
Amazonウェブスクレイパーとは
Amazonウェブスクレイパーは、Amazon.com からデータを自動で取得するための便利なツールやソフトウェアです。取得できるデータには、商品詳細、価格、レビュー、在庫状況などが含まれます。Amazonウェブスクレイパーを使う主な目的は、市場調査、価格比較、競合分析のために大量のデータを集めることです。さらに、ユーザーレビューを収集してキーワード調査に活用し、商品の長所と短所を把握することもできます。
Amazonウェブスクレイパーの主な機能
- データ抽出の自動化: 面倒なコピペ作業とはもうお別れです。ウェブスクレイパーを使えば、必要なデータをWebページから自動で取得できます。
- 柔軟なスクレイピング: 必要に応じて、特定のデータタグだけを取得するように調整できるため、狙った分析ができます。
- データのエクスポート: 抽出したデータは、Excel、CSV、JSON などの一般的な形式へ簡単に書き出せます。さまざまなデータツールでさらに分析できます。
- 定期更新: 取得間隔を設定してAmazonの商品データベースを最新の状態に保ち、常に鮮度の高いデータを維持できます。
- レビューのスクレイピング: 多くの場合、競合分析のためにレビューセクションから長所と短所を抽出する必要があります。

Amazonウェブスクレイパーを使う理由
Amazonは、豊富な商品ラインナップ、競争力のある価格、スムーズな購入体験で知られる、世界のEコマース市場の大きなプレイヤーです。企業が世界中の潜在顧客にリーチできるプラットフォームを提供し、市場の広がりを後押しします。消費者からも、信頼できるオンライン購入先として支持されており、販売者にとって安心して使える販売環境が整っています。さらに、Amazonの物流ネットワークを活用すれば、迅速で効率的な配送サービスを提供でき、顧客満足度の向上にもつながります。加えて、スポンサー広告やブランドプロモーションなど、商品の露出と売上を高めるマーケティングツールも充実しています。
