요약
세계에서 트래픽이 가장 많은 웹사이트들의 Tranco 상위 1만 개 목록에 있는 모든 도메인의 robots.txt 파일을 수집했습니다. 이어서 RFC 9309을 준수하는 파서로 각 파일을 분석하고, 각 사이트가 어떤 AI 봇 정책을 채택했는지 분류한 뒤, 2026년에 대형 언어 모델을 학습·제공하는 ChatGPT, Claude, Perplexity, Gemini, Common Crawl, Bytespider, Apple Intelligence 등 각종 크롤러를 실제로 차단하려는 상위 방문 사이트가 얼마나 되는지 집계했습니다.
robots.txt를 깔끔하게 읽을 수 있었던 7,248개 사이트 기준 핵심 수치는 다음과 같습니다.
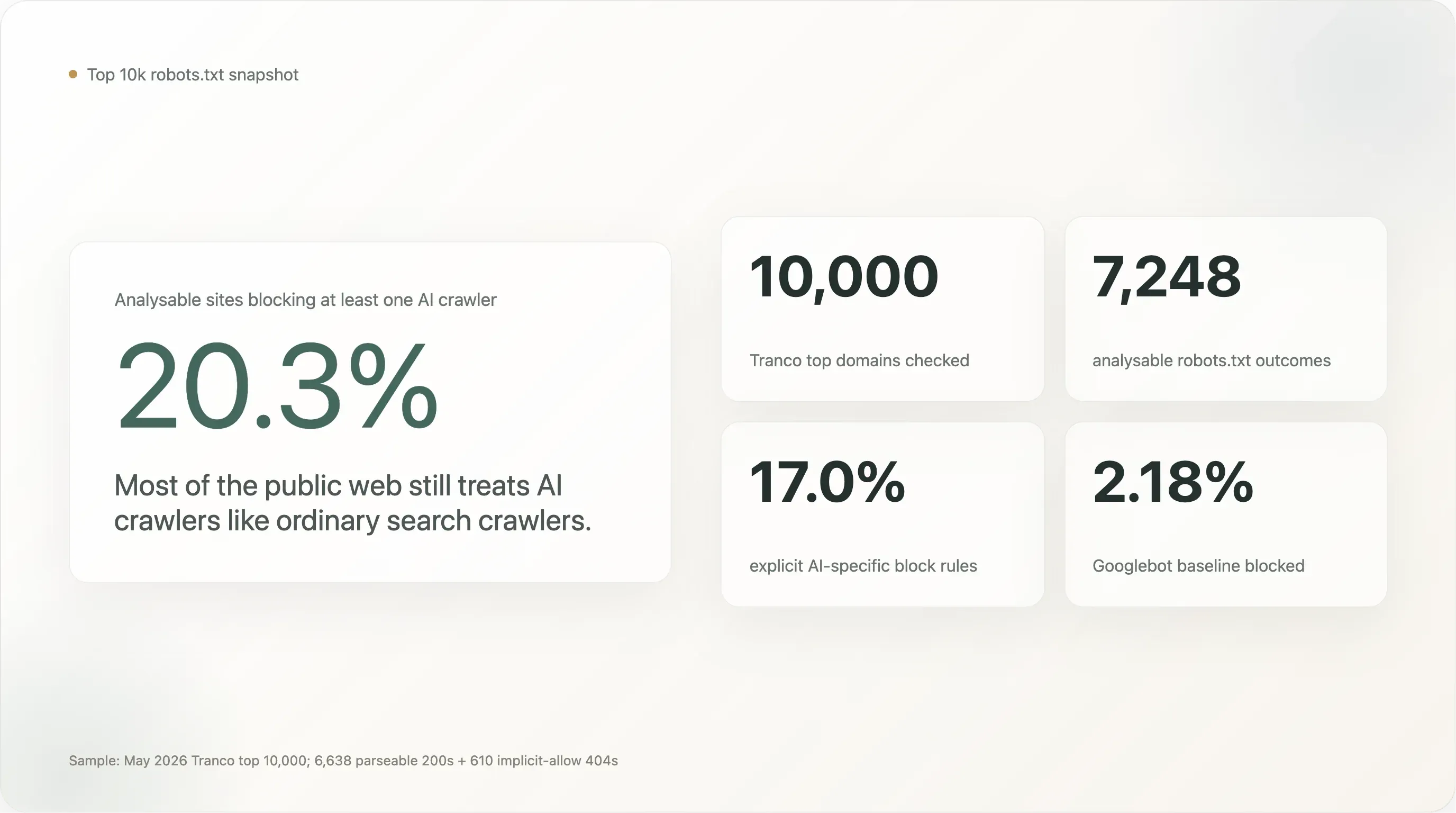
전 세계 상위 1만 개 사이트의 20.3%가 최소 1개의 AI 크롤러를 차단합니다. 17.0%는 의도적으로 AI 전용 규칙을 명시했습니다. 나머지 80%는 Googlebot만큼이나 AI 크롤러를 사실상 환영하고 있습니다.
이 이야기를 바꾸는 여섯 가지 발견:
- 뉴스 매체의 차단률은 47%로 가장 높습니다. 업종 중 최고 수준입니다. **독일 뉴스는 88%, 프랑스는 80%, 러시아는 0%**였습니다. 기술이나 산업 경제보다 법제도가 핵심 동인입니다.
CCBot(Common Crawl)이 16.3%로 가장 많이 차단된 봇입니다.GPTBot(15.8%),Bytespider(14.9%)보다 높습니다. 퍼블리셔들은 모델 브랜드가 아니라 학습 코퍼스를 겨냥하고 있습니다. 가장 널리 채택된 선택적 규칙은 "CCBot차단,Googlebot허용"이며, 이는 전체 사이트의 14.1%에서 보였습니다.- 프랑스의
.fr사이트는 AI 차단률이 50.6%로 모든 국가 중 선두입니다. EU 집단은 전 세계 기준선보다 16포인트 높습니다.robots.txt파일 275개가 EU 지침 2019/790을 명시적으로 언급했습니다. Article 4만이 눈에 띄게 수치를 움직인 유일한 법적 체계였습니다. - 17.8%는 자체 AI 규칙을 작성했고, 4.5%는 Cloudflare의 벤더 템플릿을 사용했으며, 75.7%는 아무 말도 하지 않았습니다. 대형 사이트는 직접 작성하고, 긴 꼬리 구간은 토글을 사용합니다. The Atlantic과
cloudflare.com자체도 Cloudflare Managed 목록에 포함됩니다. - 108개 사이트가
GPTBot을 명시적으로 허용합니다. WordPress.org, Kaspersky, Norton, Avast, Sophos, The Verge, The Atlantic, NBA.com, The Sun, Branch.io 등이 포함됩니다. 보안 및 개발 도구 관련 사이트의 비중이 높습니다. - AI 정책은 곡선 상단으로 갈수록 더 공격적이지 않습니다. 상위 100위, 101~1000위, 1001~5000위, 5001~10000위는 모두 19%~23% 사이에 있습니다. 헤드라인 수치는 개별 사이트 규모가 아니라 2026년 공개 웹의 특성입니다.
이제 핵심은 웹이 "반격하고 있느냐"가 아닙니다. 어떤 업종이, 어떤 국가가, 어떤 법제가, 어떤 AI 벤더가 능동적 정책의 대상인지, 그리고 그렇지 않은지가 중요합니다.
I. 배경: robots.txt가 어떻게 AI 정책 문서가 되었나
OpenAI가 2023년 8월 GPTBot을 출시한 이후, robots.txt의 의미를 바꾼 힘은 세 가지였습니다.
AI 벤더가 급증했습니다. Google의 Google-Extended, Anthropic의 ClaudeBot, ByteDance의 Bytespider, Apple의 Applebot-Extended, Amazon의 Amazonbot, Meta의 Meta-ExternalAgent가 뒤를 이었습니다. 이미 존재하던 Common Crawl의 CCBot은 가장 영향력 큰 차단 대상이 되었습니다. 이 아카이브가 대부분의 오픈 웨이트 모델 학습에 쓰이기 때문입니다. 벤더 외 봇도 등장했습니다. AI2Bot, cohere-ai, PerplexityBot, YouBot, DuckAssistBot, Diffbot, Omgili 등이 그 예입니다. 2026년 기준 포괄적 차단 목록은 약 25개 이름에 이릅니다.
EU 저작권 지침 2019/790의 Article 4는 권리자가 권리를 "기계 판독 가능한 방식"으로 명시적으로 유보하면 적용되지 않는 텍스트·데이터 마이닝 예외를 만들었습니다. 2024~2025년 동안 EU 퍼블리셔와 법무팀은 이 유보를 표현하는 표준 수단으로 robots.txt를 채택했습니다. 우리 데이터셋에서는 275개 사이트가 Directive 2019/790을 명시적으로 언급했고, 87개는 "TDM"을 언급했습니다. 유럽 뉴스 사이트에서는 이 내용이 4~8줄짜리 법적 서문으로 자리 잡았습니다.
Cloudflare가 토글을 제품화했습니다. 2024~2025년 Cloudflare는 "AI Audit" 대시보드, "Block AI Bots" 토글, 그리고 Content-Signal: search=yes,ai-train=no 문구와 EU 2019/790 보일러플레이트를 포함한 Managed robots.txt 템플릿을 출시했습니다. 2026년 5월 기준 이 템플릿은 파싱 가능한 상위 1만 개의 4.5%에서 사용 중입니다. Cloudflare의 로드맵은 새 계정에서 이 토글을 기본 활성화하는 방향을 공개적으로 논의하고 있으며, 그렇게 되면 개별 퍼블리셔의 의사결정 없이 전 세계 차단률이 5~8포인트 올라갑니다.
2026년의 robots.txt는 더 이상 2022년처럼 평범한 설정 파일이 아닙니다. EU에서는 조약적 근거를 가진 저작권 유보 메커니즘이 되었고, 긴 꼬리 구간에서는 벤더가 만든 정책 문서가 되었으며, 웹사이트 운영자와 모델 학습자 사이의 느린 협상의 최전선이 되었습니다.
II. 방법론
가장 지루하고 재현 가능하게 만드는 것을 목표로 했습니다. 전체 파이프라인(Python 스크립트, 파싱된 CSV, 원본 robots.txt 아카이브, 차트)은 이 보고서와 함께 공개합니다.
샘플
2026년 5월 시점의 Tranco 목록을 top-1m.csv.zip 형태로 내려받아 상위 10,000행을 사용했습니다. Tranco는 Cisco Umbrella, Majestic, Farsight, Cloudflare Radar의 네 가지 상위 랭킹을 합치고, 30일 안정성 기준으로 필터링하며, 명백한 크롤러/CDN 노이즈를 제거합니다. 이 목록은 공개 웹에 존재하는 가장 가까운 "전 세계 웹 트래픽 상위 1만" 표본에 해당하며, 2018년 KU Leuven에서 시작된 이후 600편 이상의 피어리뷰 논문에 쓰인 학술 웹 연구의 표준 샘플입니다.
이 목록에는 (a) 사용자가 실제로 방문하는 주요 웹사이트, (b) /에 콘텐츠를 제공하지 않는 인프라/API/DNS/CDN 최상위 도메인, (c) 대형 플랫폼 내부에서 사용되는 도메인(예: gvt1.com, apple-dns.net, googleusercontent.com)이 섞여 있습니다. 이를 사전 필터링하지 않고 모두 유지한 뒤, 분석 단계에서 infrastructure 범주를 부여했습니다. "파싱 가능한 robots.txt를 반환한 사이트"로 범위를 좁히면 자연스럽게 빠져나갑니다.
수집
10,000개 도메인 각각에 대해 HTTPS로 비동기 GET /robots.txt를 보냈고, 실패 시 HTTP로 폴백했으며, 최대 4번의 리다이렉트를 따라갔고, 총 12초 타임아웃, 500KB 본문 상한, 실제 브라우저와 유사한 User-Agent 문자열 및 Accept-Language: en-US를 사용했습니다. 동시 요청은 80개로 제한했습니다. 작업은 샌프란시스코의 단일 주거용 IP에서 수행했습니다.
수집 결과:
| 상태 | 개수 | 해석 |
|---|---|---|
200 OK | 6,638 | robots.txt 본문을 반환했고 파싱 가능했습니다. |
404 Not Found | 610 | robots.txt가 없습니다. RFC 9309에 따르면 이는 암묵적으로 "모든 것 허용"입니다. |
403 Forbidden | 563 | 원본 서버가 robots.txt 요청을 적극적으로 거부했습니다. 분석에서 제외했습니다. |
429 Too Many Requests | 7 | 이 순위대에서는 CDN 수준의 속도 제한이 거의 없었습니다. |
fetch_failed (TLS / DNS / TCP 오류) | 2,065 | 대부분 akamai.net, cloudfront.net, fastly.net, gtld-servers.net, apple-dns.net 같은 CDN 최상위 도메인으로, /에서 웹서버를 운영하지 않습니다. "차단"이 아니라 제공할 robots.txt가 없는 것입니다. |
| 기타 4xx/5xx | 117 | 서버 오류, 지오펜싱, 잘못된 응답이 혼재했습니다. |
이로써 **분석 가능한 표본은 7,248개 사이트(6,638개의 200 + 610개의 404)**가 됩니다. 2,065개의 fetch_failed는 실제 도메인이지만 CDN/DNS 최상위 지점으로, 사람들이 방문하는 사이트가 아닙니다. 이를 "AI 정책이 있다"고 보는 것은 타당하지 않습니다. 이들은 별도의 접근성 통계로 데이터셋에 남겨두었습니다.
