인터넷은 세상에서 가장 큰 도서관이지만, 그 안의 책들은 마치 본드로 꽁꽁 붙여 놓은 것 같죠. 비즈니스 오너, 마케터, 영업팀과 매일 이야기를 나누다 보면 웹페이지 곳곳에 숨어 있는 보물—제품 정보, 경쟁사 가격, 고객 리뷰, 연락처 같은 것—을 꺼내고 싶어 하지만, 막상 텍스트를 빼내는 게 생각보다 까다롭더라고요. SaaS와 자동화 업계에서 오래 일하면서 ‘복붙 마라톤’이나 ‘파이썬 직접 도전기’를 정말 많이 봐 왔거든요. 다행히 요즘은 AI 웹 스크래퍼와 똑똑한 브라우저 확장 덕분에 웹사이트에서 텍스트를 꺼내는 일이 한결 가벼워졌어요.
이 글에서는 가장 기본적인 복사·붙여넣기부터 Thunderbit(저희가 직접 만든 도구라서 장단점은 솔직하게 적어 둘게요) 같은 AI 기반 솔루션까지, 실전에서 바로 써먹을 수 있는 방법을 단계별로 정리해 볼게요. 엑셀이 손에 익은 분이든, 개발자든, 웹페이지에서 텍스트 찾는 일에 슬슬 지친 분이든 자기에게 맞는 방법을 찾을 수 있을 거예요. 자, 디지털 책장을 활짝 열고 필요한 정보를 꺼내 볼 시간이에요.
웹사이트에서 텍스트 추출, 이게 뭘까?
‘웹사이트에서 텍스트를 추출한다’는 건, 웹페이지에 보이는(혹은 안 보이는) 정보를 뽑아내서 엑셀이나 데이터베이스, 워드 문서 같은 원하는 형태로 정리해 두는 일이에요. 그런데 웹사이트 텍스트는 종류가 꽤 다양해서, 종류에 따라 접근 방식도 달라져요.
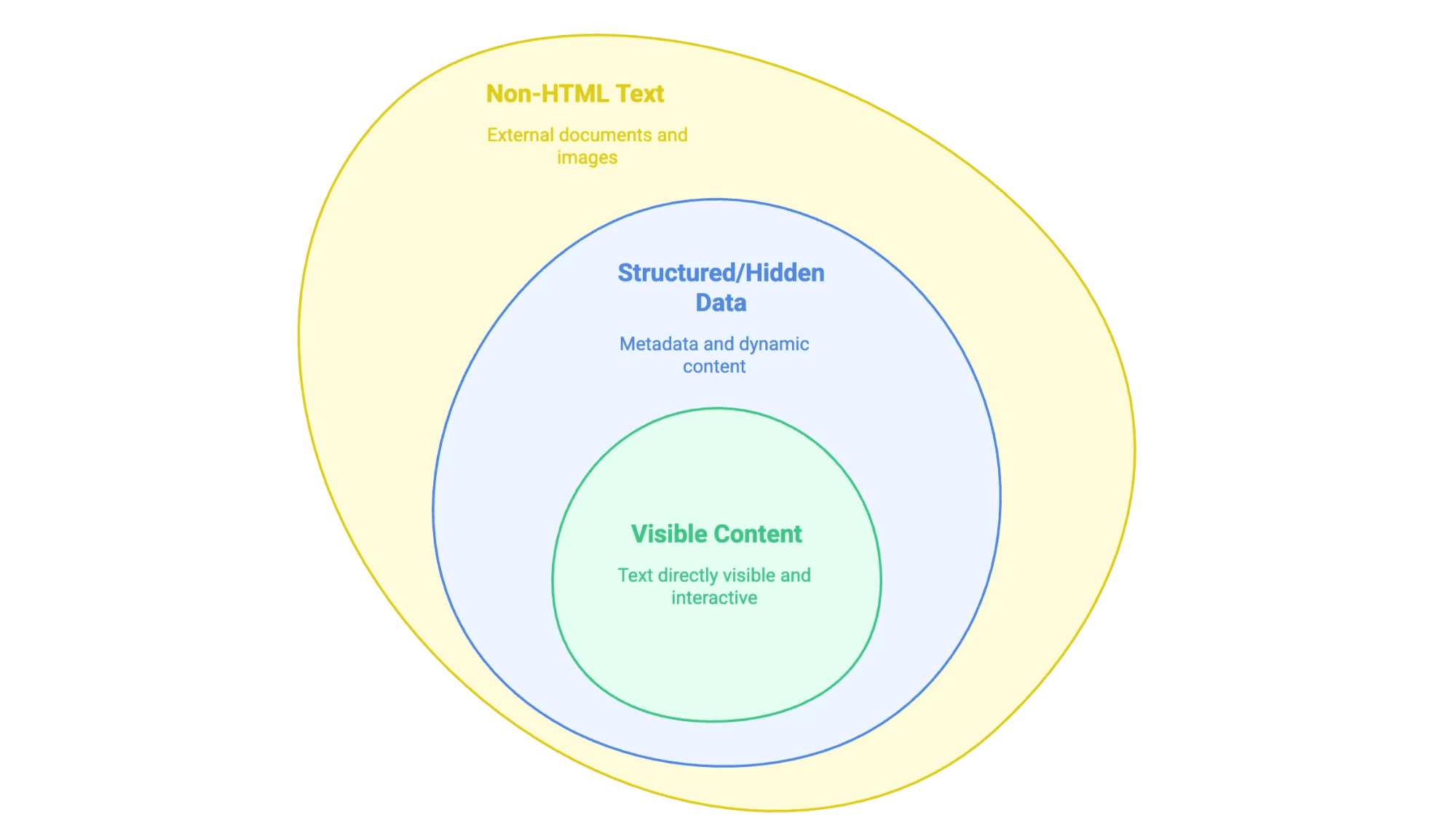
- 눈에 보이는 콘텐츠: 마우스로 드래그해서 복사할 수 있는 본문, 제목, 리스트, 표, 제품 설명, 블로그 글 같은 것들이에요.
