

Amazon은 사실상 인터넷 전체의 쇼핑몰이자 슈퍼마켓, 전자제품 매장이에요. 영업·이커머스·운영 업무를 한다면 Amazon에서 벌어지는 일이 그 안에서만 끝나지 않는다는 걸 이미 알 거예요. 가격 전략, 재고, 다음 히트 상품 출시까지 영향을 주니까요. 문제는 그 알찬 제품 정보, 가격, 평점, 리뷰가 전부 쇼핑객용 웹 인터페이스 뒤에 갇혀 있다는 점이에요. 데이터가 목마른 팀엔 답답한 노릇이죠. 그럼 주말마다 1999년처럼 복붙으로 시간을 태우지 않고, 이 데이터를 어떻게 손에 넣을까요?
바로 웹 스크래핑이 필요한 순간이에요. 이 가이드에선 Amazon 제품 데이터를 뽑는 두 길을 소개할게요. 하나는 "소매 걷어붙이고 Python으로 직접 코딩하기"라는 전통 방식, 다른 하나는 Thunderbit 같은 노코드 웹 스크래퍼로 무거운 작업을 AI에 맡기는 현대 방식이에요. 실제 Python 코드와 주의점, 우회법까지 본 다음, Thunderbit로 같은 데이터를 클릭 몇 번에 얻는 법도 보여드릴게요. 개발자든, 비즈니스 분석가든, 수동 데이터 입력에 지친 분이든 다 도움이 될 거예요.
왜 Amazon 제품 데이터를 뽑아야 할까요? (amazon scraper python, web scraping with python)
Amazon은 세계 최대 온라인 리테일러일 뿐 아니라, 경쟁 정보 분석을 위한 세계 최대의 공개 시장이에요. 6억 개 넘는 상품이 등록돼 있고 활성 셀러도 거의 200만 명에 달하는 Amazon은 다음을 원하는 사람에겐 금광이에요.

- 가격 모니터링하기(그리고 실시간으로 가격 조정하기)
- 경쟁사 분석하기(신제품 출시, 평점, 리뷰 추적하기)
- 리드 생성하기(셀러, 공급업체, 잠재 파트너 찾기)
- 수요 예측하기(재고 수준과 판매 순위를 확인하면서)
- 시장 트렌드 파악하기(리뷰와 검색 결과를 분석해서)
이론에 그치는 얘기가 아니에요. 실제 비즈니스에서 확실한 ROI가 나와요. 한 전자제품 소매업체는 Amazon 가격 데이터를 스크래핑해 이익률을 15% 높였고, 또 다른 브랜드는 경쟁사 가격 추적을 자동화한 뒤 매출 4% 증가와 분석가 업무 시간 30% 절감을 달성했어요.
아래는 활용 사례와 기대할 수 있는 ROI를 간단히 정리한 표예요.
| 활용 사례 | 사용자 | 일반적인 ROI / 효과 |
|---|---|---|
| 가격 모니터링 | 이커머스, 운영 | 이익률 15%+ 개선, 매출 4% 상승, 분석가 시간 30% 절감 |
| 경쟁사 분석 | 영업, 제품, 운영 | 더 빠른 가격 조정, 경쟁력 향상 |
| 시장 조사(리뷰) | 제품, 마케팅 | 더 빠른 제품 개선, 더 나은 광고 문구, SEO 인사이트 |
| 리드 생성 | 영업 | 월 3,000개+ 리드, 영업 담당자당 주당 8시간+ 절감 |
| 재고 및 수요 예측 | 운영, 공급망 | 과잉 재고 20% 감소, 품절 감소 |
| 트렌드 포착 | 마케팅, 경영진 | 인기 상품 및 카테고리의 조기 감지 |
게다가 조직의 90% 이상이 이제 데이터 분석에서 측정 가능한 가치를 본다고 해요. Amazon을 스크래핑하지 않으면 인사이트도, 돈도 그냥 테이블에 두고 오는 셈이죠.
개요: Amazon Scraper Python vs. 노코드 웹 스크래퍼 도구
브라우저의 Amazon 데이터를 스프레드시트나 대시보드로 옮기는 길은 크게 둘이에요.
