

웹 스크래핑에는 어떤 프로그래밍 언어를 써야 할까요? 정답은 프로젝트마다 달라요. 그리고 언어를 잘못 고른 탓에 개발자가 폭발 직전까지 간 경우도 여러 번 봤어요.
웹 스크래핑 소프트웨어 시장은 2024년 10억 1천만 달러 규모에 닿았고, 2032년까지 두 배 넘게 성장할 전망이에요. 언어를 잘 고르면 결과는 더 빨라지고 유지보수는 줄어요. 반대로 잘못 고르면 깨진 스크래퍼와 허무하게 날린 주말만 남고요.
저는 수년간 자동화 도구를 만들어 왔어요. 여기서는 제가 웹 스크래핑에 직접 써 본 7가지 언어를 풀어볼게요. 코드 예시, 솔직한 장단점, 그리고 아예 코딩을 건너뛰고 Thunderbit을 써야 하는 경우까지 같이 살펴볼게요.
웹 스크래핑에 가장 적합한 언어를 고르는 기준
웹 스크래핑에서는 모든 프로그래밍 언어가 똑같지 않아요. 몇 가지 핵심 요소에 따라 프로젝트가 크게 성공하거나, 반대로 무너지는 걸 여러 번 봤어요.
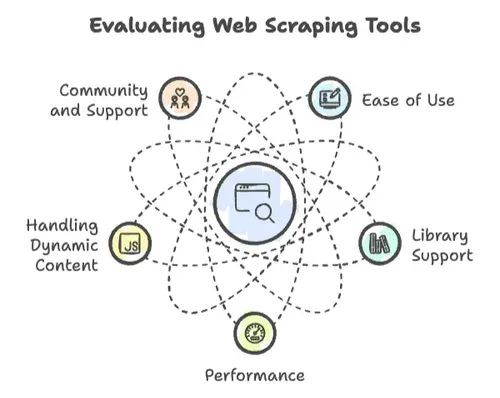
- 사용 편의성: 얼마나 빨리 시작할 수 있나요? 문법이 직관적인가요, 아니면 "Hello, World" 하나 출력하려고 컴퓨터공학 박사 학위가 필요한가요?
- 라이브러리 지원: HTTP 요청, HTML 파싱, 동적 콘텐츠 처리용 라이브러리가 탄탄한가요? 아니면 전부 직접 다시 만들어야 하나요?
- 성능: 수백만 페이지를 스크래핑할 수 있나요, 아니면 몇백 페이지만 넘어도 한계가 오나요?
- 동적 콘텐츠 처리: 요즘 웹사이트는 자바스크립트를 좋아해요. 언어가 그 속도를 따라가나요?
- 커뮤니티와 지원: 막다른 벽에 부딪혔을 때(분명 한 번쯤은 그래요), 도와줄 커뮤니티가 있나요?
이 기준과 수많은 야간 테스트를 바탕으로, 제가 다룰 7가지 언어는 이래요.
- Python: 초보자와 전문가 모두에게 가장 먼저 떠오르는 선택.
- JavaScript & Node.js: 동적 콘텐츠의 왕.
- Ruby: 깔끔한 문법, 빠른 스크립트.
- PHP: 서버 측의 단순함.
- C++: 순수 속도가 필요할 때.
- Java: 엔터프라이즈급과 확장성.
- Go (Golang): 빠르고 동시에 여러 작업을 처리하는 언어.
그리고 "저는 아예 코딩하고 싶지 않은데요"라는 생각이 든다면, 끝까지 봐 주세요. 마지막에 Thunderbit을 소개할게요.
Python 웹 스크래핑: 초보자에게도 친숙한 강력한 선택
가장 인기 있는 언어부터 시작할게요. 바로 Python이에요. 데이터 하는 사람들이 가득한 방에 들어가서 "웹 스크래핑에 가장 좋은 언어가 뭐예요?"라고 물으면, 콘서트 떼창처럼 Python이라는 답이 돌아올 거예요.
왜 Python일까요?
- 초보자 친화적인 문법: Python 코드는 소리 내어 읽어도 거의 영어처럼 들려요.
