「欲しい情報がなかなか見つからず、何度もリンクをクリックしてやっと目的のデータにたどり着いた…」そんな経験、みんな一度はあるんじゃないでしょうか?最近は多くのウェブサイトが大事な情報をサブページに分散して載せているので、データ集めがどんどん面倒になっています。エンジニアなら複雑なスクリプトを書いて対応できますが、プログラミングが苦手な人は一つ一つ手作業でリンクをたどるしかありません。そんな悩みを一気に解決してくれるのがリストクロール(バルクスクレイピングとも呼ばれます)やサブページスクレイピングです。
リストクロールとサブページスクレイピングの違いをざっくり比較
| ツール | 使いやすさ | データ品質 | おすすめ用途 |
|---|---|---|---|
| リストクロール | ★★ | ★★★ | 大規模サイト向け |
| サブページスクレイピング | ★★★★★ | ★★★★ | 軽めのスクレイピングや特定フォーマットのデータ取得 |
リストクロールとは?
リストクロールの概要
リストクロール(バルクスクレイピング)は、URLのリストをもとに大量のウェブページから一気にデータを集める方法です。まずはターゲットとなるURLリストを用意するのがポイントで、そのリストの質が結果を大きく左右します。URLごとにページの構造が違う場合は、データの整理や整形にちょっと手間がかかることも。主にビジネスやリサーチ、データ分析など、構造化された大量データを効率よく集めたいときに大活躍。ただし、集めたデータは手作業でクリーニングや整理が必要になることも多いです。
リストクロールの流れ

リストクロールの基本的な流れはこんな感じです:
- URLリストの準備:ターゲットとなるウェブページのURLをリストアップ。
- HTTPリクエスト送信:各URLにアクセスしてHTMLデータを取得。
- データ抽出:BeautifulSoupやXPath、正規表現などを使って、テキストや画像、リンクなど必要な情報を抜き出します。
- データ保存:抽出したデータをデータベースやスプレッドシートに整理して保存。
データを集めた後は、記述統計や時系列分析、相関分析、クラスタリングなどでデータを整理・分析します。AIを活用すれば、こうした作業も自動化できて、データの質もグッと上がります。
ThunderbitのAIウェブスクレイパーなら、バルクスクレイピング機能でさらにスムーズに作業できます。
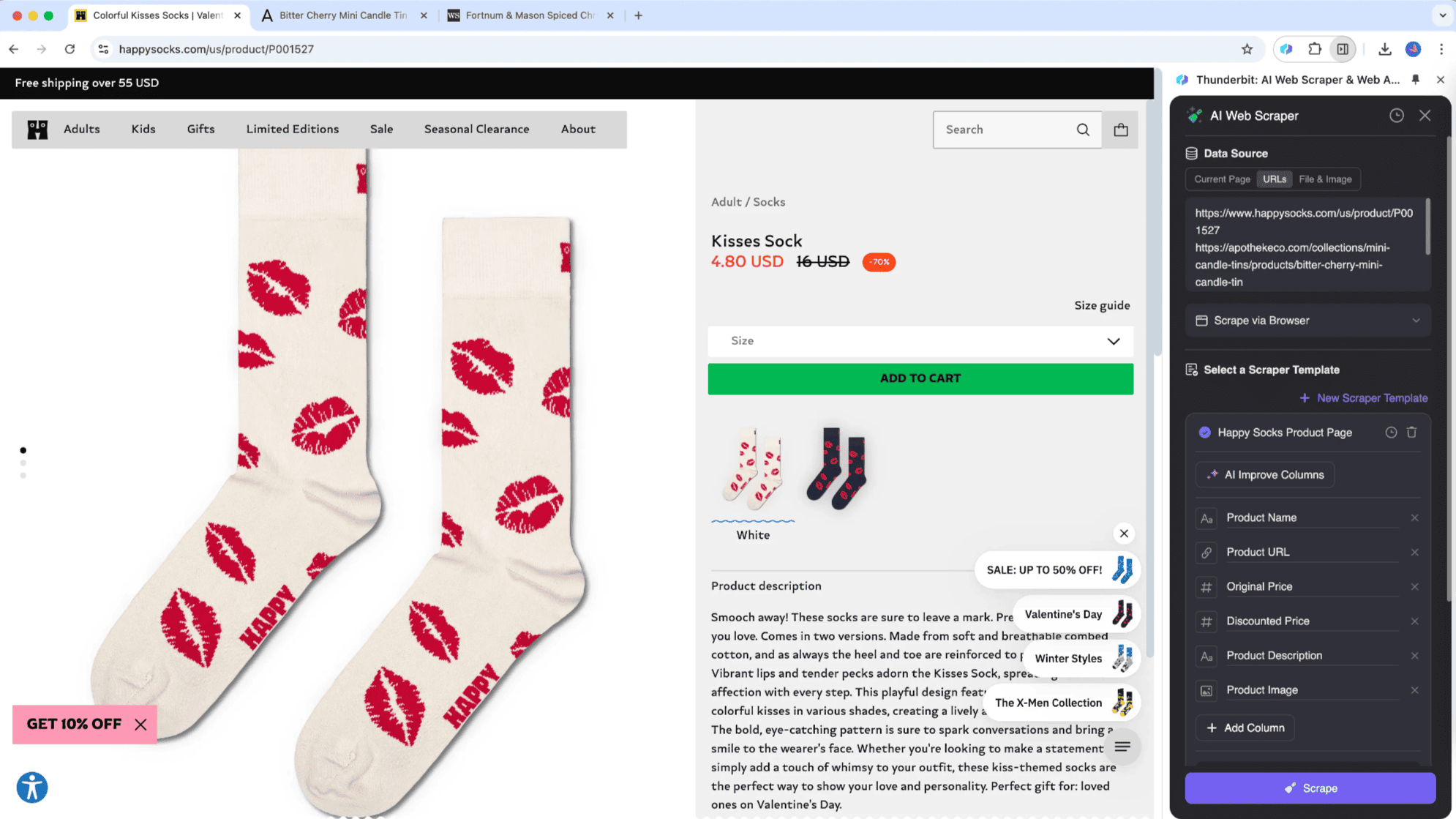
おすすめツール
-
- メリット:直感的な操作、柔軟なパース機能、パワフルな機能が揃っている
