

ウェブスクレイピングは違法なのでしょうか? これは、創業者、マーケター、データ好きの人たちから毎週のように聞かれる、まさに“1億ドル級”の質問です。
今では、インターネットトラフィック全体の51%がボットによるものであり、しかもその割合が初めて人間の利用を上回りました。その大きな部分を占めているのが、ビジネスインテリジェンス、営業、AI学習のためのウェブスクレイピングです。誰もが法的な境界線がどこに引かれるのか知りたがるのも、当然です。
ある日は「公開データのスクレイピングは問題ない」とする判決の見出しを目にし、次の日には規制当局がソーシャルメディアからの「違法な」データ収集に警告を出している。私のように Thunderbit でAIウェブスクレイピングツールを作っている人間でさえ、混乱することがあります。
では、ウェブスクレイピングは違法なのでしょうか? 答えは単純な「はい」か「いいえ」ではありません。何をスクレイピングするのか、どこから取得するのか、データをどう使うのか、そして各国の法律が何を定めているのかによって変わります。
この詳細解説では、法的な全体像を整理し、よくある誤解を解き、コンプライアンスを守るための実践的なヒントや、いくつかの実例も紹介します。ひとりの創業者であっても、Fortune 500のデータチームであっても役立つ内容です。
ウェブスクレイピングと法律:明確な線はあるのか?
一言で答えが欲しいなら、先にお伝えします。法律は、ウェブスクレイピングに対して明快で一律の線を引いてはいません。
実際には、データ所有権、プライバシー、知的財産、アンチハッキング法、そして悪名高い利用規約(ToS)など、重なり合うルールが入り組んでいます。それぞれが関係する可能性があり、結論は多くの場合、個別の状況次第です(multilogin.com)。
大きく分けると、法的な論点は次の3つです。
- データ所有権: 一般に、事実や公開情報(価格や電話番号など)は著作権の対象になりません。ただし、記事や画像のような創作的コンテンツ、そして独自のデータベースは保護されることがあります。特にEUでは「データベース権」があるため、注意が必要です(cliffordchance.com)。
- プライバシー: 現代のプライバシー法(欧州のGDPR、中国のPIPLなど)は、公開されていても個人データを規制対象の資産として扱います。名前、メールアドレス、SNSプロフィールなどを合法的根拠なくスクレイピングすると、厄介な問題に発展する可能性があります(ico.org.uk)。
- 契約(利用規約): 多くのサイトは利用規約でスクレイピングを明確に禁止しています。利用規約自体は法律ではありませんが、裁判所は拘束力のある契約として扱うことがあります。違反すれば訴訟につながる可能性があり、場合によっては技術的制限を回避したことでアンチハッキング法に触れることもあります(cliffordchance.com)。
つまり、ウェブスクレイピングは違法なのか? 場合によります。合法のこともあれば違法のこともあり、多くは「状況次第」です。結局は細部が勝負です。
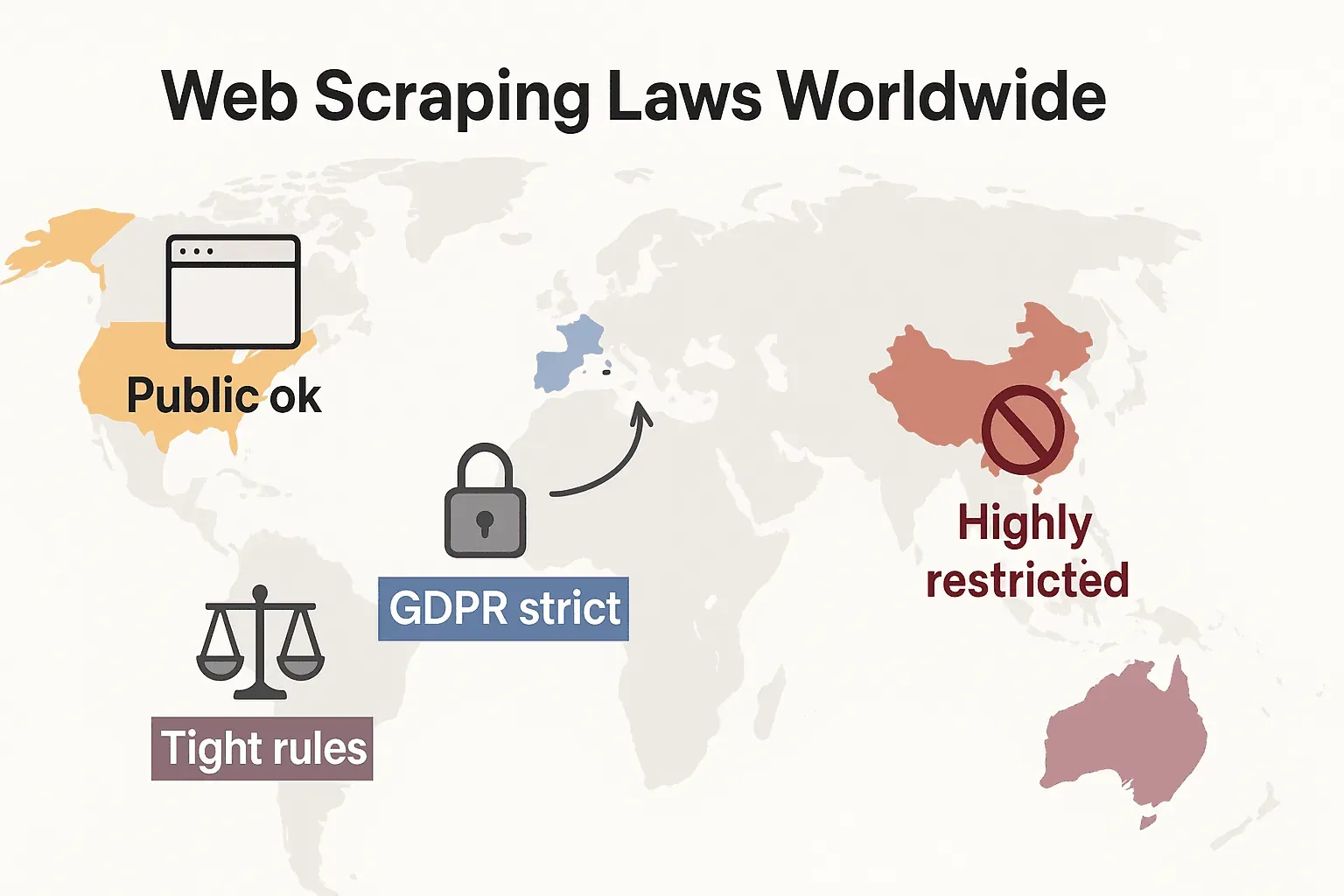
法的な視点の比較:米国、EU、英国、中国
主要地域がウェブスクレイピングをどう扱っているか、簡単な表で見てみましょう。
| 地域 | 公開データのスクレイピング | 個人・非公開データのスクレイピング | 執行と主なポイント |
|---|---|---|---|
| 米国 | 公開データについては一般に許容されます(hiQ v. LinkedInを参照)。利用規約違反は民事訴訟につながる可能性があります。 | ログインを突破したり、個人データを不正利用したりすると制限・違法の可能性があります。州法(CCPAなど)が適用されることもあります。 | 差止め通知、IPブロック、訴訟。技術的障壁を回避した場合はCFAAが適用されます。 |
| EU | 非個人の公開データであれば条件付きで許容されます。データベース権が適用される場合があります。EU AI法(2026年)は、AI学習データに透明性要件を追加します。 | GDPRの下で厳しく規制されます。公開された個人データであっても法的根拠が必要です。 | データ保護当局がプライバシー違反に罰金を科すことがあります。著作権・データベース権も執行されます。EU AI法はAI向けの顔画像スクレイピングを禁止します。 |
