データはシステムよりも長く価値を持ち続ける、まさに資産だ。
- 、ワールドワイドウェブの生みの親・コンピュータ科学者
Googleは毎日もの検索リクエストをさばいています。これらは単なる日常の疑問解決だけでなく、市場の動きや競合の状況、消費者のインサイトなど、ビジネスに役立つ膨大な情報の宝庫です。営業担当やのプロ、マーケターなら、このデータを活用して戦略を練ることができます。
もし今も手作業でコピペしているなら、そろそろ卒業のタイミングです。
この記事では、Google検索結果ページ(SERP)とは何か、そこにどんな価値あるデータが眠っているのか、そしてGoogle検索結果 スクレイピングの3つの方法(特にノーコードで使えるAIウェブスクレイパーも紹介)を分かりやすく解説します。
Google検索結果ページ(SERP)とは?
(検索エンジン結果ページ)は、Googleや、などでキーワードを入力した後に表示されるページのこと。ネット上の情報への玄関口であり、ユーザーが最初に目にする重要なページです。
SERPの最大の特徴は、リアルタイムでどんどん変化すること。アルゴリズムのアップデートや新機能、キーワードのトレンド、サイト内容の変化などが検索結果に影響します。また、検索履歴や位置情報によってパーソナライズされるため、同じタイミングでも人によって表示内容が異なります。こうした理由から、技術に詳しくない人がSERPから効率よくデータを抜き出すのはなかなか難しいのが現実です。
