 읽기 작업에선 이걸 그냥 둘 수 없어요.
지수 백오프가 있는 조합형 재시도 래퍼
일부러 짧게 짰어요. 핵심 로직은 사실 열 줄 정도예요.
const wait = ms => new Promise(resolve => setTimeout(resolve, ms));
export async function fetchWithRetry(url, options = {}, retries = 2) {
for (let attempt = 0; ; attempt++) {
try {
const response = await fetch(url, options);
if (response.ok || ![408, 429, 500, 502, 503, 504].includes(response.status)) {
return response;
}
if (attempt >= retries) return response;
} catch (error) {
if (attempt >= retries) throw error;
}
await wait(250 * 2 ** attempt); // 250ms, 500ms, 1000ms...
}
}
언제 재시도하고, 언제 하지 말아야 할까?
- 재시도할 것: 멱등적인 GET, HEAD 요청, 일시적 상태 코드(408, 429, 500, 502, 503, 504), 네트워크 순간 장애.
- 재시도하지 말 것: 레코드를 만들거나, 결제를 처리하거나, 부작용을 일으키는 비멱등 POST. 단, idempotency key를 쓴다면 예외예요.
- Retry-After를 존중할 것: 429(속도 제한)와 503(서비스 사용 불가)에선 백오프 전에
Retry-After헤더부터 확인하세요.
재시도 로직을 직접 짜기 싫다면 Ky가 재시도, 타임아웃, hooks, HTTPError를 기본으로 주는 가벼운 fetch 래퍼예요. 의존성도 없고요.
Undici의 Agent와 Pool로 연결 재사용하기
고처리량 루프에선 TCP 연결 재사용이 시간을 크게 아껴줘요. 수백 페이지를 스크래핑하거나, API를 배치로 부르거나, 서비스를 폴링할 때가 그렇죠. 새 연결마다 DNS 조회, TCP 핸드셰이크, HTTPS면 TLS 협상까지 새로 해야 하거든요.
Node의 fetch는 Undici가 돌리니까 커스텀 dispatcher를 넘길 수 있어요.
import { Agent } from 'undici';
const agent = new Agent({
keepAliveTimeout: 10_000,
keepAliveMaxTimeout: 60_000,
});
const response = await fetch('https://api.example.com/data', {
dispatcher: agent,
});
특정 origin을 더 촘촘히 제어하려면:
import { Pool } from 'undici';
const pool = new Pool('https://api.example.com', { connections: 10 });
const response = await fetch('https://api.example.com/data', {
dispatcher: pool,
});
// 사용 후:
await pool.close();
Undici README 벤치마크를 보면 연결 재사용과 풀링이 처리량을 크게 끌어올려요. 로컬 벤치마크에서 undici - dispatch는 초당 약 22,234건, undici - fetch는 약 5,904건이었어요. 실제 수치야 다르겠지만 방향은 분명해요. 같은 origin에 요청을 많이 보낸다면 풀링이 중요해요.
하나만 더요. 응답 본문은 항상 소비하거나 취소하세요. 소비되지 않은 본문은 Node의 HTTP 내부에서 리소스 누수를 일으킬 수 있어요.
Node.js Fetch API로 스트리밍 응답 처리하기
대용량 파일 다운로드, 청크로 오는 JSON 피드, 서버 전송 이벤트, LLM 출력 같은 건 전체 응답을 다 받은 뒤 처리하면 시간과 메모리를 낭비하기 쉬워요. 스트리밍을 쓰면 데이터가 도착하는 족족 처리할 수 있어요.
