
インターネットの進化は本当に目覚ましいですよね。2024年現在、11億以上のウェブサイトが存在し、149ゼタバイトものデータが毎日生み出されています(来年には181ZBに到達する見込みです)。これだけ膨大な情報がある中で、実は検索エンジンにインデックスされているのは全体のたった4%しかありません。残りは「ディープウェブ」と呼ばれ、普段の検索では見つけられない世界です。では、検索エンジンや企業はどうやってこの広大なデジタル空間を把握しているのでしょうか?そこで活躍するのがウェブクローラーです。
この記事では、ウェブクローリングの仕組みやその重要性を、エンジニアだけでなく、ネット上のデータを活用したいすべての人に向けて分かりやすく解説します。ウェブクローリングとウェブスクレイピングの違い(実は全然別物です)、実際の活用事例、コードを使った方法からノーコードツール(個人的におすすめなのはThunderbit)まで、幅広くご紹介します。初心者の方も、ビジネスでデータ活用を目指す方も、ぜひ参考にしてみてください。
ウェブクローラーとは?ウェブクローリングの基本を知ろう
まずはざっくり説明します。ウェブクローラー(スパイダーやボット、ウェブサイトクローラーとも呼ばれます)は、インターネット上のページを自動で巡回し、リンクをたどって新しいコンテンツを見つけていくプログラムです。イメージとしては、図書館の司書ロボットが本(URL)のリストから読み始め、参考文献をたどってさらに多くの本を探し出す感じです。ただし、対象は本ではなくウェブページ、図書館ではなくインターネット全体です。
基本的な流れはこんな感じです:
- URLリスト(シード)からスタート
- 各ページを訪問してHTMLや画像などのコンテンツを取得
- ページ内のリンクを見つけて、次に巡回するリストに追加
- この流れを繰り返す
ウェブクローラーの主な役割は、ページを発見して整理することです。検索エンジンの場合、クローラーがページの内容をコピーしてインデックス用に送ります。特定のデータを抜き出す専用クローラーも存在します(これがウェブスクレイピングですが、詳しくは後ほど)。
ポイント:
ウェブクローリングの目的は、ウェブ全体を発見して地図を作ることです。GoogleやBingなどの検索エンジンが世界中の情報を把握できるのは、この仕組みがあるからなんです。
検索エンジンの仕組み:クローラーの役割
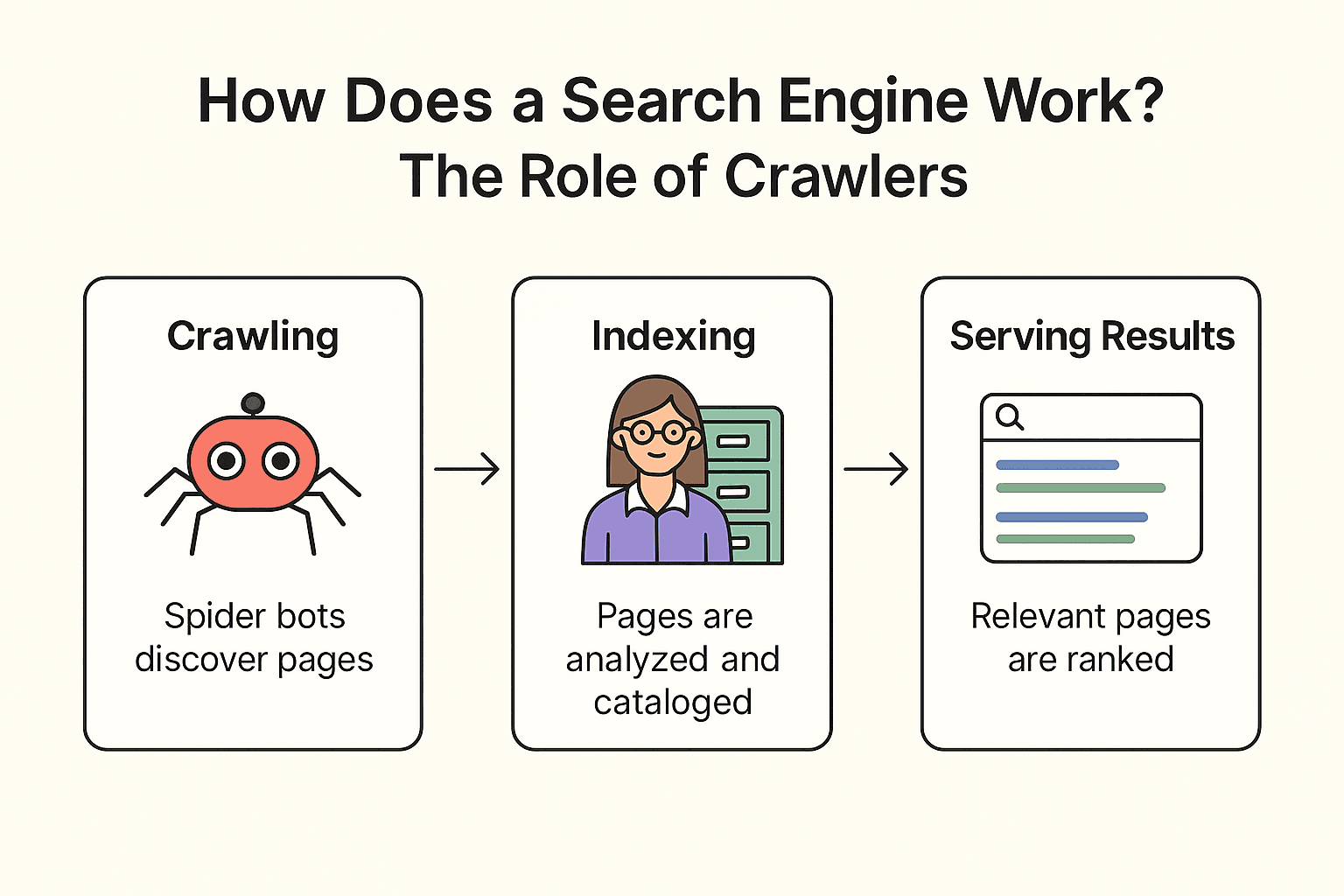
GoogleやBing、DuckDuckGoなどの検索エンジンは、どんな仕組みで動いているのでしょう?大きく分けて3つのステップがあります:クローリング、インデックス作成、検索結果の表示(Google公式ドキュメントも参考にどうぞ)。
図書館を例にすると分かりやすいです:
-
クローリング:
検索エンジンは「スパイダーボット」(例:Googlebot)を使ってウェブを巡回します。既知のページからスタートし、内容を取得し、リンクをたどって新しいページを発見します。まるで司書が本棚をチェックし、参考文献をたどって新しい本を見つけるようなイメージです。
