
지난주, 영업팀 한 명이 데이터 벤더에게서 구매한 4,000개 연락처가 들어 있는 스프레드시트를 보여줬습니다. 아웃리치를 2주간 진행한 뒤 회신율은 0.3%, 반송률은 12%를 훌쩍 넘었습니다. 그 리스트에 실제 돈을 썼지만, 돌아온 건 거의 없었습니다.
2026년의 대부분 리드 리스트는 시작하자마자 사실상 실패한 상태입니다. 2025년에 발송된 3,100만 통의 이메일을 바탕으로 한 에 따르면, 콜드 이메일 시퀀스의 평균 회신율은 고작 4.5%입니다. 그리고 이건 평균일 뿐이라, 실제로는 이보다 훨씬 낮은 캠페인도 적지 않습니다. 한편 는 일반적인 세일즈 담당자가 주당 업무 시간의 40%만 실제 판매에 쓰고, 나머지 60%는 행정, 리서치, 그리고 말 그대로 잠재고객 발굴에 쓴다고 말합니다.
즉, 시간을 들여 리스트를 만든다면, 적어도 회신이 오는 리스트여야 합니다. 이 가이드는 2026년형 전체 워크플로우를 처음부터 끝까지 다룹니다. ICP 정의, LinkedIn 밖에서 리드 찾기, 제대로 된 템플릿 만들기, 반송률이 발신자 평판을 망치지 않도록 데이터 검증하기, 발송 전 리드 점수 매기기, 그리고 시간이 지나도 정보를 최신 상태로 유지하는 방법까지 모두 포함했습니다. 또한 예산 기준으로 정리했기 때문에, 오늘 바로 0달러로 시작할 수도 있습니다.
- 난이도: 초급
- 소요 시간: 첫 50~100개 리드 기준 약 2~3시간
- 준비물: Chrome 브라우저, , Google Sheet 또는 스프레드시트, 그리고 문서화된 ICP
리드 리스트란 무엇이며, 왜 대부분의 리스트는 실패할까?

리드 리스트는 잠재 구매자, 즉 접근하고 싶은 사람과 회사 정보를 구조화해 정리한 데이터셋입니다. 보통 개인 단위 필드(이름, 직함, 이메일, 전화번호, LinkedIn URL)와 회사 단위 필드(산업, 규모, 매출, 위치)를 포함합니다. 아웃바운드 세일즈의 출발점이 바로 이 리스트입니다.
대부분의 팀이 실수하는 지점은 리드 리스트와 단순한 연락처 덤프를 혼동한다는 점입니다. 쓸모 있는 리드 리스트는 왜 이 회사인가, 왜 지금 이 사람인가에 대한 답을 줍니다. 반면 무작위 벤더에서 산 리스트는 종종 "아직 살아 있을지도 모르는 이메일 주소" 정도만 알려줍니다. 결과 차이는 엄청납니다.
리드 리스트는 더 넓은 퍼널의 한 단계이기도 합니다. 리드는 시장에 맞을 가능성이 있는 사람이고, MQL(Marketing Qualified Lead)은 어느 정도 적합성이나 관심을 보인 리드입니다. SQL(Sales Qualified Lead)은 직접 후속 대응이 가능한 상태이고, Opportunity는 실제 진행 중인 딜입니다. 리드 리스트는 이 퍼널의 맨 위에 해당합니다. 시작점이 쓰레기로 가득 차 있으면 이후 모든 단계가 무너집니다.
리드 리스트가 실패하는 가장 흔한 이유는 다음과 같습니다.
- 오래된 데이터: 에 따르면 이메일 리스트의 최소 합니다. 즉, 12개월마다 연락처의 거의 4분의 1이 무용지물이 됩니다.
- 잘못된 대상: info@, sales@ 같은 역할 기반 이메일이나 의사결정 권한을 알 수 없는 "Staff" 같은 모호한 직함.
- 타겟 기준 부재: 전략처럼 보이지만 사실은 숫자만 늘리는 방식. 어느 포럼 사용자가 말했듯, "우리는 종종 양을 품질로 착각한다."
- 검증 부재: 에 따르면 는 CRM 데이터의 절반도 정확하고 완전하지 않다고 답했고, 고 응답했습니다.
- 양 중심 사고: 는 21~50명을 타깃으로 한 캠페인의 평균 회신율이 인 반면, 501명 이상을 대상으로 한 캠페인은 평균 에 그친다고 보여줍니다. 더 크고 느슨한 리스트보다 작고 정교한 리스트가 낫습니다.
리드 리스트 템플릿: 스프레드시트는 실제로 어떻게 생겨야 할까?
저는 "리드 리스트를 만드는 방법" 관련 가이드를 수십 개 봤는데, 늘 아쉬운 점이 있습니다. 다들 "연락처 정보, firmographics, lead score를 포함하라"고 말하면서도 정작 스프레드시트가 어떤 모습이어야 하는지는 보여주지 않습니다. 그래서 여기, 다들 놓치고 있는 실제 형태를 정리했습니다.
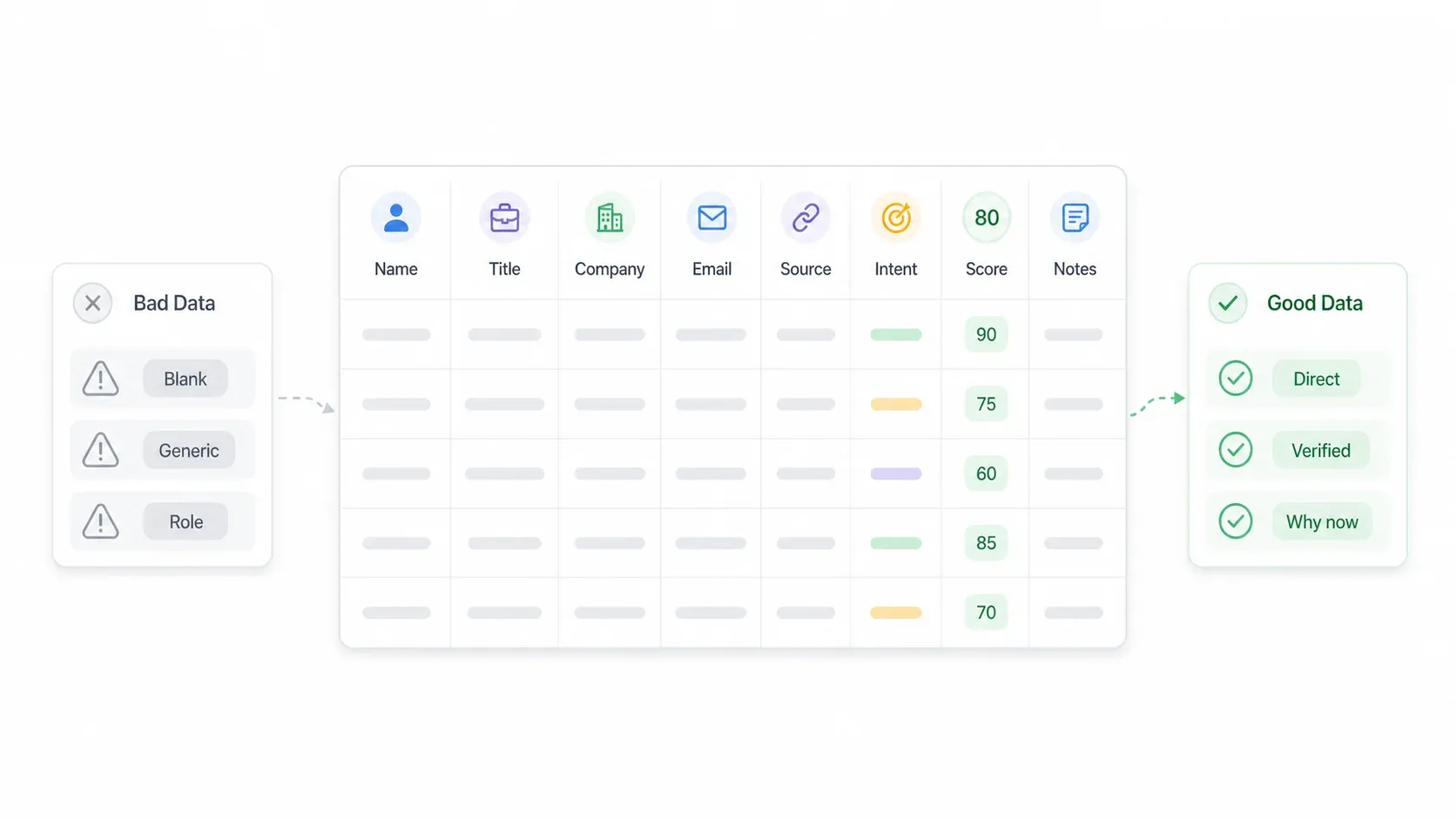
추천 시작 컬럼
리드 리스트 스프레드시트에는 처음부터 다음 컬럼이 있어야 합니다.