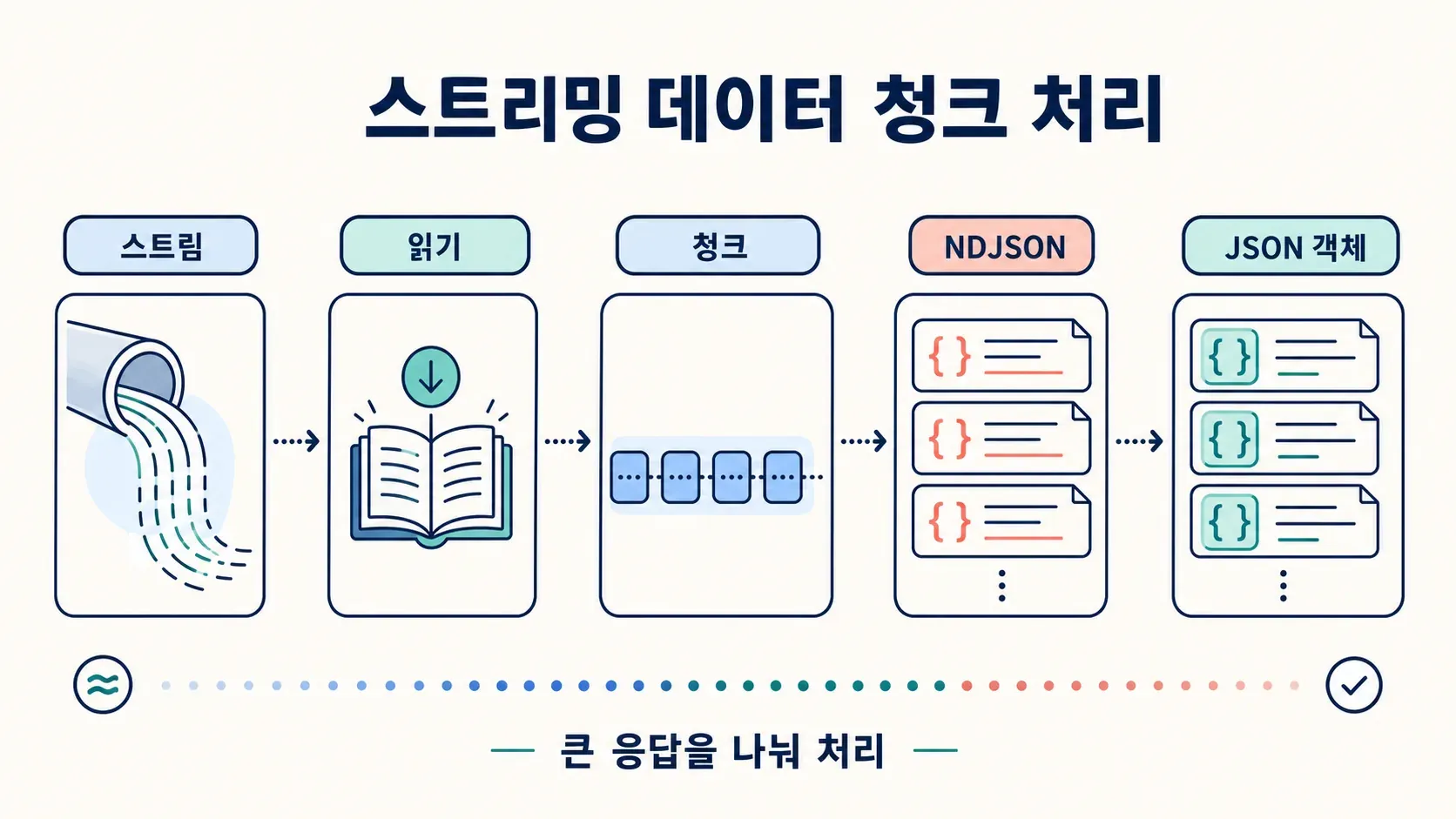
Node 18 이상엔 브라우저 호환 ReadableStream이 들어 있어요. 줄바꿈으로 나뉜 JSON 응답을 스트리밍하면서 도착하는 즉시 한 줄씩 처리하는 방법은 이래요.