Googleは世界の検索エンジン市場でのシェアを誇ります。Google SERPの構造を理解し、うまく活用できるかどうかがビジネスの成否を分けるカギになります。
Google SERPにはどんなデータがある?
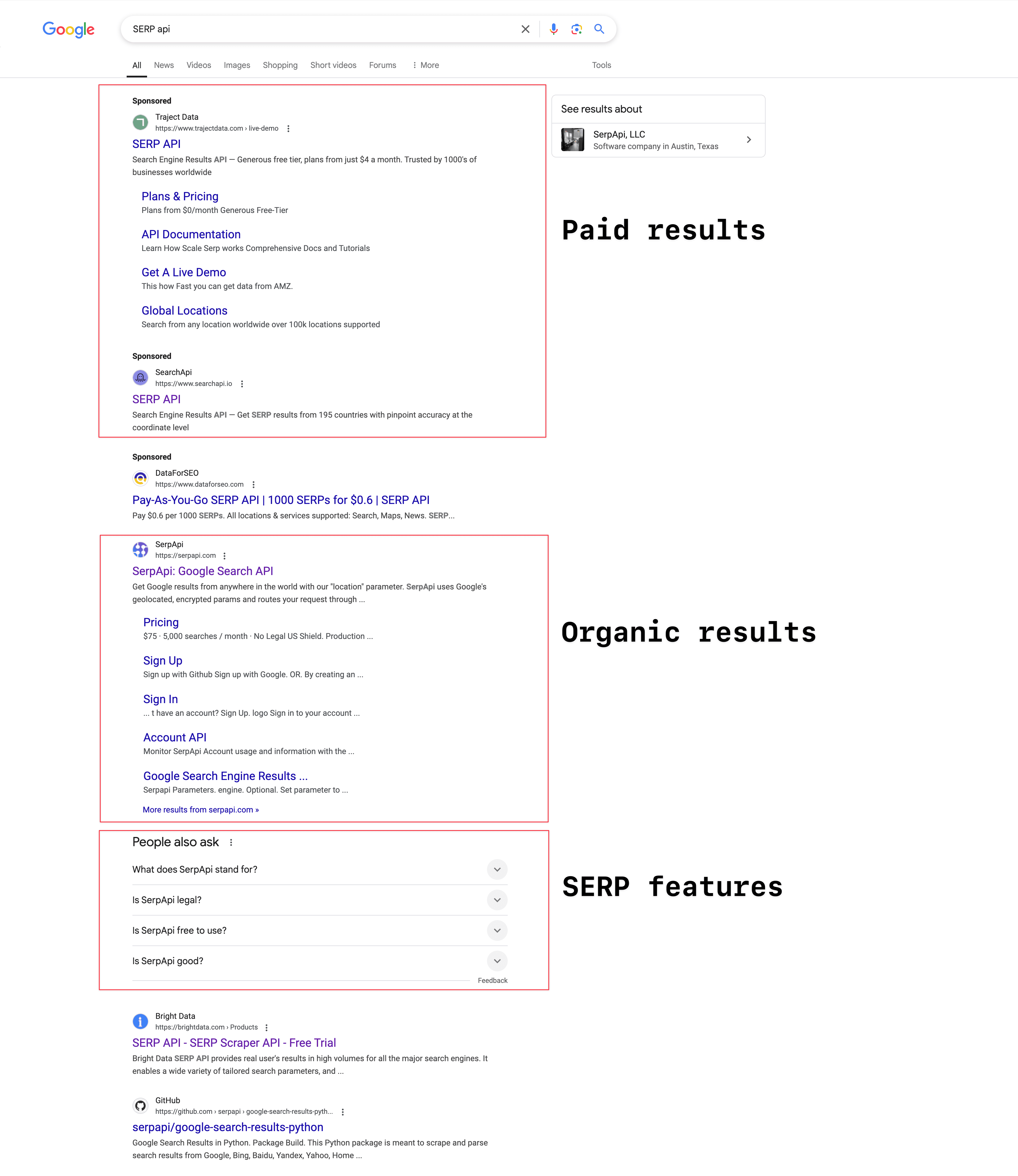
Google SERPの主な構成
検索内容によってSERPの見た目は変わりますが、主に次の3つの要素でできています:
-
広告枠(Paid Results):検索結果の上や下に「広告」や「スポンサー」と表示される部分。企業がGoogleに広告費を払って表示させています。検索内容によっては広告が出ないことも。2023年のGoogle広告収益は2,645億9,000万ドルに達しました(より)。
-
オーガニック検索結果(Organic Results):広告ではなく、関連性やページ評価に基づいて表示される通常の検索結果。タイトル、メタディスクリプション、URLが含まれます。
-
SERP機能(SERP Features):Googleがユーザー体験を高めるために導入している追加機能。フィーチャードスニペット、AIによる概要、People Also Ask(関連質問)、ナレッジパネル、ローカルパック(地域情報)、動画、画像、ショッピング情報など、日々進化しています。
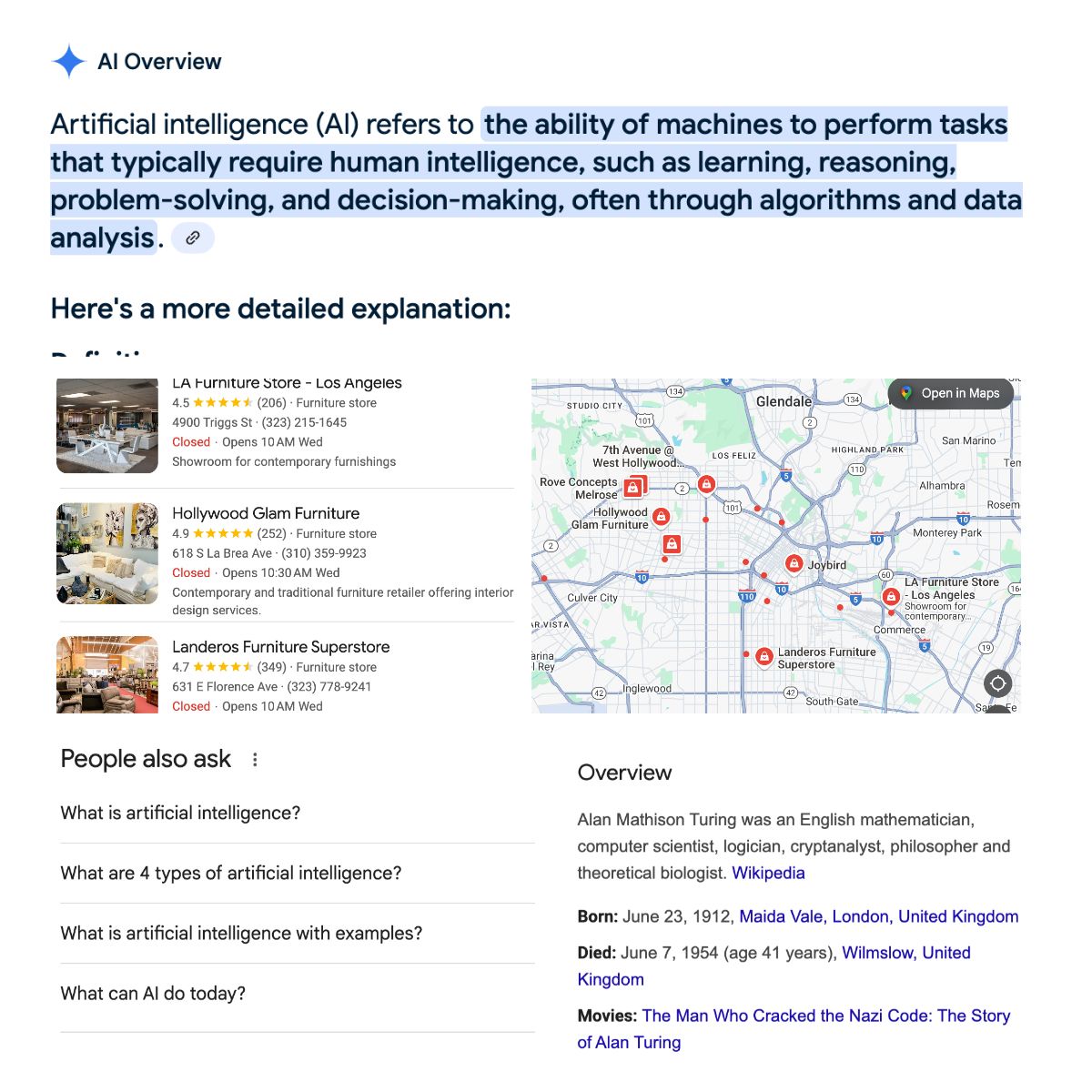
どんなデータが取れるのか?
