
요약
이 연구는 1,238개의 DTC 도메인을 대상으로 AI 검색 준비도를 네 가지 층위로 평가합니다: AI 파일 품질, 일반 구조화 데이터, 상품 페이지 구조화 신호, 메타데이터. 평균 점수는 100점 만점에 36.4점이고, 중앙값은 37.0점입니다. 이 점수 체계에서 ai_ready 등급에 도달한 도메인은 11개뿐이었습니다.
가장 큰 발견은 표면적인 발견 가능성과 상품 수준의 이해 사이에 있는 격차입니다. 가장 큰 llms.txt 품질 구간은 platform_default로, 629개 도메인이 여기에 해당합니다. 즉, 많은 브랜드가 플랫폼이 자동 생성한 기본 AI 읽기 가능 파일만 가지고 있다는 뜻입니다. 하지만 홈페이지만 기준으로 Product 스키마가 보이는 비율은 평가된 도메인의 **0.9%**에 불과했고, 상품 페이지 Product 스키마는 상품 페이지를 시도한 도메인 중 **39.2%**에서만 나타났습니다. 상품 페이지의 가격 신호는 48.1%, 리뷰 또는 평점 신호는 **43.5%**였습니다.
등급 분포는 이 시장이 얼마나 초기 단계인지를 잘 보여줍니다:
| AI 준비도 등급 | 도메인 수 |
|---|---|
| 준비 안 됨 | 435 |
| 부분적으로 준비됨 | 425 |
| 기본 발견 가능 | 367 |
| AI 준비됨 | 11 |
이 구분이 유용한 이유는 자주 뒤섞이는 세 가지 개념을 분리해 주기 때문입니다. 브랜드는 발견될 수 있습니다. 브랜드는 메타데이터를 가질 수 있습니다. 브랜드는 llms.txt를 가질 수 있습니다. 하지만 발견 가능하다고 해서 상품 수준에서 이해 가능하다는 뜻은 아닙니다.
llms.txt 품질 분포를 보면 그 차이는 더 분명해집니다:
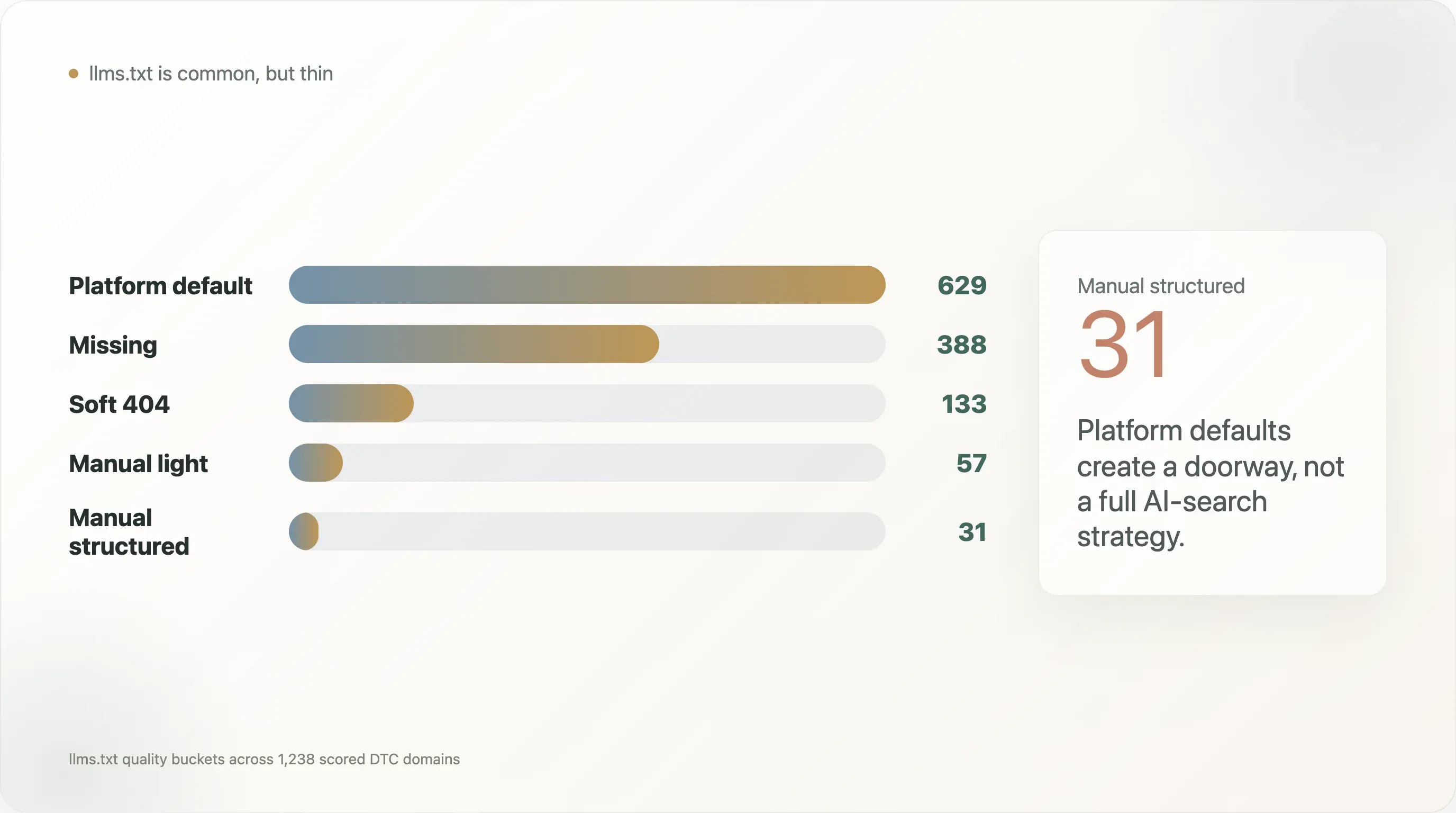
| llms.txt 품질 구간 | 도메인 수 |
|---|---|
| 플랫폼 기본값 | 629 |
| 없음 | 388 |
| 소프트 404 | 133 |
| 수동 간단형 | 57 |
| 수동 구조화형 | 31 |
따라서 이 보고서의 가장 강력한 해석은 “DTC 브랜드가 llms.txt를 갖고 있다”는 식이 아닙니다. 그건 너무 얕은 결론입니다. 더 나은 해석은 플랫폼 기본값이 AI 발견 가능성의 얇은 첫 층은 만들어 줬지만, 대부분의 DTC 브랜드는 AI 쇼핑과 답변 엔진에 필요한 상품 수준의 구조화 데이터 층을 아직 만들지 못했다는 것입니다.
좋은 사례는 더 나은 준비도가 어떤 모습인지 보여줍니다. ai_ready 등급에는 Mokobara, Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods, La Maison Convertible, Unbloat, NuRange Coffee, Three Ships Beauty, Manukora 같은 브랜드가 포함됩니다. 이 예시들이 중요한 이유는 AI 준비도가 특정 카테고리나 특정 유형의 브랜드에만 해당하는 것이 아님을 보여 주기 때문입니다. 식품, 뷰티, 웰니스, 가구, 의류, 특화 커머스 모두 기계가 읽을 수 있는 상품 계층을 개선할 수 있습니다.