- デメリット:ローカル環境やブラウザ依存が必要な場合あり
- 最適な用途:データの質を重視した高品質なデータ収集
- Scrapy
- メリット:カスタマイズ性が高く、大規模なスクレイピングに強い
- デメリット:学習コストが高く、プログラミング知識が必須
- 最適な用途:大規模なデータ収集プロジェクト
- Beautiful Soup
- メリット:使いやすく、ドキュメントも豊富で柔軟なパースが可能
- デメリット:パフォーマンスは普通、非同期処理には非対応
- 最適な用途:小規模なスクレイピングやデータ分析
- Selenium
- メリット:動的ページにも対応、ユーザー操作のシミュレーションができる
- デメリット:動作が遅く、リソース消費が大きい
- 最適な用途:JavaScriptで生成されるページのデータ取得
サブページスクレイピングとは?

サブページスクレイピングの概要
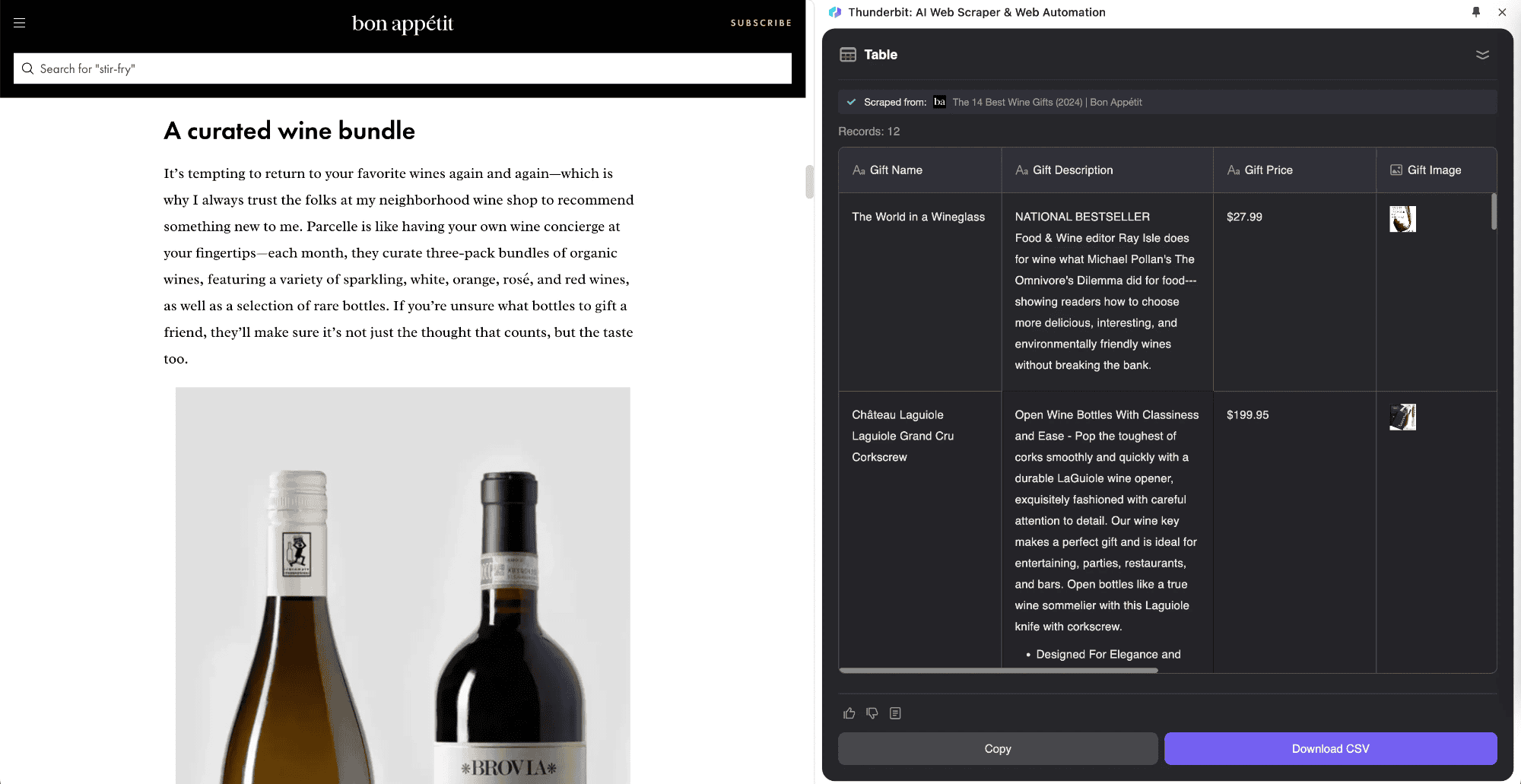
サブページスクレイピングは、1つのページからリストデータを取得し、さらに各サブページの情報をメインテーブルにまとめる方法です。ThunderbitはAIウェブスクレイパーのAI機能を活用して、この新しいスクレイピング手法を実現しました。商品ページやブログ、ナビゲーション型サイトなど、サブページが多いサイトにぴったり。サブページスクレイピングの強みは、サブページの情報を自動で集めてメインテーブルにまとめてくれるところです。
たとえば「今日の株式市場」みたいな記事を読んでいて、全銘柄の株価リストを取得したいとき、を使えば、テーブルを定義するだけで自動的に株価を抽出し、リアルタイムページも開いてデータを統合してくれます。ニュースを読みながら正確な情報を記録できるのはかなり便利。ThunderbitのAIウェブスクレイパーは、従来のツールでは難しかったページごとの違いにも柔軟に対応します。
なぜサブページスクレイピングが便利なのか?
Thunderbit AIウェブスクレイパーは、データ収集の効率と精度を大幅にアップさせる多彩な機能を持っています。
AIによるスマートなデータ抽出
Thunderbit AIウェブスクレイパーはAIを活用し、ページ構造の変化にも自動で対応。必要なデータを自然言語で指定するだけで、抽出ルールを自動生成してくれます。これでデータ精度もアップし、プログラミングが苦手な人でも簡単にデータ収集が可能。テキスト・リンク・画像など、いろんなデータタイプに対応しているので、幅広いニーズに応えられます。
サブページの自動処理
