

요즘은 데이터를 누가 더 잘 길어 올리느냐가 곧 경쟁력이에요. 매일 수십억 개의 웹페이지가 웹 스크래핑을 거쳐 인사이트, 가격 정보, 리드, 리서치 같은 다양한 용도로 쓰여요. 이 데이터가 이커머스 가격 경쟁부터 AI 혁신까지 거의 모든 분야의 연료가 되고 있고요(Kanhasoft). 글로벌 웹 스크래핑 시장은 **2025년 말 90억 달러(약 12조 원)**를 넘길 전망이에요. 효율적인 크롤러를 안 쓰면 그만큼 기회를 놓칠 수밖에 없죠(Kanhasoft).

SaaS와 자동화 업계에서 오래 일하다 보니, 크롤러 하나가 프로젝트 성패를 가르는 장면을 수도 없이 봤어요. 요즘은 특히 Rust가 크롤러 개발에 얼마나 강한지 직접 체감하고 있고요. 이 글에선 Rust가 왜 크롤러에 잘 맞는지, 어떻게 시작하면 되는지, 그리고 Thunderbit 같은 AI 도구와 묶어서 속도·안정성·편의를 한꺼번에 잡는 법을 풀어볼게요.
왜 Rust로 웹 크롤러를 만들어야 할까?
“굳이 왜 Rust로 크롤러를 짜죠?” 이런 질문 많이 받아요. Python이나 Node.js로 스크래핑해 본 분이라면 더 그렇고요. Rust가 도드라지는 이유는 이래요.
- 압도적인 속도: Rust는 네이티브 코드로 컴파일돼서 크롤러가 가진 성능을 다 뽑아내요. 벤치마크상 연산이 많은 작업에서 Python보다 2~10배 빠르고, Node.js보다 70% 빠르면서 메모리는 90%까지 적게 쓸 수 있어요(Rayobyte, BrightData).
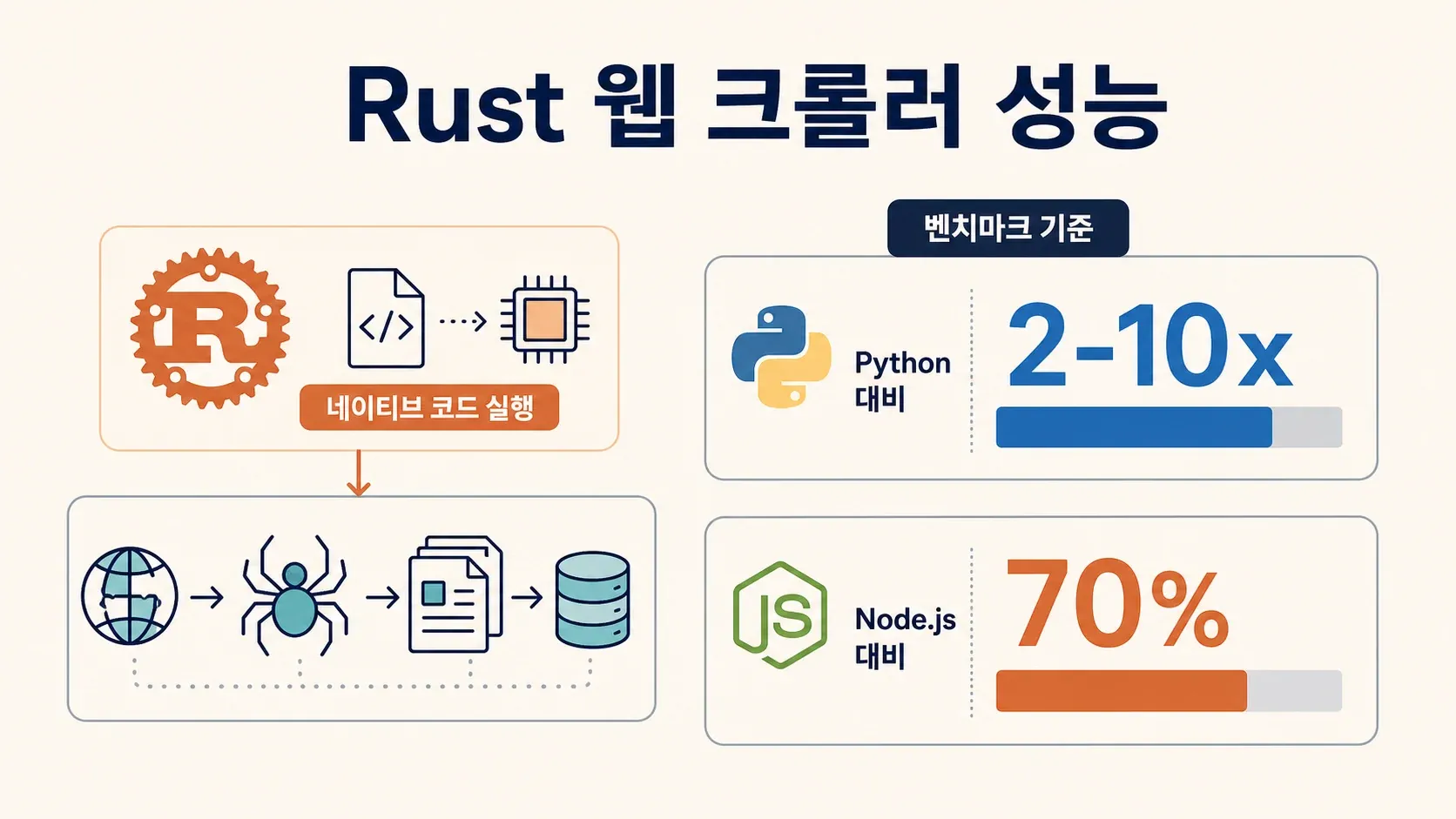
- 메모리 안전성: Rust의 소유권 시스템 덕에 갑작스러운 크래시나 메모리 누수 걱정이 없어요. 컴파일 단계에서 버그를 미리 잡아주거든요.