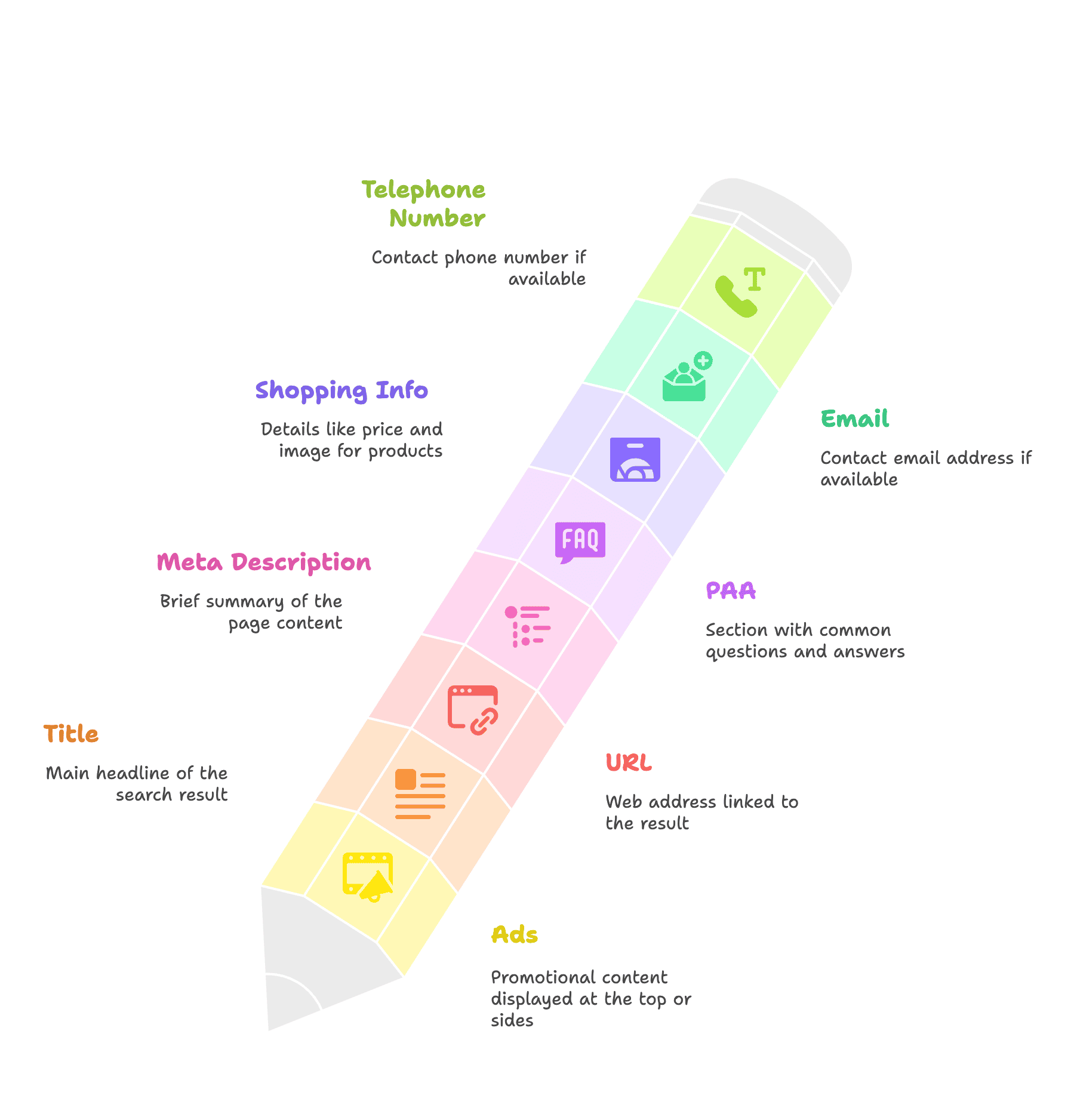
SERPの構造を知れば、どんな情報が抜き出せるかイメージしやすくなります。主なデータ例は以下の通り:
- 広告情報
- タイトル
- URL
- メタディスクリプション
- People Also Ask(PAA)ボックス
- ショッピング情報(価格・画像)
- メールアドレス
- 電話番号
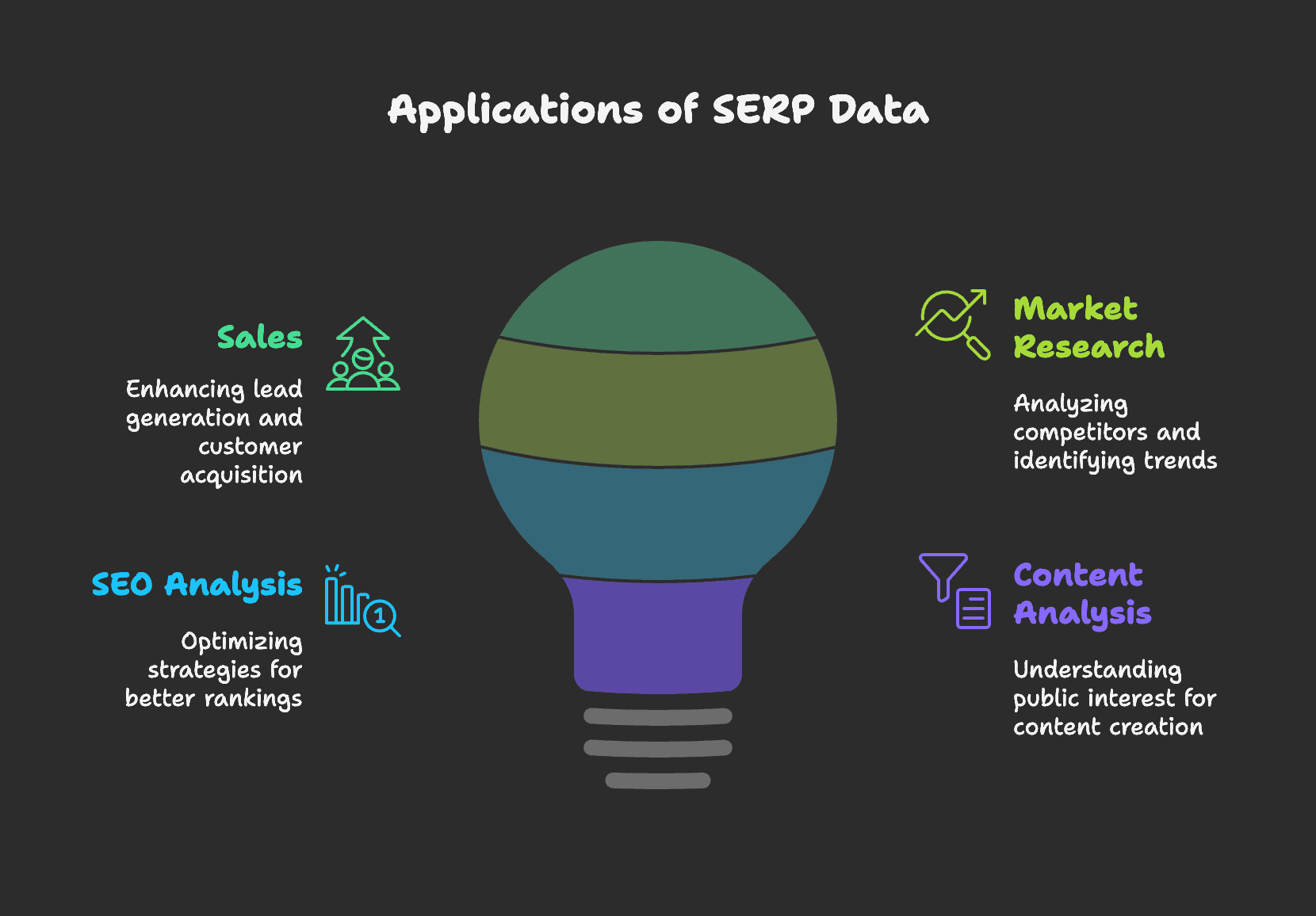
SERPデータの活用シーン
営業活動
検索クエリを工夫すれば、営業チームは効率よくリードを発掘し、他社が見逃している商機も見つけられます。Googleを活用すれば、SNS上の見込み顧客のメールアドレスや電話番号などの連絡先も抽出可能。後ほどInstagramからリードを抜き出す具体的な方法も紹介します。
市場調査
SERPデータはマーケターの業務効率化にも大活躍。たとえば競合分析では、競合他社の広告や商品情報をスクレイピングして、戦略を把握し自社の広告やマーケ施策の最適化に役立てられます。