| 英国 | EUに近い考え方です。公開された非個人データはスクレイピング可能ですが、データ権利と契約は尊重する必要があります。 | 個人データには厳格です。UK GDPRが適用されます。Computer Misuse Actは無断アクセスを犯罪とします。 | ICOがデータ保護違反に罰則を科すことがあります。裁判所が利用規約を執行する場合もあります。 |
| 中国 | 厳しく管理されています。公開された非個人データは社内利用目的であればスクレイピング可能な場合がありますが、全体としては慎重な環境です。 | 非常に制限が厳しく、PIPLでは個人データに同意が必要です。不正競争防止法も適用されます。 | 大規模スクレイピングでは刑事事件に発展することがあります。裁判所は不正競争法を使って無断スクレイピングを止めます。 |
ウェブスクレイピングは違法?検討すべき主要な法的要素
では、あなたのスクレイピングプロジェクトが合法か、それともリスクが高いかを決めるのは何でしょうか? 主な要素は次のとおりです。
- 公開データか非公開データか: オープンウェブ上で誰でも見られるデータをスクレイピングする方が、一般には安全です。ログイン、ペイウォール、技術的障壁の向こう側にあるものを取得するのは? それは違法である可能性が高いです(thunderbit.com)。
- データの性質: 個人データ(名前、メール、プロフィール)はプライバシー法の対象になります。著作物(記事、画像)は丸ごとコピーできません。単なる事実(価格、天気など)は、たいてい問題になりにくいです(oxylabs.io)。
- 利用目的: 再配信や販売よりも、社内分析や調査のほうが一般に寛容に見られます。スクレイピングしたデータで元サイトと直接競合するなら? 訴訟に発展する可能性が高いです(thunderbit.com)。
- サイト規則の遵守: robots.txt と利用規約は必ず確認しましょう。robots.txt は法的拘束力はありませんが、尊重するのがベストプラクティスです。利用規約違反は民事訴訟などにつながる可能性があります(promptcloud.com)。
- 技術的措置: 人間の利用に近い速度で行い、セキュリティ対策を回避しないことが重要です。サーバーを過負荷にしたり、CAPTCHAを回避したりすると、ハッキングの領域に踏み込むことがあります(cliffordchance.com)。
2024〜2026年に何が変わったのか:重要な判例と規制
2023年以降、ウェブスクレイピングをめぐる法的環境は大きく変わりました。スクレイパーなら必ず知っておくべき動きを整理します。
主要な裁判所判断
-
Meta v. Bright Data(2024年): 米連邦裁判所は、Metaの利用規約は、ログインしていないユーザーによる公開データのスクレイピングを禁止していないと判断しました。判事は「アカウントを持っていなければ、訪問者は『ユーザー』とは見なされない」と述べました。その後、Metaは残りの請求を取り下げました。これは公開データスクレイピングにとって大きな勝利です。
-
X Corp v. Bright Data(2024年): Twitter(現X)も同様の訴訟で敗訴し、同じ原則が強化されました。ログインせずに公開データをスクレイピングすることは利用規約違反ではない、なぜならスクレイパーはその規約に同意していないからです。
-
Reddit v. Perplexity AI(2025年10月): RedditはPerplexity AI と複数のスクレイピング提供事業者を提訴し、DMCAを持ち出してボット対策システムの回避を主張しました。これは新たな法的戦略の兆しです。プラットフォームはCFAAではなく、著作権と回避禁止規定を使い始めています。
-
NYT v. OpenAI(2025年3月): 連邦判事はニューヨーク・タイムズによるOpenAIへの著作権訴訟の継続を認め、OpenAIの却下申立てを退けました。これは、AIモデルの学習のためにコンテンツをスクレイピングする行為が「フェアユース」に当たるかどうかに関する重要な先例になる可能性があります。
