

2026년 데이터 시장 온도가 한 번 더 올라갔어요. 영업, 이커머스, 부동산 어느 쪽이든 웹에 쌓인 정보를 자기 자산으로 바꾸느냐가 매출 격차로 이어지는 시대예요. 셀에 일일이 붙여 넣는 방식은 더 이상 답이 아니에요. 숫자 하나만 봐도 분위기가 보입니다. Mordor Intelligence 집계로 글로벌 웹 스크래핑 시장은 2025년 10억 3천만 달러(약 1조 4천억 원)를 찍었고(PromptCloud의 2026년 웹 스크래핑 현황 보고서 인용), 2030년까지 거의 두 배로 커질 전망이에요.
빅테크만의 이야기도 아니에요. Browsercat 조사로는 **이커머스 기업 82%**와 투자사 3분의 1 이상이 리드, 가격, 시장 조사용으로 웹 데이터를 긁어모으고 있어요. 정리하면, 스크래핑 도구를 안 쓰고 있다면 매출과 인사이트를 그냥 흘려보내는 셈이에요.
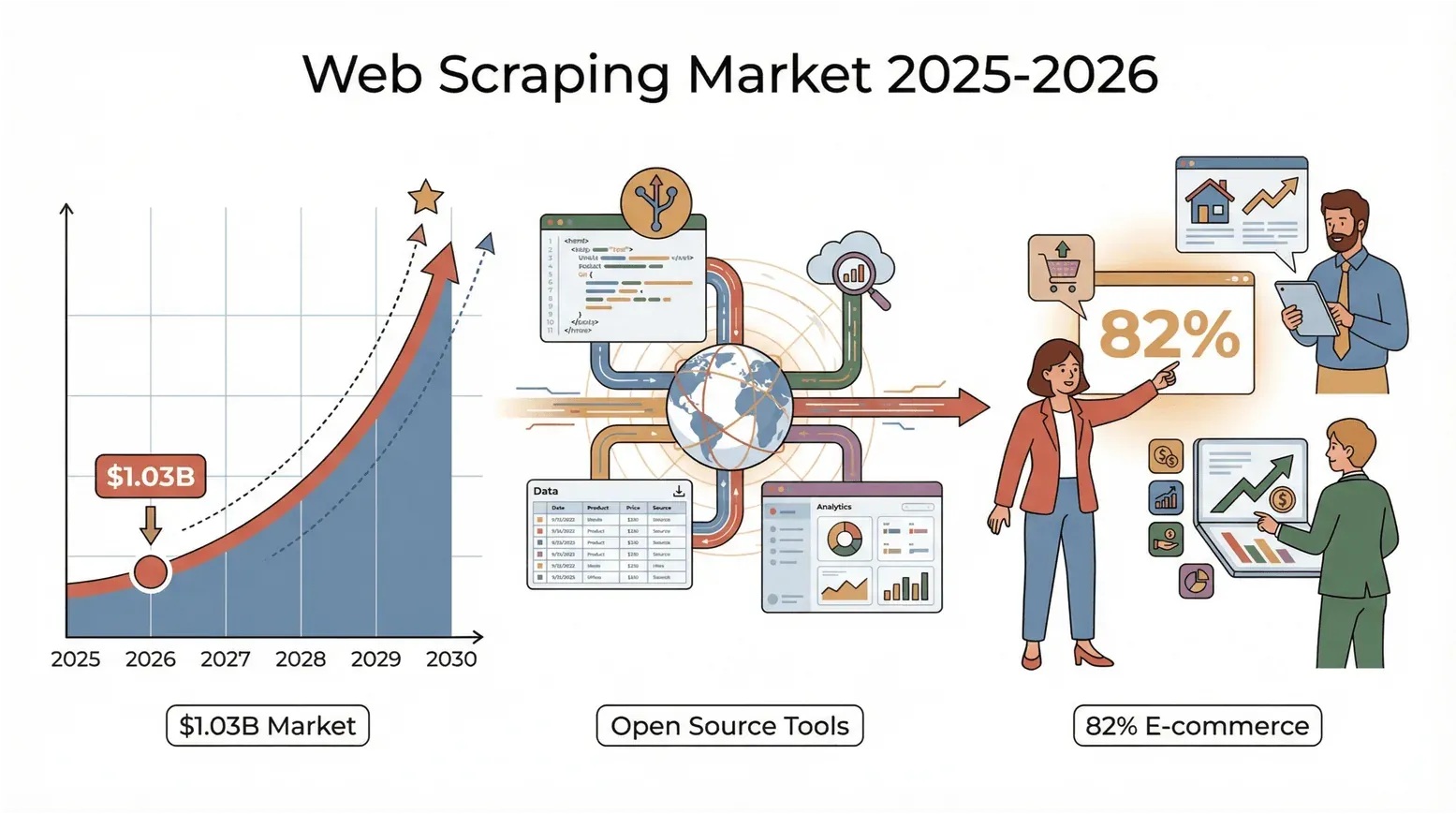
다행인 점도 있어요. 오픈 소스 웹 스크래핑 도구는 예전과 비교가 안 될 만큼 강




