웹 데이터는 말 그대로 폭증 중이고, 그 속도를 따라가야 한다는 압박도 점점 커지고 있죠. 현업에서 보면 영업팀이나 운영팀이 ‘의사결정’보다 스프레드시트 정리, 그리고 웹사이트에서 복사·붙여넣기 하는 데 시간을 더 많이 쓰는 경우가 정말 흔합니다. Salesforce에 따르면 영업 담당자는 이제 에 쓰고, Asana는 라고 말합니다. 수작업 데이터 수집에 빨려 들어가는 시간이 그만큼 크다는 뜻이죠. 그 시간만 아꼈어도 계약을 더 따내거나, 캠페인을 더 빨리 론칭할 수 있었을 겁니다.
다행히도, 여기엔 꽤 반가운 변화가 있습니다. 웹 스크래핑은 이제 더 이상 개발자만의 전유물이 아니에요. Ruby는 예전부터 웹 데이터 추출 자동화에 꾸준히 사랑받아 온 언어인데, 여기에 같은 최신 AI 웹 스크래퍼를 붙이면 ‘코드의 유연함’과 ‘노코드의 편리함’을 한 번에 챙길 수 있습니다. 마케터든, 이커머스 매니저든, 끝없는 복붙에 지친 누구든 이 가이드를 따라오면 ruby 웹 스크래핑을 Ruby와 AI로 제대로 써먹는 방법을 잡을 수 있습니다. 그리고 핵심 포인트 하나: 스크래핑 코드는 꼭 네가 직접 다 짤 필요가 없습니다.
Ruby로 하는 웹 스크래핑이란? 자동화된 데이터 수집의 출발점
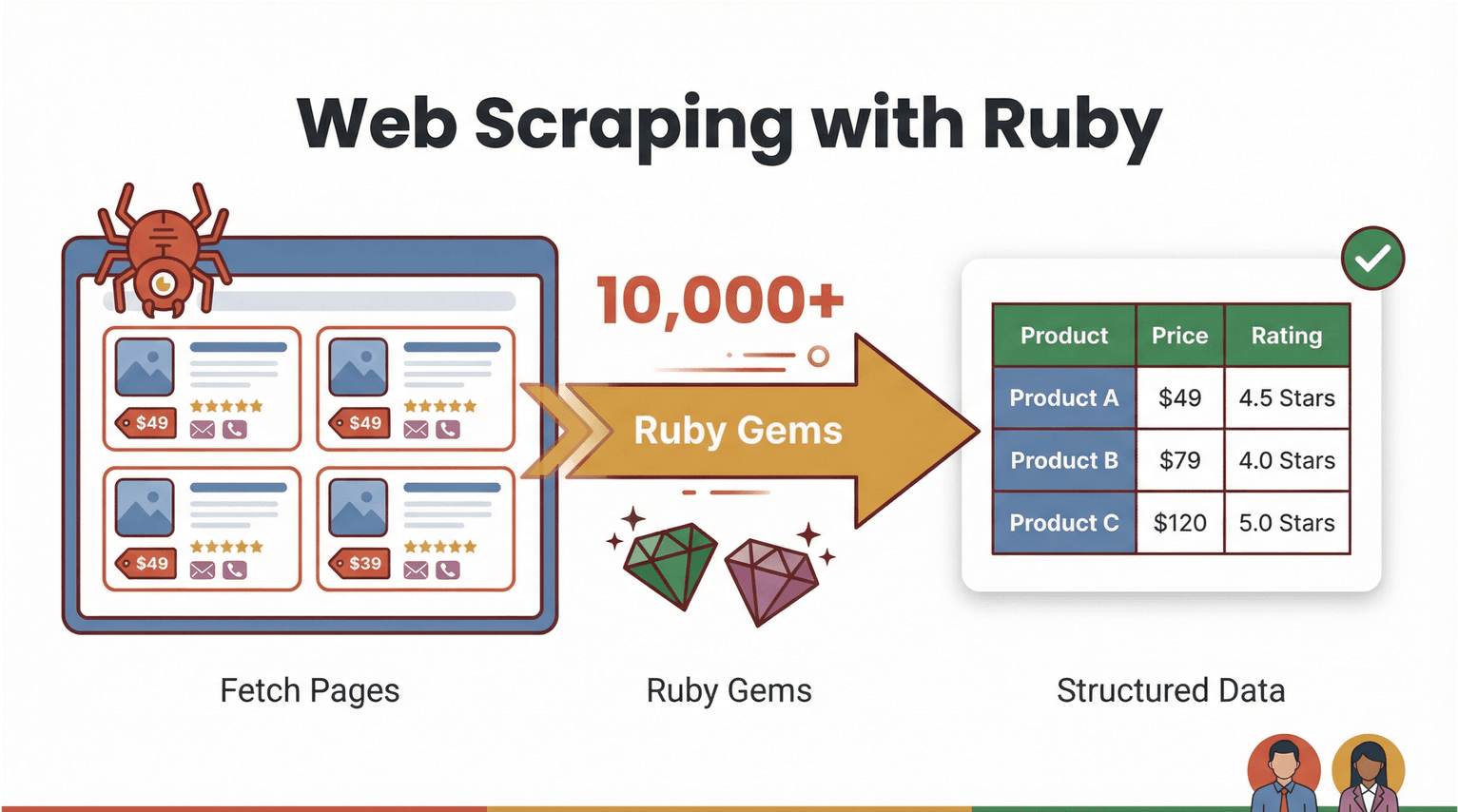
기본부터 깔끔하게 정리해볼게요. 웹 스크래핑은 프로그램으로 웹페이지를 불러온 다음, 상품 가격·연락처·리뷰처럼 필요한 정보만 쏙 뽑아 CSV나 Excel 같은 ‘정돈된 형태’로 바꿔주는 작업입니다. Ruby로 웹 스크래핑을 하면 강력하면서도 진입장벽이 낮은 편인데요. 문법이 비교적 읽기 쉽고, 자동화를 빠르게 만들어주는 방대한 “gem”(라이브러리) 생태계가 탄탄하기 때문입니다().
