
データドリブンな意思決定は重要だと言われますが、その前段にある「データを集める作業」の負担は見落とされがちです。手作業でデータを集めた経験がある方なら、必要な情報を探し、コピーし、表に整えるだけで多くの時間が消えることを実感しているはずです。非効率なデータ収集が原因で、データ活用の取り組みが進まない企業も少なくありません。
💡 この記事では、データスクレイピングの基本と、それがテクノロジーの進化によってどう変わってきたのかをわかりやすく解説します。従来手法の課題、AIを活用したデータスクレイピングのメリット、そして実務で使える具体的なヒントまで、幅広く紹介します。
データスクレイピングとは?
データスクレイピング、またはweb scrapingとは、Webページから構造化された情報をツールで抽出することです。多くの場合、取得した情報は表形式のデータとして整理されます。たとえば、Google Mapsから公開情報を集めてリード獲得に活用したり、AmazonからEC商品のSKUを取得して転売や市場分析に使ったり、YelpからSNSやレビュー情報を集めて顧客インサイトを得たりできます。
データスクレイピングを取り巻く技術の変化
以前のデータ収集は、技術者がスクリプトを書くか、担当者が手作業でコピーするものと見なされがちでした。ですが、2025年の今、AI の進化によって状況は大きく変わっています。データスクレイピングは、プログラマーだけの専門領域でも、単純な自動化だけでもなくなりました。
従来手法の限界
現代のWebサイトは、以前よりはるかに複雑です。React/Vueのようなフレームワークによる動的コンテンツの読み込み、テキスト・動画・画像をまたぐマルチモーダルデータ、同じページ内でもテンプレートがそろっていない非標準的な構造など、対応すべき課題が増えています。最近の調査では、従来のWebスクレイピング手法には大きく3つの問題があると指摘されています。
-
保守コストが膨らみやすい
従来のWebスクレイパーは、継続的に手作業でのメンテナンスが必要です(1サイトあたり月3〜5時間ほど)。サイトの更新やフロントエンドの変更が入ると、XPathセレクタの60%が使えなくなることもあります。AIツールは、言語モデルとコード理解を活かして、構造変化の90%に自動対応でき、保守コストを60〜80%削減できます。React/Vueで構築された現代的なサイトでも、クラス名が変わっても意味を理解して追従できるため、データスクレイピングの安定性を保てます。 -
取得できるデータの幅が狭い
従来手法では構造化データしか取得しづらく、次のような価値ある情報を取りこぼしがちです。- 画像内のデータ
- 記事本文に含まれるテキストデータ
- HTMLタグのない非構造化データ
-
データ品質の問題