Thunderbitはサブページ処理も得意。サブページを自動で判別・アクセスし、1つのテンプレートで異なるレイアウトにも対応。AIがページ構造の変化を検知してくれるので、ユーザーはサブページごとの抽出を気にしなくてOK。サブページの内容も自動でメインテーブルに統合し、情報整理をサポート。AIアシスタントのようにデータのクリーニングやラベリングも自動化して、データ品質を高めてくれます。
効率的なデータ管理
Thunderbitは多様なエクスポート形式や外部サービス連携(Google Sheets、Airtable、Notionなど)にも対応。スクレイパーテンプレートをGoogle Sheetsに連携すれば、集めたデータを一元管理できるし、Notionのデータベースにも自動で整理できます。柔軟なエクスポートオプションで、用途に合わせたデータ管理が可能。カスタムラベルや分類も自動で管理プラットフォームの形式に合わせて変換されるので、後の作業もスムーズです。
実用的なプリセットテンプレート
Thunderbitはユーザーの作業効率を上げるため、豊富なプリセットテンプレートを用意。ECデータ収集(、)、不動産情報()、SNSデータ分析(、)、企業情報収集(企業サイトやビジネスディレクトリ)など、幅広い用途をカバー。テンプレートを使えば、作業時間を大幅に短縮できて、データの一貫性や精度もバッチリです。
実践ステップガイド
サブページスクレイピングのやり方
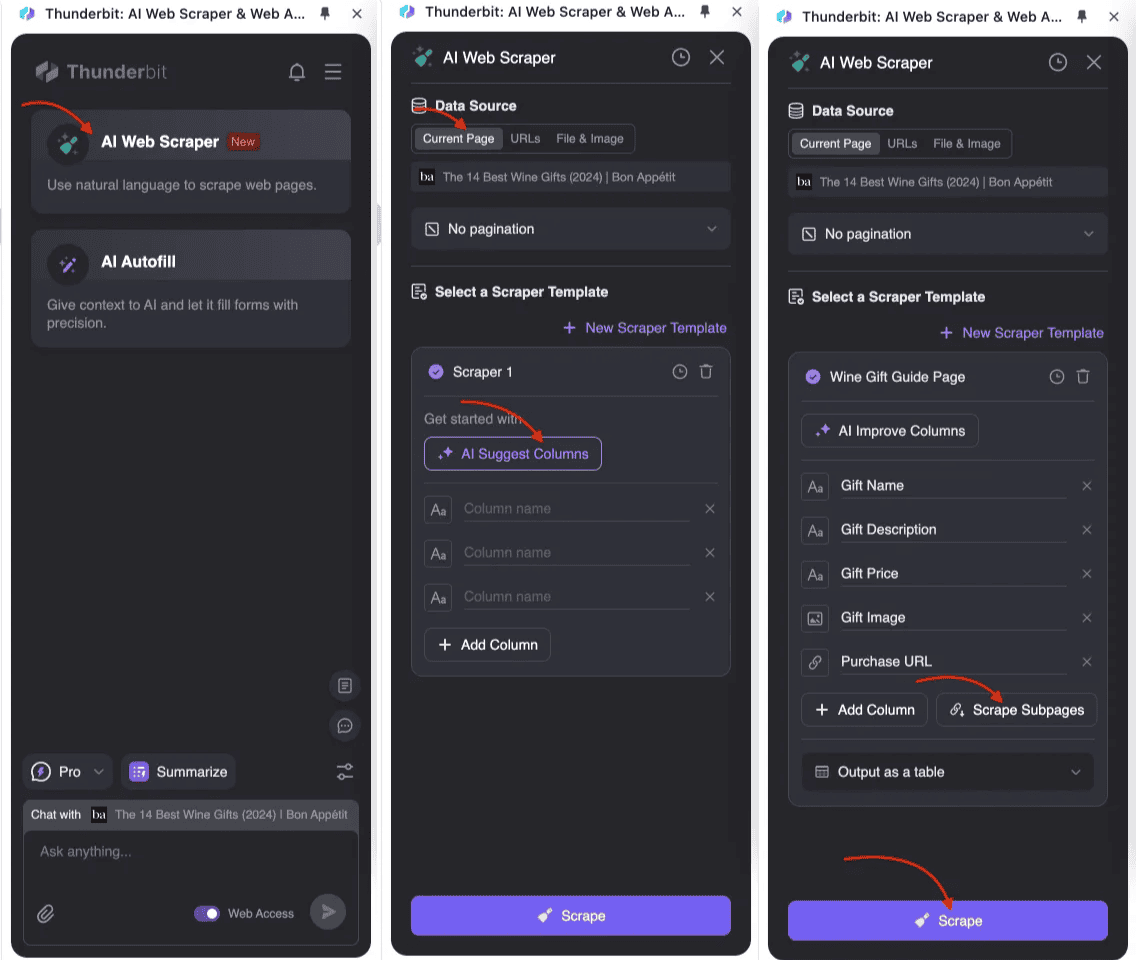
- :Thunderbit AIウェブスクレイパーを開いて、新しいスクレイパーテンプレートを作成します。
- メインテーブルの構造を定義:テーブル設定で、タイトル・価格・説明など集めたい項目を追加。サブページのデータ用にフィールドを作り、サブページスクレイピングを有効化します。
- スクレイパーを実行:Thunderbitがメインページからリストデータを抽出し、各サブページに自動でアクセスして必要な情報を取得、メインテーブルにまとめてくれます。すべてAIが自動でやってくれるので、難しいコーディングは一切不要です。
リストクロールのやり方
開発者向けには、いろんな言語やツールでリストクロールを実装できますが、Pythonはシンプルでライブラリも豊富なので特に人気です。以下はrequestsとBeautifulSoupを使った基本的なPythonサンプルです:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4def scrape_urls(urls):
5 data = []