-
インデックス作成:
見つけたページの内容を分析し、どんな情報があるかを把握して、巨大なデジタル目録(インデックス)に登録します。すべてのページが登録されるわけではなく、ブロックされていたり、品質が低かったり、重複している場合はスキップされます。
-
検索結果の表示:
例えば「近くの美味しいピザ」と検索すると、インデックスから関連するページを探し、キーワードや人気度、新しさなど数百の要素で順位付けして、最適なリストを表示します。
豆知識:
検索エンジンはウェブ上のすべてのページを巡回しているわけではありません。ログインが必要なページやrobots.txtでブロックされているページ、外部からリンクされていないページは見つけられないことも多いです。そのため、企業は自社サイトのURLやサイトマップをGoogleに直接送信することもあります。
ウェブクローリングとウェブスクレイピングの違い
ここは混同しやすいポイントです。「ウェブクローリング」と「ウェブスクレイピング」は似ているようで、実は目的も使い方も全然違います。
| 項目 | ウェブクローリング(スパイダー) | ウェブスクレイピング |
|---|---|---|
| 目的 | できるだけ多くのページを発見・インデックス化 | 特定のウェブページから必要なデータを抽出 |
| 例え | 図書館の本をすべて目録に登録する司書 | 必要な本から重要なメモだけを抜き出す学生 |
| 出力 | URLリストやページ内容(インデックス用) | 欲しい情報をまとめたCSV、Excel、JSONなどのデータセット |
| 主な利用者 | 検索エンジン、SEO監査、ウェブアーカイブ | 営業、マーケティング、リサーチなどのビジネスチーム |
| 規模 | 大規模(数百万〜数十億ページ) | ピンポイント(数十〜数千ページ) |
ざっくりまとめると:
- ウェブクローリングはページを見つけて地図を作ること
- ウェブスクレイピングはそのページから欲しいデータを抜き出すこと
特に営業やEC、マーケティングの現場では、スクレイピング(構造化データの取得)の方がニーズが高いです。クローリングは検索エンジンや大規模な情報収集に不可欠ですが、スクレイピングは必要なデータを効率よく集めるための手法です。
ウェブクローラーのビジネス活用例
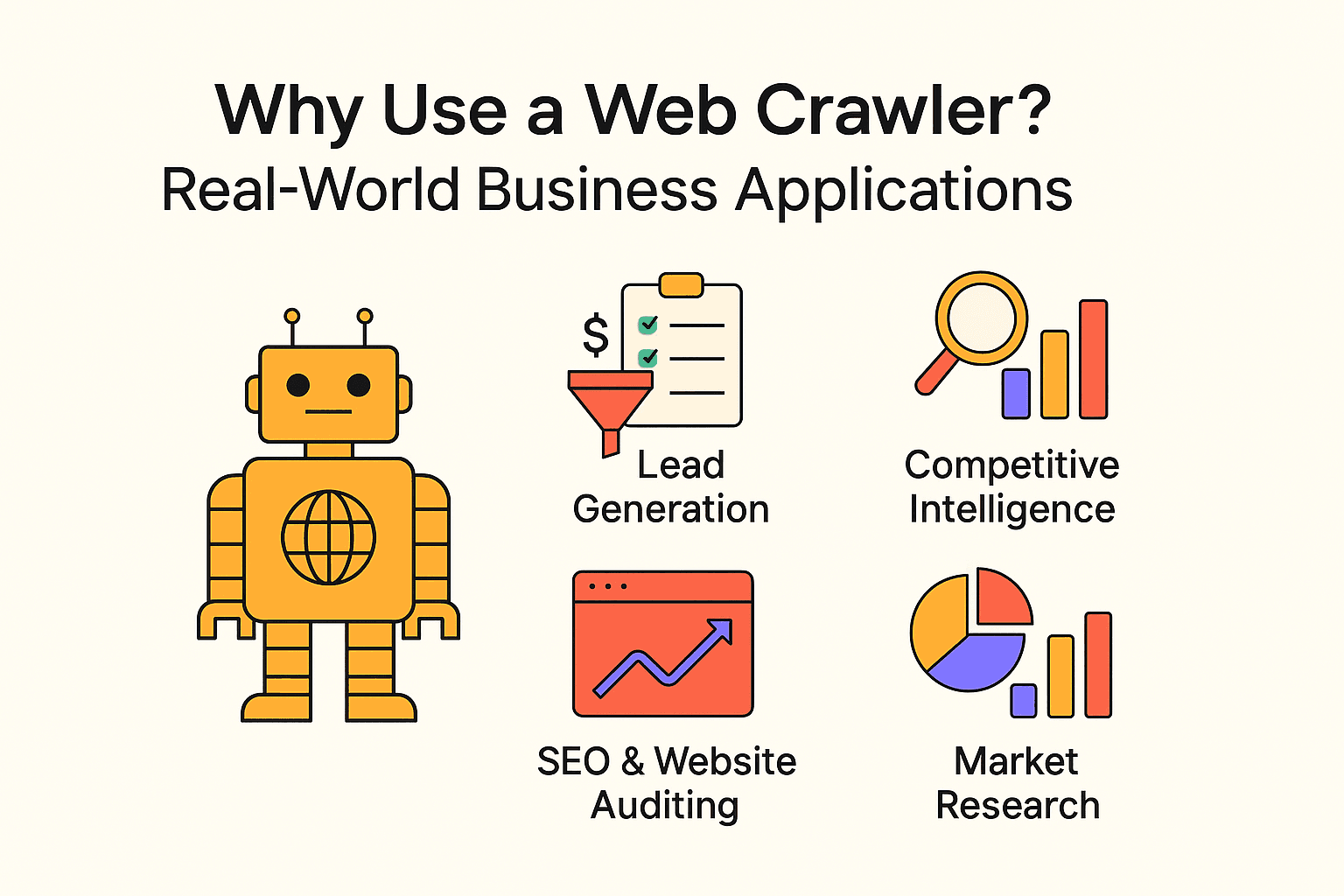
ウェブクローリングは検索エンジンだけのものではありません。多くの企業がクローラーやスクレイパーを活用し、業務効率化や新たなビジネスチャンスを生み出しています。主な活用例をまとめました:
| 用途 | 主な利用者 | 期待できる効果 |
|---|---|---|
| リード獲得 | 営業チーム | 見込み顧客の自動収集、CRMのリード充実 |
| 競合調査 | 小売・EC | 競合の価格や在庫、商品変更のモニタリング |
| SEO・サイト監査 | マーケ・SEO担当 | リンク切れやサイト構造の最適化 |
| コンテンツ集約 | メディア、リサーチ、HR | ニュース、求人、公開データの収集 |