Eコマース企業にとって、Amazon上の販売データを分析することは非常に重要です。Amazonウェブスクレイパーを使えば、市場トレンドや消費者行動を把握するためのデータを収集し、商品戦略や在庫管理の最適化につなげられます。これにより、Amazonプラットフォーム上で効率よく事業を拡大し、売上とブランド認知を高めながら持続的な成長を実現できます。以下では、分析にAmazonウェブスクレイパーをどう活用できるかを紹介します。
市場調査
-
SKUの選定
適切な**SKU(在庫管理単位)**を選ぶことは、Eコマース成功のカギです。商品構成、サプライチェーン効率、在庫管理に大きく影響します。Amazonウェブスクレイパーを使えば、数百万件の商品から正確なデータを抽出し、売上動向や顧客の好みを分析できます。たとえば、Amazonの商品詳細ページをスクレイピングすれば、商品価格、レビュー数、販売者評価などの重要情報を簡単に取得でき、より深い市場分析が可能です。こうしたデータは、SKUに市場性があるかを判断するのに役立ち、どの商品が最も好調かも見えてきます。同じカテゴリ内で商品を比較することで、企業は商品選定を最適化し、人気SKUの在庫を増やし、動きの遅い商品の在庫を減らすことで、在庫回転率を改善できます。
-
顧客トレンドの把握
大量の商品レビュー、評価、顧客フィードバックをスクレイピングすることで、ウェブスクレイパーは消費者需要の変化を素早く見つける助けになります。たとえば、レビューのデータを分析すれば、「手頃な価格」や「耐久性」など、消費者が商品で最も重視している特徴を特定できます。これは、製品開発、価格戦略、マーケティング戦略にとって非常に重要です。さらに、購入頻度や時系列の売上動向をスクレイピングすれば、季節ごとの売上変動を予測し、在庫やマーケティング施策を前もって計画できます。

競合分析
-
価格モニタリング
