
질 높은 세일즈 파이프라인을 직접 만들어 본 적이 있다면 이런 느낌, 아마 잘 아실 겁니다. 여기저기 흩어진 스프레드시트, 끝도 없이 늘어나는 탭, 그리고 수작업 리서치에 쏟아붓는 시간들. 마치 현대적인 세일즈를 하는 게 아니라 디지털 고고학을 하는 기분이죠. 사실 요즘 시장에서는 파이프라인이 힘없이 꺼지느냐, 아니면 진짜 성장을 만들어내느냐를 가르는 게 단순히 어떤 도구를 고르느냐가 아닙니다. 그 도구를 어떻게 쓰는지, 그리고 지금 우리가 실제로 판매하고 있는 환경에 맞게 프로세스 전체를 어떻게 설계했는지가 훨씬 더 중요합니다.
저는 SaaS와 자동화 분야에서 오래 일하면서, 리드 발굴 도구를 어떻게 쓰느냐에 따라 팀이 “간신히 버티는 수준”에서 “목표를 가볍게 뛰어넘는 팀”으로 바뀌는 장면을 여러 번 봐 왔습니다. 그런데 핵심은 새 기능이나 화려한 대시보드를 좇는 데 있지 않습니다. 전략, 데이터, 그리고 사람 냄새 나는 감각을 놓치지 않으면서 AI를 내 편으로 만드는 데 있습니다. 이제 전문가 팀과 그렇지 않은 팀을 가르는 5가지 베스트 프랙티스를 살펴보고, 에서는 이걸 어떻게 실천하는지, 또 왜 이게 세일즈와 오퍼레이션 팀의 게임 체인저가 되는지 보여드리겠습니다.
리드 발굴 도구를 다시 생각하기: 기능보다 전략이 먼저다
먼저 현실부터 짚어보겠습니다. 전체 리드 중 실제로 자격이 부여되는 비율은 약 . 즉, 처음부터 전략적으로 접근하지 않으면 대부분의 노력이 허공으로 날아간다는 뜻입니다.

너무 많은 팀이 리드 발굴 도구를 마치 마법 지팡이처럼 생각합니다. 도구만 사서 버튼 몇 번 누르면 결과가 뚝 떨어질 거라고 기대하는 거죠. 하지만 진짜 성과를 내는 팀은 도구를 비즈니스 목표, 고객 프로필, 데이터 전략에 맞게 설계합니다. 도구를 쓰기 전에 먼저 이런 질문부터 던져야 합니다.
- 우리의 이상적인 고객은 누구인가? (firmographic, technographic, intent signal 기준)
- 핵심 비즈니스 목표는 무엇인가? 볼륨, 품질, 속도, 아니면 그 조합인가?
- 데이터를 활용해 어떻게 리드를 세분화하고, 개인화하고, 추적할 것인가?
실제로 어떤 회사들은 기능을 더 얹어서가 아니라, 잠재고객 발굴 워크플로우를 ICP와 세일즈 퍼널에 맞춰 정렬한 것만으로 전환율을 3배까지 끌어올렸습니다(). 리드 발굴 도구는 릴레이 경주의 한 구간을 맡는 주자라고 생각하면 됩니다. 데이터와 전략이라는 배턴이 매 단계 매끄럽게 이어져야 제대로 힘을 발휘하죠().
프로 팁: Account-Based Marketing(ABM)이나 “세일즈 퍼널 릴레이” 같은 프레임워크를 활용해서, 내 도구가 더 큰 그림에서 어떤 역할을 하는지 먼저 그려보세요. 프로세스가 도구를 끌고 가게 두지 말고, 전략이 도구를 이끌게 해야 합니다.
리드 발굴 도구에서 기능 과잉보다 중요한 건 데이터 소스의 폭이다
솔직히 말하면, 리드 발굴 도구에서 진짜 중요한 건 기능 수가 아닙니다. 접근할 수 있는 데이터 소스의 폭과 품질이 훨씬 더 중요합니다. 화려한 기능 목록에 홀려서, 정작 중요한 곳에서 리드를 가져올 수 없다는 걸 뒤늦게 깨닫는 팀을 많이 봤습니다.
