

끊어진 링크. 고아 페이지. 2019년에 만들어 둔 「test」 페이지가 어느새 Google에 색인돼 있는 상황. 웹사이트를 직접 운영해 본 사람이라면 이 답답한 기분을 아주 잘 알 거예요.
좋은 크롤러는 이런 문제를 하나하나 찾아내고, 사이트 전체 구조를 한눈에 보여줘서 바로 손볼 수 있게 해줘요. 그런데 많은 분들이 「웹 크롤러」와 「웹 스크래퍼」를 같은 뜻으로 헷갈리곤 해요. 사실 이 둘은 완전히 달라요.
저는 실제 사이트를 대상으로 10개의 무료 크롤러를 직접 돌려 봤어요. 어떤 도구는 SEO 점검에 특히 강했고, 어떤 도구는 데이터 추출에 더 잘 맞았어요. 아래에서 무엇이 잘 됐고, 무엇이 아쉬웠는지 깔끔하게 정리해 드릴게요.
웹사이트 크롤러란? 기본 개념부터 이해하기
먼저 분명히 해둘게요. 웹사이트 크롤러는 웹 스크래퍼와 같은 게 아니에요. 둘 다 자주 섞어서 말하지만, 역할은 완전히 달라요. 크롤러는 사이트의 지도 제작자라고 생각하면 돼요. 사이트 구석구석을 훑고, 모든 링크를 따라가며, 전체 페이지 구조를 그려내요. 즉, 핵심은 발견이에요. URL을 찾고, 사이트 구조를 파악하고, 콘텐츠를 색인화하죠. Google 같은 검색엔진의 봇이 하는 일이 바로 이거고, SEO 도구들도 이 방식을 활용해 사이트 상태를 점검해요(Thunderbit Blog: What Is a Web Crawler?).
반대로 웹 스크래퍼는 데이터 채굴자에 가까워요. 사이트 전체 지도를 만들고 싶은 게 아니라, 제품 가격, 회사명, 리뷰, 이메일처럼 필요한 정보만 정확하게 뽑아내고 싶어 하죠. 스크래퍼는 크롤러가 찾아낸 페이지에서 원하는 특정 필드를 추출해요(Thunderbit Blog: How to Web Crawl a Site?).
둘을 나란히 놓고 보면 더 쉽게 와닿아요:
- 크롤러: 마트 안 진열대를 전부 돌면서 상품 목록을 작성하는 사람
- 스크래퍼: 커피 코너로 바로 가서 유기농 블렌드 가격만 적어 오는 사람
이 차이를 알아두면 도구를 고를 때 헤매지 않아요. 사이트의 모든 페이지를 찾고 싶다면(예: SEO 점검) 크롤러가 필요해요. 경쟁사 사이트에서 제품 가격만 쏙쏙 뽑고 싶다면 스크래퍼가 필요하죠. 가능하다면 둘 다 되는 도구가 가장 좋아요.
온라인 웹 크롤러를 써야 하는 이유: 비즈니스 관점의 핵심 이점
웹 크롤러가 필요해지는 건 웹이 갈수록 더 복잡해지고 있기 때문이에요. 실제로 기업 브랜드의 54% 이상이 전용 크롤링 플랫폼을 사용해 사이트를 최적화하고 있고, 일부 SEO 도구는 하루에 70억 페이지까지 크롤링해요.
크롤러가 도와줄 수 있는 일은 아래와 같아요.
- SEO 감사: 끊어진 링크, 빠진 제목, 중복 콘텐츠, 고아 페이지 등을 찾아내요(SEO.ai).
- 링크 점검 및 QA: 사용자가 먼저 발견하기 전에 404 오류와 리다이렉트 루프를 잡아내요(Screaming Frog).
- 사이트맵 생성: 검색엔진과 내부 기획용 XML 사이트맵을 자동으로 만들어요(PowerMapper).
- 콘텐츠 인벤토리: 사이트의 모든 페이지, 계층 구조, 메타데이터를 목록으로 정리해요.