가장 공유하기 쉬운 발견
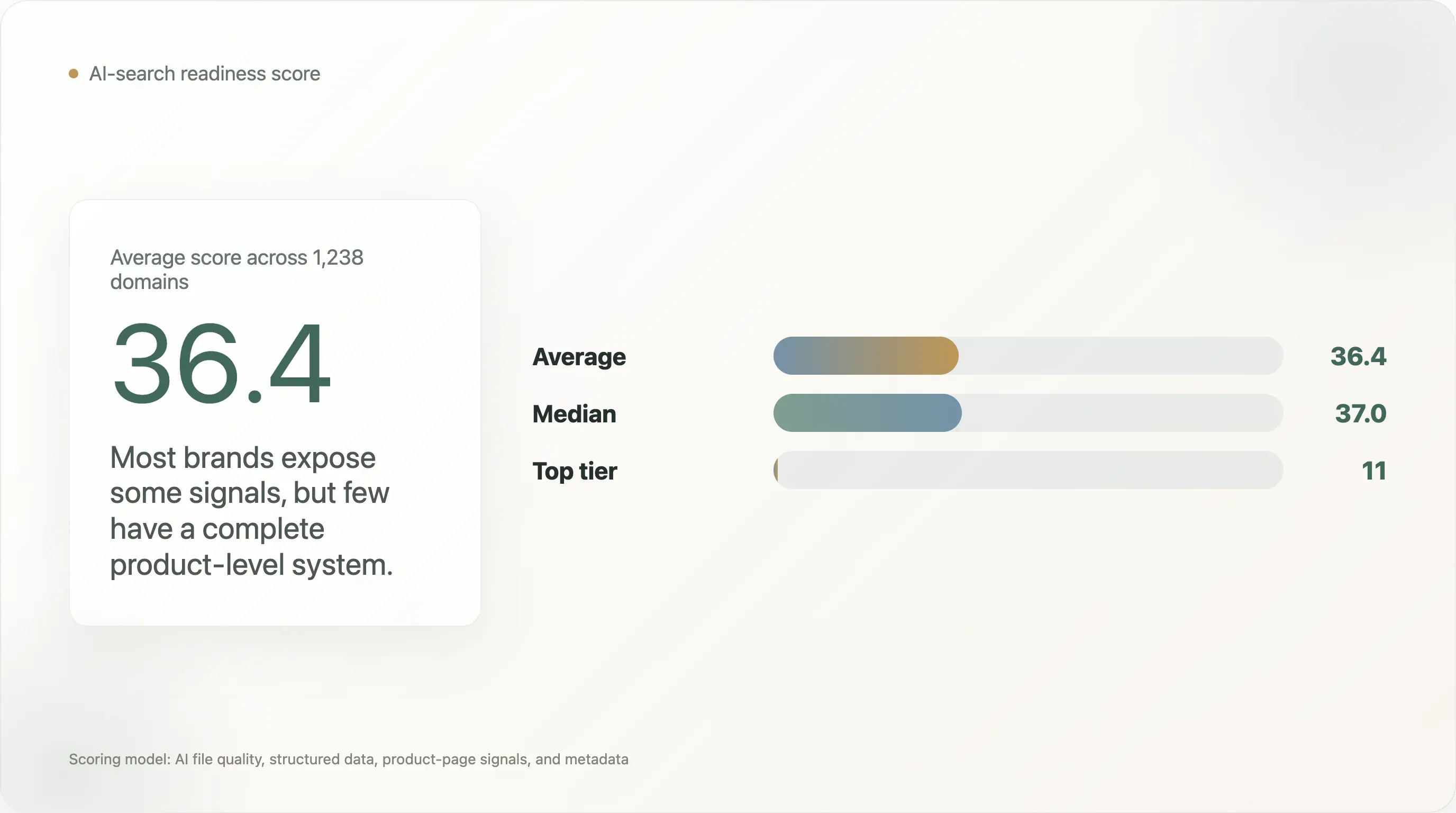
-
DTC AI 준비도 평균 점수는 36.4/100에 불과합니다.
-
평가된 1,238개 도메인 중
ai_ready등급은 11개뿐입니다. -
llms.txt는 흔하지만, 대부분 플랫폼이 생성한 것입니다. 가장 큰 품질 구간은 플랫폼 기본값이며, 629개 도메인이 여기에 해당합니다.
-
수동 구조화형 llms.txt는 드뭅니다. 수동 구조화형 구간에 속하는 도메인은 31개뿐입니다.
-
홈페이지 Product 스키마는 거의 없습니다. 평가된 도메인의 0.9%에서만 나타납니다.
-
상품 페이지 Product 스키마는 더 낫지만 여전히 불완전합니다. 상품 페이지를 시도한 도메인 중 39.2%에서만 나타났습니다.
-
AI 쇼핑 준비에는 크롤러 접근만이 아니라 상품 정보가 필요합니다. 가격, 오퍼, 리뷰, 재고 가능 여부, Product 스키마 신호가 얇은 파일 하나보다 더 중요합니다.
1. AI 검색 준비도가 SEO 기본기와 다른 이유
전통적인 SEO는 페이지를 크롤링할 수 있는지, 인덱싱되는지, 순위가 오르는지, 클릭되는지를 묻습니다. AI 검색은 다른 층위를 추가합니다. 시스템이 브랜드, 상품, 오퍼, 가격, 리뷰, 재고 가능 여부, 정책, 엔터티 관계를 질문에 답하거나 상품을 추천할 만큼 잘 이해할 수 있는가 하는 문제입니다.
이 차이는 DTC에서 특히 중요합니다. 커머스 페이지에는 사람에게는 쉬워도 기계에게는 복잡할 수 있는 정보가 많기 때문입니다. 쇼핑객은 상품 페이지를 보고 상품명, 가격, 크기, 구독 옵션, 할인, 리뷰, 재고 상태, 반품 정책을 쉽게 이해합니다. 하지만 크롤러나 AI 에이전트는 이런 사실이 일관되게 표현되어 있어야 합니다.
메타데이터는 도움이 됩니다. Open Graph도 도움이 됩니다. canonical 태그도 도움이 됩니다. llms.txt는 크롤러가 중요한 콘텐츠를 찾는 데 도움이 될 수 있습니다. 하지만 진짜 시험대는 상품 수준의 구조입니다. AI 쇼핑 도우미가 단백질 파우더, 스킨케어 제품, 캔들, 드레스, 커피 구독을 다섯 개 비교한다면, 구조화된 사실이 필요합니다. 그런 사실이 없으면 브랜드는 보이더라도 안정적으로 이해되지는 않습니다.
이 보고서는 네 가지 준비도 층위를 구분합니다:
- AI 파일 층: llms.txt가 존재하는지, 그리고 없음, 소프트 404, 플랫폼 기본값, 수동 간단형, 수동 구조화형 중 어디에 해당하는지.
