웹 데이터는 이제 진짜로 ‘21세기의 원유’라고 불릴 만큼 소중한 자원이 됐어요. 하지만 이 데이터들은 온갖 웹사이트에 흩어져 있고, 복잡한 HTML 구조나 CAPTCHA, 그리고 다양한 봇 차단 기술로 꽁꽁 숨겨져 있죠. 혹시 직접 손으로 제품 가격이나 경쟁사 정보, 리드 데이터를 복사해본 적 있다면, 손목 아프고 시간만 잡아먹는다는 걸 잘 아실 거예요. 그래서 요즘 웹 스크래핑은 현대 비즈니스에서 빼놓을 수 없는 핵심 역량이 됐습니다. 실제로 웹 스크래핑을 포함한 대체 데이터 시장은 규모로 빠르게 커지고 있어요.

여기서 중요한 포인트! 파이썬이 입문자들에게 인기 많지만, 사실 Go(또는 Golang)는 전 세계에서 가장 빠르고 안정적인 웹 스크래퍼를 조용히 뒷받침하고 있다는 사실입니다. Go의 진짜 매력은? 강력한 동시성, 탄탄한 표준 라이브러리, 그리고 백엔드 개발자들이 반할 만한 퍼포먼스죠. 실제로 Go로 전환한 팀들은 스크래핑 속도가 절반 이하로 줄기도 했어요. 게다가 제대로 된 도구만 있으면, 구글 엔지니어가 아니어도 누구나 쉽게 시작할 수 있습니다.
Go로 웹 스크래핑 실력을 키우고 싶으신가요? 환경 세팅부터 고급 스크래핑, 실전 코드와 꿀팁, 그리고 같은 AI 도구까지 5단계로 쫙 정리해드릴게요.
Go로 웹 스크래핑을 선택해야 하는 이유: 비즈니스 관점
수천, 수백만 페이지를 스크래핑할 때 1초도 아깝죠. Go는 이런 대규모 작업에 딱 맞는 언어입니다. 기업들이 Go를 웹 스크래핑에 선택하는 이유는 다음과 같아요:
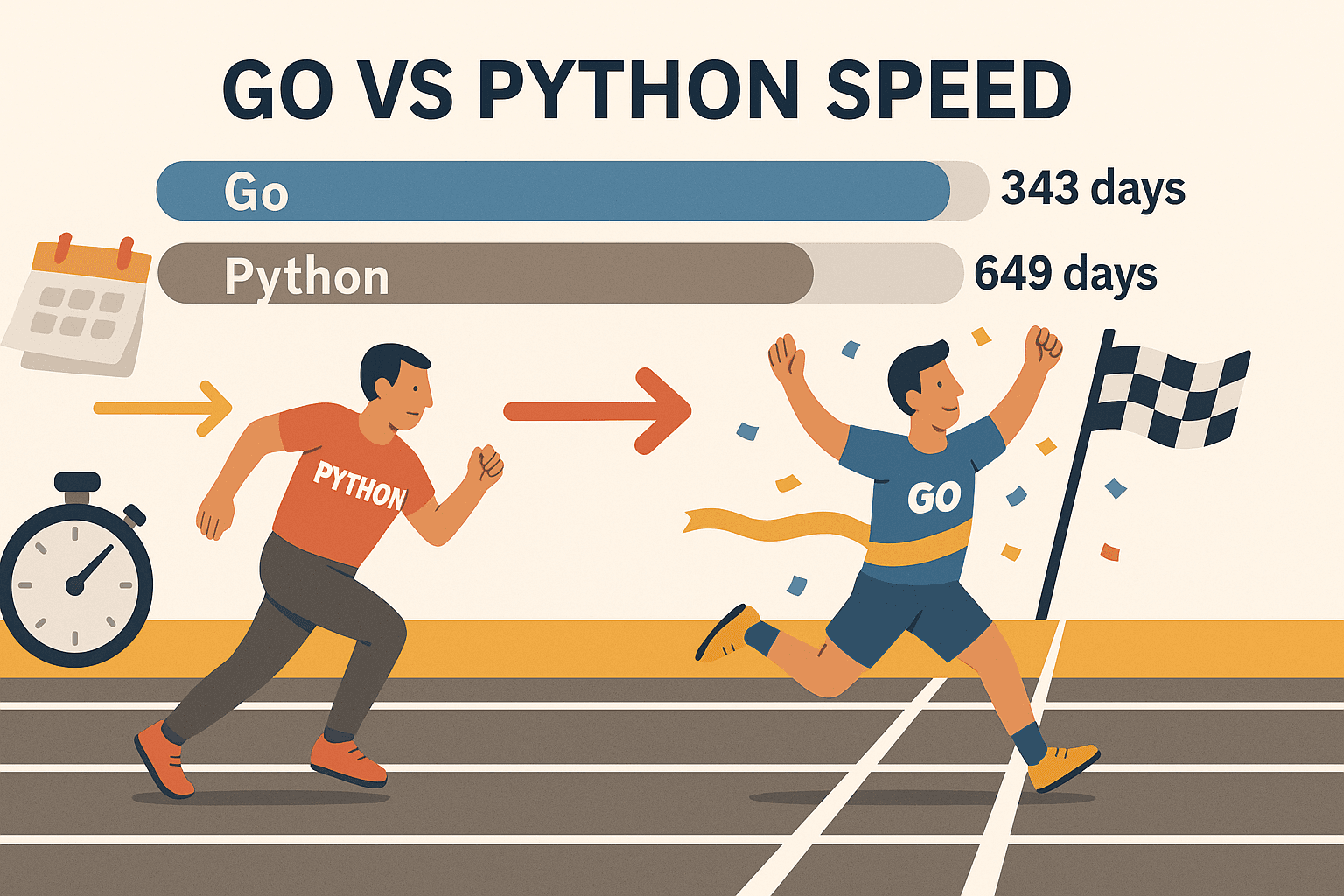
- 확장성 있는 동시성: Go의 고루틴(경량 스레드) 덕분에 수백 개 페이지를 동시에 스크래핑해도 노트북이 버팁니다. 한 벤치마크에 따르면 Go는 만에 처리했지만, 파이썬은 같은 작업에 649일이 걸렸어요. 그냥 빠른 게 아니라, 차원이 다릅니다.
- 안정성과 신뢰성: Go는 강한 타입과 효율적인 메모리 관리로 대규모, 장시간 크롤러에 딱이에요. 새벽에 스크립트 멈추는 일도 확 줄어듭니다.