- 규정 준수 및 접근성 점검: 각 페이지가 WCAG, SEO, 법적 기준을 충족하는지 확인해요(SiteOne Crawler).
- 성능 및 보안 점검: 느린 페이지, 용량이 큰 이미지, 보안 이슈를 찾아 표시해요(SiteOne Crawler).
- AI 및 분석용 데이터: 크롤링한 데이터를 분석 도구나 AI 도구에 연결할 수 있어요(Thunderbit Blog: Crawl4AI Review).
아래는 대표적인 활용 사례와 적합한 직무를 정리한 표예요.
| 활용 사례 | 추천 대상 | 효과 / 결과 |
|---|---|---|
| SEO 및 사이트 감사 | 마케팅, SEO, 소규모 사업자 | 기술 문제 발견, 구조 최적화, 순위 향상 |
| 콘텐츠 인벤토리 및 QA | 콘텐츠 매니저, 웹마스터 | 콘텐츠 점검·이관, 끊어진 링크/이미지 탐지 |
| 리드 생성(스크래핑) | 영업, 사업개발 | 잠재고객 발굴 자동화, CRM에 신선한 리드 입력 |
| 경쟁사 분석 | 이커머스, 제품 매니저 | 경쟁사 가격, 신제품, 재고 변동 모니터링 |
| 사이트맵 및 구조 복제 | 개발자, DevOps, 컨설턴트 | 리디자인이나 백업을 위한 사이트 구조 복제 |
| 콘텐츠 집계 | 연구자, 미디어, 분석가 | 여러 사이트의 데이터를 모아 분석·트렌드 모니터링 |
| 시장 조사 | 분석가, AI 학습 팀 | 분석용 대규모 데이터셋 수집 및 AI 모델 학습 |
(Thunderbit Blog: How to Web Crawl a Site?)
최고의 무료 웹사이트 크롤러를 고른 기준
문서를 읽고, 테스트 크롤을 돌리고, 꽤 많은 시간을 들여 크롤러 도구들을 샅샅이 살펴봤어요. 비교 기준은 다음과 같아요.
- 기술 역량: JavaScript, 로그인, 동적 콘텐츠가 있는 최신 사이트도 처리할 수 있는가?
- 사용 편의성: 비개발자도 쉽게 쓸 수 있는가, 아니면 명령줄 기술이 필요한가?
- 무료 플랜 제한: 정말 무료인가, 아니면 체험판 수준인가?
- 온라인 접근성: 클라우드 도구인가, 데스크톱 앱인가, 코드 라이브러리인가?
- 차별화 기능: AI 추출, 시각적 사이트맵, 이벤트 기반 크롤링 같은 특별한 기능이 있는가?
각 도구를 직접 테스트하고, 사용자 반응도 확인하고, 기능도 하나씩 비교했어요. 써 보니 답답함만 커지는 도구는 목록에서 과감히 제외했어요.