| 市場調査 | アナリスト、商品企画 | レビューやトレンド、口コミの大規模分析 |
- Grouponはウェブクローリングでリード獲得数を2倍に
- EC企業の82%、金融機関の71%が意思決定にウェブスクレイピングを活用
- ウェブスクレイピングはインフラコストを90%削減、作業時間も60%短縮できる事例も
つまり、ウェブデータを活用しないと、競合に後れを取るリスクが高いということです。
Pythonでウェブクローラーを作るには?
プログラミングに慣れている方なら、Pythonはカスタムクローラー作成にぴったりの言語です。基本的な流れは:
- requestsでウェブページを取得
- BeautifulSoupでHTMLを解析し、リンクやデータを抽出
- ループや再帰でリンクをたどり、さらにページを巡回
メリット:
- 柔軟性が高く、複雑なロジックやデータフローも実装可能
- データベース連携や独自処理も自由自在
デメリット:
- プログラミングスキルが必要
- サイト構造が変わるとメンテナンスが大変
- ボット対策や遅延、エラー処理も自分で対応が必要
初心者向けPythonクローラー例:
以下はquotes.toscrape.comから名言と著者を取得するシンプルなスクリプトです:
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com/page/1/>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for quote in soup.find_all('div', class_='quote'):
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
print(f"{text} --- {author}")
複数ページを巡回したい場合は、「次へ」ボタンを見つけてループ処理を追加しましょう。
よくある落とし穴:
- robots.txtやクロール遅延を無視しない(マナーを守りましょう)
- ボット対策でブロックされることがある
- 無限ループ(例:カレンダーなど)に注意
Pythonでシンプルなウェブクローラーを作る手順
自分でコードを書いてみたい方のために、基本的なクローラーの作り方をステップごとに紹介します。
ステップ1:Python環境の準備
まずPythonをインストールし、必要なライブラリを追加します:
pip install requests beautifulsoup4
うまくいかない場合は、Pythonのバージョン(python --version)やpipの動作を確認しましょう。
ステップ2:クローラーのコアロジックを書く
基本パターンは以下の通りです:
import requests
from bs4 import BeautifulSoup
def crawl(url, depth=1, max_depth=2, visited=None):
if visited is None:
visited = set()