- 일반 구조화 데이터 층: JSON-LD, Organization, WebSite, BreadcrumbList, Product 스키마.
- 상품 페이지 층: Product 스키마, 오퍼 또는 가격 신호, 평점 또는 리뷰 신호, 재고 가능 여부 신호.
- 메타데이터 층: canonical, 메타 설명, Open Graph 이미지, Twitter 카드, hreflang 등 기계가 읽을 수 있는 맥락.
이 계층형 모델이 중요한 이유는 피상적인 결론을 막아 주기 때문입니다. llms.txt는 있지만 상품 정보가 없는 브랜드는 겉보기만큼 준비된 것이 아닙니다. llms.txt는 없지만 상품 페이지 스키마가 풍부한 브랜드는 파일 층이 암시하는 것보다 더 잘 이해될 수 있습니다.
2. llms.txt 이야기: 플랫폼이 대부분 만든 얇은 층
llms.txt 감사에서는 다섯 가지 품질 구간이 확인되었습니다:
| 품질 구간 | 도메인 수 | 해석 |
|---|---|---|
| 플랫폼 기본값 | 629 | 보통 얇지만 유효한 표준 플랫폼 생성 파일 |
| 없음 | 388 | 사용할 수 있는 파일이 없음 |
| 소프트 404 | 133 | 오해를 부르거나 쓸모 없는 응답 |
| 수동 간단형 | 57 | 사람이 만들었거나 커스텀했지만 구조가 제한적임 |
| 수동 구조화형 | 31 | 제목, 링크, 상품 또는 정책 용어가 포함된 더 탄탄한 수동 파일 |
이 보고서에서 가장 중요한 뉘앙스는 이것입니다. 표면적으로는 플랫폼 기본값 파일이 흔하므로 llms.txt 채택률이 높아 보입니다. 하지만 플랫폼 기본값은 신중한 AI 검색 전략과 같은 의미가 아닙니다. 대개는 기본적인 안내 층에 가깝습니다.
그렇다고 플랫폼 기본값 파일이 무가치하다는 뜻은 아닙니다. 크롤러가 중요한 경로를 찾는 데 도움을 줄 수 있습니다. 또한 플랫폼 수준의 결정이 시장을 얼마나 빨리 바꿀 수 있는지도 보여 줍니다. 플랫폼 하나가 브랜드 팀이 AI 검색 운영을 논의하기도 전에 수백 개 매장에 새로운 기계 읽기 가능 파일을 제공할 수 있습니다.
하지만 수동 구조화형 구간은 훨씬 작습니다. 31개 도메인뿐입니다. 감사 과정에서는 Dermalogica, Ad Hoc Atelier, DKNY 같은 브랜드와, Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods, Three Ships Beauty 같은 ai_ready 사례가 포함된 수동 구조화형 파일이 확인되었습니다. 이들은 기본 파일을 넘어선다는 것이 무엇을 뜻하는지 보여 주는 좋은 예시입니다. 더 많은 링크, 더 많은 제목, 더 많은 상품 용어, 더 많은 정책 용어, 더 의도적인 구조가 들어 있습니다.
소프트 404 구간도 중요합니다. 소프트 404는 요청에 대한 응답은 오지만, 유용한 llms.txt 파일은 아니라는 뜻입니다. 이는 단순 감사에서 오해를 일으킬 수 있습니다. AI 검색 준비도에서는 존재 여부만으로는 충분하지 않습니다. 품질 확인이 중요합니다.
3. 진짜 격차는 상품 수준 구조에 있습니다
데이터에서 가장 큰 격차는 Product 스키마입니다.
홈페이지 Product 스키마는 평가된 도메인의 **0.9%**에만 나타납니다. 상품 페이지 Product 스키마는 상품 페이지를 시도한 도메인 중 **39.2%**에서 나타납니다. 상품 페이지의 가격 신호는 48.1%, 리뷰 또는 평점 신호는 **43.5%**였습니다.
이 수치는 분명한 이야기를 들려줍니다. 기본적인 상품 정보조차도, 커머스 스토어프런트를 가진 브랜드에서조차 일관되게 기계가 읽을 수 있는 형태로 제공되지 않는다는 뜻입니다.
이는 AI 검색과 AI 쇼핑이 명확성을 보상할 가능성이 높기 때문에 중요합니다. 상품 페이지가 Product 스키마, 오퍼, 가격, 재고 가능 여부, 리뷰 신호, 정책 링크를 노출하면 기계가 더 신뢰할 수 있는 정보를 얻게 됩니다. 반대로 이런 정보가 JavaScript, 일관성 없는 템플릿, 이미지, 동적 위젯에 묻혀 있으면 기계는 이를 잘못 이해하거나 아예 무시할 수 있습니다.
준비도 격차는 단순히 순위의 문제가 아닙니다. 표현의 문제입니다. AI 시스템이 상품 카테고리를 요약하거나, 옵션을 비교하거나, “무엇에 좋은가” 질문에 답하거나, 쇼핑 추천을 생성할 때, 더 깔끔한 상품 정보를 가진 브랜드가 정확하게 포함되기 더 쉽습니다.
ai_ready 그룹의 좋은 사례들이 이를 잘 보여 줍니다:
- Mokobara는 출력에서 가장 높은 83점을 기록했습니다.
- Magic Mind, Le Petit Ballon, Maine Lobster Now는 각각 81점을 받았습니다.
- Yo Mama's Foods는 80점이었습니다.
- La Maison Convertible, Unbloat, Vinocheepo, NuRange Coffee는 각각 79점이었습니다.
- Three Ships Beauty는 77점이었습니다.
- Manukora는 75점이었습니다.
이 예시들은 여러 카테고리를 가로지릅니다. AI 준비도는 뷰티만의 문제도, 기술 업계만의 문제도 아닙니다. 식품, 웰니스, 가구, 의류, 특화 상품, 그리고 쇼핑객이 AI 시스템에 추천, 비교, 설명을 요청할 수 있는 모든 카테고리에 중요합니다.