- 강력한 네트워킹: Go 표준 라이브러리만으로 HTTP 요청, HTML 파싱, JSON 처리까지 다 됩니다. 별도 패키지 찾느라 헤맬 필요 없어요.
- 간편한 배포: Go는 단일 바이너리로 컴파일돼서 어디서든 실행 가능! 가상환경이나 복잡한 의존성 관리 필요 없습니다.
- 업계 채택: Go는 현재 로 Node.js를 제쳤고, Google, Uber, Netflix 등 대기업에서도 신뢰받고 있어요.
물론, 파이썬은 빠른 프로토타입이나 머신러닝 라이브러리가 필요할 때 여전히 좋습니다. 하지만 속도, 확장성, 안정성이 중요하다면 Go가 진짜 답이에요. 특히 Colly, Goquery 같은 라이브러리와 함께라면 더 강력하죠.
1단계: Go 환경 세팅하기
스크래핑을 시작하려면 먼저 Go 개발 환경부터 준비해야겠죠? 다행히 설치 과정이 정말 간단합니다.
1. Go 설치
- 에서 운영체제(Windows, macOS, Linux)에 맞는 설치 파일을 받으세요.
- 설치 파일 실행하고 안내에 따라 설치하면 끝! Linux는 패키지 매니저로도 설치할 수 있어요.
- 터미널에서 아래 명령어를 입력해보세요:
1go versiongo version go1.21.0 darwin/amd64처럼 나오면 성공입니다.
문제 생겼을 때: go 명령어가 안 먹힌다면 PATH 설정을 확인하세요. Linux/macOS는 export PATH=$PATH:/usr/local/go/bin을 ~/.bash_profile이나 ~/.zshrc에 추가해야 할 수도 있어요.
2. 새 Go 프로젝트 만들기
- 스크래퍼용 새 폴더를 만드세요:
1mkdir my-scraper && cd my-scraper - Go 모듈을 초기화합니다:
이 과정에서 의존성 관리용1go mod init github.com/yourname/my-scrapergo.mod파일이 생깁니다.
3. 에디터 선택
- 와 Go 확장팩(자동완성, 린트, 디버깅 지원) 추천!
- JetBrains GoLand도 Go 개발자들 사이에서 인기 많아요.
- Vim/Neovim에 Go 플러그인 추가해서 써도 좋습니다.
