
웹은 데이터로 가득하고, 솔직히 제품 목록이나 경쟁사 가격 페이지를 천 번씩 복사해 붙여넣을 시간은 아무도 없어요. 제가 대부분의 자동화와 개발 작업에 Linux를 쓰는 것처럼, 이 플랫폼이 데이터 중심 팀에 꽤 강력한 도구라는 사실도 이미 알고 계실 거예요. 실제로 , 하고 있어요. 다만 문제는, 비기술직 비즈니스 사용자든 숙련된 개발자든 상관없이 내 작업 방식에 딱 맞는 Linux용 웹 스크래퍼를 찾는 일이 사막에서 바늘 찾기처럼 느껴질 수 있다는 점이죠.
그래서 이번 글에서는 2026년 최고의 Linux 웹 스크래핑 도구 18선을 깊이 있게 정리해 봤어요. 같은 AI 기반 노코드 솔루션부터(네, 제 팀과 제가 직접 만든 도구예요) Scrapy와 Beautiful Soup 같은 클래식 개발 프레임워크까지, 이 목록은 시행착오의 스트레스 없이 내게 맞는 최고의 Linux 웹 스크래퍼를 고르는 지름길이 되어줄 거예요.
비즈니스 사용자에게 Linux 웹 스크래핑 도구가 중요한 이유
현실적으로 말해 볼게요. 수동으로 데이터를 모으는 건 생산성을 갉아먹는 주범이에요. 연구에 따르면 복사-붙여넣기 방식에 의존하는 팀은 매주 수 시간을 허비하고, 오류율도 거의 5%에 달한다고 해요. 이는 비용이 큰 실수와 놓친 기회로 이어지는 지름길이죠(). 안정성, 보안, 유연성을 갖춘 Linux는 데스크톱, 서버, 클라우드 어디에서든 24시간 돌아가야 하는 스크래퍼를 실행하기에 최적의 플랫폼이에요.
Linux 웹 스크래핑 도구의 대표적인 비즈니스 활용 사례:
- 리드 생성: 영업팀이 디렉터리, 소셜 미디어, 리뷰 사이트에서 새 연락처를 수집해 수작업을 줄여요().
- 가격 모니터링: 이커머스 팀이 경쟁사 가격과 재고 데이터를 자동으로 가져와 자사 가격 전략을 더 빠르고 정확하게 조정해요.
- 경쟁사 조사: 마케팅 및 운영팀이 제품 출시, 리뷰, SEO 키워드를 추적해 더 이상 감에만 의존하지 않아요.
- 시장 인텔리전스: 분석가가 뉴스, 포럼, 소셜 데이터를 모아 트렌드를 실시간으로 포착해요.
- 업무 자동화: 일부 도구, 특히 AI 기반 도구는 Linux 환경에서 바로 폼 입력이나 대시보드 탐색 같은 웹 워크플로까지 자동화할 수 있어요.
가장 좋은 점은? 적절한 Linux 웹 스크래핑 도구만 있으면 코더뿐 아니라 비기술 사용자도 웹 데이터를 활용해 더 똑똑하고 빠른 비즈니스 결정을 내릴 수 있다는 거예요.
Linux용 최고의 웹 스크래퍼를 고르는 기준
특히 Linux에서는 모든 스크래퍼가 똑같지 않아요. 제가 본 핵심 기준은 다음과 같아요:
- Linux 호환성: 여기 소개하는 모든 도구는 Linux에서 네이티브로 실행되거나, 브라우저를 통해 사용하거나, Wine이나 클라우드 접근 같은 간단한 우회 방법으로 쓸 수 있어요.
- 사용 편의성: 자연어 AI 프롬프트부터 시각적인 클릭형 인터페이스까지, 비코더도 빠르게 결과를 낼 수 있는 도구를 우선했어요. 물론 완전한 제어를 원하는 파워 유저도 놓치지 않았고요.
- 데이터 추출 성능: 동적 콘텐츠, 페이지네이션, 하위 페이지, 다양한 데이터 유형을 처리할 수 있는지? 차단 회피 장치에도 버틸 수 있는지?
- 확장성 및 자동화: 예약 실행, 클라우드 스크래핑, 분산 크롤링은 진지한 데이터 프로젝트라면 필수예요.
