
웹은 정말 상상 이상으로 빠르게 커지고 있어요. 2024년 기준으로 11억 개가 넘는 웹사이트와 149제타바이트라는 어마어마한 데이터가 쌓여 있고, 내년엔 181 ZB까지 늘어날 거라는 전망이 있어요. 그야말로 정보의 홍수죠. 그런데 흥미로운 건, 온라인 콘텐츠의 4% 정도만 검색 엔진에 색인화되어 있다는 점이에요. 나머지는 평소엔 검색이 닿지 않는 ‘딥웹’에 잠겨 있고요. 그렇다면 검색 엔진이나 기업들은 이 거대한 디지털 세상을 어떻게 이해하고 있을까요? 그 비밀이 바로 웹 크롤러예요.
이번 글에서는 웹 크롤링이 뭔지, 어떻게 동작하는지, 왜 중요한지를 가볍게 풀어 볼게요. IT 전문가뿐 아니라, 온라인 데이터를 비즈니스에 활용해 보고 싶은 분이라면 누구에게나 도움이 될 거예요. 웹 크롤링과 웹 스크래핑의 차이(둘은 분명히 달라요)부터 실제 활용 사례, 직접 코딩하는 방법, 그리고 노코드 솔루션(저희 Thunderbit도 빼놓을 수 없죠)까지 함께 살펴봐요. 이제 막 웹 데이터에 관심을 가진 분이든, 이미 비즈니스에서 활용 중인 분이든 편하게 읽어 보시면 좋을 것 같아요.
웹 크롤러란? 웹 크롤링의 기본 개념
먼저, 웹 크롤러(스파이더, 봇, 웹사이트 크롤러 같은 이름으로도 불려요)는 자동으로 웹을 돌아다니면서 페이지를 수집하고, 링크를 따라가며 새 콘텐츠를 찾아 주는 프로그램이에요. 마치 로봇 사서가 책 목록(즉, URL)에서 출발해 한 권씩 읽어 보고, 참고문헌을 따라 더 많은 책을 찾아 나가는 모습이라고 보면 이해가 빨라요. 여기서 책은 웹페이지, 도서관은 인터넷 전체라고 생각하면 돼요.
핵심 원리는 이래요.
- **URL 목록(시드)**에서 출발
- 각 페이지를 방문해 콘텐츠(HTML, 이미지 등)를 다운로드
- 페이지 안의 하이퍼링크를 찾아 큐에 추가
- 반복—새 링크를 따라가면서 더 많은 페이지를 탐색
웹 크롤러의 핵심 역할은 페이지를 찾아내고 정리하는 일이에요. 검색 엔진에서는 크롤러가 페이지 내용을 복사해 색인화와 분석을 위해 서버로 보내요. 이 외에도 특정 데이터만 콕 집어 뽑아내는 특화 크롤러가 있는데, 이게 바로 웹 스크래핑과 맞닿아 있어요(자세한 내용은 아래에서 이어 갈게요).
핵심 요약:
웹 크롤링은 웹을 탐색하고 지도로 그리는 과정이에요. 단순히 데이터를 긁어오는 게 아니라, 구글이나 Bing 같은 검색 엔진이 인터넷을 이해하기 위해 꼭 필요한 기술이거든요.
