

Simplescraperで気づけば1,000回以上スクレイピングを回してきました。途中から「成功した数」を数えるのをやめて、「失敗した理由」を記録するようになったんです。「ちゃんと動いた?」から「今回はなぜ壊れた?」へ——この視点の切り替えで、どのドキュメントページよりも多くを学べました。
Simplescraper は、コードを書かずにWebサイトからデータを取り出せる、使い勝手のいいChrome拡張機能です。Chromeウェブストアで6万人のユーザーを抱え、クリック中心の直感的なインターフェースが本当に気持ちいい——ノーコードのスクレイピングツールとしては、しっかり定着している1本です。ただ、ランディングページが教えてくれないことがあるんです。「安定した結果を大規模に出すには、ビジュアル系スクレイパーがどこで脆くなるのかを理解しないと厳しい」、ということ。2025年のある調査では、従業員が繰り返しのデータ入力に週9時間以上を費やしているという結果が出ています。まさに、こうした負担が人をSimplescraperのようなツールへ向かわせるんですよね。とはいえ、ツールの癖を知らずに使うと、その9時間が「節約」ではなく「デバッグ」に消えていきます。この記事では、実運用から積み上げた5つのベストプラクティス——選択失敗のトラブルシューティング、スクレイピングモードの使い分け、無料枠の最大活用、ブロック回避、見切りのつけどき——を順に解説します。

Simplescraperとは何か、そしてなぜベストプラクティスが大事なのか
Simplescraperは、Webページ上の要素——商品タイトル、価格、画像、連絡先——を視覚的に選んで、コードを1行も書かずに構造化データとして取り出せるChrome拡張機能です。欲しい部分をクリックしていくと、似た構造のページでも使い回せる「レシピ」が出来上がります。
仕組みはシンプルです。
- 要素の視覚選択: 欲しい項目をクリックするだけ。Simplescraperが繰り返しパターン(商品一覧、検索結果、求人情報など)を自動で見つけてくれます。
- レシピ: 抽出設定を保存して、あとで再利用したり、URLの一括処理にも回せます。
- 2つのスクレイピングモード: ブラウザ(ローカル、Chrome上で実行)とクラウド(Simplescraperのサーバー上、無人実行)。
- 連携: Google Sheets、Airtable、webhook、Zapier、Make、CSV、JSONへ出力できます。
- AI抽出: 比較的最近追加されたSmart Extract機能で、スキーマをプロンプトで指示するとCSSセレクタを生成してくれます。
対象ユーザーはかなり幅広く、マーケター、営業チーム、EC運営者、リサーチャーまで——開発者を雇わずにWebサイトから構造化データを取り出したい人なら、誰でも対象です。しかも、整ったページならSimplescraperはサクッと結果を出してくれます。
では、なぜベストプラクティスが効いてくるのか。商品一覧や整然としたディレクトリページの「外側」に踏み出した瞬間、急に摩擦が増えるからです。動的コンテンツ、ボット対策、遅延読み込みの画像、入れ子のHTML——こうした現実の条件が、「使えるツール」と「生産性の罠」の差を生みます。最初から正しいやり方を押さえておけば、何時間もの試行錯誤を回避できます。
ベストプラクティス1: Simplescraperが要素を選択できないときの対処法
これが、私が見てきた中でいちばん多い不満です。要素をクリックすると、Simplescraperがハイライトしてくれて、よし行けると思う。なのに出力を見たら、データが半分抜けている。写真は空、プロフィールは空、所在地は消えている——そんなことが普通に起きます。