- 연동 및 내보내기: CSV, Excel, Google Sheets, API 등으로 데이터를 꺼낼 수 있어야 의미가 있죠.
- 가격 및 라이선스: 무료, 오픈소스, 유료까지—솔로 창업자부터 엔터프라이즈 팀까지 예산에 맞는 선택지가 있어야 해요.
- 커뮤니티 및 지원: 활발한 사용자층, 좋은 문서, 빠른 지원은 문제를 만났을 때 큰 차이를 만들어요.
여기에 실제 사용자 피드백, 업계 리뷰, 그리고 제가 직접 사용해 본 경험도 함께 반영했어요. 이제 목록을 살펴볼게요.
1. Thunderbit
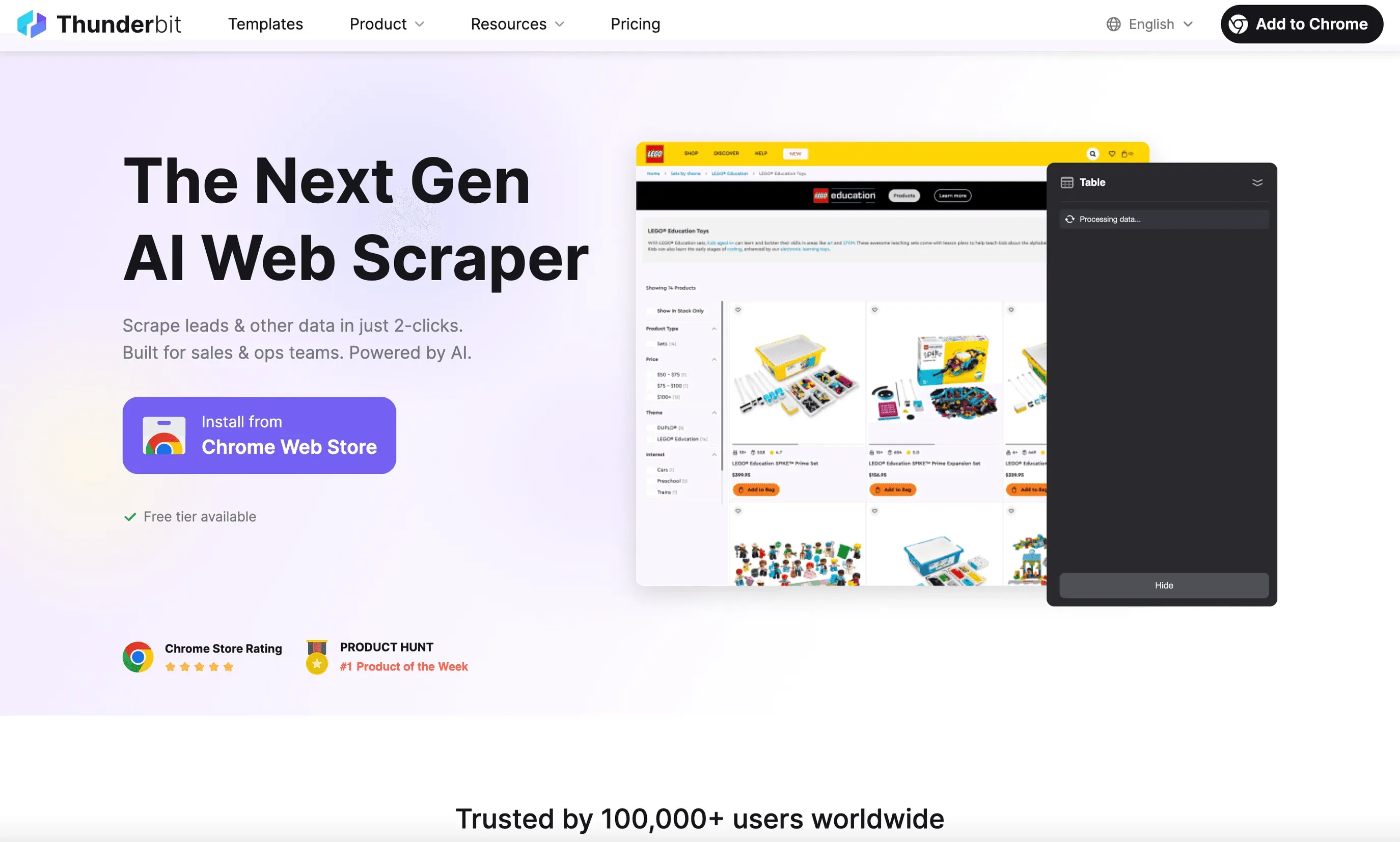 는 제가 비즈니스 사용자에게 가장 먼저 추천하는, Linux용 웹 스크래퍼예요. 으로 Linux에서 완벽하게 작동하고(Chrome이나 Chromium만 열면 돼요), 어떤 웹사이트든 두 번의 클릭만으로 데이터를 추출할 수 있어요.