4. AI 준비도 등급: 대부분의 브랜드는 아직 기준선 아래에 있습니다
등급 분포는 다음과 같습니다:
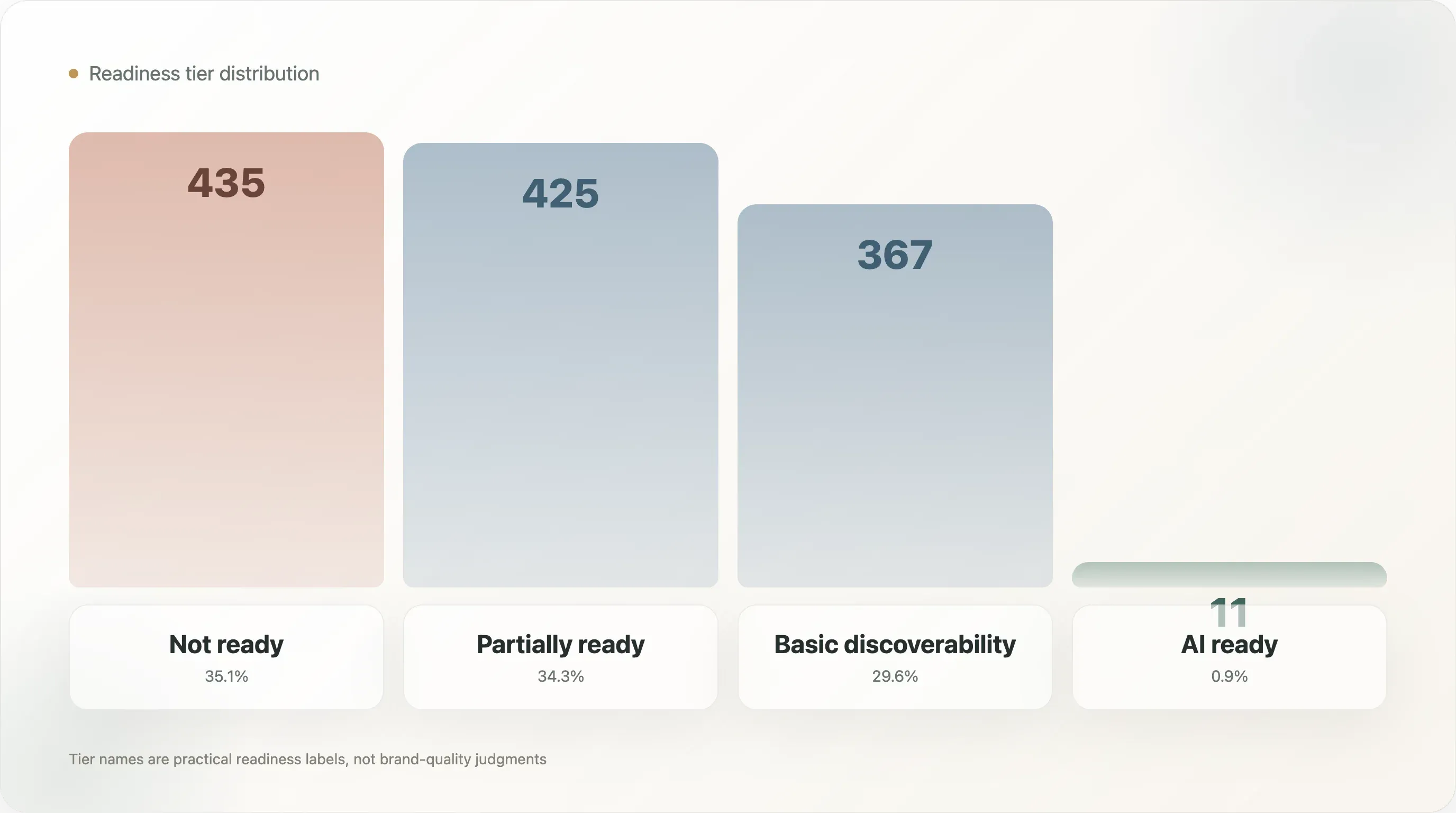
| 등급 | 도메인 수 | 표본 비중 |
|---|---|---|
| 준비 안 됨 | 435 | 35.1% |
| 부분적으로 준비됨 | 425 | 34.3% |
| 기본 발견 가능 | 367 | 29.6% |
| AI 준비됨 | 11 | 0.9% |
이 이름들은 의도적으로 실용적으로 설정했습니다. 준비 안 됨은 브랜드가 나쁘다는 뜻이 아닙니다. 이 모델이 사용하는 공개 신호가 AI 검색 준비도를 충분히 보여 주지 못한다는 뜻입니다. 부분적으로 준비됨은 일부 요소는 있지만 중요한 층이 빠져 있다는 뜻입니다. 기본 발견 가능은 브랜드가 기계에게 더 잘 보이지만, 여전히 상품 수준의 완성도가 부족할 수 있다는 뜻입니다. AI 준비됨은 파일 품질, 구조화 데이터, 상품 정보, 메타데이터가 더 강하게 결합되어 있다는 뜻입니다.
최상위 등급에 도달한 도메인은 11개뿐입니다. 이 숫자가 헤드라인이지만, 더 유용한 통찰은 중간 구간의 형태입니다. 표본은 준비 안 됨, 부분적으로 준비됨, 기본 발견 가능 사이에 거의 고르게 나뉘어 있습니다. 시장은 비어 있는 것이 아니라 전환기입니다. 많은 브랜드가 일부 신호는 갖고 있지만, 완전한 시스템을 가진 곳은 많지 않습니다.
이는 단기 기회를 만듭니다. AI 검색 준비도는 아직 충분히 초기 단계이기 때문에, llms.txt 개선, 스키마 검증, 상품 정보 노출, 메타데이터 정리, 기계가 상품 페이지를 더 잘 파싱할 수 있게 만드는 작업만으로도 평균에서 강한 상태로 올라갈 수 있습니다.
5. 카테고리 패턴: 뷰티와 의류가 앞서 있지만, 완성된 카테고리는 없습니다
카테고리 분류는 방향성을 보여 주는 것이지 정확한 분류는 아닙니다. 그래도 아래 표는 유용한 패턴을 보여 줍니다:
| 카테고리 | 표본 | 평균 AI 준비도 | 수동 또는 구조화형 llms | 상품 페이지 스키마 | 상품 페이지 스키마 비율 |
|---|---|---|---|---|---|
| 뷰티 & 스킨케어 | 98 | 46.2 | 3 | 56 | 57.1% |
| 의류 & 신발 | 149 | 45.7 | 6 | 79 | 53.0% |
| 주얼리 & 액세서리 | 34 | 44.5 | 0 | 20 | 58.8% |
| 반려동물 | 15 | 43.5 | 0 | 8 | 53.3% |
| 베이비 & 키즈 | 27 | 42.6 | 1 | 15 | 55.6% |
| 식품 & 음료 | 118 | 42.5 | 5 | 58 | 49.2% |
| 홈 & 가구 | 48 | 42.3 | 0 | 23 | 47.9% |
| 헬스 & 웰니스 | 58 | 40.7 | 6 | 27 | 46.6% |
| 아웃도어 & 스포츠 | 49 | 39.8 | 1 | 23 | 46.9% |
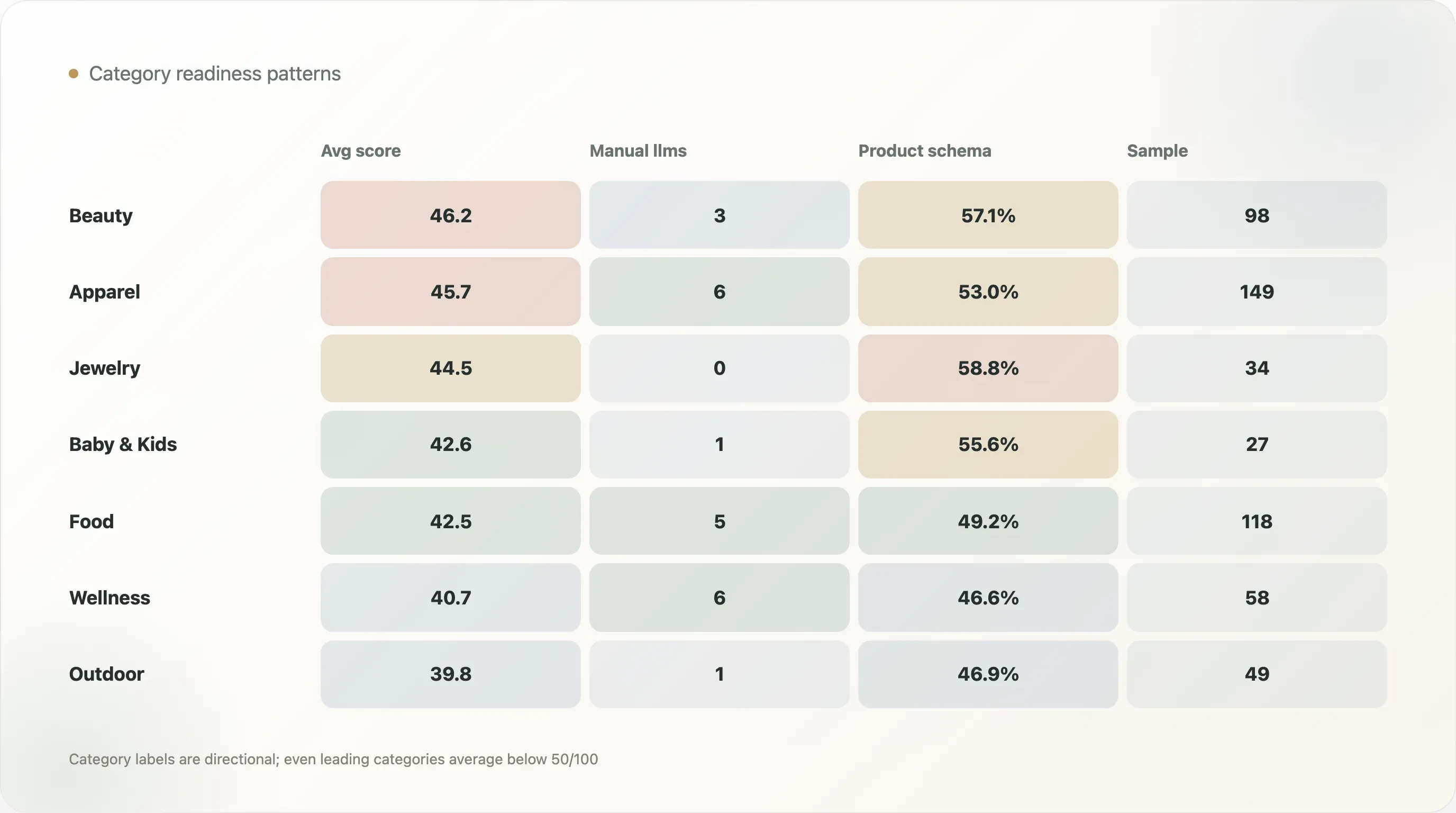
뷰티 & 스킨케어는 평균 AI 준비도 점수가 46.2점으로 가장 높습니다. 의류 & 신발이 45.7점으로 그 뒤를 잇습니다. 이 카테고리들은 강한 커머스 템플릿, 풍부한 상품 카탈로그, 리뷰, 옵션, 시각 자산, 콘텐츠 수요를 갖는 경우가 많습니다. 구조화된 상품 작업의 효과를 더 빨리 볼 수 있습니다.