한눈에 보는 10가지 최고의 무료 웹사이트 크롤러 비교표
| 도구 & 유형 | 핵심 기능 | 가장 적합한 용도 | 기술 요구 수준 | 무료 플랜 상세 |
|---|---|---|---|---|
| BrightData (클라우드/API) | 엔터프라이즈 크롤링, 프록시, JS 렌더링, CAPTCHA 해결 | 대규모 데이터 수집 | 어느 정도 기술 지식 있으면 좋음 | 무료 체험: 스크래퍼 3개, 각 100개 레코드(총 약 300개) |
| Crawlbase (클라우드/API) | API 크롤링, 안티봇 대응, 프록시, JS 렌더링 | 백엔드 크롤 인프라가 필요한 개발자 | API 연동 | 무료: 7일간 약 5,000회 API 호출, 이후 월 1,000회 |
| ScraperAPI (클라우드/API) | 프록시 로테이션, JS 렌더링, 비동기 크롤링, 사전 제작 엔드포인트 | 개발자, 가격 모니터링, SEO 데이터 | 설정 간단 | 무료: 7일간 5,000회 API 호출, 이후 월 1,000회 |
| Diffbot Crawlbot (클라우드) | AI 크롤링 + 추출, 지식 그래프, JS 렌더링 | 대규모 구조화 데이터, AI/ML | API 연동 | 무료: 월 10,000 크레딧(약 1만 페이지) |
| Screaming Frog (데스크톱) | SEO 감사, 링크/메타 분석, 사이트맵, 맞춤 추출 | SEO 점검, 사이트 관리자 | 데스크톱 앱, GUI | 무료: 크롤당 500개 URL, 핵심 기능만 제공 |
| SiteOne Crawler (데스크톱) | SEO, 성능, 접근성, 보안, 오프라인 내보내기, Markdown | 개발자, QA, 이관, 문서화 | 데스크톱/CLI, GUI | 무료 및 오픈소스, GUI 보고서에서 1,000개 URL(설정 가능) |
| Crawljax (Java, 오픈소스) | JavaScript가 많은 사이트를 위한 이벤트 기반 크롤링, 정적 내보내기 | 개발자, 동적 웹앱 QA | Java, CLI/설정 | 무료 및 오픈소스, 제한 없음 |
| Apache Nutch (Java, 오픈소스) | 분산형, 플러그인 기반, Hadoop 연동, 맞춤 검색 | 자체 검색엔진, 대규모 크롤링 | Java, 명령줄 | 무료 및 오픈소스, 인프라 비용만 발생 |
| YaCy (Java, 오픈소스) | P2P 크롤링 및 검색, 프라이버시, 웹/인트라넷 색인 | 개인 검색, 탈중앙화 | Java, 브라우저 UI | 무료 및 오픈소스, 제한 없음 |
| PowerMapper (데스크톱/SaaS) | 시각적 사이트맵, 접근성, QA, 브라우저 호환성 | 에이전시, QA, 시각적 구조 파악 | GUI, 쉬움 | 무료 체험: 30일, 스캔당 100페이지(데스크톱) 또는 10페이지(온라인) |
BrightData: 엔터프라이즈급 클라우드 웹사이트 크롤러

BrightData는 웹 크롤링 쪽에서 규모로 밀어붙이는 대형 플랫폼이에요. 대규모 프록시 네트워크, JavaScript 렌더링, CAPTCHA 해결, 그리고 맞춤 크롤링용 IDE까지 갖춘 클라우드 플랫폼이죠. 수백 개의 이커머스 사이트를 대상으로 가격 변동을 모니터링하는 식의 대규모 수집이라면, BrightData의 인프라는 꽤 강력해요(aimultiple.com).
장점:
- 안티봇 장치가 강한 사이트도 잘 처리함
- 엔터프라이즈 규모에 맞게 확장 가능함
- 자주 쓰는 사이트용 사전 제작 템플릿 제공
단점:
- 영구 무료 플랜은 없음(3개 스크래퍼, 각 100개 레코드 체험판만 제공)
- 단순한 감사 작업에는 과할 수 있음
- 비기술 사용자는 익숙해지는 데 시간이 좀 걸림
대규모 웹 크롤링이 필요할 때 BrightData는 그만큼 무거운 장비예요. 다만 체험 기간이 끝난 뒤까지 무료라고 기대하면 안 돼요(BrightData Pricing).
Crawlbase: 개발자를 위한 API 중심 무료 웹 크롤러

Crawlbase(이전 이름: ProxyCrawl)는 프로그램 방식의 크롤링에 초점이 맞춰져 있어요. URL을 API에 넘기면 HTML을 돌려주고, 그 뒤에서는 프록시, 지역 타기팅, CAPTCHA 처리를 알아서 해줘요(Capterra).
장점:
- 높은 성공률(99% 이상)
- JavaScript가 많은 사이트도 처리 가능
- 자체 앱이나 업무 흐름에 붙이기 좋음
단점:
- API 또는 SDK 연동이 필요함
- 무료 플랜: 7일간 약 5,000회 API 호출, 이후 월 1,000회
프록시를 직접 관리하지 않으면서 대규모 웹 크롤링을 하고 싶은 개발자라면 Crawlbase는 꽤 괜찮은 선택이에요(Crawlbase Pricing).
ScraperAPI: 동적 웹 크롤링을 쉽게 만드는 도구

ScraperAPI는 말 그대로 「그냥 대신 가져와 줘」에 가까운 API예요. URL만 주면 프록시, 헤드리스 브라우저, 안티봇 대응을 처리한 뒤 HTML을 돌려줘요(일부 사이트는 구조화된 데이터도 제공해요). 특히 동적 페이지에 강하고, 무료 플랜도 꽤 넉넉해요(ScraperAPI Pricing).
장점:
- 개발자 입장에서 매우 간단함(API 호출 한 번이면 끝)
- CAPTCHA, IP 차단, JavaScript 처리 지원
- 무료: 7일간 5,000회 API 호출, 이후 월 1,000회
단점:
- 시각적 크롤링 보고서는 없음
- 링크를 따라가며 크롤링하려면 직접 로직을 작성해야 함
코드베이스에 웹 크롤링을 몇 분 안에 붙이고 싶다면, ScraperAPI는 거의 고민할 필요가 없어요.
Diffbot Crawlbot: 사이트 구조를 자동으로 파악하는 크롤러

Diffbot Crawlbot은 한 단계 더 똑똑해요. 단순히 크롤링만 하는 게 아니라, AI로 페이지를 분류하고 기사, 제품, 이벤트 같은 구조화 데이터를 JSON으로 추출해요. 읽은 내용을 실제로 이해하는 로봇 인턴을 두는 느낌이죠(Diffbot Free Plan).
장점:
- 단순 크롤링이 아니라 AI 기반 추출 제공
- JavaScript와 동적 콘텐츠 처리 가능
- 무료: 월 10,000 크레딧(약 1만 페이지)
단점:
- 개발자 중심(API 연동 필요)
- 시각적 SEO 도구는 아니고, 데이터 프로젝트에 더 적합
특히 AI나 분석용으로 대규모 구조화 데이터가 필요하다면, Diffbot은 상당히 강력한 선택지예요.
Screaming Frog: 무료 데스크톱 SEO 크롤러

Screaming Frog는 SEO 점검용 클래식 데스크톱 크롤러예요. 무료 버전은 한 번에 최대 500개 URL까지 크롤링할 수 있고, 끊어진 링크, 메타 태그, 중복 콘텐츠, 사이트맵 등 필요한 정보를 폭넓게 보여줘요(Screaming Frog User Guide).
장점:
- 빠르고 꼼꼼하며, SEO 업계에서 검증됨
- 코딩 없이 URL만 넣으면 바로 시작 가능
- 크롤당 500개 URL까지 무료
단점:
- 데스크톱 전용(클라우드 버전 없음)
- 고급 기능(JavaScript 렌더링, 예약 실행 등)은 유료 라이선스 필요
SEO를 진지하게 한다면 Screaming Frog는 거의 필수 도구예요. 다만 1만 페이지짜리 사이트를 무료로 전부 크롤링할 수 있을 거라고 기대하진 마세요.
SiteOne Crawler: 정적 사이트 내보내기와 문서화에 강한 도구

SiteOne Crawler는 기술 감사에 두루 쓰이는 만능 도구예요. 오픈소스이고, 여러 플랫폼에서 실행되며, 사이트를 크롤링하고 감사할 뿐 아니라 Markdown으로 내보내 문서화나 오프라인 활용도 가능해요(SiteOne Crawler).
장점:
- SEO, 성능, 접근성, 보안을 폭넓게 점검
- 보관이나 이관을 위해 사이트를 내보낼 수 있음
- 무료 및 오픈소스, 사용 제한 없음
단점:
- 일부 GUI 도구보다 기술적인 성격이 강함
- 기본 GUI 보고서는 1,000개 URL로 제한(설정으로 변경 가능)
개발자, QA 담당자, 컨설턴트처럼 깊이 있는 분석이 필요하고 오픈소스를 선호한다면, SiteOne은 눈여겨볼 만한 도구예요.