const response = await fetch('https://example.com/large-file.ndjson');
if (!response.ok) throw new Error(`HTTP ${response.status}`);
const reader = response.body.getReader();
const decoder = new TextDecoder();
let buffer = '';
while (true) {
const { value, done } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
let newlineIndex;
while ((newlineIndex = buffer.indexOf('\n')) >= 0) {
const line = buffer.slice(0, newlineIndex).trim();
buffer = buffer.slice(newlineIndex + 1);
if (line) {
const item = JSON.parse(line);
console.log('처리됨:', item.id);
}
}
}
더 단순한 텍스트 스트리밍, 예를 들어 LLM 출력을 stdout으로 바로 흘려보내고 싶다면:
const response = await fetch('https://example.com/stream');
const reader = response.body.getReader();
const decoder = new TextDecoder();
for (;;) {
const { value, done } = await reader.read();
if (done) break;
process.stdout.write(decoder.decode(value, { stream: true }));
}
스트리밍은 기본 fetch와 Got이 둘 다 강한 영역이에요. Axios는 스트리밍 지원이 조금 제한적이에요.
fetch()가 한계에 부딪힐 때: API를 활용한 구조화된 웹 스크래핑
어느 순간이 되면 fetch 자체는 더 이상 병목이 아니에요. 진짜 문제는 *"HTML은 가져왔는데, 이제 뭘 하지?"*로 바뀌죠.
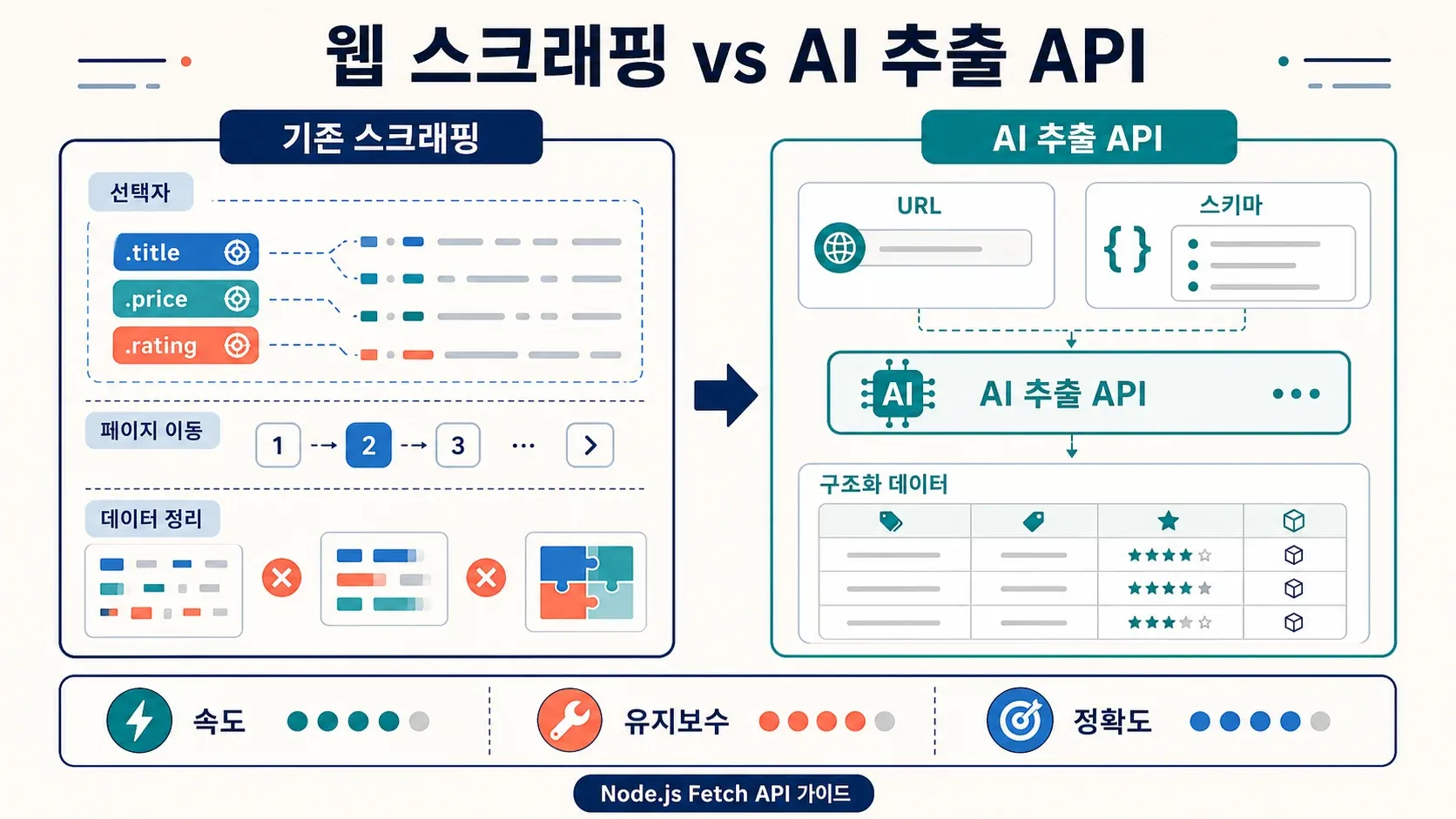
fetch는 HTTP 클라이언트예요. 바이트, 텍스트, JSON, HTML을 가져오는 데까지가 일이죠. 제품 카드, 가격, 평점, 연락처 표 같은 개념은 전혀 몰라요. 구조화된 웹 스크래핑을 하려면 보통 이런 원시 스택이 필요해요.
