

"웹사이트에서 데이터를 스크래핑해도 법적으로 괜찮나요?" 영업, 운영, 마케팅팀에서 거의 매주 받는 질문이에요. 웹 스크래핑이 리드 발굴부터 경쟁사 분석까지 두루 쓰이다 보니, 다들 확실한 답을 찾고 싶어 하죠. 그런데 현실은 그리 깔끔하지 않아요. 딱 떨어지는 단일 기준이 없거든요. 한쪽에선 공개 데이터 스크래핑은 괜찮다고 하고, 다른 쪽에선 "불법 데이터 수집"이라며 경고해요. 그러니 많은 팀이 법적 리스크를 걱정하는 것도 당연해요.
실제로 전체 조직의 3분의 2 이상이 웹 스크래핑을 데이터 분석이나 AI 프로젝트에 쓰고 있어요. 이커머스 기업의 78%는 가격 정보 수집에 스크래핑을 활용하고요. 하지만 LinkedIn과 hiQ Labs 소송처럼 굵직한 분쟁이 터지면서, 법적 리스크도 같이 커졌어요. 그렇다면 웹 데이터를 안전하게 쓰려면 어떻게 해야 할까요? 핵심 법적 프레임워크, 준수 체크리스트, 실무 팁을 정리해 드릴게요. 그리고 Thunderbit가 합법적 스크래핑을 어떻게 쉽게 만들어 주는지도 함께 소개해요.
법적 환경 이해하기: 웹사이트 데이터 스크래핑, 합법일까요?
웹 스크래핑의 법적 쟁점 웹 스크래핑의 법적 이슈와 준수 방법을 자세히 알아보세요. Get Started Free
핵심만 말하면, 웹 스크래핑의 합법성은 무엇을, 어떻게, 어디서 스크래핑하느냐에 달려 있어요. "스크래핑은 합법" 혹은 "불법"이라고 단번에 가를 단일 법은 없어요. 대신 해킹 방지법, 개인정보 보호법, 저작권법, 각 사이트 이용약관 등 여러 규정이 얽혀 있어요 (Thunderbit Blog).
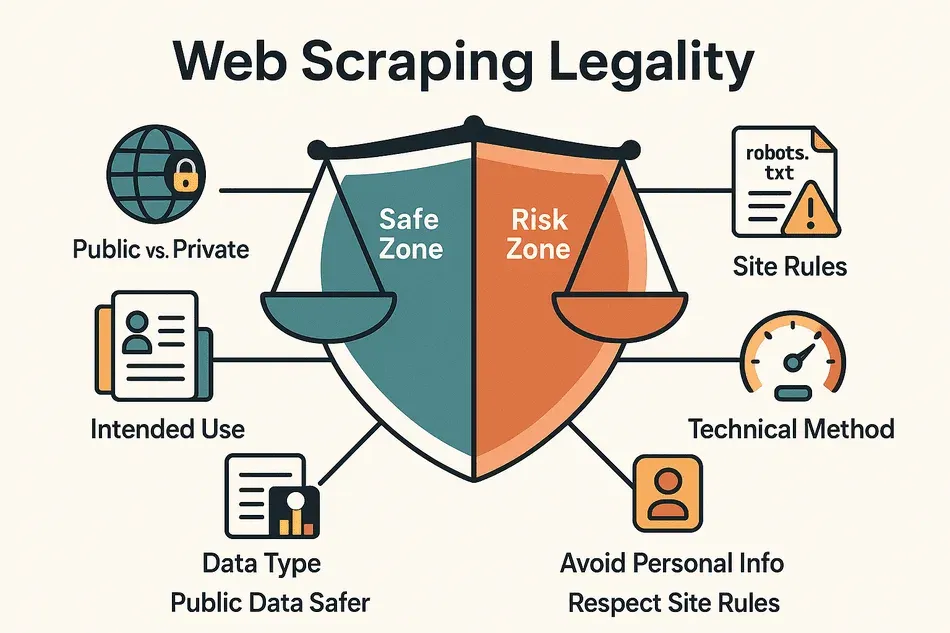
합법 여부를 가르는 주요 포인트는 이래요.