- 비교 불가한 라이브러리 지원: HTML 파싱용 BeautifulSoup, 대규모 크롤링용 Scrapy, HTTP용 Requests, 브라우저 자동화용 Selenium까지 Python엔 다 있어요.
- 거대한 커뮤니티: 웹 스크래핑만 해도 Stack Overflow 질문이 33,000개 이상 쌓여 있어요.
Python 샘플 코드: 페이지 제목 가져오기
import requests
from bs4 import BeautifulSoup
response = requests.get("<https://example.com>")
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.string
print(f"페이지 제목: {title}")
장점
- 빠른 개발과 프로토타이핑.
- 튜토리얼과 Q&A가 정말 많음.
- 데이터 분석과 궁합이 좋음. Python으로 스크래핑하고, pandas로 분석하고, matplotlib으로 시각화할 수 있어요.
- 라이브러리도 계속 진화 중. Scrapy 2.14(2026년 1월)에서는 프레임워크 전반에 네이티브
async/await가 들어와서, 이제 비동기 이야기가 Selenium·Playwright만의 전유물이 아니에요.
한계
- 대규모 작업에서는 컴파일 언어보다 느려요.
- 아주 동적인 사이트를 다루면 좀 번거로울 수 있어요(그래도 Selenium과 Playwright가 도와줘요).
- 수백만 페이지를 초고속으로 스크래핑하는 용도엔 최적이 아니에요.
한줄 요약
스크래핑이 처음이거나 그냥 빨리 결과를 내고 싶다면 Python이 웹 스크래핑에 가장 좋은 언어예요. 왜 Python이 웹 스크래핑을 지배하는지 더 알아보기.
JavaScript & Node.js: 동적 웹사이트를 손쉽게 스크래핑
Python이 만능 도구라면, **JavaScript(그리고 Node.js)**는 전동 드릴이에요. 특히 자바스크립트 중심의 최신 웹사이트를 스크래핑할 때 강력하죠.
왜 JavaScript/Node.js일까요?
- 동적 콘텐츠에 네이티브: 브라우저에서 돌아가니까, 페이지가 React, Angular, Vue로 만들어져도 사용자가 보는 그대로 확인할 수 있어요.
- 기본이 비동기: Node.js는 수백 개 요청을 동시에 처리해요.
- 웹 개발자에게 익숙함: 웹사이트를 만들어 본 적 있다면 이미 JavaScript를 어느 정도 알고 있는 셈이에요.
주요 라이브러리
- Playwright: 다중 브라우저(Chromium, Firefox, WebKit) 지원, 자동 대기, 컨텍스트별 프록시. 2026년에 새 Node 스크래퍼를 만든다면 기본 선택이에요.
- Puppeteer: Chrome DevTools Protocol로 헤드리스 Chrome을 제어해요. Chrome 전용 작업이나 더 가벼운 의존성이 필요할 때 여전히 훌륭하고요.
- Cheerio: 실제 브라우저가 필요 없을 때 Node에서 쓰는 jQuery 스타일 HTML 파서.
Node.js 샘플 코드: Puppeteer로 페이지 제목 가져오기
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
const title = await page.title();
console.log(`페이지 제목: ${title}`);
await browser.close();
})();
장점
- 자바스크립트로 렌더링된 콘텐츠를 네이티브로 처리.
- 무한 스크롤, 팝업, 인터랙티브 사이트 스크래핑에 적합.
- 대규모 동시 스크래핑에 효율적.
한계
- 비동기 프로그래밍은 초보자에게 까다로울 수 있어요.
- 헤드리스 브라우저는 많이 띄우면 메모리를 많이 먹어요.
- Python에 비해 데이터 분석 도구는 적은 편이고요.
언제 JavaScript/Node.js가 가장 좋은 언어일까요?
대상 사이트가 동적이거나, 브라우저 동작 자체를 자동화하고 싶을 때예요. 동적 콘텐츠 스크래핑을 위한 Node.js 더 알아보기.
Ruby: 빠른 웹 스크래핑 스크립트를 위한 깔끔한 문법
Ruby는 Rails 앱과 우아한 코드만을 위한 언어가 아니에요. 웹 스크래핑에도 꽤 좋은 선택이에요. 특히 코드가 시처럼 읽히길 좋아한다면 더 그렇고요.