파싱
모든 200 본문은 Scrapy가 운영 환경에서 사용하는 RFC 9309 구현체인 **protego**로 파싱했습니다. 각 (사이트, 봇) 쌍에 대해 세 가지를 계산했습니다.
can_fetch_root— 표준의 그룹 단위 의미론, 가장 긴 일치 규칙 우선, 그리고 둘 다 존재할 때 특정 봇 차단이User-agent: *보다 우선하는지 여부.has_specific_rule— 파일에 이 정확한 봇 이름을 명시한User-agent:행이 있는지 여부(대소문자 무시).disallow_count— 해당 블록의Disallow:지시문 개수. 전면 차단과 경로 수준 제한을 구분하는 데 사용했습니다.
이 조합이 중요한 이유는, 표면적인 "차단률" 하나로는 전혀 다른 두 현상을 가리기 때문입니다. 하나는 "User-agent: GPTBot \n Disallow: /처럼" 의도적으로 작성한 브랜드이고, 다른 하나는 예전에 스테이징이나 유지보수 용도로 만들어 둔 일반적인 User-agent: * \n Disallow: / 규칙이 우연히 그 이후 등장한 모든 AI 봇까지 막아 버리는 경우입니다. 이 보고서에서 "AI 차단" 수치는 두 종류를 모두 포함하고, "명시적 AI 차단" 수치는 의도적으로 쓴 하위 집합만 포함합니다.
분석 대상 봇
우리는 25개 봇을 추적했으며, 세 범주로 묶었습니다.
- AI 학습 크롤러(16):
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Meta-ExternalAgent,Bytespider,Applebot-Extended,Diffbot,Amazonbot,ImagesiftBot,FacebookBot,cohere-ai,AI2Bot,Omgili,Omgilibot. - AI 추론 / 실시간 검색 봇(7):
PerplexityBot,Perplexity-User,ChatGPT-User,OAI-SearchBot,ClaudeBot(학습과 추론을 모두 담당),YouBot,DuckAssistBot. - 검색 기준선(6):
Googlebot,Bingbot,DuckDuckBot,Slurp(Yahoo),Baiduspider,YandexBot.
일부 봇은 학습/추론 경계를 넘나듭니다. 가장 대표적인 것이 ClaudeBot입니다. Anthropic은 2024년에 이전 UA인 anthropic-ai를 폐기하고 현재는 ClaudeBot을 학습과 실시간 검색 모두에 사용하므로, Disallow: ClaudeBot 규칙은 더 이상 "학습은 막고 인용은 허용"이라는 의미로 깔끔하게 매핑되지 않습니다. 우리는 일단 배정은 그대로 두고, 그 결과는 뒤에서 따로 설명했습니다.
산업 분류
각 도메인을 16개 산업 버킷(news, social, streaming, ecommerce, search, finance, infrastructure, saas, academia, dev, gov, adult, gambling, travel, telecom, unknown) 중 하나로 분류했습니다. 계층형 접근을 사용했습니다.
- 알려진 도메인 사전 — 약 500개의 고트래픽 도메인을 산업에 대응시킨 수동 정제 맵.
- TLD / 접미사 패턴 —
.gov→gov,.edu및.ac.*→academia, 인식된 CDN 접미사 →infrastructure. - 도메인 이름 키워드 — news, post, shop, bank, porn, casino 등을 보조 신호로 사용.
- 홈페이지 스크래핑 — 앞의 세 단계로 분류되지 않았고
robots.txt에서200을 반환한 사이트는 홈페이지 HTML을 가져와<title>,<meta name="description">,<meta property="og:type">를 추출하고, 언어 모델식 범주 단서에 대해 키워드 점수를 적용했습니다.
그 결과 3,407개 사이트(34%)는 확실한 산업 태그를 얻었고, 6,593개는 unknown으로 남았습니다. unknown 버킷은 비영어권 지역 포털, 어떤 단일 버킷에도 깔끔히 들어맞지 않는 기업 .com 브랜드 사이트, 사전 항목이 없는 소규모 언어권 전통 매체가 대부분입니다. 이 보고서에서 업종별 비율을 인용할 때의 분모는 전체 1만 개가 아니라 해당 업종에서 분류에 성공한 표본입니다.
III. 발견
발견 1 — 상위 트래픽 사이트 5개 중 1개는 최소 1개 AI 봇을 차단한다
분석 가능한 7,248개 사이트 중 **1,472개(20.31%)**가 최소 1개 AI 봇을 차단합니다. **1,230개(16.97%)**는 의도적인 AI 전용 규칙을 갖고 있습니다. Googlebot 기준선은 2.18%(158개 사이트)로, 그중 대부분은 유지보수 기본값으로 모든 것을 막고 있거나, 3곳은 경쟁사를 차단하는 검색엔진입니다.
헤드라인 20%는 Googlebot 기준선의 9배입니다. 이는 실제 신호입니다. 상위 트래픽 사이트는 검색 크롤러보다 AI 크롤러를 한 자릿수 이상 더 자주 차단합니다. 하지만 2024년 이후 언론에서 계속 반복된 "AI 차단이 보편화되고 있다"는 서사보다는 훨씬 작은 수치이기도 합니다. 웹에서 가장 많이 방문되는 상위 1만 개 사이트조차 6개 중 5개는 AI에 대해 침묵합니다.
"모든 AI 차단"(20.3%)과 "명시적 AI 차단"(17.0%)의 차이는 절대값으로는 작지만 개념적으로 중요합니다. 3.3포인트 격차는 기존의 User-agent: * \n Disallow: / 규칙이 우연히 그 앞을 지나가는 모든 것을 막아 버리기 때문에 AI 봇까지 차단하는 사이트들의 비율입니다. 17.0%라는 의도적 수치는 "세계 최대 웹사이트들 중 얼마나 많은 곳이 AI에 대한 특정 결정을 내렸는가"를 더 깨끗하게 보여줍니다.
이전 연구와 비교하면:
| 출처 | 시점 | 표본 | 차단률 |
|---|---|---|---|
| Originality.ai | 2025년 3월 | 가장 인기 있는 뉴스 1,000개(영문) | GPTBot 차단 35.7% |
| Palewire | 2024년 8월 | 뉴스 조직 1,500개 | AI 크롤러 차단 36.0% |
| Reuters Institute | 2025년 봄 | 10개국 주요 뉴스 브랜드 50개 | AI 크롤러 차단 78% |
| WIRED / NYT | 2023년 말 | 미국 뉴스 상위 50개 | GPTBot 차단 26% |
| 이 보고서(Thunderbit) | 2026년 5월 | Tranco 상위 1만 개(전체 업종) | 20.3% / 명시적 17.0% |
우리의 17.0% 명시적 수치는 표본의 3분의 2가 뉴스가 아니기 때문에 뉴스 전용 연구들보다 낮습니다. 뉴스 650개 사이트만 놓고 보면 47%로, 표본 구성을 감안하면 이전 연구들과 같은 범위에 들어갑니다. 구조적 그림은 일관됩니다. 뉴스 집단은 나머지 웹보다 AI를 3~4배 더 많이 차단합니다.
발견 2 — 업종별 심층 분석: 뉴스에서 통신까지 12배 차이
지난 2년간 "AI 스크래핑" 보도에서 가장 자주 인용된 발견은 Originality.ai와 Palewire가 제시한 뉴스 매체의 80%가 GPTBot을 차단한다는 수치였습니다. 우리 분석은 더 작지만 여전히 뚜렷한 수치를 보여줍니다. 상위 1만 개 뉴스 사이트의 47.2%가 최소 1개의 AI 봇을 차단하고, 45.2%는 명시적 AI 규칙을 작성했습니다.
하지만 "뉴스 vs 나머지 모두"는 너무 거친 구분입니다. 전체 세부 분해(표본 n ≥ 10 업종)는 훨씬 풍부한 이야기를 들려줍니다.
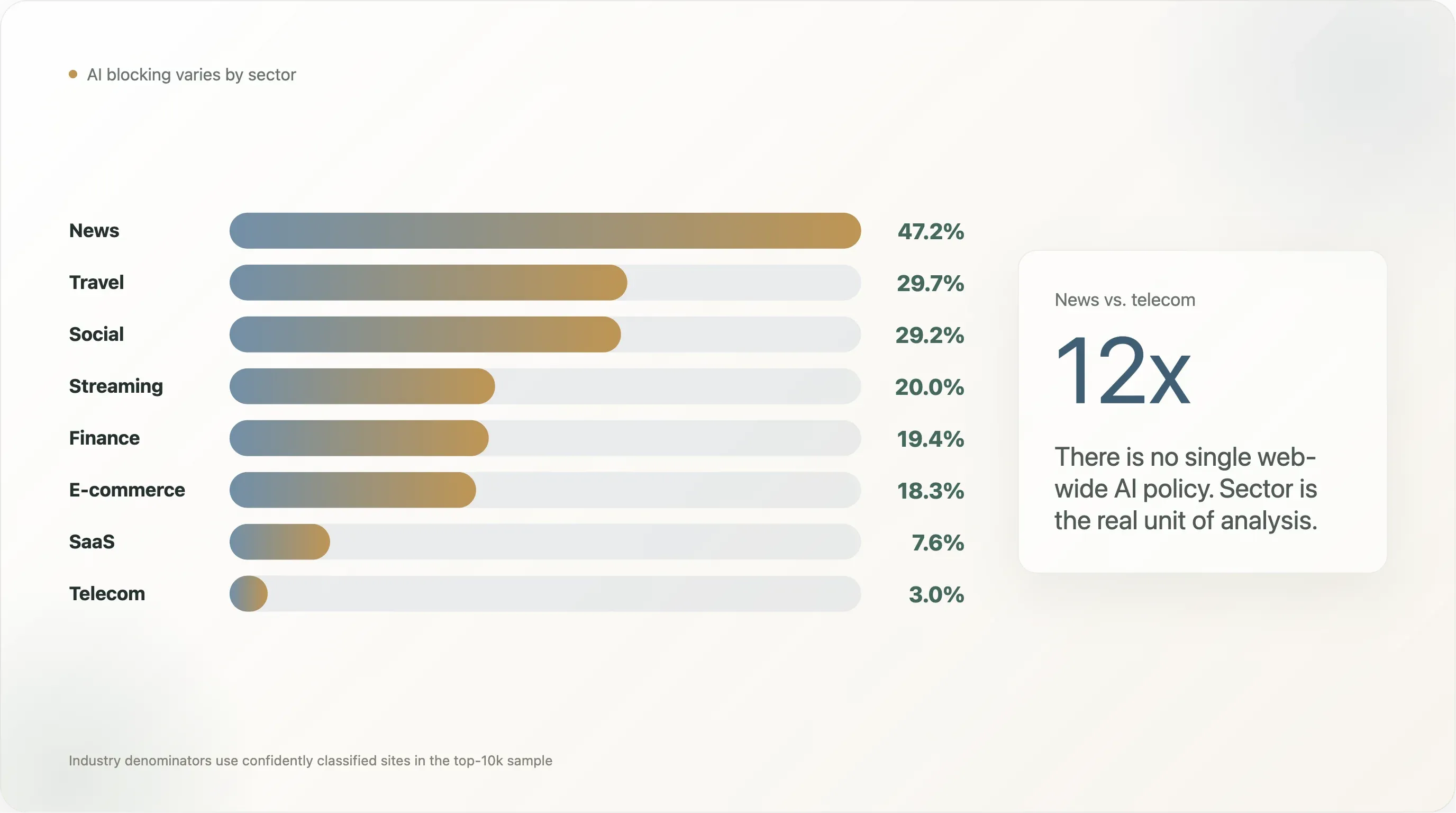
| 업종 | n | AI 차단 | 명시적 차단 | Googlebot 차단 | DIY 규칙 | Cloudflare Managed | 침묵 |
|---|---|---|---|---|---|---|---|
| 뉴스 | 650 | 47.2% | 45.2% | 1.5% | 46.9% | 1.5% | 48.5% |
| 여행 | 64 | 29.7% | 29.7% | 0.0% | 35.9% | 3.1% | 54.7% |
| 소셜 | 65 | 29.2% | 23.1% | 4.6% | 23.1% | 6.2% | 66.2% |
| 스트리밍 | 440 | 20.0% | 17.7% | 0.7% | 16.8% | 3.6% | 75.5% |
| 금융 | 129 | 19.4% | 12.4% | 0.8% | 14.7% | 2.3% | 75.2% |
| 이커머스 | 224 | 18.3% | 17.4% | 0.4% | 24.1% | 1.3% | 66.1% |
| 성인 | 254 | 17.3% | 14.6% | 0.4% | 10.2% | 7.9% | 79.5% |
| 검색 | 12 | 16.7% | 0.0% | 0.0% | 0.0% | 0.0% | 100.0% |
| 학술 | 268 | 14.6% | 13.8% | 0.4% | 13.4% | 3.4% | 77.2% |
| 도박 | 100 | 14.0% | 13.0% | 0.0% | 18.0% | 4.0% | 77.0% |
| 개발 도구 | 129 | 10.1% | 7.8% | 0.0% | 8.5% | 5.4% | 77.5% |
| SaaS | 369 | 7.6% | 6.2% | 0.3% | 9.5% | 0.8% | 87.5% |
| 정부 | 172 | 5.2% | 3.5% | 0.0% | 4.1% | 0.6% | 83.1% |
| 인프라 | 47 | 4.3% | 0.0% | 0.0% | 4.3% | 2.1% | 72.3% |
| 통신 | 33 | 3.0% | 3.0% | 0.0% | 12.1% | 0.0% | 78.8% |
뉴스와 통신 사이의 12배 격차는 "웹의 AI 정책"이라는 단일 단위를 쓰는 것이 왜 잘못된 분석 단위인지 보여줍니다. 숫자는 하나가 아니라, 업종별로 한 자릿수 이상 차이가 나는 여러 개입니다. 아래에서 가장 뚜렷한 네 가지를 살펴봅니다.