- HTML을 내려받기 위한
fetch() - CSS 선택자로 요소를 찾는 Cheerio(또는 유사 도구)
- 커스텀 페이지네이션 로직
- 페이지가 클라이언트 사이드 렌더링일 때의 JavaScript 렌더링
- 프록시/안티봇/CAPTCHA 처리
- 사이트 레이아웃이 바뀔 때마다 선택자 유지보수
전형적인 fetch + Cheerio 예시는 이래요. 제품 제목을 스크래핑하는 데 코드가 한 열다섯 줄쯤 들어요.
import * as cheerio from 'cheerio';
const response = await fetch('https://example-store.com/products');
if (!response.ok) throw new Error(`HTTP ${response.status}`);
const html = await response.text();
const $ = cheerio.load(html);
const products = $('.product-card')
.map((_, el) => ({
name: $(el).find('.product-title').text().trim(),
price: $(el).find('.price').text().trim(),
url: new URL($(el).find('a').attr('href'), response.url).href,
}))
.get();
console.log(products);
HTML 구조가 안정적인 페이지에선 잘 돌아가요. 그런데 금세 부서지기 쉬워져요. JavaScript 렌더링 콘텐츠, 바뀌는 클래스명, 안티봇 대응, 페이지네이션까지 얹히면 복잡도가 확 뛰어요.
Thunderbit의 Open API: 원시 HTML을 한 번에 구조화된 데이터로
여기서부터는 결이 다른 도구가 도움이 돼요. Thunderbit에선 JavaScript 렌더링, 안티봇 보호, 레이아웃 변경처럼 골치 아픈 부분을 대신 처리하는 API 계층을 만들었어요. 그래서 사용자는 원하는 데이터에만 집중하면 돼요.
Distill API (POST /distill): 어떤 URL이든 깔끔한 Markdown으로 바꿔줘요. LLM에 넣거나, 지식 베이스를 만들거나, 콘텐츠를 분석할 때 좋아요. HTML 파서가 필요 없어요.
Extract API (POST /extract): 원하는 구조화된 데이터(제품명, 가격, 평점 등)를 JSON Schema로 정의하면 AI가 뽑아줘요. CSS 선택자도 필요 없고, 레이아웃이 바뀌어도 안 깨져요.