왜 Ruby일까요?
- 읽기 쉽고 표현력 좋은 문법: Ruby로 만든 스크래퍼는 장보기 목록만큼 쉽게 읽혀요.
- 프로토타이핑에 강함: 빠르게 쓰고 고치기 쉬워요.
- 주요 라이브러리: 파싱용 Nokogiri, 탐색 자동화용 Mechanize.
Ruby 샘플 코드: 페이지 제목 가져오기
require 'open-uri'
require 'nokogiri'
html = URI.open("<https://example.com>")
doc = Nokogiri::HTML(html)
title = doc.at('title').text
puts "페이지 제목: #{title}"
장점
- 아주 읽기 쉽고 간결함.
- 작은 프로젝트, 일회성 스크립트, 또는 이미 Ruby를 쓰는 경우에 적합.
한계
- 큰 작업에서는 Python이나 Node.js보다 느려요.
- 스크래핑용 라이브러리와 커뮤니티 지원이 상대적으로 적고요.
- 자바스크립트가 많은 사이트엔 최적이 아니에요(물론 Watir나 Selenium을 쓸 수는 있어요).
가장 잘 맞는 경우
Ruby를 이미 쓰고 있거나, 빠른 스크립트를 툭 만들어야 할 때예요. 대규모 동적 스크래핑이라면 다른 선택지를 보세요.
PHP: 웹 데이터 추출을 위한 서버 측의 단순함
PHP는 초창기 웹의 유물처럼 보일 수 있지만 여전히 현역이에요. 특히 서버에서 직접 데이터를 스크래핑하고 싶다면 더 그렇고요.
왜 PHP일까요?
- 어디서나 실행됨: 대부분의 웹 서버엔 이미 PHP가 깔려 있어요.
- 웹 앱과 쉽게 통합: 한 번에 스크래핑하고 사이트에 바로 띄울 수 있어요.
- 주요 라이브러리: HTTP용 cURL, 요청용 Guzzle, 헤드리스 브라우저 자동화용 Symfony Panther.
PHP 샘플 코드: 페이지 제목 가져오기
<?php
$ch = curl_init("<https://example.com>");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$html = curl_exec($ch);
curl_close($ch);
$dom = new DOMDocument();
@$dom->loadHTML($html);
$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
echo "페이지 제목: $title\n";
?>
장점
- 웹 서버에 쉽게 배포 가능.
- 웹 워크플로의 일부로 스크래핑하기 좋음.
- 단순한 서버 측 스크래핑 작업에서는 빠름.
한계
- 고급 스크래핑용 라이브러리 지원이 제한적이에요.
- 높은 동시성이나 대규모 스크래핑에 맞춰 설계되진 않았고요.
- 자바스크립트가 많은 사이트를 다루기 까다로워요(물론 Panther가 어느 정도 도와줘요).
가장 잘 맞는 경우
이미 PHP 스택을 쓰고 있거나, 사이트에 데이터를 스크래핑해 띄우고 싶을 때 실용적인 선택이에요. 스크래핑에서 PHP와 Python 비교 더 보기.
C++: 대규모 프로젝트를 위한 고성능 웹 스크래핑
C++는 프로그래밍 언어의 머슬카예요. 순수한 속도와 제어가 필요하고 약간의 수작업도 괜찮다면 C++이 큰 힘을 발휘해요.
왜 C++일까요?
- 압도적으로 빠름: CPU 중심 작업에서 대부분의 언어보다 뛰어나요.
- 세밀한 제어: 메모리, 스레드, 성능 튜닝을 직접 관리해요.
- 주요 라이브러리: HTTP용 libcurl, 파싱용 htmlcxx.