従来手法は動的コンテンツに弱く、データが欠けたり、誤って取得されたりしやすいという課題があります。- ページ分割されたデータ(ECの商品一覧など)では、1画面目の内容の30〜50%しか取得できないことがある
- 無限スクロールのページ(SNSフィードなど)では、重要データの60%以上を取り逃すことがある
- 非構造化データの照合精度が低く、リストの対応付けで誤りが起こりやすい
こうした課題に対して、ThunderbitのようなAI駆動ツールが実務の選択肢になっています。
AIデータスクレイピングの台頭
AIを使ってあらゆるWebサイトからデータを抽出 Get Started Free
2025年までに、AI、特に大規模言語モデル(LLM)は大きく進化しました。自然言語を理解・生成し、複雑なデータ分析にも対応できるようになったことで、多くのデータスクレイピングツールがLLMを活用し始めています。ここ数か月で13種類のデータスクレイピングツールを検証した結果、私はThunderbit AI Web Scraperをおすすめします。
Thunderbitが際立っている理由は次のとおりです。
-
操作体験がまったく新しい
ユーザーは自然な言葉で指示するだけで、システムが自動でスクレイピング計画を作成します。従来のツールと比べて、設定時間を87%短縮できます。 -
ローカル環境でのスクレイピングに強い
ブラウザ拡張機能として動作するThunderbitは、次のような強みがあります。- すぐにデータを抽出できる
- 動的ページや無限スクロールページを取得できる
- ログインが必要なページも対応できる
-
強力なマルチモーダル処理
Thunderbitは、次のような多様なデータ形式を扱えます。- 記事内テキストからの情報抽出
- PDFからの財務データ表の抽出
- 複数画像からの情報認識と表形式化
- 動画字幕の抽出と要約
Thunderbitを使えば、さまざまなデータ収集シーンに対応しやすくなります。
AIを使ったデータスクレイピングの方法
Thunderbitの高性能なAI web scraping機能を使うには、次の手順で進めます。
-
ブラウザ拡張機能をインストールする
Thunderbitの公式サイトにアクセスし、Chrome Web StoreからThunderbit拡張機能をダウンロードします。インストールが完了したら、ブラウザのツールバーにピン留めしておきましょう。 -
登録して無料クレジットを受け取る
拡張機能内でサインアップすると、試用用クレジットを獲得できます。このクレジットで、AIによるWebスクレイピング、フォーム自動入力、スマート要約といった主要機能を試せます。いきなり本番で使う前に、まずはプレイグラウンドで無料体験して、使い勝手を確かめるのがおすすめです。 -