-
Anthropicの和解(2025年9月): Anthropicは、自社AIモデルの学習に著作権付きテキストを使用した件で、米国の著作権集団訴訟を15億ドルで和解することに合意しました。AI向けスクレイピングのコストが現実的に大きいことを示しています。
大きな流れ:CFAAから契約法・著作権法へ
傾向は明確です。CFAA(Computer Fraud and Abuse Act)は、公開データのスクレイパーに対する武器としての力を失いつつあります。 Meta、X、LinkedIn など、公開データスクレイピングにCFAAを使おうとした企業は、概ね成功していません。その代わり、法廷の主戦場は次のように移っています。
- 契約法(利用規約違反。ただし裁判所は、同意していない非ユーザーには利用規約は拘束しないと述べています)
- 著作権請求(特にAI学習データ)
- 回避禁止法(DMCA第1201条)
スクレイパーにとって、法的リスクが消えたわけではありません。ただ、場所が移っただけです。
規制の変更
- CCPA 2026年改定: カリフォルニア州の改定CCPA規則は2026年1月1日に施行され、自動意思決定技術(ADMT)、リスク評価、データブローカーの義務に関する新ルールが追加されました。
- 米国の新たな州プライバシー法: インディアナ州、ケンタッキー州、ロードアイランド州でも、2026年に包括的プライバシー法が施行されました。
- EU AI法: 本格施行は2026年8月2日に始まり、AI開発者に対して学習データの出所開示、著作権オプトアウトの尊重、顔画像スクレイピングの禁止などを求めます。
- AI Accountability for Publishers Act(2026年2月): AI企業に対し、コンテンツをスクレイピングする前に出版社の許可を得て、対価を支払うことを義務づけることを目指す米国の法案です。
主要プラットフォームのスクレイピングポリシー:知っておくべきこと
すべてのサイトがスクレイピングを同じようには扱っていません。ここでは、大手プラットフォームごとに、何を許可し、何をブロックし、裁判所が何を言ってきたかを整理します。
| プラットフォーム | 利用規約上のスクレイピング | 技術的防御 | 法的執行 | 実務上安全な範囲 |
|---|---|---|---|---|
| Google(検索・Maps) | 利用規約で自動アクセスを禁止。Maps Platform には明示的な「No Scraping」条項があります。 | SearchGuard のJSチャレンジ、CAPTCHA、レート制限。2025年にrobots.txtを更新し、AIクローラーをブロック。 | 2025年12月にDMCAを使ってスクレイパーを提訴。AIクローラー(Anthropic、Meta、OpenAI)を積極的にブロック。 | 公開されているGoogle Mapsのビジネスデータのスクレイピングは法的に主張可能ですが、技術的なブロックは覚悟してください。可能なら公式APIを使いましょう。 |
| Amazon | 利用条件であらゆるスクレイピングを明示的に禁止(「robot、spider、scraper、その他の自動手段は禁止」)。 | 強力なボット検知、CAPTCHA、IPブロック。robots.txtはGooglebot/Bingbot以外のすべてのボットをブロック。2025年以降はAIクローラーも明示的に遮断。 | 2025年11月にPerplexity AIを提訴。定期的に差止め通知を送付。2026年3月にはAIエージェント規則を含むBSAを更新。 | 商品情報(価格、出品情報)は事実ベースであり、米国法上は取得可能ですが、Amazonは強く対抗してきます。リクエストは抑制し、個人データは避けてください。 |