그럼 “Ruby로 웹 스크래핑”은 실제로 어떤 흐름일까요? 예를 들어 이커머스 사이트에서 상품명과 가격을 전부 가져오고 싶다고 해봅시다. Ruby 스크립트는 보통 아래 과정을 밟습니다.
- 웹페이지 다운로드(예: )
- HTML을 파싱해서 원하는 데이터 찾기(예: )
- 스프레드시트나 DB로 내보내기
그런데 요즘은 여기서 한 단계 더 재밌는 변화가 생겼습니다. 이제는 매번 코드를 짤 필요가 없다는 거예요. 같은 AI 기반 노코드 웹 스크래퍼가 페이지를 읽고, 뽑아야 할 필드를 알아서 감지하고, 몇 번 클릭만으로 깔끔한 데이터 테이블을 만들어 바로 내보내 줍니다. Ruby는 여전히 맞춤형 워크플로우를 이어주는 ‘자동화 접착제’로 훌륭하지만, AI 웹 스크래퍼 덕분에 비즈니스 사용자도 웹 데이터 자동화에 훨씬 쉽게 참여할 수 있게 됐죠.
비즈니스 팀에게 Ruby 웹 스크래핑이 중요한 이유

솔직히 하루 종일 데이터 복사·붙여넣기만 하고 싶은 사람은 없잖아요. 자동화된 웹 데이터 추출 수요가 폭발적으로 늘어나는 데는 다 이유가 있습니다. ruby 웹 스크래핑(그리고 AI 도구)이 비즈니스 운영을 어떻게 바꿔놓는지, 대표적인 사례를 보면 이렇습니다.
- 리드 생성: 디렉터리나 LinkedIn에서 연락처 정보를 빠르게 모아 영업 파이프라인을 채웁니다.
- 경쟁사 가격 모니터링: 수백 개 SKU의 가격 변동을 추적—이제 매일 수동 확인은 그만.
- 상품 카탈로그 구축: 자사 스토어/마켓플레이스에 올릴 상품 정보와 이미지를 한 번에 수집합니다.
- 시장 조사: 리뷰·평점·뉴스를 모아 트렌드를 읽고 분석합니다.
ROI는 꽤 명확합니다. 웹 데이터 수집을 자동화한 팀은 매주 몇 시간씩 시간을 아끼고, 실수를 줄이고, 더 최신이면서 신뢰도 높은 데이터를 확보합니다. 예를 들어 제조업에서는 데이터 양이 2년 만에 두 배로 늘었는데도, 여전히 하고 있다고 합니다. 자동화로 개선할 여지가 엄청 크다는 얘기죠.