4. 환경 테스트
간단한 main.go 파일을 만들어보세요:
1package main
2import "fmt"
3func main() {
4 fmt.Println("Go is installed and working!")
5}실행:
1go run main.go메시지가 잘 나오면 준비 끝!
2단계: Go로 첫 HTTP 요청 보내기
이제 첫 웹페이지를 불러와볼까요? Go의 net/http 패키지로 정말 쉽게 할 수 있어요.
기본 HTTP GET 예시:
1package main
2import (
3 "fmt"
4 "io"
5 "net/http"
6)
7func main() {
8 resp, err := http.Get("https://example.com")
9 if err != nil {
10 fmt.Println("Error fetching the URL:", err)
11 return
12 }
13 defer resp.Body.Close()
14 body, err := io.ReadAll(resp.Body)
15 if err != nil {
16 fmt.Println("Error reading the response body:", err)
17 return
18 }
19 fmt.Println(string(body))
20}중요 포인트:
http.Get다음엔 항상 에러 체크!defer resp.Body.Close()로 리소스 누수 방지.io.ReadAll로 전체 응답을 읽을 수 있습니다.
꿀팁:
- 브라우저 User-Agent 등 커스텀 헤더를 추가하려면
http.NewRequest를 써보세요:1req, _ := http.NewRequest("GET", "https://example.com", nil) 2req.Header.Set("User-Agent", "Mozilla/5.0") 3client := &http.Client{} 4resp, err := client.Do(req) resp.StatusCode도 꼭 확인! 200이면 성공, 403/404면 차단 또는 페이지 없음입니다.
3단계: Go로 HTML 파싱 및 데이터 추출하기
HTML만 받아오면 끝이 아니죠. 이제 제품명, 가격, 링크 등 원하는 정보를 뽑아내야 합니다.
Goquery 소개: jQuery 스타일 셀렉터로 HTML을 파싱할 수 있는 Go 라이브러리입니다.
Goquery 설치:
1go get github.com/PuerkitoBio/goquery예시: 제품명과 가격 추출
1package main
2import (
3 "fmt"
4 "net/http"
5 "github.com/PuerkitoBio/goquery"
6)
7func main() {
8 resp, err := http.Get("https://example.com/products")
9 if err != nil {
10 panic(err)
11 }
12 defer resp.Body.Close()
13 doc, err := goquery.NewDocumentFromReader(resp.Body)
14 if err != nil {
15 panic(err)
16 }
17 doc.Find("div.product").Each(func(i int, s *goquery.Selection) {
18 name := s.Find("h2").Text()
19 price := s.Find(".price").Text()
20 fmt.Printf("Product %d: %s - %s\n", i+1, name, price)
21 })
22}작동 방식:
doc.Find("div.product")로 모든 제품 컨테이너를 선택.- 각 컨테이너에서
s.Find("h2").Text()로 제품명,s.Find(".price").Text()로 가격 추출.
정규표현식: 이메일 등 간단한 패턴은 Go의 regexp 패키지로 처리할 수 있지만, 복잡한 HTML 구조는 Goquery가 훨씬 편해요.
4단계: Go 라이브러리(Colly & Gocolly)로 스크래퍼 업그레이드
한 단계 더 나아가고 싶다면 를 추천합니다. Colly는 크롤링, 동시성, 쿠키 관리 등 웹 스크래핑에 필요한 기능을 다 갖췄어요.
Colly의 장점:
- 간단한 API: 원하는 요소에 콜백만 등록하면 끝.
- 동시성:
colly.Async(true)로 수백 페이지를 병렬로 스크래핑 가능. - 자동 크롤링: 링크 추적, 페이지네이션도 쉽게 처리.
- 안티봇 대응: 커스텀 헤더, User-Agent 회전, 쿠키 관리 등 지원.
- 에러 처리: 실패한 요청에 대한 훅 제공.