創業者本人も、早い時期に「要素/CSSセレクタはまだ100%ではない」と認めています。この正直さは好感が持てるんですが、水曜の夜23時に壊れたスクレイピングを直してはくれませんよね。
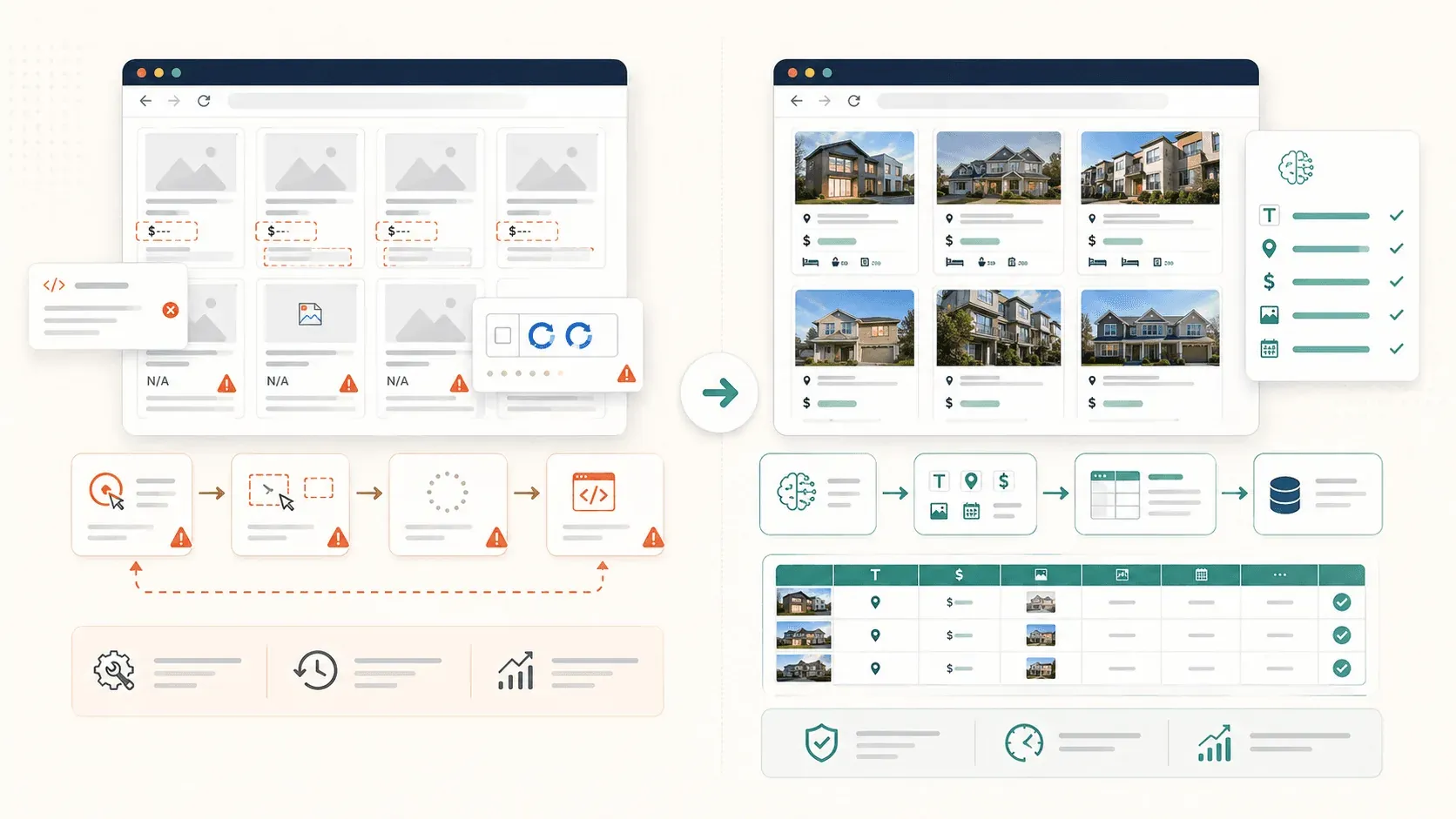
よくある選択失敗とその理由
Simplescraperがつまずきやすいパターンは、ざっくり4つあります。
- 遅延読み込み画像: 画像要素は、その位置までスクロールするまでページ上に実体として存在しません。スクロール前にスクレイピングすると、画像欄が空っぽになります。
- 入れ子・グループ化されたコンテナ: Simplescraperの自動検出はなるべく正確にしようとします。結果、ページ全体の繰り返しセットではなく、一部のセクションだけ拾ってしまうことがあります。ユーザーからは「1回で全行を選択できない表がある」という報告も。
- 動的なJavaScriptコンテンツ: React、Vue、AJAXなどで初回表示後に描画される要素は、スクレイパーが先走るとまだ存在しません。
- 無限スクロール型ページネーション: 欲しいデータが、まだHTMLに読み込まれていないだけ。スクロールするか「もっと見る」をクリックしないと出てきません。
実践的なトラブルシューティング手順
手動セレクタに踏み込む前に、まず次を試してください。
- ページを最後までスクロールする。 これで遅延読み込みの画像やコンテンツがDOMに展開されます。
- 一覧の件数が妙に少ないときは「類似項目を含める」を使う。 Simplescraperのドキュメントでも、グループ化コンテンツに対して推奨されています。
- JavaScriptが多いサイトでは、描画完了を待つ。 スクレイピング開始前に数秒だけ余分に待ちましょう。
- 最初は少量でテスト。 500ページのバッチに突っ込む前に、2〜3ページで行数を確認します。
手動CSSセレクタへの切り替え
視覚選択が何度も失敗するなら、手動に切り替えるべきです。ここが、ライトユーザーと使いこなす人の分かれ目になります。
手順はこうです。
- Chromeで欲しい要素を右クリック → 検証。
- DevToolsで、その要素のクラス名やdata属性を特定します(例:
.product-card .priceや[data-test="location"])。 - SimplescraperでEdit Propertiesタブに切り替えて、セレクタを貼り付けます。
- 小規模スクレイピングを実行してセレクタをテストします。
堅牢なセレクタを書くコツ:
- 位置指定(
div:nth-child(3))より、クラス名(.listing-title)を優先する - 使えるならdata属性を使う。サイト更新後も安定しやすい
- サイトのHTML構造が変わると壊れる、深くネストしたパスは避ける
AIによる代替案: Thunderbitにフィールドを自動検出させる
正直に言うと、私たちのチームがThunderbitを作ったのは、まさにこの問題にうんざりしたからです。Thunderbitの「AI Suggest Fields」はページ構造を読み取り、列と抽出ロジックを自動で提案してくれます。CSSの知識は要りません。AIは各サイトのレイアウトに合わせて適応し、入れ子コンテンツや遅延読み込み画像にも対応します。
毎回のスクレイピングでセレクタのデバッグに数分以上かかっているなら、まったく別のアプローチを試す価値があります。
ベストプラクティス2: クラウドとブラウザ、どちらのモードを使い分けるか
多くのSimplescraperユーザーは、最初に試したモードをそのまま使い続けます。実際の用途と合っているかは、深く考えずに、です。その結果、本来なら避けられたはずの失敗が起きてしまいます。
ブラウザ(ローカル)スクレイピングを使うべき場面
- ログイン必須ページ: LinkedIn、CRMダッシュボード、社内ツールなど、認証の裏側にあるものは、アクティブなブラウザセッションが必須です。
- 単発の素早い抽出: すでにページを開いていて、今すぐデータが欲しいとき。
- 無料クレジットの節約: ブラウザスクレイピングはクラウドクレジットを消費しません。
弱点は、PCの電源を入れたままにする必要があることと、大規模ジョブではクラウドより遅くなることです。
クラウドスクレイピングを使うべき場面
- 公開ページ(EC商品一覧、ディレクトリ、不動産サイトなど)でログインが要らない場合。
- 定期監視: 無人で繰り返し回したい場合。
- バッチジョブ: 1回のクラウドバッチで最大5,000 URLまで処理できます。
- 連携先への配信: Google Sheets、Airtable、webhookへの自動送信。
弱点は、クラウドスクレイピングがクレジットを消費すること。JavaScript対応ページは1ページ2クレジット、非JSページは1クレジットなので、無料枠の100クレジットはあっという間に底を突きます。
判断フレームワーク
| シナリオ | 推奨モード | 理由 | 選び方を誤った場合のリスク |
|---|---|---|---|
| ログインが必要なページ(LinkedIn、ダッシュボード) | ブラウザ | 認証済みセッションが必要 | クラウドだとログイン壁にぶつかる |
| 公開ECの商品一覧 | クラウド | 高速で無人実行できる | ブラウザだとPCを占有する |
| 定期的な監視 | クラウド | 自分がいなくても動く | ブラウザだと常時立ち会いが必要 |
| ボット対策が厳しいサイト(Amazon、Yelp) | ブラウザ(代替)またはプロキシ付きクラウド | IPローテーションかセッション再利用が必要 | プロキシなしのクラウドはすぐブロックされる |
| 素早い単発抽出 | ブラウザ | すぐ実行でき、クレジット不要 | 1ページのためにクラウドを準備するのは大げさ |

Thunderbitならどう楽になるか
Thunderbitでは、同じ画面内のシンプルな切り替えで選べます。クラウドモードは最大50ページを同時処理でき、クラウド利用のために別料金プランを契約する必要もありません。ブラウザモードは追加設定なしで、ログイン必須サイトにそのまま対応します。両方が同じワークフローに収まっているだけで、「どちらを使うか」という迷いがかなり減ります。
ベストプラクティス3: Simplescraperの無料枠をしゃぶり尽くす
料金体系の誤解は、本当によくあります。私自身、「無料のChrome拡張機能だから全部無料でしょ」と思い込んでいる人の投稿を何度も見ましたし、逆に有料プランの説明が目立たないせいで「Simplescraperは高い」と決めつけている人もいました。どちらの捉え方も、得しません。
Simplescraperの無料プランに実際に含まれるもの
Simplescraperの現在のプランによると、こうです。
- ブラウザスクレイピング: 無制限(Chrome上でローカル実行)
- クラウドクレジット: 月100
- 保存できるレシピ: 3つ
- 出力形式: CSVとJSON
- 含まれないもの: 優先サポート、高度なプロキシオプション、より多いクラウドクレジット
現実的な無料枠の使い方
公開ECサイトの商品ページを50件スクレイピングしたいとしましょう。
- ブラウザモード(無料): 完全無料でいけます。各ページを開く(または一覧を使う)、レシピを実行する、CSVに出力する、という流れ。所要時間は忍耐力と通信速度次第ですが、手動でページ移動するなら、50ページで15〜30分の実作業を見ておくといいでしょう。
- クラウドモード(無料枠): JavaScriptレンダリングを有効にすると、1ページあたり2クレジット。50ページなら100クレジット——これで月間のクラウド枠を1ジョブで使い切る計算です。スケジュール実行も、失敗時の再試行もできません。
無料枠は、小規模でたまにやるスクレイピングなら本当に役立ちます。ただし、クラウド自動化やスケール運用に踏み込もうとすると、あっという間に足りなくなります。
無料枠の比較: SimplescraperとThunderbit
| 機能 | Simplescraper 無料 | Thunderbit 無料 |
|---|---|---|
| ページ数/クレジット | ブラウザ無制限 + クラウド100クレジット | AI機能付きで6ページ |
| AI抽出 | 制限あり(Smart Extractはクレジット消費) | AI Suggest Fieldsをフル搭載 |
| 出力先 | CSV、JSON | Excel、Google Sheets、Airtable、Notion ― すべて無料 |
| 保存設定 | 3レシピ | テンプレートあり |
| サブページスクレイピング | 手動でレシピ設定 | ページ数に含まれる |
この2つは、そもそも設計思想が違います。Simplescraperは「ローカルは無制限、クラウドには制約あり」というモデル。一方Thunderbitは、ページ数は少なめでも、1ページごとのAI機能をフル搭載し、チームが日常的に使うツールへの無料エクスポートも揃えています。基本のローカルスクレイピングで多少の手作業を許容できるならSimplescraperの無料枠で十分回ります。AI抽出と柔軟な出力先を重視するなら、Thunderbitの無料枠のほうが1ページあたりの実質価値は高いです。
ベストプラクティス4: スクレイピング中にブロックされないために
CAPTCHAの壁や空っぽのデータセットを目の前にするまで、誰もボット対策のことなんて考えません。その時点では、すでに時間もクレジットも溶けたあと、です。
先回りの対策は、後からのトラブルシューティングよりいつだって安く済みます。
レート制限を入れて、リクエストの間隔を空ける
ブロックされる最大の理由は、短時間に大量リクエストを叩き込むこと。Webサーバーから見れば、1つのIPから10秒で50リクエスト飛んでくるのは、興味のあるリサーチャーではなく「攻撃」です。
目安はこんな感じ:
- 一般的な商用サイトでは、ページ間に2〜5秒の間隔
- マーケットプレイスやレビューサイトなど敏感な対象は、もっと遅くして5〜10秒
- SimplescraperのAPIを使う場合は、
waitForSelectorパラメータで、抽出前にページが完全に読み込まれるのを待たせられます。結果として、実行速度も自然と落ちます
プロキシローテーションを有効にすべきタイミング
プロキシローテーションは、リクエストごとにIPアドレスを切り替えて、複数の別ユーザーのように見せかける仕組みです。次のような場面で必要になります。
- Amazon、Yelp、TripAdvisor、LinkedIn(ボット対策が厳しい)
- IP単位でレート制限するサイト
- 大規模バッチジョブ(1ドメインに対して数百ページ)
Simplescraperのプラットフォームはプロキシモードに対応していて、標準、プレミアム、住宅用などのオプションがあります。ただし、どのプランでどこまで使えるかは公開ドキュメントだけでは必ずしも明確ではありません。難しい対象を無料枠で捌けると思い込む前に、要確認です。住宅用プロキシは通常高価ですが、検知されにくい傾向があります。
JavaScriptが重いサイトへの対処
React、Vue、Angularで作られた最近のサイトは、初回読み込みの「あと」にコンテンツを描画します。スクレイパーがJavaScriptの実行完了前に動くと、欄は空になります。
打てる手はこちら:
- クラウドスクレイピングモードを使って描画品質を上げる(SimplescraperのクラウドはJavaScriptを実行できます)
- ブラウザスクレイピング前に、手動でスクロールして遅延読み込みコンテンツを呼び出す
- APIベースのワークフローでは
waitForSelectorを使い、対象要素が出るまで待たせる - 極端に動的なシングルページアプリの一部は、そもそもビジュアルスクレイパーでは安定して扱えないと割り切る
手間をかけたくない場合の代替案
Thunderbitのクラウドスクレイピングなら、ボット対策、CAPTCHA、JavaScriptレンダリングを自動で処理します。プロキシ設定も、遅延調整も、手動スクロールも不要。商品カタログを取るためだけにアマチュアのDevOps担当になる気がない人にとっては、これは大きな違いです。問題自体が消えるわけではありませんが、あなたが抱え込まずに済みます。
ベストプラクティス5: Simplescraperの限界を見極める
2年前の自分に、誰かこの章を渡してくれていたらよかった、と思います。
ある時点で、ツールは「時間を節約してくれる道具」から「時間を食う存在」に変わります。その境目を早く見抜ければ、「もう15個もレシピを作ったから、今さら乗り換えられない」というサンクコストの罠を避けられます。
Simplescraperの実用上の限界
- 従来のページ遷移なしでAJAXによりコンテンツを読み込む動的なシングルページアプリ
- 全項目を読み込むのに延々スクロールが必要な無限スクロール(標準的なクリック型ページネーションではない)
- サブページの強化: 一覧をスクレイピングしたあと、各詳細ページに移動して追加データを取る処理。Simplescraperはバッチワークフローで対応はできますが、設定の複雑さがすぐに膨らみます。
- 既存レシピを壊すレイアウト変更。サイトがHTML構造を更新すると、丁寧に整えたCSSセレクタが効かなくなります。
ツールの限界を超えたサイン
以下のような状態になっていたら、限界に達している可能性が高いです。
- 自動検出が毎回失敗するので、スクレイピングのたびにCSSセレクタを手で調整している
- サイト更新のたびにレシピが壊れ、作り直しが必要になる
- 数十〜数百ページを同時にスクレイピングしたいのに、クレジットや速度の上限に毎回ぶつかる
- サブページのデータ取得に、何段にも連鎖したレシピが必要になる
- 抽出したデータを使う時間より、スクレイピングを維持する時間のほうが長い
最後のサインが、いちばん分かりやすい指標です。「保守」が仕事になった瞬間、ノーコードの便利さによる恩恵は霧散します。
AI搭載ワークフローへの移行
ここで、私たちのチームがThunderbitで作ったものに少しだけ触れさせてください。なぜなら、まさに上で挙げた失敗パターンに向けて設計されているからです。
- AIが毎回ページを読み直すので、壊れやすいレシピやCSSセレクタの保守は不要。サイトのレイアウトが変わっても、次回実行時にAIが追従します。
- サブページスクレイピングで、1クリックでデータ表を拡張可能。一覧を取って、その後各詳細ページを自動で訪問し、追加項目を取得します。
- スケジュールスクレイピングは、タイミング設定をいじるのではなく自然言語(「毎週月曜の9時」など)で指定できます。
- クラウドスクレイピングを50ページ同時実行できるので、公開サイトでも高速です。
- Google Sheets、Airtable、Notion、Excelへのネイティブ無料エクスポートがあり、webhook設定は要りません。
SimplescraperとThunderbitの比較
全体を1枚にまとめるとこうなります。

| 機能 | Simplescraper | Thunderbit |
|---|---|---|
| フィールド設定 | 手動CSSセレクタ / 視覚選択 | AI Suggest Fields(平易な英語) |
| サブページ強化 | バッチワークフローで可能(設定が複雑) | 1クリックで自動強化 |
| レイアウト変更への自動追従 | 壊れる(手動修正が必要) | AIが毎回ページ構造を読み直す |
| クラウドの同時処理数 | 最大5,000 URLのバッチ(プランにより変動) | 50ページを同時処理 |
| Notion/Airtableへの出力 | webhook経由(有料プラン) | ネイティブ対応、無料 |
| スケジューリング | プリセット + カスタム時間設定 | 自然言語で指定 |
| ボット対策 / CAPTCHA対応 | プロキシモードあり(プラン依存) | 自動対応、設定不要 |
| 無料枠 | クラウド100クレジット + ブラウザ無制限 + 3レシピ | AI機能付き6ページ + 無料エクスポート |
要するに、Simplescraperは「シンプル」「視覚的」「設定少なめ」「たまの手動調整は許容」というゾーンで強みを発揮します。Thunderbitは、そのモデルが行き詰まる先を引き受ける役回りです。ページの解釈、レイアウト変化への対応、ワークフローの複雑さ——そういう面倒を肩代わりしてくれます。
どちらが常に上、ということではありません。複雑さのカーブ上で、置かれている位置が違うだけ。それで全然いいんです。
すぐ使える: Simplescraperベストプラクティスのチェックリスト
次のスクレイピングで使えるよう、ブックマークしておいてください。
- 必ず最初は少量でテスト。 2〜3ページで行数とフィールドの完全性を確認してから本番へ。
- スクレイピング前にページを最後までスクロール。 遅延読み込みコンテンツを呼び出すため。
- 一覧検出が狭すぎるときは「類似項目を含める」を使う。
- スクレイピングモードは意図して選ぶ。 ログイン必須サイトはブラウザ、公開ページや定期ジョブはクラウド。
- リクエスト間の遅延を設定する。 商用サイトは最低2〜5秒、ボット対策が厳しい対象ではさらに長く。
- 無料枠の計算をきちんと理解する。 クラウド100クレジット = JavaScript対応ページ50枚。計画的に使うこと。
- レシピは安定したページにだけ保存する。 サイト更新が多いところでは、レシピは壊れやすい。
- 基本的なCSSセレクタを覚えておく。 クラス名とdata属性は位置指定より強い。
- ブロックを先回りで監視する。 結果が空、あるいはCAPTCHAが出たら、速度を落とすかモードを切り替える。
- 限界を見極める。 保守に使う時間が、データ活用に使う時間を上回ったら、代替案を検討するタイミング。
まとめ: せっかくのスクレイピングを無駄にしないために
1,000回以上のスクレイピングから得た最大の教訓は、特定のツールの話ではありません。大事なのはソフトウェアより、やり方です。 遅延読み込み、間違ったモード選択、強すぎるボット対策、壊れやすいセレクタ——「なぜ失敗したか」を理解することのほうが、機能一覧をなぞるよりずっと価値があります。
Simplescraperは、シンプルな抽出作業ならちゃんと動きます。ページが整っていて、要求が控えめで、たまの手動調整を気にしないなら、期待にしっかり応えてくれます。
でも、「使う時間」より「戦う時間」のほうが長くなっているなら——セレクタのデバッグ、壊れたレシピの作り直し、プロキシ設定、ページの手動スクロール——それは失敗ではなく、サインです。「ビジュアルスクレイピングだけでは、もう対応しきれなくなっている」というサイン。
心当たりがあるなら、Thunderbitの無料枠を試してみてください。AI機能付きで6ページ、Sheets、Airtable、Notionへの無料エクスポートも付いてきます。今のワークフローと並べて、どこがしっくりくるかを見比べてみてください。ときには、「別のツールを使うべきだ」と見極めること自体が、最良のベストプラクティスになります。
FAQ
Simplescraperは無料で使えますか?
はい。Simplescraperには無料プランがあり、ローカルのブラウザスクレイピング無制限、月100クラウドクレジット、保存済みレシピ3つ、CSV/JSON出力が含まれます。JavaScript対応のクラウドページは1ページ2クレジットなので、その100クレジットでクラウドモードでは約50ページを処理できる計算です。有料プランは、6,000クレジットのPlusが月39ドル、15,000クレジットのProが月70ドルから始まります。
SimplescraperはJavaScriptが重いWebサイトに対応できますか?
場合によります。SimplescraperのクラウドモードはJavaScriptを描画でき、シングルページアプリにも対応していると案内されています。ただし、複雑なSPA、重い動的描画、無限スクロール、強力なボット対策があるサイトでは、結果が不完全になることがあります。適切な待機時間を入れたクラウドモードを使えば信頼性は上がりますが、動的要素の強いサイトは、どのビジュアルスクレイパーにとっても依然として難所です。
Simplescraperのクラウドスクレイピングとブラウザスクレイピングの違いは何ですか?
ブラウザスクレイピングはChromeブラウザ内でローカル実行されます。現在のセッションを使えるのでログイン必須サイトに向いており、クレジットを消費しません。ただしPCを起動したままにする必要があります。クラウドスクレイピングはSimplescraperのサーバー上で動き、高速かつ無人実行ができ、スケジュールや連携にも対応します。一方で1ページごとにクレジットを消費し、個人ログインの裏側にあるページにはアクセスできません。
SimplescraperからThunderbitのような代替ツールに切り替えるのは、どんなときですか?
いちばん分かりやすいのは、保守に使う時間が、データ活用に使う時間を上回ったとき。サイト更新のたびに壊れたセレクタを直している、プロキシ設定を毎回いじっている、レシピを作り直している、あるいは分析よりトラブルシューティングに時間を使っている——そうなっているなら、手動のビジュアルスクレイピングではもう効率的に対応しきれていません。Thunderbitのように、実行のたびにAIでページ構造を解釈するツールなら、その保守負担の大半をなくせます。
Simplescraperでブロックされないようにするにはどうすればいいですか?
ポイントは3つ。まず、ページ間に2〜5秒の遅延を入れてリクエストのペースを落とすこと(AmazonやYelpのようなボット対策が厳しいサイトではさらに長めに)。次に、クラウドIPを強く弾くサイトではブラウザモードを代替手段として使うこと。ブラウザセッションのほうが通常アクセスに近く見えます。最後に、敏感な対象で大規模バッチを回すならプロキシローテーションを有効にすること。ただし、実際に使えるプロキシオプションがプランに含まれているかは、先に確認しておきましょう。
さらに詳しく