| 利用規約でスクレイピングを禁止。サービス利用にはユーザー同意が必要です。 | 多くのプロフィールデータにログイン壁、ボット検知、レート制限。 | hiQ事件で公開プロフィールのスクレイピングはCFAA違反ではないと確認された一方、偽アカウントを使った場合は契約・不正競争の請求でLinkedInが勝訴。 | ログイン不要で見える公開プロフィールのスクレイピングは法的に主張可能です。偽アカウントを作成したり、ログイン後データを取得したりしてはいけません。 | |
| Meta(Facebook・Instagram) | 利用規約でスクレイピングを禁止。ログイン状態とログアウト状態で別ルールがあります。 | 多くのコンテンツにログイン壁、先進的なボット検知。 | 2024年にBright Dataに敗訴。裁判所は、ログインしていないスクレイパーには利用規約が適用されないと判断。残りの請求も取り下げ。 | ログイン不要で見える公開データ(ビジネスページ、公開投稿)は比較的安全です。非公開プロフィールやログイン後のデータは絶対にスクレイピングしないでください。 |
| X(Twitter) | 2023年に利用規約を更新し、書面による同意なしのあらゆるスクレイピングとクロールを禁止。旧来のrobots.txt例外も廃止。 | robots.txtで全クローラーをブロック(Disallow: /)。Cloudflare Turnstile チャレンジ。厳しいレート制限(300 req/hr)。IPレピュテーションスコアリング。 | 公開データについてBright Dataには敗訴したものの、技術的アクセスは強力に制限。 | 公開ツイートやプロフィールのスクレイピングは法的に主張可能ですが、2026年時点でXの技術的障壁は最も厳しい部類です。プレミアムなプロキシ基盤なしではブロックされる可能性が高いです。 |
要するに: 裁判所は一貫して、ログインせずに公開表示されているデータをスクレイピングすることはCFAA違反ではないと判断してきました。ただし、プラットフォームは契約法、著作権、回避禁止法を使ってなお追及できますし、技術的な障壁でかなりやりにくくしてきます。常に責任ある方法でスクレイピングしましょう。
AI学習データとウェブスクレイピング:新たな法的最前線
2026年のニュースを追っていれば、AIモデルを学習させるためのデータスクレイピングが最も熱い法廷闘争になっていることはご存じでしょう。今起きていることは次のとおりです。
- 著作権訴訟が相次いでいます。 ニューヨーク・タイムズ、著者、出版社などがOpenAIやAnthropicらを提訴し、LLM学習のために大量の著作物をスクレイピングするのは「フェアユース」ではないと主張しています。Anthropicは2025年に15億ドルで大規模集団訴訟を和解しており、AI向けスクレイピングのコストが現実に大きいことを示しています。
- 「フェアユース」抗弁は不安定です。 米国裁判所は、スクレイピングしたデータでAIを学習させることがフェアユースに当たるかについて、まだ決定的判断を示していません。初期の判断を見る限り、どのようにデータを取得したか、そしてAIの出力を何に使うかが大きく影響します。
- 新しい法整備が進んでいます。 AI Accountability for Publishers Act(2026年2月提出)は、AI企業に対し、コンテンツをスクレイピングする前に出版社の許可を得て対価を支払うことを義務づけることを目指しています。
- EU AI法(本格施行は2026年8月)は、AI開発者に対して学習データの出所開示、機械可読な著作権オプトアウトの尊重(著作権指令のTDM例外に基づく)、AI生成コンテンツの表示を求めます。また、ネット上の顔画像をスクレイピングするAIシステムも禁止します。
- AI/LLMクローラーが急増しています。 AIクローラーは、わずか8か月でWebトラフィックに占める割合を2.6%から10.1%へと4倍に増やしました。OpenAIのGPTBotだけでも305%増加しています。これを受けて、Amazon、Reddit、NYTなどの大手サイトはrobots.txtを更新し、AIクローラーを明示的にブロックしています。
これが意味すること: 従来の業務目的(リード獲得、価格監視、市場調査)でデータをスクレイピングする場合、こうしたAI特有の規制が直接当てはまらないこともあります。しかし、スクレイピングしたデータをAIモデルに投入するなら、極めて慎重になるべきです。そして、法律の専門家に相談してください。
世界のウェブスクレイピング法:ざっくり比較
視野を広げて、世界全体でどのようなルールになっているかを見てみましょう。
- 米国: 一律禁止ではありません。公開サイトのスクレイピングは一般に合法であり(hiQ v. LinkedIn)、2024年のMetaとX Corpの判決によって、公開データスクレイピングの根拠はさらに強まりました。ただし、ログインの裏側や技術的ブロックの向こう側をスクレイピングすると、CFAAが発動する可能性はあります。現在の流れは、企業が契約法と著作権請求を使う方向です。プライバシー法も急速に拡大しており、CCPAは2026年1月1日施行で大幅改正され、自動意思決定やデータブローカー義務に関する新ルールが導入されました。インディアナ州、ケンタッキー州、ロードアイランド州でも2026年に包括的プライバシー法が成立しています。
- 欧州連合: 厳格なプライバシー法が適用されます。GDPRは公開された個人データにも及びます。データベース権により、構造化データの大規模スクレイピングが阻まれることがあります(cliffordchance.com)。新情報: EU AI法は2026年8月2日に全面施行され、AI開発者に学習データの出所開示と著作権オプトアウトの尊重を求めます。また、AIシステム向けにネット上の顔画像をスクレイピングすることを禁止します。
- 英国: ブレグジット後もEUのルールに近い運用です。公開データはスクレイピングできますが、個人情報のスクレイピングは厳しく規制されます。Computer Misuse Act が無断アクセスを犯罪化する場合があります。
- 中国: 非常に厳格です。PIPL とデータセキュリティ法により、個人データには同意が必要です。裁判所は、不正競争防止法を使って事業に害を与えるスクレイピングを差し止めます(malwarebytes.com)。
結論として、社内利用のために公開された非個人データをスクレイピングするのが、一般には最も安全です。それ以外は? 現地法を確認し、慎重に進めましょう。
ウェブスクレイピングの合法性に関するよくある誤解
よく聞く誤解をいくつか、ここで整理しておきます。
- 誤解1: 「ウェブスクレイピングは、完全に違法だ」
これは誤りです。すべてのウェブスクレイピングを禁止する法律はありません。重要なのは、何をどうスクレイピングするかです(oxylabs.io)。 - 誤解2: 「公開データなら、好きに使っていい」
そこまで単純ではありません。公開データでも、プライバシー法や著作権法で保護されることがあり、利用規約で用途が制限されている場合もあります(ico.org.uk)。 - 誤解3: 「ウェブスクレイピングはハッキングと同じ」
いいえ。公開ウェブページのスクレイピングはハッキングではありません。ログインや技術的障壁を回避するのは別の話です(calawyers.org)。 - 誤解4: 「見つからなければ問題ない」
危険な考え方です。多くのサイトはアンチボット技術を使っており、必ず気づきます。沈黙は同意ではありません。 - 誤解5: 「クレジットを入れれば、内部利用なら大丈夫」
表示を入れても、著作権法やプライバシー法は無効になりません。内部利用のほうが安全ではありますが、フリーパスではありません。 - 誤解6: 「すべてのウェブスクレイピングはプライバシー侵害だ」
すべてのスクレイピングが個人データを扱うわけではありません。ただし、大量の個人情報を保護策なしで取得するのは、ほぼ常に違法です(oxylabs.io)。 - 誤解7: 「サイトの利用規約でスクレイピング禁止なら、スクレイピングは常に違法」
必ずしもそうではありません。2024年には、Meta v. Bright Data と X Corp v. Bright Data で、同意していないユーザーに利用規約は拘束力を持たないと裁判所が判断しました。つまり、ログインせず、アカウントも作らずにスクレイピングしているなら、そのサイトの利用規約があなたに適用されない可能性があります。これはまだ発展途上の分野ですが、かなり大きな変化です。
データを合法的にスクレイピングする方法:コンプライアンスのベストプラクティス
私が普段使っている、合法かつ倫理的なウェブスクレイピングのチェックリストを紹介します。
- サイトの利用規約を読み、守る。 「スクレイピング禁止」と書いてあるなら、やめるか許可を取ることを検討しましょう(ql2.com)。
- 公開データに絞る。 パスワードが必要なら、それは制限されたデータです。スクレイピングしないでください(thunderbit.com)。
- robots.txt を確認し、丁寧にクロールする。 法的拘束力はありませんが、礼儀として重要です。サーバーに負荷をかけないよう、リクエスト間隔を空けましょう(promptcloud.com)。
- 合法的根拠がない限り、個人データは避ける。 どうしても取得する必要があるなら、GDPR/CCPAに従い、収集量を最小限に抑えましょう。
- スクレイピングした内容を丸ごと再配信しない。 価値や分析を加えるか、許可を取りましょう(thunderbit.com)。
- 著作権を確認せずに、スクレイピングした内容をAIモデルに入れない。 法的環境は急速に変化しています。この用途なら、必ず助言を求めてください。
- 公式APIやデータエクスポートがあれば、それを使う。 それらはこの目的のために設計されており、通常は安全です(thunderbit.com)。
- 透明性と説明責任を持つ。 個人データを収集するなら、本人に知らせ、活動ログを残しましょう。
- データを最小化し、安全に保管する。 必要なものだけを収集し、正確性を保ち、安全に保存します。
- 最新動向を追い、グレーゾーンは専門家に相談する。 法律や判例は急速に変わっています。特にEU AI法や米国州プライバシー法は要注意です。迷ったら、プロに聞きましょう。
コンプライアンスに配慮したスクレイピングをThunderbit Chrome拡張で試す
ウェブスクレイピングツールを合法的に使う:企業が知るべきこと
Thunderbit のようなウェブスクレイピングツールは、ノーコードでデータ収集を可能にしますが、使い方は責任を持つ必要があります。
- コンプライアンス重視のツールを選ぶ。 たとえば Thunderbit は、ブラウザで見えている範囲だけをスクレイピングします。裏技的なAPIハックや無断アクセスはありません(thunderbit.com)。
- 適切な用途に限定する。 社内分析、市場調査、競合価格の監視は一般に安全です。スクレイピングしたデータの再配信や販売は、はるかにリスクが高いです。
- コンプライアンスを意識して設定する。 クロール遅延を設定し、robots.txt を守り、必要なものだけを集めるテンプレートを使いましょう。
- 社内利用にとどめる。 スクレイピングしたデータは、公開し直すより社内で使うほうが安全です。
- チームを教育する。 全員がルールとベストプラクティスを理解していることを確認しましょう。
- 組み込みのコンプライアンス機能を活用する。 Thunderbit は危険なサイトについて警告し、人間に近い速度でスクレイピングし、データをサーバーに保存しません。
- 無理に突破しない。 ツールで取得できないサイトを、無理やり回避して取得しようとしないでください。すべてのデータがリスクなく取れるわけではありません。
Thunderbitの考え方:コンプライアンスに配慮したAIウェブスクレイピングを実現する
Thunderbit では、コンプライアンスについて長く考えてきました。私たちのAI Web Scraperが、ユーザーが法の範囲内にとどまるのをどう支援するかをご紹介します。
- 見えているものだけをスクレイピング。 Thunderbit はブラウザセッション内で動作するため、手動でコピーできないデータにはアクセスできません。
- 警告でユーザーをガイド。 厳しいスクレイピング対策があるサイトを取得しようとすると、Thunderbit が警告します。
- 人間らしい速度でスクレイピング。 ローカルでもクラウドでも、サーバーに負荷をかけすぎないように設計されています。
- 柔軟なデータ選択。 AIが関連列を提案し、必要なものだけを集めやすくします。
- サブページとページネーションに対応。 Thunderbit は、実際のユーザーのようにサイトをたどり、構造を尊重します。
- プライバシーとセキュリティ。 データはあなたのものであり、Thunderbit が保存したり再利用したりしません。
- コンプライアンスに配慮したエクスポート。 Google Sheets、Airtable、Notion、CSVへ直接出力でき、社内で安全に使えます。
- スケジュール設定と自動化。 責任ある間隔で定期スクレイピングを設定できます。
- 多言語対応。 Thunderbit のUIは34言語に対応しており、世界中で使いやすくなっています。
- テンプレートの定期更新。 人気サイト向けの即時テンプレートは、法的・技術的変更に合わせて更新されています。
コンプライアンスを製品に組み込むことで、Thunderbit はチームが必要なデータを集めつつ、法的な悩みを減らせるようにしています。
先を行くために:ウェブスクレイピングの法的・技術的変化に適応する
さらにウェブスクレイピングのガイドを見る Get Started Free
ウェブスクレイピングは、設定したら終わりの仕事ではありません。法律もサイトの構造も常に変化しています。先手を打つための方法は次のとおりです。
- 法的動向を追う。 2024〜2026年は変化のスピードが加速しました。テック法ニュース、規制当局の更新、業界ブログ(Thunderbit など)を追いましょう。EU AI法の施行(2026年8月)、米国州プライバシー法の新設、進行中のAI著作権訴訟に注目してください。
- 技術変化に適応する。 サイトはレイアウトやアンチボット対策を頻繁に更新します。Amazon、X、Google などの主要プラットフォームは、2025〜2026年に防御を大幅に強化しました。Thunderbit のAIとテンプレートは、それに自動で適応するよう設計されています。
- 公式APIがあれば使う。 サイトが有料APIモデルに移行したら、信頼性とコンプライアンスのために切り替えを検討しましょう。
- 定期的に監査する。 データソースを記録し、利用規約やポリシーの変更を確認し、必要に応じて方針を見直します。
- Thunderbitのテンプレート更新を活用する。 私たちのチームがテンプレートを最新に保つので、破壊的変更や新しいコンプライアンス要件に悩まされにくくなります。
- 柔軟でいる。 データソースのリスクが高くなったら、別のソースへ切り替えるか、提携を検討しましょう。
適切なツールと考え方があれば、法的な落とし穴を踏まずに、データパイプラインを流し続けられます。
まとめ:ウェブスクレイピングの法的環境をどう進むか
ウェブスクレイピング自体が本質的に違法というわけではなく、ビジネス、研究、イノベーションに役立つ強力なツールです。ただし、どんなツールにもルールがあります。重要なのは、何をスクレイピングするのか、どうスクレイピングするのか、そしてデータをどう使うのかを理解することです。現地法を尊重し、サイトのポリシーに従い、Thunderbit のようなコンプライアンス重視のツールを使って、運用を適法な範囲に保ちましょう。
2024〜2026年の判決(Meta v. Bright Data、X Corp v. Bright Data)は、公開データのスクレイピングを後押ししましたが、AI学習データ、著作権請求、EU AI法をめぐる新たなリスクも生まれています。Google、Amazon、LinkedIn、Meta、X など、プラットフォームごとにポリシーは大きく異なるため、スクレイピングする前に全体像を把握しておく必要があります。
不安がある場合は、特に大規模案件やセンシティブな案件では、法律の専門家に相談してください。そして忘れないでください。法的環境は常に変わるので、最新情報を追い、機敏に対応することが大切です。
ウェブスクレイピング、コンプライアンス、自動化についてもっと知りたいですか? ぜひ Thunderbit Blog で他のガイドをチェックするか、ThunderbitのChrome拡張機能 を実際に試してみてください。
Thunderbitでコンプライアンスに配慮したウェブスクレイピングを始める
よくある質問
1. ウェブスクレイピングはどこでも違法ですか?
いいえ。ウェブスクレイピング自体が違法というわけではありませんが、合法かどうかは、何を、どのように、どこでスクレイピングするかによって変わります。社内利用のために公開された非個人データを取得するのは多くの地域で一般に許容されていますが、個人データや著作権付きデータのスクレイピング、サイト規約違反は違法になることがあります(oxylabs.io)。
2. robots.txt を無視すると、スクレイピングは違法になりますか?
robots.txt には法的拘束力はありませんが、尊重するのがベストプラクティスです。無視しただけで直ちに訴えられるわけではありませんが、紛争になった際に「悪質な行為者」と見なされやすくなります(promptcloud.com)。
3. Google、Amazon、LinkedIn はスクレイピングできますか?
これは複雑です。3社とも利用規約でスクレイピングを禁止していますが、裁判所はログインしていないユーザーには利用規約が拘束力を持たない場合があると判断しています(2024年の Meta v. Bright Data と X Corp v. Bright Data を参照)。公開表示されているデータ(商品価格、企業リスト、公開プロフィールなど)のスクレイピングは、米国では一般に法的に主張可能です。ただし、各プラットフォームの執行の強さは異なります。Amazon は法的措置が最も強硬で、2025年11月には Perplexity AI を提訴しました。LinkedIn は技術的障壁と契約請求を重視しています。Google はDMCAベースの執行を強めています。常に責任ある方法でスクレイピングし、技術的な対抗策を想定してください。
4. Facebook や Instagram はスクレイピングできますか?
Meta v. Bright Data(2024年)以降、Facebook や Instagram の公開データをログインせずにスクレイピングすることは、法的により強い立場にあります。裁判所は Meta の利用規約は非ユーザーには適用されないと判断しました。ただし、偽アカウントを作成したり、ログイン壁の向こう側のデータを取得したりしてはいけません。それは一線を越えています。
5. X(Twitter)はスクレイピングできますか?
X は2023年に利用規約を更新し、書面同意なしのスクレイピングをすべて禁止しました。また、Cloudflare Turnstile、1時間あたり300件のレート制限、IPレピュテーションスコアリングなど、強力な技術的防御を導入しています。ただし、Bright Data は同様の論点で裁判に勝っており、アカウントなしで取得した公開データは X の利用規約に縛られないとされています。技術面では、X は2026年に最もスクレイピングしづらいプラットフォームの一つです。
6. AIモデル学習のためのデータスクレイピングは合法ですか?
これは2026年時点で最大の未解決問題です。NYT v. OpenAI や Anthropic の15億ドル和解など、大きな訴訟は重大な法的リスクを示しています。EU AI法は、学習データの出所開示と著作権オプトアウトの尊重を求めます。提案中の AI Accountability for Publishers Act は、許可と支払いを義務づける内容です。AI学習目的でスクレイピングするなら、始める前に法律相談を受けてください。
7. Thunderbit のようなウェブスクレイピングツールを最も安全に使う方法は?
公開データに絞り、サイトの規約を尊重し、法的根拠がない限り個人情報は避け、データは社内利用にとどめることです。Thunderbit は、ブラウザで見えているものだけを取得し、リスクの高いサイトについて警告することで、コンプライアンスを守る手助けをするよう設計されています(thunderbit.com)。
8. 商用利用のためにデータをスクレイピングできますか?
場合によります。社内分析や調査のために使うなら、一般には比較的安全です。特に著作権付きデータや個人データを再配信・販売するのは、かなりリスクが高く、許可やライセンスが必要になることがあります。
9. ウェブスクレイピングの法的・技術的変化にどう追いつけばよいですか?
テック法ニュースを追い、対象サイトの利用規約やポリシー変更を監視し、テンプレートやコンプライアンス機能を定期更新する Thunderbit のようなツールを使いましょう。2026年に注目すべき点は、EU AI法の施行(8月)、継続中のAI著作権訴訟、そして米国州プライバシー法です。迷ったら、法律専門家に相談してください。
AI Web Scraper を試す Get Started Free