주얼리 & 액세서리는 상품 페이지 스키마 비율이 **58.8%**로 높지만, 카테고리 표에서는 수동 또는 구조화형 llms.txt 탐지가 없습니다. 이는 준비도가 반드시 계층적으로 봐야 함을 보여 줍니다. 어떤 카테고리는 상품 스키마는 강하지만 AI 파일 품질은 약할 수 있습니다.
식품 & 음료에는 Maine Lobster Now, Yo Mama's Foods, NuRange Coffee, Manukora 같은 강한 긍정 사례가 포함됩니다. 식품과 음료 제품은 원재료, 영양성분, 1회 제공량, 구독, 원산지, 배송, 보관, 리뷰, 재고 가능 여부처럼 명확한 사실이 특히 중요합니다. 사이트가 이를 깔끔하게 노출해야만 AI 시스템이 정확하게 표현할 수 있습니다.
헬스 & 웰니스는 수동 또는 구조화형 llms 비율이 **10.3%**로 표의 주요 카테고리 중 가장 높지만, 평균 점수는 40.7점입니다. 이는 이 카테고리의 일부 브랜드가 AI 읽기 가능한 파일을 적극적으로 실험하고 있지만, 상품 페이지 구조는 여전히 개선 여지가 크다는 뜻입니다. 신뢰와 교육 부담이 큰 웰니스 카테고리라면 구조화된 사실에 가장 공격적으로 투자해야 합니다.
어떤 카테고리도 끝난 곳은 없습니다. 선도 카테고리조차 평균이 50점 미만입니다. 그래서 카테고리별 AI 준비도 콘텐츠는 SEO 작성자와 컨설턴트에게 강한 기회가 됩니다.
6. 좋은 모습은 무엇인가: AI 준비 브랜드의 긍정 패턴
ai_ready 그룹은 규모는 작지만, 따라 배울 만한 패턴을 보여 주기 때문에 유용합니다.
Mokobara는 83점으로 가장 높은 점수를 받았습니다. 단일 신호의 승리가 아니라, 강한 결합 준비도의 예시로 볼 수 있습니다.
Magic Mind, Le Petit Ballon, Maine Lobster Now는 모두 81점을 기록했고, 수동 구조화형 llms 구간에 속합니다. 이는 플랫폼 기본값만이 아니라 의도적인 파일 수준 작업이 있었다는 점에서 중요합니다.
Yo Mama's Foods는 80점을 기록했으며, 역시 수동 구조화형 llms에 속합니다. 식품 브랜드는 AI 읽기 가능한 구조의 혜택을 크게 받을 수 있습니다. AI 시스템이 원재료, 맛, 사용 사례, 레시피, 식이 적합성, 비교를 묻는 질문을 받을 수 있기 때문입니다.
Three Ships Beauty는 수동 구조화형 llms와 함께 77점을 받았습니다. 뷰티는 피부 타입, 성분, 루틴, 질감, 리뷰, 대안에 대해 쇼핑객이 자주 묻기 때문에, 구조화된 AI 준비도에 특히 적합한 카테고리입니다.
Manukora는 75점을 기록했습니다. 꿀과 웰니스에 가까운 식품 제품은 원산지, 품질, 효능, 인증, 사용법에 대한 교육이 필요한 경우가 많아, 구조화된 상품 및 정책 신호가 특히 유용합니다.
중요한 교훈은 모든 브랜드가 똑같아야 한다는 것이 아닙니다. 교훈은 AI 준비도가 하나의 시스템이라는 점입니다:
- 유용한 llms.txt 파일
- 깔끔한 메타데이터
- 구조화된 조직 및 웹사이트 데이터
- 상품 페이지 스키마
- 가격과 오퍼 신호
- 리뷰 또는 평점 신호
- 재고 가능 여부 신호
- 정책과 지원의 명확성
어느 한 층도 도움이 됩니다. 하지만 준비도를 만드는 것은 이들의 조합입니다.