| 컬럼 | 무엇을 담는가 | 좋은 데이터 예시 | 나쁜 데이터 예시 |
|---|---|---|---|
| 전체 이름 | 실제 사람 이름 | "Jordan Lee" | "Sales Team" |
| 직함 | 현재 맡은 구체적 역할 | "VP of Sales" | "Staff" |
| 회사명 | 법인명 또는 브랜드명 | "Acme Logistics" | "Acme?" |
| 산업 | 표준화된 카테고리 | "B2B SaaS" | "Tech-ish" |
| 회사 규모 | 직원 수 구간 | "51-200" | 공란 |
| 이메일 | 직접 연결되는 업무용 이메일 | "jordan@acme.com"처럼 검증됨 | "info@acme.com" |
| 전화번호 | 직통 또는 대표번호, 형식 정리됨 | E.164 형식 | 지역 번호가 뒤섞인 형식 |
| LinkedIn URL | 프로필 또는 회사 페이지 | 전체 URL | 검색 결과 URL |
| 리드 소스 | 데이터가 어디서 왔는지 | "G2 카테고리 페이지, 2026년 5월" | "Internet" |
| 의도 신호 | 왜 지금인지 | "SDR 3명 채용", "신규 투자" | 공란 |
| 리드 점수 | 우선순위 숫자 | 규칙 기반 70/100 | 직감 |
| 마지막 접촉일 | 아웃리치 날짜 | "2026-05-26" | "최근" |
| 메모 | 관련 맥락 | "Shopify Plus 사용" | 길고 정리 안 된 메모 덩어리 |
샘플 리드 리스트(익명화)
아래는 실제로 채워진 리스트가 어떤 모습인지 보여주는 예시입니다. 서로 다른 페르소나를 포함한 10개 행입니다.
| 전체 이름 | 직함 | 회사명 | 산업 | 규모 | 이메일 | 소스 | 의도 신호 | 점수 |
|---|---|---|---|---|---|---|---|---|
| Alex M. | VP Sales | Mid-market SaaS vendor | SaaS | 201-500 | 직접 검증됨 | G2 카테고리 | AE 채용 중 | 78 |
| Priya S. | Head of Ops | DTC apparel brand | Ecommerce | 51-200 | 직접 검증됨 | Shopify 쇼케이스 | 물류 확대 | 72 |
| Marcus T. | Founder | Local agency | Professional services | 11-50 | 직접 검증됨 | Clutch | 새 리뷰 증가 | 66 |
| Elena R. | Revenue Ops Manager | Cybersecurity startup | SaaS | 51-200 | catch-all로 표시됨 | 컨퍼런스 발표자 목록 | Series A | 61 |
| Ben C. | Owner | HVAC contractor | Local services | 11-50 | 대표 메일 | Google Business | 리뷰 수 많음 | 48 |
| Mina K. | Director of Partnerships | Marketplace company | Ecommerce | 201-500 | 직접 검증됨 | 이벤트 아젠다 | 이벤트 후원 중 | 74 |
| Diego P. | Real Estate Broker | Regional brokerage | Real estate | 11-50 | 직접 검증됨 | 협회 디렉터리 | 신규 오피스 페이지 | 58 |
| Sarah N. | Customer Support Lead | B2B software company | SaaS | 51-200 | 역할 기반 제거됨 | Capterra | 지원 리뷰 수 적음 | 44 |
| Omar A. | IT Manager | Manufacturing firm | Manufacturing | 501-1000 | 직접 검증됨 | 회사 팀 페이지 | ERP 이전 언급 | 69 |
| Lena W. | Growth Marketing Lead | Fintech startup | SaaS | 51-200 | 직접 검증됨 | Product Hunt | 신규 출시 | 71 |
각 컬럼의 의미와 “좋은” 데이터의 기준
몇몇 컬럼은 좀 더 설명이 필요합니다.
- 직함: "VP of Sales"는 이 사람이 예산 권한이 있다는 뜻입니다. "Staff"는 아무 정보도 주지 않습니다. 의사결정 권한이나 영향력을 보여주는 구체적인 직함을 항상 노려야 합니다.
- 이메일: 개인 업무용 이메일(jordan@acme.com)은 금처럼 귀합니다. 역할 기반 주소(sales@acme.com)는 콜드 아웃리치에서는 거의 쓸모가 없습니다. 공유 받은편지함에 들어가서 아무도 안 보는 경우가 많기 때문입니다.
- 리드 소스: 대부분의 사람이 빼먹는 컬럼이지만, 시간이 지날수록 가장 중요해집니다. 각 리드가 어디서 왔는지 추적하면 어떤 채널이 단순히 행만 만드는지, 어떤 채널이 실제 회신을 만드는지 알 수 있습니다. "G2 카테고리 페이지, 2026년 5월"은 유용합니다. "Internet"은 아닙니다.
- 의도 신호: 이건 "왜 지금인가"를 보여주는 컬럼입니다. 최근 Series A 투자를 받은 회사, SDR 채용 공고를 3개 올린 회사, 새 제품을 출시한 회사는 조용히 있는 회사보다 훨씬 뜨거운 리드입니다. 의도 신호를 찾을 수 없다면 우선순위가 낮을 수 있습니다.
Thunderbit의 AI Suggest Fields가 템플릿을 자동으로 만드는 방식
제가 에서 특히 자랑스럽게 생각하는 기능 중 하나는, 어떤 컬럼을 만들어야 할지 추측할 필요가 없다는 점입니다. 디렉터리, 회사 팀 페이지, 컨퍼런스 발표자 목록처럼 잠재고객이 많은 페이지를 Thunderbit로 열고 **"AI Suggest Fields"**를 클릭하면, AI가 페이지를 읽고 적절한 컬럼명과 데이터 유형을 자동으로 만들어 줍니다. 페이지에 이름, 이메일, 직함, 회사 정보가 있다면 Thunderbit는 정확히 그 컬럼들을 제안합니다.