- 구조화돼 있거나 숨겨진 데이터:
<meta>태그 안의 메타데이터, JSON-LD 스크립트, 클릭하거나 스크롤해야 나타나는 자바스크립트 기반 정보 등이에요. - HTML이 아닌 텍스트: PDF, 워드 문서, 이미지(스캔된 계약서, 인포그래픽 등) 안에 들어 있는 텍스트도 있어요.
어떤 데이터를 뽑고 싶은지에 따라 어울리는 방법도 달라지거든요.
왜 웹사이트에서 텍스트를 추출할까? 비즈니스에서의 활용
솔직히 취미로 웹사이트 텍스트를 추출하는 사람은 거의 없잖아요. 기업들이 이 작업에 시간과 비용을 쓰는 이유는 그만큼 확실한 이득이 따라오기 때문이에요. 웹 스크래핑 소프트웨어 시장은 했고, 앞으로도 계속 커질 거라는 전망이 많거든요. 이유를 살펴보면 이래요.
| 팀 | 활용 예시 | 이점 |
|---|---|---|
| 영업 | 디렉터리에서 리드 및 연락처 추출 | 더 빠르고 풍부한 잠재고객 확보 |
| 마케팅 | 경쟁사 블로그 및 SEO 데이터 추출 | 콘텐츠 분석, 트렌드 파악 |
| 운영 | 이커머스 사이트 가격 모니터링 | 동적 가격 책정, 재고 관리 |
| 부동산 | 매물 및 상세 정보 수집 | 시장 분석, 리드 생성 |
| 고객지원 | 리뷰 및 포럼 Q&A 수집 | 감정 분석, 이슈 조기 발견 |
실제 사례로 보면 이래요.

- 리드 생성: 한 식자재 업체는 을 몇 분 만에 끝냈어요.
- 경쟁사 모니터링: John Lewis 같은 리테일러는 고 알려져 있고요.
- SEO 분석: 팀에서는 메타 태그와 키워드를 뽑아 와서 해요.
AI 기반 도구를 쓰면 는 데이터도 있더라고요.