Crawljax: 동적 페이지용 오픈소스 Java 웹 크롤러
Crawljax는 꽤 전문적인 도구예요. 클릭, 폼 입력 같은 사용자 행동을 흉내 내면서 최신 JavaScript 기반 웹앱을 크롤링하도록 설계됐어요. 이벤트 기반으로 동작하고, 동적 사이트를 정적 버전으로 뽑아낼 수도 있어요(Wikipedia: Crawljax).
장점:
- SPA와 AJAX가 많은 사이트 크롤링에 탁월
- 오픈소스이며 확장 가능
- 사용 제한 없음
단점:
- Java와 어느 정도의 프로그래밍/설정이 필요함
- 비기술 사용자에게는 맞지 않음
React나 Angular 앱을 실제 사용자처럼 크롤링해야 한다면, Crawljax가 좋은 선택이 될 수 있어요.
Apache Nutch: 대규모 분산형 웹 크롤러

Apache Nutch는 오픈소스 크롤러의 원조 격이에요. 수백만, 수억 페이지를 색인하는 대규모 분산 크롤링을 염두에 두고 만들어졌어요. 자체 검색엔진을 만들거나 방대한 웹을 색인하려는 경우에 잘 맞아요(Martechvibe).
장점:
- Hadoop과 함께 수십억 페이지까지 확장 가능
- 높은 수준의 설정 및 확장성
- 무료 및 오픈소스
단점:
- 익히는 데 시간이 많이 듦(Java, 명령줄, 설정 파일 필요)
- 소규모 사이트나 가벼운 사용에는 부적합
대규모 크롤링을 하고 싶고, 명령줄 작업이 크게 부담스럽지 않다면 Nutch가 잘 맞아요.
YaCy: P2P 웹 크롤러이자 검색엔진
YaCy는 독특한 탈중앙화 크롤러이자 검색엔진이에요. 각 인스턴스가 사이트를 크롤링하고 색인하며, P2P 네트워크에 참여해 다른 사용자와 색인을 공유할 수 있어요(TechRadar: YaCy).
장점:
- 중앙 서버가 없는 프라이버시 중심 구조
- 사설 검색이나 인트라넷 검색 구축에 적합
- 무료 및 오픈소스
단점:
- 결과 품질이 네트워크 커버리지에 좌우됨
- Java와 브라우저 UI 등 약간의 설정 필요
탈중앙화에 관심이 있거나 직접 검색엔진을 만들어 보고 싶다면, YaCy는 꽤 흥미로운 선택이에요.
PowerMapper: UX와 QA를 위한 시각적 사이트맵 생성기

PowerMapper는 사이트 구조를 시각적으로 보여주는 데 초점을 둔 도구예요. 사이트를 크롤링해 인터랙티브 사이트맵을 생성하고, 접근성, 브라우저 호환성, 기본 SEO 항목도 점검해요(Slickplan Review).
장점:
- 시각적 사이트맵은 에이전시와 디자이너에게 특히 유용
- 접근성과 규정 준수 점검 가능
- 쉬운 GUI, 기술 지식이 거의 없어도 사용 가능
단점:
- 무료 체험만 제공(30일, 스캔당 데스크톱 100페이지/온라인 10페이지)
- 정식 버전은 유료
클라이언트에게 사이트맵을 보여주거나 규정 준수를 점검해야 한다면 PowerMapper가 꽤 유용해요.
내게 맞는 무료 웹 크롤러 고르는 법
선택지가 이렇게 많으니, 간단한 기준으로 좁혀볼게요.
- SEO 점검용: Screaming Frog(소규모 사이트), PowerMapper(시각화), SiteOne(심층 감사)
- 동적 웹앱용: Crawljax
- 대규모 또는 맞춤 검색용: Apache Nutch, YaCy
- API 접근이 필요한 개발자용: Crawlbase, ScraperAPI, Diffbot
- 문서화나 보관용: SiteOne Crawler
- 기업 규모의 체험판이 필요하다면: BrightData, Diffbot
고려할 핵심 요소:
- 확장성: 사이트나 크롤 작업의 규모가 어느 정도인가?