특히 빈 스프레드시트를 보며 "도대체 어떤 필드를 모아야 하지?"라고 막막해하는 초보자에게 유용합니다. Thunderbit는 소스 페이지에 실제로 존재하는 데이터를 바탕으로 답을 제시합니다. 그다음 **"Scrape"**를 클릭하면 Google Sheets, Excel, Airtable, Notion으로 바로 내보낼 수 있습니다.
리드 리스트를 만들기 전에 이상적인 고객 프로필(ICP)부터 정의하는 방법
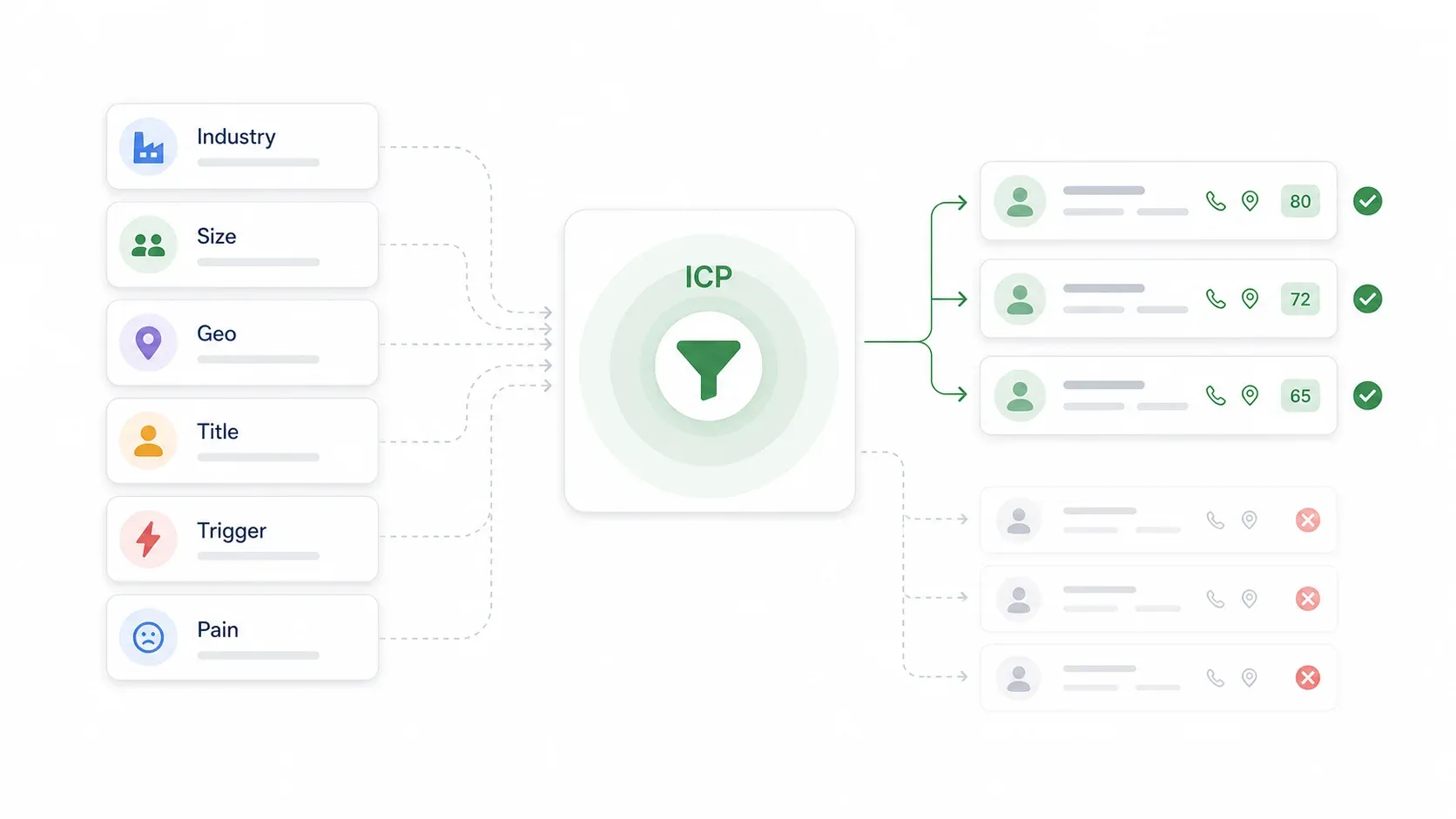
제가 팀에서, 그리고 저 자신에게서도 가장 자주 보는 실수는, 누구를 담을지 정하기 전에 먼저 리스트를 만드는 것입니다. 그러면 이름만 가득한 스프레드시트가 생기고, 이 사람들 중 누가 왜 내 제품에 관심을 가져야 하는지 전혀 알 수 없게 됩니다.
ICP는 우리 제품을 가장 잘 사주고, 가장 큰 가치를 얻고, 오래 남을 가능성이 높은 회사와 사람의 정의입니다. 페르소나 연습이 아니라 타겟팅 필터입니다.
ICP 구성 요소
| ICP 항목 | 질문 | 예시 |
|---|---|---|
| 산업 | 어떤 카테고리에 이 문제가 있는가? | B2B SaaS, ecommerce, professional services |
| 회사 규모 | 지금 구매할 수 있는 규모는? | 51-500명 |
| 지역 | 어디에 판매하고 잘 지원할 수 있는가? | 미국, 캐나다, 영국 |
| 매출 범위 | 어떤 ARR 구간이 맞는가? | $5M-$100M ARR |
| 구매자 직함 | 누가 문제와 예산을 쥐고 있는가? | VP Sales, RevOps, Head of Ops |
| 트리거 | 어떤 상황에서 지금 당장 시급해지는가? | 채용, 투자, 이전, 낮은 리뷰 |
| 페인 포인트 | 어떤 문제를 체감하는가? | 수동 리스트 작성, 오래된 데이터, 느린 보강 |
| 제외 대상 | 누구를 걸러야 하는가? | 학생, 취미 사업, 경쟁사 |
실전 연습: 현재 가장 성과가 좋은 기존 고객 5~10곳을 살펴보세요. 공통점이 무엇인가요? 산업? 규모? 계약을 체결한 사람의 직함? 공통된 특징 3~5개를 적어보세요. 그것이 ICP 초안입니다.
Firmographics와 Demographics: 무엇이 더 중요할까?
Firmographics는 산업, 규모, 매출, 위치처럼 회사 단위 데이터입니다. B2B 맥락에서 demographics는 직함, 직급, 기능, 부서처럼 사람 단위 데이터입니다. B2B 리드 리스트에서는 firmographics가 회사를 좁히고, demographics가 사람을 좁힙니다. 둘 다 필요합니다. 완벽한 회사에 잘못된 연락처를 넣으면 한 줄이 낭비되고, 완벽한 연락처를 잘못된 회사에서 찾으면 역시 무용지물입니다.
한 가지 더 중요한 점이 있습니다. 는 을 분석한 결과, 의사결정 단위가 평균 정도라고 밝혔습니다. 즉, 좋은 리드 리스트는 타겟 계정당 한 명 이상의 연락처를 포함하는 경우가 많지만, 너무 많아서 아웃리치가 스팸처럼 보일 정도는 아니어야 합니다.
LinkedIn 밖에서 리드를 찾는 곳: 웹사이트, 디렉터리, 소셜 미디어
이 주제를 조사하면서 놀랐던 콘텐츠 공백이 하나 있었습니다. 검색 상위권의 “리드 리스트 만드는 방법” 글 6개 중 5개가 리드 소스로 LinkedIn Sales Navigator를 가장 먼저 언급하고 있었습니다. 물론 Sales Navigator는 강력합니다. 하지만 비용도 만만치 않습니다(Core 기준 대략 ), 실제 사용자들은 내보내기 제한, 복잡한 인터페이스, 스크래핑의 번거로움을 자주 불평합니다.