スマートスクレイピングを開始する
Thunderbitのサイドバーからテンプレートを起動します。言葉で抽出したいデータ内容や種類を指定し、出力形式やその他の条件を調整します。あとはスクレイプボタンを押すだけで、データスクレイピングが始まります。
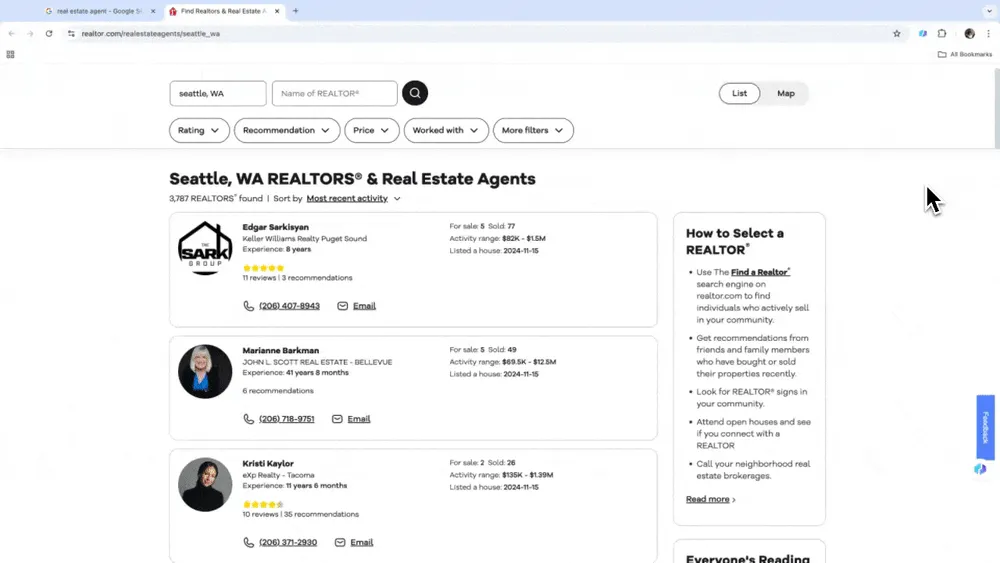
高度なスクレイピング機能(Proプラン)
ThunderbitのPro Tierに加入するか、無料トライアルを開始すると、次の機能が使えるようになります。
-
マルチモーダルデータ処理
PDF文書の解析(財務報告書・製品マニュアル)、画像からのデータ抽出(価格ラベル・仕様書)、動画字幕のスクレイピングなど、複雑なケースに対応します。非構造化データも自動で整形されます。 -
詳細ページまでの深掘りスクレイピング
ページ内のすべてのサブリンク(商品詳細ページやレビューページなど)を必要に応じて辿り、関連データを自動で判別してメインのデータ表に統合します。ECの商品カタログ、不動産一覧などに最適です。 -
あらかじめ用意されたテンプレートライブラリ
スクレイピングテンプレートを使えば、TikTok、Amazon、Zillowなど30以上のプラットフォームに対応した最適化済みテンプレートをすぐ使えます。ページ構造の変化にも自動で適応します。新規ユーザーは設定時間を平均83%短縮できます。 -
一括スクレイピングタスク
複数のスクレイピング処理を同時に実行でき、URLリストの読み込みによるバッチ処理にも対応します。 -
ページ送りの自動処理
「もっと見る」ボタンやページナビゲーションを含むページ分割コンテンツを自動認識して抽出し、無限スクロールにも対応します。200ページを超えるEC商品一覧を完全に取得できることも検証済みです。
Thunderbitの実践ガイド
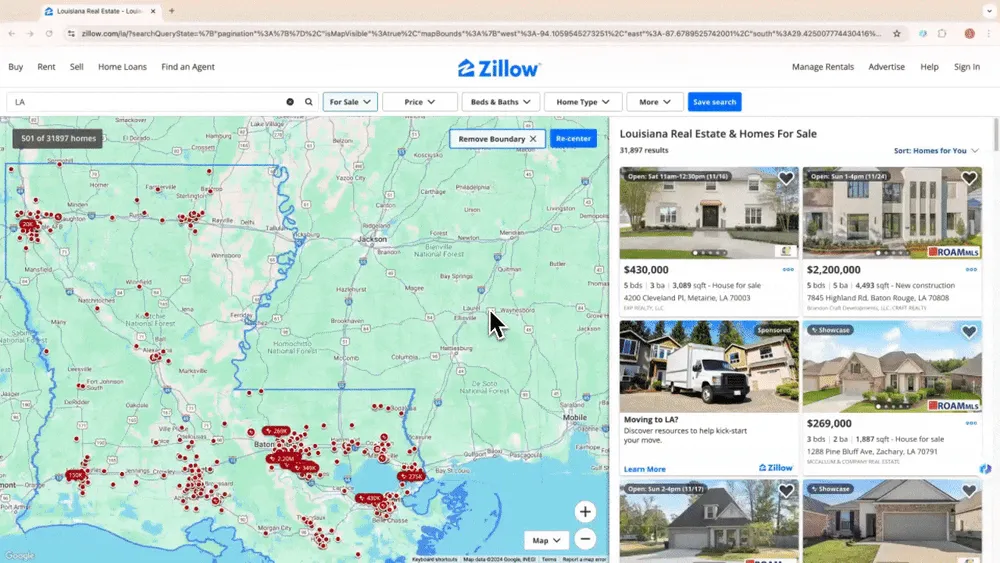
シーン1:不動産データ収集
Zillowから物件データを集めたい不動産エージェントや、有望な投資先を探している投資家にとって、信頼できるWebスクレイパーは強い味方です。ThunderbitのAI web scraperなら、Zillowから重要な物件情報を抽出し、最新情報を保ちながら競争力を維持できます。Thunderbitを使ってZillowをスクレイピングするチュートリアル動画もご覧ください。
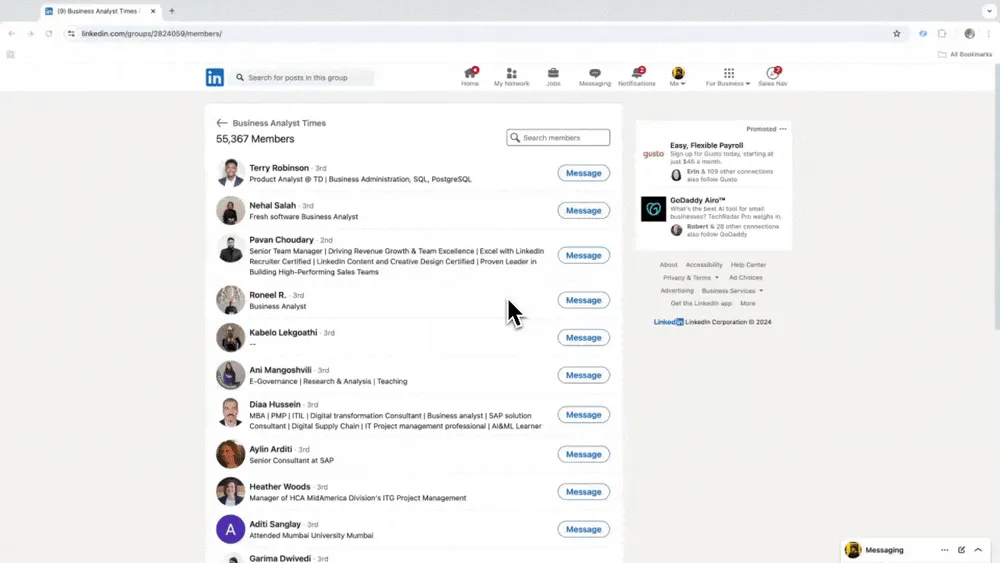
シーン2:人材・見込み顧客のリサーチ