7. llms.txt만으로는 충분하지 않은 이유
llms.txt는 AI 준비도의 편리한 축약어가 되었습니다. 보이기 쉽고, 확인하기 쉽고, 새로워서 전략적으로 느껴지기 때문입니다. 하지만 이 연구는 그것이 전부로 취급되어서는 안 되는 이유를 보여 줍니다.
플랫폼 기본값 llms.txt 파일은 기본적인 문을 만들어 줄 수 있습니다. 크롤러를 중요한 페이지로 안내할 수도 있습니다. 사이트에 AI 읽기 가능한 진입점이 있음을 기계에 알려 줄 수도 있습니다. 그러나 상품 페이지가 상품 정보를 명확히 노출하지 않는다면, 그 문은 결국 엉망인 방으로 이어집니다.
AI 검색 문제는 단지 “크롤러가 사이트를 찾을 수 있는가?”가 아닙니다. 다음과 같은 질문입니다:
- 크롤러가 상품을 식별할 수 있는가?
- 브랜드를 식별할 수 있는가?
- 가격을 파싱할 수 있는가?
- 재고 가능 여부를 파싱할 수 있는가?
- 리뷰나 평점을 식별할 수 있는가?
- 상품 콘텐츠와 마케팅 콘텐츠를 구분할 수 있는가?
- 정책을 이해할 수 있는가?
- 옵션을 비교할 수 있는가?
- 올바른 canonical 페이지를 인용할 수 있는가?
llms.txt는 탐색과 우선순위 지정에 도움이 됩니다. 구조화된 상품 데이터는 이해에 도움이 됩니다. AI 준비도에는 둘 다 필요합니다.
8. 운영팀을 위한 플레이북: AI 검색 준비도를 높이는 방법
DTC 및 이커머스 팀에게 실무 흐름은 비교적 간단합니다.
1단계: AI 파일 층을 확인하세요. 도메인에 llms.txt가 있나요? 실제 파일인가요, 아니면 소프트 404인가요? 플랫폼 기본값인가요, 수동 간단형인가요, 구조화형인가요? 유용한 페이지를 가리키고 있나요?
2단계: 메타데이터를 점검하세요. canonical 태그, 메타 설명, Open Graph 이미지, Twitter 카드, 관련성이 있다면 hreflang, 모바일 viewport를 확인하세요. 화려하지는 않지만 기계가 맥락을 만드는 데 도움이 됩니다.
3단계: JSON-LD를 검증하세요. Organization, WebSite, BreadcrumbList, Product 스키마를 확인하세요. 이커머스에서 가장 중요한 격차는 Product 스키마입니다.
4단계: 홈페이지만 보지 말고 상품 페이지를 점검하세요. AI 쇼핑은 상품 페이지를 중요하게 봅니다. 상품명, 설명, 이미지, 가격, 오퍼, 재고 가능 여부, SKU, 리뷰, 평점, 옵션, 반품 정책을 확인하세요.
5단계: 상품 정보를 안정적으로 만드세요. 중요한 상품 정보를 이미지, 깔끔하게 렌더링되지 않는 탭, 크롤러가 파싱하지 못할 수 있는 JavaScript 위젯에만 숨기지 마세요.
6단계: 정책의 명확성을 높이세요. 배송, 반품, 구독 약관, 보증, 인증, 안전 주장 등을 쉽게 찾고 쉽게 파싱할 수 있어야 합니다.
7단계: 템플릿 변경 후 다시 테스트하세요. 스키마는 리디자인, 테마 변경, 앱 변경, 헤드리스 마이그레이션 중에 자주 깨집니다. 구조화 데이터를 QA의 일부로 취급하세요.
8단계: 시스템의 주인은 명확해야 합니다. AI 준비도는 SEO만의 일이 아닙니다. 이커머스, 상품, 콘텐츠, 엔지니어링, 법무, 고객 지원이 모두 연결됩니다.
9. SEO와 콘텐츠 팀이 인용할 수 있는 포인트
이 연구는 몇 가지 강력한 인용 포인트를 제공합니다:
“평가된 1,238개 DTC 도메인 중 AI 준비됨 등급에 도달한 곳은 11개뿐입니다.” 가장 넓은 준비도 훅입니다.
“llms.txt는 흔하지만, 대부분 플랫폼이 생성한 것입니다.” 플랫폼 기본값 구간에는 629개 도메인이 있고, 수동 구조화형 파일은 31개에 불과합니다.
“홈페이지 Product 스키마는 평가된 도메인의 0.9%에서만 나타납니다.” 가장 날카로운 구조화 데이터 격차입니다.
“상품 페이지 Product 스키마는 상품 페이지를 시도한 경우 39.2%에서 나타납니다.” 뉘앙스를 더합니다. 상품 페이지가 홈페이지보다 낫지만 여전히 불완전하다는 뜻입니다.
“뷰티와 의류가 카테고리 표에서 앞서지만, 여전히 평균 50/100 미만입니다.” 카테고리별 접근 포인트를 만듭니다.
“AI 준비도는 계층적입니다.” llms.txt를 준비도와 동일시할 수 있는 독자에게 가장 중요한 교육 포인트입니다.
주의점도 중요합니다. 이 데이터는 이 표본의 공개 웹사이트 신호를 반영할 뿐, 전체 산업 채택률이나 내부 검색 성과를 나타내지는 않습니다.
10. AI 쇼핑이 DTC 팀에 바꾸는 것
기존 이커머스 발견은 페이지, 순위, 광고, 클릭을 중심으로 구축되었습니다. 쇼핑객은 검색하고, 결과를 비교하고, 페이지를 열고, 리뷰를 읽고, 결정을 내렸습니다. AI 쇼핑과 답변 엔진은 그 과정을 압축합니다. 쇼핑객은 “평일 저녁 파스타에 좋은 저당 소스”, “후기 좋은 200달러 이하 기내용 배낭”, “향 없는 민감성 피부용 순한 클렌저”를 물을 수 있습니다. AI 시스템은 쇼핑객이 브랜드 페이지를 보기 전에 옵션을 요약할 수 있습니다.
이것은 상품 페이지의 역할을 바꿉니다. 페이지는 여전히 사람을 설득해야 하지만, 동시에 기계가 비교할 수 있을 만큼 상품을 명확하게 설명해야 합니다. 브랜드 톤만으로는 충분하지 않습니다. 아름다운 이미지도 충분하지 않습니다. 기발한 상품명도 충분하지 않습니다. 기계는 사실이 필요합니다. 무엇인지, 누구를 위한 것인지, 가격이 얼마인지, 구매 가능한지, 어떤 옵션이 있는지, 리뷰는 무엇을 말하는지, 어떤 주장이 뒷받침되는지, 어떤 원재료나 소재가 중요한지, 어떤 정책이 적용되는지 같은 사실입니다.