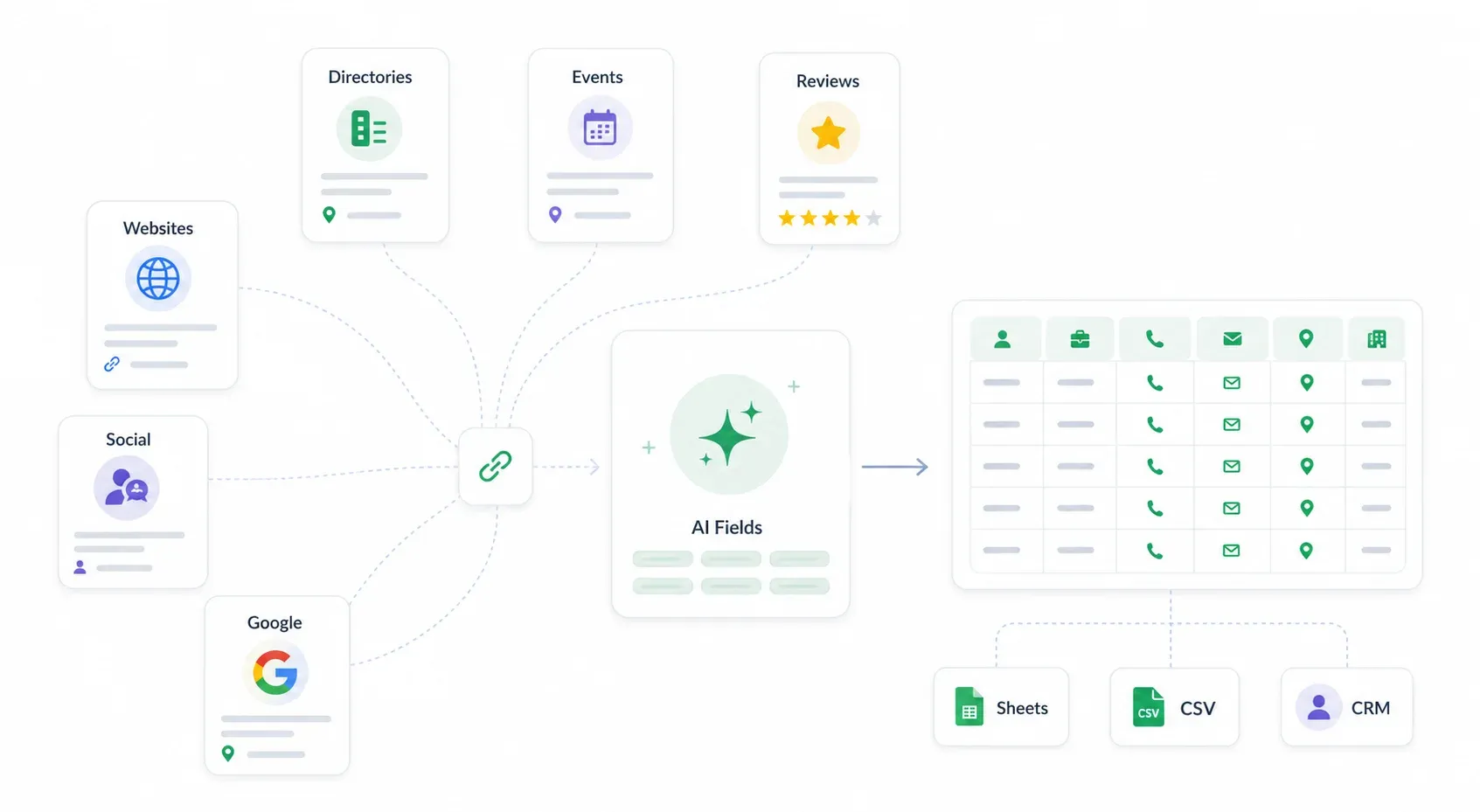
2026년의 현실은 리드가 LinkedIn에만 있지 않다는 점입니다. 회사 웹사이트, 업계 디렉터리, 이벤트 페이지, 리뷰 사이트, 심지어 소셜 미디어 프로필까지도 풍부한 연락처 소스입니다. 많은 경우 유료 데이터베이스보다 더 최신이고 더 구체적이기도 합니다.
리드 소스 비교
| 리드 소스 | 가장 적합한 대상 | 방법 | 비용 |
|---|---|---|---|
| 회사 웹사이트 / 소개 페이지 | 틈새 B2B, 로컬 서비스, 에이전시 | 팀/연락처 페이지 방문, 이름/이메일/전화 추출 | 무료 |
| 업계 디렉터리(Clutch, G2, Yelp) | 서비스 기반 리드, 산업별 생태계 | 카테고리/지역으로 필터링 후 리스트 스크래핑 | 무료~저비용 |
| 이벤트 참가자/발표자 목록 | 구매 의도가 높은 B2B 잠재고객 | 컨퍼런스 아젠다, 후원사 페이지, 웨비나 등록자 | 무료~유료 이벤트 접근 |
| 리뷰 사이트(G2, Capterra, Google Business) | SaaS 및 로컬 비즈니스 | 카테고리 탐색 후 회사 연락처 추출 | 무료 |
| 소셜 미디어(Instagram, X) | B2C, 퍼스널 브랜드, 로컬 비즈니스 | 공개 소개글, 비즈니스 페이지 | 무료 |
| Google site: 연산자 | 롱테일 탐색, 타깃 연락처 페이지 | 고급 검색 쿼리 | 무료 |
| LinkedIn(기본) | 전문 검색 | 수동 검색, 공개 프로필 | 무료 |
| LinkedIn Sales Navigator | 성숙한 아웃바운드 팀 | 고급 필터, 저장 리드, TeamLink | 월 $99+ |
산업별로 유용한 디렉터리
| 산업군 | 스크래핑할 만한 소스 |
|---|---|
| SaaS | G2, Capterra, Product Hunt, SaaSworthy, AWS Marketplace, Chrome Web Store 카테고리 |
| Ecommerce | Shopify 스토어/쇼케이스, BuiltWith 리스트, Klaviyo 파트너 디렉터리 |
| 부동산 | Realtor 디렉터리, 중개사 오피스 페이지, 로컬 MLS 공개 페이지, 상공회의소 디렉터리 |
| 전문 서비스 | Clutch, DesignRush, UpCity, GoodFirms, 지역 변호사회/회계사 디렉터리 |
| 로컬 비즈니스 | Google Business 결과, Yelp, Yellow Pages, BBB, 지역 상공회의소 페이지 |
| 이벤트 | 스폰서/전시사 페이지, 발표자 목록, 아젠다 페이지, 웨비나 랜딩 페이지 |
리드 찾기에 유용한 Google 고급 검색 연산자
이 방법은 무료인데도 놀랄 만큼 강력합니다. 몇 가지 예시는 다음과 같습니다.
site:clutch.co/agencies "B2B SaaS" "United States"— 카테고리와 지역으로 필터링된 Clutch의 에이전시 리스트를 찾습니다.site:company.com ("email" OR "contact") "VP Sales"— 특정 회사 사이트에서 VP Sales가 언급된 연락처 페이지를 찾습니다.intitle:"sponsors" "SaaS" "2026" "conference"— 2026년 SaaS 컨퍼런스 후원사 페이지를 찾습니다.site:g2.com/categories "sales engagement" "mid-market"— 미드마켓 세일즈 툴 관련 G2 카테고리 페이지를 찾습니다.