人事担当として人材を探している方や、営業担当として新規リードを探している方にも、信頼できるWebスクレイパーは役立ちます。Thunderbitを使えば、公開Webサイト、ディレクトリ、プロフィールページから連絡先情報や企業データを抽出でき、人材検索やリード管理を効率化できます。手作業の検索やコピペを減らしたい場合は、Website Contact Scraperから始めるのがおすすめです。
シーン3:市場分析と顧客ターゲティング
地域ベースのデータを集めて市場分析をしたい事業者や、地元企業のリードを探したい営業担当者にとって、Webスクレイパーは有効な情報収集手段です。ThunderbitならGoogle Mapsから重要データを抽出でき、より的確な意思決定やアプローチにつなげられます。
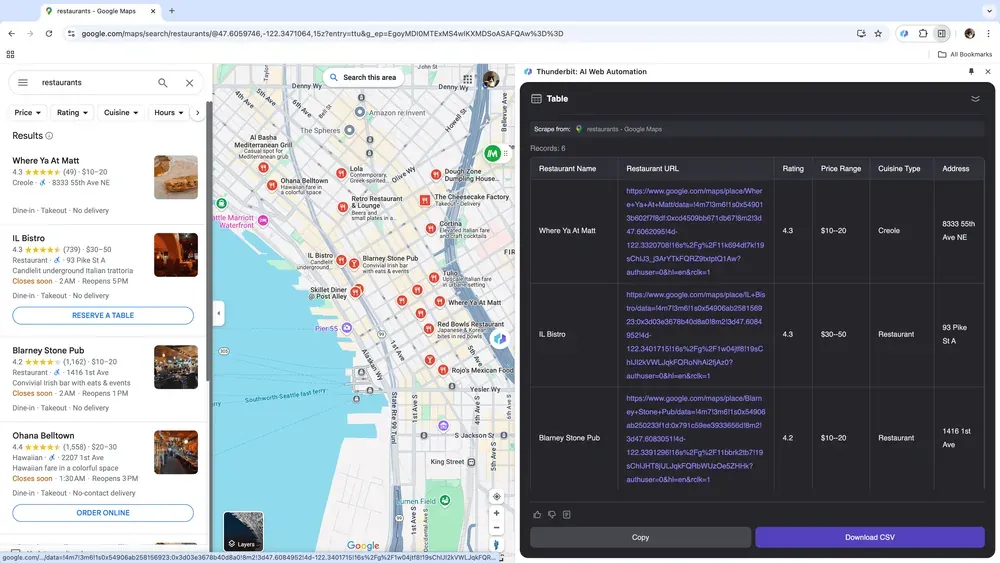
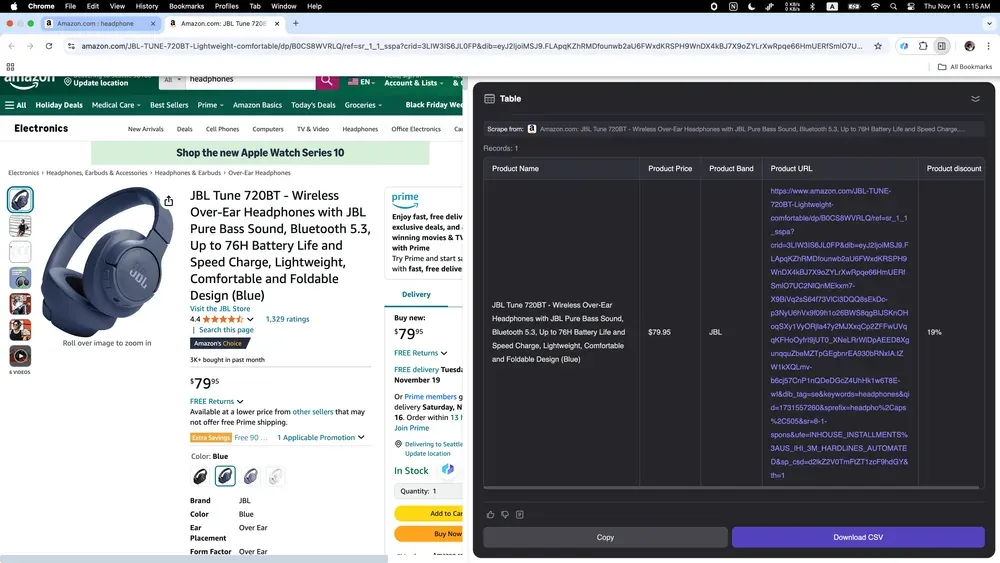
シーン4:ECデータ分析
競合を把握したいオンライン販売者や、市場動向を追いたい起業家にとっても、Thunderbitは実用的なツールです。Amazonから商品説明、価格、ユーザーレビューなど、さまざまな商品データを収集できます。
ThunderbitのAI web scraperは、ビジネスユーザーのデータ収集をより速く、簡単で、効率的なものにします。不動産市場で物件を探す場合でも、人材市場で候補者を探す場合でも、EC市場のトレンドを分析する場合でも、AI Web Scraperは時間と手間の削減に役立ちます。WebスクレイピングにAIを取り入れることで、生産性を一段上げやすくなります。
データクレンジングのための特別ヒント
従来のスクレイパーでは、データスクレイピング後のデータクレンジングが大きな負担になります。ThunderbitのAIは、LLMを活用してスクレイピングの途中でデータクレンジングまで行えるため、以下の機能によってクレンジング作業を83%削減できます。
ヒント1:項目の自動対応付け
ECの商品ページ、Zillowの物件情報、企業ディレクトリのように、複数ソースの異種データを扱う場合でも、ThunderbitのAIは意味を理解して自動でマッピングします。
- 異なるデータソース間の項目対応を自動認識(例:「price」↔「售价」↔「Price」)
- 類似項目を賢く統合(例:「area」と「square feet」)
- プラットフォームをまたいだデータ標準化(例:LinkedInの「current position」とZillowの「property status」をタグ情報として統一)
ヒント2:文脈を踏まえた補完
大規模言語モデルの文脈理解により、Thunderbitは業界最高水準の99%のデータ補完率を実現します。
- 住所補完:郵便番号から都市・州情報を自動補完(例:10001 → New York City, NY)
- キャリア推定:LinkedInの学歴情報から、あり得る職務経験を予測