는 제가 비즈니스 사용자에게 가장 먼저 추천하는, Linux용 웹 스크래퍼예요. 으로 Linux에서 완벽하게 작동하고(Chrome이나 Chromium만 열면 돼요), 어떤 웹사이트든 두 번의 클릭만으로 데이터를 추출할 수 있어요.
Thunderbit가 돋보이는 이유:
- 자연어 프롬프트: 원하는 내용을 그냥 설명하기만 하면 돼요. (“이 페이지의 모든 제품명과 가격을 추출해 줘”) 나머지는 Thunderbit의 AI가 알아서 처리해요.
- AI 필드 추천: 한 번 클릭하면 Thunderbit가 페이지를 스캔해서 열과 데이터 유형을 제안해 줘요. 수동으로 필드를 고를 필요가 없어요.
- 하위 페이지 및 페이지네이션 스크래핑: 더 자세한 정보가 필요하신가요? Thunderbit는 각 하위 페이지(예: 제품 상세 페이지)를 방문해 표를 자동으로 확장해 줘요.
- 클라우드 또는 로컬 스크래핑: 클라우드에서는 한 번에 최대 50페이지까지 추출할 수 있고, 로그인 필요한 사이트는 브라우저 모드로 처리할 수 있어요.
- 즉시 내보내기: Excel, Google Sheets, Airtable, Notion, CSV, JSON으로 한 번에 내보내기 가능하고, 항상 무료예요.
- 추가 도구: 이메일, 전화번호, 이미지를 한 번의 클릭으로 추출할 수 있어요. AI 오토필로 폼 입력도 자동화할 수 있고요.
가격: 무료 플랜(6~10페이지 추출 가능), 유료 플랜은 500행 기준 월 15달러부터 시작해요(). 사용자들은 “학습 곡선이 거의 없다”는 점과 “몇 시간 걸리던 일을 몇 분으로 바꿔 준다”는 점을 특히 좋아해요(). 대규모 작업은 여러 번으로 나눠야 할 수 있지만, 대부분의 비즈니스 활용 사례에서는 엄청난 시간 절약 효과를 줘요.
Linux 호환성: 100%. Linux 데스크톱이나 서버에서 Chrome/Chromium만 실행하면 돼요.
추천 대상: 가장 빠르고 쉬운 설정을 원하는 비기술직 비즈니스 사용자(영업, 마케팅, 운영).
2. Scrapy
 는 유연하고 확장성 있는 Linux용 웹 스크래퍼를 원하는 Python 개발자에게 가장 표준적인 선택이에요. 오픈소스이고, 매우 빠르며(비동기 크롤링), 간단한 스크래핑부터 대규모 분산 크롤링까지 모두 처리할 수 있어요.
는 유연하고 확장성 있는 Linux용 웹 스크래퍼를 원하는 Python 개발자에게 가장 표준적인 선택이에요. 오픈소스이고, 매우 빠르며(비동기 크롤링), 간단한 스크래핑부터 대규모 분산 크롤링까지 모두 처리할 수 있어요.
핵심 기능:
- 비동기 고속 크롤링 — 수천 페이지를 긁어오기에 딱 좋아요.
- 높은 확장성: 프록시, CAPTCHA 등 각종 플러그인을 지원해요.
- Python 데이터 스택과 연동: JSON, CSV, 데이터베이스, pandas로 출력 가능해요.
- 쿠키, 세션, 자동 속도 조절 지원.
가격: 100% 무료 오픈소스.
Linux 호환성: 네이티브(pip으로 설치). 서버와 컨테이너에서도 잘 작동해요.
추천 대상: 맞춤형 대규모 스크래퍼를 만드는 개발자.