- 공개 vs. 비공개 데이터: 누구나 볼 수 있는 데이터(로그인·결제 없이 접근 가능)는 비교적 안전해요. 로그인이나 결제가 필요한 영역을 긁으면 불법 소지가 커져요.
- 데이터 종류: 이름, 이메일, 소셜 프로필 같은 개인정보나 저작권 콘텐츠(기사, 이미지 등)는 위험도가 높아요. 가격, 제품 정보, 업체 리스트 같은 사실 정보는 상대적으로 안전해요.
- 활용 목적: 내부 분석이나 연구용이면 리스크가 낮지만, 데이터를 재배포하거나 팔면 위험이 커져요.
- 사이트 규정 준수: 이용약관이나 robots.txt를 무시하면, 공개 데이터라도 문제가 될 수 있어요.
- 기술적 접근 방식: 사람처럼 천천히 접근하고, 보안장치(CAPTCHA, IP 차단 등)는 우회하지 않는 게 중요해요.
 (https://strapi.thunderbit.com/uploads/webscrapinglegalitysafevsriskzones_6ee3935a34.png)
정리하면, 공개되고 비개인적인 데이터를 내부 용도로 쓰는 건 많은 지역에서 허용되는 편이에요. 다만 개인정보, 저작권, 과도한 스크래핑에는 각별히 조심해야 해요 (Thunderbit Blog).
(https://strapi.thunderbit.com/uploads/webscrapinglegalitysafevsriskzones_6ee3935a34.png)
정리하면, 공개되고 비개인적인 데이터를 내부 용도로 쓰는 건 많은 지역에서 허용되는 편이에요. 다만 개인정보, 저작권, 과도한 스크래핑에는 각별히 조심해야 해요 (Thunderbit Blog).
데이터 스크래핑 법적 프레임워크: 주요 국가별 규정 한눈에 보기
 주요 국가의 웹 스크래핑 관련 법을 간단히 짚어 볼게요.
주요 국가의 웹 스크래핑 관련 법을 간단히 짚어 볼게요.
미국: CFAA, 저작권, 계약법
- 컴퓨터 사기·남용 방지법(CFAA): 무단 접근을 막는 해킹 방지법이에요. 그런데 법원은 공개 웹사이트 스크래핑은 CFAA 위반이 아니라고 봤어요 (California Lawyers Association).
- 주요 판례: hiQ Labs v. LinkedIn 사건에서 공개 LinkedIn 프로필 스크래핑은 CFAA 위반이 아니라는 판결이 나왔어요. 단, LinkedIn은 약관 위반이나 저작권 침해로 따로 소송을 걸 수 있어요.
- 기타 리스크: eBay v. Bidder's Edge처럼 과도한 요청(하루 10만 건)으로 서버에 피해를 주면 "trespass to chattels(타인 자산 침해)"로 제재받을 수 있어요 (Wikipedia).
유럽연합: 개인정보보호법(PIPA)에 해당하는 GDPR, 데이터베이스 권리
- GDPR: 공개된 개인정보라도 GDPR이 적용돼요. 국내 개인정보보호법(PIPA)과 마찬가지로, 개인을 식별할 정보를 모으려면 합법적 근거(동의, 정당한 이익 등)와 엄격한 보호 조치가 필요해요.
- 데이터베이스 지침: EU는 데이터베이스 전체도 보호해요. 부동산 사이트의 전체 매물처럼 "실질적 부분"을 긁으면 데이터베이스 권리 침해가 될 수 있어요 (Thunderbit Blog).
영국: UK GDPR, 데이터 보호법
- UK GDPR: 브렉시트 이후에도 EU와 비슷한 규정이 적용돼요. 공개되고 비개인적인 데이터는 비교적 자유롭지만, 개인정보는 엄격히 규제돼요.
- 컴퓨터 오용법: 무단 접근 시 형사 처벌 대상이 될 수 있어요.
중국: PIPL, 데이터 보안법
- 개인정보 보호법(PIPL): 개인정보를 모으려면 동의가 필수예요. 동의 없이 중국 내 개인정보를 긁으면 위법이에요.