ヒント3:データ最適化
- 多言語翻訳(英語、中国語、日本語など12言語のリアルタイム翻訳に対応)
- スマート要約(500語の商品説明を3つの訴求ポイントに圧縮)
- 単位の統一(square feet ↔ square meters、Fahrenheit ↔ Celsius を自動変換)
- フォーマットの標準化(日付は YYYY-MM-DD に統一、通貨は USD に統一)
ヒント4:品質検証
- エラーの自動修正:フォーマットエラーを自動補正(例:電話番号 +01 138-1234-5678 → +113812345678)
- 論理チェック:「建築年」が「最終リフォーム時期」より前かどうかを確認
ヒント5:AIタグ付け
自然言語処理を使って、意味のあるタグを自動生成します。
- 感情分析タグ(レビューをポジティブ/ネガティブ/ニュートラルに自動分類)
- ビジネス価値タグ(「有望顧客」「フォローアップすべき物件」などを自動付与)
- 業界分類タグ(LinkedInプロフィールに「tech|finance|healthcare」などのラベルを自動付与)
データスクレイピングのデメリット
データスクレイピングには大きな価値がありますが、企業が直面しうる課題もあります。特に法的な観点は重要です。GDPRやCCPAのような規制はデータ収集に厳格な要件を課しており、プライバシー法への慎重な対応が求められます。Webサイト側も、Cloudflareのような高度な防御策を導入し、IP制限などでスクレイピング行為を検知・遮断することがあります。
AI時代におけるデータスクレイピングの未来
AIの進化によって、Webスクレイピングはより直感的に使える企業向けソリューションへ変わりつつあります。たとえば、zillow.comのようなドメインと「ニューヨーク市のすべての物件一覧を取得して」といった要望を入力するだけで、AIが物件情報から価格動向まで関連するデータ項目を自動で整理する世界が近づいています。
こうした仕組みは、取得したデータを業務フローに自然に組み込みます。公開企業ページや問い合わせページから取得した見込み顧客情報をCRMに流し込んだり、ECの指標を分析ダッシュボードへ送ったりできます。さらに、高度なパターン認識により、在庫変動や新たな市場トレンドを先回りして監視する予測型スクレイピングも可能になります。重要なのは、AIがコンプライアンスにも動的に対応し、変化する規制に合わせてスクレイピング設定をリアルタイムで調整しながら、監査証跡の透明性も確保できる点です。
このAI主導の変化は、重要なビジネスインテリジェンスへのアクセスを広げ、企業がWebデータと向き合う方法そのものを変えます。技術が成熟するにつれ、ThunderbitのようなAI搭載スクレイピングソリューションを早く導入した企業は、データドリブンな意思決定で競争優位を得やすくなるでしょう。