Colly 설치:
1go get github.com/gocolly/colly/v2Colly 기본 예제:
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly/v2"
5)
6func main() {
7 c := colly.NewCollector(
8 colly.AllowedDomains("example.com"),
9 colly.Async(true),
10 )
11 c.OnHTML(".product-list-item", func(e *colly.HTMLElement) {
12 name := e.ChildText("h2")
13 price := e.ChildText(".price")
14 fmt.Printf("Product: %s - %s\n", name, price)
15 })
16 c.OnRequest(func(r *colly.Request) {
17 r.Headers.Set("User-Agent", "Mozilla/5.0")
18 })
19 c.OnError(func(r *colly.Response, err error) {
20 fmt.Println("Request failed:", r.Request.URL, "->", err)
21 })
22 c.Visit("https://example.com/products")
23 c.Wait()
24}Goquery vs. Colly 기능 비교
| 기능 | Goquery | Colly |
|---|---|---|
| HTML 파싱 | 지원 | 지원 (내부적으로 Goquery 사용) |
| HTTP 요청 | 수동 처리 | 내장 지원 |
| 동시성 | 수동 (고루틴) | 간편 (Async(true)) |
| 크롤링/링크 추적 | 수동 | 자동 지원 |
| 안티봇 대응 | 수동 | 내장 지원 |
| 에러 처리 | 수동 | 내장 지원 |
Colly는 단순한 스크래핑을 넘어서는 작업에 진짜 시간을 아껴줍니다.
5단계: Go 웹 스크래핑 실전 문제 해결법
실제 웹 스크래핑은 생각보다 까다로운 문제들이 많아요. 주요 이슈별 대응법을 정리해봤어요:
1. IP 차단
- Go의
http.Transport나 Colly의 프록시 기능으로 프록시를 순환 사용하세요. - 요청 간 랜덤 딜레이도 추가해보세요.
2. User-Agent 및 헤더
- 항상 실제 브라우저와 비슷한 User-Agent를 사용하세요.
- Accept-Language 등 브라우저 헤더도 같이 세팅하면 효과적입니다.
3. CAPTCHA
- CAPTCHA가 뜬다면 너무 빠르거나 봇으로 인식된 경우입니다.
- 같은 헤드리스 브라우저로 시각적 상호작용이 필요한 사이트를 공략하세요.
- 강력한 안티봇 사이트는 CAPTCHA 솔버 서비스 연동도 고려해보세요.
4. 페이지네이션
- Colly에서는 “다음” 링크를 자동으로 따라가게 할 수 있습니다:
1c.OnHTML("a.next", func(e *colly.HTMLElement) { 2 e.Request.Visit(e.Attr("href")) 3})
5. 동적 콘텐츠(JavaScript)
- Go의 HTTP 라이브러리는 JS 실행이 안 됩니다. Rod, chromedp 같은 헤드리스 브라우저를 쓰거나, API 엔드포인트를 직접 찾는 방법도 있어요.
6. 너무 복잡하다면… Thunderbit 활용
사이트가 너무 동적이거나, 빠르게 데이터가 필요할 때는 가 해답입니다. Thunderbit는 AI 기반 웹 스크래퍼 크롬 확장 프로그램으로:
- AI가 필드를 자동 감지 및 추출(“AI 컬럼 추천” 클릭만으로 가능)
- 하위 페이지 이동, 페이지네이션도 자동 처리
- 실제 브라우저(또는 클라우드)에서 실행되어 JS 기반 사이트와 대부분의 안티봇도 대응
- 엑셀, 구글 시트, Airtable, Notion 등으로 바로 내보내기(코딩 불필요)
- 스케줄링 및 팀 단위 자동화 지원
Thunderbit는 비즈니스 사용자, 영업팀, 데이터가 필요한 누구에게나 반복 작업을 줄여주는 필수 도구입니다. 저 역시 이런 문제를 해결하려고 직접 개발했어요.
Go와 Thunderbit의 시너지: 생산성 극대화
비밀은 바로 이거! Go와 Thunderbit를 굳이 하나만 고를 필요 없이, 같이 쓰면 최고의 효율을 낼 수 있습니다.
예시 워크플로우:
- Go(Colly 활용)로 대량 URL 수집 및 기본 데이터 크롤링
- Thunderbit에 URL을 입력해 상세 정보, 동적 콘텐츠, 하위 페이지 등 복잡한 데이터 추출
- Thunderbit에서 구글 시트나 CSV로 데이터 내보내기
- Go로 데이터 후처리, 병합, 분석 등 추가 작업
이런 하이브리드 방식은 Go의 속도와 제어력, Thunderbit의 AI와 유연성을 모두 누릴 수 있어요. 마치 스위스 아미 나이프와 전동 드릴을 동시에 갖춘 느낌!