- 데이터 보안법: 데이터 소유자에게 피해를 주거나 불공정 경쟁을 부르는 스크래핑을 단속해요.
기타 지역
- 캐나다, 호주, 아시아: 대부분 EU/UK와 비슷한 해킹 방지법과 개인정보 보호법을 둬요. 진행 전에 꼭 현지 법을 확인하세요.
핵심 요약: 공개되고 비개인적인 데이터를 내부 용도로만 쓰고, 지역별 규정을 반드시 확인하세요 (Thunderbit Blog).
합법적 데이터 스크래핑을 위한 체크리스트
스크래핑을 시작하기 전, 아래 항목을 꼭 확인하세요.
- 사이트 이용약관 확인: 약관에 "스크래핑 금지"가 적혀 있다면 멈추거나 사전 허가를 받으세요 (Thunderbit Blog).
- 공개 데이터만 수집: 로그인이나 결제가 필요한 영역은 명확한 허가 없이는 피하세요.
- robots.txt 확인:
site.com/robots.txt에서 봇 접근이 막힌 영역이 있는지 보세요. 법적 강제력은 없지만, 예의를 지키는 편이 좋아요. - 개인정보 수집 자제: 이름, 이메일 같은 개인정보는 합법적 근거와 보호 계획이 있을 때만 모으세요.
- 창작물 복제 금지: 기사, 이미지 같은 창작물은 복제하지 말고 사실 정보만 모으세요.
- 공식 API 우선: 공식 API가 있다면 그걸 먼저 쓰세요.
- 서버에 부담 주지 않기: 사람처럼 천천히 접근하고, 보안장치 우회는 피하세요.
- 과정 기록: 언제, 무엇을, 왜 스크래핑했는지 기록을 남기세요.
- 중단 요청 시 즉시 중단: 중단 요청(cease-and-desist letter)을 받으면 곧바로 멈추고 다시 검토하세요.
Thunderbit의 합법적 스크래핑 원칙: 안전하고 믿을 수 있는 데이터 추출
Thunderbit는 처음부터 준수를 최우선에 두고 설계했어요. Thunderbit가 법적 리스크를 줄여 주는 방식은 이래요.
- 브라우저 기반 스크래핑: Thunderbit는 브라우저에 보이는 정보만 가져와요. 숨은 API 호출이나 로그인 우회는 하지 않아요. 사용자가 못 보는 정보는 Thunderbit도 긁지 않아요 (Thunderbit Blog).
- 내장 경고 기능: 스크래핑이 강하게 금지된 사이트에서는 경고 메시지를 띄워요. 준수 담당자가 옆에서 귀띔해 주는 느낌이죠.
- AI 필드 추천: Thunderbit의 AI가 페이지를 살펴 민감하지 않은 필드만 추천해요. 불필요한 개인정보 수집을 막아 줘요 (Thunderbit Blog).
- 사람과 비슷한 속도: 로컬이든 클라우드든, Thunderbit는 서버에 부담을 안 주도록 속도를 조절해요.
- 데이터 미보관: 추출한 데이터는 사용자에게 바로 가고, Thunderbit 서버에는 저장되지 않아요. 개인정보 보호에 유리해요.
- 준수 친화적 내보내기: Google Sheets, Excel, Airtable, Notion 등으로 바로 내보낼 수 있어 내부 활용에 잘 맞아요.
- 하위 페이지·페이지네이션 지원: 실제 사용자가 사이트를 둘러보듯, 페이지와 하위 페이지를 자연스럽게 오가요.
- 책임 있는 예약 스크래핑: 예약 스크래핑에서도 간격을 적절히 띄워 사이트에 과부하를 주지 않아요.
- 다국어 지원: Thunderbit는 34개 언어를 지원해서, 전 세계 어디서든 준수 가이드를 쉽게 볼 수 있어요.
다시 말해 Thunderbit는 "준수 원칙을 제품에 내장"해서, 법률 전문가가 아니어도 책임감 있게 스크래핑하도록 안내해요 (Thunderbit Blog).
데이터 스크래핑 vs. 데이터 재사용: 법적 경계는 어디까지?