競争の激しい環境では、価格モニタリングはEコマース企業にとって欠かせません。Amazonウェブスクレイパーを使えば、商品データをリアルタイムで取得し、競合の価格変動を追跡できるため、自社価格の競争力を維持しやすくなります。これは、ダイナミックプライシング戦略を導入するうえで特に有効です。類似商品の価格情報を収集することで、市場需要、在庫水準、競合価格に応じて自動調整する柔軟な価格モデルを構築でき、利益最大化につながります。
-
レビューのスクレイピング
顧客レビュー は、商品の売上に影響を与えるだけでなく、市場需要の変化も反映します。Amazonウェブスクレイパーを使えば、大量の顧客フィードバックを収集できます。AIベースのウェブスクレイパーなら、要約や感情分析も支援できるため、自社商品や競合商品に対するユーザーの意見を把握し、製品設計やマーケティング戦略をすばやく調整できます。
コスト比較
Amazonウェブスクレイパーを使えば、類似商品の価格、送料、プロモーション情報を収集し、包括的なコスト比較ができます。こうしたデータを分析することで、コスト構造の最適化、不要な支出の削減、利益率の向上が可能です。Amazonで仕入れ先を探す企業にとっても、各販売者の送料や販売価格を把握できるため、コストを抑えながら市場で競争力のある価格設定を実現し、最終的には粗利益率の改善につながります。
AIを使ったウェブスクレイピングを試す
ぜひ試してみてください。クリックして操作しながら、実際のワークフローを見て体験できます。
AIでAmazonの商品データをスクレイピングする理由
AIの急速な進化により、AI駆動のAmazonウェブスクレイパーツールはデータ取得の新時代を切り開いています。従来のウェブスクレイピングに比べて、さまざまな利便性を提供します。AIはデータ収集の効率と精度を高めるだけでなく、技術的なハードルも大きく下げ、Eコマース企業により革新的な可能性をもたらします。
非エンジニアにも使いやすい