생각해보세요. 전통적인 도구들은 대개 ZoomInfo나 Apollo 같은 고정된 데이터베이스, 아니면 몇 개 안 되는 통합 기능에 기대는 경우가 많습니다. 타깃 고객이 늘 같은 곳에만 있다면 괜찮습니다. 하지만 다음 큰 고객이 niche 산업 블로그, 공개 디렉터리, 혹은 지난달 전시회 명단 PDF 속에 숨어 있다면 어떨까요?
바로 그 지점에서 가 강합니다. Thunderbit의 AI 웹 스크래퍼는 어떤 웹페이지, PDF, 심지어 이미지에서도 리드를 추출할 수 있습니다. 코딩도, 템플릿도 필요 없고, 클릭 두 번이면 됩니다. LinkedIn이든, Crunchbase든, 정부 조달 리스트든, 아니면 산업 포럼처럼 예측 불가능한 공간이든 Thunderbit는 이를 구조화된 실행 가능한 데이터로 바꿔줍니다().
도구를 평가할 때는 이런 질문을 던져보세요.
- 비정형이거나 덜 구조화된 사이트도 처리할 수 있는가?
- 필드를 자동으로 감지하고 구조화하는가, 아니면 새 소스마다 템플릿을 직접 만들어야 하는가?
- 새 데이터 소스를 찾은 뒤 CRM에 리드 리스트가 들어오기까지 얼마나 빠른가?
현실적으로 멀티채널 리드 소스에 만족하는 마케터는 절반 정도에 불과합니다(). 결국 성과를 내는 팀은 LinkedIn, 블로그, 디렉터리, 보도자료 등 다양한 소스를 함께 씁니다. 그리고 B2B 연락처 데이터는 업종에 따라 연간 사라질 수 있기 때문에, 리스트를 신선하고 풍부하게 유지해 줄 도구가 꼭 필요합니다.
Thunderbit로 리드 커버리지를 넓히는 실전 방법
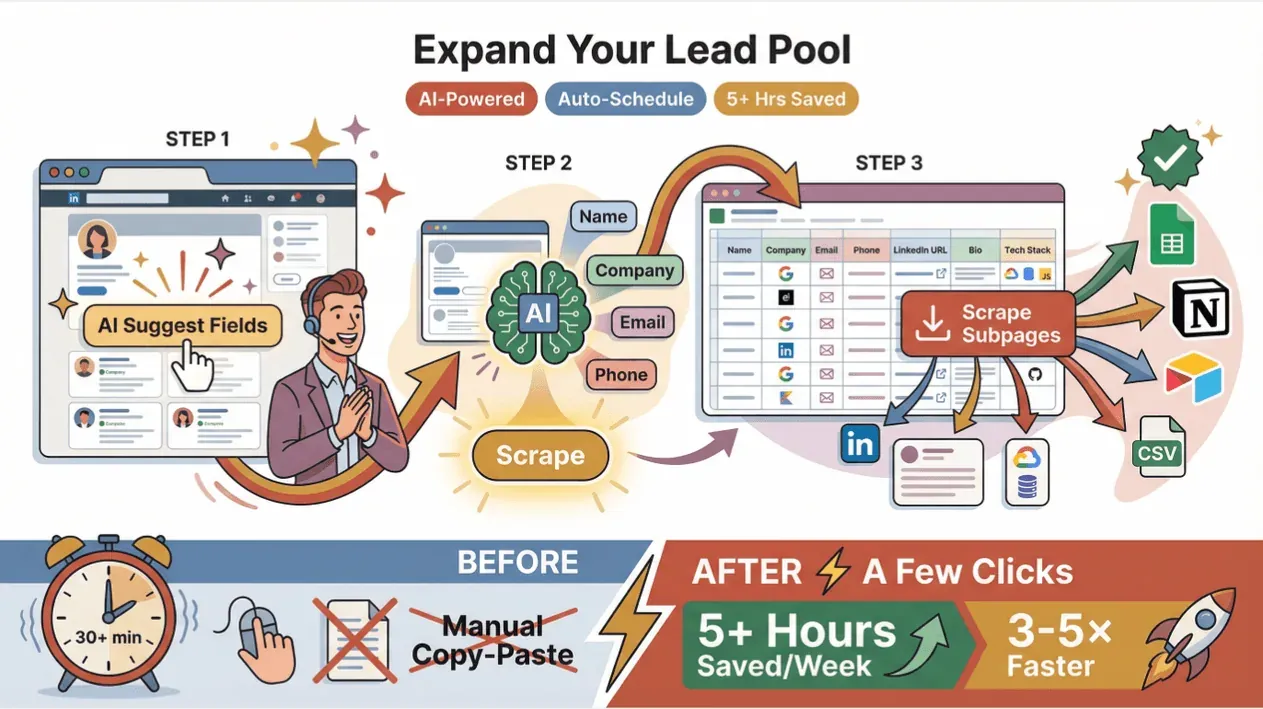
이제 실전으로 들어가 보겠습니다. Thunderbit가 리드 커버리지를 넓히고 팀 시간을 얼마나 아껴주는지 살펴보죠.