Ruby와 AI 도구로 웹 스크래핑을 했을 때의 가치를 한눈에 보면 아래처럼 정리됩니다.
| 활용 사례 | 수작업의 고통 포인트 | 자동화의 이점 | 일반적인 결과 |
|---|---|---|---|
| 리드 생성 | 이메일을 하나씩 복사 | 수천 건을 몇 분 만에 추출 | 리드 10배, 반복 작업 감소 |
| 가격 모니터링 | 매일 사이트 확인 | 스케줄 기반 자동 가격 수집 | 실시간 가격 인사이트 |
| 카탈로그 구축 | 수동 데이터 입력 | 대량 추출 및 포맷 정리 | 출시 속도 향상, 오류 감소 |
| 시장 조사 | 리뷰를 직접 읽고 정리 | 대규모 수집 및 분석 | 더 깊고 최신의 인사이트 |
이건 단순히 “빠르다”의 문제가 아닙니다. 자동화는 실수를 줄이고 데이터의 일관성을 끌어올립니다. 실제로 고 답할 정도로, 데이터 품질은 지금도 큰 숙제예요.
웹 스크래핑 솔루션 비교: Ruby 스크립트 vs. AI 웹 스크래퍼 도구
그럼 결론적으로, Ruby로 직접 스크립트를 짜는 게 좋을까요? 아니면 AI 기반 노코드 웹 스크래퍼를 쓰는 게 더 나을까요? 선택지를 나눠서 보겠습니다.
Ruby 스크립팅: 완전한 제어, 대신 유지보수 부담
Ruby에는 스크래핑에 쓸 만한 gem이 정말 다양합니다.
- : HTML/XML 파싱의 사실상 표준.
- : 웹페이지 및 API 호출.
- : 쿠키·폼·페이지 이동이 필요한 사이트에 특히 유용.
- / : 실제 브라우저 자동화(자바스크립트 비중이 큰 사이트에 적합).
Ruby 스크립트의 가장 큰 장점은 유연성입니다. 맞춤 로직, 데이터 정제, 내부 시스템 연동까지 원하는 대로 설계할 수 있죠. 다만 사이트 레이아웃이 바뀌면 스크립트가 쉽게 깨질 수 있고, 코딩이 익숙하지 않다면 시작 자체가 부담일 수 있습니다.
AI 웹 스크래퍼 & 노코드 도구: 빠르고 쉬우며 변화에 강함
같은 최신 노코드 웹 스크래퍼는 접근 방식 자체를 바꿔놓습니다. 코드를 쓰는 대신, 보통 이런 흐름으로 끝나요.
- Chrome 확장 프로그램 열기
- “AI Suggest Fields”를 눌러 AI가 추출 항목을 자동으로 잡게 하기
- “Scrape”를 눌러 데이터 추출 및 내보내기
Thunderbit의 AI는 웹 레이아웃이 바뀌어도 비교적 유연하게 대응하고, 상품 상세 같은 하위 페이지(서브페이지)까지 처리하며, Excel/Google Sheets/Airtable/Notion으로 바로 내보낼 수 있습니다. “귀찮은 건 싫고 결과가 급하다”는 비즈니스 사용자에게 특히 잘 맞습니다.
표로 비교하면 더 직관적입니다.
| 방식 | 장점 | 단점 | 추천 대상 |
|---|---|---|---|
| Ruby 스크립팅 | 완전한 제어, 맞춤 로직, 높은 유연성 | 학습 난이도, 유지보수 필요 | 개발자, 고급 사용자 |
| AI 웹 스크래퍼 | 노코드, 빠른 설정, 변경에 강함 | 세밀한 제어는 제한적, 일부 한계 | 비즈니스 사용자, 운영팀 |
웹사이트가 점점 복잡해지고 방어도 강해지는 흐름 속에서, 많은 비즈니스 워크플로우가 AI 웹 스크래퍼 쪽으로 옮겨가는 건 자연스러운 수순입니다.
시작하기: Ruby 웹 스크래핑 환경 설정
Ruby 스크립팅을 직접 해보고 싶다면, 먼저 환경부터 세팅해봅시다. 좋은 소식은 Ruby가 설치가 비교적 쉽고 Windows/macOS/Linux 어디서든 잘 돌아간다는 점이에요.
1단계: Ruby 설치
- Windows: 를 받아 안내대로 설치하면 됩니다. Nokogiri 같은 gem의 네이티브 확장 빌드를 위해 MSYS2 포함 설치를 권장해요.