검색 엔진은 어떻게 작동할까? 크롤러의 역할
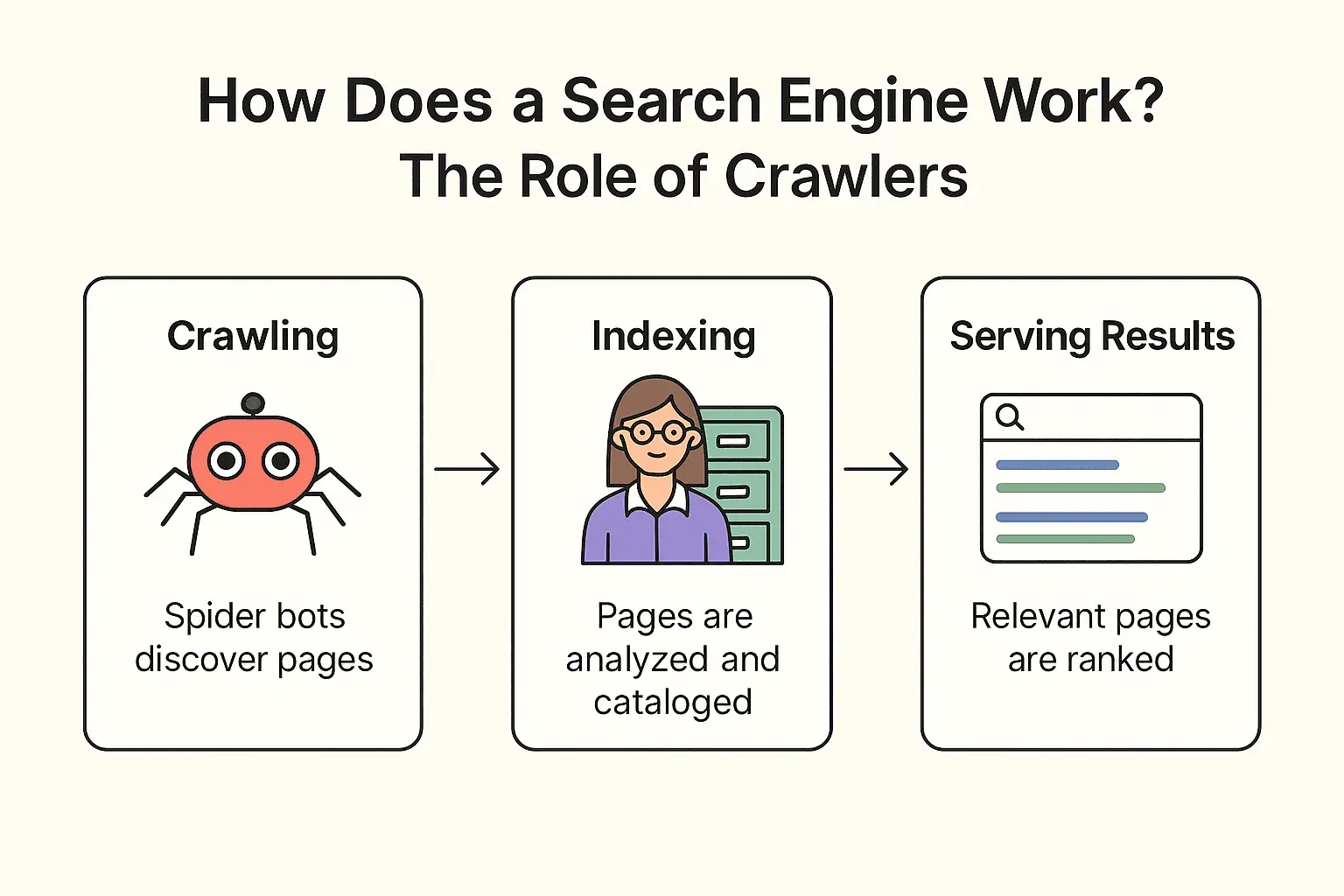
구글, Bing, DuckDuckGo 같은 검색 엔진은 어떻게 돌아갈까요? 크게 크롤링, 색인화, 검색 결과 제공 세 단계로 나눌 수 있어요(Google 공식 문서 참고).
도서관에 비유해서 풀어 볼게요.
-
크롤링:
검색 엔진은 ‘스파이더 봇’(예: Googlebot)을 웹에 보내 탐색을 시작해요. 이미 알려진 페이지에서 출발해서 내용을 가져오고, 링크를 따라가며 새 페이지를 발견하죠. 사서가 책장을 훑고, 각 책의 참고문헌을 따라 더 많은 책을 찾아 나가는 그림이라고 보면 돼요.
-
색인화:
발견한 페이지는 검색 엔진이 내용을 분석해 어떤 주제인지 파악하고, 중요한 정보를 거대한 디지털 카드 카탈로그(색인)에 차곡차곡 넣어요. 모든 페이지가 색인되는 건 아니고, 차단됐거나 품질이 낮거나 중복인 페이지는 빠지기도 하고요.
-
검색 결과 제공:
사용자가 “내 주변 최고의 피자”라고 검색하면, 검색 엔진은 색인에서 관련 페이지를 찾아 수백 가지 요소(키워드, 인기도, 최신성 등)를 기준으로 순위를 매겨요. 그 결과로 정돈된 웹페이지 목록이 화면에 뜨는 거죠.