- 타깃 페이지를 엽니다. 디렉터리, LinkedIn 검색 결과, 블로그 등 무엇이든 괜찮습니다.
- **“AI Suggest Fields”**를 클릭합니다. Thunderbit의 AI가 페이지를 읽고 Name, Company, Email, Phone 같은 컬럼을 제안합니다.
- 필요하면 컬럼을 조정한 뒤 **“Scrape”**를 누릅니다. Thunderbit가 보이는 리드를 한 번에 표로 가져옵니다.
- 더 깊은 정보가 필요하면 **“Scrape Subpages”**를 클릭하세요. 각 프로필 링크를 방문해 LinkedIn URL, 소개, technographic 같은 추가 정보를 수집합니다.
- Google Sheets, Notion, Airtable, CSV로 바로 내보냅니다. 끝입니다.
이 워크플로우는 예전엔 30분 넘게 걸리던 복붙 작업을 몇 번의 클릭으로 바꿔줍니다. 사용자들은 주당 담당자 1인당 하고, 리드 풀을 이전보다 3~5배 빠르게 키웠다고 말합니다. 또 스케줄링 기능을 쓰면 목록을 자동으로 최신 상태로 유지할 수 있습니다().
실제 사례: SaaS 세일즈 담당자가 Crunchbase에서 벤더를 찾고, AI-Suggest로 이름과 직책을 뽑아낸 뒤, 서브페이지 스크래핑으로 회사 프로필에서 이메일과 전화번호를 가져옵니다. 결과는? 훨씬 더 풍부하고 바로 쓸 수 있는 리드 리스트가 짧은 시간에 완성됩니다.
사례 연구: LinkedIn과 산업 블로그를 하나의 리드 리스트로 통합하기
실제 사례를 하나 보겠습니다. 한 B2B 소프트웨어 고객사는 LinkedIn에서 얻는 임원급 리드와 산업 블로그에서 얻는 전문가 리드가 모두 필요했습니다. 이들은 이렇게 했습니다.
- Thunderbit로 LinkedIn 프로필을 스크래핑해 조직도와 이메일을 수집했습니다.
- 블로그 작성자 페이지와 댓글 목록도 스크래핑해 추가 연락처를 확보했습니다.
- 두 소스를 하나의 통합 리드 리스트로 합치고, 출처 태그를 붙였습니다.
결과는 어땠을까요? 블로그를 함께 분석하면서 추가로 25~40%의 고의도 연락처를 찾아냈습니다. 기존 데이터베이스에는 없던 리드였죠. 또 각 리드에 출처 태그가 붙어 있어서 아웃리치 메시지를 훨씬 더 정교하게 개인화할 수 있었습니다. 예를 들어 블로그 리드에게는 최근 글을 언급하는 식이었습니다.
이 접근법은 실제 성과로 이어졌습니다. 콘텐츠 마케팅은 이제 을 차지하고, . 여러 소스를 묶은 덕분에 팀은 더 깊은 인사이트를 얻었고, 오픈율과 응답률도 올라갔습니다. 맞춤형 이메일은 대략 을 보이며, 여러 필드를 활용한 개인화는 일반 대량 발송보다 훨씬 큰 차이를 만들어냅니다.
AI 기반 데이터 분석: 리드 발굴 도구를 더 똑똑하게 만드는 방법
리드를 모으는 것만으로는 충분하지 않습니다. 진짜 가치는 도구가 데이터를 분석하고, 정리하고, 보강해 주는 순간에 생깁니다. 그것도 자동으로 말이죠.
Thunderbit의 AI 기능은 단순 스크래핑을 훨씬 넘어섭니다.
- Field AI Prompts: “이 제품을 카테고리별로 분류해줘”, “날짜 형식을 맞춰줘”, “텍스트를 번역해줘” 같은 지시를 각 필드에 붙일 수 있습니다. Thunderbit는 데이터를 추출하는 동시에 라벨링, 포맷팅, 번역까지 처리합니다().