Go 웹 스크래핑 솔루션 비교: 순수 Go vs. Colly vs. Thunderbit
아래 표로 각 도구의 특징을 한눈에 비교해보세요:
| 항목 | 순수 Go (net/http + html) | Go + Colly (라이브러리) | Thunderbit (AI 노코드) |
|---|---|---|---|
| 환경설정/학습 난이도 | 높음 (코딩 필요) | 중간 (간편 API) | 가장 쉬움 (코드 불필요, AI 기반) |
| 동시성 | 수동 (고루틴) | 내장 (Async(true)) | 클라우드/브라우저 병렬 처리 |
| 동적 콘텐츠(JS) | 헤드리스 브라우저 필요 | 일부 JS 지원, 또는 Rod | 완전한 브라우저, JS 네이티브 처리 |
| 안티봇 대응 | 수동 (프록시, 헤더) | 내장 기능 | 대부분 자동, 클라우드 IP |
| 데이터 구조화 | 커스텀 코드 | 콜백, 커스텀 구조체 | AI 추천, 자동 포맷 |
| 내보내기 옵션 | 커스텀 (CSV, DB 등) | 커스텀 | 엑셀, 시트, Notion, Airtable |
| 유지보수 | 높음 (코드 자주 수정) | 중간 | 낮음 (AI가 사이트 변화에 적응) |
| 적합 대상 | 개발자, 커스텀 파이프라인 | 개발자, 빠른 프로토타입 | 비개발자, 비즈니스 사용자 |
팁: 대규모, 커스텀, 백엔드 연동 프로젝트에는 Go/Colly를, 빠른 작업이나 복잡한 프론트엔드 사이트에는 Thunderbit를 활용하세요.
핵심 요약: Go로 웹 스크래핑 시작하기
- Go는 웹 스크래핑에 최적화된 언어입니다. 속도, 동시성, 안정성이 필요할 때 특히 강력합니다.
- 기본부터 시작: Go 환경을 세팅하고, HTTP 요청, Goquery로 HTML 파싱을 익혀보세요.
- Colly로 업그레이드: 크롤링, 동시성, 안티봇 대응까지 Colly가 도와줍니다.
- 실전 문제 해결: 프록시 순환, 헤더 세팅, 헤드리스 브라우저, Thunderbit 등 다양한 방법을 활용하세요.
- 도구 조합: Go와 Thunderbit를 함께 쓰면 최고의 효율을 경험할 수 있습니다.
웹 스크래핑은 영업, 운영, 리서치팀의 생산성을 극대화하는 무기입니다. Go와 다양한 라이브러리, 그리고 AI까지 더하면 반복 작업은 자동화하고, 비즈니스에 중요한 인사이트에 집중할 수 있습니다.
Go 웹 스크래핑 추가 자료
더 깊이 배우고 싶으신가요? 추천 자료를 소개합니다:
즐거운 스크래핑 하세요! 데이터는 항상 잘 정리되고, 스크래퍼는 빠르며, 커피는 진하게!
자주 묻는 질문(FAQ)
1. 왜 Go로 웹 스크래핑을 해야 하나요? 파이썬이나 자바스크립트보다 좋은 점은?
Go는 동시성, 속도, 안정성에서 정말 뛰어납니다. 대규모, 장시간 스크래핑에 특히 강하고, 컴파일된 이식성 높은 바이너리로 어디서든 실행할 수 있어요.
2. Go에서 HTML 파싱을 가장 쉽게 하는 방법은?
라이브러리를 써보세요. jQuery처럼 DOM을 탐색하고 데이터를 추출할 수 있습니다.
3. JavaScript로 렌더링되는 사이트는 Go에서 어떻게 처리하나요?
나 같은 헤드리스 브라우저 라이브러리를 활용하세요. 또는 를 쓰면 별도 코딩 없이 브라우저 기반으로 JS까지 자동 처리됩니다.
4. 스크래핑 중 차단을 피하려면 어떻게 해야 하나요?
User-Agent를 바꾸고, 프록시를 사용하며, 요청 간 딜레이를 추가하고, 실제 브라우저와 비슷한 행동을 모방하세요. Colly는 이런 기능을 쉽게 제공하고, Thunderbit는 대부분의 안티봇을 자동으로 처리합니다.
5. Go와 Thunderbit를 함께 쓸 수 있나요?
당연하죠! 대규모 크롤링이나 백엔드 연동에는 Go를, AI 기반 추출, 하위 페이지 스크래핑, 비즈니스 툴로 내보내기에는 Thunderbit를 활용하세요. 개발자와 비즈니스 사용자 모두에게 강력한 조합입니다.
웹 스크래핑 실력을 한 단계 업그레이드하고 싶으신가요? 또는 에서 더 많은 팁, 튜토리얼, 심층 자료를 확인해보세요.