6 for url in urls:
7 response = requests.get(url)
8 soup = BeautifulSoup(response.text, 'html.parser')
9 titles = soup.find_all('h2', class_='product-title')
10 prices = soup.find_all('span', class_='product-price')
11 for title, price in zip(titles, prices):
12 data.append({
13 'title': title.get_text(),
14 'price': price.get_text()
15 })
16 return pd.DataFrame(data)
17# 使用例
18urls = ['<http://example.com/product1>', '<http://example.com/product2>']
19data_frame = scrape_urls(urls)
20print(data_frame)まとめ
今のビジネスシーンでは、データはまさに企業のエンジン。効率よくデータを集めて分析できる会社ほど、市場で有利に立てます。データは市場の動きや顧客のニーズをつかみ、商品開発やマーケティング戦略の意思決定に欠かせないヒントをくれます。でも、ネット上に散らばる膨大なデータを効率よく集めて整理するのは、なかなか大変。
Thunderbitのようなツールを使えば、データ収集の悩みは一気に解消。まるで頼れるアシスタントのように、膨大なデータの中から価値ある情報を見つけ出し、意思決定を後押ししてくれます。競合情報や市場トレンド、ユーザーレビューなども簡単に取得できて、より賢いビジネス判断が可能です。
Thunderbitはデータ収集だけでなく、強力なデータ処理・分析機能も搭載。集めたデータを自動でクリーンアップ・構造化し、直感的なレポートも作成。市場動向を定期的にモニタリングしたい企業にも、Thunderbitの自動収集機能は大幅な時短と効率化を実現します。
データドリブンな時代、Thunderbitのようなツールは企業のデジタル変革を強力にサポート。データの重要性が増す今、Thunderbitのようなインテリジェントなデータ収集ツールは、これからのビジネスに欠かせない武器になるでしょう。
よくある質問(FAQ)
-
Thunderbitって何? は、ビジネスユーザー向けにウェブ作業を自動化するChrome拡張機能です。AIウェブスクレイパー、AIクリップボード、AIウェブチャットなどの機能で、データ抽出やフォーム入力、をAIで実現。日々の作業を効率化し、時間を節約できる生産性ツールです。