알아두면 좋은 점:
검색 엔진이 웹의 모든 페이지를 크롤링하는 건 아니에요. 로그인 뒤에 있거나, robots.txt로 막혀 있거나, 외부 링크가 하나도 없는 페이지는 아예 발견되지 않을 수도 있거든요. 그래서 기업들이 직접 URL이나 사이트맵을 구글에 제출하는 경우도 많아요.
웹 크롤링 vs. 웹 스크래핑: 뭐가 다를까?
“웹 크롤링”과 “웹 스크래핑”을 같은 말처럼 쓰는 분도 많은데, 사실 목적과 방식이 꽤 달라요.
| 항목 | 웹 크롤링(스파이더링) | 웹 스크래핑 |
|---|---|---|
| 목적 | 가능한 많은 페이지를 발견하고 색인화 | 한두 개 또는 여러 웹페이지에서 특정 데이터 추출 |
| 비유 | 도서관의 모든 책을 정리하는 사서 | 필요한 책에서 핵심 내용만 필기하는 학생 |
| 결과물 | URL 목록 또는 페이지 내용(색인용) | 원하는 정보가 담긴 구조화된 데이터셋(CSV, Excel, JSON 등) |
| 주 사용자 | 검색 엔진, SEO 감사, 웹 아카이빙 | 영업, 마케팅, 리서치 등 비즈니스팀 |
| 규모 | 대규모(수백만~수십억 페이지) | 소규모(수십~수천 페이지) |
짧게 정리하면 이래요.
- 웹 크롤링은 페이지를 찾는 일이에요(웹의 지도를 그리는 작업).
- 웹 스크래핑은 원하는 데이터를 뽑아내는 일이고요(스프레드시트로 옮겨 담는 작업).
실제로 영업, 이커머스, 마케팅 같은 비즈니스 현장에서는 스크래핑, 즉 분석용 구조화 데이터 추출이 훨씬 많이 쓰여요. 크롤링은 검색 엔진이나 대규모 데이터 수집에 꼭 필요하지만, 스크래핑은 특정 목적에 맞춘 데이터 수집에 잘 어울리거든요.
웹 크롤러의 활용: 실제 비즈니스 적용 사례
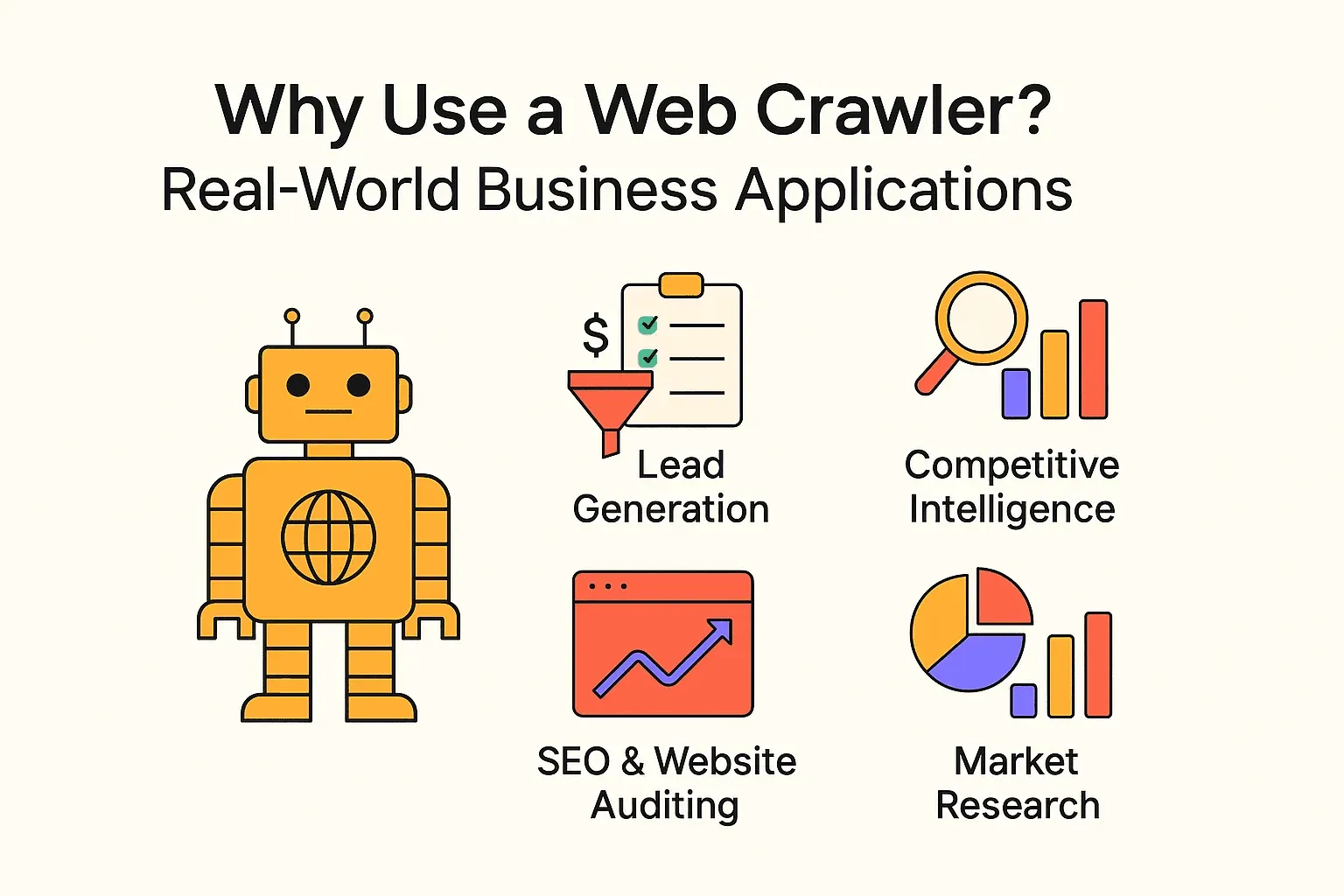
웹 크롤링은 검색 엔진만 쓰는 게 아니에요. 다양한 기업이 크롤러와 웹 스크래퍼를 함께 활용해서 인사이트를 얻고, 반복적인 업무를 자동화하고 있거든요. 자주 보이는 활용 예시는 이런 식이에요.