- macOS/Linux: 버전 관리를 위해 를 쓰는 게 편합니다. 터미널에서:
1brew install rbenv ruby-build
2rbenv install 4.0.1
3rbenv global 4.0.1(최신 안정 버전은 에서 확인하세요.)
2단계: Bundler 및 필수 gem 설치
Bundler는 의존성 관리를 깔끔하게 해주는 도구입니다.
1gem install bundler프로젝트에 Gemfile을 만들고:
1source 'https://rubygems.org'
2gem 'nokogiri'
3gem 'httparty'아래를 실행합니다.
1bundle install이렇게 해두면 스크래핑 환경을 일관되게 맞출 수 있어요.
3단계: 설치 확인
IRB(Ruby 대화형 셸)에서 아래를 실행해 보세요.
1require 'nokogiri'
2require 'httparty'
3puts Nokogiri::VERSION버전 번호가 찍히면 정상입니다.
단계별 가이드: 첫 Ruby 웹 스크래퍼 만들기
이제 실제 예제로 가볼게요. 스크래핑 연습용으로 유명한 에서 상품 데이터를 가져와 보겠습니다.
아래는 책 제목, 가격, 재고 상태를 뽑아오는 아주 기본적인 Ruby 스크립트입니다.
1require "net/http"
2require "uri"
3require "nokogiri"
4require "csv"
5BASE_URL = "https://books.toscrape.com/"
6def fetch_html(url)
7 uri = URI.parse(url)
8 res = Net::HTTP.get_response(uri)
9 raise "HTTP #\{res.code\} for #\{url\}" unless res.is_a?(Net::HTTPSuccess)
10 res.body
11end
12def scrape_list_page(list_url)
13 html = fetch_html(list_url)
14 doc = Nokogiri::HTML(html)
15 products = doc.css("article.product_pod").map do |pod|
16 title = pod.css("h3 a").first["title"]
17 price = pod.css(".price_color").text.strip
18 stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
19 { title: title, price: price, stock: stock }
20 end
21 next_rel = doc.css("li.next a").first&.[]("href")
22 next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
23 [products, next_url]
24end
25rows = []
26url = "#\{BASE_URL\}catalogue/page-1.html"
27while url
28 products, url = scrape_list_page(url)
29 rows.concat(products)
30end
31CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
32 rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
33end
34puts "Wrote #\{rows.length\} rows to books.csv"이 스크립트는 각 페이지를 가져오고, HTML을 파싱해 필요한 데이터를 뽑은 다음, CSV로 저장합니다. 만들어진 books.csv는 Excel이나 Google Sheets에서 바로 열 수 있어요.
자주 겪는 문제:
- gem 누락 오류가 뜨면 Gemfile을 확인하고
bundle install을 다시 돌려보세요. - 자바스크립트로 데이터를 불러오는 사이트는 Selenium이나 Watir 같은 브라우저 자동화 도구가 필요할 수 있습니다.
Thunderbit로 Ruby 스크래핑을 한 단계 업그레이드: AI 웹 스크래퍼 실전
이제 로 스크래핑을 훨씬 가볍게 하는 방법을 보겠습니다. 코드는 필요 없습니다.
Thunderbit는 어떤 웹사이트든 클릭 몇 번으로 구조화된 데이터를 뽑아주는 입니다. 흐름은 아래처럼 간단해요.
- 스크래핑할 페이지에서 Thunderbit 확장 프로그램 열기
- “AI Suggest Fields” 클릭: AI가 페이지를 훑고 “상품명/가격/재고” 같은 컬럼을 추천
- “Scrape” 클릭: 데이터 추출, 페이지네이션 처리, 필요하면 서브페이지까지 자동 방문
- 데이터 내보내기: Excel, Google Sheets, Airtable, Notion으로 바로 export
Thunderbit의 매력은 복잡하고 동적인 페이지도 코드나 깨지기 쉬운 셀렉터 없이 처리한다는 점입니다. 그리고 Thunderbit로 먼저 데이터를 뽑고, Ruby 스크립트로 후처리/보강하는 식으로 워크플로우를 섞어 쓰는 것도 충분히 가능합니다.
팁: Thunderbit의 서브페이지 스크래핑은 이커머스/부동산 팀에서 특히 빛을 봅니다. 상품 목록에서 링크를 먼저 모은 다음, 각 상세 페이지를 자동으로 방문해 스펙·이미지·리뷰까지 추가로 뽑아 데이터셋을 더 탄탄하게 만들 수 있어요.