Thunderbit의 Extract API로 같은 제품 스크래핑을 하면, native fetch로 이렇게 부를 수 있어요.
const response = await fetch('https://openapi.thunderbit.com/openapi/v1/extract', {
method: 'POST',
headers: {
Authorization: `Bearer ${process.env.THUNDERBIT_API_KEY}`,
'Content-Type': 'application/json',
},
body: JSON.stringify({
url: 'https://example-store.com/products',
renderMode: 'basic',
schema: {
type: 'object',
properties: {
products: {
type: 'array',
items: {
type: 'object',
properties: {
name: { type: 'string', description: '제품명' },
price: { type: 'string', description: '표시된 제품 가격' },
rating: { type: 'number', description: '평균 고객 평점' },
},
required: ['name', 'price'],
},
},
},
required: ['products'],
},
}),
});
if (!response.ok) throw new Error(`Thunderbit API: ${response.status}`);
const result = await response.json();
console.log(result.data);
비교해 보면, fetch + Cheerio 열다섯 줄과 부서지기 쉬운 선택자 대신, 깔끔한 JSON을 돌려주는 API 호출 하나면 끝이에요. 배치 작업이라면 Thunderbit는 batch extract 호출 한 번에 최대 50개 URL, batch distill 호출로 최대 100개 URL까지 지원해요.
Thunderbit는 fetch를 대체하는 도구가 아니에요. fetch는 전송 수단이고, Thunderbit는 원시 HTML 파싱이 진짜 문제일 때 쓰는 추출 계층이에요. 가격이 궁금하면 무료 플랜에서 600 API 유닛으로 먼저 실험해 볼 수 있고, 유료 플랜은 월 6달러(약 8천 원)부터예요. 브라우저에서 바로 노코드 추출을 하고 싶다면 Thunderbit Chrome Extension도 확인해 보세요.
구조화된 스크래핑 접근법을 더 알고 싶다면 최고의 데이터 추출 도구, 웹 스크래퍼 만드는 법, 웹사이트 데이터를 엑셀로 스크래핑하기 가이드에서 구체적인 워크플로를 자세히 다뤄요.
빠른 참고: Node.js Fetch API 치트시트
이 섹션은 북마크해 두세요. 복붙할 패턴이 필요할 때 다시 오시면 돼요.
| 패턴 | 예시 코드 |
|---|---|
| 기본 GET | const res = await fetch(url); const data = await res.json(); |
| 기본 POST | await fetch(url, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(payload) }); |
| HTTP 오류 확인 | if (!res.ok) throw new Error(\\HTTP ${res.status}\); |
| 타임아웃(간단) | await fetch(url, { signal: AbortSignal.timeout(5000) }); |
| 수동 중단 | const c = new AbortController(); setTimeout(() => c.abort(), 5000); await fetch(url, { signal: c.signal }); |
| 재시도 대상 상태 코드 | 408, 429, 500, 502, 503, 504를 재시도하세요. POST를 무작정 재시도하지 마세요. |
| JSON 래퍼 | fetchJSON()으로 ok를 확인하고, content type을 파싱하고, HTTPError를 던지세요. |
| 연결 풀 | import { Pool } from 'undici'; const pool = new Pool(origin, { connections: 10 }); fetch(url, { dispatcher: pool }); |
| 스트림 청크 | const reader = res.body.getReader(); await reader.read()를 반복하세요 |
| 구조화 추출 | 웹페이지의 원시 HTML이 아니라 필드가 목표라면 Thunderbit Extract API를 사용하세요. |
결론과 핵심 요점
Node.js 기본 fetch는 2026년 기준 운영에 써도 돼요. 새 프로젝트에 node-fetch도, 습관적인 Axios 의존성도 필요 없어요. 다만 원시 fetch()만으론 운영용 HTTP 전략이 못 돼요.
대부분의 튜토리얼이 건너뛰는 다섯 가지, 그리고 이 글이 다룬 내용은 이래요.
- 오류 함정:
fetch()는 4xx/5xx에서 예외를 던지지 않아요. 항상response.ok를 확인하거나fetchJSON()같은 래퍼를 쓰세요. - 타임아웃: 간단한 경우엔
AbortSignal.timeout()을 쓰세요.AbortSignal.timeout()은TimeoutError를, 수동controller.abort()는AbortError를 던져요. - 재시도 로직: 내장돼 있지 않아요. 멱등 요청과 일시적 실패엔 지수 백오프를 더하세요. 기본 재시도가 필요하면 Ky를 쓰고요.