에는 정확히 일치하는 따옴표와 site: 같은 연산자가 문서화되어 있으니, 문법이 헷갈리면 여기서 확인할 수 있습니다.
AI 웹 스크래퍼로 어떤 웹사이트든 연락처를 추출하는 방법
여기서 Thunderbit가 워크플로우에 자연스럽게 들어갑니다. 위에서 말한 어떤 소스든 — Clutch 디렉터리, 회사 팀 페이지, 컨퍼런스 발표자 목록 — 절차는 같습니다.
- 을 설치한 Chrome에서 페이지를 엽니다.
- **"AI Suggest Fields"**를 클릭합니다. Thunderbit의 AI가 페이지를 읽고 Name, Email, Phone, Title, Company 같은 컬럼을 제안합니다.
- 제안된 필드를 검토하고, 필요에 따라 추가하거나 제거합니다.
- **"Scrape"**를 클릭합니다.
- Google Sheets, Excel, Airtable, Notion으로 내보냅니다.
핵심 장점은 Thunderbit가 정형화되지 않은 복잡한 사이트에서도 작동한다는 점입니다. 미리 만들어진 스크래퍼 템플릿이 레이아웃을 커버하지 못하는 경우에도, AI가 페이지를 새로 읽고 구조에 맞게 적응합니다. Thunderbit의 무료 는 어떤 페이지든 한 번 클릭으로 추출할 수 있으며, 무료 플랜에서도 무제한으로 사용할 수 있습니다.
서브페이지 스크래핑으로 리드 리스트를 더 풍부하게 만드는 방법
제가 자주 쓰는 워크플로우가 있습니다. 먼저 디렉터리 목록 페이지를 스크래핑한 뒤(예: Clutch의 회사 리스트), Thunderbit의 Subpage Scraping으로 각 회사의 상세 페이지를 방문해 이메일, 전화번호, 인원 수, 기술 스택, 설명 같은 추가 데이터를 가져오는 방식입니다.
이렇게 하면 단순한 디렉터리 리스트가 수작업 클릭 없이도 리서치 가능한 풍부한 리드 리스트로 바뀝니다. "회사 이름 50개"가 "연락 이메일, 팀 규모, 설명까지 포함된 회사 50개"로 자동 변환되는 셈입니다. 에 대해 더 알고 싶다면, 자세한 가이드를 참고하세요.
2026 워크플로우: 리드 리스트를 단계별로 만드는 법
아래는 오늘 당장 실제 리드 리스트를 만들고 싶은 비기술 세일즈/오퍼레이션 담당자를 위한 전체 워크플로우입니다.
1단계: ICP를 확정한다
어떤 도구를 열기 전에 ICP 기준을 먼저 적어두세요(위 ICP 섹션 참고). 산업, 회사 규모, 지역, 구매자 직함, 트리거, 제외 대상입니다. 이 작업은 15~30분이면 끝나고, 불필요한 스크래핑 시간을 몇 시간씩 절약해 줍니다.
2단계: 리드 소스를 고른다
ICP와 예산을 기준으로 비교표에서 2~3개의 리드 소스를 선택하세요. 제 추천은 무료 소스부터 시작하는 것입니다. SaaS 회사를 타깃으로 한다면 G2 카테고리 페이지와 회사 팀 페이지부터 보세요. 로컬 비즈니스가 대상이라면 Google Business 결과와 Yelp부터 시작하면 됩니다. 무료 소스를 모두 소진한 뒤에야 Sales Navigator 같은 유료 소스를 추가하세요.
3단계: AI 스크래핑 또는 수동 검색으로 리드를 추출한다
소스별 추출 방법은 다음과 같습니다.
- 웹사이트와 디렉터리: Thunderbit의 AI 웹 스크래퍼를 사용합니다. 페이지를 열고 "AI Suggest Fields"를 클릭한 뒤, 컬럼을 검토하고, "Scrape"를 클릭합니다. 인기 사이트의 경우 Thunderbit에는 필드를 자동 설정하는 도 있습니다.
- LinkedIn: Sales Navigator 검색과 내보내기를 사용하거나, Thunderbit로 할 수 있습니다.
- Google: 고급 검색 연산자를 실행한 뒤, 결과 페이지를 스크래핑하거나 개별 페이지를 방문합니다.
내보내기 옵션: Google Sheets, Excel, Airtable, Notion, CSV, JSON.
4단계: 데이터를 검증하고 정리한다
이 단계는 선택 사항이 아닙니다. 아래 전용 섹션에서 전체 검증 워크플로우를 설명하겠지만, 간단히 말하면 역할 기반 이메일 제거, 중복 제거, 검증 툴 통과, catch-all 도메인 표시, 캠페인 전 재검증이 핵심입니다.
5단계: 리드 점수를 매기고 우선순위를 정한다
아웃리치를 시작하기 전에 간단한 점수 모델을 적용하세요(아래에서 자세히 설명). 이렇게 하면 스프레드시트 상단에 있는 사람부터가 아니라, 가장 가치 있는 리드부터 접촉하게 됩니다.
6단계: CRM 또는 아웃리치 도구로 내보낸다
정리되고 점수가 매겨진 리스트를 CRM(HubSpot, Salesforce, Pipedrive)이나 아웃리치 플랫폼(lemlist, Mailshake, Apollo)으로 옮깁니다. Thunderbit는 Google Sheets, Airtable, Notion으로 직접 내보낼 수 있고, 이들은 네이티브 연동이나 Zapier로 CRM과 동기화할 수 있습니다.
7단계: 아웃리치를 시작하고 결과를 추적한다
수집한 데이터를 바탕으로 아웃리치를 개인화하세요. 상대의 산업을 언급하고, 의도 신호("SDR 채용 중인 걸 봤습니다")를 참고하고, 페인 포인트에 맞게 가치 제안을 조정합니다. 회신율, 반송률, 전환율을 추적하고, 이 데이터를 다음 ICP와 점수 모델에 다시 반영하세요.
예산 우선: 0달러부터 엔터프라이즈까지 리드 리스트 만드는 법
초기 창업자와 소규모 세일즈 팀에서 제가 가장 자주 듣는 고민은 이겁니다. "비싼 툴 없이 리드 리스트를 어떻게 만드나요?" 아주 타당한 질문입니다. ZoomInfo 계약은 연간 5자리 숫자부터 시작하고, Sales Navigator는 월 $99+입니다. Apollo와 Lusha는 무료 플랜이 있긴 하지만 좋은 기능은 유료 벽 뒤에 있습니다.
솔직한 답은: 무료만으로도 생각보다 멀리 갈 수 있습니다. 다만 규모를 키우려면 어느 정도 투자가 필요합니다. 아래처럼 단계별로 생각하면 됩니다.
| 티어 | 비용 | 방법 | 도구 |
|---|---|---|---|
| 무료 ($0) | $0 | Google 연산자, 수동 LinkedIn, 회사 웹사이트, Thunderbit 무료 플랜(페이지 6개 + 무료 이메일/전화 추출기) | Thunderbit Free, Google, LinkedIn 기본 |
| 저비용 (<$50/월) | $0-50 | 대량 AI 스크래핑, 기본 보강, 이메일 검증 | Thunderbit Starter/Pro, Hunter Starter ($34/월), Bouncer/NeverBounce PAYG |
| 중간 ($50-200/월) | $50-200 | Sales Navigator, 더 풍부한 필터, CRM 연동 | Sales Navigator Core (~$99/월), 유료 Apollo, Lusha |
| 엔터프라이즈 ($200+/월) | $200+ | 의도 데이터, 보강 제품군, 컴플라이언스 워크플로우 | ZoomInfo(견적 기반), Cognism(견적 기반), Clearbit |
가격은 2026년 5월 기준이며, 구매 전 최신 요금을 반드시 확인하세요.
무료로 어디까지 할 수 있고, 어디서 한계에 부딪히는가?
Thunderbit 무료 플랜(월 6페이지의 AI 스크래핑), 무료 Email Extractor와 Phone Number Extractor(무제한, 1클릭), Google 검색 연산자, 기본 LinkedIn 검색만으로도 개인 창업자는 오후 한나절에 50~100개 리드 리스트를 충분히 만들 수 있습니다. 우리 팀에서도 실제로 그렇게 하는 모습을 많이 봤습니다.
한계가 오는 지점은 다음과 같습니다. 볼륨(무료 플랜의 월 페이지 수), 보강 깊이(유료 툴 없이는 의도 데이터나 기술 스택 정보를 얻기 어려움), 그리고 대규모 이메일 검증(무료 검증 툴은 소량만 지원). 이런 한계가 느껴지기 시작하면 저비용 티어로 넘어갈 시점입니다. 를 사용하면 subpage scraping, bulk scraping, pagination, scheduled scraper를 쓸 수 있습니다.
반송률 해결: 실제로 작동하는 데이터 검증 워크플로우
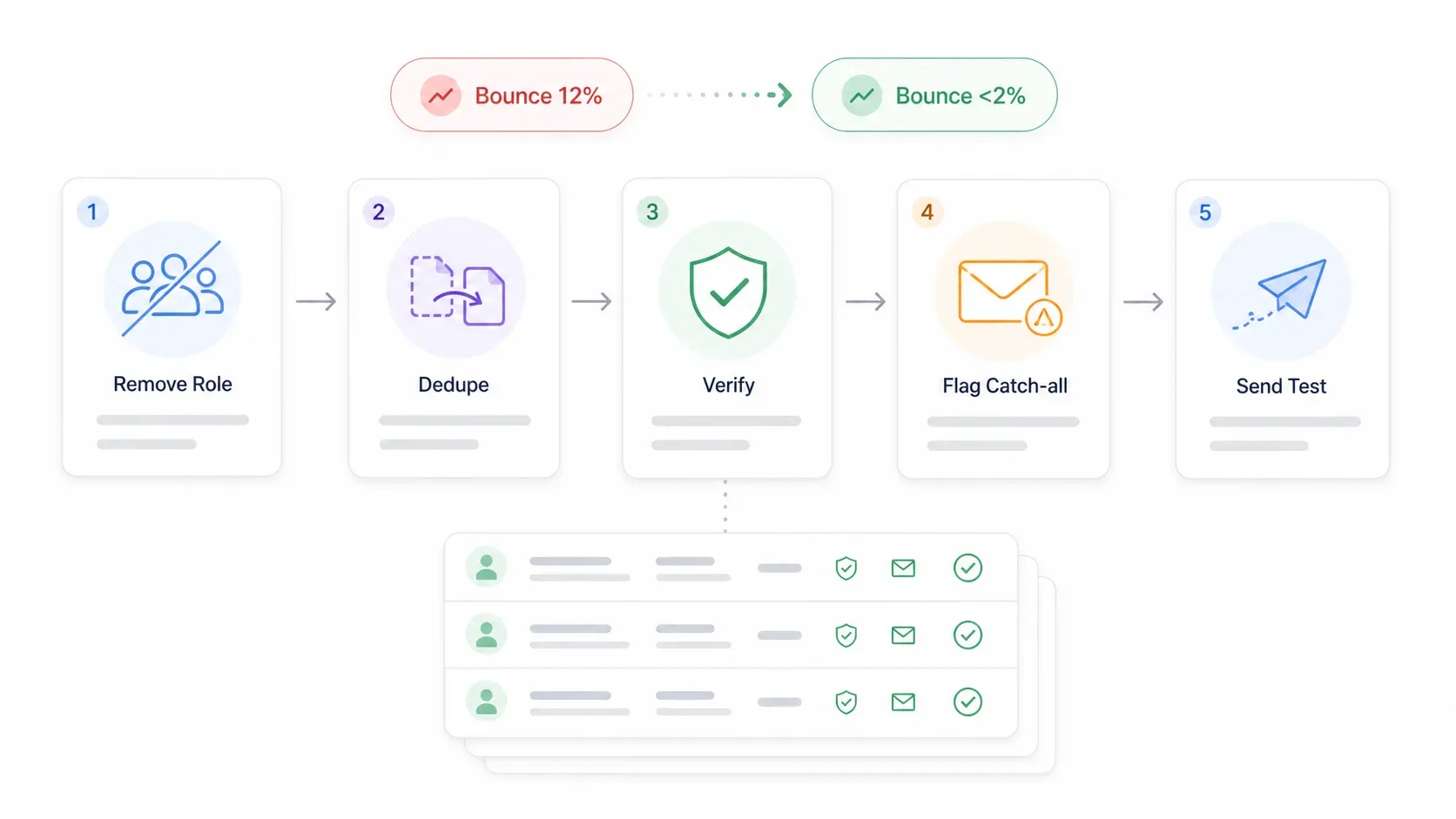
포럼 글을 보면 구매 리스트로 을 겪었다는 사용자가 있습니다. 이건 단순히 시간 낭비가 아니라 실제로 위험합니다. 반송률이 높으면 발신자 평판이 떨어지고, 그러면 잘 만든 이메일까지 스팸으로 들어가기 시작합니다.
에 따르면 건강한 반송률은 2% 미만이고, 1% 미만이면 매우 좋습니다. 에서는 발신자의 거의 절반이 반송률 2~5%를 보고했고, 했습니다. 5%를 넘는다면 발신자 평판이 위험합니다.
제가 추천하는 검증 워크플로우는 다음과 같습니다.
- 역할 기반 이메일 제거: info@, sales@, support@, admin@ 같은 주소는 의도적으로 공유 메일함을 타깃하는 경우가 아니라면 삭제하세요(콜드 아웃리치에서는 드뭅니다).
- 형식 오류 제거: 중복, 오타, 도메인 누락, 죽은 도메인을 정리하세요. 스프레드시트에서 간단히 정렬과 필터만 해도 대부분 잡힙니다.
- 이메일 검증 툴 사용: Hunter, ZeroBounce, NeverBounce, Bouncer, Kickbox 같은 툴을 활용하세요. 이들은 이메일을 보내지 않고도 메일 서버에 ping을 보내 수신함 존재 여부를 확인합니다.
- catch-all 도메인 표시 또는 제거: 에 따르면 catch-all 주소는 서버 수준에서는 메일을 받지만 특정 수신함이 존재하는지는 증명하지 못하는 위험 범주입니다. 개별 수신함을 검증할 수 없다면 해당 레코드를 표시해 두고 신뢰도가 낮은 데이터로 취급하세요.
- 각 캠페인 전에 재검증: 데이터는 빠르게 낡습니다. 리스트가 30~90일 이상 되었다면 발송 전에 다시 검증하세요.
- 처음엔 소량으로 보낸다: 첫 50~100통에서 반송률과 불만율을 확인하세요. 품질이 유지될 때만 확장합니다.
리드 소스가 데이터 품질에 미치는 영향
모든 리드 데이터가 같은 수준은 아닙니다. 회사의 공개 팀 페이지에서 직접 가져온 이메일 — 즉, 그 사람이 의도적으로 공개한 연락처 정보 — 는 몇 달째 업데이트되지 않은 집계 데이터베이스의 이메일보다 대체로 더 최신이고 정확합니다.
제가 정적 데이터베이스만 믿기보다 실시간 공개 페이지를 스크래핑하는 방식을 선호하는 이유 중 하나도 여기에 있습니다. Thunderbit의 AI는 오래된 데이터가 아니라 실제 웹사이트를 매번 새로 읽기 때문에, 추출되는 이메일과 전화번호가 최신일 가능성이 높습니다. Phone Number Extractor는 번호를 E.164 표준으로 다시 포맷하므로 CRM으로 가져갈 때 형식 오류도 줄어듭니다.
신선한 소스를 스크래핑하는 것이 검증을 대신하는 것은 아닙니다. 하지만 출발점이 훨씬 깨끗해집니다.
캠페인 전 체크리스트
어떤 캠페인이든 "보내기"를 누르기 전에 다음을 확인하세요.
- [ ] 모든 이메일이 최근 30일 이내에 검증됨
- [ ] 발송 목록에 역할 기반 주소(info@, sales@) 없음
- [ ] 중복 없음
- [ ] 마지막 캠페인의 반송률 검토 완료
- [ ] 수신 거부/구독 취소 메커니즘 있음
- [ ] 억제 목록(suppression list) 동기화 완료(이전 수신 거부는 모두 존중)
만들고 나서 점수 매기기: 소규모 팀을 위한 간단한 리드 스코어링 모델
제가 읽은 거의 모든 가이드는 "리드 우선순위를 정하라"고 말하지만, 정작 어떻게 하라는지는 알려주지 않습니다.

개인 창업자나 3인 영업팀이라면 Salesforce Einstein이나 예측형 스코어링 엔진은 필요 없습니다. 필요한 건 투명한 수식이 들어간 스프레드시트 컬럼입니다.
스코어링 프레임워크
| 신호 | 점수 | 예시 |
|---|---|---|
| ICP 산업과 일치 | +20 | SaaS, mid-market |
| 회사 규모 적합 | +10 | 51-500명 |
| 의사결정자 직함 | +15 | VP Sales, Head of Ops |
| 분명한 의도 신호 | +15 | 채용, 투자, 툴 이전 |
| 이메일 검증 완료 | +10 | 검증 통과 |
| 직접 소스의 품질 높음 | +10 | 회사 페이지, 발표자 페이지 |
| 내 콘텐츠와 상호작용 | +10 | 가이드 다운로드, 웨비나 참석 |
| catch-all / 미검증 이메일 | -10 | 위험한 검증 상태 |
| 역할 기반 이메일 | -10 | info@, sales@ |
| 일반적인 직함(역할 불명확) | -5 | "Staff" |
계산 예시
리드 A: 120명 규모의 SaaS 회사 VP Sales, SDR 채용 중, 이메일 검증 완료, 회사 채용/팀 페이지에서 수집.
점수: 20(산업) + 10(규모) + 15(직함) + 15(의도) + 10(검증) + 10(소스) = 80 → 이번 주 우선 아웃리치 대상.
리드 B: 5명짜리 취미 사업의 "Staff", 역할 기반 이메일, 의도 신호 없음.
점수: 0 + 0 + 0 + 0 + 0 - 10(역할 기반) - 5(일반 직함) = -15 → 제외 또는 삭제.
이 모델은 Google Sheets의 간단한 수식으로 구현할 수 있습니다. 예를 들면 아래처럼요.
1=IF(D2="SaaS",20,0)+IF(AND(E2>=51,E2<=500),10,0)+IF(REGEXMATCH(B2,"VP|Head|Director|Founder"),15,0)+IF(J2<>"",15,0)+IF(K2="Verified",10,IF(K2="Catch-all",-10,0))Salesforce는 필요 없습니다.
스크래핑 중 AI를 활용해 리드에 라벨과 점수를 붙이는 방법
제가 Thunderbit에 넣은 기능 중 실제로 점수 매기기에 특히 유용하다고 느끼는 것은 Field AI Prompts입니다. 스크래핑을 설정할 때 어떤 컬럼이든 프롬프트를 추가할 수 있습니다. 예를 들어, "직함과 페이지 맥락을 바탕으로 이 리드의 seniority를 Decision-Maker, Influencer, Individual Contributor 중 하나로 분류해라" 같은 식입니다.
Thunderbit는 추출 후가 아니라 추출 도중 데이터를 라벨링합니다. 그래서 Sheets로 내보낼 때 이미 seniority 분류, 회사 유형, 산업 태그가 들어가 있어 바로 스코어링 수식에 넣을 수 있습니다. 덕분에 수동 태깅이라는 번거로운 단계를 없앨 수 있습니다.
Subpage Scraping을 사용해 원본 리스트 데이터를 더 풍부하게 만들 수도 있습니다. 먼저 디렉터리를 스크래핑한 뒤 각 회사 페이지를 방문해 인원 수, 펀딩 상태, 기술 스택을 가져오면, 이 정보들이 모두 스코어링 모델에 반영됩니다.
점수를 다시 봐야 하는 시점
리드 점수는 한 번 매기고 끝나는 것이 아닙니다. 매달, 또는 대형 캠페인 후에 다시 점수화하세요. 리드가 긍정적으로 답하면 점수도 바뀝니다(이제는 콜드 리드가 아니라 활성 대화 대상입니다). 이메일이 반송되면 그에 맞게 조정하세요. 6개월 전에 채용 중이던 회사가 지금은 구조조정을 했다면 의도 신호도 달라진 것입니다.
리드 리스트를 최신 상태로 유지하는 법(자동화와 유지관리)
리드 리스트는 한 번 만들고 끝나는 프로젝트가 아닙니다.
이미 언급했듯이, 합니다. 사람은 이직하고, 회사는 방향을 바꾸고, 이메일은 낡습니다. 5월에 훌륭한 리스트를 만들고 10월까지 손대지 않으면, 상당 부분이 이미 죽은 데이터입니다.
유지관리 주기
| 작업 | 빈도 | 이유 |
|---|---|---|
| 이메일 검증 | 모든 캠페인 전(최소 매월 1회) | 하드 반송 방지 |
| 연락처 중복 제거 | 적극적인 발굴 기간에는 매주 | 중복 아웃리치 방지 |
| 의도 신호 업데이트 | 매월 | 채용/투자/리뷰는 빠르게 변함 |
| 회사 firmographics 갱신 | 분기별 또는 반기별 | 규모, 매출, 기술 스택은 변동됨 |
| suppression list 동기화 | 매일 또는 실시간 | 수신 거부 준수 및 불만 감소 |
| 소스 성과 검토 | 매월 | 단순히 행만 만드는 채널이 아니라 회신을 만드는 채널 파악 |
지속적인 리드 생성을 위한 예약 스크래핑 설정
여기서 Thunderbit의 Scheduled Scraper가 유용합니다. 매달 디렉터리를 직접 다시 방문하는 대신, 반복 스크래핑을 설정할 수 있습니다. 설정은 간단합니다. 시간 간격을 자연어로 적으면 됩니다(예: "매주 월요일 오전 8시"), 웹사이트 URL을 넣고 "Schedule"을 클릭하세요. Thunderbit의 AI가 이 문장을 일정으로 변환해 자동 실행하며, 새로운 결과를 연결된 Google Sheet나 Airtable base로 내보냅니다.