- 자동 필드 감지: 이메일, 전화번호, URL 등을 알아서 인식해 깔끔하게 정리합니다. 이상하게 포맷된 데이터를 손으로 다시 맞출 필요가 없습니다().
- 서브페이지 보강: LinkedIn URL, 소개, technographic 같은 숨은 정보를 메인 테이블로 끌어와, 모든 리드를 풍부하고 실행 가능한 상태로 만듭니다.
이건 단순히 시간을 아끼는 문제만은 아닙니다. 물론 시간도 크게 절약됩니다. 핵심은 데이터 품질입니다. AI 보강은 빠진 정보를 채우고, 오래된 데이터를 잡아내고, 진짜 개인화를 가능하게 합니다. 고급 보강 기능을 쓰는 팀은 예전엔 리드당 15~30분 걸리던 작업이 이제는 몇 초면 끝난다고 말합니다().
실전 팁: AI 프롬프트를 활용해 업종별로 리드를 세분화하거나, 출처를 태그하거나, 최근 활동을 요약해 보세요. 맥락이 많아질수록 아웃리치는 더 정교하고 효과적으로 바뀝니다.
리드 발굴 도구를 세일즈 워크플로우에 연결하기
아무리 좋은 리드 리스트라도 세일즈 프로세스로 자연스럽게 이어지지 않으면 무용지물입니다. 베스트 프랙티스는 뭘까요? 처음부터 리드 발굴 도구를 CRM과 다른 시스템에 연결하는 것입니다.
Thunderbit는 이걸 아주 쉽게 만들어 줍니다.
- Google Sheets, Airtable, Notion, Excel, CSV, JSON으로 바로 내보낼 수 있습니다().
- 각 리드에 출처와 날짜를 태그한 뒤 담당자나 육성 트랙에 배정할 수 있습니다.
- CRM 중복 제거 규칙을 활용해 같은 연락처에 두 번 연락하는 일을 피할 수 있습니다.
- 누락된 필드를 스크래핑해서 기존 CRM 레코드를 보강하고 다시 동기화할 수 있습니다.
프로 팁: 벤더나 가격처럼 자주 바뀌는 데이터는 정기적으로 다시 스크래핑하세요. 그리고 CRM에서 리드 응답 날짜를 추적해, 이미 식어버린 잠재고객을 계속 쫓지 않도록 하세요. 흐름을 얼마나 자동화하느냐에 따라 팀은 스프레드시트 정리에 시간을 쓰지 않고 실제 세일즈에 더 집중할 수 있습니다.
성과 측정하기: 리드 발굴 도구의 KPI
내 도구가 진짜 잘 작동하고 있는지 어떻게 알 수 있을까요? 올바른 KPI를 추적해야 합니다.
- 리드 품질: MQL→SQL 전환율, SQL→딜 전환율. 평균 딜 승률은 수준입니다.
- 효율성: 리드/미팅당 소요 시간, 자동화로 절약한 시간().
- 비용과 전환: Lead당 비용(CPL), 고객획득비용(CAC), 파이프라인 커버리지.
- 퍼널 건강도: 퍼널 누수 여부를 확인하세요. 스크래핑한 리스트는 큰데 SQL로 이어지는 비율이 낮다면, 자격 판단 기준이나 메시지를 손봐야 합니다.
KPI는 출처와 캠페인별로 나눠서 보세요. 잘 되는 부분은 더 밀고, 안 되는 부분은 줄이고, 계속 개선해야 합니다. 리드 생성에 우선순위를 두는 회사는 경쟁사보다 이 높습니다.
리드 발굴 도구를 사용할 때 흔히 빠지는 함정
아무리 좋은 도구라도 잘못된 프로세스까지 구해주진 못합니다. 아래 함정을 조심하세요.
- 자동화 의존 과다: 무작정 일반 발송을 하지 마세요. 개인화는 정말 중요합니다. 구매자의 76%는 비개인화된 아웃리치에 불만을 느낍니다().
- 데이터 품질 무시: 데이터를 항상 검증하고 정리하세요. . 이탈이 잦은 업종일수록 더 빠릅니다.
- 개인화 소홀: 보강된 데이터를 활용해 더 구체적인 메시지를 만드세요. 2026 벤치마크 기준 맞춤형 아웃리치는 응답률을 높이며, 여러 필드를 활용한 개인화는 그 효과를 더 키웁니다.