- 연결 재사용: 고처리량 루프에선 Undici의
Agent나Pool을dispatcher옵션으로 쓰세요. - 구조화 추출: 원시 HTML이 아니라 웹페이지에서 데이터를 얻어야 한다면, 부서지기 쉬운 CSS 선택자를 직접 관리하기보다 Thunderbit 같은 추출 API를 고려하세요.
한 문장으로 줄인 판단 기준은 이래요. 대부분의 프로젝트엔 기본 fetch, 인터셉터가 필요하면 Axios, 내장 재시도와 HTTP/2가 필요하면 Got, fetch 스타일에 더 나은 기본값이 필요하면 Ky, 그리고 fetch 기반 스크래핑 스크립트가 감당이 안 될 만큼 복잡해졌다면 Thunderbit API를 쓰세요.
구조화된 데이터 추출을 위해 Thunderbit 사용해 보기
이 글의 패턴을 직접 한번 돌려 보세요. Thunderbit가 구조화된 추출을 어떻게 처리하는지 보고 싶다면 무료 플랜에서 시작해도 좋고, Thunderbit YouTube 채널에서 워크스루를 봐도 돼요.
AI 웹 스크래핑을 위해 Thunderbit 사용해 보기 Get Started Free
자주 묻는 질문
1. fetch는 Node.js에 기본 포함되어 있나요, 아니면 설치해야 하나요?
fetch는 Node.js 18 이상에 기본 포함돼 있어서 설치가 필요 없어요. Node 21에서 안정화됐고, Node 22 LTS와 24 LTS에서 완전히 지원돼요. 더 오래된 Node에선 node-fetch 패키지를 쓸 수 있지만, 새 프로젝트는 관리되는 LTS를 대상으로 잡는 게 좋아요.
2. fetch는 404나 500 응답에서 오류를 던지나요?
아니요. fetch는 네트워크 레벨 실패(DNS 오류, 연결 없음, 요청 중단)에서만 promise를 reject해요. 404, 403, 500 같은 HTTP 응답은 response.ok === false인 상태로 정상 resolve돼요. 그래서 response.ok나 response.status를 직접 확인해야 하고, 이 글의 fetchJSON() 같은 래퍼를 써도 돼요.
3. Node.js에서 fetch에 타임아웃을 어떻게 추가하나요?
가장 간단한 길은 Node 18.11+에서 쓸 수 있는 AbortSignal.timeout(ms)예요. await fetch(url, { signal: AbortSignal.timeout(5000) })처럼 쓰면 돼요. 요청이 5초를 넘기면 TimeoutError가 나요. 더 세밀하게 제어하려면 AbortController를 직접 만들고 setTimeout에서 controller.abort()를 부르세요. 수동 패턴은 AbortError, AbortSignal.timeout()은 TimeoutError를 잡으면 돼요.
4. Node.js에서 웹 스크래핑에 fetch를 쓸 수 있나요?
네. 다만 fetch는 원시 HTML만 돌려줘요. 특정 요소를 뽑으려면 Cheerio 같은 파서가 필요하고, 페이지네이션, JavaScript 렌더링 페이지, 안티봇 대응용 커스텀 로직도 더해야 해요. 제품명, 가격, 연락처처럼 깔끔한 JSON이 필요한 대규모 구조화 추출이라면, CSS 선택자나 레이아웃 의존 코드 없이 AI가 구조화 데이터를 돌려주는 Thunderbit의 Extract API를 고려해 보세요.
5. 2026년에 Axios에서 기본 fetch로 바꿔야 하나요?
Node 22+의 새 프로젝트라면 기본 fetch가 강력한 기본 선택지예요. 의존성이 없고, Promise 기반이고, 브라우저 fetch와 같은 API를 공유해요. 요청/응답 인터셉터, 기본 HTTP 오류 거부, 더 오래된 Node와의 호환성이 필요하다면 Axios를 그대로 두세요. 둘 다 유효한 선택이고, 결정은 프로젝트가 실제로 쓰는 기능에 달렸어요.
더 알아보기