-
Amazon Scraper Python(web scraping with python):
Requests와 BeautifulSoup 같은 Python 라이브러리로 직접 스크립트를 짜는 방식이에요. 완전한 제어가 되지만, 코딩을 할 줄 알아야 하고, 안티봇 대응도 직접 하며, Amazon이 사이트를 바꿀 때마다 스크립트를 손봐야 해요.
-
노코드 웹 스크래퍼 도구(Thunderbit 같은):
가리키고, 클릭하고, 데이터를 뽑는 도구를 쓰는 방식이에요. 프로그래밍이 전혀 필요 없죠. Thunderbit 같은 최신 도구는 AI로 어떤 데이터를 가져올지 알아서 파악하고, 하위 페이지와 페이지네이션도 처리하며, Excel이나 Google Sheets로 바로 내보내기도 해요.
비교하면 이런 느낌이에요.
| 기준 | Python 스크래퍼 | 노코드(Thunderbit) |
|---|---|---|
| 설정 시간 | 높음(설치, 코딩, 디버깅) | 낮음(확장 프로그램 설치) |
| 필요한 기술 | 코딩 필요 | 없음(가리키고 클릭) |
| 유연성 | 무제한 | 일반적인 활용 사례에선 높음 |
| 유지보수 | 직접 코드 수정 | 도구가 자동 업데이트됨 |
| 안티봇 대응 | 프록시, 헤더 직접 처리 | 내장되어 있어 자동 처리 |
| 확장성 | 수동(스레드, 프록시) | 클라우드 스크래핑, 병렬 처리 |
| 데이터 내보내기 | 맞춤형(CSV, Excel, DB) | Excel, Sheets로 원클릭 내보내기 |
| 비용 | 무료(시간 + 프록시 비용) | 프리미엄, 대량 사용 시 유료 |
다음 섹션에서 두 방식을 다 봐요. 먼저 Python으로 Amazon 스크래퍼를 만드는 법을 실제 코드와 함께 보고, 그다음 Thunderbit의 AI 웹 스크래퍼로 같은 작업을 하는 법을 알려드릴게요.
Amazon Scraper Python 시작하기: 준비물과 설정
코드로 들어가기 전에 개발 환경부터 세팅할게요.
준비물:
- Python 3.x(python.org에서 다운로드 가능)
- 코드 편집기(저는 VS Code를 좋아하지만 아무거나 괜찮아요)
- 다음 라이브러리:
requests(HTTP 요청용)beautifulsoup4(HTML 파싱용)lxml(빠른 HTML 파서)pandas(데이터 테이블/내보내기용)re(정규표현식, 내장)
라이브러리 설치:
pip install requests beautifulsoup4 lxml pandas
프로젝트 설정:
- 프로젝트용 새 폴더를 만드세요.
- 편집기를 열고 새 Python 파일을 만드세요(예:
amazon_scraper.py). - 이제 시작할 준비가 끝났어요!
단계별: Python으로 Amazon 제품 데이터 웹 스크래핑하기
이제 Amazon 제품 페이지 하나를 스크래핑해 볼게요. (걱정 마세요. 조금 뒤엔 여러 제품과 여러 페이지를 스크래핑하는 법도 다뤄요.)
1. 요청 보내고 HTML 가져오기
먼저 제품 페이지의 HTML을 가져와 볼게요. (URL은 아무 Amazon 제품 페이지로 바꿔도 돼요.)
import requests
url = "<https://www.amazon.com/dp/B0ExampleASIN>"
response = requests.get(url)
html_content = response.text
print(response.status_code)
주의: 이 기본 요청은 Amazon에 막힐 가능성이 커요. 제품 페이지 대신 503 오류나 CAPTCHA가 보일 수도 있어요. Amazon이 이 요청을 진짜 브라우저로 안 보기 때문이죠.
Amazon의 안티봇 대응 처리하기
Amazon은 봇을 싫어해요. 차단을 피하려면 다음이 필요해요.
- User-Agent 헤더 설정하기(Chrome이나 Firefox처럼 보이게)
- User-Agent 회전하기(매번 같은 값을 쓰지 않기)
- 요청 속도 조절하기(랜덤 지연 추가)
- 프록시 사용하기(대규모 스크래핑용)
헤더를 설정하는 방법은 이래요.
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
response = requests.get(url, headers=headers)
더 정교하게 하려면 User-Agent 목록을 만들어 요청마다 바꿔 써요. 대규모 작업이라면 프록시 서비스가 좋지만, 소규모라면 헤더와 지연만으로 충분한 경우가 많아요.
주요 제품 필드 추출하기
HTML을 확보했다면 이제 BeautifulSoup으로 파싱할 차례예요.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, "lxml")
이제 핵심 정보를 뽑아볼게요.
제품 제목
title_elem = soup.find(id="productTitle")
product_title = title_elem.get_text(strip=True) if title_elem else None
가격
Amazon의 가격은 몇 군데에 흩어져 있어요. 아래 방법들을 시도해 보세요.
price = None
price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
if price_elem:
price = price_elem.get_text(strip=True)
else:
price_whole = soup.find("span", {"class": "a-price-whole"})
price_frac = soup.find("span", {"class": "a-price-fraction"})
if price_whole and price_frac:
price = price_whole.text + price_frac.text
평점과 리뷰 수
rating_elem = soup.find("span", {"class": "a-icon-alt"})
rating = rating_elem.get_text(strip=True) if rating_elem else None
review_count_elem = soup.find(id="acrCustomerReviewText")
reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
reviews_count = reviews_text.split()[0] # 예: "1,554개 평점"
메인 이미지 URL
Amazon은 HTML 속 JSON에 고해상도 이미지를 숨겨두기도 해요. 간단한 정규표현식으로 찾는 방법은 이래요.
import re
match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
main_image_url = match.group(1) if match else None
또는 메인 이미지 태그를 직접 가져올 수도 있어요.
img_tag = soup.find("img", {"id": "landingImage"})
img_url = img_tag['src'] if img_tag else None
제품 상세 정보
브랜드, 무게, 크기 같은 사양은 보통 표에 들어 있어요.
details = {}
rows = soup.select("#productDetails_techSpec_section_1 tr")
for row in rows:
header = row.find("th").get_text(strip=True)
value = row.find("td").get_text(strip=True)
details[header] = value
또는 Amazon이 "detailBullets" 형식을 쓰는 경우도 있어요.
bullets = soup.select("#detailBullets_feature_div li")
for li in bullets:
txt = li.get_text(" ", strip=True)
if ":" in txt:
key, val = txt.split(":", 1)
details[key.strip()] = val.strip()
결과를 출력해 보세요.
print("제목:", product_title)
print("가격:", price)
print("평점:", rating, "리뷰 수 기준", reviews_count)
print("메인 이미지 URL:", main_image_url)
print("상세 정보:", details)
여러 제품 스크래핑과 페이지네이션 처리하기
제품 하나도 좋지만, 보통은 전체 목록이 필요하죠. 검색 결과와 여러 페이지를 스크래핑하는 법을 볼게요.
검색 페이지에서 제품 링크 가져오기
search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
res = requests.get(search_url, headers=headers)
soup = BeautifulSoup(res.text, "lxml")
product_links = []
for a in soup.select("h2 a.a-link-normal"):
href = a['href']
full_url = "<https://www.amazon.com>" + href
product_links.append(full_url)
페이지네이션 처리하기
Amazon의 검색 URL은 &page=2, &page=3 같은 형식을 써요.
for page in range(1, 6): # 처음 5페이지 스크래핑
search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
res = requests.get(search_url, headers=headers)
if res.status_code != 200:
break
soup = BeautifulSoup(res.text, "lxml")
# ... 위와 같이 제품 링크 추출 ...
제품 페이지를 순회하고 CSV로 내보내기
제품 데이터를 딕셔너리 목록에 모은 다음 pandas를 쓰세요.
import pandas as pd
df = pd.DataFrame(product_data_list) # dict 목록
df.to_csv("amazon_products.csv", index=False)
Excel로 내보내려면 이렇게 하면 돼요.
df.to_excel("amazon_products.xlsx", index=False)
Amazon Scraper Python 프로젝트를 위한 모범 사례
현실을 말하면, Amazon은 사이트를 끊임없이 바꾸며 스크래퍼와 싸워요. 프로젝트를 안정적으로 굴리려면 이렇게 하세요.
- 헤더와 User-Agent를 회전하기(
fake-useragent같은 라이브러리 활용) - 대규모 스크래핑에는 프록시 사용하기
- 요청 속도 조절하기(요청 사이에 랜덤
time.sleep()넣기) - 에러를 우아하게 처리하기(503이면 재시도, 차단되면 백오프)
- 유연한 파싱 로직 작성하기(필드마다 여러 선택자를 시도)
- HTML 변경 사항 모니터링하기(스크립트가 갑자기 전부
None을 반환하면 페이지를 확인) - robots.txt를 존중하기(Amazon은 많은 섹션의 스크래핑을 허용하지 않아요—책임 있게 하세요)
- 데이터를 수집하면서 정리하기(통화 기호, 쉼표, 공백 제거)
- 커뮤니티와 연결 유지하기(포럼, Stack Overflow, Reddit의 r/webscraping)
스크래퍼 유지보수 체크리스트:
- User-Agent와 헤더 회전하기
- 대규모 스크래핑 시 프록시 사용하기
- 랜덤 지연 추가하기
- 쉽게 업데이트할 수 있도록 코드 모듈화하기
- 차단이나 CAPTCHA 발생 여부 모니터링하기
- 데이터를 정기적으로 내보내기
- 선택자와 로직 문서화하기
더 깊이 보고 싶다면 제 Python 웹 스크래핑 가이드를 확인해 보세요.
노코드 대안: Thunderbit AI 웹 스크래퍼로 Amazon 스크래핑하기
AI로 Amazon 제품 데이터 스크래핑하기 Get Started Free
좋아요, Python 방식은 봤죠. 그런데 코딩은 하기 싫거나, 그냥 클릭 두 번에 데이터를 받아 바로 다음 일로 넘어가고 싶다면요? 그럴 때 필요한 게 Thunderbit예요.
Thunderbit은 코딩 없이 Amazon 제품 데이터(그리고 거의 모든 웹사이트 데이터)를 뽑는 AI 웹 스크래퍼 Chrome 확장 프로그램이에요. 제가 좋아하는 이유는 이래요.
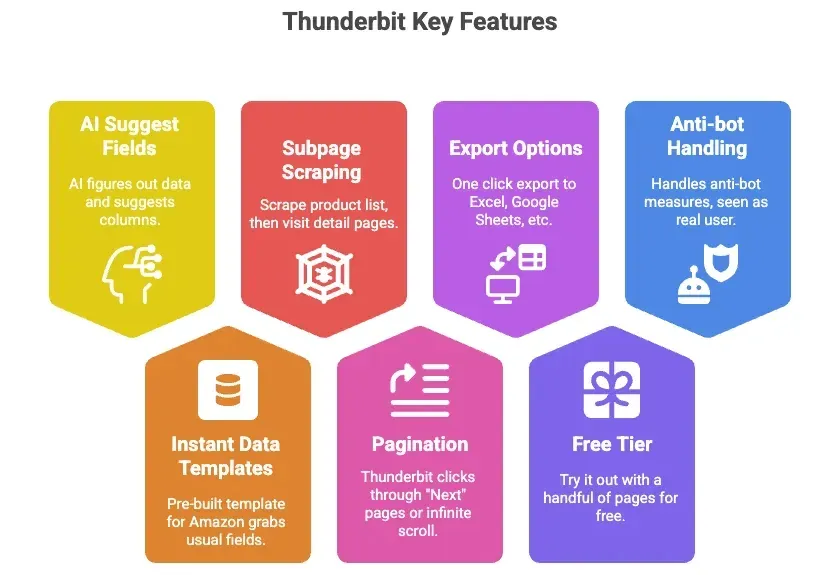
- AI 필드 추천: 버튼 하나만 누르면 Thunderbit의 AI가 페이지 데이터를 파악해 제목, 가격, 평점 같은 열을 추천해 줘요.
- 즉시 쓰는 데이터 템플릿: Amazon에는 자주 쓰는 필드를 한 번에 가져오는 템플릿이 있어 설정이 필요 없어요.
- 하위 페이지 스크래핑: 제품 목록을 스크래핑한 뒤, Thunderbit이 각 상세 페이지를 돌며 추가 정보를 자동으로 가져오게 할 수 있어요.
- 페이지네이션: Thunderbit이 "다음" 페이지를 눌러가며 이동하거나 무한 스크롤을 처리해요.
- Excel, Google Sheets, Airtable, Notion으로 내보내기: 한 번 클릭이면 바로 쓰는 데이터가 돼요.
- 무료 티어: 몇 페이지는 무료로 체험해 볼 수 있어요.
- 안티봇 요소도 자동 처리: 브라우저 안이나 클라우드에서 실행돼, Amazon은 이를 진짜 사용자로 인식해요.
단계별: Thunderbit로 Amazon 제품 데이터 스크래핑하기
정말 쉬워요.
-
Thunderbit 설치하기:
Thunderbit Chrome 확장 프로그램을 다운로드하고 로그인하세요.
-
Amazon 열기:
스크래핑할 Amazon 페이지로 이동하세요(검색 결과, 제품 상세 페이지 등 뭐든 괜찮아요).
-
"AI 필드 추천"을 누르거나 템플릿 쓰기:
Thunderbit이 추출할 열을 제안하거나, Amazon Product 템플릿을 고를 수 있어요.
-
열 검토하기:
원하면 열을 손보세요(필드 추가/삭제, 이름 변경 등).
-
"스크래핑" 클릭하기:
Thunderbit이 페이지 데이터를 가져와 표로 보여줘요.
-
하위 페이지 및 페이지네이션 처리하기:
목록을 스크래핑했다면 "하위 페이지 스크래핑"을 눌러 각 상세 페이지를 돌며 정보를 더 가져오세요. Thunderbit이 "다음" 페이지도 자동으로 눌러줘요.
-
데이터 내보내기:
"Excel로 내보내기" 또는 "Google Sheets로 내보내기"를 누르세요. 끝이에요.
-
(선택 사항) 스크래핑 예약하기:
이 데이터를 매일 받아야 하나요? Thunderbit의 스케줄러로 자동화하면 돼요.
이게 전부예요. 코드도, 디버깅도, 프록시도, 골치 아픈 일도 없어요. 시각적 안내가 필요하다면 Thunderbit YouTube 채널이나 Amazon Product Scraper 템플릿 페이지를 확인해 보세요.
Amazon Product Scraper 템플릿 사용해 보기
Amazon Scraper Python vs. 노코드 웹 스크래퍼: 한눈에 비교
전체를 다시 정리할게요.
| 기준 | Python 스크래퍼 | Thunderbit(노코드) |
|---|---|---|
| 설정 시간 | 높음(설치, 코딩, 디버깅) | 낮음(확장 프로그램 설치) |
| 필요한 기술 | 코딩 필요 | 없음(가리키고 클릭) |
| 유연성 | 무제한 | 일반적인 활용 사례에선 높음 |
| 유지보수 | 직접 코드 수정 | 도구가 자동 업데이트됨 |
| 안티봇 대응 | 프록시, 헤더 직접 처리 | 내장되어 있어 자동 처리 |
| 확장성 | 수동(스레드, 프록시) | 클라우드 스크래핑, 병렬 처리 |
| 데이터 내보내기 | 맞춤형(CSV, Excel, DB) | Excel, Sheets로 원클릭 내보내기 |
| 비용 | 무료(시간 + 프록시 비용) | 프리미엄, 대량 사용 시 유료 |
| 가장 적합한 대상 | 개발자, 맞춤 요구사항 | 비즈니스 사용자, 빠른 결과 |
직접 만지는 걸 좋아하고 아주 커스텀한 게 필요한 개발자라면 Python이 잘 맞아요. 속도, 단순함, 코딩 없는 접근을 원한다면 Thunderbit이 정답이에요.
Amazon 데이터에 Python, 노코드, AI 웹 스크래퍼 중 무엇을 고를까요?
다음과 같다면 Python을 고르세요:
- 맞춤 로직이 필요하거나 스크래핑을 백엔드 시스템에 통합하고 싶을 때
- 매우 대규모로 스크래핑할 때(수만 개의 제품)
- 스크래핑이 내부에서 어떻게 도는지 배우고 싶을 때
다음과 같다면 Thunderbit(노코드, AI 웹 스크래퍼)을 고르세요:
- 코딩 없이 빠르게 데이터를 얻고 싶을 때
- 비즈니스 사용자, 분석가, 마케터일 때
- 팀이 직접 데이터를 가져올 수 있게 하고 싶을 때
- 프록시, 안티봇 대응, 유지보수의 번거로움을 피하고 싶을 때
둘 다 쓰면 좋은 경우:
- Thunderbit으로 빠르게 프로토타입을 만들고, 운영용은 맞춤 Python 솔루션으로 구축하고 싶을 때
- Thunderbit으로 데이터를 모으고 Python으로 정제·분석하고 싶을 때
대부분의 비즈니스 사용자에겐 Thunderbit이 Amazon 스크래핑 수요의 90%를 훨씬 짧은 시간에 풀어줘요. 나머지 10%—아주 커스텀하거나, 대규모거나, 깊이 통합된 작업—에선 여전히 Python이 가장 강해요.