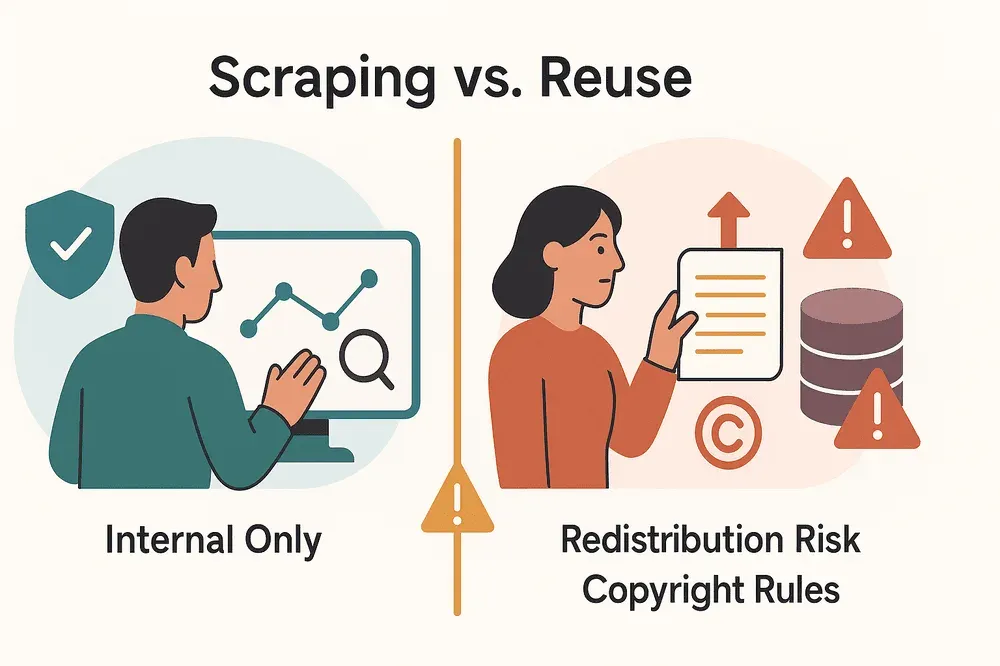 내부 분석용으로 데이터를 모으는 것과, 그 데이터를 밖에 재배포하거나 파는 건 완전히 달라요. 법적 경계가 또렷해지는 지점은 이래요.
내부 분석용으로 데이터를 모으는 것과, 그 데이터를 밖에 재배포하거나 파는 건 완전히 달라요. 법적 경계가 또렷해지는 지점은 이래요.
- 내부 활용: 공개 데이터를 내부 분석(영업 리드, 가격 모니터링 등)에만 쓰면, 개인정보나 프라이버시 침해가 없는 한 비교적 안전해요.
- 재배포·재판매: 스크래핑한 데이터를 웹사이트, 제품, 판매용으로 다시 쓰면 저작권, 데이터베이스 권리, 계약 위반 문제가 생길 수 있어요.
- 저작권·데이터베이스 권리: 미국에선 사실 정보 자체는 저작권 대상이 아니지만, 데이터를 배열하거나 선별한 방식은 보호받을 수 있어요. EU/UK에선 데이터베이스의 "실질적 부분"을 긁으면 별도 권리 침해가 될 수 있어요.
- 공정 이용: 미국법상 일부 분석·비평 목적의 "공정 이용"은 허용되지만, 대량 복사·붙여넣기는 거의 인정 안 돼요.
- 출처 표기: 데이터를 밖에 공개할 땐 출처를 꼭 밝히세요. 다만 출처 표기만으로 법적 문제가 다 풀리는 건 아니에요.
- 원본 데이터 판매 금지: 가공 없이 긁은 데이터셋을 파는 건 특히 위험해요. 데이터는 인사이트를 뽑는 데 쓰고, 그 자체를 상품으로 팔지 마세요.
실무 팁: 스크래핑 데이터는 내부 의사결정과 인사이트 도출에만 쓰세요. 밖에 공유해야 한다면 집계·가공한 뒤, 허가 여부를 반드시 확인하세요 (Thunderbit Blog).