技術的な背景がないユーザーにとっても、AI対応のAmazonウェブスクレイパーツールは非常に便利です。従来のスクレイパーのように手動でのコーディングやAPI呼び出しは不要で、必要なスクレイピング条件を伝えて、取得したい列名を選ぶだけです。AIが適切なスクレイピング計画や提案を自動生成してくれるため、プログラミングや複雑な設定の手間を省けます。こうした使いやすさにより、専門の技術担当がいなくてもEコマースチームは効率よくデータを取得でき、チームの生産性向上と、非技術職のメンバーでも高度なデータ収集ツールを簡単に使える環境づくりに役立ちます。
高速で効率的
AIを使ってあらゆるWebサイトからデータをスクレイピング Get Started Free
AI Web Scraper はデータ抽出プロセスを自動化し、スクレイピングの速度と効率を大幅に向上させます。複雑なサイト構造や動的コンテンツにも素早く対応し、対象データを正確に取得できるため、手作業の介入を減らし、全体の精度も高めます。さらに、AI Web Scraper は運用コストを大きく削減し、ワークフローを最適化できるため、より低コストで高品質なデータを取得し、意思決定により的確な材料を提供できます。
インテリジェントな分析と提案
従来のウェブスクレイパーと比べて、AI web scraper には、インテリジェントなワークフロー自動化という強みがあります。AIツールはデータの分類、要約、インサイトの提示まで自動で行えます。たとえば、商品をあらかじめ定義したカテゴリに自動分類したり、大量のレビューを分析してキーワードや感情の傾向を抽出したりできるため、企業は顧客の声をより深く理解し、商品を最適化できます。また、AIはスクレイピングしたデータをもとにカスタムレポートを作成し、市場分析を自動生成して、人気商品の特徴や潜在的な市場機会をすばやく見つける手助けもします。
賢い出力とエクスポートの選択肢