그래서 일반적인 AI 파일보다 상품 수준 구조가 더 중요합니다. llms.txt는 크롤러가 어디를 봐야 하는지 이해하도록 도울 수 있습니다. Product 스키마와 깔끔한 상품 페이지 정보는 크롤러가 무엇을 찾았는지 이해하도록 도와줍니다.
DTC 브랜드의 위험은 단지 배제되는 것만이 아닙니다. 잘못 표현되는 것입니다. 상품 페이지가 불명확하면 AI 답변이 잘못된 기능을 요약하거나, 핵심 차별점을 놓치거나, 중요한 정책을 누락하거나, 더 잘 구조화된 경쟁사와 불공정하게 비교할 수 있습니다. 그런 의미에서 AI 준비도는 부분적으로 브랜드 보호 이슈이기도 합니다.
복잡한 고려 경로가 있는 카테고리일수록 위험은 더 큽니다. 뷰티 쇼핑객은 피부 타입, 성분, 루틴, 민감성, 결과를 묻습니다. 식품 쇼핑객은 영양, 알레르기 유발 물질, 원산지, 맛, 레시피, 식단 적합성을 묻습니다. 의류 쇼핑객은 핏, 사이즈, 소재, 반품, 스타일링을 묻습니다. 웰니스 쇼핑객은 근거, 사용법, 안전성, 신뢰를 묻습니다. 홈 카테고리 쇼핑객은 크기, 소재, 배송, 조립, 내구성을 묻습니다. 이 모든 것은 마케팅 문제이기도 하지만, 동시에 기계가 읽을 수 있어야 하는 콘텐츠 문제입니다.
기회는 대부분의 브랜드가 아직 초기 단계라는 점입니다. 평균 준비도 점수는 36.4/100에 불과하고, ai_ready 등급에 도달한 도메인은 11개뿐입니다. 브랜드가 전체 사이트를 다시 만드는 일을 기다릴 필요는 없습니다. 템플릿, 스키마, 정책 명확성, 상품 정보부터 시작할 수 있습니다.
11. 부서별 AI 준비도 계획
AI 준비도는 SEO만의 책임이 되어서는 안 됩니다. 여러 팀이 관여합니다.
SEO는 발견 가능성과 스키마 검증을 담당합니다. canonical 태그, 메타데이터, 구조화 데이터, Product 스키마, breadcrumbs, hreflang, 크롤러 접근성을 점검해야 합니다. 또한 테마 변경과 앱 업데이트 이후에도 Product 스키마가 유지되는지 모니터링해야 합니다.
이커머스는 상품 페이지 정보를 담당합니다. 상품명, 가격, 옵션, 재고 가능 여부, 번들, 구독, 리뷰, 배송 약관, 반품 세부사항이 명확하고 일관되어야 합니다. 이런 정보가 위젯, 탭, 이미지, 스크립트로 분산되면 기계가 어려움을 겪을 수 있습니다.
콘텐츠는 설명의 깊이를 담당합니다. AI 시스템은 질문에 명확하게 답하는 페이지를 선호합니다. 구매 가이드, 비교표, 성분 설명, 사용 사례 페이지, 사이즈 가이드, FAQ 섹션은 사람과 기계 모두에게 도움이 됩니다.
엔지니어링은 구현 품질을 담당합니다. 스키마는 유효하고, 안정적이며, 템플릿 기반이어야 합니다. 상품 정보가 취약한 클라이언트 사이드 렌더링에 전적으로 의존해서는 안 됩니다. 상품 페이지 템플릿은 배포 후 테스트되어야 합니다.
법무와 컴플라이언스는 주장 관리를 담당합니다. 상품이 건강, 지속 가능성, 안전, 원재료, 성능 관련 주장을 한다면 그 주장은 정확하고, 입증 가능하며, 해석하기 쉬워야 합니다. AI 시스템은 불분명한 주장을 증폭시킬 수 있습니다.
고객 지원은 반복 질문을 담당합니다. 지원 티켓은 쇼핑객과 AI 시스템이 무엇을 물을지 보여 줍니다. 배송 시간, 핏, 원재료, 호환성, 반품, 구독 취소, 관리 방법, 상품 비교 같은 질문입니다. 이런 질문은 상품 페이지 콘텐츠로 이어져야 합니다.
리더십은 우선순위를 담당합니다. AI 준비도는 다른 많은 프로젝트와 경쟁합니다. 리더십 관점의 핵심은 간단합니다. 구조화된 상품 정보는 SEO, AI 검색, 상품 피드, 유료 쇼핑, 사이트 내 검색, 지원, 전환을 모두 돕습니다. 이것은 단지 AI 프로젝트가 아닙니다.
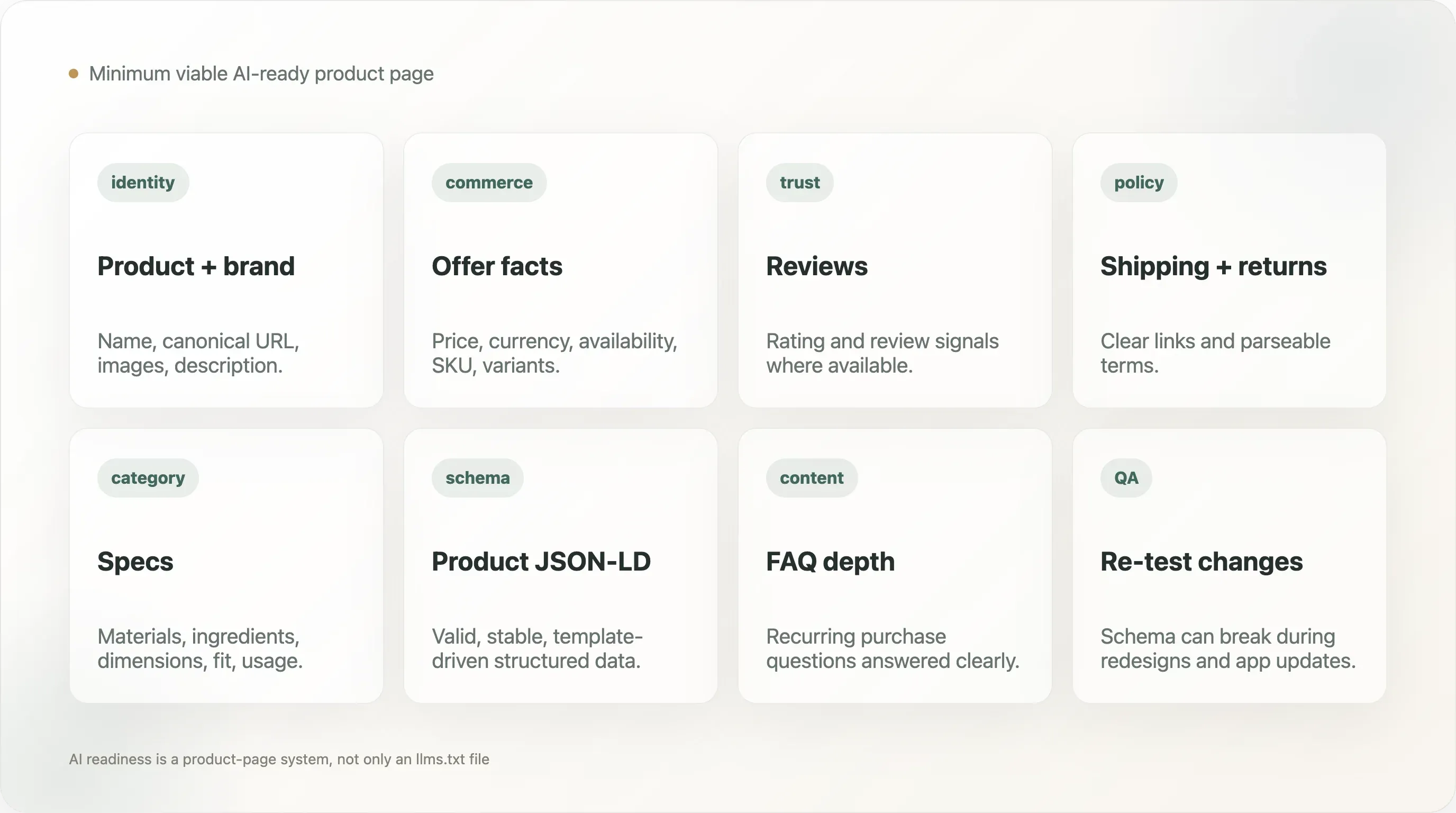
12. 최소 실행 가능 AI 준비 상품 페이지
실용적인 DTC 상품 페이지는 다음을 노출해야 합니다:
- 상품명
- 브랜드명
- canonical URL
- 상품 설명
- 상품 이미지
- 가격
- 통화
- 재고 가능 여부
- 옵션 정보
- 관련성이 있다면 SKU 또는 상품 식별자
- 가능한 경우 리뷰 또는 평점 신호
- 오퍼 세부사항
- 배송 및 반품 정책 링크
- 카테고리에 따라 관련 있는 소재, 원재료, 사양 정보
- 반복 구매 질문을 위한 FAQ 또는 지원 콘텐츠