참고: 비코더에게는 학습 곡선이 있지만, Python을 안다면 Scrapy는 정말 강력해요.
3. Beautiful Soup
 은 HTML과 XML을 파싱하기 위한 가벼운 Python 라이브러리예요. 빠르게 간단히 스크래핑하거나 지저분한 웹페이지를 정리할 때 가장 많이 쓰여요.
은 HTML과 XML을 파싱하기 위한 가벼운 Python 라이브러리예요. 빠르게 간단히 스크래핑하거나 지저분한 웹페이지를 정리할 때 가장 많이 쓰여요.
핵심 기능:
- 단순하고 직관적인 API — 초보자에게 좋아요.
- requests와 함께 사용하기 좋음 — 페이지 가져오기에 잘 맞아요.
- 깨진 HTML도 유연하게 처리.
가격: 무료 오픈소스.
Linux 호환성: 100%(순수 Python).
추천 대상: 소규모~중간 규모의 스크래핑 또는 파싱 작업을 하는 개발자와 데이터 과학자.
제한점: JavaScript나 동적 콘텐츠는 처리하지 못해요. 그런 경우 Selenium이나 Puppeteer와 함께 쓰면 돼요.
4. Selenium
 은 클래식한 브라우저 자동화 프레임워크예요. Chrome, Firefox 같은 브라우저를 제어해서 동적이고 JavaScript가 많은 사이트를 스크래핑할 수 있어요.
은 클래식한 브라우저 자동화 프레임워크예요. Chrome, Firefox 같은 브라우저를 제어해서 동적이고 JavaScript가 많은 사이트를 스크래핑할 수 있어요.
핵심 기능:
- 실제 브라우저를 자동화 — 로그인, 클릭, 스크롤, 상호작용을 사람처럼 할 수 있어요.
- Python, Java, C# 등 다양한 언어 지원.
- 헤드리스 모드로 Linux 서버에서도 실행 가능해요.
가격: 무료 오픈소스.
Linux 호환성: 완전 지원(적절한 브라우저 드라이버만 설치하면 돼요).
추천 대상: QA 엔지니어, 스크래핑 개발자, 사용자 행동을 시뮬레이션해야 하는 사람.
참고: 자원 소모가 크고 순수 HTTP 스크래퍼보다 느리지만, 필요한 데이터를 얻는 유일한 방법일 때도 있어요.
5. Puppeteer
 는 Google이 만든 Node.js 라이브러리로, 헤드리스 Chrome/Chromium을 제어할 수 있어요. Selenium과 비슷하지만, 현대적인 JavaScript API와 Chrome 기능과의 강한 통합이 장점이에요.
는 Google이 만든 Node.js 라이브러리로, 헤드리스 Chrome/Chromium을 제어할 수 있어요. Selenium과 비슷하지만, 현대적인 JavaScript API와 Chrome 기능과의 강한 통합이 장점이에요.
핵심 기능:
- JavaScript 실행, 동적 콘텐츠 처리, 스크린샷 촬영 가능.
- 빠르고 안정적이며, Node.js 개발자에게 사용하기 쉬움.
- 네트워크 요청을 가로채고 불필요한 리소스를 차단할 수 있음.
가격: 무료 오픈소스.
Linux 호환성: Chromium이 자동 설치되고, 기본적으로 헤드리스로 작동해요.
추천 대상: 현대적인 웹앱이나 싱글 페이지 사이트를 스크래핑하는 개발자.
6. Octoparse
 는 드래그 앤 드롭 인터페이스와 수많은 사전 제작 템플릿을 갖춘 노코드 웹 스크래퍼예요. 데스크톱 앱은 Windows/Mac 전용이지만, Linux 사용자는 브라우저를 통해 Octoparse의 클라우드 플랫폼에 접근하거나 Wine으로 Windows 앱을 실행할 수 있어요.
는 드래그 앤 드롭 인터페이스와 수많은 사전 제작 템플릿을 갖춘 노코드 웹 스크래퍼예요. 데스크톱 앱은 Windows/Mac 전용이지만, Linux 사용자는 브라우저를 통해 Octoparse의 클라우드 플랫폼에 접근하거나 Wine으로 Windows 앱을 실행할 수 있어요.
핵심 기능:
- Amazon, eBay, Zillow 등 사이트용 100개 이상의 готов?