AIベースのAmazonウェブスクレイパーを使えば、より賢い形でデータを出力できます。従来のコーディング手法では通常CSVファイルの出力に限られますが、AIツールはCSV形式に加え、Google SheetsやNotionなどのコラボレーションプラットフォームへも自動エクスポートでき、データ分析と共有を大幅に効率化します。たとえば、データをGoogle Sheetsに直接取り込んでリアルタイム分析したり、チームのコラボレーションツールに連携したりできるため、部門間での情報共有がスムーズになります。このようなスマートなデータ出力により、チームはより素早く意思決定でき、事業全体の柔軟性と対応力が向上します。
Thunderbit でスクレイピングする方法: AI Web Scraper
Thunderbit は、新しく登場した強力で包括的な AI駆動のウェブスクレイパーツール です。データ取得のニーズに合わせて設計されています。Thunderbit を使えば、商品詳細、価格変動、顧客レビューなど、Amazonのさまざまなデータを簡単に収集し、価値あるビジネスインサイトへ素早く変換できます。Eコマース企業の競争力強化に Thunderbit がどう役立つのか、見ていきましょう。
まず、ThunderbitのWebサイト にアクセスし、Thunderbitの ウェブスクレイパー拡張機能 をChromeブラウザに追加します。Googleアカウントまたは任意のメールアドレスでログインしてください。
 次に、Thunderbitに標準搭載されている事前作成済みのウェブスクレイパー、または AI web scraper を使って、Amazonの商品データとレビューをスクレイピング できます。手順は以下のとおりです。
次に、Thunderbitに標準搭載されている事前作成済みのウェブスクレイパー、または AI web scraper を使って、Amazonの商品データとレビューをスクレイピング できます。手順は以下のとおりです。