C++ 샘플 코드: 페이지 제목 가져오기
#include <curl/curl.h>
#include <iostream>
#include <string>
size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
std::string* html = static_cast<std::string*>(userp);
size_t totalSize = size * nmemb;
html->append(static_cast<char*>(contents), totalSize);
return totalSize;
}
int main() {
CURL* curl = curl_easy_init();
std::string html;
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
std::size_t startPos = html.find("<title>");
std::size_t endPos = html.find("</title>");
if(startPos != std::string::npos && endPos != std::string::npos) {
startPos += 7;
std::string title = html.substr(startPos, endPos - startPos);
std::cout << "페이지 제목: " << title << std::endl;
} else {
std::cout << "제목 태그를 찾지 못했습니다" << std::endl;
}
return 0;
}
장점
- 대규모 스크래핑 작업에서 비교 불가한 속도.
- 고성능 시스템에 스크래핑을 통합하기 좋음.
한계
- 학습 곡선이 가팔라요(커피를 챙기세요).
- 수동 메모리 관리가 필요해요.
- 고수준 라이브러리가 제한적이라 동적 콘텐츠엔 최적이 아니에요.
가장 잘 맞는 경우
수백만 페이지를 스크래핑해야 하거나, 성능이 절대적으로 중요할 때예요. 안 그러면 스크래핑보다 디버깅에 시간을 더 쓰게 될 수도 있어요.
Java: 엔터프라이즈급 웹 스크래핑 솔루션
Java는 엔터프라이즈 세계의 주력이에요. 오래 돌아가야 하고, 방대한 데이터를 다뤄야 하고, 심지어 좀비 아포칼립스도 버텨야 하는 무언가를 만든다면 Java가 든든한 친구예요.
왜 Java일까요?
- 견고하고 확장성 좋음: 크고 오래 도는 스크래핑 프로젝트에 적합.
- 강한 타입과 에러 처리: 운영 환경에서 예측 못 한 일이 적어요.
- 주요 라이브러리: 파싱용 Jsoup, 브라우저 자동화용 Selenium WebDriver, HTTP용 Apache HttpClient.
Java 샘플 코드: 페이지 제목 가져오기
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ScrapeTitle {
public static void main(String[] args) throws Exception {
Document doc = Jsoup.connect("<https://example.com>").get();
String title = doc.title();
System.out.println("페이지 제목: " + title);
}
}
장점
- 높은 성능과 동시성.
- 크고 유지보수하기 좋은 코드베이스에 탁월.
- 동적 콘텐츠 지원도 좋음(Selenium 또는 HtmlUnit 사용).
한계
- 문법이 장황하고, 스크립트 언어보다 준비 작업이 많아요.
- 작은 일회성 스크립트엔 과한 선택이고요.
가장 잘 맞는 경우
엔터프라이즈 규모 스크래핑이거나, 아주 안정적이고 확장 가능한 시스템이 필요할 때예요.
Go (Golang): 빠르고 동시에 여러 작업을 처리하는 웹 스크래핑
Go는 비교적 새내기지만, 특히 고속 동시 스크래핑 분야에서 이미 큰 주목을 받고 있어요.
왜 Go일까요?
- 컴파일 속도와 실행 속도: C++에 거의 맞먹을 만큼 빨라요.
- 내장 동시성: 고루틴 덕분에 병렬 스크래핑이 아주 쉬워요.
- 주요 라이브러리: 스크래핑용 Colly, 파싱용 Goquery.
Go 샘플 코드: 페이지 제목 가져오기
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("페이지 제목:", e.Text)
})
err := c.Visit("<https://example.com>")
if err != nil {
fmt.Println("오류:", err)
}
}
장점
- 대규모 스크래핑에서 아주 빠르고 효율적.
- 배포가 쉬움(단일 바이너리).
- 동시 크롤링에 탁월.
한계
- Python이나 Node.js보다 커뮤니티가 작아요.
- 고수준 스크래핑 라이브러리가 상대적으로 적고요.
- 자바스크립트가 많은 사이트를 처리하려면 추가 설정이 필요해요(Chromedp 또는 Selenium).
가장 잘 맞는 경우
대규모로 스크래핑해야 하거나, Python이 충분히 빠르지 않을 때예요. 스크래핑에서 Go와 Python 성능 비교.
웹 스크래핑에 가장 좋은 프로그래밍 언어 비교
이제 전체를 한 번에 정리해 볼게요. 2026년 웹 스크래핑에 가장 적합한 언어를 고르는 데 도움이 되는 비교표예요.
| 언어/도구 | 사용 편의성 | 성능 | 라이브러리 지원 | 동적 콘텐츠 처리 | 가장 적합한 용도 |
|---|---|---|---|---|---|
| Python | 매우 높음 | 보통 | 매우 뛰어남 | 좋음(Selenium/Playwright) | 범용, 초보자, 데이터 분석 |
| JavaScript/Node.js | 중간 | 높음 | 강함 | 매우 뛰어남(네이티브) | 동적 사이트, 비동기 스크래핑, 웹 개발자 |
| Ruby | 높음 | 보통 | 무난함 | 제한적(Watir) | 빠른 스크립트, 프로토타이핑 |
| PHP | 중간 | 보통 | 보통 | 제한적(Panther) | 서버 측, 웹 앱 통합 |
| C++ | 낮음 | 매우 높음 | 제한적 | 매우 제한적 | 성능이 중요한 대규모 작업 |
| Java | 중간 | 높음 | 좋음 | 좋음(Selenium/HtmlUnit) | 엔터프라이즈, 장기 실행 서비스 |
| Go (Golang) | 중간 | 매우 높음 | 성장 중 | 보통(Chromedp) | 고속, 동시성 스크래핑 |
코딩을 건너뛰고 싶다면: 노코드 웹 스크래핑 솔루션인 Thunderbit
Thunderbit AI 웹 스크래퍼 사용해 보기 비즈니스 사용자, 마케터, 영업팀을 위한 노코드 AI 웹 스크래핑. Get Started Free
솔직하게 말해 볼게요. 때로는 코딩, 디버깅, "왜 이 셀렉터는 안 먹히지?" 같은 골치 아픈 일 없이 그냥 데이터만 원할 때가 있어요. 그럴 때 필요한 게 Thunderbit이에요.
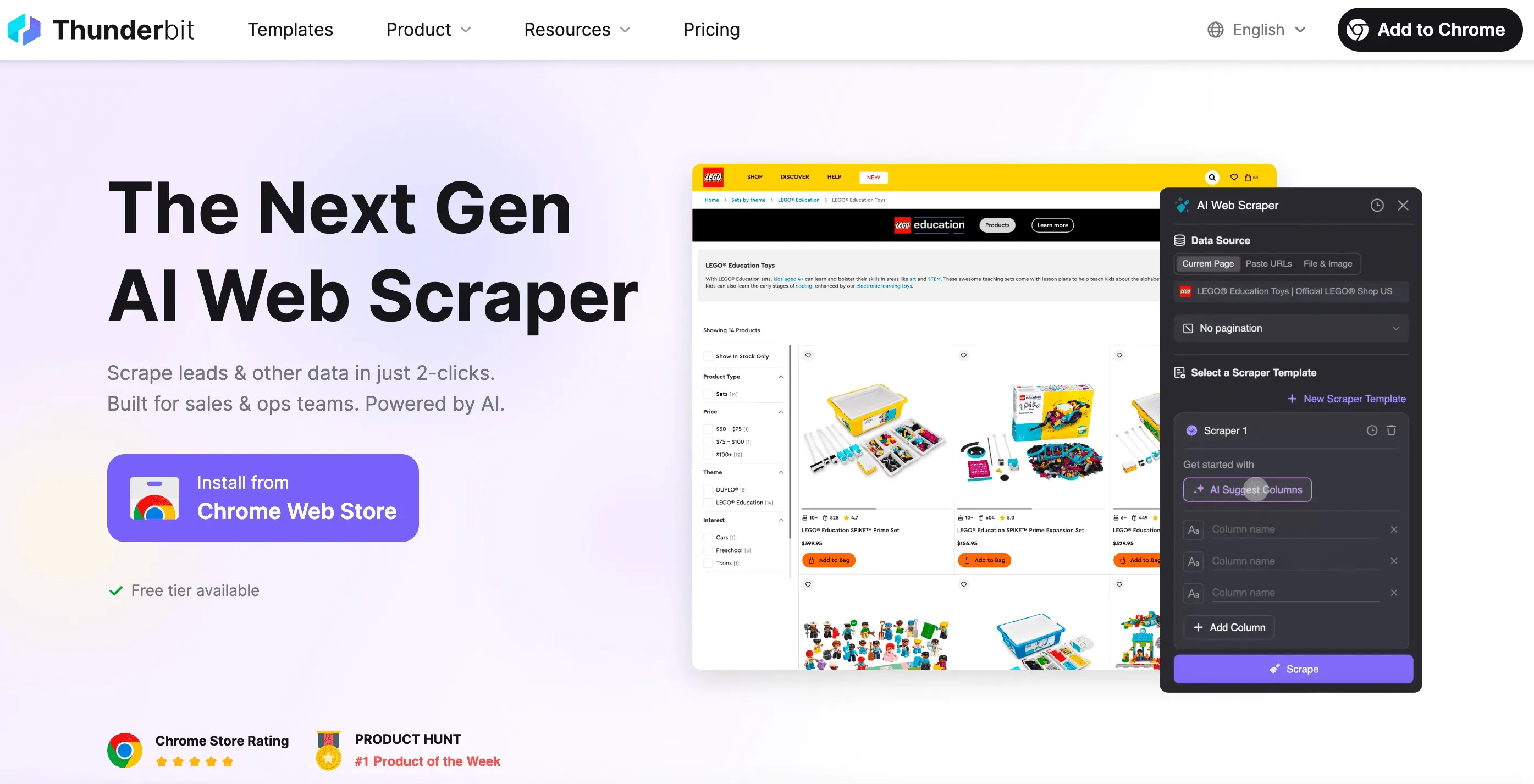
Thunderbit의 공동 창업자로서, 저는 웹 스크래핑을 배달 음식 주문만큼 쉽게 만들고 싶었어요. Thunderbit의 차별점은 이래요.
- 2번 클릭으로 설정: "AI 필드 추천"과 "스크래핑"만 누르면 돼요. HTTP 요청, 프록시, 안티봇 기법을 만질 필요가 없어요.
- 스마트 템플릿: 스크래퍼 템플릿 하나가 여러 페이지 레이아웃에 맞게 적응해요. 사이트가 바뀔 때마다 스크래퍼를 다시 쓸 필요가 없고요.
- 브라우저·클라우드 스크래핑: 브라우저에서 스크래핑할지(로그인 필요한 사이트에 좋음), 클라우드에서 할지(공개 데이터에 매우 빠름) 고를 수 있어요.
- 동적 콘텐츠 처리: Thunderbit의 AI는 실제 브라우저를 조작하니까 무한 스크롤, 팝업, 로그인 등을 처리해요.
- 어디로든 내보내기: Excel, Google Sheets, Airtable, Notion으로 내려받거나 클립보드에 복사해요.
- 유지보수 불필요: 사이트가 바뀌어도 AI 추천을 다시 실행하면 돼요. 밤늦게 디버깅하는 일도 이제 끝이고요.
- 스케줄링과 자동화: 스크래퍼를 일정에 맞춰 돌게 설정할 수 있어요. cron 작업도, 서버 설정도 필요 없어요.
- 전문 추출기: 이메일, 전화번호, 이미지가 필요하면, 클릭 한 번으로 쓰는 추출기도 있어요.
가장 좋은 점은요? 코드 한 줄도 몰라도 된다는 거예요. Thunderbit은 비즈니스 사용자, 마케터, 영업팀, 부동산 전문가처럼 빠르게 데이터를 확보해야 하는 모든 분을 위해 만들었어요.
Thunderbit이 어떻게 도는지 보고 싶으세요? Chrome 확장을 다운로드하거나, 데모가 담긴 YouTube 채널을 확인해 보세요.
Thunderbit AI 웹 스크래퍼를 무료로 사용해 보기
결론: 2026년에 가장 좋은 웹 스크래핑 언어를 고르는 법
데이터 스크래핑이란 무엇이며 어떻게 하는가 Get Started Free
2026년의 웹 스크래핑은 그 어느 때보다 접근하기 쉽고 더 강력해졌어요. 자동화 현장에서 수년을 보내며 제가 배운 건 이래요.
- Python은 빠르게 시작하고 풍부한 자료를 활용하고 싶다면 여전히 가장 좋은 언어예요.
- JavaScript/Node.js는 동적인 자바스크립트 중심 사이트를 스크래핑할 때 따라올 언어가 없어요.
- Ruby와 PHP는 빠른 스크립트와 웹 통합에 좋아요. 특히 이미 쓰고 있다면 더 그렇고요.
- **C++**와 Go는 속도와 규모가 필요할 때 좋은 선택이에요.
- Java는 엔터프라이즈와 장기 프로젝트에 가장 잘 맞아요.
- 그리고 아예 코딩을 건너뛰고 싶다면? Thunderbit이 비밀 병기예요.
시작하기 전에 스스로 물어보세요.
- 내 프로젝트 규모는 어느 정도인가요?
- 동적 콘텐츠를 처리해야 하나요?
- 내 기술 수준은 어느 정도인가요?
- 도구를 만들고 싶은가요, 아니면 그냥 데이터를 얻고 싶은가요?
위의 코드 예시를 직접 돌려보거나, 다음 프로젝트에서는 Thunderbit을 써 보세요. 더 깊이 알아보고 싶다면, 가이드와 팁, 실전 스크래핑 사례가 가득한 Thunderbit 블로그를 확인해 보세요.
즐거운 스크래핑 되시길 바라요. 언제나 데이터가 깨끗하고 구조화돼 있고, 클릭 한 번으로 손에 들어오길 바라고요.
추신. 새벽 2시에 웹 스크래핑 미로에 빠져 있다면, 항상 Thunderbit이 있다는 걸 기억하세요. 아니면 커피를 마시거나요. 둘 다 해도 되고요.
지금 Thunderbit AI 웹 스크래퍼 사용해 보기 Get Started Free
자주 묻는 질문
1. 2026년에 웹 스크래핑에 가장 좋은 프로그래밍 언어는 무엇인가요?
Python은 읽기 쉬운 문법, 강력한 라이브러리(BeautifulSoup, Scrapy, Selenium 등), 큰 커뮤니티 덕분에 여전히 최고의 선택이에요. 특히 데이터 분석과 스크래핑을 같이 하려는 초보자와 전문가 모두에게 이상적이고요.
2. 자바스크립트가 많은 웹사이트를 스크래핑하기에 가장 좋은 언어는 무엇인가요?
동적 사이트엔 JavaScript(Node.js)가 가장 좋아요. Puppeteer와 Playwright 같은 도구를 쓰면 브라우저를 완전히 제어해서 React, Vue, Angular로 로드된 콘텐츠와 상호작용할 수 있어요.
3. 웹 스크래핑에 노코드 옵션도 있나요?
네. Thunderbit은 동적 콘텐츠부터 스케줄링까지 다 처리하는 노코드 AI 웹 스크래퍼예요. "AI 필드 추천"만 누르고 스크래핑을 시작하면 돼요. 빠르게 구조화된 데이터가 필요한 영업, 마케팅, 운영팀에 딱이고요.
4. AI 코딩 에이전트가 대신 스크래퍼를 짜 준다면, 여전히 언어를 골라야 하나요?
2026년엔 충분히 나올 만한 질문이에요. Claude Code, Cursor, OpenAI Codex 같은 도구는 한 단락짜리 프롬프트만으로도 Scrapy 스파이더, Playwright 스크립트, Go + Colly 크롤러를 바로 만들어 줘요. 그래서 "처음 어떤 언어를 배워야 하나"의 부담은 2년 전보다 정말 줄었어요. 그래도 에이전트는 여전히 어떤 언어로든 코드를 뱉어내고, 결국 당신(또는 프로젝트를 넘겨받는 사람)이 그 코드를 읽고, 디버깅하고, 배포해야 해요. 그래서 언어 선택은 여전히 중요한데, 이제는 처음 30줄보다 유지보수에서 더 중요해졌어요. 아예 코드를 건드리고 싶지 않다면 Thunderbit이 바로 그 답이에요. 언어 문제를 통째로 건너뛰게 해주니까요.
더 알아보기




