

EC業界の動きはとにかく速く、競合の値付けを見張り、新商品の投入を追い、レビューの傾向を読み解くことは、もはや「やれたらいい」ではなく、生き残りの最低条件になっています。とはいえ、こうした情報集めは長らく、込み入ったツールや手のかかるスプレッドシート、あるいは開発者向けのPythonスクリプトと格闘する作業でした。最近はplaywrightのようなブラウザ自動化ツールが登場し、ウェブスクレイピングもずいぶん進歩しましたが、ビジネスユーザーから見れば技術のハードルはまだまだ高いまま。そんな状況に風穴を開けたのが、AIを積んだThunderbitのようなツールで、プログラミング抜きで誰でも数分で欲しいデータに届くようになりました。
この記事では、playwrightを使ったウェブスクレイピングの基本(題材はeBay)、初心者がはまりやすい落とし穴、そしてThunderbitのAIウェブスクレイパーが業務をどこまで身軽にしてくれるかを、営業・マーケ・オペレーション担当の方に向けて噛み砕いて紹介します。「Pythonエンジニアになる気はない、とにかくデータだけ欲しい」——そんな方にこそ読んでほしい内容です。
Playwrightとは?初心者向けの概要
まずは土台から。playwrightって、そもそも何でしょう?
playwrightはMicrosoftが手がけたブラウザ自動化フレームワークです。ウェブブラウザをプログラムから遠隔操作できるツールで、ボタンのクリックやフォーム入力はもちろん、JavaScriptで動的に表示されるコンテンツの取得まで自動化できます。しかもChromium、Firefox、WebKitといった複数ブラウザ、さらにPython、JavaScript/Node.js、Java、C#など多彩な言語に対応しているのが大きな魅力です。
なぜスクレイピングで重宝されるのか。従来のrequestsやBeautifulSoupは静的なページには滅法強い反面、JavaScriptで中身を組み立てる今どきのサイトにはめっぽう弱いんです。その点playwrightは、動的な要素も人間の操作さながらに扱えます。たとえるなら、文句も言わず24時間働き続けるロボットのインターンのような存在です。
SeleniumやPuppeteerとの違いは?
- Selenium: ブラウザ自動化の元祖。対応言語は幅広いものの、動作はやや重め。
- Puppeteer: Google製でChromium系に特化。速いがChrome/Chromium専用。
- playwright: 当初からクロスブラウザ前提で設計。Seleniumより速く、APIも今風。いまや自動化・スクレイピングの主役になりつつあります(参考データ)。
Playwrightがウェブスクレイピングに最適な理由
営業やオペレーション、EC担当者がplaywrightに目を向けるのは、なぜでしょうか。
playwrightの強みは、ここにあります。
- JavaScript主体のサイトも平気: eBayのように、商品情報が動的に出てくるサイトもしっかり捌けます。
- ユーザー操作の自動化: 「次のページ」のクリック、スクロール、ログインまで、人間っぽく再現。
- ヘッドレスモード対応: ブラウザ画面を出さず、裏方として静かに動かせます。
- 賢い待機機能: ページの読み込みが終わるのを自動で待ってから取得するので、エラーや取りこぼしを大きく減らせます(詳細はこちら)。

実践例:
たとえば自社EC担当が、eBayでノートPCの価格を定期的にウォッチしたいとします。playwrightなら「laptop」で検索し、商品名と価格を自動で抜き出し、複数ページもループでまとめて取得できます。こうして集めたデータはダイナミックプライシング戦略の土台になり、競合のセールにも即座に対応できるわけです(購入前に81%がネットで調査)。
主なビジネス活用例:
- 価格モニタリング: 競合価格を追い、自社価格をリアルタイムで調整
- 商品カタログの抽出: 自社リストの作成・更新
- 競合分析: トレンドや在庫状況、プロモーション手法の把握
- リード獲得: ディレクトリやマーケットプレイスから出品者情報・連絡先を抽出
自動の価格モニタリングを取り入れた企業では、売上が5〜25%伸びたという報告もあります(出典)。
Playwright Pythonのセットアップ手順
それでは、実際にplaywright pythonを動かしてみましょう(初心者の方にも分かるよう、丁寧に進めます)。
1. 事前準備
- Python 3.7以上(
python --versionで確認) - pip(Pythonのパッケージ管理ツール)
2. Playwrightとブラウザエンジンのインストール
ターミナルやコマンドプロンプトで次を実行します:
pip install playwright
python -m playwright install
これでplaywright本体と各種ブラウザエンジン(Chromium, Firefox, WebKit)が一式ダウンロードされます。
3. 「Hello World」スクリプト
手始めに、eBayのトップページを開いてみましょう:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True) # ヘッドレスモードで起動
page = browser.new_page()
page.goto("https://www.ebay.com/")
print(page.title())
browser.close()
このスクリプトを走らせると、eBayのページタイトルがターミナルに出力されます。これで自動化の第一歩はクリアです。
インストール時によくあるトラブルと対処法
どんなツールにもつまずきはつきもの。playwrightで起こりがちな問題と、その対処法を挙げておきます:
- Pythonやpipが見つからない: PythonがシステムのPATHに含まれているか確認
- 権限エラー: 管理者権限でターミナルを開く、Mac/Linuxなら
sudoを利用 - ブラウザバイナリが見つからない:
python -m playwright installを再実行 - ファイアウォールやプロキシの問題: 社内ネットワークでダウンロードが弾かれる場合は自宅回線で試す
行き詰まったら、公式トラブルシューティングガイドが頼りになります。
実践:PlaywrightでeBayの商品データをスクレイピング
ここからは、eBayから商品名と価格を取り出す手順を具体的に追っていきます。
1. 検索ワードの設定
今回は「laptop」で検索することにします。
2. スクリプト例
from playwright.sync_api import sync_playwright
search_term = "laptop"
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto(f"https://www.ebay.com/sch/i.html?_nkw={search_term}")
page.wait_for_selector("h3.s-item__title") # 商品が表示されるまで待機
page_num = 1
results = []
while page_num <= 2: # 例として2ページ分取得
print(f"Scraping page {page_num}...")
titles = page.locator("h3.s-item__title").all_text_contents()
prices = page.locator("span.s-item__price").all_text_contents()
for title, price in zip(titles, prices):
results.append({"title": title, "price": price})
print(f"{title} --> {price}")
# 次のページへ
next_button = page.locator("a[aria-label='Go to next search page']")
if next_button.count() > 0:
next_button.click()
page.wait_for_selector("h3.s-item__title")
page_num += 1
page.wait_for_timeout(2000) # サーバーに優しい遅延
else:
break
print(f"Found {len(results)} items in total.")
browser.close()
このスクリプトのポイント
- ヘッドレスブラウザを立ち上げ、「laptop」でeBayを検索し、商品タイトルが出るまで待機
- ページ内の全商品名と価格を抽出
- 「次のページ」ボタンをクリックして複数ページを取得
- サーバー負荷を避けるため、ほどよい遅延を挟む
playwrightの基本リズムは「移動→待機→抽出→繰り返し」。これさえつかめば応用が利きます。
ページ送りや動的コンテンツへの対応
近頃のECサイトは無限スクロールや動的読み込みが当たり前ですが、その多くはplaywrightのwait_for_selectorで対応できます。ただし、
- 「次へ」ボタンのクリック
- AJAXコンテンツの待機:
wait_for_selectorやwait_for_timeoutを活用 - 無限スクロール: プログラムでスクロールし、新しい商品が出るのを待つ
といった部分は、多少の試行錯誤と粘りが必要になります。
アンチスクレイピング対策への対応
eBayのような大手サイトは、スクレイパー対策にも力を入れています。代表的な防御は次のとおり:
- CAPTCHA
- ユーザーエージェントチェック
- リクエスト制限やIPブロック
playwrightは実ブラウザをまねるため比較的かわしやすいものの、本格的に大量取得をするなら、
- ユーザーエージェントのローテーション
- プロキシの利用
- リクエスト間隔のランダムな遅延
といった工夫が欠かせません。それでも規模が大きくなれば、ブロックされることもあります(eBayのレート制限例)。
Playwright自動化の初心者が直面する課題
強力なplaywrightですが、ノーコードツールのように「触ればすぐ動く」わけではありません。初心者がつまずきやすいのは、次のあたりです:
- プログラミング知識が前提: Python、HTML/CSSセレクタ、デバッグの基礎はどうしても必要
- スクリプトの保守: サイトのレイアウトが変わると、スクリプトが動かなくなる
- 動的コンテンツ対応: AJAXや無限スクロール、タイムアウト管理が悩ましい
- リソース消費: ヘッドレスブラウザはCPUもメモリも食う
- アンチボット対策: CAPTCHAやプロキシ管理など、追加のひと工夫が要る
私自身、セレクタの直しや「なぜかデータが取れない」原因探しで、夜更かしした覚えが何度もあります。スクレイパーの通過儀礼のようなものですが、誰もがそこまで時間と情熱を注げるわけではありませんよね。
Thunderbit:コーディング不要のAIウェブスクレイピング
そこで新しい選択肢として、Thunderbitを紹介します。
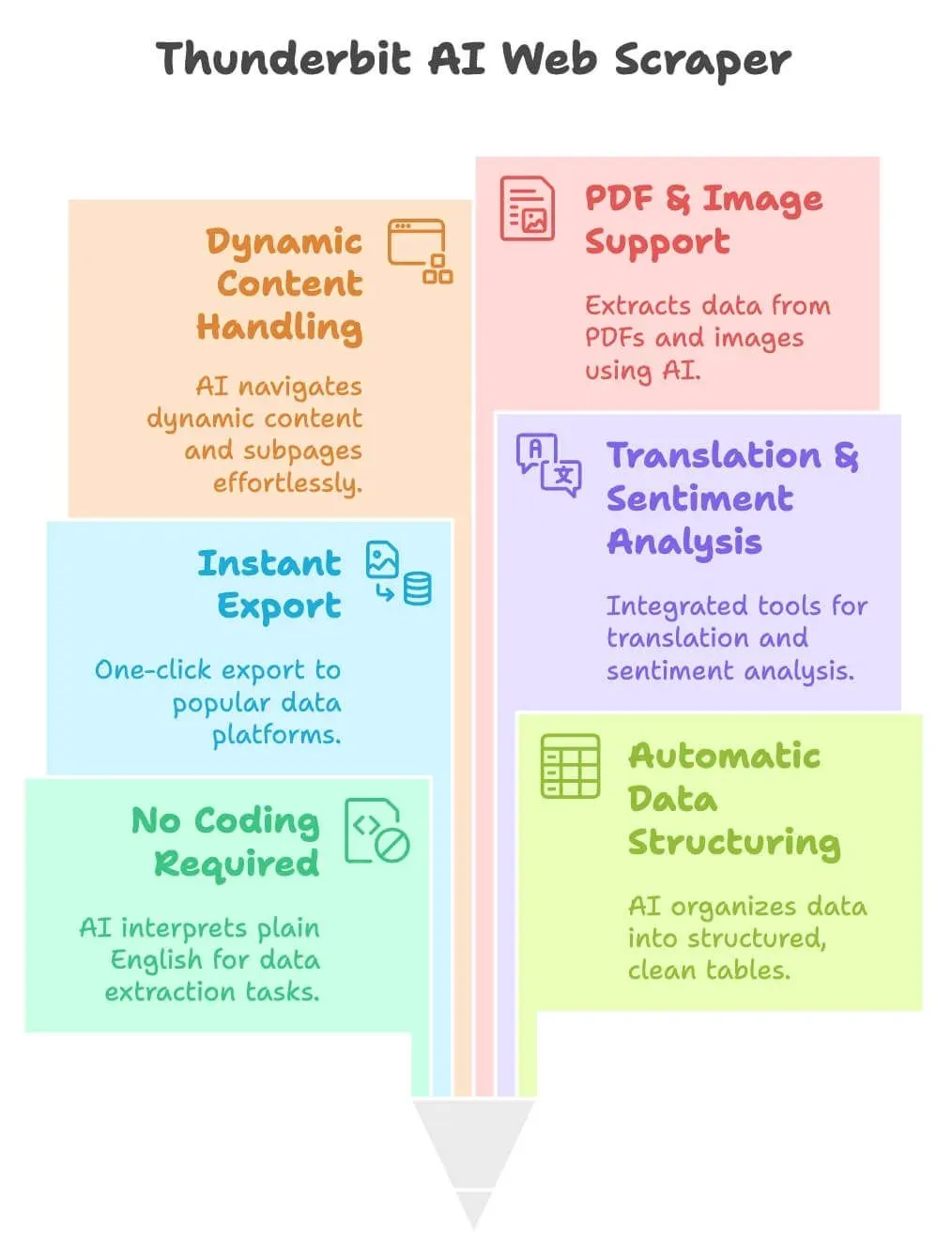
Thunderbitは、ビジネスユーザーのために設計されたAIウェブスクレイパーのChrome拡張機能です。営業・マーケ・オペレーション担当の「コードは書きたくない、データだけ欲しい」をそのまま叶えてくれます。
- コーディングは一切不要: 欲しいデータを日本語や英語で説明するだけ。抽出方法はAIが判断
- データ構造も自動で提案: 商品名・価格・評価など、AIが最適なカラムを提案し、整った表にまとめてくれる
- ワンクリックでエクスポート: Excel、Googleスプレッドシート、Airtable、Notionへ即出力
- 翻訳・感情分析も内蔵: 商品説明の翻訳やレビューのポジ/ネガ判定も、ワークフロー内で自動化
- 動的コンテンツ・ページ送り・サブページも自動対応: 「次へ」ボタンや無限スクロール、サブページ遷移もAIがさばく
- PDFや画像もOK: ウェブページに限らず、PDFや画像からもOCR+AIでデータ抽出
まるで多言語対応のデータアシスタントが、疲れも見せずに単純作業を引き受けてくれる——そんな感覚です。
ThunderbitとPlaywrightの比較
eBayスクレイピングを題材に、両者を並べてみましょう:
| 項目 | Playwright(コード) | Thunderbit(AI・ノーコード) |
|---|---|---|
| セットアップ時間 | 30分以上(インストール・コーディング・デバッグ) | 5分以内(拡張機能インストール→「AIでカラム提案」→「スクレイピング」) |
| 必要スキル | Python、HTML/CSSセレクタ、デバッグ力 | 不要。ウェブ閲覧ができればOK |
| 保守性 | サイト変更時は手動でスクリプト修正 | AIが自動でレイアウト変化に対応。テンプレートも随時更新 |
| 動的コンテンツ・ページ送り | コードで自力対応 | AIが自動で処理 |
| データ拡張 | 翻訳や感情分析は外部APIや追加コードが必要 | UIでワンタッチ。翻訳・分類・感情分析も内蔵 |
| エクスポート | CSV/JSON出力やAPI連携を自作 | Excel、Google Sheets、Airtable、Notionにワンクリック出力 |
| スケーラビリティ | 並列処理やプロキシで拡張可能だがリソース消費大 | 通常のビジネス用途(数百〜数千件)はクラウドで自動処理 |
| コスト | 無料(オープンソース)だが開発工数やプロキシ費用が発生 | サブスクリプション(月額約9〜15ドル〜)。小規模なら無料枠あり |
ビジネスユーザーにとって、playwrightは「学習・保守・コーディング」がセットでついてきます。一方Thunderbitなら、「数クリックで構造化データ+翻訳・感情分析」まで一気に片付くわけです。
高度なデータ処理:Thunderbitの翻訳・感情分析機能
Thunderbitがビジネスチームでとりわけ効いてくるのが、この部分です。
たとえばeBayの多言語レビューを分析したいとき、playwrightだと次の手順を踏むことになります:
- レビューをスクレイピング
- 各レビューを翻訳APIに送るコードを書く
- さらに感情分析APIを呼ぶコードを足す
- 結果を1つのスプレッドシートに統合
Thunderbitなら、UIで「翻訳」「感情分析」をONにするだけ。AIがレビューを自動で翻訳し、ポジティブ/ネガティブ/ニュートラルに振り分け、整った表で出してくれます。
ビジネスでのメリット例:
- グローバル市場分析: どんな言語のレビューや商品情報も、その場で翻訳
- 顧客フィードバックの分類: トレンドや課題をひと目で把握
- 意思決定の迅速化: 複数ツールを行き来せず、すぐ実用的なインサイトを得られる
かつて開発者やデータアナリストの手を借りていた作業が、いまや数クリックで完結します。
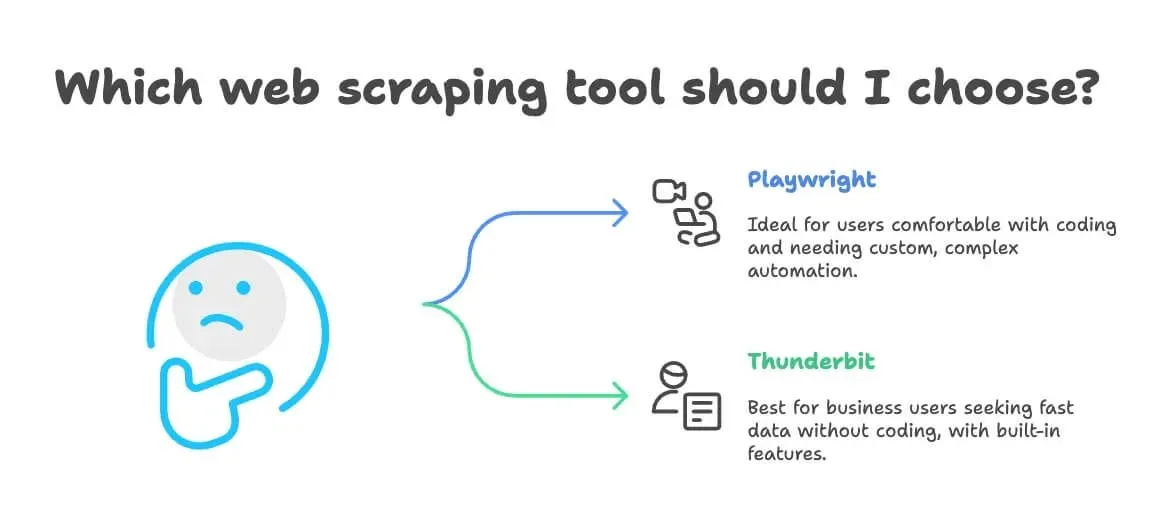
PlaywrightとThunderbit、どちらを選ぶべき?
正直なところ、どんな場面にも効く唯一の正解はありません。それを踏まえたうえで、私のおすすめはこうです:
playwrightが向いているのは…
- コーディングに慣れている、または開発チームが手元にある
- ログインやCAPTCHA対応、社内システム連携など、込み入った自動化が必要
- 柔軟性ときめ細かな制御を何より優先したい
- 大規模なデータ取得や、システムへの組み込みが前提
Thunderbitが向いているのは…
- とにかく「今すぐデータが欲しい」ビジネスユーザー
- コードを書くのも保守するのも避けたい
- 翻訳・感情分析・データ構造化までまとめて済ませたい
- ExcelやGoogle Sheets、Airtable、Notionへ直接出したい
- 営業・マーケ・EC運用・不動産など、リードリストや価格調査、カタログ抽出が主な用途
実際、私が知る営業・オペレーション担当の多くは、「プログラミングの勲章」より「すぐ使えるデータ」を求めています。Thunderbitは、まさにそこに応えるためのツールです。
まとめ:ビジネスで使えるウェブスクレイピングの選び方
2025年版おすすめウェブスクレイピングツール&ソフトウェア Get Started Free
要点を整理すると、こうなります:
- playwrightは、強力で柔軟なウェブスクレイピング・ブラウザ自動化ツール。技術者や、細部まで制御したい人に最適。
- Thunderbitは、AI搭載・ノーコードのウェブスクレイパー。ビジネスユーザー向けに、データ抽出から翻訳・感情分析まで数クリックで完結。
開発好きにとってplaywrightは心強い武器ですが、「営業・マーケ・オペレーションで結果がすべて」という人には、Thunderbitが最短ルートになります。
Thunderbitを試してみませんか?
Thunderbit Chrome拡張機能から無料で始められます。他ツールとの比較はThunderbitブログもあわせてチェックしてみてください。
迷っている方も、結局のところ大切なのは「必要なデータを、欲しい形式で、手間なく手に入れられること」。効率のよいスクレイピングで、あなたの業務をもっとスマートにしていきましょう。
ウェブスクレイピングやAI自動化の最新ノウハウは、Thunderbitブログの他の記事もぜひのぞいてみてください。データスクレイピングとは?2025年版ガイドやAIでAmazon商品・レビューをスクレイピングする方法もおすすめです。
ビジネスユーザー向けAIウェブスクレイパーを試す Get Started Free