뉴스: 47% 차단, 47% DIY. 뉴스는 플레이북을 쓴 집단입니다. 뉴스 업종에서 Cloudflare Managed는 1.5%에 불과합니다. 이 퍼블리셔들은 규칙을 외주 주지 않습니다. 텍스트도 매우 풍부합니다. NYT는 "EU Directive의 Art. 4"를 인용하는 14줄짜리 법적 서문으로 시작하고, BBC는 *"사람처럼 사이트를 이용해 주세요. 로봇처럼 말고요... TL;DR: 사람처럼 둘러보고, 읽고, 보고, 즐겨 주세요."*로 시작하며, The Sun은 *"The Sun은 대형 언어 모델을 위한 당사 콘텐츠의 무허가 사용을 허용하지 않습니다."*라고 씁니다. 이는 설정 파일이 아니라 정책 문서로서의 robots.txt입니다.
여행 업종 30% — 의외의 결과. Booking, Expedia, TripAdvisor, Kayak, 주요 항공사들은 뉴스 업종의 2/3 수준에서 차단합니다. 선택적 패턴도 일관됩니다. 평균적인 여행 업종 차단 사이트는 5~7개의 학습 UA를 차단하지만 추론 UA(PerplexityBot, ChatGPT-User, OAI-SearchBot)는 건드리지 않습니다. 집계된 요금·리뷰 데이터가 해자이고, 사이트로 돌아오는 인용이 이득입니다. 단일 업종에서 보이는 가장 깔끔한 "학습은 차단, 추론은 허용" 패턴입니다.
성인 업종 17% — 역시 의외의 결과. 이전의 작은 표본에서는 0%였습니다. 전체 표본에서는 성인 사이트 6개 중 1개가 최소 1개의 AI 봇을 차단했으며, 모든 업종 중 Cloudflare Managed 비율이 가장 높았습니다(7.9%). 성인 사이트의 AI 차단 절반 이상은 퍼블리셔의 판단이 아니라 Cloudflare 토글에서 비롯됩니다. 이미지 생성 학습이 암묵적 위협입니다. Stable Diffusion 계열 모델은 텍스트 모델이 문체를 배우는 것보다 시각적 스타일을 훨씬 빨리 학습합니다.
SaaS 7.6%는 직관을 깨뜨립니다. 소프트웨어 벤더는 AI 정책 담론에서 가장 큰 목소리를 내는 세그먼트지만, robots.txt는 대체로 열려 있습니다. 올바른 해석은 이렇습니다. SaaS 마케팅 팀은 AI 검색이 배포 채널이라는 사실을 정확히 파악했습니다. 실제로 이 문제를 고민한 벤더들은 회피가 아니라 참여를 선택하고 있습니다. 명시적 Allow: /-GPTBot 목록(발견 12번)은 보안 및 개발 도구 SaaS가 주도합니다.
정부 5.2%, 통신 3.0%, 인프라 4.3%, 개발 10.1%. 공공기록 의무는 .gov에서 Disallow: /를 법적으로 민감하게 만듭니다. 통신 마케팅 사이트는 발견 가능성을 원합니다. CDN 최상위 도메인은 보호할 것이 없습니다. 개발 도구는 명시적으로 참여를 택합니다(콘텐츠가 LLM이 이를 인용할 때 가치가 커지기 때문입니다).
요약하면, "웹이 AI를 차단하느냐 마느냐"라는 단일 숫자는 전달하는 것보다 잃는 것이 더 많습니다. 데이터를 정직하게 다루는 유일한 방법은 업종 단위 보고입니다.
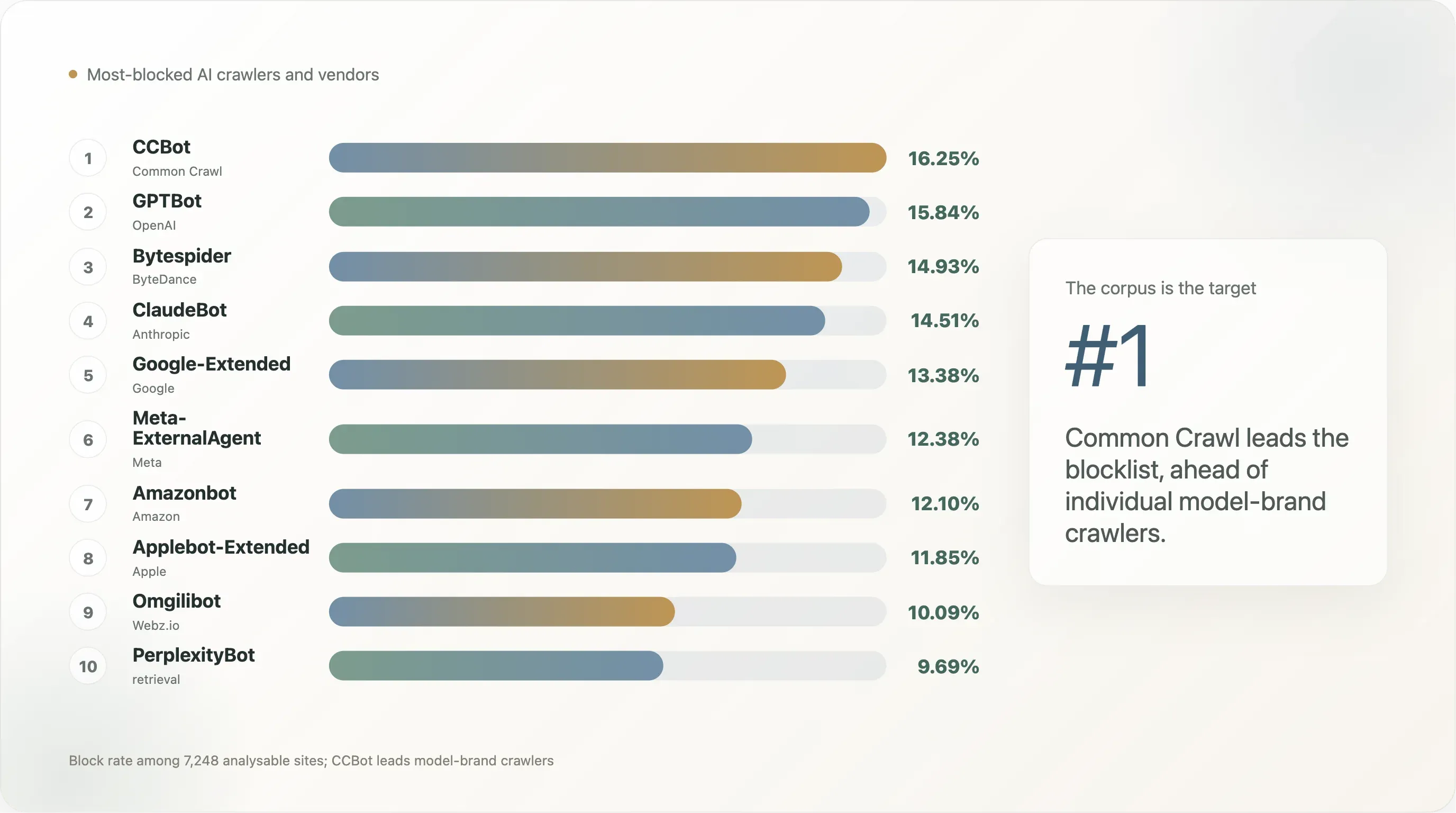
발견 3 — AI 벤더별: 누가 가장 많이 차단되고 있나?
데이터를 보는 또 다른 자연스러운 방식은 봇이 아니라 AI 회사별로 나누는 것입니다. 여러 벤더는 여러 봇을 운영합니다(OpenAI는 GPTBot, ChatGPT-User, OAI-SearchBot 3개; Anthropic은 ClaudeBot, anthropic-ai 2개; Meta는 Meta-ExternalAgent, FacebookBot 2개). 벤더 수준으로 집계하면, 공개 웹이 각 AI 회사를 어떻게 보는지에 가장 가깝게 다가갈 수 있습니다.
| AI 벤더 | 집계된 봇 | ≥1개 봇 차단 사이트 | 분석 가능 사이트 대비 비율 |
|---|---|---|---|
| Common Crawl | CCBot | 1,178 | 16.25% |
| OpenAI | GPTBot, ChatGPT-User, OAI-SearchBot | 1,172 | 16.17% |
| Anthropic | ClaudeBot, anthropic-ai | 1,111 | 15.33% |
| ByteDance | Bytespider | 1,082 | 14.93% |
| Meta | Meta-ExternalAgent, FacebookBot | 989 | 13.65% |
Google-Extended | 970 | 13.38% | |
| Amazon | Amazonbot | 877 | 12.10% |
| Apple | Applebot-Extended | 859 | 11.85% |
| Webz.io (Omgili) | Omgili, Omgilibot | 731 | 10.09% |
| Cohere | cohere-ai | 717 | 9.89% |
| Perplexity | PerplexityBot, Perplexity-User | 715 | 9.86% |
| Diffbot | Diffbot | 684 | 9.44% |
| You.com | YouBot | 563 | 7.77% |
| AI2(Allen AI) | AI2Bot | 487 | 6.72% |
| DuckDuckGo | DuckAssistBot | 482 | 6.65% |
Common Crawl이 단일 차단 대상 1위입니다. LLM 운영사가 아니라 비영리 웹 아카이브인데도 그렇습니다. 이유는 영향력입니다. CCBot은 거의 모든 오픈 웨이트 모델과 폐쇄형 모델 상당수의 학습에 쓰입니다. 퍼블리셔가 쓸 수 있는 가장 높은 커버리지의 규칙은 먼저 CCBot을 막는 것입니다.
OpenAI, Anthropic, ByteDance는 14~16%대에 몰려 있습니다. OpenAI가 약간 앞선 것은 일부 집계 효과(단일 봇인 ByteDance와 달리 OpenAI는 3개 봇) 때문입니다. **Bytespider의 14.9%는 "Bytespider 행동 효과"**를 보여줍니다. 2024년부터 robots.txt를 무시한다는 문서가 있었고, 퍼블리셔들은 TikTok이 걱정돼서가 아니라 공개 신호로 차단하고 있습니다.
**Meta, Google, Amazon, Apple은 12~14%**로 두 번째 그룹입니다. 이들은 입장 표명이라기보다 방어적으로 작성된 규칙입니다. **소규모 벤더(Webz.io, Cohere, Perplexity, Diffbot, You.com, AI2, DuckDuckGo)는 6~10%**로, 대부분 3.8%의 범용 바닥값에 끌려 올라간 수치입니다. 이들에 대한 명시적 규칙은 1~4%대입니다.
xAI(Grok), Mistral, 그리고 대부분의 유럽/중국 모델 연구소는 표에서 빠져 있습니다. 문서화된 학습 크롤러 UA를 공개하지 않았기 때문입니다. 현재의 robots.txt 생태계는 UA를 배포한 미국/중국 벤더와 규칙을 작성한 미국/EU 퍼블리셔 사이의 대화입니다. UA를 배포하지 않은 벤더는 협상에서 보이지 않습니다.
발견 4 — GPTBot이 아니라 CCBot이 새로운 표적이다
상위 1만 개에서 봇 차단 순서는 다음과 같습니다.
| 순위 | 봇 | 차단률 | 명시적 규칙 비율 |
|---|---|---|---|
| 1 | CCBot (Common Crawl) | 16.25% | 12.90% |
| 2 | GPTBot (OpenAI) | 15.84% | 12.72% |
| 3 | Bytespider (ByteDance) | 14.93% | 11.35% |
| 4 | ClaudeBot (Anthropic) | 14.51% | 11.13% |
| 5 | Google-Extended | 13.38% | 10.18% |
| 6 | Meta-ExternalAgent | 12.38% | 8.95% |
| 7 | Amazonbot | 12.10% | 8.66% |
| 8 | Applebot-Extended | 11.85% | 8.72% |
| 9 | Omgilibot | 10.09% | 5.31% |
| 10 | anthropic-ai (폐기됨) | 9.99% | 6.55% |
| 11 | cohere-ai | 9.89% | 6.42% |
| 12 | PerplexityBot | 9.69% | 6.40% |
| 13 | Diffbot | 9.44% | 5.95% |
| 14 | ChatGPT-User(추론) | 8.90% | 5.73% |
| 15 | YouBot(추론) | 7.77% | 4.29% |
| 16 | OAI-SearchBot(추론) | 6.83% | 3.66% |
| 기준선 | Googlebot | 2.18% | — |
| 기준선 | Bingbot | 2.27% | — |
이 표가 말해 주는 핵심은 공개 웹이 가장 먼저 차단하는 봇은 모델 브랜드가 아니라 코퍼스라는 점입니다. Common Crawl의 2,500억 페이지 아카이브는 GPT-3, GPT-4, Llama 1/2/3, Falcon, Mistral, BLOOM, 그리고 2020년 이후 공개된 대부분의 오픈 웨이트 모델의 단일 최대 학습 입력이었습니다. "다음 프런티어 모델에 포함되지 않기"를 원하는 사이트는 CCBot부터 차단하는 것이 최적입니다. 일단 Common Crawl에 없으면 무료로 오픈소스 학습 파이프라인에서 사실상 제외됩니다. GPTBot과 ClaudeBot이 2위와 3위인 이유는 두 상용 제품의 가시적인 전면이기 때문이고, 구조적 타깃은 코퍼스 수준 UA입니다.
표의 낮은 순위 AI 봇도 의미가 있습니다. Omgilibot이 10%로, 많은 독자에게 익숙하지 않을 봇치고는 비정상적으로 높습니다. 이는 LLM 운영사에 웹 아카이브를 판매하는 콘텐츠 데이터 중개업체 Webz.io가 운영하며, 상당수 뉴스 조직이 파일에서 이 이름을 명시적으로 적기 시작했다는 뜻입니다. AI2Bot의 6.7%(그리고 Squarespace 사이트에서의 대응 규칙 Ai2Bot-Dolma)는 학계 LLM 커뮤니티도 퍼블리셔로부터 플래깅되고 있음을 시사합니다. 일부 퍼블리셔는 "비영리 연구 크롤러"와 "상업 크롤러"를 구분하지 않습니다.
추론 집단 — ChatGPT-User, OAI-SearchBot, YouBot, Perplexity-User — 은 학습 집단보다 4~8포인트 낮습니다. 이 격차가 오랜 정책 질문에 대한 답입니다. 네, 상위 트래픽 사이트들은 미래 모델 학습용 데이터를 수집하는 봇과 사용자 질문에 지금 답하기 위해 실시간 검색을 수행하는 봇을 구분합니다. 항상 구분하는 것은 아니지만(범용 규칙은 그렇지 않습니다), 상당수는 학습 쪽만 겨냥한 규칙을 작성합니다.
발견 5 — 14%가 Googlebot은 살리고 CCBot은 막는다: "코퍼스는 차단, 검색은 유지" 패턴
상위 1만 개에서 가장 널리 채택된 선택적 규칙:
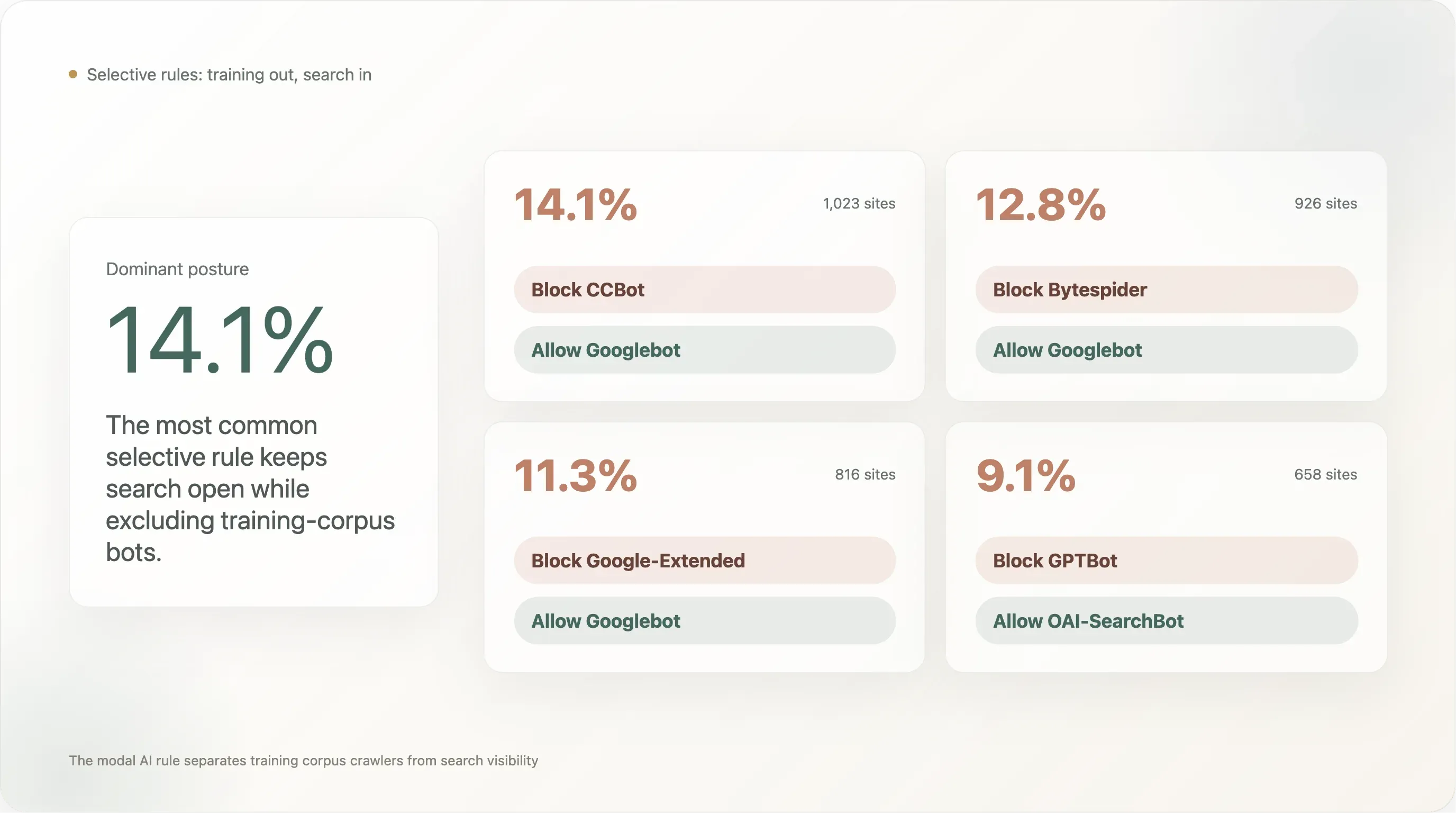
This paragraph contains content that cannot be parsed and has been skipped.
가장 널리 채택된 패턴(14.1%)은 "Common Crawl은 차단하되 Google 검색 가시성은 유지"입니다. 2위(12.8%)는 "Bytespider는 차단하되 Google 검색 가시성은 유지"로, 즉 평판상 표적이 된 ByteDance 크롤러는 막고 합법적 검색 기준선은 그대로 두는 것입니다. 3위(11.3%)는 "Google의 AI 학습 UA는 차단하되 Google의 검색 UA는 허용"인데, 이것이 바로 Google이 Google-Extended를 만든 이유입니다. 퍼블리셔는 검색 순위를 잃지 않으면서 Bard / Gemini 학습만 제외할 수 있습니다.
이 세 수치를 함께 보면 상위 1만 웹의 지배적 정책 자세가 보입니다. 학습 코퍼스 봇은 차단하고, 검색 및 추론 봇은 건드립니다. 학습은 차단하지만 이 LLM의 특정 실시간 검색 UA는 허용하는 소수 패턴 — GPTBot ✗ / ChatGPT-User ✓가 7.2% — 도 존재하지만, 코퍼스 수준 차단보다 규모는 작습니다.
anthropic-ai / ClaudeBot의 0.81%는 Anthropic의 2024년 UA 폐기를 반영합니다. 현재 ClaudeBot은 학습과 추론을 모두 담당하므로, 과거 anthropic-ai UA가 허용하던 "학습은 막고 인용은 허용"의 깔끔한 표현이 사라졌습니다. 이것은 2024~2025년 가장 과소평가된 UA 설계 결정입니다. robots.txt에서 한 종류의 정책 표현 전체를 없애 버렸기 때문입니다.
발견 6 — 뉴스의 세부: 국가별·언어별 차이
뉴스 범주를 국가 코드 TLD 기준으로 나누면 — 여기서 중요한 것은 .de가 독일 뉴스, .fr가 프랑스 뉴스 등을 의미할 뿐, 실제 제공 언어를 뜻하는 것은 아니라는 점입니다 — 뉴스 내부의 편차가 뉴스와 나머지 간의 편차보다 더 큽니다.
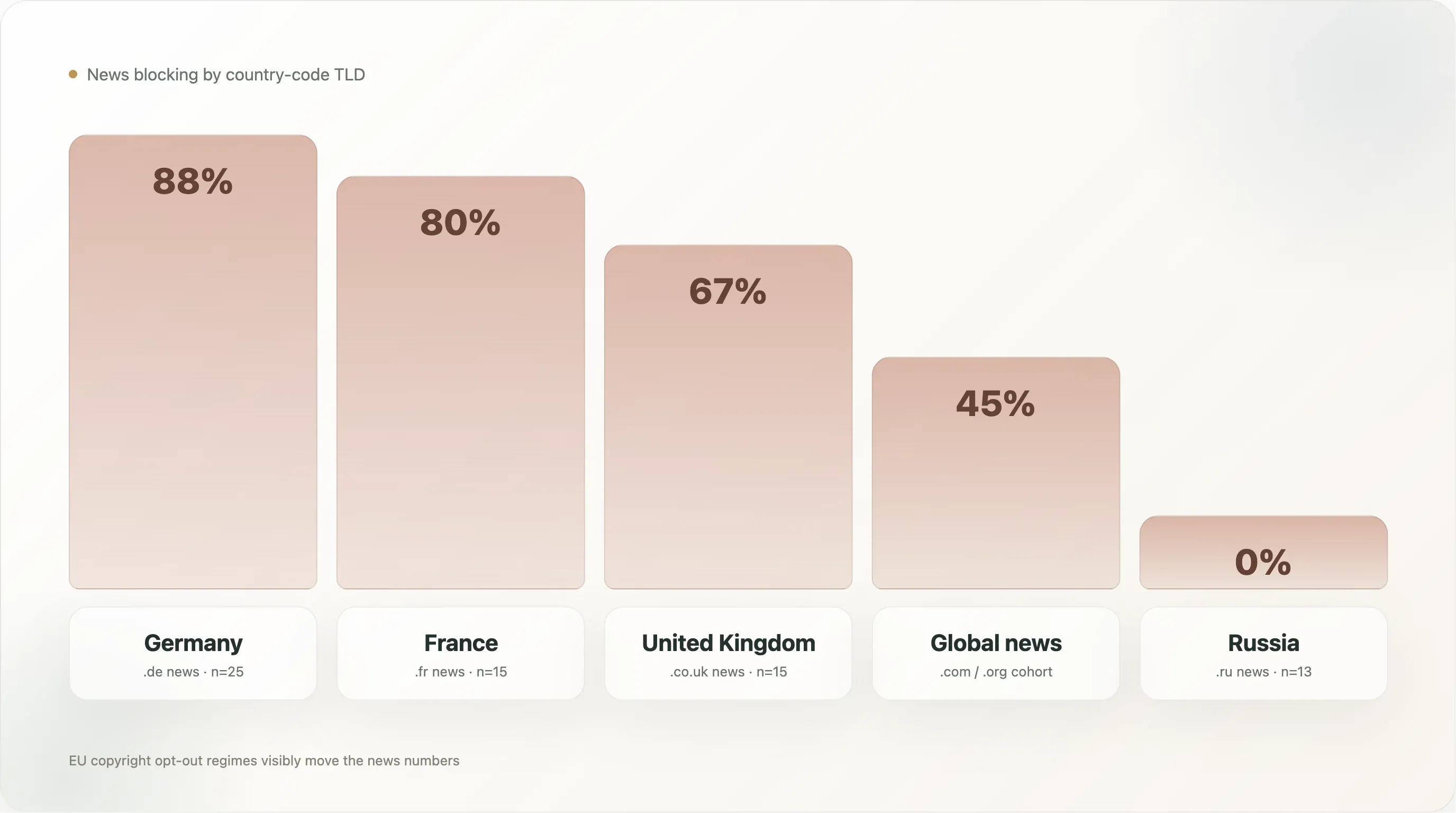
| 국가(뉴스만) | n | AI 차단 | 명시적 |
|---|---|---|---|
🇩🇪 독일 (.de) | 25 | 88.0% | 88.0% |
🇫🇷 프랑스 (.fr) | 15 | 80.0% | 80.0% |
🇬🇧 영국 (.co.uk) | 15 | 66.7% | 53.3% |
🇪🇸 스페인 (.es) | 5 | 60.0% | 60.0% |
🇮🇹 이탈리아 (.it) | 13 | 53.8% | 53.8% |
글로벌 뉴스 (.com/.org 등) | 500 | 45.0% | 42.8% |
🇵🇱 폴란드 (.pl) | 7 | 42.9% | 42.9% |
🇯🇵 일본 (.jp) | 12 | 25.0% | 25.0% |
🇷🇺 러시아 (.ru) | 13 | 0.0% | 0.0% |
🇬🇷 그리스 (.gr) | 6 | 0.0% | 0.0% |
독일 뉴스는 전체 데이터셋에서 88%로 가장 높은 차단률을 보인 세그먼트이며, 88%가 명시적 차단입니다. 상위 1만 개에서 AI 학습 크롤러를 아카이브에 접근시키는 독일 뉴스 사이트는 사실상 없습니다. 이 집단은 Spiegel, Bild, Welt, Zeit, FAZ, Süddeutsche, Heise, Golem, Stern, Focus가 주도하며, 기술 매체까지 독자적으로 규칙을 작성했습니다. 배경 인프라가 촘촘합니다. VG Media(독일 퍼블리셔 집단 저작권 단체)는 EU AI 저작권 소송에서 가장 공격적인 원고 집단이었고, EU 지침의 Article 4는 독일법에서 §44b UrhG로 구현되며 기계 판독 가능한 opt-out 문구를 명시합니다. AI 벤더가 등장했을 때, 독일 퍼블리셔들은 robots.txt 규칙으로 이 법적 입장을 옮길 준비가 어느 국가보다 잘 되어 있었습니다.
프랑스 뉴스 80%는 그 바로 아래입니다. 법적 환경이 비슷합니다(EU 지침 2019/790이 프랑스법으로 전환됨). 집단 행동도 비슷합니다. lemonde.fr, lefigaro.fr, liberation.fr, lequipe.fr, 20minutes.fr, ouest-france.fr가 모두 차단하며, Le Monde 파일은 프랑스의 droit du producteur de base de données(지식재산권법 Article L 342-1)을 병행적 국내 법적 근거로 추가 언급합니다. 프랑스는 2024년 파리 상사법원의 판결이라는 추가 요소가 있습니다. 이 판결은 Article 4 하에서 robots.txt 기반 opt-out이 충분한 통지라고 보았습니다. 다른 어떤 관할도 아직 맞추지 못한 직접적 판례 근거입니다.
영국의 67%는 더 낮습니다. 이유는 몇몇 주요 영국 퍼블리셔(thesun.co.uk, dailymail.co.uk, mirror.co.uk)가 AI 전용 규칙이 아니라 User-agent: * 전면 거부 블록을 사용하기 때문입니다. 그래서 명시적 수치가 53%로 낮아집니다. 총효과는 같습니다. 이 사이트들은 AI 크롤링을 허용하지 않습니다. 다만 정책 표현이 이름 붙은 AI 봇에 대한 Disallow가 아니라 "이 특정 검색엔진 화이트리스트를 제외한 모든 봇 금지"입니다. 법적 기반도 더 약합니다. 브렉시트 이후 영국은 Article 4 논리를 물려받았지만, 대응하는 국내 판례는 훨씬 적습니다.
러시아 뉴스 0%는 가장 놀라운 행입니다. 표본의 러시아 도메인 뉴스 사이트 13개(dzen.ru, rbc.ru, ria.ru, kommersant.ru, tass.ru, lenta.ru, gazeta.ru, interfax.ru, kp.ru, tass.com 등) 중 어느 곳도 AI 크롤러를 차단하지 않았습니다. 가능한 설명은 다음과 같습니다. 러시아어 LLM 학습은 주로 Yandex의 자체 GPT 계열 모델이 주도하며(이들은 Common Crawl이 아니라 Yandex 내부 크롤러를 사용), 러시아 저작권 환경에는 Article 4에 대응하는 체계가 없고, 주요 러시아 퍼블리셔들은 서구 LLM을 큰 문제로 보지 않습니다(미국의 수출 통제로 OpenAI/Anthropic 서비스는 이미 러시아에서 제한됨). 반면 Yandex는 적대자가 아니라 국내 이해관계자로 인식됩니다. 정책 자세가 본질적으로 다릅니다.
**일본 뉴스 25%**는 세 번째 패턴입니다. 일본은 국내 저작권법에 명시적인 텍스트·데이터 마이닝 예외가 있습니다(2018년 개정된 일본 저작권법 제30-4조). 이는 EU 지침 Article 4보다 더 허용적입니다. AI 학습을 포함한 "비향유 목적"의 TDM을 권리자 동의 없이 허용합니다. 일본 퍼블리셔는 opt-out에 대한 법적 근거가 상대적으로 약하고, 따라서 robots.txt 차단률도 더 낮습니다. 차단하는 25%는 대체로 가장 크고 국제 지향적인 퍼블리셔(asahi.com, nikkei.com)입니다.
국가별 뉴스 데이터는 기술이나 산업 경제보다 법제도가 AI 차단의 핵심 동인이라는 점을 보고서에서 가장 명확하게 보여 줍니다. EU 뉴스 집단은 54%~88% 사이에 모이고, EU 외 뉴스 집단(러시아, 일본, 글로벌 .com 집단)은 0%~45% 범위입니다. 88%의 최고치는 Article 4 구현이 가장 발달한 국가에 있고, 0%의 최저치는 사실상 AI 정책 법제가 없는 국가에 있습니다.
발견 7 — EU 대 나머지: 16포인트 격차
국가 관점을 한 단계 끌어올리면, EU와 비EU의 큰 구분은 분명합니다.
| 지역 | n | AI 차단 | 명시적 |
|---|---|---|---|
EU ccTLD (.fr, .de, .es, .it, .nl, .pl, .se, .dk, .fi, .be, .at, .cz, .hu, .ro, .gr, .pt, .ie, .sk, .bg) | 617 | 35.2% | 33.9% |
비EU 국가 ccTLD (.uk, .jp, .kr, .cn, .ru, .br, .in, .au, .mx, .ca, .tr, .ar, .cl, .co, .pe) | 897 | 17.2% | 13.6% |
글로벌 (.com, .net, .org 등) | 5,734 | 19.2% | 15.7% |
EU ccTLD 사이트는 비EU 국가 집단의 두 배, 글로벌 .com 기준선의 거의 두 배 비율로 AI를 차단합니다. 이 차이는 EU 회원국 전반에서 일관되고(어느 한 국가가 평균을 좌우하지 않음), 업종 전반에서도 일관됩니다(.de 뉴스 88%, .de SaaS 약 12%, .de 이커머스 약 25% — 모두 글로벌 대응군보다 높음).
상위 1만 개 중 275개 robots.txt 파일이 주석에서 Directive 2019/790을 명시적으로 인용했습니다. 이는 파싱 가능한 표본의 약 3.8%입니다. 집단은 EU 퍼블리셔가 주도하지만 그 범위를 넘습니다. 몇몇 미국 뉴스 브랜드(특히 NYT는 "EU Directive의 Art. 4"를 직접 인용), 일부 영국 사이트, 그리고 몇몇 대형 유럽 이커머스 사이트도 이 법적 문구를 재현합니다. 87개 파일은 "TDM" 또는 "text and data mining"을 이름으로 언급합니다. 460개 파일은 특정 법률을 인용하지 않더라도 어떤 형태로든 저작권 유보 문구("명시적 opt-out", "all rights reserved", "no commercial use", "no machine learning")를 포함합니다.
이 구간에서 나온 두 가지 더 세부적인 관찰:
EU 효과는 뉴스에만 있는 것이 아닙니다. 뉴스를 고정하면, EU 비뉴스 사이트도 비EU 비뉴스 사이트보다 더 높은 비율로 AI를 차단합니다(대략 28% vs 14%). EU의 소규모지만 실제 있는 SaaS, 이커머스, 학술 사이트 일부가 Article 4 프레임을 자기 업종에 내재화했습니다.
EU식 문구는 EU 밖에서도 사실상의 템플릿이 되고 있습니다. 전 세계적으로 채택되는 Cloudflare Managed robots.txt 템플릿은 보일러플레이트에 "ARTICLE 4 OF THE EUROPEAN UNION DIRECTIVE 2019/790"를 명시적으로 인용합니다. 미국 사이트가 Cloudflare의 "Block AI Bots" 설정을 켜면, 자기도 모르게 EU 법적 권리 유보를 주장하는 셈입니다. 이것은 우리가 발견한 가장 흥미로운 정책 확산 사례 중 하나입니다. 유럽의 법 개념이 미국 인프라 제공업체의 제품 UI를 통해 세계화되고 있기 때문입니다.
발견 8 — 템플릿과 템플릿 출처
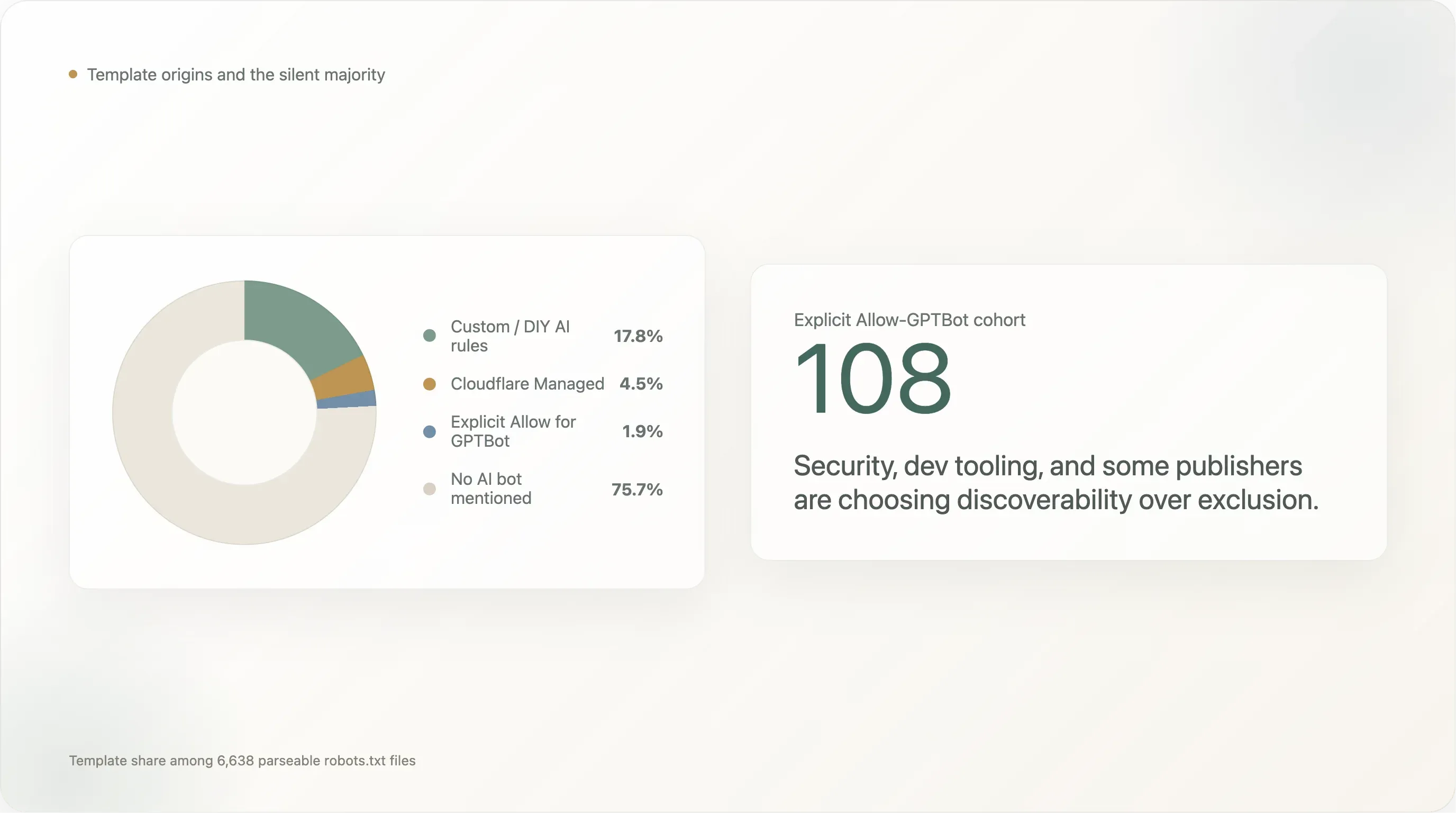
파싱 가능한 robots.txt를 반환한 6,638개 사이트의 템플릿 출처 분포:
This paragraph contains content that cannot be parsed and has been skipped.
DIY 규칙이 17.8%로 지배적입니다. 자체 작성 차단 사이트 집단은 모든 소셜 미디어 플랫폼(facebook.com, twitter.com, linkedin.com, whatsapp.com, tiktok.com, snapchat.com, pinterest.com, x.com, chatgpt.com 자체), 대형 이커머스 목적지(amazon.com, amazonvideo.com), 주요 뉴스 브랜드(nytimes.com, cnn.com, bbc.com, theguardian.com, forbes.com, reuters.com, bbc.co.uk, t-online.de, weather.com), 핵심 스트리밍/미디어(netflix.com, vimeo.com, soundcloud.com, imdb.com), 그리고 전문 서비스 사이트의 긴 꼬리(canva.com, medium.com)가 주도합니다.
**Cloudflare Managed는 4.5%**로, 곡선의 극상단보다 훨씬 높고 이 보고서 범위 밖의 긴 꼬리보다 낮습니다. 이 템플릿은 주로 1001~10000위 구간에서 채택되며(4~5%), 곡선 최상단에서는 사실상 없습니다(상위 100위: 1개, 101~1000위: 5개). 큰 글로벌 자산은 직접 작성하고, 긴 꼬리는 토글을 사용합니다.
특히 주목할 Cloudflare Managed 사이트들이 있습니다. cloudflare.com 자체가 이 템플릿을 사용합니다.(자사 도구를 자사 도메인에 사용하는 것은 일관적입니다.) theatlantic.com도 이 템플릿을 사용합니다. 우리가 찾은 주요 미국 뉴스 브랜드 중 커스텀 규칙을 쓰지 않은 유일한 사례입니다. spankbang.com도 이 템플릿을 사용합니다. Cloudflare 주입 AI 차단을 채택한 가장 높은 순위의 성인 사이트입니다. linktr.ee는 이 템플릿을 사용해 링크트리 기반 크리에이터 경제 전체에서 AI 학습을 한 번의 벤더 결정으로 차단합니다. launchpad.net, nexusmods.com, vinted.fr, cookielaw.org, rustdesk.com, 그리고 다수의 소규모 미디어 자산도 Cloudflare Managed 집단에 포함됩니다.
Cloudflare 채택 패턴은 "웹의 AI 정책" 상당 부분이 인프라 제공업체에 의해 결정되고 있음을 보여주는 가장 구체적인 증거입니다. 절대 비중은 작지만(4.5%), 구조적으로 중요합니다. 이 템플릿은 Cloudflare가 기본으로 제공하는 것이고, 다음 12개월의 기본 활성화 추세는 더 높아질 가능성이 큽니다. Cloudflare가 새 계정에 대해 이 토글을 기본 활성화로 바꾸면, 개별 퍼블리셔의 결정 없이 전 세계 차단률이 실질적으로 올라갑니다.
Squarespace 기본값(상위 1만 개에서 5개, 하지만 표본 밖에서는 훨씬 큰 집단)은 다른 패턴입니다. Squarespace는 하나의 블록에서 AI 봇 28개를 이름으로 적은 robots.txt를 배포하지만, 이 봇들은 사이트 전체 차단이 아니라 User-agent: *의 경로 제한을 상속합니다. AI 크롤러는 /, 홈페이지, 제품 페이지, 블로그를 가져올 수 있습니다. 다만 /config나 /account는 못 가져옵니다. 우리는 이전에 이를 Squarespace 사이트에 대한 제3자 스캔에서 "AI 차단" 오탐의 원인으로 지적한 바 있으며, 여기에도 같은 주의가 적용됩니다.
발견 9 — 순위 분포 전반에서 AI 정책은 거의 균일하다
이런 종류의 연구에서 흔히 떠올리는 직관은, 가장 많이 방문되는 사이트일수록 AI 정책이 가장 공격적일 것이라는 것입니다. 학습 대체 위험이 가장 크고, 법적 역량이 가장 크며, 대중의 주목도 가장 크기 때문입니다. 하지만 데이터는 그 직관을 지지하지 않습니다.
| 순위 구간 | n | AI 차단 | 명시적 | Cloudflare Managed |
|---|---|---|---|---|
| 상위 100 | 67 | 22.4% | 17.9% | 1개 사이트 |
| 상위 101~1,000 | 598 | 22.9% | 19.2% | 5개 사이트 |
| 상위 1,001~5,000 | 2,810 | 19.0% | 15.3% | 99개 사이트 |
| 상위 5,001~10,000 | 3,773 | 20.8% | 17.8% | 197개 사이트 |
네 구간은 19%~23% 사이에 있습니다. 상위 100위가 5001~10000위 긴 꼬리보다 더 공격적이지 않습니다. 헤드라인 수치는 개별 사이트의 규모나 존재감이 아니라 2026년 공개 웹의 특성으로 보입니다.
두 가지 요인이 있습니다. 첫째, 곡선의 상단은 인프라 / SaaS / 검색 / 포털 도메인(Microsoft, Apple, Google 등)으로 채워져 있고, 이들은 본래 AI 차단률이 낮습니다. 둘째, 긴 꼬리에는 지역 뉴스 퍼블리셔와 EU 관할 사이트가 많이 포함되어 있으며, 발견 6과 7에서 보았듯 이들은 글로벌 평균보다 훨씬 적극적으로 AI를 차단합니다. 이 두 효과가 대체로 상쇄되어, 결과는 균일한 헤드라인 수치가 됩니다.
Cloudflare Managed 열은 곡선 상에서 분명히 이동합니다. 상위 1000위에는 Cloudflare Managed 사이트가 6개(1.0%)이고, 상위 1001~10000위에는 296개(5.7%)입니다. 대형 사이트는 직접 작성하고, 긴 꼬리는 벤더 토글을 사용합니다. 이것이 이 데이터셋에서 유일하게 의미 있는 순위 의존 신호이며, 웹 상단에서 긴 꼬리로 내려갈수록 벤더가 설정한 AI 정책의 비중이 점점 높아진다는 점을 시사합니다. 우리는 이 기울기가 상위 1만을 넘어 상위 10만, 그 이상까지 이어질 것으로 예상합니다.
발견 10 — 다섯 가지 해부: robots.txt가 실제 정책일 때 어떤 모습인가
숫자는 데이터셋의 모양을 설명하지만, 공개 웹의 "AI 정책"의 실제 성격은 특정 파일을 읽어야 가장 잘 보입니다. 정책 스펙트럼을 가로지르는 다섯 개를 골라 보겠습니다.
해부 1 — New York Times (nytimes.com)
nytimes.com/robots.txt의 첫 14줄:
1# New York Times content is made available for your personal, non-commercial
2# use subject to our Terms of Service here:
3# https://help.nytimes.com/hc/en-us/articles/115014893428-Terms-of-Service.
4# Use of any device, tool, or process designed to data mine or scrape the content
5# using automated means is prohibited without prior written permission from
6# The New York Times Company. Prohibited uses include but are not limited to:
7# (1) text and data mining activities under Art. 4 of the EU Directive on Copyright in
8# the Digital Single Market;
9# (2) the development of any software, machine learning, artificial intelligence (AI),
10# and/or large language models (LLMs);
11# (3) creating or providing archived or cached data sets containing our content to others; and/or
12# (4) any commercial purposes.
13# Contact https://nytlicensing.com/contact/ for assistance.이것은 법적 증거물로서의 robots.txt입니다. NYT v. OpenAI 소송에서 증거로 제출될 수 있도록 구조화되어 있습니다. 미국 퍼블리셔가 "EU Directive의 Art. 4"를 언급하는 것은 발견 7에서 말한 EU 법적 프레임이 글로벌 담론으로 스며들고 있음을 보여 줍니다. "아카이브나 캐시된 데이터셋을 만들거나 제공하는 행위"를 명시적으로 금지하는 부분은 Common Crawl을 정면으로 겨냥합니다. 파일은 60줄이 넘고, GPTBot, OAI-SearchBot, ChatGPT-User, anthropic-ai, ClaudeBot, CCBot, Google-Extended, Applebot-Extended, Bytespider, Diffbot, Meta-ExternalAgent, Amazonbot, Omgili, Omgilibot 등 이름 붙은 User-agent 블록을 모두 따로 둡니다. 각각의 봇은 전부 Disallow: /를 받습니다.
해부 2 — Der Spiegel (spiegel.de) — 섹션 단위 AI 허용
Der Spiegel은 전체 데이터셋에서 가장 운영적으로 정교한 robots.txt입니다. 관련 블록:
1# TLP-6507: Testweise Freischaltung der OpenAI-Suchcrawler fuer ausgewaehlte Bereiche
2User-agent: OAI-SearchBot
3Allow: /ausland/
4Allow: /partnerschaft/
5Allow: /gesundheit/
6Allow: /familie/
7Allow: /reise/
8Allow: /psychologie/
9Allow: /stil/
10Disallow: /
11User-agent: ChatGPT-User
12Allow: /ausland/
13Allow: /partnerschaft/
14Allow: /gesundheit/
15Allow: /familie/
16Allow: /reise/
17Allow: /psychologie/
18Allow: /stil/
19Disallow: /주석은 "선택된 영역에 대해 OpenAI 검색 크롤러를 시험적으로 개방"이라는 뜻입니다. Spiegel은 OpenAI의 추론 UA에 대해 국제 뉴스, 파트너십, 건강, 가족, 여행, 심리, 라이프스타일 7개 범주만 허용하고 나머지는 모두 차단했습니다. 정치 섹션, 독일 국내 뉴스, 탐사 보도는 명시적으로 제외됩니다. Common Crawl, Bytespider, Cohere, Webzio-Extended 및 기타 학습 UA는 파일 아래쪽에서 전부 Disallow: /를 받습니다.
이것은 섹션 수준의 편집 정책으로서의 robots.txt입니다. 암묵적 이론은 라이프스타일 콘텐츠는 학습 대체 위험이 낮고 추론 인용 이득이 높다는 것이며, 그래서 Spiegel은 해당 섹션을 AI에 허용합니다. 정치 및 탐사 콘텐츠는 해자이므로 AI를 제외합니다. 우리는 이 패턴을 다른 곳에서는 보지 못했습니다. 이는 편집·법무·인프라 팀 간의 내부 조정 수준이 대부분의 뉴스룸을 넘어섰음을 시사합니다. 이런 세분화된 섹션 수준 정책은 2026~2027년에 확산될 것으로 보이며, Spiegel 파일은 사실상 선행 지표입니다.
해부 3 — BBC (bbc.com) — 정책 선언 형식
BBC의 robots.txt는 다음으로 시작합니다.
1# version: ec59bd036e5138eb4831a9ed44447b1ff310e235
2# The BBC's Terms of Use: https://www.bbc.co.uk/terms
3# - Explain the rules for using our services
4# - Tell you what you can do with our content
5#
6# In short: Please use our site like a human, not a robot.
7# That means:
8# - No scraping, crawling, or systematic extraction of content
9# - No use of BBC content for training or fine-tuning AI models, including LLMs
10# - No retrieval-augmented generation (RAG), AI-powered search, agentic AI or
11# grounding using BBC content
12# - No creating datasets from BBC content
13# - No text and data mining (TDM) under Article 4 of the EU Directive on Copyright
14# - No using BBC content to create summaries for your own use
15# - No business use without permission
16# - The BBC reserves all rights in its content and expressly opts out of any
17# statutory exceptions in any jurisdiction for text and data mining,
18# as permitted by law
19#
20# TL;DR: Browse, read, watch, enjoy - like a human.BBC는 robots.txt에 버전 문자열을 붙이고(version: ec59bd...는 git 커밋 해시), BBC 법무팀이 추적하는 8가지 AI 사용을 금지하며, 브랜드가 구축한 문체 그대로 한 줄 요약으로 끝맺습니다. "모든 관할에서 법정 예외를 명시적으로 거부한다"는 문구는 의도적인 전 세계적 권리 유보입니다. 즉 우리는 어떤 단일 법체계도 우리가 원하는 보호를 주지 않는다고 보고, 모든 곳에서 동시에 opt-out을 주장한다는 의미입니다. 데이터셋에서 가장 정교하게 작성된 robots.txt이며, 설정 파일이라기보다 보도자료에 가깝습니다.
해부 4 — WordPress.org — 명시적 환영
위와 대비되는 wordpress.org를 보겠습니다.
1User-agent: GPTBot
2Allow: /
3User-agent: ClaudeBot
4Allow: /
5User-agent: anthropic-ai
6Allow: /
7User-agent: Google-Extended
8Allow: /
9User-agent: Applebot-Extended
10Allow: /
11User-agent: PerplexityBot
12Allow: /
13User-agent: Bytespider
14Allow: /
15User-agent: CCBot
16Allow: /
17User-agent: Copilot
18Allow: /WordPress.org는 Bytespider, CCBot, anthropic-ai를 포함한 9개 AI 학습 크롤러를 명시적으로 허용합니다. 암묵적 이론은 WordPress 문서와 플러그인 생태계가 AI 어시스턴트가 이를 질문에 답할 수 있을수록 가치가 커지는 공공재라는 것입니다. 누군가 Claude에게 "WordPress에서 퍼머링크를 어떻게 설정하나요?"라고 물었을 때, Claude가 wordpress.org/documentation/으로 학습되어 있다면 WordPress의 미션은 수행된 것입니다. 재단은 모든 모델의 학습 코퍼스 안에 들어가는 것이 전략적으로 긍정적이라고 판단한 것으로 보이며, 파일의 표현 문법으로 이를 분명히 밝혔습니다.
해부 5 — The Verge (theverge.com) — 후원형 하이브리드
마지막으로 하나 더. The Verge는 AI 규칙을 Disallow: / \ Allow: /sp/ 형태로 구성합니다.
1User-agent: GPTBot
2Allow: /
3User-agent: Applebot
4Allow: /
5User-agent: Google-Extended
6Disallow: /
7Allow: /sp/
8User-agent: anthropic-ai
9Disallow: /
10Allow: /sp/
11User-agent: Bytespider
12Disallow: /
13Allow: /sp/
14User-agent: CCBot
15Disallow: /
16Allow: /sp/
17User-agent: ChatGPT-User
18Disallow: /
19Allow: /sp/
20User-agent: ClaudeBot
21Disallow: /
22Allow: /sp//sp/ 경로는 The Verge의 스폰서/파트너 콘텐츠 섹션입니다. 편집 콘텐츠는 AI 학습에서 차단하고, 후원 콘텐츠는 허용합니다. 경제 논리는 분명합니다. 스폰서는 자신의 콘텐츠가 AI를 통해서도 발견되길 원하고, 편집 플래그십은 해자입니다. GPTBot은 완전히 열려 있고(아마도 OpenAI와의 직접적 관계를 반영), Applebot은 검색 기준선으로 완전히 열려 있으며, 나머지는 하이브리드 방식입니다. 우리가 찾은 유일한 "단계적 AI 접근" 구조입니다.
이 다섯 개 파일은 현재의 robots.txt AI 정책 범위를 보여 줍니다. 상위 1만 개의 대부분은 이들 중 어느 것과도 닮지 않았습니다. 침묵이거나 벤더 템플릿을 쓰고 있습니다. 이들 중 하나와 닮은 파일은, 파일을 꼼꼼히 읽을 가치가 있다고 판단한 사람들이 작성한 것입니다.
파일 규모에 대한 메모: 표본의 robots.txt 본문 중앙값은 858바이트로, 의미 있는 AI 정책을 담기에는 너무 작습니다. 실제 규칙은 오른쪽 꼬리에 있습니다. 1,005개 사이트(15.3%)가 5KB보다 큰 파일을 갖고 있고, 273개는 20KB보다 크며, 최대치는 248KB였습니다. 460개 파일은 저작권 유보 문구를 포함하고, 275개는 EU 2019/790을 명시적으로 인용했습니다. 2026년의 robots.txt는 점점 버전 관리되고 변호사 검토를 거친 문서가 되고 있으며, 단순 설정 줄이 아닙니다.
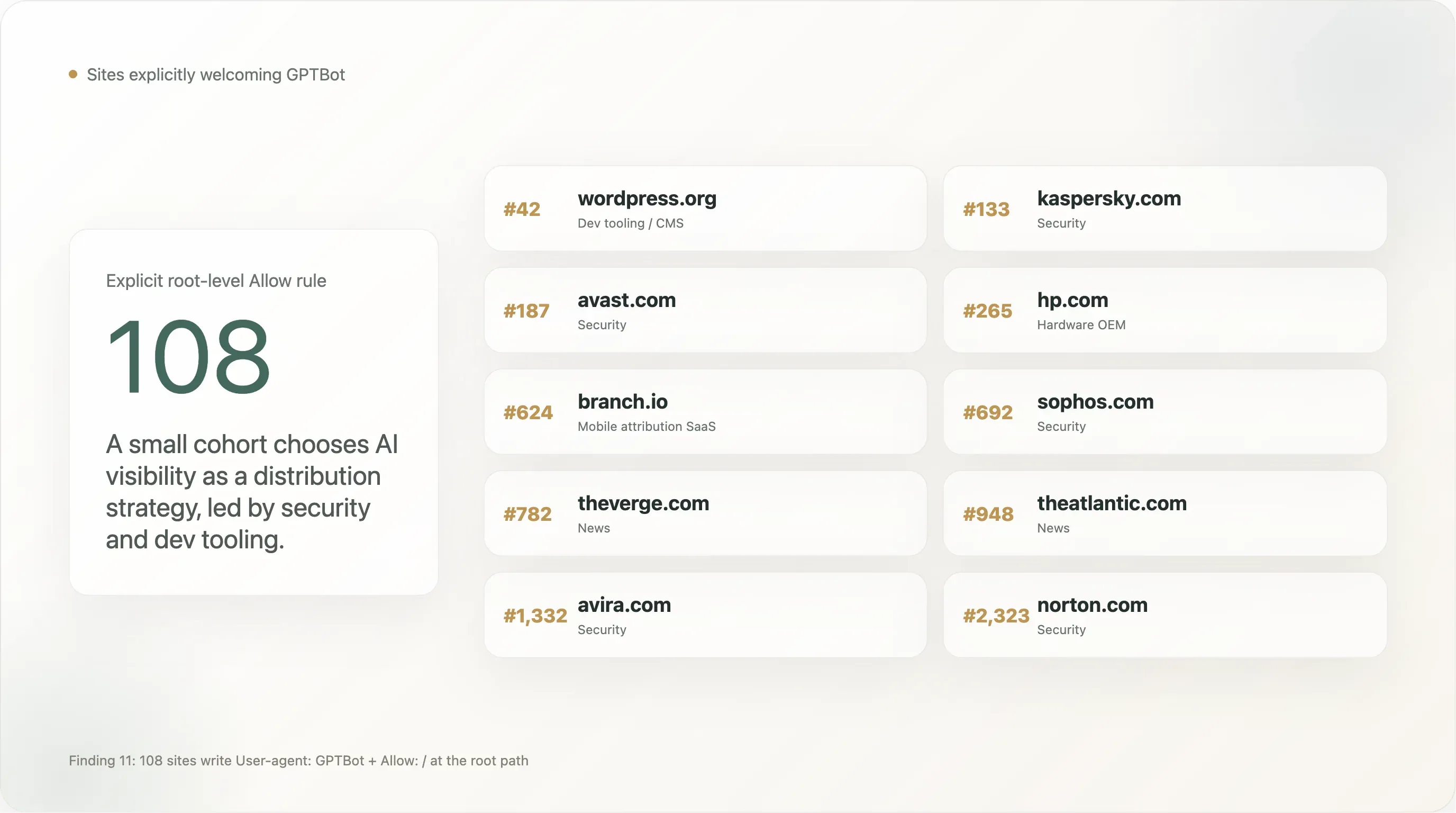
발견 11 — 108개 사이트가 GPTBot을 명시적으로 환영한다
작지만 눈에 띄는 집단은 User-agent: GPTBot \n Allow: / 규칙을 작성합니다. 많이 논의되는 "GPTBot 차단"의 반대입니다. 표본에서 root 경로 기준 GPTBot을 명시적으로 허용하는 사이트는 108개입니다. Tranco 순위 상위 25개는 다음과 같습니다.
| 순위 | 도메인 | 업종 |
|---|---|---|
| 42 | wordpress.org | 개발 도구 / CMS |
| 133 | kaspersky.com | 보안 |
| 187 | avast.com | 보안 |
| 265 | hp.com | 하드웨어 OEM |
| 624 | branch.io | 모바일 어트리뷰션 SaaS |
| 692 | sophos.com | 보안 |
| 782 | theverge.com | 뉴스 |
| 905 | rambler.ru | 러시아 포털 |
| 945 | kleinanzeigen.de | 독일 마켓플레이스 |
| 948 | theatlantic.com | 뉴스 |
| 1,092 | lge.com | LG전자 |
| 1,300 | justdial.com | 인도 로컬 검색 |
| 1,332 | avira.com | 보안 |
| 1,412 | youm7.com | 이집트 뉴스 |
| 1,530 | goodreturns.in | 인도 금융 |
| 1,621 | publi24.ro | 루마니아 분류 광고 |
| 1,807 | geocomply.com | 컴플라이언스 SaaS |
| 1,908 | nba.com | 스포츠 |
| 1,956 | oneindia.com | 인도 뉴스 |
| 1,974 | mindbox.ru | 러시아 SaaS |
| 2,009 | thesun.co.uk | 뉴스 |
| 2,126 | vox.com | 뉴스 |
| 2,140 | mgid.com | 네이티브 광고 |
| 2,314 | ninjarmm.com | IT 관리 SaaS |
| 2,323 | norton.com | 보안 |
몇 가지 패턴이 보입니다.
보안 회사의 비중이 눈에 띄게 높습니다. Kaspersky, Avast, Sophos, Avira, Norton, NinjaRMM이 모두 GPTBot을 명시적으로 허용합니다. 이것은 분명한 유통 전략입니다. 사용자가 ChatGPT에 *"내 Windows PC에 가장 좋은 백신은 뭐야?"*라고 물을 때, 브랜드가 모델 학습 코퍼스 안에 들어 있으면 추천 결과에 직접 영향을 줍니다. 보안은 AI 검색이 이미 SEO를 대체하는 몇 안 되는 B2C 제품 카테고리 중 하나이며, 이 브랜드들이 먼저 움직였습니다. 우리는 나머지 보안 업종도 12개월 안에 따라올 것으로 봅니다.
주요 뉴스 브랜드 일부가 차단 목록이 아니라 이 목록에 있습니다. The Verge, The Atlantic, Vox, The Sun, NBA.com. 모순이 아닙니다. 이 퍼블리셔들은 ChatGPT 검색 안에서 인용될 수 있는 것이 학습으로부터 보호받는 것보다 더 가치 있다고 판단했을 가능성이 높습니다. 그리고 CDN이나 CMS가 앞으로 과도하게 차단하는 상황을 막기 위해 명시적 Allow 규칙을 썼습니다. NYT / Reuters / BBC / Forbes / Guardian의 명시적 Disallow와 대비해 보십시오. 둘 다 충분히 합리적입니다. 뉴스 업계는 단일하지 않습니다.
The Sun의 존재는 특히 눈에 띕니다. 같은 사이트가 파일의 다른 곳에서는 User-agent: * 전면 거부를 사용하기 때문입니다. The Sun의 정책은 가장 잘 이렇게 읽힙니다. AI 학습은 금지하지만 AI 검색은 허용하며, ChatGPT가 The Sun을 인용해 답변할 수 있도록 전면 거부 예외로 GPTBot을 명시적으로 화이트리스트에 올린다. 이것은 GPTBot-허용 규칙 가운데 가장 법적으로 정교한 형태입니다. opt-out과 단일 벤더 opt-in이 함께 들어 있습니다.
WordPress.org의 존재는 목록에서 가장 중요한 단일 항목입니다. 글로벌 오픈소스 CMS 생태계의 상당수가 WordPress.org 문서를 참조하거나 거기서 플러그인을 호스팅합니다. WordPress Foundation은 wordpress.org/robots.txt에서 GPTBot을 명시적으로 허용함으로써 사실상 WordPress 문서 생태계가 학습에 개방되어 있다고 선언한 셈이며, 이는 Claude, Gemini, ChatGPT가 WordPress에 관한 "어떻게 하나요?" 질문에 더 잘 답할 수 있게 만드는 파급 효과를 갖습니다.
나머지 83개 사이트는 지역 뉴스, 중소 보안 벤더, 비영어권 시장의 분류 광고 플랫폼, B2B SaaS의 긴 꼬리입니다. 우리가 보기에는 업계 전체 차원의 "Allow GPTBot" 조율은 없습니다. 이 규칙은 각 운영자가 코퍼스 안에 들어가는 것이 전략적으로 유리하다고 판단할 때 하나씩 채택되고 있습니다.
발견 12 — llms.txt는 이 규모에서는 거의 소문 수준이다
LLM 친화적 콘텐츠 탐색을 위한 대안 파일 형식으로 제안된 llms.txt는(2024년 말부터 Mintlify, Anthropic, Vercel, 그리고 일부 개발 도구 벤더가 추진) 우리 표본에서는 거의 보이지 않습니다.
파싱 가능한 robots.txt를 반환한 6,638개 사이트 중 83개(1.15%)만 llms.txt를 언급합니다. 보통은 Sitemap: https://example.com/llms.txt 같은 행입니다. 이는 Vercel과 Mintlify 기본값이 채택률을 부풀리는 개발 도구 중심 상거래 표본에서 측정한 같은 지표보다 두 자릿수 낮습니다.
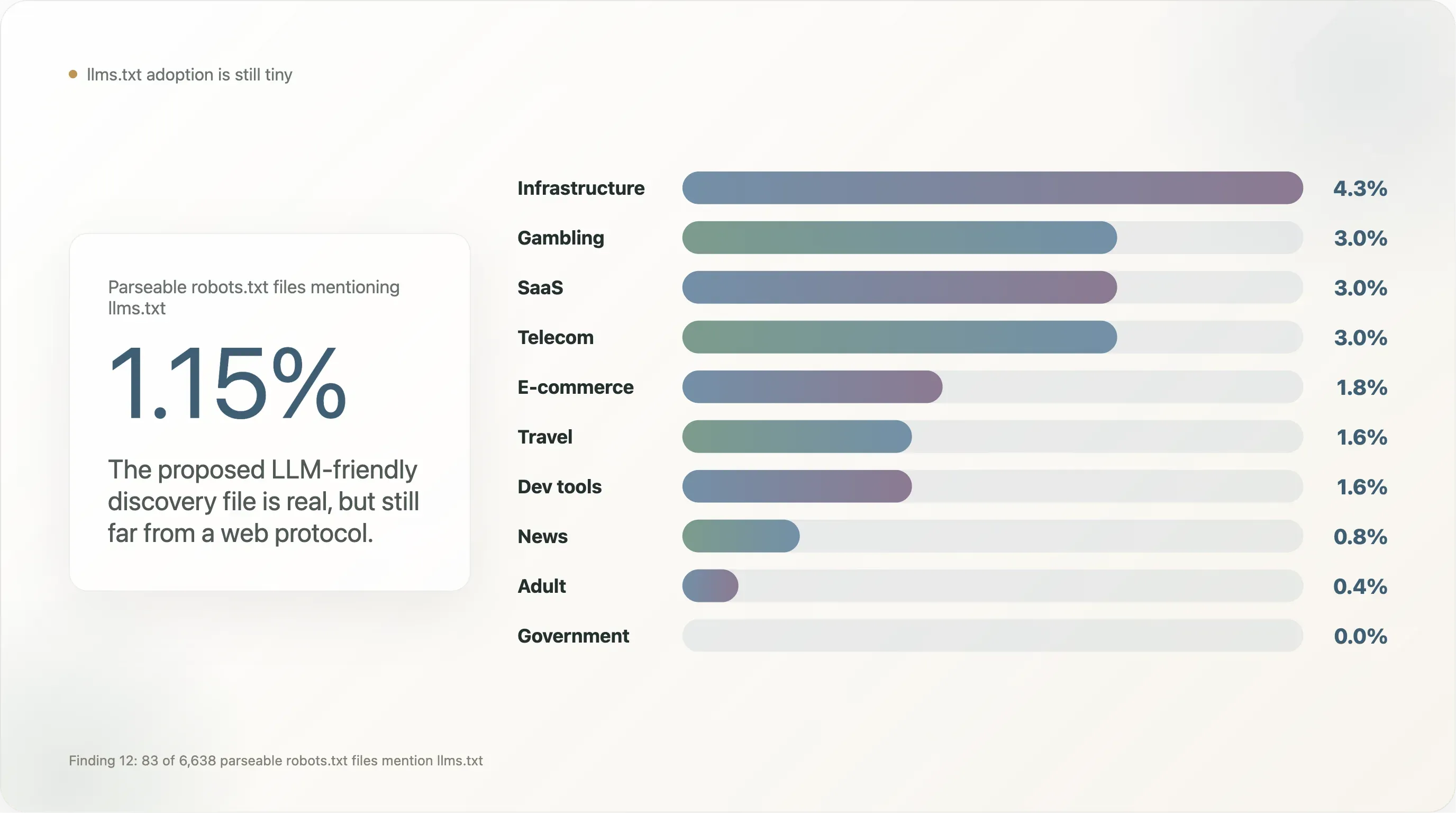
업종별 분포:
| 업종 | n | llms.txt 언급 비율 |
|---|---|---|
| 인프라 | 47 | 4.3% |
| 도박 | 100 | 3.0% |
| SaaS | 369 | 3.0% |
| 통신 | 33 | 3.0% |
| 이커머스 | 224 | 1.8% |
| 여행 | 64 | 1.6% |
| 개발 도구 | 129 | 1.6% |
| 뉴스 | 650 | 0.8% |
| 성인 | 254 | 0.4% |
| 정부 | 172 | 0.0% |
| 학술 | 268 | 0.0% |
| 검색 | 12 | 0.0% |
llms.txt는 개발 도구와 가까운 SaaS, 새 용어의 robots.txt 기능을 다른 규제 업종보다 빠르게 채택하는 도박 업종(규정 준수 팀이 추가 메타데이터를 겹겹이 얹는 데 익숙하기 때문), 그리고 B2B 이커머스에 집중되어 있습니다. 뉴스와 정부에서는 눈에 띄게 드뭅니다. 이 둘은 AI 정책에 가장 적극적으로 관여하는 세그먼트이자, 표준이 "벤더 실험"에서 "웹 프로토콜"로 승격하려면 반드시 채택해야 할 영역입니다. 그때까지 llms.txt는 실재하지만 작고, 2026년 말 후속 점검은 유용한 재검증이 될 것입니다.