수작업 방법: 복사·붙여넣기로 웹사이트 텍스트 추출하기
가장 기본적인 방법부터 시작해 볼까요? 양이 적은 정보라면 별다른 도구 없이도 충분하거든요.
수동으로 텍스트 추출하는 방법
- 복사 & 붙여넣기: 페이지에서 원하는 텍스트를 드래그한 다음 Ctrl+C(또는 우클릭 > 복사)로 복사해서 문서나 스프레드시트에 붙여넣어요.
- 페이지 저장: 브라우저에서 파일 > 다른 이름으로 저장. ‘웹페이지, HTML만’으로 저장하면 원본 HTML이, .txt로 저장하면 텍스트만 남아요.
- PDF로 저장: 브라우저 인쇄 기능에서 ‘PDF로 저장’을 선택해요. PDF에서 직접 텍스트를 복사하거나 PDF 리더의 ‘텍스트로 저장’ 기능을 써도 되고요.
- 개발자 도구: 우클릭 > 검사 또는 F12로 DevTools를 열면, HTML 소스나 메타 태그, 숨겨진 JSON 같은 정보를 그대로 복사해 올 수 있어요.
한계점
수작업은 작은 작업엔 괜찮은데, 양이 많아지면 비효율이 금방 드러나요. . 인턴이 표를 한 줄씩 복사하느라 며칠을 보내는 광경도 적지 않게 봐 왔는데, 솔직히 누구도 그런 일은 하고 싶지 않잖아요.
브라우저 확장 프로그램과 온라인 도구로 웹사이트 텍스트 추출하기
조금 더 효율적으로 작업하고 싶다면, 브라우저 확장과 온라인 도구가 비즈니스 사용자에게 딱이에요. 코딩 없이 클릭 몇 번으로 데이터를 꺼내올 수 있거든요.
이런 도구를 써야 하는 이유

- 수작업보다 훨씬 빨라요
- 프로그래밍 지식이 따로 없어도 돼요
- 표, 리스트, 파일 등 다양한 데이터를 다룰 수 있어요
- 엑셀, 구글 시트, CSV 같은 포맷으로 바로 내보내기가 돼요
대표적인 도구들을 하나씩 살펴볼게요.
Thunderbit: 빠르고 정확한 AI 웹 스크래퍼
조금 자랑처럼 들릴 수 있지만, 는 웹 텍스트 추출을 정말 단순하게 만들어 줘요. 사용법은 이래요.
Thunderbit로 텍스트 추출하는 단계별 방법
- 크롬 확장 프로그램 설치:
- 웹사이트 접속: 추출하고 싶은 페이지로 이동해요.
- ‘AI 필드 추천’ 클릭: Thunderbit AI가 페이지를 읽고 뽑을 만한 필드(예: 제품명, 가격, 설명 등)를 알아서 제안해 줘요.
- 필드 확인 및 수정: 추천된 필드를 직접 손보거나 추가할 수 있어요.
- ‘스크랩’ 클릭: Thunderbit가 데이터를 자동으로 수집해 줘요. 하위 페이지나 페이지네이션도 같이 따라가고요.
- 내보내기: 엑셀, 구글 시트, Airtable, Notion, CSV/JSON 같은 다양한 포맷으로 무료로 내보낼 수 있어요.
Thunderbit만의 차별점
- AI 기반 필드 추천: 복잡한 셀렉터나 코딩 없이도 AI가 중요한 정보를 알아서 골라 줘요.
- 하위 페이지 및 페이지네이션 지원: 카테고리 안에 있는 모든 제품 상세 정보까지 자동으로 따라가서 모아 줘요.
- PDF, 이미지, 문서까지 추출: PDF 매뉴얼이나 제품 이미지에 들어 있는 텍스트도 내장 OCR로 꺼낼 수 있어요.
- 다국어 지원: 34개 언어를 지원해요(클링온어는 아직 준비 중이에요).
- 무료 데이터 내보내기: 데이터 추출 후 추가 비용 없이 내보낼 수 있어요.
- 활용 예시: 제품 설명, 연락처, 블로그 콘텐츠, 리드 리스트 등 다양한 비즈니스 데이터에 잘 어울려요.
실제 사용법이 궁금하다면 에서 같은 가이드를 한번 둘러보세요.
기타 브라우저 확장 프로그램 및 온라인 도구
다른 인기 도구들도 짧게 정리해 둘게요.
- Web Scraper(): 무료에 포인트-앤-클릭 방식이긴 한데, 익숙해지는 데 시간이 좀 들어요. 기술에 어느 정도 익숙한 분석가에게 잘 맞고, ‘사이트맵’과 셀렉터를 직접 설정해 줘야 해요. 페이지네이션은 되지만 PDF나 이미지는 안 되고요.
- CopyTables: HTML 표를 복사해서 클립보드나 엑셀로 곧장 붙여넣을 수 있는 아주 단순한 도구예요. 표만 빠르게 빼낼 때는 편리한데, 한 번에 한 페이지씩만 되고 표 외엔 안 돼요. .
- ScraperAPI(): 개발자용 도구라 URL을 보내면 HTML을 돌려줘요(프록시, 차단 우회 같은 기능도 들어 있고요). 다만 텍스트 파싱은 직접 해 줘야 해요.
어떤 도구를 언제 써야 할까?
- Thunderbit: 빠른 속도, AI 지원, 다양한 포맷(PDF/이미지 포함) 추출이 필요할 때.
- Web Scraper: 세밀한 설정과 제어가 필요하고, 기술에 어느 정도 익숙할 때.
- CopyTables: 표만 빠르게 추출하고 싶을 때.
- ScraperAPI: 직접 코드로 스크래퍼를 만들고 싶을 때.
자동화 웹 스크래핑: 개발자를 위한 프로그래밍 방식
개발자라면 직접 스크래퍼를 코딩해서 완벽하게 통제할 수 있어요. 기본 흐름은 이래요.
- HTTP 요청 보내기: Python의
requests같은 라이브러리로 페이지를 가져와요. - HTML 파싱:
BeautifulSoup,lxml,Scrapy같은 도구로 원하는 텍스트를 찾아내요. - 추출 및 내보내기: 텍스트를 뽑아내고 정제해서 CSV, JSON, 데이터베이스 같은 곳에 저장해요.
예시: Python + Beautiful Soup
1import requests
2from bs4 import BeautifulSoup
3url = "<http://quotes.toscrape.com>"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
7for qt in quotes:
8 print(qt)장단점
- 장점: 어떤 사이트든, 어떤 데이터든 다룰 수 있고, 다른 시스템과의 연동도 자유로워요.
- 단점: 프로그래밍 지식이 필요하고, 유지보수 부담이 있고, 차단 우회 같은 추가 작업도 따라와요.
이런 경우에 추천
- 수천~수백만 페이지 단위의 대량 추출이 필요할 때
- 로그인, 다단계 폼 같은 복잡한 사이트를 다뤄야 할 때
- 스크래핑 자체를 앱이나 워크플로우에 깊게 녹여야 할 때
비 HTML 포맷에서 텍스트 추출: PDF, 워드, 이미지
웹사이트에는 HTML 외에도 PDF, 워드, 이미지 같은 파일에 중요한 정보가 들어 있는 경우가 많아요. 이런 경우엔 이렇게 접근해요.
- 텍스트 기반 PDF: Adobe Acrobat이나
PDFMiner,PyPDF2같은 도구로 텍스트를 뽑아내요. - 스캔 PDF: Tesseract, , 같은 OCR 도구를 활용해요.
워드/엑셀 문서
- 워드:
python-docx로 .docx 파일을 읽어요. - 엑셀:
openpyxl이나pandas로 .xlsx 파일을 다뤄요.
이미지
- OCR 도구: 오픈소스 Tesseract나 클라우드 서비스를 써요(이미지 화질이 좋을수록 정확도가 올라가요).