잘 작동하는 사례는 다음과 같습니다.
- 세일즈 팀이 매달 Clutch 카테고리 페이지를 다시 스크래핑해 시장에 새로 들어온 에이전시를 포착한다.
- ecommerce 운영팀이 매주 경쟁사 디렉터리를 모니터링해 신규 상품 등록을 확인한다.
- SaaS 창업자가 매월 아웃바운드 배치 전에 G2 카테고리 페이지를 새로 고쳐 새로 등록된 회사를 찾는다.
Thunderbit의 클라우드 모드는 할 수 있어서, 대형 디렉터리도 빠르게 갱신됩니다. 설정 방법이 더 궁금하다면 가이드를 참고하세요.
컴플라이언스와 데이터 프라이버시에 대한 짧은 메모
이 가이드의 핵심은 아니지만, 매우 중요하므로 짧게 짚고 넘어가겠습니다.
- CAN-SPAM(미국): B2B를 포함한 모든 상업용 이메일에 적용됩니다. 각 위반 이메일마다 최대 의 벌금이 발생할 수 있습니다. 요구사항은 정확한 헤더, 기만적이지 않은 제목, 유효한 우편 주소, 명확한 수신 거부 방법, 그리고 10영업일 내 수신 거부 반영입니다.
- GDPR(EU/UK): 이름이 식별되는 업무용 이메일도 개인 데이터가 될 수 있습니다. B2B 마케팅은 신원을 숨기면 안 되고, 유효한 수신 거부 수단을 제공해야 하며, 이의를 존중해야 합니다.
- CCPA/CPRA(캘리포니아): 고지, 목적 제한, 데이터 최소화, 소비자 권리를 강조합니다. 최신 내용은 를 참고하세요.
- Google 및 Yahoo 발신자 규칙: 대량 발송자가 스팸 비율을 0.30% 미만으로 유지하고, SPF/DKIM/DMARC로 인증하며, 원클릭 구독 취소를 지원해야 한다고 요구합니다. 합니다.
결론은 이렇습니다. 공개적으로 접근 가능한 데이터만 스크래핑하고, 허가 없는 로그인 장벽은 피하고, 항상 수신 거부 메커니즘을 포함하며, 억제 목록을 유지하고, 현지 법적 요구사항을 확인하세요. Thunderbit는 공개 페이지를 스크래핑할 뿐이며, 데이터를 어떻게 활용할지는 사용자의 책임입니다.
결론과 핵심 정리
2026년의 리드 리스트 워크플로우는 더 많은 이름을 찾는 것이 아니라, 더 작고, 더 최신이고, 검증되었으며, 출처를 이해할 수 있는 아웃리치 데이터셋을 만들어 실제로 회신을 받는 데 있습니다.
전체 워크플로우를 요약하면 다음과 같습니다.
- 어떤 도구를 쓰기 전에 ICP를 정의합니다.
- 리드 소스 2~3개를 선택합니다. 데이터베이스에 돈을 쓰기 전에 디렉터리, 회사 페이지, Google 연산자 같은 무료 소스부터 시작하세요.
- AI 스크래핑으로 리드를 추출합니다. Thunderbit의 2클릭 프로세스는 거의 모든 공개 페이지에서 작동합니다.
- 제대로 된 템플릿을 구성합니다. 소스 추적, 의도 신호, 스코어링 컬럼을 포함하세요.
- 검증하고 정리합니다. 역할 기반 이메일 제거, 중복 제거, 검증 실행, catch-all 표시가 필요합니다.
- 점수를 매기고 우선순위를 정합니다. 직감이 아니라 투명한 스프레드시트 모델을 쓰세요.
- CRM/아웃리치 도구로 내보냅니다. 수집한 데이터를 바탕으로 개인화합니다.
- 성과를 추적합니다. 리드 소스별 반송률, 회신율, 전환율을 보세요.
- 지속적으로 최신 상태로 유지합니다. 캠페인 전에 다시 검증하고, 고가치 소스는 일정에 맞춰 재스크래핑하세요.
데이터도 이를 뒷받침합니다. 회신율에서 거의 3배 더 좋은 성과를 냅니다. 검증된 200개짜리 리스트는 5,000개가 들어 있는 오래된 데이터베이스보다 거의 항상 더 잘 작동합니다.
첫 리스트를 만들 준비가 되셨나요? 은 월 6페이지의 AI 스크래핑, 무제한 무료 이메일 및 전화번호 추출, 그리고 Google Sheets 또는 Excel로의 내보내기를 제공합니다. 오늘 오후에 첫 50~100개 리드를 만들기에 충분합니다.
FAQ
첫 리드 리스트에는 몇 개의 리드가 있어야 하나요?
수천 개의 자격 미달 연락처보다, 잘 타깃팅되고 검증된 50~100개의 리드로 시작하세요. Hunter 데이터에 따르면 더 작고 촘촘한 리스트(21~50명)는 평균 6.2%의 회신율을 보이며, 501명 이상 리스트보다 거의 3배 높습니다. 품질은 누적되지만, 양은 희석됩니다.
리드 리스트를 사는 게 나을까요, 직접 만드는 게 나을까요?
대부분의 경우 직접 만드는 편이 훨씬 낫습니다. 구매한 리스트는 오래된 데이터, 스팸 트랩, 불투명한 출처, 컴플라이언스 리스크를 더 많이 안고 있습니다. AI 스크래핑과 수동 리서치를 활용해 직접 만든 리스트는 공개 페이지의 최신 정보를 사용하므로 더 신선하고 관련성도 높습니다. 만약 구매한다면 수집 날짜, 검증 날짜, 동의 근거, 갱신 프로세스의 투명성을 반드시 요구하세요.
무료로 리드 리스트를 만드는 가장 좋은 방법은 무엇인가요?
Google 고급 검색 연산자(site:, intitle:, exact-match 쿼리)와 Thunderbit 무료 플랜 — 월 6페이지의 AI 스크래핑과 무제한 무료 이메일/전화 추출 — 그리고 기본 LinkedIn 검색을 결합하세요. 이 조합이면 회사 페이지, 디렉터리, 이벤트 목록, 프로필을 한 푼도 쓰지 않고 커버할 수 있습니다.
리드 리스트는 얼마나 자주 업데이트해야 하나요?
특히 리스트가 30일 이상 되었다면, 모든 캠페인 전에 이메일을 다시 검증하세요. 최소 분기별로는 전체 갱신을 하세요 — 소스 재스크래핑, firmographics 업데이트, 죽은 리드 제거까지 포함합니다. ZeroBounce는 이메일 리스트의 최소 23%가 1년 안에 소멸한다고 보고하므로, "한 번 해두고 잊어버리기"는 반송률 상승의 지름길입니다.
리드 리스트 기반 콜드 아웃리치에서 좋은 회신율은 얼마인가요?
2025~2026 벤치마크 기준으로 보면, 긍정 회신율 3~5%는 양호, 5~8%는 강한 편, 8% 이상은 매우 좋습니다. 가장 큰 변수는 리스트 품질입니다. 타겟팅, 검증, 개인화가 핵심입니다. 검증된 이메일, 분명한 의도 신호, 개인화된 메시지가 있는 잘 만든 리스트는, 일반적인 연락처와 템플릿 문구만 있는 큰 리스트보다 일관되게 더 좋은 성과를 냅니다.
더 알아보기