페이지에는 유효한 Product 스키마가 포함되어야 하며, 크롤러가 파싱하지 못할 수 있는 이미지나 스크립트 안에 중요한 사실만 숨기지 않아야 합니다. 그렇다고 지루한 상품 페이지를 만들라는 뜻은 아닙니다. 설득력 있는 디자인과 신뢰할 수 있는 구조화 사실을 분리하라는 뜻입니다.
많은 브랜드에게 가장 빠른 성과는 긴 AI 전략 문서를 쓰는 것이 아닙니다. 중요한 상품 페이지 10개를 검증하고, 스키마를 수정하고, 가장 중요한 상품 사실이 HTML과 구조화 데이터에 보이도록 만드는 것입니다.
방법론
이 연구는 2026년 5월 11일에 수집된 DTC 듀얼 리포트 데이터셋을 사용합니다. master.csv, detection.csv, seo_signals.csv, 원본 llms.txt 파일, 그리고 사용 가능한 경우 원본 상품 페이지 HTML을 사용해 1,238개 도메인을 평가했습니다.
점수 모델은 네 가지 층으로 나뉩니다:
- AI 파일 층: llms.txt 존재 여부와 품질.
- 일반 구조화 데이터 층: JSON-LD, Organization, WebSite, BreadcrumbList, Product 및 관련 구조화 신호.
- 상품 페이지 층: Product 스키마, 오퍼 또는 가격 신호, 리뷰 또는 평점 신호, 재고 가능 여부 신호.
- 메타데이터 층: canonical, 메타 설명, Open Graph 이미지, Twitter 카드, hreflang 및 관련 페이지 맥락.
이 모델은 0에서 100까지의 AI 준비도 점수를 산출하고, 도메인을 준비 안 됨, 부분적으로 준비됨, 기본 발견 가능, ai_ready 네 가지 등급 중 하나로 분류합니다.
주의사항
-
AI 준비도는 AI 트래픽이 아닙니다. 이 점수는 AI 검색 시스템이나 쇼핑 에이전트로부터의 실제 유입을 측정하지 않습니다.
-
공개 신호는 하한선입니다. 일부 구조화 데이터는 동적으로 로드되거나 크롤링이 포착하지 못한 방식으로 나타날 수 있습니다.
-
llms.txt 품질은 휴리스틱입니다. 수동 구조화형 파일은 제목, 링크, 상품 용어, 정책 용어 같은 관찰 가능한 파일 특성으로 식별합니다.
-
상품 페이지 탐지는 시도된 상품 페이지 가져오기에 의존합니다. 상품 페이지 스키마 비율은 상품 페이지를 시도했고 이용 가능했던 경우에 적용됩니다.
-
표본은 전체 DTC 모집단이 아닙니다. 이커머스 도구 생태계와 공개 DTC 목록에서 보이는 브랜드에 편향되어 있습니다.
-
카테고리 라벨은 방향성입니다. 넓은 비교에는 유용하지만 정확한 분류 체계는 아닙니다.
-
AI 검색 표준은 계속 변화하고 있습니다. 이 점수 모델은 영구적인 정의가 아니라 2026년의 실용적 기준점으로 설계되었습니다.
재현성 참고
배포 폴더에는 다음이 포함됩니다:
analyze_ai_search_readiness.py—llms.txt, 구조화 데이터, 상품 페이지 신호, 메타데이터 신호 전반에서 DTC 도메인을 평가하는 데 사용된 점수 스크립트.ai_search_readiness_scores.csv— 도메인 수준의 AI 준비도 점수, 등급, 구성 요소 신호.llms_quality_audit.csv— 플랫폼 기본값, 소프트 404, 없음, 수동 간단형, 수동 구조화형 분류를 포함한 도메인 수준llms.txt품질 감사.category_ai_readiness.csv— 카테고리 수준 AI 준비도 비교.top_ai_ready_brands.csv— 편집 검토와 예시 선정을 위한 최고 점수 도메인.lowest_ai_ready_brands.csv— 격차 분석과 편집 검토를 위한 최저 점수 도메인.summary.json— 표본 크기, 등급 수, 평균 점수, 중앙값, 상품 페이지 신호 비율을 포함해 이 보고서에서 인용한 핵심 집계 지표.
방법론 수정, 데이터셋 이슈, 후속 분석 제안은 support@thunderbit.com 으로 보내 주세요. 이 보고서는 Thunderbit의 상업적 입장과 무관하게 발행되었으며, 우리는 AI 기반 웹 스크래퍼를 만들고 있고, 공개 이커머스 웹사이트가 사람과 검색 엔진, AI 에이전트에게 더 정확히 이해되기 쉬워지는 데 구조적 이해관계가 있습니다. 이 벤치마크는 2026년 5월 11일에 수집된 공개 웹사이트 신호를 바탕으로 평가된 1,238개의 DTC 도메인을 기반으로 합니다. 이 보고서의 데이터는 그 자체로 의미를 가집니다. — Thunderbit 연구팀, 2026년 5월.