オプション1: Thunderbitの事前作成済みウェブスクレイパーを使う
Thunderbit は、ユーザーのニーズに基づいてさまざまな事前作成済みウェブスクレイパーツールを設計・最適化しており、その中にはAmazon専用のスクレイパーモジュールも含まれています。これらのツールには、Amazonの複雑なデータ構造に対応したテンプレートがあらかじめ用意されているため、大量のデータ収集をすぐに始められます。スクレイピングロジックを自分で設計する必要がなく、より速く効率的にデータを取得できます。
Amazonの任意のページを開いたら、Thunderbit拡張機能のウェブスクレイパーを起動します。すると、列名が充実した2つの事前作成済みスクレイパーが表示されます。抽出したい列名にチェックを入れるだけで、あとはThunderbitが処理してくれます。
-
Amazon SKUレビューの収集
このツールには、商品名、商品URL、総合評価、詳細な評価内訳、レビュー件数、レビュータイトル、投稿者名、レビュー本文、レビューの国、キーワードなどの事前作成済み列名が用意されています。抽出したい列名にチェックを入れてスクレイピングをクリックすれば、商品レビュー分析に必要なSKUレビューのデータをすばやく取得できます。
-
Amazon SKU詳細の収集
このツールでは、商品名、商品URL、ブランド、メーカー、初回価格、最終価格、説明、評価、カテゴリ、配送オプション、販売者URLなどの事前作成済み列名が利用できます。抽出したい列名にチェックを入れてスクレイピングをクリックすれば、必要なSKU詳細データをすぐに取得できます。販売者、メーカー、配送オプションの比較、市場調査、SKUの価格競争力の確認、最新の売上動向の把握など、これらのSKU詳細データは分析に役立ちます。