よくある質問
-
Thunderbitとは?
Thunderbitは、LLMを基盤としたスマートなブラウザ拡張機能で、現代のデータ収集ニーズに対応するよう設計されています。AI web scraping機能だけでなく、マルチモーダルデータ処理も統合し、動的なWebページ、PDF文書、画像、動画から包括的にデータを抽出できます。ローカルで動作するブラウザソリューションとして、動的に読み込まれる公開ページや操作が必要なページにも対応し、現代的なフロントエンドの変更にも自動で適応します。 -
ThunderbitのAI web scraperはどう動く?
ThunderbitのAI web scraperは、AIを使ってWebサイトから構造化データを抽出します。ユーザーは「AI Suggest Columns」をクリックして、現在のサイトをどう抽出するかをAIに提案させ、その後「Scrape」をクリックしてデータを取得します。Webサイト、PDF、画像のどれでも、わずか2クリックで処理できます。 -
リストスクレイピングとサブページスクレイピングの違いは?
リストスクレイピングは、ページ分割されたシナリオ(ECの商品一覧など)に最適化されており、ページ送りのロジックを自動認識して何千件ものデータを抽出できます。サブページスクレイピングは、Zillowの物件一覧→詳細ページ→間取りのようなツリー構造で収集し、意味的な関連付けによって親子テーブルを自動で構築します。 -
プログラミングができなくてもThunderbitは使える?
Thunderbitは自然言語で操作できる設計です。ユーザーは「名前、メール、電話番号」のように欲しい項目を伝えるだけで、システムが自動でスクレイピング計画を生成します。テストでは、Webプログラミングの知識がなくても、85%のユーザーが初回のデータ収集を10分以内に完了できました。 -
Thunderbitはどんなデータに対応している?
Thunderbitは、さまざまなデータ形式を賢く認識できます。- 構造化データ:表、リスト(例:Amazonの商品仕様)
- 非構造化データ:レビュー本文、PDF文書(自動認識)
- マルチモーダルデータ:画像内の価格ラベル、動画字幕の抽出
- 動的データ:無限スクロールコンテンツ、遅延読み込み画像
- 関連データ:ページをまたぐ関係性のマッピング(例:LinkedInの連絡先→企業情報)
-
Thunderbitの始め方は?
すぐに始めたい方は、スクレイピング機能の詳細を確認するか、テンプレートライブラリを活用してください。
参考リンク:
AI Web Scraperを試す Get Started Free