llms.txt가 직면한 구조적 문제는 IETF 프로세스로 표준화되지 않았고, 주요 AI 벤더들도 이를 준수하겠다고 약속하지 않았다는 점입니다. robots.txt는 30년짜리 크롤러 인프라가 뒷받침하지만, llms.txt는 그렇지 않습니다. 적어도 한 주요 벤더(OpenAI, Anthropic, Google, Cloudflare)가 공식 지원을 선언하기 전까지는 사실상 Mintlify / Vercel 생태계의 마케팅 산출물에 가깝습니다. 2026년 안에 이 상황이 바뀔 것으로는 보지 않습니다.
발견 13 — 접근성: robots.txt는 여전히 상위 웹의 3분의 2에서 읽을 수 있다
원래는 발견으로 삼을 생각이 없던 부수적 관찰 하나: 상위 1만 개 사이트의 66%가 단일 연구 IP에 대해 파싱 가능한 robots.txt를 반환했고, 10,000개 중 7개(0.07%)만 429 Too Many Requests를 반환했습니다. 이는 robots.txt가 공개 프로토콜이라는 점에 좋은 소식입니다.
비교하자면, 두 달 전 같은 파이프라인을 1,008개 도메인의 중간 시장 상거래 표본에 돌렸을 때는 해석 가능한 도메인의 52%에서 429를 받았습니다. Shopify와 Cloudflare CDN이 주요 검색엔진이 아닌 UA를 강하게 속도 제한한 것입니다. 상위 트래픽 웹은 훨씬 친절합니다. 상위 사이트는 (a) 봇 관리 단계가 덜 공격적이거나, (b) 알려진 연구 크롤러용 명시적 허용 목록이 있거나, 또는 둘 다인 경우가 많습니다.
상위 1만 개에서 21%의 fetch_failed는 대부분 /에서 웹서버를 운영하지 않는 CDN 최상위 도메인(akamai.net, cloudfront.net, fastly.net, apple-dns.net, gtld-servers.net)이 차지합니다. 이들은 우리를 막은 것이 아니라 제공할 것이 없을 뿐입니다. 이를 제외하면 실제로 "읽으려 했지만 실패한" 비율은 한 자릿수 초반입니다.
즉, 이 보고서의 향후 버전 — 분기별 스냅샷, 전년 대비 비교 — 은 단일 머신에서도 저렴하고 재현 가능하게 실행할 수 있습니다. 감사 가능성은 곡선 상단에서 계속 열려 있습니다. 비대칭 사례는 긴 꼬리와 상거래 세그먼트로, CDN 수준의 속도 제한이 사실상 robots.txt를 이미 사유화하고 있습니다. 이 분리는 더 심해질 것으로 보입니다. 상위 사이트는 검색엔진이 읽을 수 있기를 요구하기 때문에 계속 읽을 수 있는 상태로 남고, 긴 꼬리 상거래는 Cloudflare의 봇 전쟁 계층이 더 강력해질수록 덜 읽히게 될 것입니다. robots.txt의 공개 감사 가능성은 "눈에 보이는 웹"과 "운영적으로 보호된 웹"을 가르는 선을 따라 양분되고 있습니다.
IV. 이 모든 것이 의미하는 바
데이터가 가장 강하게 뒷받침하는 순서대로 네 가지 주장입니다.
1. 인터넷에는 전역 AI 정책이 아니라 업종별 AI 정책이 있습니다. 뉴스와 통신 사이의 12배 격차가 모든 집계 수치를 압도합니다. 업종별 분해 없이 "웹의 X%가 AI를 차단한다"고 말하면 SaaS/정부/개발을 과대평가하고 뉴스/여행/소셜을 과소평가하게 됩니다. 업종별 보고만이 정직한 프레이밍입니다.
2. EU 저작권 지침의 Article 4가 수치를 실제로 움직이는 유일한 법제도입니다. EU ccTLD 사이트는 35%로, 글로벌 19% 기준선의 두 배 가까이 AI를 차단합니다. 미국의 소송(NYT 대 OpenAI, 2025년 1월 저작권청 보고서)은 미국 뉴스 집단에는 영향을 주었지만 미국 전체 웹에는 그렇지 않았습니다. EU의 프레임은 Cloudflare 템플릿을 통해 전 세계로 누출되고 있으며, 이 템플릿은 고객 관할과 무관하게 보일러플레이트에 Directive 2019/790을 인용합니다.
3. 서로 평행한 두 개의 "AI 정책"이 존재하고, 서로 합의하지 않습니다. 의도적으로 손수 작성한 정책(17.8%, 주로 뉴스/소셜/여행/이커머스)과 상속된 Cloudflare 관리 정책(4.5%)은 내용은 비슷하지만 정당성은 다릅니다. AI 운영자들이 robots.txt를 무시하는 데 법적 근거를 찾고 있는 세계에서, *"우리가 직접 작성하고 검토했다"*는 방어는 *"그냥 토글만 켰다"*보다 구조적으로 더 강합니다. 소송의 유인은 두 번째 범주의 정책을 첫 번째로 끌어올리는 것입니다.
4. 퍼블리셔가 차단하는 것은 모델이 아니라 코퍼스입니다. CCBot의 16.3%는 어떤 모델 브랜드 봇보다 높으며, 이것이 가장 명확한 증거입니다. OpenAI만 막는다고 학습 대상에서 빠지는 것이 아니고, CCBot을 막아야 빠집니다. 상위 1만 개 웹의 14.1%가 Googlebot은 허용하면서 CCBot은 차단합니다. "학습은 차단, 검색은 유지" 패턴이 2026년의 대표적 AI 규칙입니다.
자신의 정책을 고민하는 사이트를 위해: 가장 흔한 자세는 침묵입니다. 상위 1만 개의 80%는 AI에 대해 아무 말도 하지 않습니다. 규칙을 작성한 17%는 Disallow에 몰려 있지만, 소수지만 증가하는 집단(보안 벤더가 주도하는 1.5%의 명시적 Allow-GPTBot 목록)은 반대로 공개적 허용을 택하고 있습니다. 업계 합의는 없고, 향후 12개월 내에도 생기지 않을 것입니다.
AI 운영자를 위해: robots.txt가 오래된 프로토콜이고 의미가 애매하다고 계속 주장하기는 점점 어려워지고 있습니다. 세계 최대 사이트의 17%가 봇 이름을 손수 적은 명시적 규칙을 작성했고, 파일의 3.8%가 특정 EU 법률 조문 번호를 인용하기 때문입니다. 그 규칙을 존중할지 여부는 비즈니스 결정이지만, 그 규칙이 존재하는지는 이제 실증적 사실입니다.
V. 전망: 2026년 말까지 예상되는 변화
데이터셋에서 보이는 세 가지 추세:
Cloudflare Managed는 비중이 두 배 이상으로 늘어날 것이며, 파싱 가능한 상위 1만 개의 10% 이상에 도달할 가능성이 있습니다. Cloudflare의 로드맵은 새 계정에 대해 Block AI Bots를 기본 활성화하는 방향을 공개적으로 논의하고 있습니다. 토글이 기본 활성화로 배포되면, 개별 퍼블리셔의 의사결정 없이 전 세계 차단률이 5~8포인트 상승합니다. 상위 5001~10000위 구간의 Cloudflare Managed 비중이 현재 5.7%를 넘으면 실제로 이런 변화가 진행 중이라는 것을 알 수 있습니다.
섹션 수준 AI 정책(Spiegel식)은 주요 뉴스 플래그십들 사이에서 확산될 것입니다. 경제 논리 — 위험도가 낮은 콘텐츠는 AI가 인용하게 두고, 해자 콘텐츠는 보호한다 — 가 충분히 설득력 있어, 2026년 말까지 최소 10개 이상의 플래그십 뉴스룸이 섹션 수준 규칙을 배포할 것으로 예상합니다. 먼저 독일과 프랑스의 중간급 언론을 보십시오. 법적 구조가 그곳에서 실험을 더 잘 보상합니다.
명시적 Allow: /-GPTBot 집단은 B2B SaaS와 개발 도구가 주도하며 성장할 것입니다. 보안 업계에서 이미 그렇듯, 소프트웨어 벤더에 대한 AI 검색이 측정 가능한 획득 채널이 되면, 마케팅 책임자는 우발적 과차단을 막기 위해 User-agent: GPTBot \n Allow: /를 작성할 것입니다. 108개 사이트 목록은 연말까지 대략 두 배로 늘어날 것으로 예상합니다.
우리가 기대하지 않는 것: 침묵하는 다수의 비중이 크게 바뀌는 것. AI에 대해 아무 말도 하지 않는 웹의 80%에는 규칙을 쓸 경제적 이유도 없고 법적 압박도 없는 업종(gov, telecom, infrastructure, B2B SaaS)이 포함됩니다. 전 세계적 AI 정책은 오지 않습니다.
VI. 한계
- 한 번의 스냅샷 편향. 수집은 2026년 5월 초 36시간 창에서 이뤄졌습니다. 상위 100개는 매일 파일이 바뀌므로, 헤드라인 수치는 분기당 1~2포인트 정도 흔들릴 수 있습니다.
- 산업 분류의 공백. 4단계 분류기 후에도 10,000개 중 6,593개가
unknown으로 남았습니다. 업종별 비율은 n이 큰 곳에서는 견고합니다(news: 650, streaming: 440, saas: 369, academia: 268, adult: 254, ecommerce: 224, gov: 172, finance: 129, dev: 129). n=30 미만에서는 더 노이즈가 큽니다. 국가별 뉴스 분해도 마찬가지입니다. DE/FR/UK는 n≥15이지만, 한국/스웨덴/체코는 n=20~25에 의존합니다. robots.txt는 자발적입니다.Disallow는 장벽이 아니라 요청입니다.Bytespider,PerplexityBot등은 규칙을 무시한 사례가 문서화되어 있습니다. 우리는 정책 집행이 아니라 정책 선언을 측정했습니다.- 단일 IP, 미국 기반 감사. 21%의 해석 가능한 도메인을 읽지 못했습니다. 대부분은 웹서버가 없는 CDN 최상위 도메인이고, 일부는 오리진에 도달하기 전에 CDN이 우리를 차단한 사이트입니다. 이는 표본을 약간 오래된 인프라 쪽으로, 그리고 국가별 지오펜스 사이트 쪽으로 다소 치우치게 만듭니다.
- Tranco 목록의 의미. Tranco는 안정성 기준으로 필터링합니다. 진짜 사용자 행동 순위가 아닙니다. 집계 수치는 목록 선택에 견고하지만, 개별 순위 위치는 그렇지 않습니다.
- 트래픽 데이터 부재.
robots.txt정책만 측정했으며, 실제 AI 봇 처리량은 측정하지 않았습니다. 정책과 트래픽은 항상 일치하지 않습니다.
VII. 재현 방법
이 보고서 제작에 사용한 모든 것은 납품 폴더에 들어 있습니다.
- tranco_top10k.csv — 입력 목록
- out/sites.csv — 도메인 × 순위 × 업종 × 언어 × robots.txt 상태(10,000행)
- out/fetch_meta.csv — 도메인별 수집 결과(상태, 스킴, 바이트, 오류)
- out/bot_status.csv — 도메인 × 봇 그리드(250,000행: blocked, has_rule, fetch_status)
- out/site_meta.csv — 사이트당 분석 레코드 1개(템플릿, 요약 불리언)
- out/analysis.json — 보고서에서 인용한 모든 지표
- 01_fetch_robots.py, 02_classify.py, 03_parse_and_analyze.py — 전체 Python 파이프라인
방법론 수정, 데이터셋 이슈, 후속 분석 제안은 support@thunderbit.com *으로 보내 주세요. 이 보고서는 Thunderbit이 보유한 어떤 상업적 입장과도 무관하게 발행되었습니다. 우리는 AI 기반 웹 스크래퍼를 만들고 있으며, 공개 웹에서 robots.txt가 여전히 의미 있는 기계 판독 가능한 계약으로 남아 있는 데 구조적 이해관계가 있습니다. 이 보고서의 데이터는 그 자체로 독립적입니다. — Thunderbit 연구팀, 2026년 5월.