- 도구만 믿기: 도구가 전략을 대신해주진 않습니다. 스크래핑 기준은 반드시 ICP나 캠페인 목표에 맞춰야 합니다.
- CRM 관리 부실: 리드를 태그하고, 품질을 기록하고, 다음 액션을 남기세요. CRM이 지저분하면 파이프라인도 지저분해집니다.
- 일회성 접근: 리드 발굴은 한 번 하고 끝내는 작업이 아닙니다. 매일의 습관이어야 합니다. 리드 수집과 데이터 갱신을 정기 루틴에 넣으세요.
결론: 지속 가능한 리드 발굴 엔진 만들기
리드 발굴 도구를 제대로 다루는 5가지 베스트 프랙티스를 다시 정리해보겠습니다.
- 전략부터 시작하기: 도구를 비즈니스 목표와 ICP에 맞추세요.
- 데이터 소스의 폭을 우선하기: 기능 과잉보다 풍부하고 다양한 데이터 접근성을 갖춘 도구를 고르세요.
- AI로 보강하기: AI를 활용해 데이터를 정리하고, 라벨링하고, 보강해 더 똑똑한 아웃리치를 만드세요.
- 워크플로우에 통합하기: 리드가 CRM과 세일즈 스택으로 자연스럽게 흘러가도록 연결하세요.
- 측정하고 개선하기: KPI를 추적하고, 흔한 함정을 피하며, 프로세스를 계속 다듬으세요.
그 결과는 무엇일까요? 파이프라인을 고가치 잠재고객으로 채우고 안정적인 매출 성장을 이끄는, 스스로 돌아가는 리드 엔진입니다. Thunderbit는 이걸 단순히 가능하게 만드는 수준이 아니라, 코드 한 줄 없는 팀도 쉽게 쓸 수 있게 만드는 데 집중하고 있습니다.
리드 발굴을 한 단계 끌어올릴 준비가 되셨나요? 하고, “리드를 어디서 찾지?”에서 “여기 제 다음 대형 딜입니다”로 얼마나 빨리 바뀌는지 직접 확인해 보세요. 더 깊이 알아보고 싶다면 에서 더 많은 가이드, 팁, 실제 성공 사례를 만나보실 수 있습니다.
FAQ
1. 리드 발굴 도구를 사용할 때 팀이 가장 흔히 저지르는 실수는 무엇인가요?
가장 흔한 실수는 도구를 만능 해결책처럼 보는 것입니다. 기능보다 비즈니스 목표와 고객 프로필에 맞추는 게 우선입니다. 항상 전략부터 세우고, 그에 맞는 도구를 고르세요.
2. Thunderbit는 기존 리드 발굴 도구와 어떻게 다른가요?
Thunderbit는 AI를 사용해 웹페이지, PDF, 이미지 어디서든 리드를 추출합니다. 코딩이나 템플릿이 필요 없고, 복잡하거나 비정형적인 소스도 처리할 수 있습니다. 또한 데이터 정리, 보강, 내보내기까지 자동화해 자주 쓰는 플랫폼으로 바로 연결해 줍니다.
3. 데이터 소스 다양성이 왜 그렇게 중요한가요?
하나의 데이터베이스나 채널에만 의존하면 niche 블로그, 디렉터리, 비정형 소스에 숨어 있는 고가치 리드를 놓치게 됩니다. 여러 데이터 소스를 섞을수록 더 풍부하고 정확한 리드 풀을 만들 수 있습니다.
4. 리드 데이터를 최신 상태로 정확하게 유지하려면 어떻게 해야 하나요?
정기적으로 다시 스크래핑하고, AI 보강으로 누락 정보를 채우고, 이메일과 전화번호는 항상 검증하세요. B2B 데이터는 빨리 낡기 때문에 자동화가 목록을 최신으로 유지하는 데 큰 도움이 됩니다.
5. 리드 발굴 성과를 측정하려면 어떤 KPI를 봐야 하나요?
리드 품질(MQL→SQL, SQL→딜 전환율), 효율성(절약한 시간, 리드당 비용), 퍼널 건강도(전환율, 누수), 통합 수준(리드가 세일즈 프로세스로 얼마나 매끄럽게 흘러가는지)에 집중하세요. 무엇이 효과적인지 정기적으로 점검하고 조정해야 합니다.
더 알아보기