결론 및 핵심 정리
2025년 AI로 Amazon 제품과 리뷰를 스크래핑하는 방법 Get Started Free
Amazon 제품 데이터를 스크래핑하는 능력은 영업·이커머스·운영 팀에 강력한 무기예요. 가격 추적, 경쟁사 분석, 반복적인 복붙 줄이기 등 무엇이든 답이 있어요.
- Python 스크래핑은 완전한 제어를 주지만, 학습 곡선과 꾸준한 유지보수가 따라와요.
- Thunderbit 같은 노코드 웹 스크래퍼는 Amazon 데이터 추출을 누구나 할 수 있게 만들어요. 코딩도, 골치 아픈 일도 없고 결과만 있죠.
- 가장 좋은 길은요? 자기 기술 수준, 일정, 비즈니스 목표에 맞는 도구를 쓰는 거예요.
궁금하면 Thunderbit을 한번 써보세요. 시작은 무료고, 필요한 데이터를 얼마나 빨리 얻는지 놀라실 거예요. 개발자라면 두 방식을 섞는 것도 주저하지 마세요. 때로는 지루한 부분을 AI에 맡기는 게 가장 빠른 개발이니까요.
자주 묻는 질문
1. 기업이 Amazon 제품 데이터를 스크래핑하려는 이유는 무엇인가요?
Amazon을 스크래핑하면 가격을 모니터링하고, 경쟁사를 분석하고, 제품 조사를 위한 리뷰를 모으고, 수요를 예측하고, 영업 리드를 만들 수 있어요. 6억 개 넘는 상품과 거의 200만 명의 셀러가 있는 Amazon은 경쟁 정보의 풍부한 원천이에요.
2. Amazon 스크래핑에서 Python과 Thunderbit 같은 노코드 도구의 가장 큰 차이는 무엇인가요?
Python 스크래퍼는 최대한의 유연성을 주지만 코딩 실력, 설정 시간, 꾸준한 유지보수가 필요해요. Thunderbit은 노코드 AI 웹 스크래퍼로, Chrome 확장 프로그램으로 코딩 없이 Amazon 데이터를 즉시 뽑아요. 안티봇 처리와 Excel·Sheets 내보내기도 기본 제공되고요.
3. Amazon 데이터를 스크래핑하는 것은 합법인가요?
Amazon의 서비스 약관은 일반적으로 스크래핑을 금지하고, Amazon도 적극적으로 안티봇 조치를 걸어요. 다만 많은 기업은 공개 데이터를 책임감 있게 쓰려고 요청 속도를 지키고 과도한 요청을 피하는 식으로 주의하며 스크래핑해요.
4. 웹 스크래핑 도구로 Amazon에서 어떤 데이터를 뽑을 수 있나요?
보통 제품 제목, 가격, 평점, 리뷰 수, 이미지, 제품 사양, 재고 여부, 셀러 정보 등을 뽑아요. Thunderbit은 하위 페이지 스크래핑과 페이지네이션도 지원해 여러 목록과 페이지에 걸친 데이터를 모을 수 있어요.
5. 언제 Python 스크래핑을 고르고, 언제 Thunderbit 같은 도구를 골라야 하나요?
완전한 제어, 맞춤 로직, 백엔드 시스템 통합이 필요하면 Python을 쓰세요. 코딩 없이 빠른 결과를 원하거나, 쉽게 확장해야 하거나, 유지보수가 적은 솔루션을 찾는 비즈니스 사용자라면 Thunderbit을 쓰세요.
더 깊이 보고 싶으신가요? 아래 자료도 확인해 보세요.
즐거운 스크래핑 되세요. 여러분의 스프레드시트가 늘 최신이길 바랄게요.
Amazon용 Thunderbit AI 웹 스크래퍼 사용해 보기 Get Started Free