| 활용 사례 | 주요 사용자 | 기대 효과 |
|---|---|---|
| 리드 생성 | 영업팀 | 잠재 고객 자동 발굴, CRM에 신규 리드 추가 |
| 경쟁사 분석 | 리테일, 이커머스 | 경쟁사 가격, 재고, 상품 변화 모니터링 |
| SEO & 웹사이트 점검 | 마케팅, SEO팀 | 깨진 링크 탐지, 사이트 구조 최적화 |
| 콘텐츠 집계 | 미디어, 리서치, HR | 뉴스, 채용공고, 공개 데이터셋 수집 |
| 시장 조사 | 애널리스트, 제품팀 | 리뷰, 트렌드, 감성 분석 등 대규모 데이터 분석 |
- Groupon은 웹 크롤링 자동화로 인바운드 리드를 2배로 늘렸어요.
- 이커머스 기업의 82%, 금융 서비스 기업의 71%가 의사결정에 웹 스크래핑을 적극 활용하고 있고요.
- 웹 스크래핑은 인프라 비용의 90%, 시간의 60%까지 줄여 주기도 해요.
결론은 하나예요. 웹 데이터를 활용하지 않고 있다면, 경쟁사는 이미 활용하고 있을 가능성이 커요.
파이썬으로 웹 크롤러 만들기: 알아야 할 것들
코딩에 익숙하다면, 파이썬은 맞춤형 웹 크롤러를 만들 때 가장 많이 선택되는 언어예요. 기본 흐름은 이래요.
- requests로 웹페이지 요청
- BeautifulSoup으로 HTML 파싱과 링크·데이터 추출
- 반복문(또는 재귀)으로 링크를 따라가면서 추가 페이지 크롤링
장점:
- 원하는 대로 자유롭게 설계할 수 있어요.
- 복잡한 로직, 데이터 흐름, DB 연동 같은 고급 기능까지 직접 구현할 수 있고요.
단점:
- 프로그래밍 지식이 어느 정도 필요해요.
- 사이트 구조가 바뀌면 그때마다 코드 유지보수가 따라와요.
- 봇 차단, 지연, 오류 처리 같은 부분도 직접 신경 써야 해요.
입문자를 위한 파이썬 크롤러 예시:
아래는 quotes.toscrape.com에서 명언과 저자를 뽑아내는 간단한 코드예요.
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com/page/1/>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for quote in soup.find_all('div', class_='quote'):
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
print(f"{text} --- {author}")
여러 페이지를 한 번에 크롤링하고 싶다면 “다음” 버튼을 찾아 반복문을 더해 주면 돼요.
자주 하는 실수:
- robots.txt나 크롤링 지연을 무시해서 서버에 무리를 주는 경우
- 봇 차단에 걸려 버리는 경우
- 무한 루프(예: 끝없이 이어지는 달력 페이지) 때문에 서버가 과부하되는 경우
단계별 가이드: 파이썬으로 간단한 웹 크롤러 만들기
직접 코딩에 도전해 보고 싶다면, 아래 단계를 따라가 보세요.
1단계: 파이썬 환경 준비
파이썬이 설치돼 있는지 확인하고, 필요한 라이브러리를 깔아요.
pip install requests beautifulsoup4
문제가 생기면 파이썬 버전(python --version)과 pip 설치 여부부터 점검해 보면 좋아요.
2단계: 크롤러 핵심 로직 작성
기본 패턴은 이런 모양이에요.
import requests
from bs4 import BeautifulSoup
def crawl(url, depth=1, max_depth=2, visited=None):
if visited is None:
visited = set()
if url in visited or depth > max_depth:
return
visited.add(url)
print(f"Crawling: {url}")
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 링크 추출
for link in soup.find_all('a', href=True):
next_url = link['href']
if next_url.startswith('http'):
crawl(next_url, depth + 1, max_depth, visited)
start_url = "<http://quotes.toscrape.com/>"
crawl(start_url)
팁:
- 크롤링 깊이에 제한을 둬서 무한 루프를 피해요.
- 방문한 URL을 따로 기록해 두면 같은 페이지를 또 도는 일이 줄어들어요.
- robots.txt를 지키고, 요청 사이에 딜레이(time.sleep(1))를 넣어 주는 것도 잊지 마세요.
3단계: 데이터 추출 및 저장
데이터는 CSV나 JSON 파일로 저장하면 편해요.
import csv
with open('quotes.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Quote', 'Author'])
# 크롤링 루프 내에서:
writer.writerow([text, author])
파이썬의 json 모듈을 활용해 JSON으로 저장해도 좋고요.
웹 크롤링 시 주의사항 및 베스트 프랙티스
웹 크롤링은 강력하지만, 그만큼 책임감 있게 써야 해요(잘못하면 IP가 차단될 수도 있거든요). 다음 항목들은 꼭 챙겼으면 해요.
- robots.txt 준수: 사이트의 robots.txt부터 확인하고, 금지된 영역은 건드리지 말아요.
- 서버에 무리 주지 않기: 요청 사이에 충분한 딜레이(몇 초 이상)를 넣어 주세요.
- 범위 제한: 꼭 필요한 페이지만 크롤링하고, 깊이와 도메인에 제한을 걸어 두면 좋아요.
- User-Agent 명확히: 자신을 알리는 User-Agent를 사용하세요.
- 법적 이슈 확인: 비공개·민감 정보는 크롤링하지 말고, 공개된 데이터만 다뤄야 해요.
- 윤리적 사용: 사이트 통째로 복사하거나 스팸 목적으로 데이터를 쓰는 일은 피해 주세요.
- 테스트는 소규모로: 작은 범위부터 시작해서 문제가 없을 때 점진적으로 넓혀 나가요.
더 자세한 내용은 이 베스트 프랙티스 가이드를 참고해 보세요.
웹 스크래핑이 더 적합한 경우: 비즈니스 사용자를 위한 Thunderbit
AI로 어떤 웹사이트든 데이터 추출하기 Get Started Free
솔직히 말씀드리면, 검색 엔진을 직접 만들거나 사이트 전체 구조를 통째로 분석해야 하는 게 아니라면 대부분의 비즈니스 사용자에겐 웹 스크래핑 도구가 훨씬 효율적이에요.
이 지점에서 Thunderbit가 진가를 발휘해요. 공동 창업자이자 CEO라서 어쩔 수 없이 약간의 편견은 있을 수 있지만, Thunderbit는 비전문가도 손쉽게 웹 데이터를 뽑아 쓸 수 있는 가장 좋은 솔루션이라고 자신 있게 말할 수 있어요.
Thunderbit의 장점
- 두 번 클릭이면 끝: “AI 필드 추천”을 누르고 “스크랩”을 한 번 더 누르면 바로 끝나요.
- AI 기반: Thunderbit가 페이지를 읽고, 추출하기 좋은 컬럼(상품명, 가격, 이미지 등)을 자동으로 제안해 줘요.
- 대량 & PDF 지원: 현재 페이지뿐 아니라 여러 URL, PDF에서도 데이터를 추출할 수 있어요.
- 유연한 내보내기: CSV/JSON 다운로드는 기본이고, Google Sheets·Airtable·Notion으로 바로 보낼 수도 있어요.
- 코딩 불필요: 브라우저만 다룰 줄 알면 누구나 쓸 수 있어요.
- 서브페이지 스크래핑: 정보가 더 필요할 땐 Thunderbit가 하위 페이지까지 자동으로 들어가 데이터를 보강해 줘요.
- 스케줄링: “매주 월요일 오전 9시”처럼 자연어로 반복 스크래핑을 예약할 수 있어요.
언제 크롤러가 더 적합할까요?
사이트 전체를 지도처럼 그려야 할 때(예: 검색 인덱스나 사이트맵 구축)는 크롤러가 필요해요. 하지만 상품 목록, 리뷰, 연락처처럼 특정 페이지에서 구조화된 데이터만 뽑고 싶다면 스크래핑이 훨씬 빠르고 가벼워요.
결론 & 핵심 요약
정리하면 이렇게 돼요.
- 웹 크롤링은 검색 엔진과 대규모 데이터 프로젝트가 웹을 발견하고 지도로 그리는 방식이에요. 한마디로 최대한 많은 페이지를 찾는 데 초점이 있어요.
- 웹 스크래핑은 그중에서 필요한 데이터만 뽑아내는 작업이고요. 비즈니스 사용자 대부분에겐 크롤링보다 스크래핑이 더 자주 필요해요.
- 직접 크롤러를 코딩해도 되지만(파이썬 추천), 시간과 기술, 그리고 꾸준한 유지보수가 따라와요.
- 노코드/AI 기반 도구(Thunderbit 같은)를 쓰면 누구나 쉽게 웹 데이터를 추출할 수 있어요.
- 베스트 프랙티스 준수: 사이트 규칙을 늘 지키고, 데이터를 윤리적으로 활용해 주세요.
이제 막 시작하는 단계라면, 작은 프로젝트(예: 상품 가격 수집, 디렉토리에서 리드 추출 등)로 손에 감을 익혀 보면 좋아요. 결과를 빨리 보고 싶다면 Thunderbit 같은 도구를, 코딩 자체를 배우고 싶다면 파이썬을 시도해 보세요.
웹은 그야말로 정보의 보고예요. 올바른 방법으로 접근하기만 하면, 더 똑똑한 의사결정과 시간 절약, 비즈니스 경쟁력 강화에 든든한 자산이 되어 줄 거예요.
FAQ
- 웹 크롤링과 웹 스크래핑의 차이는?
크롤링은 페이지를 찾고 지도를 그리는 것, 스크래핑은 그 페이지에서 원하는 데이터를 추출하는 것입니다. 크롤링=발견, 스크래핑=추출.
- 웹 스크래핑은 합법인가요?
공개 데이터라면 robots.txt와 서비스 약관을 지키는 한 대부분 문제 없어요. 비공개나 저작권 콘텐츠는 피하세요.
- 웹사이트에서 데이터를 추출하려면 코딩이 꼭 필요한가요?
아니요. Thunderbit 같은 도구를 사용하면 클릭과 AI만으로도 데이터 추출이 가능해요.
- 왜 구글이 웹 전체를 색인화하지 않나요?
대부분의 웹페이지가 로그인, 유료벽, 차단 등으로 인해 접근이 불가능하기 때문입니다. 실제로 약 4%만 색인화돼요.
더 읽어보기
- FreeCodeCamp – 파이썬과 BeautifulSoup으로 웹 스크래핑하기
- Scrapy 공식 튜토리얼
- Real Python – Selenium과 파이썬으로 웹 스크래핑하기
- Apify Academy: 웹 스크래핑과 자동화
AI 웹 스크래퍼 체험하기 Get Started Free