- 사용 편의성: 코드를 다룰 수 있는가, 아니면 클릭 몇 번으로 끝나는 도구가 필요한가?
- 데이터 내보내기: CSV, JSON, 또는 다른 도구와의 연동이 필요한가?
- 지원: 막혔을 때 도움말 문서나 커뮤니티가 있는가?
웹 크롤링과 웹 스크래핑이 만나는 지점: Thunderbit가 더 스마트한 선택인 이유
AI로 어떤 웹사이트든 데이터 추출 Get Started Free
현실적으로 대부분의 사람들은 보기 좋은 구조도를 만들려고 웹사이트를 크롤링하는 게 아니에요. 진짜 목적은 보통 구조화된 데이터를 얻는 거죠. 제품 목록, 연락처 정보, 콘텐츠 인벤토리 같은 데이터 말이에요. 이럴 때 Thunderbit가 나와요.
Thunderbit는 단순한 크롤러나 스크래퍼가 아니에요. 두 기능을 합쳐 놓은 AI 기반 Chrome 확장 프로그램이에요. 작동 방식은 아래와 같아요.
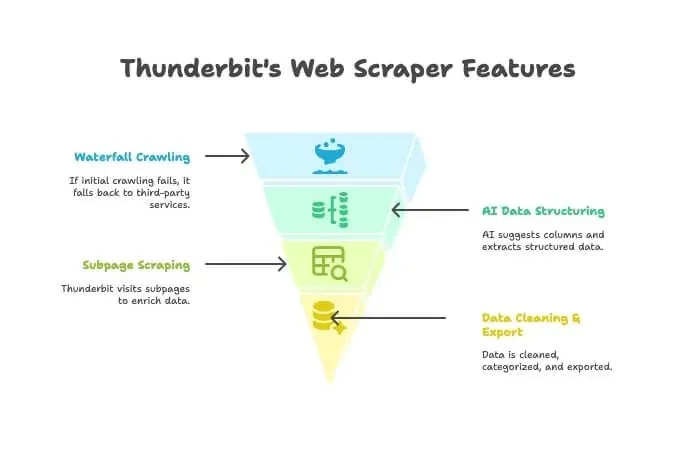
- AI 크롤러: Thunderbit가 사이트를 크롤러처럼 탐색해요.
- 워터폴 크롤링: Thunderbit 자체 엔진이 페이지를 가져오지 못할 때(예: 강한 안티봇 차단이 있을 때) 자동으로 외부 크롤링 서비스로 전환해요. 별도 설정은 필요 없어요.
- AI 데이터 구조화: HTML을 확보하면 Thunderbit의 AI가 적절한 열을 제안하고, 이름, 가격, 이메일 같은 데이터를 셀렉터 작성 없이 구조화해서 추출해요.
- 하위 페이지 스크래핑: 각 제품 페이지의 상세 정보도 자동으로 방문해 표를 더 풍성하게 만들 수 있어요.
- 데이터 정리 및 내보내기: 데이터를 요약, 분류, 번역하고 Excel, Google Sheets, Airtable, Notion으로 한 번에 내보낼 수 있어요.
- 노코드의 편리함: 브라우저를 쓸 줄 안다면 Thunderbit도 바로 쓸 수 있어요. 코딩도, 프록시도, 복잡한 설정도 필요 없어요.
전통적인 크롤러보다 Thunderbit가 더 나은 경우는 언제일까요?
- 목적이 URL 목록이 아니라, 깔끔하게 정리된 스프레드시트일 때
- 크롤링, 추출, 정리, 내보내기를 한곳에서 자동화하고 싶을 때
- 시간과 정신 건강을 아끼고 싶을 때
Thunderbit의 Chrome 확장 프로그램은 여기에서 다운로드할 수 있어요. 왜 많은 비즈니스 사용자들이 이 도구로 갈아타는지 직접 확인해 보세요.