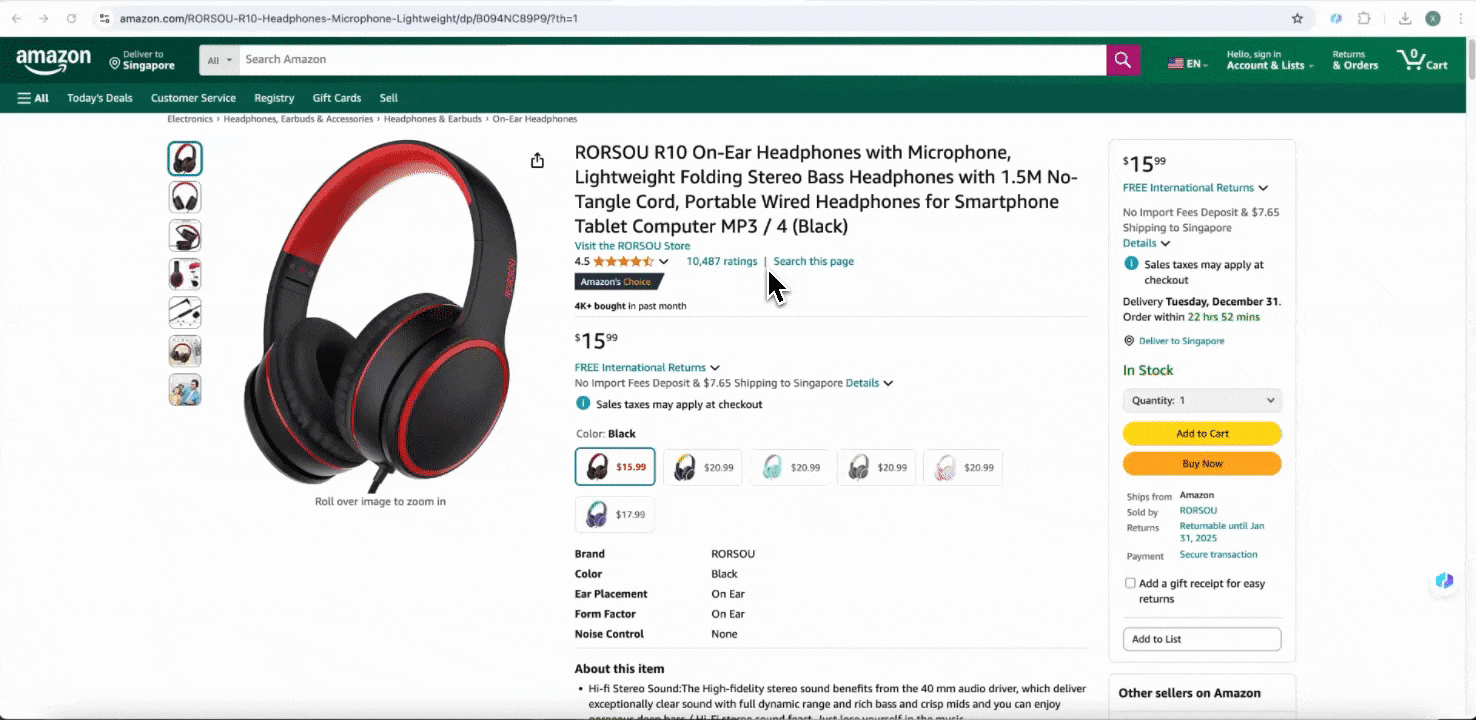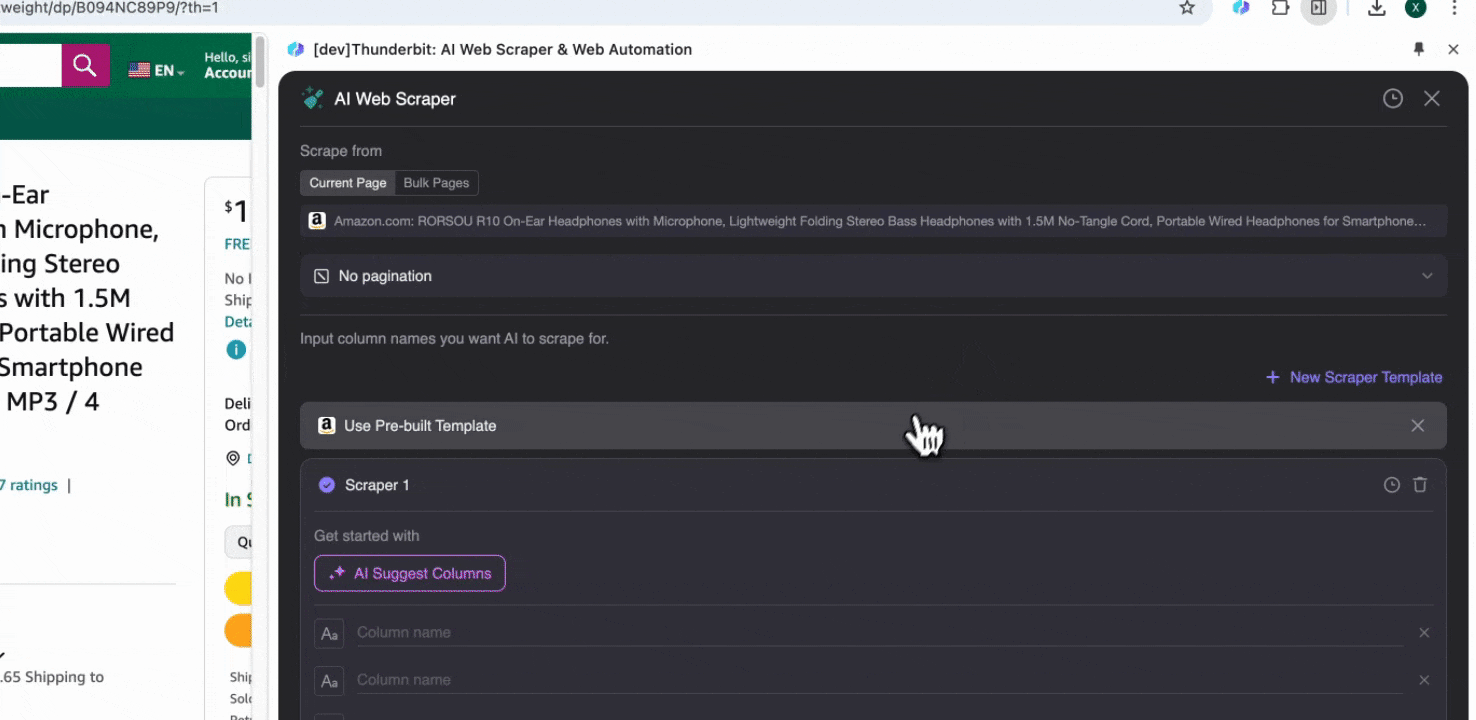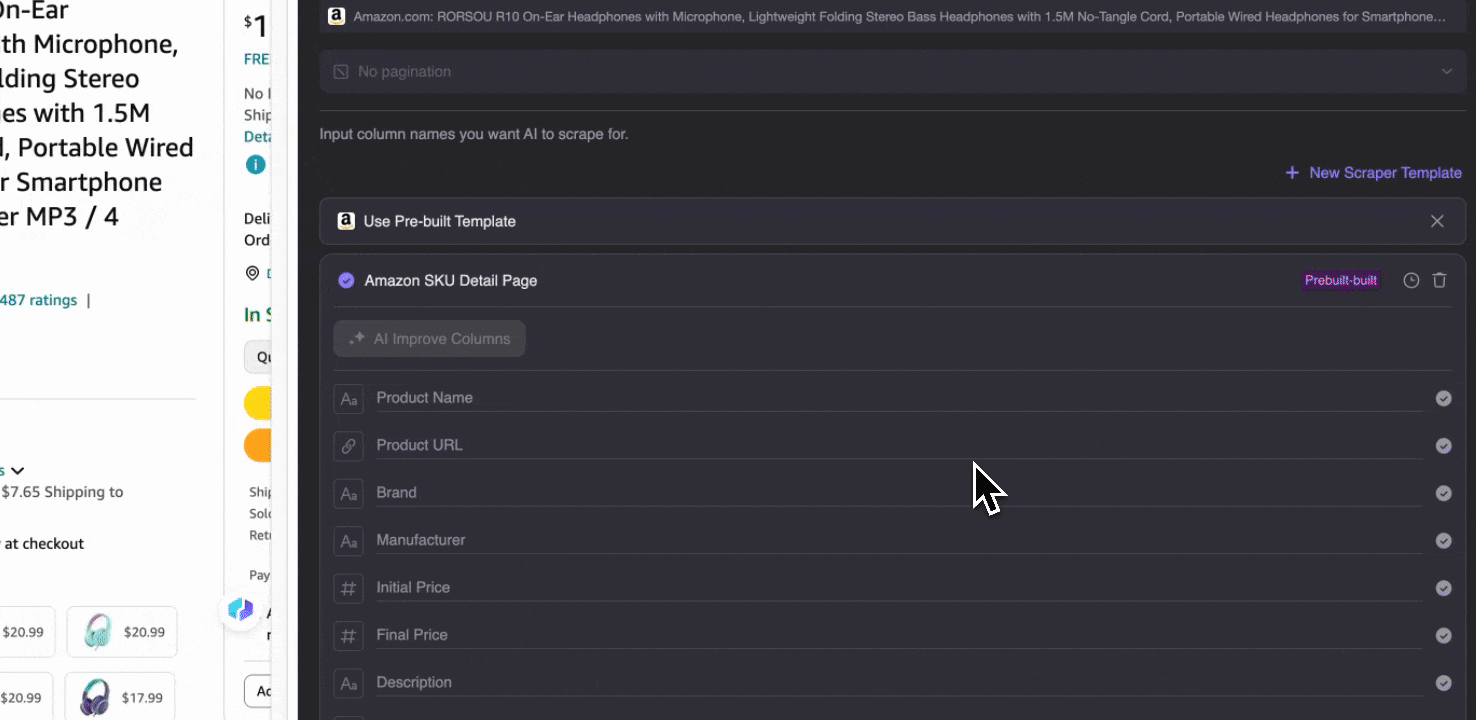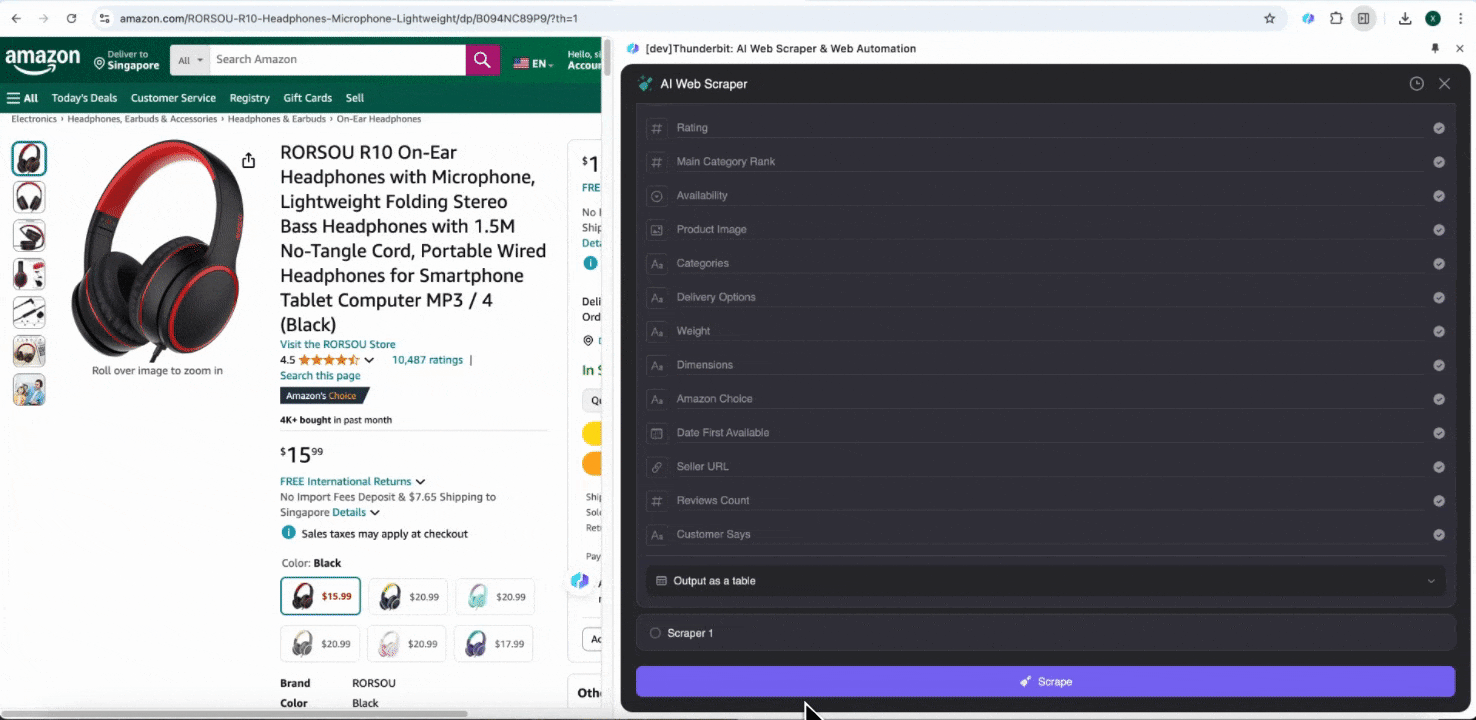
オプション2: ThunderbitのAI Web Scraperを使う
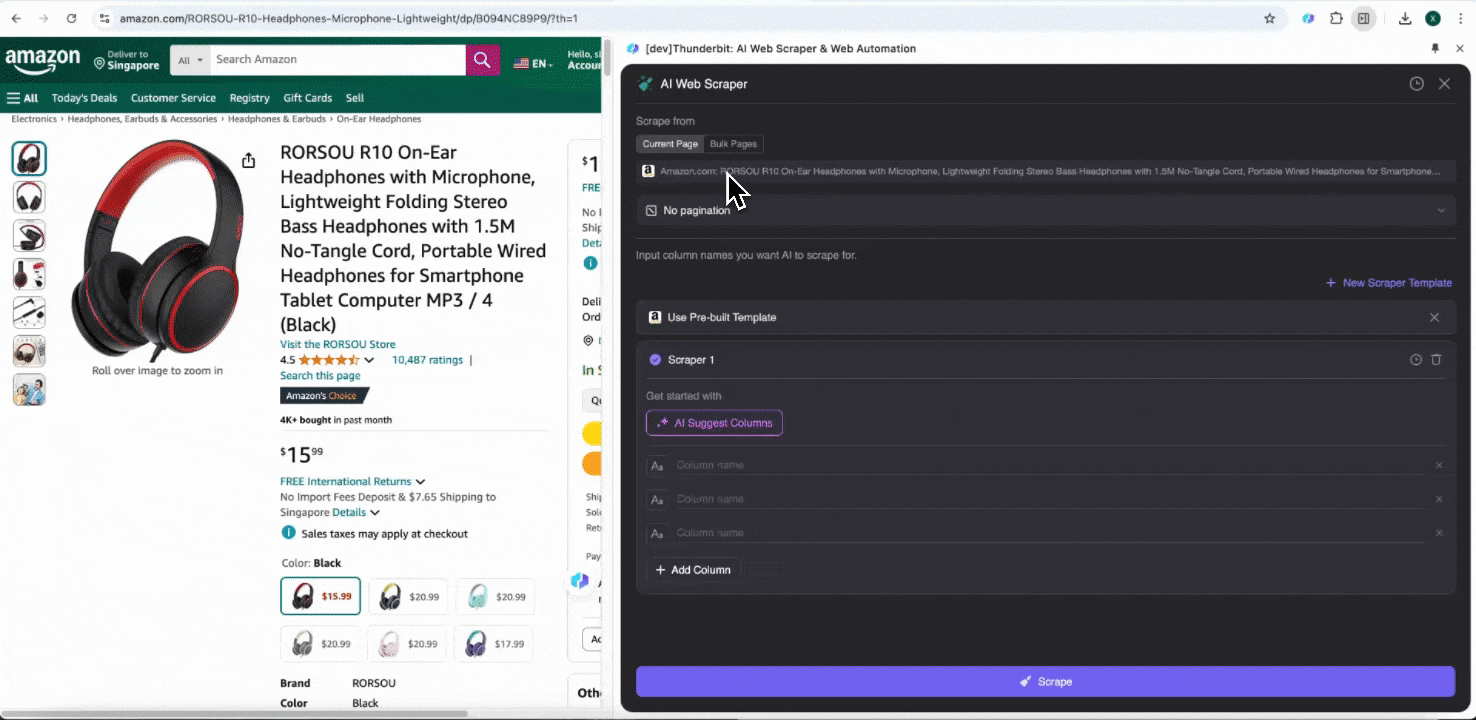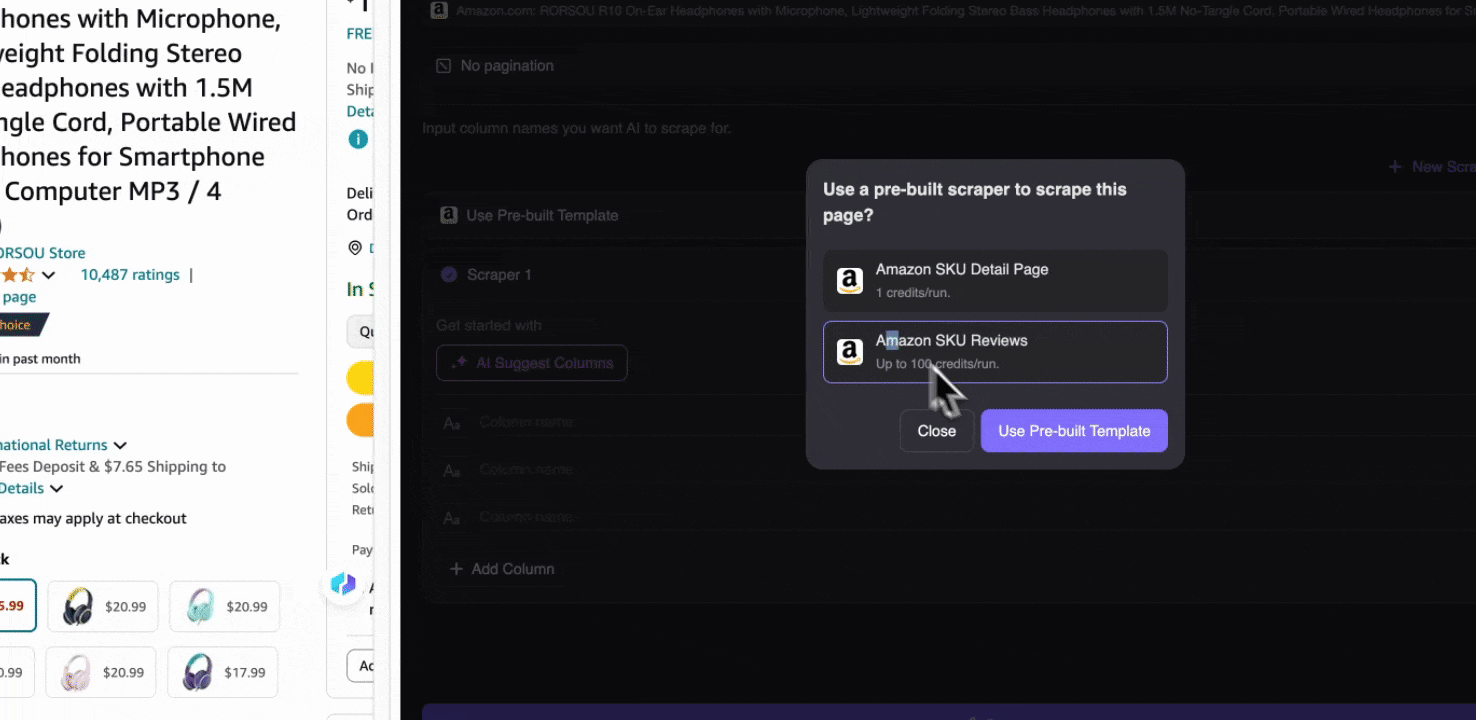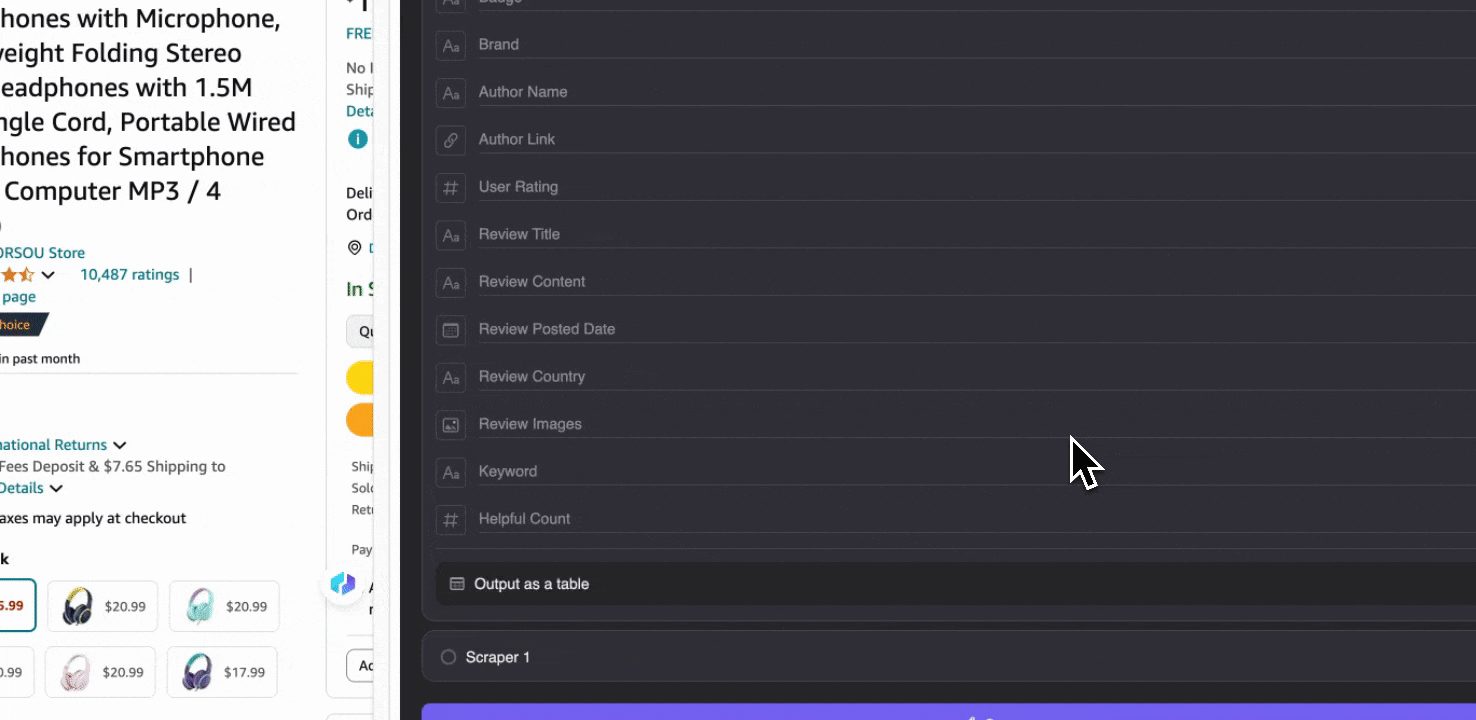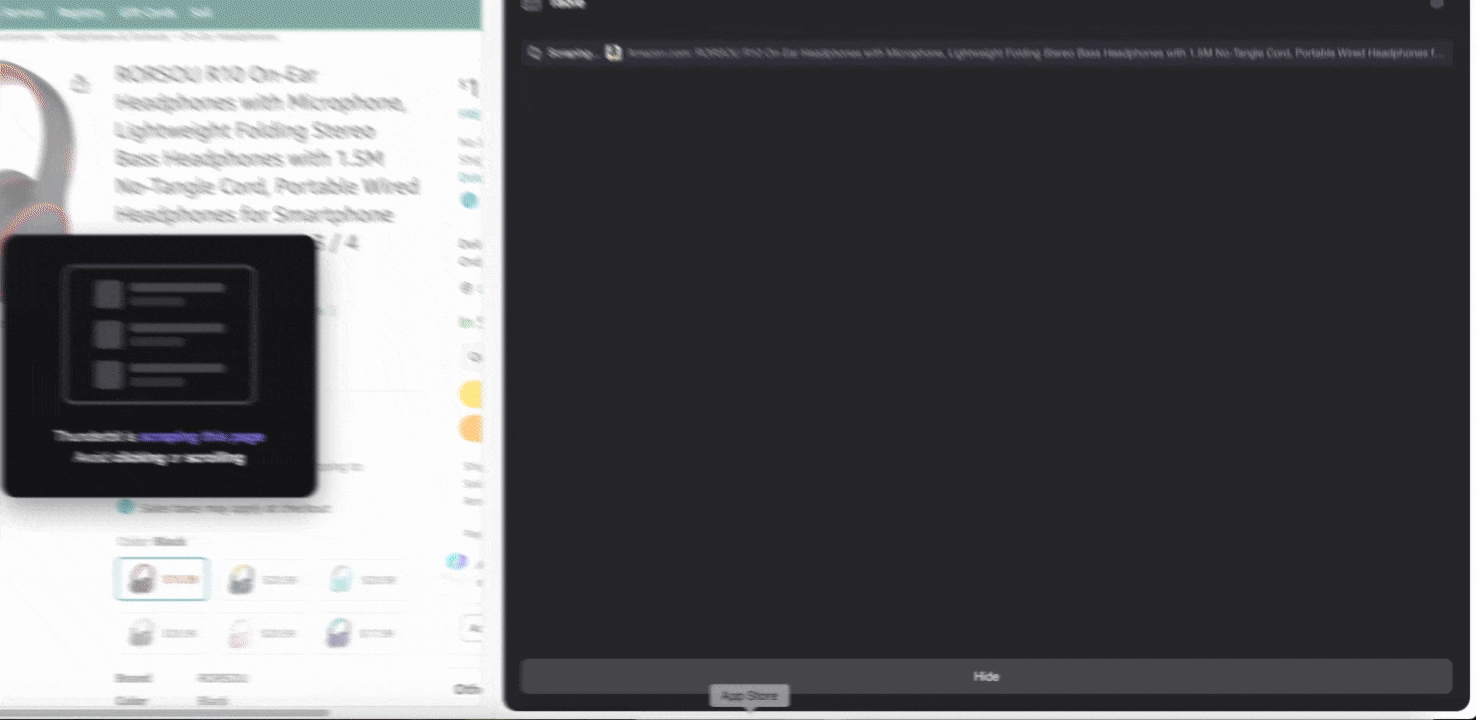
ステップ1: Amazon.com を開き、サイドバーの「AI Web Scraper」をクリックする
Chromeブラウザで AmazonのWebサイト を開き、データを抽出したいページを検索または閲覧したら、Chromeの右上にあるThunderbitアイコンをクリックして拡張機能を開き、「AI Web Scraper」をクリックします。
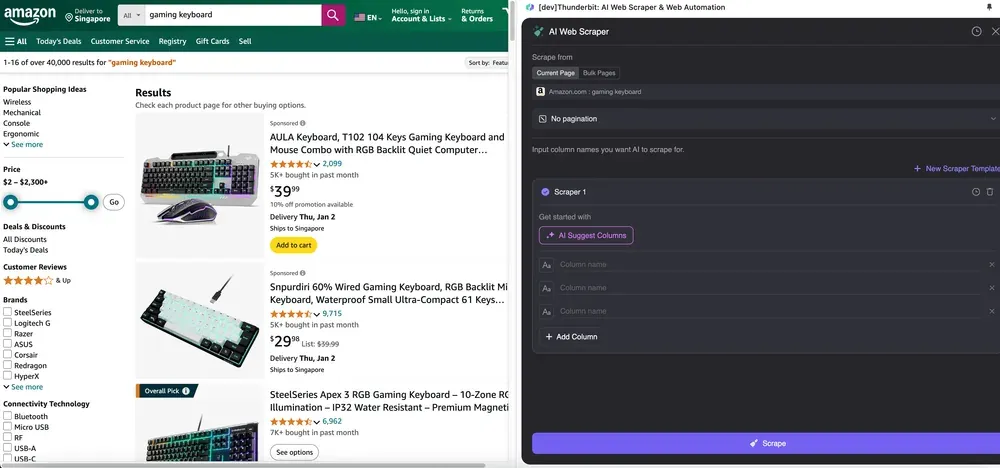
ステップ2: 抽出したいデータ項目をカスタマイズする
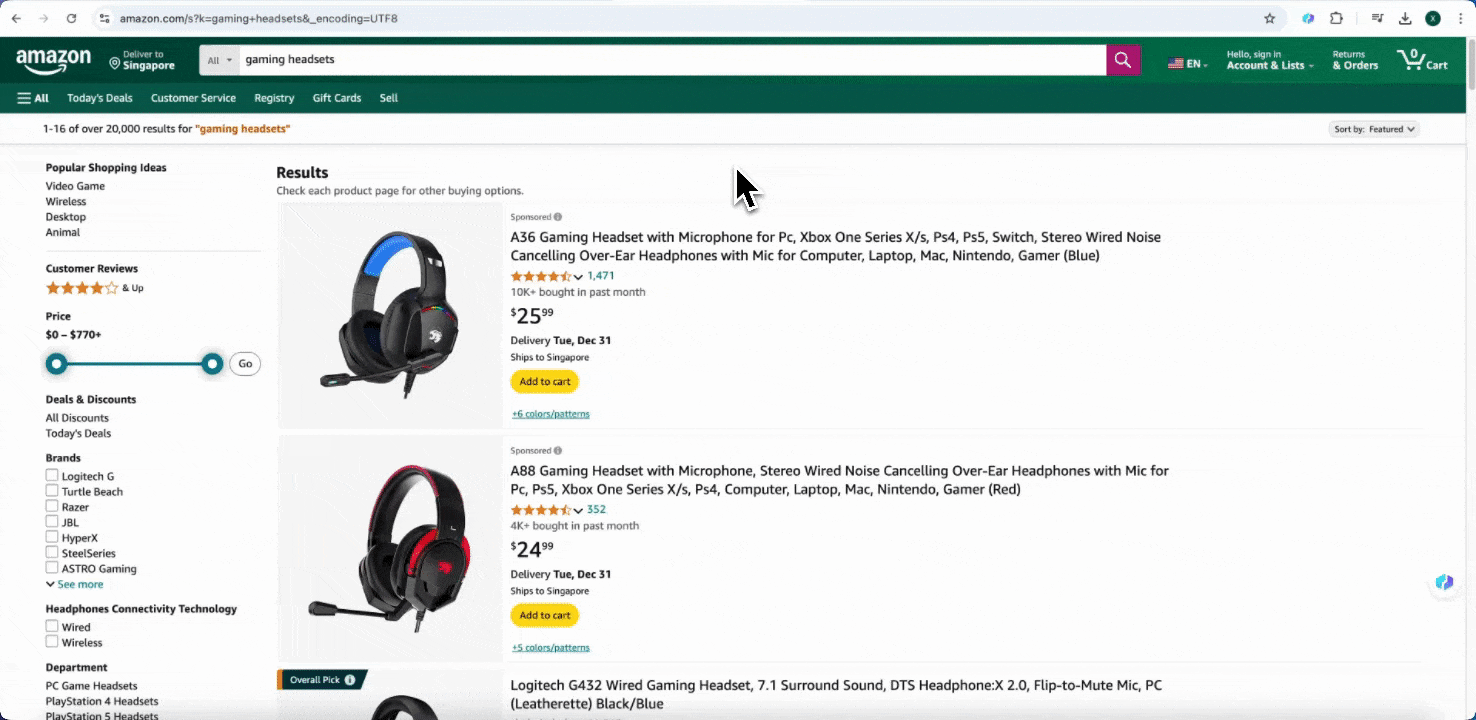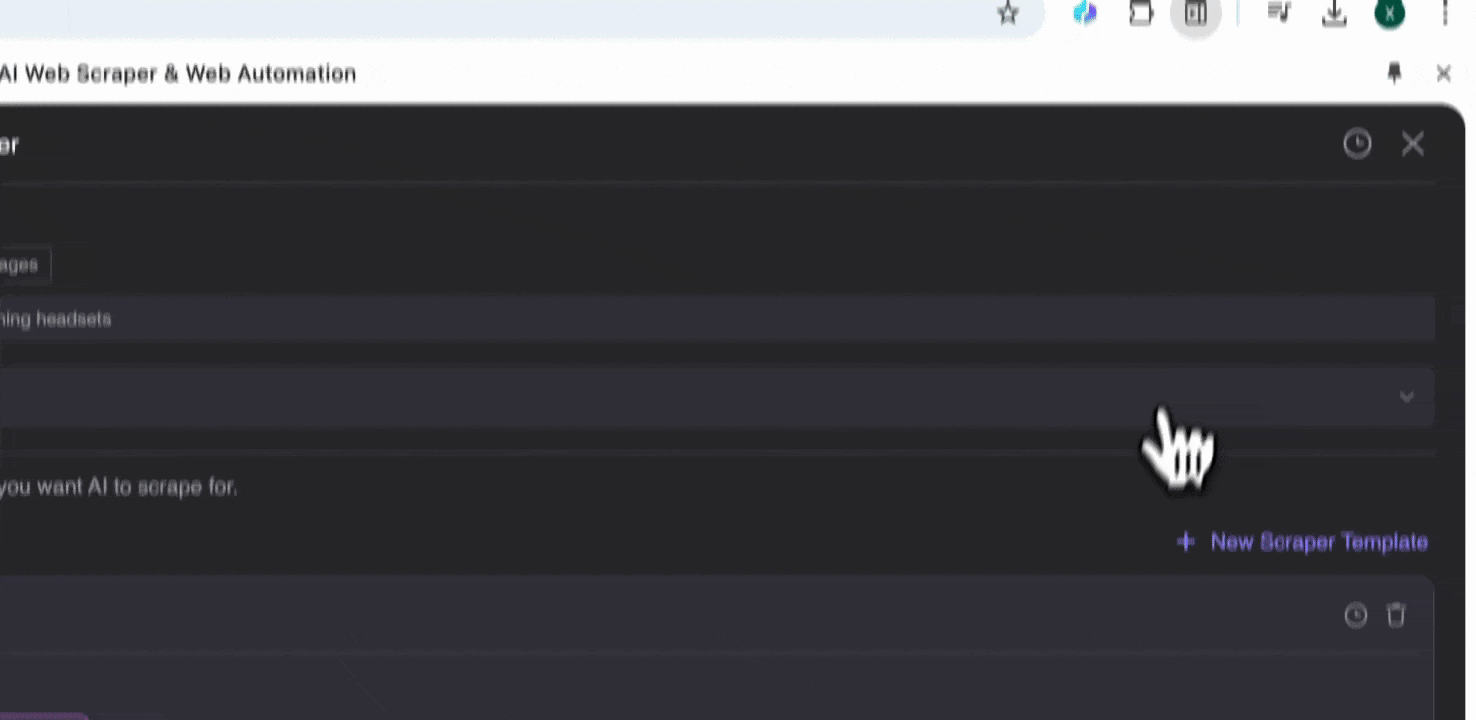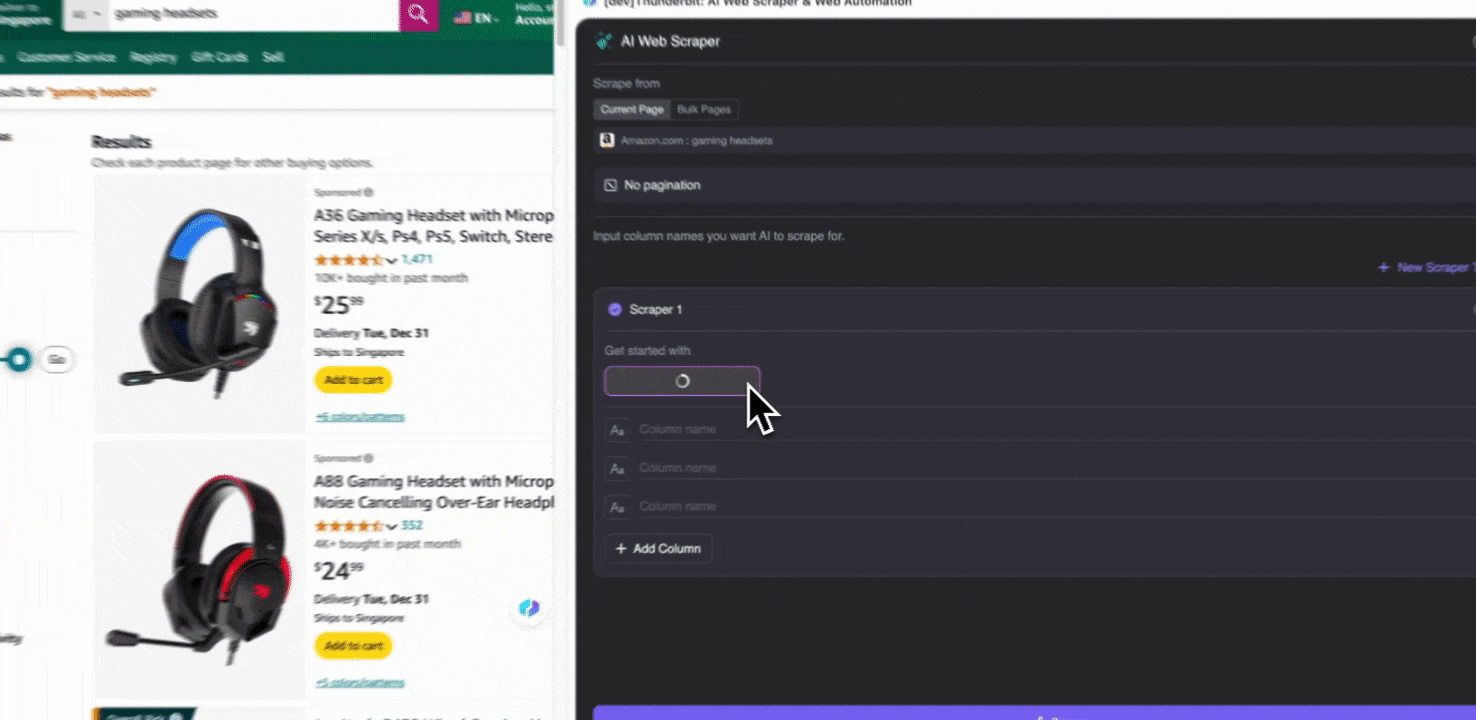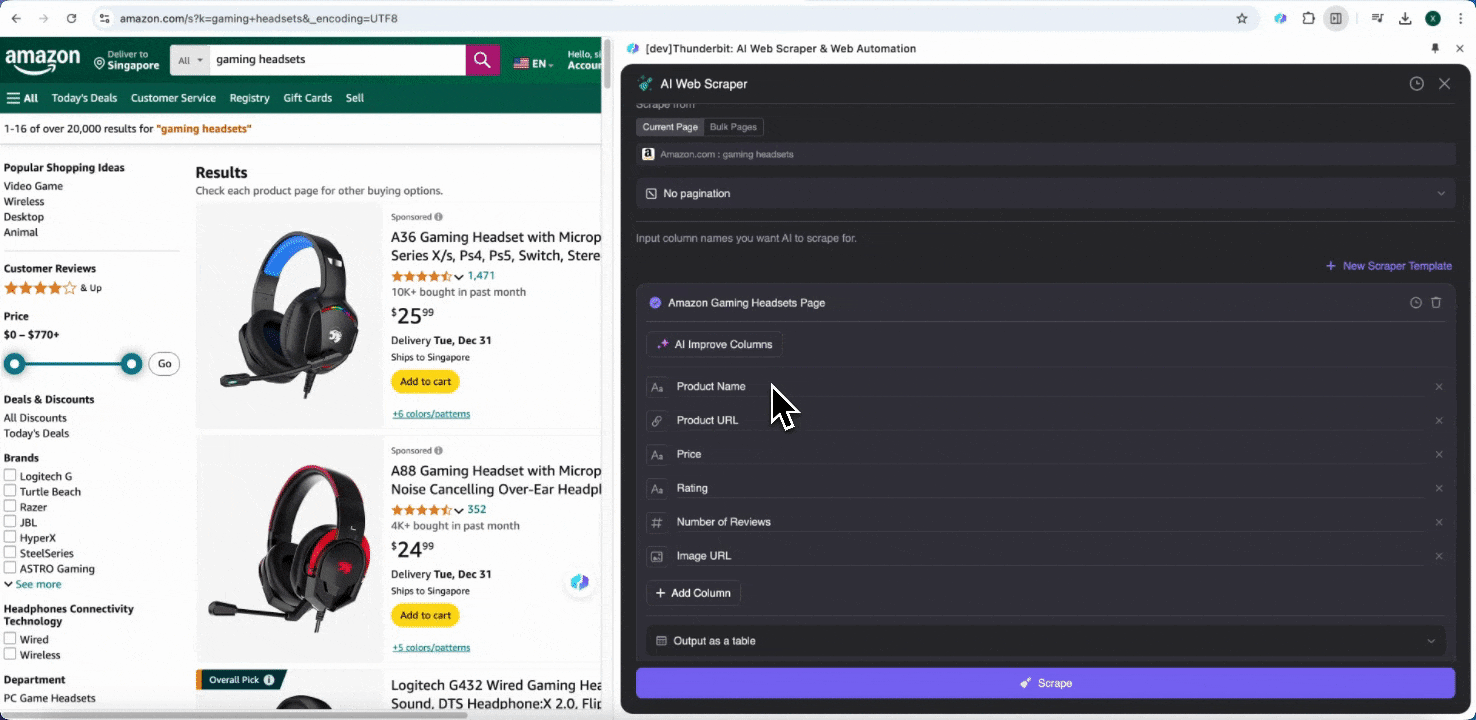
必要なデータタグがよく分からない場合は、「AIで列を提案」をクリックすると、ThunderbitのAIが信頼性の高い列名を自動生成します。自然言語で欲しいデータラベルを説明し、列名欄に入力することもできます。アイコンを選んで、画像、URL、テキスト、数値など、取得したいデータ型を切り替え、対応するデータをスクレイピングしてください。