また、SERPは市場トレンドの予測にも有効。キーワードの検索数やトレンドを分析することで、新たなビジネスチャンスを発見できます。たとえば「サステナブルファッション」の検索数が急増していれば、アパレルショップは関連商品を仕入れるタイミングかもしれません。
SEO分析
SEO担当者にとってSERPは分析の出発点。SERPデータをもとにキーワード戦略やコンテンツを最適化し、検索順位アップを目指します。
たとえばPAA(People Also Ask)をスクレイピングして関連質問を分析すれば、ユーザーが興味を持つ他の疑問を把握し、サイトコンテンツの改善に役立てられます。
コンテンツ分析
記者や編集者にとっても、Googleニュースの検索結果をスクレイピングすることで、世の中の関心事やトレンドを把握し、記事制作の参考にできます。記事抽出の具体的な方法は別ガイドで詳しく解説しています。
Google検索結果ページをスクレイピングする方法
SERPデータの活用イメージがつかめたら、次は「どうやって集めるか?」が課題です。
手作業のコピペもできますが、大量データには現実的ではありません。最近はAI技術の進化で、ウェブスクレイパーを使って効率よくデータ収集が可能になっています。ここでは3つの自動化手法を紹介します。
Thunderbit AIウェブスクレイパーを使う方法
はノーコードで使えるAIウェブスクレイパー。テンプレートを使ってもいいし、自分でカラムをカスタマイズすることも可能です。ここでは営業リード獲得の例で、Thunderbitを使ったリード抽出の流れを紹介します。
-
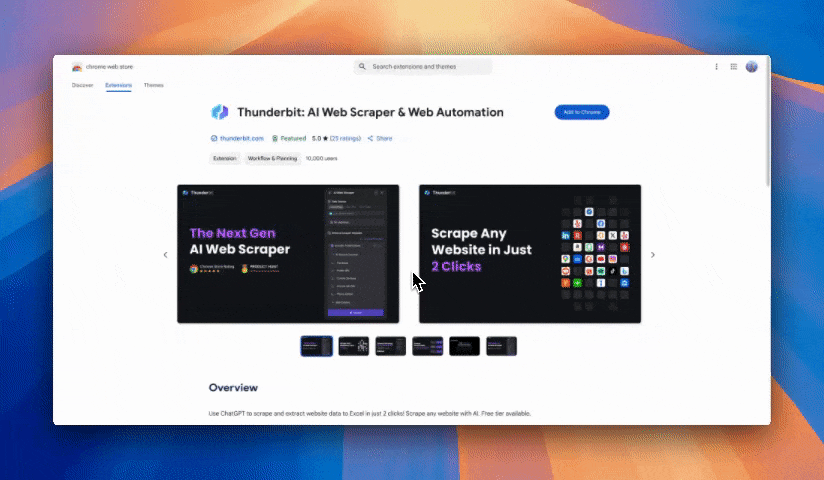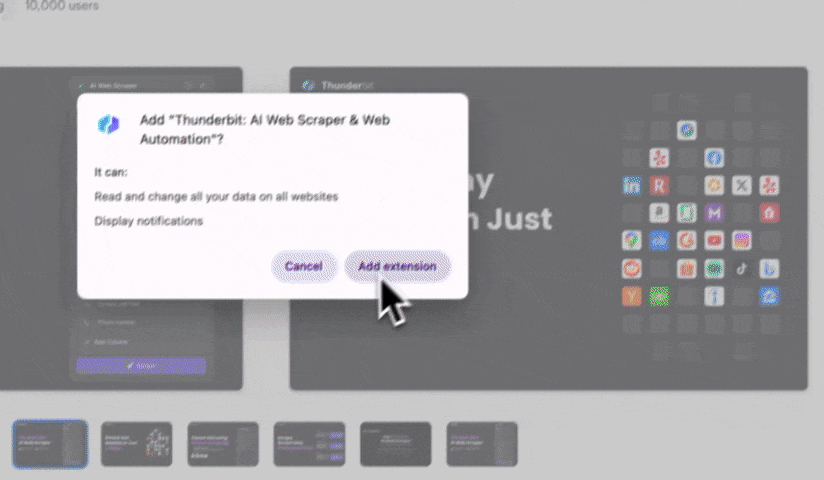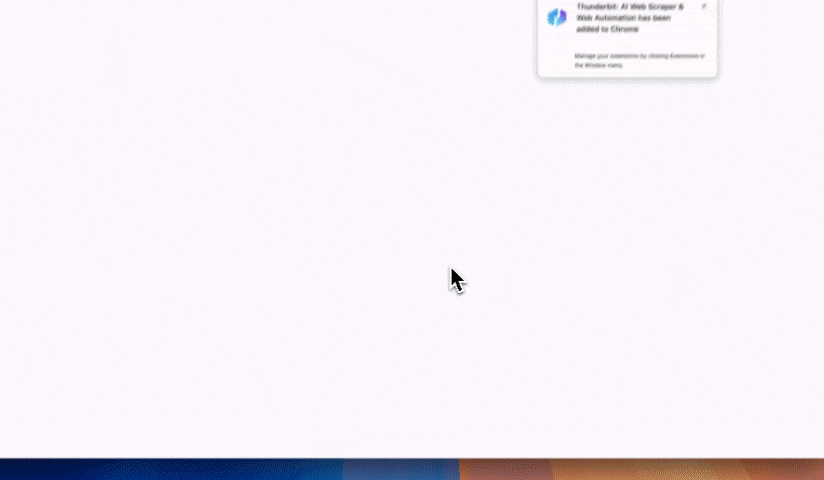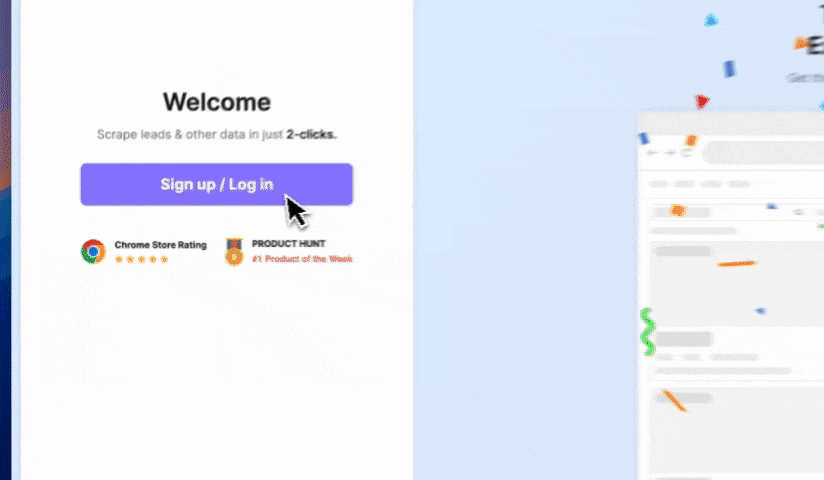
ステップ1:ThunderbitをChrome拡張機能として追加し、Googleアカウントやメールでログイン。
-
ステップ2:検索クエリを入力。
検索結果を絞り込むには、が便利です。
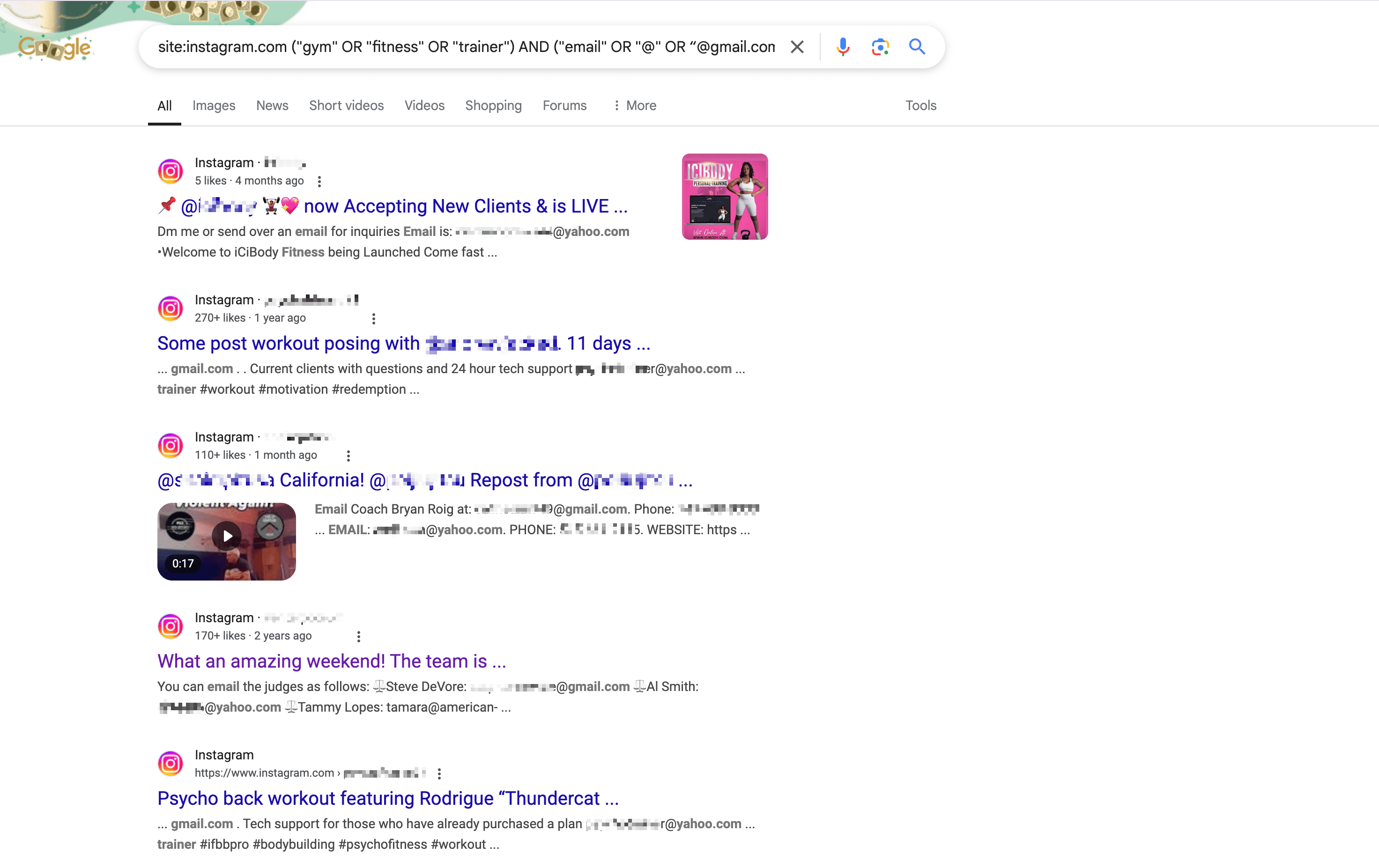
例えば、で作った「ロサンゼルスのジム関係者のInstagramメールアドレスを探す」検索クエリ例:
1site:instagram.com ("gym" OR "fitness" OR "trainer") AND ("email" OR "@" OR “@gmail.com“ or ”@yahoo.com“ ) AND ("Los Angeles" OR "LA" OR "California")このクエリをGoogleに入力して検索すれば、目的の情報が一覧で表示されます。
-
ステップ3:Thunderbitを起動してスクレイピング開始
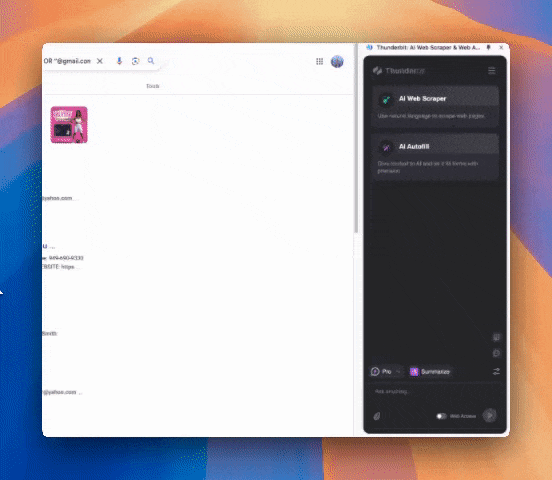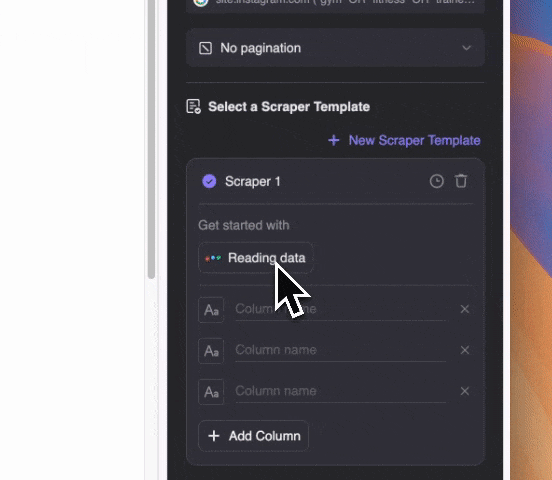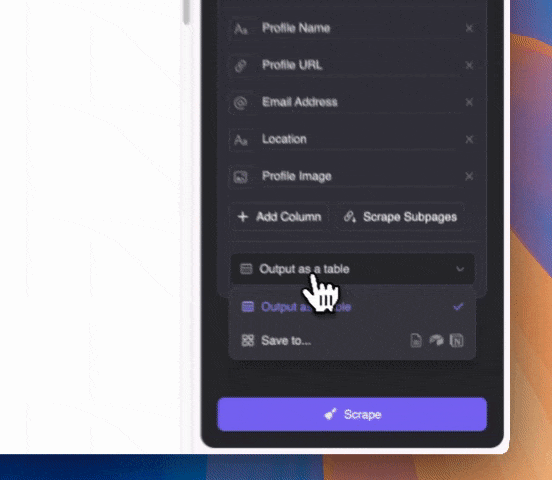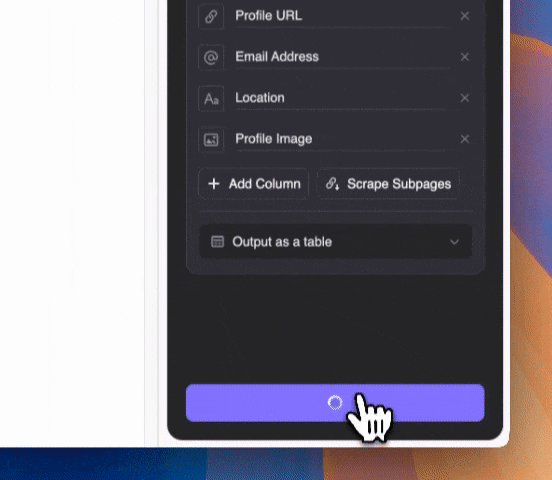 取得したい内容を自然言語で入力(「カラム詳細を追加」からさらに細かく指定もOK)。データはテーブル形式やNotion、Airtable、Google Sheetsへ直接エクスポートできます。
取得したい内容を自然言語で入力(「カラム詳細を追加」からさらに細かく指定もOK)。データはテーブル形式やNotion、Airtable、Google Sheetsへ直接エクスポートできます。ThunderbitはAIを活用しているので、Google SERPのスニペット内で他のテキストと混ざっているメールアドレスも正確に抽出できます。
あとは「スクレイプ」ボタンを押して結果を待つだけ!
従来型ウェブスクレイパーを使う方法
従来型のウェブスクレイパーでもGoogle SERPのデータを一括取得できます。ここではWebScraper.ioを例に手順を紹介します。
- Web Scraper拡張機能をインストールし、Chromeのデベロッパーツールを開く
- 「新しいサイトマップを作成」し、開始URLにGoogle検索結果ページを指定
- セレクターを設定して取得したいデータを選択
| セレクター名 | タイプ | セレクター | 複数取得 |
|---|---|---|---|
| name | テキスト | ユーザー名を選択 | いいえ ❌ |
| profile | テキスト | このページのメタディスクリプションを選択 | いいえ ❌ |
-
スクレイパーを実行し、データをエクスポート
-
取得したプロフィール文からExcelの正規表現でメールアドレスを抽出:
1text=REGEXEXTRACT(A2,"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")(A2にプロフィール文が入っている場合)
これで必要なメールアドレスを抽出できます。
この方法のデメリットは、HTMLやCSSの知識が必要なこと、そしてウェブサイトの構造が変わると(1日で変わることも)セレクターの再設定が必要になる点です。
Google公式APIやサードパーティSERP APIを使う方法
Googleはという公式APIを提供しており、プログラムから検索結果を取得できます。利用にはの作成・APIキー取得・Pythonなどでのリクエストが必要です。ただし、取得できる情報や件数には厳しい制限があり、細かいカスタマイズには向きません。
より一般的なのは、Zen SERP、SerpApi、ScrapingBeeなどのサードパーティSERPスクレイパーAPIを使う方法です。これもセットアップやリクエスト処理が必要で、InstagramプロフィールURLの取得やバイオ欄からのメール抽出など、ある程度のプログラミング知識が求められます。
1import requests
2from bs4 import BeautifulSoup
3import re
4# SerpApiの認証情報
5SERP_API_KEY = "your_serpapi_key"
6SEARCH_QUERY = "marketing consultant site:instagram.com"
7# ステップ1: SerpApiでInstagramプロフィールURLを取得
8def get_instagram_profiles(query):
9 url = "https://serpapi.com/search"
10 params = {
11 "engine": "google",
12 "q": query,
13 "api_key": SERP_API_KEY
14 }
15 response = requests.get(url, params=params)
16 data = response.json()
17 profile_urls = []
18 for result in data.get("organic_results", []):
19 link = result.get("link")
20 if "instagram.com" in link:
21 profile_urls.append(link)
22 return profile_urls
23# ステップ2: Instagramバイオ欄からメールアドレスを抽出
24def extract_email_from_bio(profile_url):
25 headers = {"User-Agent": "Mozilla/5.0"}
26 response = requests.get(profile_url, headers=headers)
27 if response.status_code != 200:
28 return None
29 soup = BeautifulSoup(response.text, "html.parser")
30 bio_section = soup.find("meta", attrs={"name": "description"})
31 if bio_section:
32 bio_content = bio_section.get("content", "")
33 emails = re.findall(r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}", bio_content)
34 return emails if emails else None
35 return None
36# 使用例
37if __name__ == "__main__":
38 profiles = get_instagram_profiles(SEARCH_QUERY)
39 print("Found Instagram Profiles:", profiles)
40 for profile in profiles:
41 emails = extract_email_from_bio(profile)
42 if emails:
43 print(f"Emails found in \{profile\}: \{emails\}")
44 else:
45 print(f"No email found in \{profile\}")3つの方法を比較
「技術知識がなく、手軽にデータを取得したい」→ が最適
「データ項目を細かく指定したい・HTML/CSSの知識がある」→ 従来型ウェブスクレイパー
「大量データを低コストで取得したい・エンジニアがいる」→ サードパーティSERP API
Googleスクレイパーは合法?
ウェブスクレイピングの合法性はよく話題になります。?という問いに対し、答えは「場合による」です。国や目的、利用規約、取得する内容によって異なり、一概には言えません。
Googleのでは自動的なスクレイピングを禁止しています。ただし、のも事実。商用か非営利かなど、利用目的も重要な判断材料となります。
倫理的かつ合法的にスクレイピングを行うには、利用規約をよく読み、公開データのみを対象にし、違法利用を避けることが大切です。大規模なスクレイピングを行う場合は、専門家に相談するのが安心です。
まとめ
データは「」とも呼ばれ、Google SERPはまだまだ活用しきれていない金鉱です。SERPデータを素早くビジネス戦略に変換できる人が、競争の激しい市場で優位に立てます。リード獲得、市場調査、SEO対策など、活用シーンは多岐にわたります。
技術力・予算・データ量・用途に合わせて、最先端のAIウェブスクレイパーThunderbit、従来型スクレイパー、SERP APIの3つの方法を紹介しました。
「ワンクリックで全データを取得したい」ビジネスパーソンにはThunderbitが断然おすすめ。今すぐ。
FAQ
1. Google検索結果ページ(SERP)からどんなデータが抽出できますか?
タイトル、URL、メタディスクリプション、広告、フィーチャードスニペット、ショッピング情報(価格・画像)、People Also Ask、メールアドレス、電話番号など多彩なデータが取得可能です。
2. Thunderbitは従来型ウェブスクレイパーやSERP APIと何が違いますか?
はノーコード・AI搭載のChrome拡張機能で、自然言語で欲しいデータを指定するだけで構造化データを抽出できます。従来型は技術的な設定が必要、APIはコーディングやデータ取得制限があります。
3. ThunderbitでGoogle検索結果をスクレイピングするのに技術知識は必要ですか?
不要です。Thunderbitは非エンジニア向けに設計されており、欲しいデータを日本語で説明するだけでAIが自動で抽出します。
4. 取得したデータはGoogle SheetsやNotionなどにエクスポートできますか?
はい。ThunderbitならGoogle Sheets、Airtable、Notionへの直接エクスポートや、テーブル形式でのダウンロードも可能です。
5. Google SERPデータの実用的な活用例は?
リード獲得、競合調査、SEO分析、トレンド把握、コンテンツ企画などが代表例です。営業チームは連絡先抽出、マーケターは広告配置分析、SEO担当はキーワードや関連クエリの追跡などに活用できます。