- 안전한 동시성: Rust는 애초에 동시성을 염두에 두고 설계됐어요. 100개 페이지를 한꺼번에 긁고 싶어도 타입 시스템이 스레드 안전과 데이터 경합을 막아줘요.
- 높은 신뢰성: Rust의 에러 처리(
Result,Option)는 실패 상황을 꼼꼼히 챙기게 해줘요. 잘못된 요청 하나로 크롤러 전체가 멈추는 일은 없고요. - 보안성: 버퍼 오버플로우, 널 포인터 같은 치명적 취약점이 원천 차단돼요. 안전성이 높아서 이상하거나 악의적인 웹 콘텐츠에도 잘 버텨요.
Python(쉽지만 느리고 메모리 부담 큼), Node.js(I/O는 빠르지만 싱글 스레드에 메모리 많이 씀)와 비교하면 Rust는 성능과 안정성 양쪽에서 한 수 위예요. 크롤링 규모가 커질수록 차이는 더 벌어지고요(LinkGathering).
Rust 웹 크롤러 개발 환경 세팅하기
이제 Rust 개발 환경을 준비해 볼게요.
1. Rust와 Cargo 설치
Rust는 rustup으로 배포되고, 버전 관리와 빌드 도구(cargo)가 같이 따라와요. 운영체제에 맞는 설치 파일을 받아 안내대로 진행하면 돼요. Windows라면 Visual C++ Build Tools 설치 안내가 뜰 수 있고요.
설치 확인은 이렇게:
rustc --version
cargo --version
버전 정보가 뜨면 정상이에요.
2. 새 프로젝트 시작
터미널에 이 명령어를 입력하세요.
cargo new rust_web_crawler
cd rust_web_crawler
Cargo.toml과 src/main.rs가 들어간 새 프로젝트가 만들어져요.
3. 필수 라이브러리 추가
웹 크롤링에 필요한 주요 라이브러리는 이래요.
아래 명령어로 한 번에 추가할 수 있어요.
cargo add reqwest scraper csv tokio --features full
Cargo.toml에 직접 적어도 돼요.
[dependencies]
reqwest = { version = "0.11", features = ["blocking"] }
scraper = "0.16"
csv = "1.1"
tokio = { version = "1.28", features = ["full"] }
4. 개발 도구 및 IDE 추천
저는 rust-analyzer 확장을 얹은 VS Code를 추천해요. 코드 자동완성, 인라인 문서, 린트까지 개발에 필요한 게 다 들어 있거든요. 큰 프로젝트라면 JetBrains의 CLion이나 IntelliJ에 Rust 플러그인을 써도 좋아요.
5. 문제 해결 팁
cargo명령어가 안 먹히면 Rust의.cargo/bin경로가 PATH에 들어 있는지 확인하세요.- Windows에선 C++ 빌드 도구가 없을 수 있으니 안내대로 설치하세요.
- 의존성 오류가 나면
cargo update를 돌리거나Cargo.toml오타를 점검하세요.
단계별: Rust로 첫 웹 크롤러 만들기
이제 페이지를 긁어 상품 정보를 뽑고 CSV로 내보내는 기본 크롤러를 만들어 봐요. 아주 간단한 예시라 필요에 따라 얼마든지 확장할 수 있어요.
Rust로 웹페이지 가져오기
먼저 reqwest로 페이지를 불러와요.
use reqwest::blocking::get;
fn main() {
let url = "https://www.scrapingcourse.com/ecommerce/";
let response = get(url);
let html_content = response.unwrap().text().unwrap();
println!("{}", html_content);
}
실제 서비스에선 unwrap() 대신 에러 처리를 꼭 해주세요.
let response = match reqwest::blocking::get(url) {
Ok(resp) => resp,
Err(err) => {
eprintln!("Request failed for {}: {}", url, err);
return;
}
};
데이터 파싱 및 추출
scraper로 HTML에서 상품 정보를 뽑아봐요.
use scraper::{Html, Selector};
let document = Html::parse_document(&html_content);
let product_selector = Selector::parse("li.product").unwrap();
for product in document.select(&product_selector) {
let name = product
.select(&Selector::parse("h2").unwrap()).next()
.map(|e| e.text().collect::<String>());
let price = product
.select(&Selector::parse(".price").unwrap()).next()
.map(|e| e.text().collect::<String>());
let url = product
.select(&Selector::parse("a").unwrap()).next()
.and_then(|e| e.value().attr("href"))
.map(|s| s.to_string());
let image = product
.select(&Selector::parse("img").unwrap()).next()
.and_then(|e| e.value().attr("src"))
.map(|s| s.to_string());
println!("Name: {:?}, Price: {:?}, URL: {:?}, Image: {:?}", name, price, url, image);
}
이 방식은 ZenRows에서 아이디어를 얻었어요. 대부분의 이커머스나 디렉터리 페이지에 그대로 써먹을 수 있고요.
URL 관리 및 중복 방지
실제 크롤러라면 링크를 따라가면서 같은 페이지를 두 번 긁지 않게 막아야 해요. 대표적인 패턴은 이래요.
use std::collections::{HashSet, VecDeque};
let mut to_visit = VecDeque::new();
let mut visited = HashSet::new();
to_visit.push_back(start_url.to_string());
visited.insert(start_url.to_string());
while let Some(url) = to_visit.pop_front() {
// Fetch and parse page...
for link in extracted_links {
let abs_link = normalize_url(&link, &url); // `url` 크레이트 사용!
if !visited.contains(&abs_link) {
visited.insert(abs_link.clone());
to_visit.push_back(abs_link);
}
}
}
상대 경로, 슬래시, 프래그먼트 같은 건 url 크레이트로 정규화하세요.
동시성 구현으로 크롤링 속도 올리기
여기서부터 Rust의 진가가 드러나요. 한 페이지씩 순서대로 긁으면 느리니, 병렬로 돌려봐요.
방법 1: 멀티스레딩
스레드를 여러 개 만들어 큐를 나눠 처리하는 방식이에요. Arc<Mutex<>>로 상태를 공유하면 소규모 크롤링에 잘 맞아요.
방법 2: Tokio 기반 비동기 처리
진짜 속도를 원하면 비동기를 쓰세요. tokio와 비동기 reqwest를 묶으면 수백 개 요청을 동시에 처리해도 메모리 부담이 적어요.
use reqwest::Client;
use futures::future::join_all;
let client = Client::new();
let urls = vec![/* ... */];
let fetches = urls.into_iter().map(|url| {
let client_ref = &client;
async move {
match client_ref.get(url).send().await {
Ok(resp) => {
let text = resp.text().await.unwrap_or_default();
// Parse text...
}
Err(e) => eprintln!("Error fetching {}: {}", url, e),
}
}
});
join_all(fetches).await;
비동기 Rust는 빠를 뿐 아니라 안전해요. 데이터 경합이나 이상한 버그 없이 순수한 처리량을 누릴 수 있고요(ScrapingBee).
크롤링한 데이터 내보내기 및 저장
데이터를 모았다면 내보내야겠죠. csv 크레이트를 쓰면 CSV 저장이 아주 간단해요.
use csv::Writer;
use std::fs::File;
let file = File::create("products.csv").expect("could not create file");
let mut writer = Writer::from_writer(file);
writer.write_record(&["Name", "Price", "URL", "Image"]).unwrap();
for prod in &products {
let name = prod.name.as_deref().unwrap_or("");
let price = prod.price.as_deref().unwrap_or("");
let url = prod.url.as_deref().unwrap_or("");
let image = prod.image.as_deref().unwrap_or("");
writer.write_record(&[name, price, url, image]).unwrap();
}
writer.flush().unwrap();
Serde로 구조체를 바로 직렬화하거나, 복잡한 데이터는 JSON으로 빼도 돼요.
Thunderbit로 웹 데이터 추출을 더 빠르고 쉽게
이제 Thunderbit 차례예요. 직접 코딩하는 것도 좋지만, 그냥 빠르게 데이터만 얻고 싶을 때가 있잖아요. Thunderbit는 AI 기반 Chrome 확장으로, 클릭 몇 번이면 코딩 없이 데이터를 뽑아줘요.
AI로 어떤 웹사이트든 데이터 추출하기 Get Started Free
Thunderbit는 AI 웹 스크래퍼 Chrome 확장이에요. 비즈니스 사용자가 AI로 웹사이트에서 데이터를 손쉽게 뽑게 도와줘요. 반복적인 웹 작업을 자동화해 시간을 아껴주는 생산성 도구고요.
Thunderbit만의 강점은?
- AI 필드 추천: 페이지를 분석해 이름, 이메일, 가격 등 뽑을 컬럼을 알아서 제안해줘요(Thunderbit Blog).
- 원클릭 스크래핑: “스크랩” 버튼 한 번이면 데이터가 구조화된 표로 정리돼요.
- 서브페이지 추출: 상세 페이지 정보가 필요하면 각 링크를 자동으로 들어가 표를 풍성하게 채워줘요(Thunderbit Blog).
- 페이지네이션 & 무한 스크롤: 페이지네이션이나 무한 스크롤도 알아서 감지해 처리해요.
- 무료 데이터 내보내기: Excel, Google Sheets, Notion, Airtable, CSV로 손쉽게 빼낼 수 있어요.
- AI 자동입력: 로그인이나 폼 자동입력도 AI가 처리해서, 인증이 필요한 데이터도 쉽게 가져와요.
Thunderbit는 복잡하거나 동적인 JavaScript 기반 사이트를 다룰 때 비즈니스 사용자와 개발자 모두에게 큰 도움이 돼요.
Thunderbit와 Rust, 언제 각각 써야 할까?
- Thunderbit: 빠른 프로토타입, 일회성 추출, 또는 비개발자 팀원이 직접 데이터를 모아야 할 때 딱이에요.
- Rust: 대규모·맞춤형·시스템에 깊이 박힌 크롤러가 필요할 때 최고의 성능과 제어력을 줘요.
사실 둘을 같이 쓰면 시너지가 제일 커져요.
Rust 웹 크롤러와 다른 기술의 성능 비교
조금 더 기술적으로 들어가 볼게요. Rust는 다른 언어와 비교해 뭐가 좋을까요?
| 언어/프레임워크 | 속도 | 메모리 사용량 | 동시성 | 안정성 | 생태계 |
|---|---|---|---|---|---|
| Rust | 🚀🚀🚀 | 🟢 낮음 | 🟢 탁월함 | 🟢 높음 | 중간 |
| Python (Scrapy) | 🚀 | 🔴 높음 | 🟡 제한적 | 🟡 보통 | 🟢 큼 |
| Node.js | 🚀🚀 | 🔴 높음 | 🟢 좋음 | 🟡 보통 | 🟢 큼 |
| Go | 🚀🚀 | 🟢 낮음 | 🟢 탁월함 | 🟢 높음 | 중간 |
- Rust는 Python보다 2~10배 빠르고, 메모리는 10% 미만만 써요(Rayobyte, BrightData).
- Node.js는 I/O엔 강하지만 JS 실행이 싱글 스레드라 무거운 파싱에선 한계가 있어요.
- Go도 만만찮은 경쟁자예요. 그래도 메모리 안전성과 제로 오버헤드 추상화 덕분에 대규모·장시간 크롤링에선 Rust가 한 수 위고요.
대규모 크롤링이나 극한의 성능이 필요하면 Rust가 최고의 선택이에요.
Thunderbit와 Rust를 결합해 효율 극대화하기
제가 즐겨 쓰는 워크플로는 Thunderbit와 Rust를 같이 굴리는 거예요.
- 빠른 프로토타이핑: Thunderbit로 사이트 구조와 샘플 데이터를 먼저 훑어, 코드 짜기 전에 전체 흐름을 파악해요.
- 역할 분담: 동적·인증·복잡한 페이지(서브페이지 추출, AI 자동입력)는 Thunderbit가 맡고, 정적·대량 페이지는 Rust 크롤러가 담당해요.
- 정기 스크래핑: Thunderbit의 예약 스크래핑으로 주기적으로 데이터를 모으고, Rust 백엔드에서 후처리하거나 합쳐요.
- 비개발자 지원: 운영·마케팅팀이 Thunderbit로 즉석에서 데이터를 모으면, 개발자는 더 복잡한 일에 집중할 수 있어요.
- 유연성: Rust 크롤러가 레이아웃 변경으로 깨져도, Thunderbit의 AI는 바로 적응해 코드 수정 없이 계속 데이터를 뽑아요.
이런 하이브리드 방식이면 Thunderbit의 속도와 유연성, Rust의 파워와 제어력을 다 누릴 수 있어요.
웹 스크래핑 가이드 더 보기 Thunderbit 블로그에서 더 많은 팁과 튜토리얼을 확인하세요. Get Started Free
Rust 웹 크롤러를 위한 문제 해결 및 베스트 프랙티스
튼튼한 크롤러를 만들려면 코드만큼이나 실제 웹 환경의 변수도 같이 챙겨야 해요.
자주 겪는 문제
- 봇 차단 우회: 실제 브라우저 User-Agent 사용,
robots.txt준수, 요청 속도 조절, 대량 크롤링 시 프록시 활용(Rayobyte). - CAPTCHA 및 로그인: CAPTCHA나 까다로운 로그인은 Thunderbit의 AI 자동입력이나
fantoccini,headless_chrome같은 헤드리스 브라우저를 쓰세요. - JavaScript 기반 사이트: 데이터가 AJAX로 로드되면 API 호출을 직접 찾거나, JS 렌더링이 필요하면 Thunderbit나 헤드리스 브라우저를 쓰세요.
- 에러 처리: 적절한 에러 처리(
Result,Option), 타임아웃 설정, 에러 로그 기록을 항상 챙기세요. - 동시성 문제: 스레드 안전 구조체(
Arc<Mutex<>>,DashMap)를 쓰고, 공유 상태에서 병목이 안 생기게 주의하세요. - 메모리 관리: 수백만 페이지를 긁는다면 데이터를 실시간으로 디스크에 저장해 메모리를 아끼세요.
- 윤리 및 준법: 사이트 이용약관을 지키고, 서버에 과부하를 안 주고, 데이터 프라이버시 법규(한국이라면 PIPA)도 반드시 지키세요.
베스트 프랙티스
- 모듈화: 수집, 파싱, 저장 로직을 나눠 유지보수를 쉽게 하세요.
- 설정 파일 활용: URL, 동시성, 지연 시간 같은 건 설정 파일이나 CLI 인자로 관리하세요.
- 로깅:
log크레이트로 구조화된 로그를 남기세요. - 테스트: 샘플 HTML로 파싱 로직 단위 테스트를 작성하세요.
- 모니터링: 오래 도는 크롤러라면 CPU, 메모리, 에러 상태를 지켜보세요.
문제 해결 팁이 더 필요하면 LinkGathering 가이드와 ZenRows Rust 튜토리얼을 참고하세요.
결론 & 핵심 요약
Rust로 크롤러를 짜는 건 단순한 기술 도전이 아니라 데이터 중심 시대의 전략 무기가 될 수 있어요. 꼭 기억할 점은 이래요.
- Rust는 웹 크롤링에 최적화된 언어예요. 빠르고, 안전하고, 동시성에 강해요.
- 단계별로 가세요: 환경 세팅, 페이지 수집·파싱, URL 관리, 동시성 추가, 데이터 내보내기까지 차근차근요.
- Thunderbit는 복잡한 사이트나 빠른 프로토타이핑에 강한 무기예요. 코딩 없이도 데이터를 쉽게 뽑아요.
- 둘을 묶으면 효율이 극대화돼요. Thunderbit로 프로토타입과 난도 높은 페이지를, Rust로 대규모·맞춤형 크롤링을 맡기세요.
- 실용성을 잊지 마세요: 때론 수백 줄 코드보다 클릭 몇 번이 더 나은 답이에요.
웹 크롤링 실력을 한 단계 올리고 싶다면 Rust에 도전해 보세요. 필요할 땐 Thunderbit의 힘을 빌리고요. 더 많은 스크래핑 팁과 자동화 노하우는 Thunderbit 블로그에서 확인할 수 있어요.
즐거운 크롤링 되세요. 데이터가 늘 빠르고, 깨끗하고, 한층 더 똑똑하길 바라요!
자주 묻는 질문(FAQ)
1. Rust로 웹 크롤러를 만드는 게 Python이나 Node.js보다 좋은 이유는?
Rust는 성능, 메모리 안전성, 동시성에서 월등해요. Python과 Node.js는 빠른 스크립트엔 잘 맞지만, 대규모·장기·미션 크리티컬 크롤러엔 Rust가 속도와 신뢰성 면에서 탁월하고요(Rayobyte).
2. Rust 웹 크롤러 개발에 꼭 필요한 라이브러리는?
HTTP 요청은 reqwest, HTML 파싱은 scraper, 비동기 처리는 tokio, 데이터 내보내기는 csv가 필요해요. URL 정규화엔 url 크레이트도 유용하고요.
3. JavaScript 기반이나 인증이 필요한 사이트는 Rust에서 어떻게 처리하나요?
JS 기반 사이트는 API 호출을 직접 찾거나 fantoccini 같은 헤드리스 브라우저를 쓰세요. 인증 페이지는 reqwest로 쿠키를 관리하거나, Thunderbit의 AI 자동입력으로 로그인을 자동화할 수 있어요.
4. Thunderbit와 Rust를 함께 쓰는 장점은?
Thunderbit는 AI 기반 노코드 스크래핑으로 빠른 프로토타입, 동적 페이지, 비개발자 지원에 최적이에요. Rust는 맞춤형·고성능 크롤러에 강하고요. 둘을 묶으면 빠르고 효율적으로 확장할 수 있어요.
5. 크롤링 중 차단이나 밴을 피하려면 어떻게 해야 하나요?
robots.txt 준수, 실제 브라우저 헤더 사용, 요청 속도 조절, 대량 크롤링 시 프록시 활용이 필요해요. 항상 윤리적으로 크롤링하고, 사이트 이용약관과 데이터 프라이버시 법규를 지키세요(Rayobyte).
Thunderbit의 실제 쓰임이 궁금하면 Chrome 확장 프로그램을 다운로드해서 더 똑똑한 스크래핑을 시작해 보세요. 웹 자동화에 관한 더 깊은 인사이트는 Thunderbit 블로그에서 확인할 수 있어요.
Thunderbit AI 웹 스크래퍼 체험하기 Get Started Free
더 알아보기