결론: 무료 웹사이트 크롤러를 최대한 활용하는 방법
데이터 스크래핑이란 무엇이며, 어떻게 하는가 Get Started Free
웹사이트 크롤러는 정말 많이 발전했어요. 마케터, 개발자, 아니면 그냥 사이트 상태를 건강하게 유지하고 싶은 사람까지, 누구에게나 무료이거나 최소한 무료 체험이 가능한 도구가 있어요. BrightData와 Diffbot 같은 엔터프라이즈급 플랫폼부터 SiteOne과 Crawljax 같은 탄탄한 오픈소스 도구, PowerMapper 같은 시각화 도구까지 선택지는 그 어느 때보다 다양해요.
하지만 「이 데이터가 필요하다」에서 「여기 제 스프레드시트입니다」까지 더 똑똑하고 통합된 방식으로 가고 싶다면 Thunderbit를 써 보세요. 결과가 필요한 비즈니스 사용자를 위해 만들어졌지, 단순한 보고서만을 위한 도구가 아니에요.
크롤링을 시작할 준비가 됐다면, 도구를 하나 내려받아 스캔을 돌려보고, 놓치고 있던 걸 확인해 보세요. 그리고 크롤링에서 실행 가능한 데이터로 두 번 클릭 만에 넘어가고 싶다면, Thunderbit를 확인해 보세요.
더 깊이 있는 분석과 실전 가이드는 Thunderbit Blog에서 확인할 수 있어요.
AI 웹 스크래퍼 사용해 보기 Get Started Free
FAQ
웹사이트 크롤러와 웹 스크래퍼의 차이는 무엇인가요?
크롤러는 사이트의 모든 페이지를 찾아내고 구조를 정리합니다(목차를 만드는 것과 비슷합니다). 스크래퍼는 그 페이지들에서 가격, 이메일, 리뷰 같은 특정 데이터를 추출합니다. 크롤러는 찾고, 스크래퍼는 파고듭니다(Thunderbit Blog: What Is a Web Crawler?).
비기술 사용자에게 가장 좋은 무료 웹 크롤러는 무엇인가요?
소규모 사이트와 SEO 점검에는 Screaming Frog가 사용하기 쉽습니다. 시각적 구조 파악이 목적이라면 체험판 기준으로 PowerMapper가 좋습니다. 구조화된 데이터를 얻고 코드 없이 브라우저 기반으로 쓰고 싶다면 Thunderbit가 가장 쉽습니다.
웹 크롤러를 차단하는 사이트도 있나요?
네. 일부 사이트는 robots.txt 파일이나 CAPTCHA, IP 차단 같은 안티봇 장치로 크롤러를 막습니다. ScraperAPI, Crawlbase, 그리고 워터폴 크롤링을 제공하는 Thunderbit 같은 도구는 이런 장벽을 우회하는 데 도움이 되는 경우가 많지만, 항상 사이트 규칙을 존중하면서 책임감 있게 크롤링해야 합니다(BrightData Pricing).
무료 웹사이트 크롤러에도 페이지 수나 기능 제한이 있나요?
대부분 있습니다. 예를 들어 Screaming Frog의 무료 버전은 크롤당 500개 URL로 제한되고, PowerMapper 체험판은 100페이지입니다. API 기반 도구는 보통 월간 크레딧 제한이 있습니다. SiteOne이나 Crawljax 같은 오픈소스 도구는 일반적으로 하드 제한이 없지만, 하드웨어 성능에 따라 달라집니다.
웹 크롤러 사용은 합법적이고 개인정보 규정에 맞나요?
일반적으로 공개 웹페이지를 크롤링하는 것은 합법적이지만, 반드시 사이트 이용약관과 robots.txt를 확인해야 합니다. 허가 없이 비공개 데이터나 비밀번호 보호 페이지를 크롤링하면 안 되며, 개인정보를 추출할 때는 관련 개인정보 보호법도 고려해야 합니다(Crawlbase Guide).