if url in visited or depth > max_depth:
return
visited.add(url)
print(f"Crawling: {url}")
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# リンクを抽出
for link in soup.find_all('a', href=True):
next_url = link['href']
if next_url.startswith('http'):
crawl(next_url, depth + 1, max_depth, visited)
start_url = "<http://quotes.toscrape.com/>"
crawl(start_url)
ポイント:
- クロールの深さを制限して無限ループを防ぐ
- 訪問済みURLを記録して重複を避ける
- robots.txtを守り、リクエスト間に**time.sleep(1)**などで遅延を入れる
ステップ3:データの抽出と保存
データを保存するには、CSVやJSONファイルに書き出します:
import csv
with open('quotes.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Quote', 'Author'])
# クローリングループ内で:
writer.writerow([text, author])
JSON形式で保存したい場合はPythonのjsonモジュールも使えます。
ウェブクローリングの注意点とベストプラクティス
ウェブクローリングはとても便利ですが、使い方を間違えるとIPブロックなどのリスクもあります。以下の点に気をつけましょう:
- robots.txtを必ず確認・遵守する:サイトごとのルールを守る
- クロールは控えめに:リクエスト間に数秒の遅延を入れ、サーバーに負荷をかけない
- 範囲を限定する:必要な範囲・深さだけクロールする
- User-Agentを明記する:自分のボット名や連絡先を記載
- 法令遵守:個人情報や非公開データは取得しない
- 倫理的に利用する:サイト全体のコピーやスパム利用はNG
- 小規模からテスト:まずは小さく始めて問題なければ拡大
詳しくはこちらのベストプラクティスガイドも参考にしてください。
ビジネスユーザーにはウェブスクレイピング:Thunderbitの活用
AIであらゆるウェブサイトからデータ抽出 Get Started Free
正直なところ、検索エンジンを自作したい、サイト全体の構造を把握したいという場合を除けば、多くのビジネスユーザーにはウェブスクレイピングツールの方が断然おすすめです。
そこで推したいのがThunderbitです。私自身が共同創業者兼CEOとして開発に関わっていますが、技術に自信がない方でも直感的にウェブデータを抽出できるツールだと自負しています。
Thunderbitの特長
- 2クリックで完了:「AIで項目を提案」→「スクレイピング開始」だけ
- AI搭載:ページ内容を自動で解析し、商品名・価格・画像など最適なカラムを提案
- 一括・PDF対応:今見ているページ、複数URL、PDFからもデータ抽出OK
- 柔軟なエクスポート:CSV/JSONでダウンロード、Google SheetsやAirtable、Notionにも直接送信
- ノーコード:ブラウザ操作ができれば誰でも使える
- サブページも自動巡回:詳細データも自動で取得・充実
- スケジューリング:自然な日本語で定期実行も設定可能(例:「毎週月曜9時に実行」)
クローラーを使うべきケースは?
サイト全体の構造を把握したい(検索インデックスやサイトマップ作成など)場合はクローラーが適していますが、特定ページから構造化データ(商品リスト、レビュー、連絡先など)を取得したい場合は、スクレイピングの方が圧倒的に手軽で実用的です。
まとめ・ポイントのおさらい
最後にポイントをまとめます:
- ウェブクローリングは検索エンジンや大規模データ収集の基盤。幅広くページを発見・地図化する手法です。
- ウェブスクレイピングは、必要なデータをピンポイントで抽出する手法。多くのビジネスユーザーはこちらが主流です。
- 自作クローラーも可能(Pythonが便利)ですが、手間やメンテナンスが必要です。
- ノーコード・AI搭載ツール(Thunderbitなど)なら、誰でも簡単にウェブデータを活用できます。
- ルールとマナーを守ることが大切:サイトの規約や倫理を守り、正しくデータを活用しましょう。
まずは簡単なプロジェクトから始めてみましょう。例えば商品価格の収集や、ディレクトリからリード情報を集めるなど。Thunderbitのようなツールを使えばすぐに成果が出せますし、Pythonで仕組みを学ぶのもおすすめです。
ウェブは情報の宝庫です。正しい方法で活用すれば、ビジネスの意思決定や業務効率化に大きく役立ちます。
FAQ
- ウェブクローリングとウェブスクレイピングの違いは?
クローリングはページの発見・地図作成、スクレイピングはそのページから必要なデータを抽出することです。クローリング=探索、スクレイピング=抽出。
- ウェブスクレイピングは合法ですか?
公開データの取得であれば、robots.txtや利用規約を守れば基本的に問題ありません。非公開や著作権のあるコンテンツは避けましょう。
- ウェブサイトのデータ抽出にプログラミングは必要?
いいえ。Thunderbitのようなツールなら、クリックとAIだけでデータ抽出が可能です。
- なぜGoogleはウェブ全体をインデックスしないの?
多くのページがログインや有料壁の裏にあったり、ブロックされているためです。実際にインデックスされているのは全体の約4%です。
さらに学びたい方へ
- FreeCodeCamp – PythonとBeautifulSoupによるウェブスクレイピング入門
- Scrapy公式チュートリアル
- Real Python – SeleniumとPythonでのウェブスクレイピング
- Apify Academy: ウェブスクレイピングと自動化
AIウェブスクレイパーを試す Get Started Free