업계 사례로 보는 법적 리스크 관리법
실제 사례로 무엇을 조심해야 하는지 살펴볼게요.
LinkedIn vs. hiQ Labs
- 사건 개요: hiQ Labs는 공개 LinkedIn 프로필을 긁어 직원 이직 분석 서비스를 제공했어요. LinkedIn이 차단을 시도했지만, 법원은 공개 데이터 스크래핑은 CFAA 위반이 아니라고 판결했어요.
- 교훈: 미국에선 공개 데이터 스크래핑이 법적으로 인정될 수 있지만, 약관 위반·프라이버시 침해는 별개 리스크예요 (California Lawyers Association).
eBay vs. Bidder's Edge
- 사건 개요: Bidder's Edge는 eBay 경매 매물을 하루 10만 건 넘게 과도하게 긁어 약관과 robots.txt를 어겼어요. 법원은 "자산 침해"를 이유로 금지 명령을 내렸어요.
- 교훈: 공개 데이터라도 과도한 접근이나 명시적 규정 위반은 불법이 될 수 있어요 (Wikipedia).
Facebook (Meta) vs. Power Ventures
- 사건 개요: Power Ventures는 사용자 동의로 Facebook 데이터를 긁었지만, Facebook이 접근을 막은 뒤에도 계속 시도해 "무단 접근" 판결을 받았어요.
- 교훈: 사이트 운영자가 중단을 요청하면 곧바로 멈춰야 해요. 계속하면 해킹 방지법 위반이 될 수 있어요.
준수 성공 사례
EU의 가격 비교 사이트들은 사실 정보만 모으고, opt-out을 존중하고, 데이터베이스 전체를 긁지 않아 법적 분쟁 없이 운영하고 있어요. 공개되고 비개인적인 데이터만, 사이트 규정을 지키며 모으는 게 안전해요.
Thunderbit의 역할
Thunderbit의 내장 경고, 속도 제한, 브라우저 기반 방식은 이런 법적 실수를 막는 데 큰 도움이 돼요. 위험 사이트 경고와 예의 바른 스크래핑이 기본값이에요.
비즈니스 실무자를 위한 데이터 스크래핑 준수 셀프 체크리스트
다음 프로젝트에서 아래 항목을 스스로 점검해 보세요.
- 데이터가 공개되어 있나요? (로그인 불필요)
- 사이트 약관에 스크래핑 금지 조항이 있나요?
- robots.txt를 확인했나요? (대상 영역이 막혀 있나요?)
- 개인정보를 모으나요? (모은다면 프라이버시 계획이 있나요?)
- 사이트의 대량 데이터를 모으나요? (데이터베이스 전체 스크래핑은 피하세요)
- 활용 목적이 무엇인가요? (내부용 = 안전, 외부 재사용 = 위험)
- 스크래핑 속도가 적절한가요? (사람처럼, 기술적 우회 없이)
- 공식 API가 있나요? (있으면 API 우선)
- 중단 요청 시 곧바로 멈출 준비가 됐나요?
- 데이터 저장·보안 계획이 있나요? (접근 제한, 프라이버시 보호)
- 과정 기록을 남기고 있나요? (준수 증빙용)
위 항목에 "아니오"가 있거나 확신이 안 선다면, 진행 전에 추가 확인이 꼭 필요해요 (Thunderbit Blog).