실전 예시: Ruby와 Thunderbit로 이커머스 상품/가격 데이터 스크래핑
이커머스 팀 관점에서, 실제로 굴릴 수 있는 워크플로우로 묶어보겠습니다.
상황: 경쟁사 수백 개 SKU의 가격과 상품 정보를 계속 모니터링하고 싶다.
1단계: Thunderbit로 상품 목록 페이지 스크래핑
- 경쟁사 상품 리스트 페이지를 엽니다.
- Thunderbit 실행 → “AI Suggest Fields”(예: Product Name, Price, URL)
- “Scrape” 후 CSV로 내보내기
2단계: 서브페이지 스크래핑으로 데이터 보강
- Thunderbit의 “Scrape Subpages”로 각 상품 상세 페이지를 방문해 설명/재고/이미지 등 추가 필드를 추출
- 보강된 테이블을 다시 export
3단계: Ruby로 가공/분석
- Ruby 스크립트로 데이터 정리, 변환, 분석을 추가로 진행합니다. 예를 들면:
- 통화 단위 표준화
- 품절 상품 필터링
- 요약 통계 생성
아래는 재고가 있는 상품만 걸러내는 간단한 Ruby 예시입니다.
1require 'csv'
2rows = CSV.read('products.csv', headers: true)
3in_stock = rows.select { |row| row['stock'].include?('In stock') }
4CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
5 in_stock.each { |row| csv << row }
6end결과:
웹페이지 원본이 곧바로 ‘분석 가능한 데이터 테이블’로 바뀝니다. 가격 분석, 재고 계획, 마케팅 캠페인에 바로 써먹을 수 있고, 스크래핑 코드는 한 줄도 직접 안 써도 됩니다.
노코드로 충분합니다: 누구나 할 수 있는 웹 데이터 추출 자동화
Thunderbit의 큰 장점 중 하나는 비개발자도 바로 쓸 수 있다는 점입니다. Ruby, HTML, CSS를 몰라도 전혀 문제 없어요. 확장 프로그램을 열고 AI가 추천한 필드를 확인한 뒤 내보내기만 하면 끝입니다.
학습 난이도: Ruby 스크립트는 프로그래밍과 웹 구조에 대한 기본 이해가 필요합니다. 반면 Thunderbit는 설정이 ‘며칠’이 아니라 ‘몇 분’ 단위로 끝납니다.
연동: Thunderbit는 비즈니스 팀이 이미 쓰는 도구(Excel, Google Sheets, Airtable, Notion)로 바로 export합니다. 정기 모니터링이 필요하면 스케줄 스크래핑도 걸어둘 수 있어요.
현장 반응: 마케팅, 세일즈 오퍼레이션, 이커머스 매니저들이 IT 도움 없이도 리드 리스트 구축부터 가격 추적까지 자동화하는 사례를 자주 봤습니다.
베스트 프랙티스: Ruby + AI 웹 스크래퍼로 확장 가능한 자동화 만들기
안정적이고 확장 가능한 스크래핑 워크플로우를 만들고 싶다면 아래를 참고해보세요.
- 사이트 변경 대응: Thunderbit 같은 AI 웹 스크래퍼는 자동 적응력이 있지만, Ruby 스크립트는 사이트 변경 시 셀렉터 업데이트가 필요할 수 있습니다.
- 스케줄링: Thunderbit의 스케줄 기능으로 정기 수집을 자동화하세요. Ruby는 cron이나 작업 스케줄러를 활용할 수 있습니다.
- 배치 처리: 대량 수집은 배치로 나눠 차단 위험을 줄이고 시스템 부담을 낮추세요.
- 데이터 포맷/검증: 분석 전 데이터 정제와 검증은 필수입니다. Thunderbit export는 구조화되어 있지만, Ruby 커스텀 스크립트는 추가 체크가 필요할 수 있습니다.
- 컴플라이언스: 공개 데이터만 수집하고
robots.txt를 존중하며, 개인정보/프라이버시 법규를 유의하세요(특히 EU에서는 될 수 있습니다). - 대안 전략: 사이트가 너무 복잡하거나 차단이 심하면 공식 API나 다른 데이터 소스를 검토하세요.
언제 무엇을 쓰면 좋을까?