Thunderbit의 방식
‘이미지/문서 파서’ 기능을 쓰면 PDF, 이미지, 문서를 업로드하거나 링크만 넣어도 AI가 텍스트를 뽑아내고, 표가 있으면 컬럼까지 알아서 제안해 줘요. 도구를 여기저기 돌려가며 쓸 필요 없이, 파일도 웹페이지처럼 다룰 수 있는 거죠.
방법별 비교: 내게 맞는 텍스트 추출 솔루션은?
각 방법의 특징을 한눈에 비교해 보세요.
| 방법 | 사용 편의성 | 확장성 | 기술 필요도 | 지원 데이터 유형 | 추천 대상 |
|---|---|---|---|---|---|
| 수동(복붙) | 매우 쉬움 | 낮음 | 없음 | 보이는 텍스트만 | 소규모, 단발성 작업 |
| 브라우저 확장/도구 | 쉬움~보통 | 중간 | 낮음~보통 | HTML, 일부 표 | 비전문가, 소~중규모 작업 |
| AI 도구(Thunderbit) | 매우 쉬움 | 높음 | 없음 | HTML, PDF, 이미지 등 | 비즈니스, 다양한 데이터 |
| 프로그래밍(코드) | 어려움 | 매우 높음 | 높음 | 모든 유형(라이브러리 활용) | 개발자, 대규모 프로젝트 |
| 비 HTML 추출(OCR) | 보통 | 낮음~중간 | 보통 | PDF, 이미지, 문서 | 파일/이미지 중심 작업 |
가장 빠르고 유연하면서 스트레스가 적은 길을 원한다면, 특히 비즈니스 용도라면 Thunderbit 같은 AI 도구가 가장 손쉬운 선택이에요. 다만 데이터 양이 정말 많거나 모든 동작을 직접 통제해야 한다면 코딩 쪽도 진지하게 고려해 볼 만해요.
핵심 요약: 지금 바로 웹사이트에서 텍스트 추출 시작하기
- 웹에는 가치 있는 텍스트 데이터가 정말 많지만, 꺼내기는 의외로 까다로워요.
- 수작업은 작은 작업에만 어울리고, 확장은 어렵거든요.
- 브라우저 확장이나 AI 웹 스크래퍼(Thunderbit 같은)를 쓰면 누구나 빠르고 정확하게 텍스트를 추출할 수 있어요. 코딩도 필요 없고요!
- PDF, 이미지처럼 HTML이 아닌 콘텐츠는 OCR과 문서 파싱 기능이 내장된 도구를 활용하는 게 좋아요.
- 결국 팀의 기술 수준, 프로젝트 규모, 데이터 유형에 맞춰 도구를 고르는 게 정답이에요.
복붙에 시달리는 시대는 이제 끝낼 때예요. 적절한 도구만 갖추면 웹 데이터 추출은 자동으로 굴러가고, 더 가치 있는 일에 시간을 쓸 수 있거든요. 끝없는 복사·붙여넣기에서 벗어나 효율적인 작업 흐름으로 넘어가 보세요.
자주 묻는 질문(FAQ)
Q1: 모든 웹사이트에서 데이터를 추출할 수 있나요?
A1: 항상 그렇진 않아요. 일부 사이트는 스크래퍼를 차단하거나, 이용약관에서 스크래핑을 금지하기도 하거든요. 작업 전에 정책을 꼭 확인해 보세요.
Q2: AI 기반 웹 스크래퍼의 정확도는 어느 정도인가요?
A2: Thunderbit 같은 AI 스크래퍼는 정확도가 꽤 높은 편이에요. 다만 복잡하거나 동적인 페이지에서는 약간의 수동 조정이 필요할 수 있어요.
Q3: 웹 스크래핑 도구를 쓰려면 코딩이 필요한가요?
A3: 아니에요. Thunderbit를 비롯한 브라우저 확장은 비전문가도 쉽게 쓸 수 있게 만들어졌거든요.
Q4: PDF나 이미지에서 어떤 데이터를 추출할 수 있나요?
A4: OCR 도구를 쓰면 스캔된 PDF나 이미지에서도 텍스트, 표, 숨겨진 데이터까지 꺼낼 수 있어서 활용도가 꽤 높아져요.
더 알아보기