-
ThunderbitのAIウェブスクレイパーはどうやって動くの? ThunderbitのAIウェブスクレイパーは、AIを活用してウェブサイトから構造化データを抽出します。「AIカラム提案」をクリックすると、AIが最適な抽出方法を提案し、「スクレイプ」を押すだけでデータを取得可能。ウェブサイトやPDF、画像からも2クリックでデータ収集できます。
-
リストクロールとサブページスクレイピングの違いは? リストクロール(バルクスクレイピング)は、URLリストからデータを一括抽出する方法で、大規模サイト向き。一方、サブページスクレイピングは1ページとそのサブページからデータを抽出し、情報をメインテーブルにまとめます。ThunderbitのAIウェブスクレイパーは両方に対応し、インテリジェントなデータ抽出・管理を実現します。
-
プログラミングができなくてもThunderbitは使える? もちろん!Thunderbitは非エンジニアでも使いやすい設計。AI機能で、必要なデータを自然言語で指定するだけで抽出ルールを自動生成し、誰でも簡単にデータ収集ができます。
-
Thunderbitで扱えるデータの種類は? Thunderbitはテキスト・リンク・画像など多様なデータタイプに対応。ECデータ収集、不動産情報、SNS分析、企業情報収集など、幅広い用途に活用できます。
-
Thunderbitの始め方は? まずから拡張機能をインストール。AIウェブスクレイパーやAIクリップボード、AIウェブチャットなどの機能を使って、ウェブ作業を効率化しましょう。
-
Thunderbitにはプリセットテンプレートがある? はい、Thunderbitは多彩なを用意。EC、不動産、SNS、企業情報など、さまざまな分野のデータ収集を効率化し、データの一貫性と精度を確保します。
-
Thunderbitはデータ品質をどうやって担保してる? ThunderbitはAIでデータをインテリジェントに抽出・処理し、ページ構造の変化にも自動対応。データのクリーニングや整形もAIがサポートし、繰り返し作業を自動化して品質を高めます。
-
ウェブスクレイピングの活用例は? はさまざまな用途で活躍します。たとえばして市場調査したり、して文書分析に使ったり。多くの企業が分析しています。AI搭載ツールならできて、複雑なコードは不要です。 SNS分析ではやなどの専用ツールで、マーケティングに役立つデータを集められます。
もっと詳しく知りたい方はこちら: