正直に言うと、「重要なデータ」がぎっしり詰まったPDFを渡されて、それを魔法のようにスプレッドシートに変えてほしいと言われるたびに1ドルもらえていたら、一生分のコーヒー代くらいは余裕でまかなえていたはずです(ついでにChrome拡張もいくつか買えたでしょう)。PDFはあらゆるところにあります。営業契約書、商品カタログ、研究論文、請求書……挙げればきりがありません。でも、そこに入っているデータを実際に「使う」段階になると、楽しいはずの作業が一気に頭痛の種に変わります。
私も現場で何度も苦労してきました。コピーして、貼り付けて、整形して、レイアウトが崩れたり画像やリンクが跡形もなく消えたりすると、もうお手上げ……ということもありました。ですが、朗報があります。PDFスクレイピングの世界は、特にAI搭載ツールの登場によって劇的に変わりました。数字の再入力に何時間も費やしたり、壊れた表に振り回されたりするのにうんざりしているなら、まさにここがその答えです。PDFスクレイピングとは何か、なぜ重要なのか、そしてのようなツールがどうやってそれを(ついに)面倒のないものにしているのかを見ていきましょう。
PDFスクレイピングとは? PDFデータ抽出の基本を理解する
まずはシンプルにいきましょう。PDFスクレイピングとは、要するに「PDFファイルから構造化データを自動で取り出すこと」です。PDFスクレイパーは、必要な情報——テキスト、表、画像、リンクなど——を抽出して、Excel、Google Sheets、データベースのように実際に使える形式にしてくれるツール(ソフトウェア、拡張機能、サービス)です。
ただし、ここで難しいのが、PDFはWebページやExcelファイルとは違うという点です。PDFは、どこで開いても同じ見た目になるように作られた、いわばデジタル版の印刷物です。コンピューターが簡単に分解できるようには設計されていません。選択可能なテキストを含むPDFもあれば、スキャン画像だけのPDFもあります(その場合はOCR、つまり光学式文字認識が必要です)。さらに、レイアウトもバラバラです。つまり、PDFをスクレイピングするのは単なる文字のコピペではなく、レイアウトやフォント、時には隠れたメタデータまで含めたパズルを解読する作業なのです。
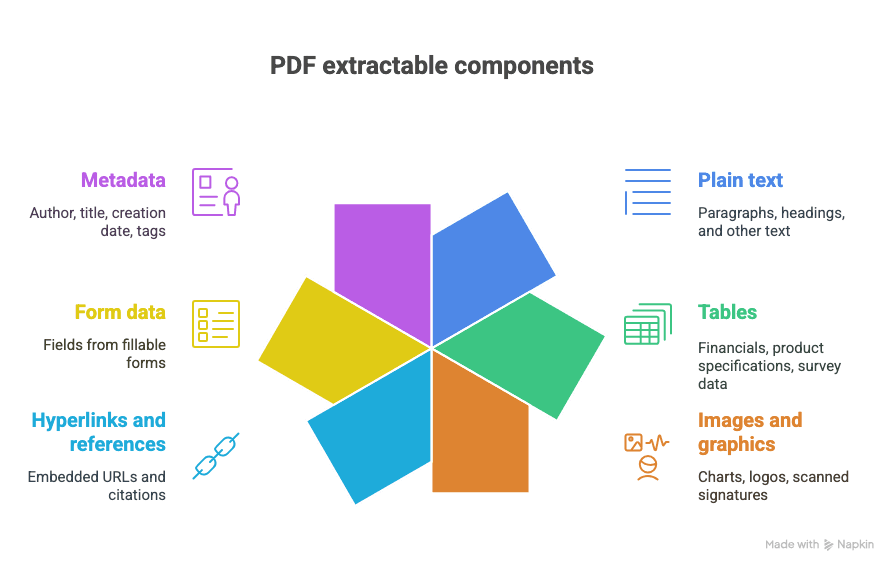
PDFから何が抽出できるのでしょうか?
- プレーンテキスト(段落、見出しなど)
- 表(財務データ、製品仕様、アンケート結果など)
- 画像とグラフィック(チャート、ロゴ、スキャンした署名など)
- ハイパーリンクと参照(埋め込みURL、引用文献など)
- フォームデータ(入力可能フォームの項目)
- メタデータ(作成者、タイトル、作成日時、タグ)
そしてもちろん、これらが全部ひとつのカオスな文書にごちゃ混ぜで入っていることも珍しくありません。
なぜPDFスクレイピングが重要なのか:実際の活用例とビジネス上のメリット
では、なぜわざわざPDFをスクレイピングするのでしょうか。理由はシンプルで、誰もがPDFを使っており、その中のデータがビジネスにとって非常に重要だからです。PDFスクレイピングが真価を発揮する場面を見てみましょう。
| 活用例 | 手作業の負担 | PDFスクレイパーを使うと | 時間とミスの削減 |
|---|---|---|---|
| 営業リード抽出 | 提案書やイベントPDFから連絡先を何時間もかけて転記し、リードを見落とすリスクもある | すべてのリードをすぐにスプレッドシートへ抽出 | 80〜90%高速化、ミス削減 |
| ECの商品データ | サプライヤーPDFから商品仕様を何日もかけて入力し、整形も大変 | CSVやSheetsに一括抽出 | 95%以上の時間削減、データの一貫性向上 |
| 研究データ分析 | 学術論文の表を何週間もかけて転記し、タイプミスのリスクが高い | 表、参考文献、スキャン文字まで抽出 | 80%の時間削減、精度向上 |
数字で見てみましょう。
- 毎年が作成されています。
- が、情報共有の主要形式としてPDFを使っています。
- PDFのデータ入力のような手作業のデジタル事務作業は、を奪っています。
- 自動化ツールを使えば、エラー率をまで下げられます。
営業、EC、研究の分野にいるなら、PDFデータ抽出の自動化は「あると便利」ではなく、競争優位そのものです。
従来のPDFスクレイピング手法:課題と限界
率直に言って、PDFからデータを取り出す昔ながらの方法は……あまり良くありません。多くの人が試してきた方法と、その面倒さを見てみましょう。

1. 手作業のコピー&ペースト
- つらい点: 書式が崩れる、表がぐちゃぐちゃになる、画像やリンクが消える、そして最後には頭痛だけが残る。
- 労力コスト: 非常に高い。PDFが5,000件あって、1件1分だとしても、80時間以上が二度と戻らない時間になります。
- エラー率: 5〜10%。タイプミス、行の抜け、誤削除……身に覚えがあるはずです。
2. Word/Excelに変換してから整える
- つらい点: シンプルな文書ならうまくいくこともありますが、複雑なレイアウトや表は崩れがちです。結局、あとで整え直す必要があります。
- 画像/リンク: たいてい失われます。
- 狙った抽出: ほぼ無理です。必要な部分だけではなく、文書全体が出てきます。
3. カスタムスクリプト(Pythonなど)
- つらい点: コーディングできる人が必要です(もしくはすぐ連絡できる人)。PDFの形式が変わるたびにスクリプトを調整しなければなりません。スキャンPDFなら、なおさら大変です。
- 保守性: 高コストです。請求書テンプレートをベンダーが少し変えるだけで、スクリプトが壊れます。
- 拡張性: 非技術者にはかなり厳しいです。
4. オンライン変換ツール
- つらい点: 単発作業には簡単ですが、機密文書を第三者のサーバーにアップロードしなければなりません(コンプライアンス上の懸念が出ます)。何を抽出するかの自由度も限られています。
- 書式: 当たり外れがあります。節約できた時間以上に、整形に時間を取られることもあります。
結論: 従来の方法は遅く、ミスが起こりやすく、スケールもしません。だからこそ、多くのチームが「まあ仕方ない」と受け入れてしまっているのですが、その代償は生産性の大きな損失です。
PDFスクレイピングの現代的な解決策:コードからノーコードへ
ありがたいことに、もう暗黒時代に戻る必要はありません。より賢く、より速く、より使いやすいPDFスクレイピングの選択肢が一気に増えました。
1. コーディング用ライブラリ(開発者向け)
- 例: 、、。
- 強み: とても柔軟で、大量処理を自動化できます。しかも無料(オープンソース)です。
- 弱み: 初期設定に時間がかかる、プログラミングスキルが必要、壊れやすい(新しい形式で動かなくなる)、OCRや画像対応が弱い。
2. オンラインPDF変換ツール
- 例: 、、。
- 強み: 準備不要、非技術者でも簡単、小規模作業ならすばやい。
- 弱み: カスタマイズ性が低い、プライバシー面の不安、書式エラー、ファイルサイズやページ数の制限。
3. AI搭載PDFスクレイパー
- 例: 、Nanonets、Docparser。
- 強み: コーディング不要、テキスト/表/画像/リンクに対応、AIが抽出項目を提案、バッチ処理対応、Sheets/Notion/Airtableと連携可能。
- 弱み: クレジットやページ数の制限がある場合がある、インターネット接続が必要、複雑な文書では学習コストがかかることもある。
PDFスクレイピングツール比較:どの方法が自分に合っているか?
| ツール/手法 | 設定 | 向いている用途 | 抽出対象 | カスタマイズ性 | 費用 |
|---|---|---|---|---|---|
| Tabula(Tabula-py) | 中程度(UI/コーディング) | PDF内の表 | 表 | ある程度 | 無料 |
| PDFMiner | コーディング必須 | 文字中心のPDF | テキスト | あり(コードで) | 無料 |
| PyPDF2 | コーディング必須 | シンプルなテキスト/メタデータ | テキスト、メタデータ | あり(コードで) | 無料 |
| Smallpdf/オンライン変換 | なし(Webベース) | すばやい変換 | 文書全体(Word/Excel) | なし | フリーミアム |
| Thunderbit | 2クリックで導入 | ビジネスユーザー、チーム | テキスト、表、画像、リンク | あり(AIプロンプト) | フリーミアム(Proは月額16.5ドル) |
Thunderbitの紹介:AI PDFスクレイパーChrome拡張機能
ここで紹介したいのが、私の仕事を、そして多くのビジネスユーザーの仕事を格段に楽にしてくれたツール、です。
Thunderbitの何が違うのか?
- 2クリックで抽出: ChromeでPDFを開き、Thunderbit拡張機能をクリックするだけ。あとはAIにおまかせです。
- AIによる項目提案: Thunderbitの「AIで列を提案」機能がPDFを読み取り、「名前」「メールアドレス」「価格」など、必要になりそうな列を提案します。
- 画像・リンク・表に対応: 単なるテキストだけではありません。Thunderbitは画像やハイパーリンクを抽出でき、スキャン文書にはOCRも実行できます。
- カスタムプロンプト: 電話番号や商品仕様だけが必要ですか? カスタム指示を追加すれば、Thunderbitがその項目に集中して抽出します。
- どこへでもエクスポート: データをそのままExcel、Google Sheets、Airtable、Notionへ送れます。CSVの手間はもう不要です。
- 一括処理とサブページ抽出: PDFやリンクのリストがありますか? Thunderbitならまとめて処理できます。
- ビジネス向けの信頼性: 正確性、プライバシー、実務フローを前提に設計されています。
一言でいえば、データ入力が好きなデジタル版のインターンを雇うようなものです(しかも疲れ知らずです)。
Thunderbitを使ってPDFからデータを抽出する方法:ステップごとのガイド
どれだけ簡単か、実際に見てみませんか? 私がThunderbitを使ってPDFを構造化された使えるデータに変える手順はこちらです。
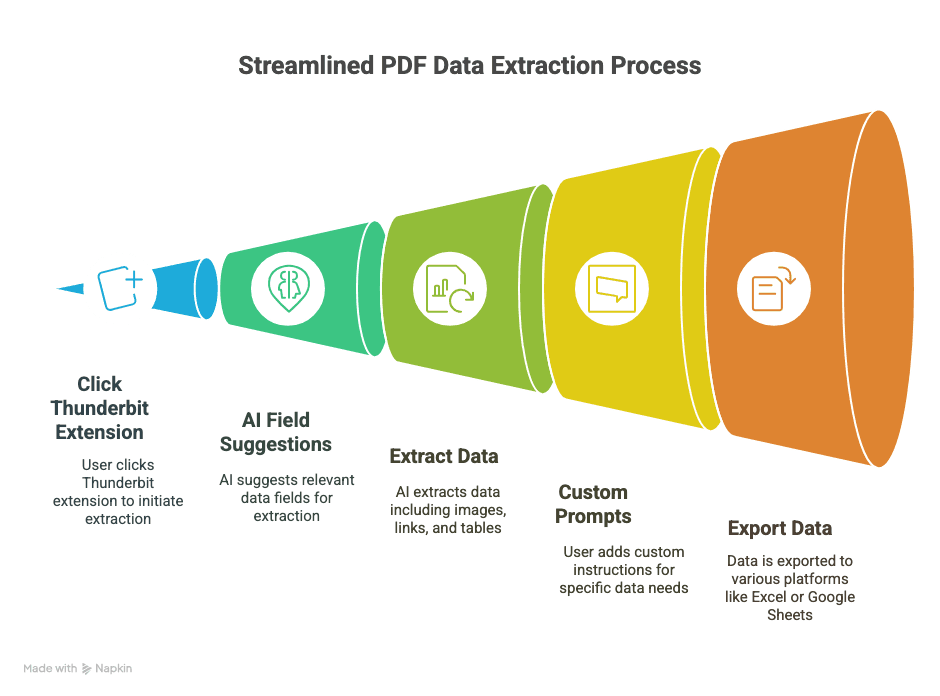
1. Thunderbitをインストールする
- を入手します。
- アカウント登録をします(Googleアカウントかメールで、数秒で完了します)。
2. ChromeでPDFを開く
- WebリンクからPDFを開くか、ローカルのPDFをChromeタブにドラッグします。
3. PDF上でThunderbitを起動する
- ブラウザのツールバーにあるThunderbitアイコンをクリックします。
- 「AI Web Scraper」を選ぶと、ThunderbitがPDFを認識して作業準備に入ります。
4. AIに項目を提案させる
- 「AIで列を提案」をクリックします。
- ThunderbitのAIがPDFをスキャンし、「日付」「金額」「担当者名」などの列を提案します。
- 抽出されたデータは、拡張機能内のテーブルでその場でプレビューできます。
5. 必要に応じて調整する
- 列名の変更、不要な項目の削除、独自列の追加(たとえば「保証期間」や「製品URL」)ができます。
- 取り扱いが難しいデータは、PDF内の文字を選択して、AIに何を抽出したいか学習させます。
6. 出力形式を選ぶ
- CSV、Google Sheets、Airtable、Notionから選べます。
- Thunderbitの連携を許可します(初回だけ設定が必要です)。
7. スクレイピングしてエクスポートする
- 「スクレイプ」または「エクスポート」を押します。
- ThunderbitがPDFを処理し、必要な場所へデータを送ります。たいてい数秒で完了します。
これで完了です。コーディング不要、コピペ不要、面倒ごともありません。
Thunderbitで正確にPDFデータを抽出するためのヒント
- AIが提案した項目を確認する: AIは賢いですが、さっと目を通すことで必要なものがきちんと取れているか確認できます。
- 複雑な表の扱い: 複数ページにまたがる表や変則的な表は、プレビューで確認し、必要に応じて列を調整してください。
- 画像/リンクの抽出: PDFにこれらの項目があるなら、必ず含めるようにしましょう。Thunderbitなら取得できます。
- スキャンPDF: Thunderbitの内蔵OCRは優秀ですが、スキャンがきれいなほど結果も良くなります。
- カスタムプロンプト: メールアドレスや電話番号だけが欲しいなら、「すべてのメールアドレスを抽出してください」のようなプロンプトを追加すると、その項目に集中してくれます。
高度なPDFスクレイピング:画像、リンク、カスタムデータの抽出
Thunderbitは単なるテキスト抽出ツールではありません。PDFからもっと多くを取り出す方法をご紹介します。
- 画像: ロゴ、チャート、埋め込みグラフィックなどを抽出できます。Thunderbitは画像内の文字にOCRをかけることも可能です。
- ハイパーリンク: すべてのURLや参照を取り出せます。研究論文や履歴書に便利です。
- カスタムデータ型: AIプロンプトを使って、本当に必要なものだけを抽出できます(例:「すべての商品SKUと価格を見つけてください」)。
- 要約と分類: 列を追加して、セクションの要約やデータの即時分類をThunderbitに依頼できます。
特定の業務ニーズに合わせたPDFデータの解析
- 営業: 提案書の一括処理から連絡先情報だけを抽出。
- EC: サプライヤーカタログから商品仕様、価格、画像を取得。
- 研究: 学術論文から表や参考文献を取り出し、要約まで生成。
そして、データを手に入れたら、Excel、Google Sheets、Notionで分析しやすい形に整えるだけです。重たい作業はThunderbitがやってくれるので、あとは結果を使うだけです。
PDFデータのエクスポートと活用:抽出から実行へ
データを取り出すのは始まりにすぎません。そこからどう活かすかが大切です。
- 出力先: CSV、Excel、Google Sheets、Airtable、Notion——好きなものを選べます。
- 整形のコツ: Thunderbitの列タイプ設定(数値、日付、テキスト)を使えば、きれいで分析しやすいデータになります。
- ワークフロー連携: エクスポートしたデータをCRM、在庫管理システム、分析ダッシュボードにつなげられます。
- 共同作業: Google SheetsやAirtableのベースをチームで共有すれば、全員が同じ最新データを見られます。
最大のメリットは、スプレッドシートを何度もメールで送り合ったり、行を見落としていないか不安になったりしなくて済むことです。
PDFスクレイピングでよくある落とし穴とその回避方法
優秀なツールを使っていても、いくつか注意点はあります。私が学んだことを共有します(時には痛い目を見ながら)。
- OCRエラー: ぼやけたスキャンや変わったフォントは、優秀なOCRでもつまずくことがあります。できるだけきれいなPDFを使い、重要な項目は必ず確認しましょう。
- 複雑なレイアウト: 複数カラムや入れ子の表は、少し手動で誘導が必要な場合があります。Thunderbitの手動選択やプロンプトを使ってください。
- データ型: カンマ入りの数値や変わった形式の日付は、エクスポート前に列タイプを設定するか、Excel/Sheetsで整えましょう。
- ファイルサイズ/ページ数の制限: 巨大なPDFは、小分けにするか、Thunderbitのクラウドモードでバッチ処理しましょう。
- AIの「幻覚」: まれですが、AIが列名を推測したり、欠けたデータを補ってしまうことがあります。特に重要な数値は、必ず目視で確認してください。
- 手動確認: 重要度の高いデータは、簡単な検証を入れましょう。自動化ツールは高精度ですが、人の目で最終確認するに越したことはありません。
もし壁にぶつかっても、Thunderbitのサポートとコミュニティが助けてくれます。
まとめと重要ポイント:PDFスクレイピングをビジネスで活かす
最後にまとめましょう。PDFからデータを抽出するのは、昔は悪夢のような作業でした。遅くて、ミスが多くて、ただただ面倒でした。ですが、のような現代的なツールがあれば、今では高速で、正確で、正直かなり快適です。
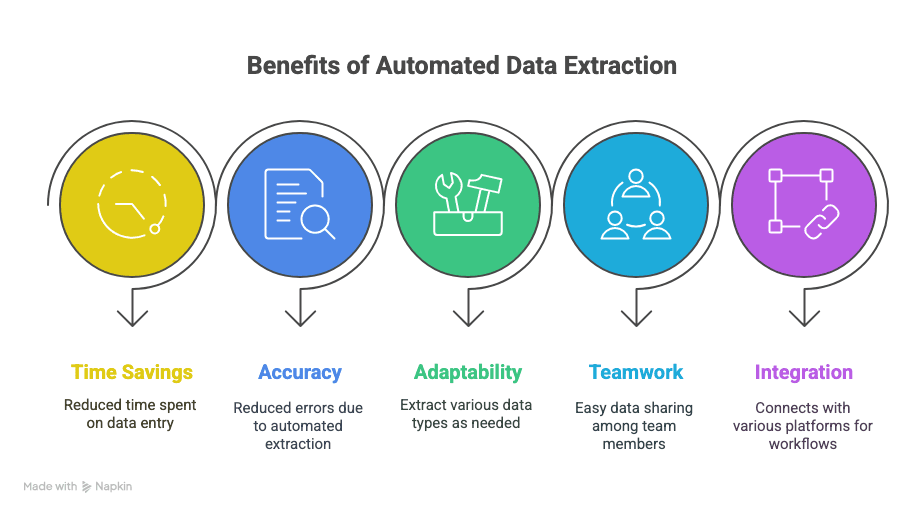
得られるものは次の通りです。
- 時間を取り戻せる: 手作業のデータ入力にかかる何時間、場合によっては何週間もの時間を節約。
- ミスが減る: 自動抽出により、タイプミスや見落としが減ります。
- 柔軟性: テキスト、表、画像、リンクなど、必要なものを必要なだけ抽出。
- 共同作業: どこにいるチームメンバーとも、すぐにデータを共有。
- 賢いワークフロー: Sheets、Notion、Airtableなどと連携可能。
試してみる準備はできましたか? をダウンロードして、次のPDFで試してみてください。どれだけ作業が楽になるか、きっと実感できるはずです。未来の自分も、そして手首も、きっと感謝してくれるでしょう。
さらに詳しいヒントやガイドは、をご覧いただくか、をぜひ読んでみてください。
PDFの悩みを生産性アップに変えていきましょう。ひとつのクリックから。
Shuai Guan、Thunderbit共同創業者兼CEO