Thunderbit 사용자를 위한 합법적 데이터 스크래핑 워크플로우 예시
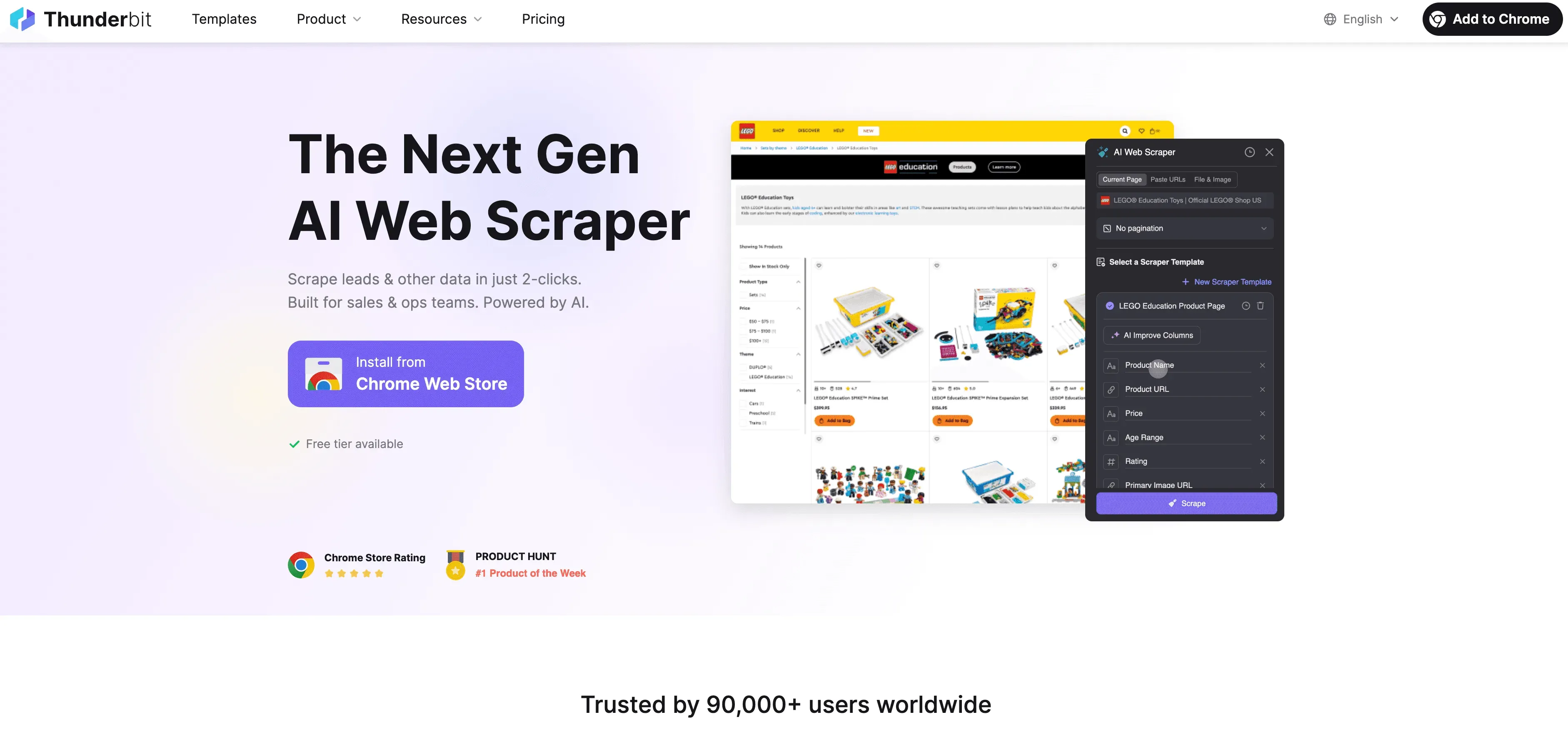 Thunderbit로 준수 중심 스크래핑을 진행하는 전형적인 흐름은 이래요.
Thunderbit로 준수 중심 스크래핑을 진행하는 전형적인 흐름은 이래요.
- 사전 점검: 사이트의 robots.txt와 이용약관을 확인하세요. 스크래핑 금지 조항이 없으면 진행해도 돼요.
- Thunderbit 실행: 대상 페이지에 접속해 Thunderbit Chrome 확장 프로그램을 실행하세요.
- AI 필드 추천: Thunderbit의 AI가 관련성 높고 민감하지 않은 필드를 추천해요. 개인정보가 섞여 있다면 합법적 근거가 있는지 다시 확인하세요.
- 필드 커스터마이즈: 필요한 컬럼과 데이터 유형만 골라, 꼭 필요한 정보만 모으세요.
- 스크래핑: "스크래핑" 버튼을 클릭하세요. Thunderbit가 사이트 구조를 존중하며 사람처럼 데이터를 가져와요.
- 하위 페이지 스크래핑: 필요하면 하위 페이지 기능으로 공개 정보만 더 모으세요.
- 내보내기: 데이터를 Google Sheets, Excel, Airtable, Notion 등으로 바로 내보내 내부 분석에 쓰세요.
- 예약(선택): 예약 스크래핑에서도 간격을 적절히 잡으세요.
- 기록: 언제, 무엇을, 왜 스크래핑했는지 기록을 남기세요.
Thunderbit는 단계마다 준수 안내를 띄워 줘서, 실수 없이 진행할 수 있어요.
결론 & 핵심 실무 팁: 안전하고 합법적으로 데이터 활용하기
웹 스크래핑은 비즈니스 성장에 강력한 도구지만, 막무가내로 덤비면 안 돼요. 법적 환경은 복잡해도 핵심 원칙은 분명해요.
- 공개되고 비개인적인 데이터만 내부 용도로 쓰세요.
- 스크래핑 전에 사이트 약관, robots.txt, 관련 법을 꼭 확인하세요.
- 개인정보나 창작물은 합법적 근거와 프라이버시 계획 없이 모으지 마세요.
- Thunderbit 같은 준수 친화적 도구로 리스크를 최소화하세요.
- 과정 기록을 남기고, 중단 요청을 받으면 곧바로 멈추세요.
준수를 습관으로 만들면, 법적 리스크 없이 웹 데이터의 가치를 최대한 끌어낼 수 있어요. 합법적 스크래핑이 얼마나 쉬운지 직접 겪어 보고 싶다면 Thunderbit를 사용해 보세요. 법무팀도, 미래의 나도 만족할 선택이에요.
웹 스크래핑, 준수, 자동화에 관한 더 깊은 인사이트는 Thunderbit 블로그에서 확인하세요.
AI 웹 스크래퍼로 합법적 데이터 추출 시작하기 Get Started Free
자주 묻는 질문(FAQ)
1. 모든 웹사이트에서 데이터 스크래핑이 합법인가요?
늘 그렇진 않아요. 공개되고 비개인적인 데이터를 내부 용도로 모으는 건 많은 지역에서 허용되지만, 개인정보, 저작권 콘텐츠, 로그인 뒤 데이터는 위험하거나 불법일 수 있어요. 사이트 약관과 현지 법을 꼭 확인하세요 (Thunderbit Blog).
2. 스크래핑과 데이터 재사용은 어떻게 다른가요?
스크래핑은 데이터를 모으는 행위이고, 재사용은 그 데이터를 공개·판매·배포하는 거예요. 내부 활용은 비교적 안전하지만, 외부 공개나 판매는 저작권, 데이터베이스 권리, 계약 위반 문제를 부를 수 있어요 (Thunderbit Blog).
3. Thunderbit는 준수를 어떻게 돕나요?
Thunderbit는 브라우저에 보이는 정보만 가져오고, 위험 사이트 경고, 민감하지 않은 필드 추천, 서버 과부하 방지 같은 준수 기능을 갖추고 있어요. 데이터는 서버에 저장하지 않고, 내보내기 옵션도 내부 활용에 맞게 최적화돼 있어요 (Thunderbit Blog).
4. 중단 요청(cease-and-desist letter)을 받으면 어떻게 하나요?
곧바로 스크래핑을 멈추고 프로젝트를 다시 검토하세요. 중단 요청을 받고도 계속하면, 법적 회색지대가 명백한 위반으로 바뀔 수 있어요 (Thunderbit Blog).
5. 공개된 개인정보도 스크래핑할 수 있나요?
합법적 근거 없이는 안 돼요. GDPR, CCPA 같은 프라이버시 법은 공개된 개인정보에도 적용돼요. 동의나 정당한 이익 같은 명확한 근거와 책임 있는 데이터 관리가 필요해요 (Thunderbit Blog).
이 가이드는 정보 제공용이며, 법적 자문이 아니에요. 복잡하거나 중요한 프로젝트라면 해당 국가의 데이터·프라이버시 전문 변호사와 꼭 상담하세요.
더 읽어보기