- 내부 시스템 연동, 맞춤 로직, 완전한 제어가 필요하면 Ruby 스크립트
- 빠른 결과, 쉬운 사용성, 레이아웃 변화 대응이 중요하면 Thunderbit
- 고급 워크플로우는 둘 다: Thunderbit로 추출 → Ruby로 보강/QA/연동
결론 및 핵심 정리
Ruby로 웹 스크래핑을 다루는 능력은 예전부터 강력한 자동화 무기였습니다. 그리고 이제 Thunderbit 같은 AI 웹 스크래퍼 덕분에 그 힘을 훨씬 더 많은 사람이 쉽게 가져다 쓸 수 있게 됐죠. 개발자는 유연성을 챙기고, 비즈니스 사용자는 번거로움 없이 결과를 얻습니다. 웹 데이터 추출을 자동화하면 수작업 시간을 줄이고, 더 빠르고 더 나은 의사결정을 할 수 있습니다.
이 글의 핵심만 다시 짚으면 이렇습니다.
- Ruby는 웹 스크래핑과 자동화에 매우 강력한 도구이며 Nokogiri, HTTParty 같은 gem이 큰 도움이 됩니다.
- Thunderbit 같은 AI 웹 스크래퍼는 비개발자도 쉽게 데이터 추출을 할 수 있게 해주며 “AI Suggest Fields”, 서브페이지 스크래핑 같은 기능이 핵심입니다.
- Ruby + Thunderbit 조합은 최고의 하이브리드: 빠른 노코드 추출 + 맞춤 자동화/분석.
- 영업/마케팅/이커머스 팀에게 웹 데이터 자동화는 전략 그 자체입니다. 반복 작업을 줄이고 정확도를 높이며 새로운 인사이트를 열어줍니다.
바로 시작해 볼까요? 로 직접 체감해 보고, 간단한 Ruby 스크립트도 한 번 실행해 보세요. 더 많은 가이드와 팁, 실전 사례는 에서 확인할 수 있습니다.
자주 묻는 질문(FAQs)
1. Thunderbit로 웹 스크래핑을 하려면 코딩을 알아야 하나요?
아니요. Thunderbit는 비기술 사용자도 쉽게 쓰도록 설계되었습니다. 확장 프로그램을 열고 “AI Suggest Fields”를 누르면 AI가 대부분을 처리합니다. Excel, Google Sheets, Airtable, Notion으로 내보내기도 가능하며 코딩은 필요 없습니다.
2. Ruby로 웹 스크래핑을 할 때의 주요 장점은 무엇인가요?
Ruby는 Nokogiri, HTTParty 같은 강력한 라이브러리를 통해 유연하고 맞춤형 스크래핑 워크플로우를 만들 수 있습니다. 완전한 제어, 커스텀 로직, 다른 시스템과의 연동이 필요한 개발자에게 특히 적합합니다.
3. Thunderbit의 “AI Suggest Fields”는 어떻게 동작하나요?
Thunderbit의 AI가 웹페이지를 스캔해 상품명, 가격, 이메일 등 핵심 데이터 필드를 자동으로 식별하고, 구조화된 테이블 형태로 컬럼을 제안합니다. 스크래핑 전에 필요에 따라 컬럼을 수정할 수도 있습니다.
4. Thunderbit와 Ruby 스크립트를 함께 써서 고급 워크플로우를 만들 수 있나요?
물론입니다. 많은 팀이 Thunderbit로(특히 복잡하거나 동적인 사이트에서) 데이터를 먼저 추출한 뒤, Ruby로 추가 가공이나 분석을 진행합니다. 맞춤 리포팅이나 데이터 보강에 매우 유용한 방식입니다.
5. 비즈니스에서 웹 스크래핑은 합법이고 안전한가요?
공개된 데이터를 수집하고, 사이트 이용약관과 개인정보 보호 법규를 준수한다면 일반적으로 합법적으로 활용할 수 있습니다. robots.txt를 확인하고, 특히 EU 사용자의 경우 GDPR 등 규정에 따라 동의 없이 개인정보를 수집하지 않도록 주의하세요.
웹 스크래핑으로 업무 흐름이 어떻게 달라질지 궁금한가요? Thunderbit의 무료 플랜을 써보거나 Ruby 스크립트를 직접 실험해 보세요. 막히는 부분이 있다면 와 에 튜토리얼과 팁이 풍부하게 정리되어 있습니다. 노코드 웹 스크래퍼만으로도 웹 데이터 자동화를 충분히 마스터할 수 있습니다.
더 알아보기