初期の列名を入力したあとで、「AIで列を改善」を選ぶと、AIがさらに内容を最適化できます。列ごとの詳細指示を追加して、ニーズに合わせてカスタマイズすることも可能です。たとえば、商品タイプの列について、商品をメンズ、レディース、子ども向け、その他に分類するよう依頼できます。Thunderbitは、その列内の各データを指定した4つのカテゴリに振り分けます。また、価格列のすべての価格を現在の為替レートで希望通貨に変換するよう指示することもでき、通貨の不一致を気にせず、分析に使いたい値を簡単に取得できます。
最後に、取得するデータ量もカスタマイズできます。Amazonの商品ページでは、ページネーションのクリック回数と、スクレイピングしたいページ数を選択できます。Thunderbitが自動でページ送りし、各ページのデータをすべて抽出します。
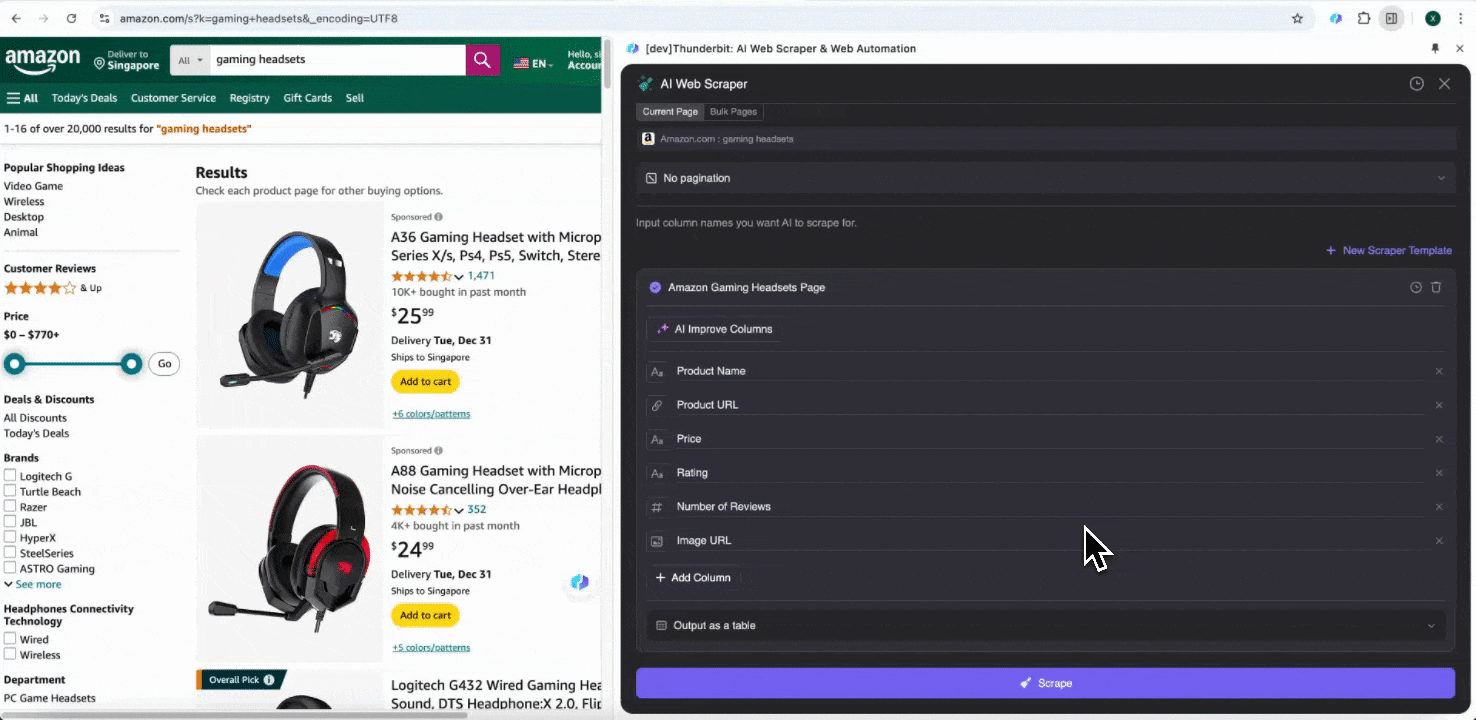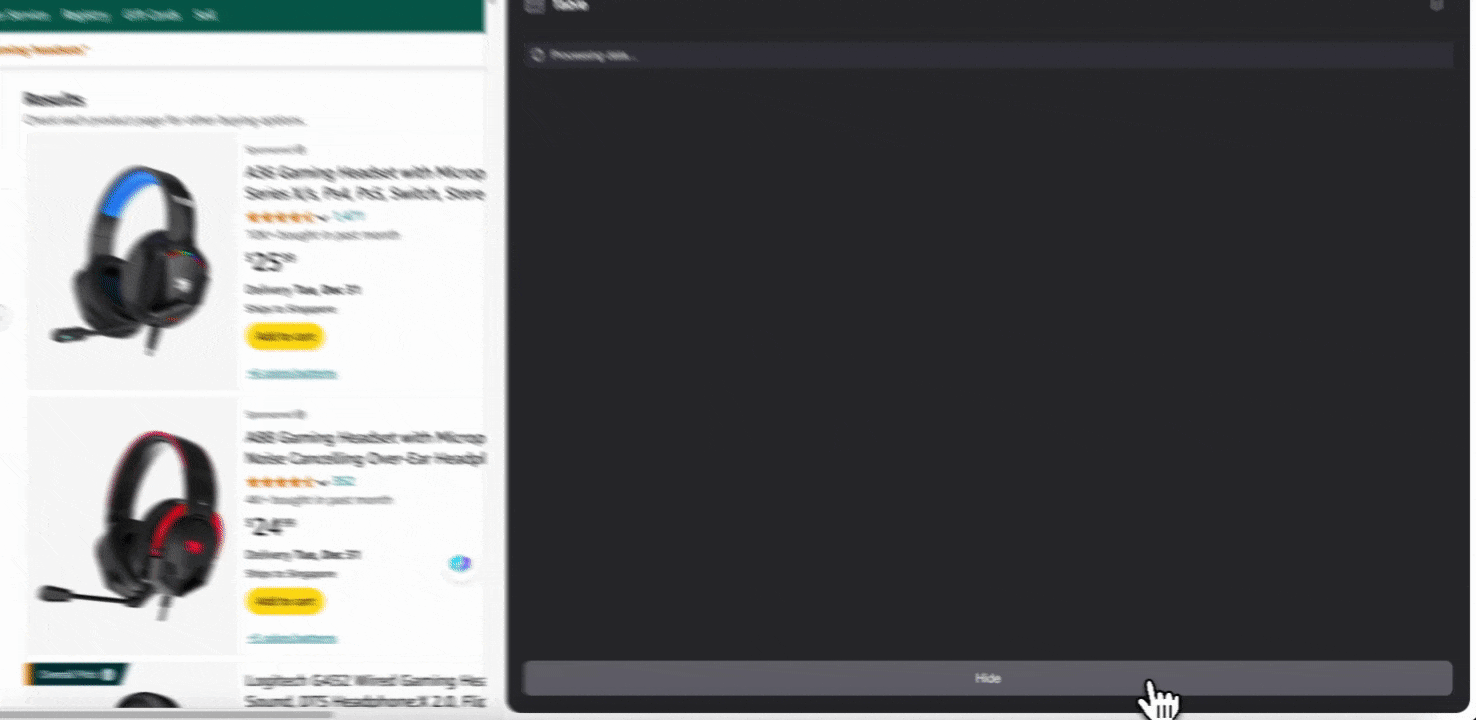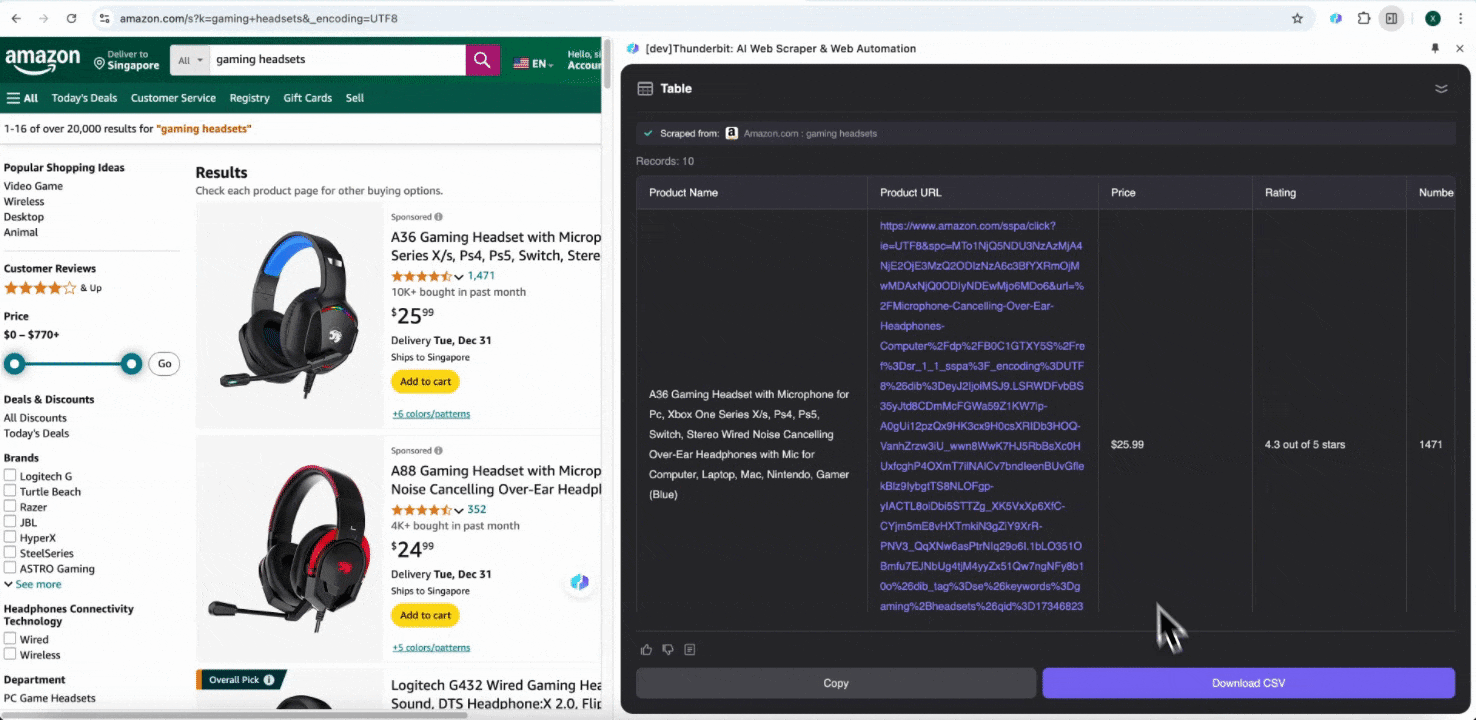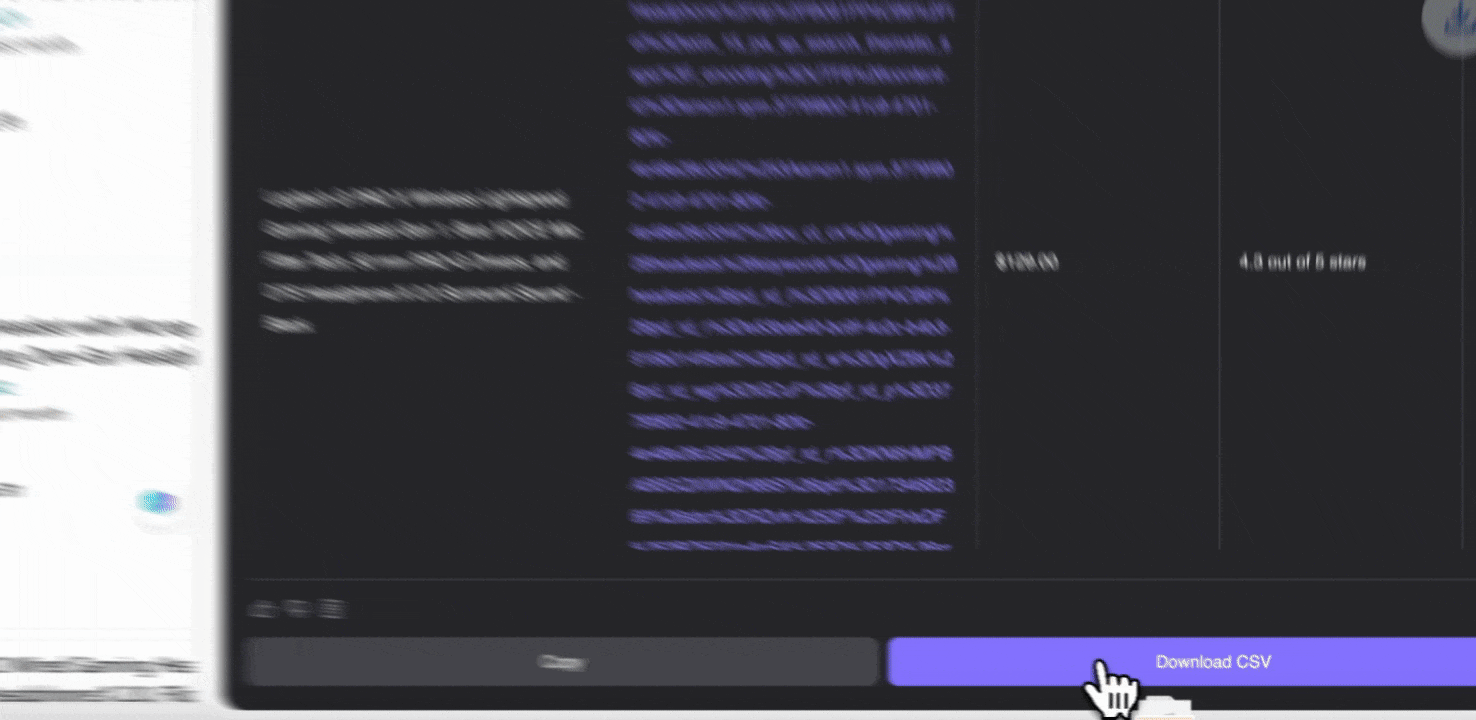
ステップ3: 抽出したデータをダウンロードするか、表としてエクスポートする
Thunderbitのウェブスクレイパー拡張機能を使えば、抽出したデータをさまざまな方法でエクスポート できます。出力形式として表を選び、CSVファイルをローカルにダウンロードするか、Google Sheetsに保存 、Notion、Airtable のいずれかを選択します。アカウントにログインして、これらのオンラインファイル管理・共同作業プラットフォームへ直接エクスポートできます。
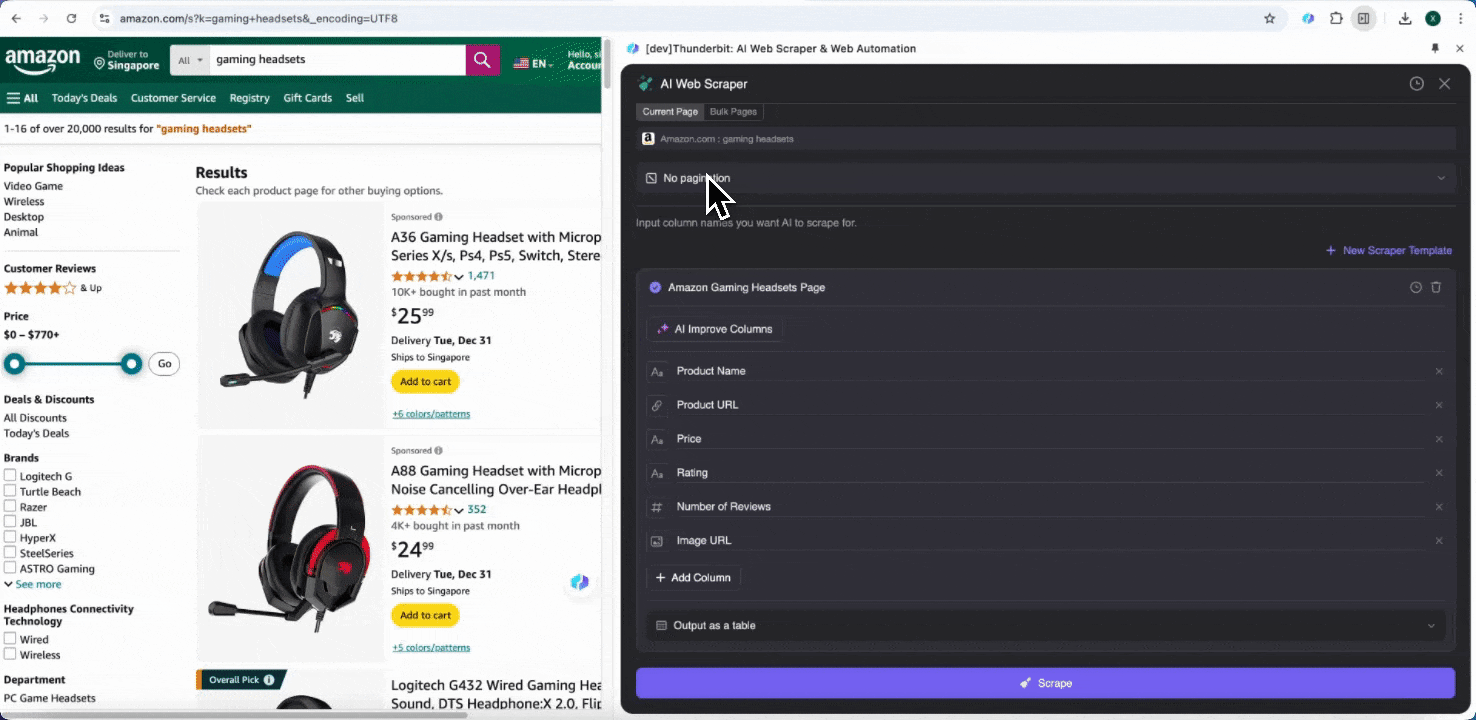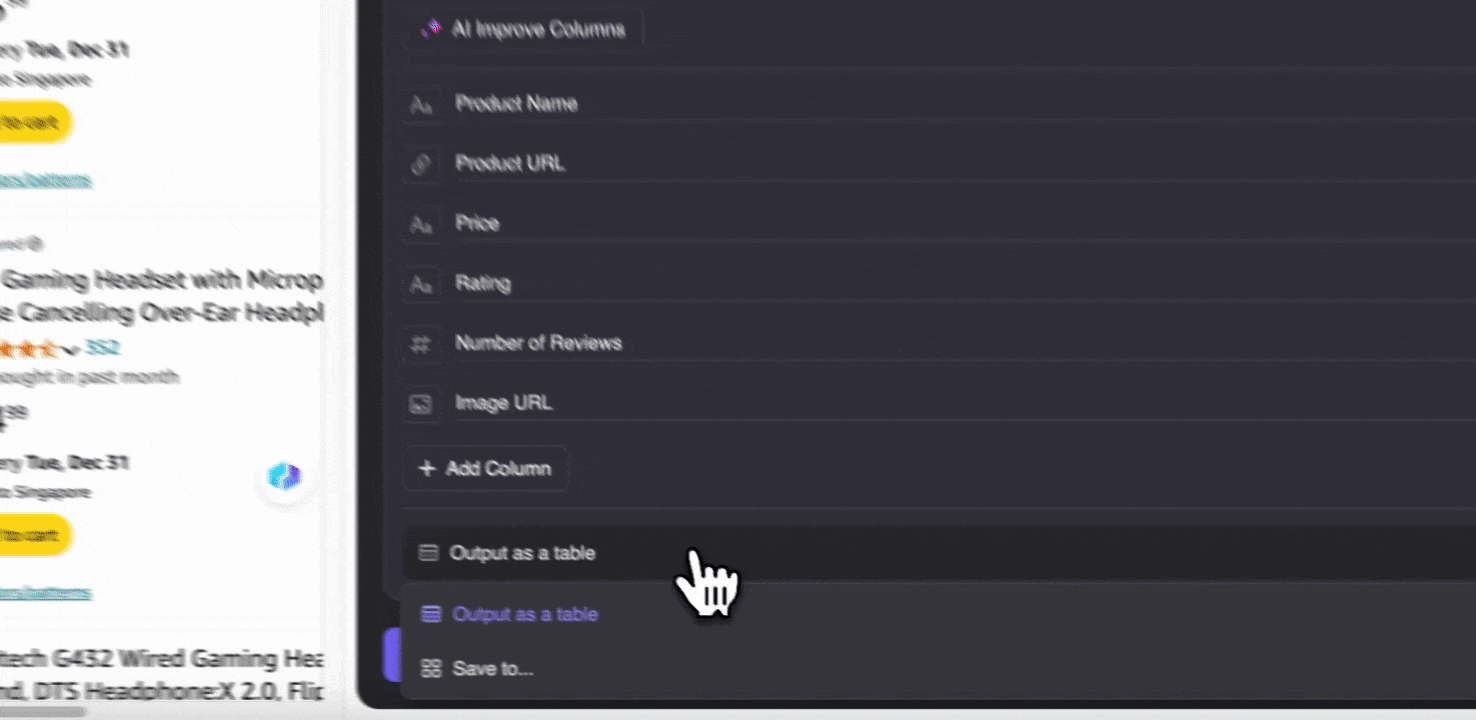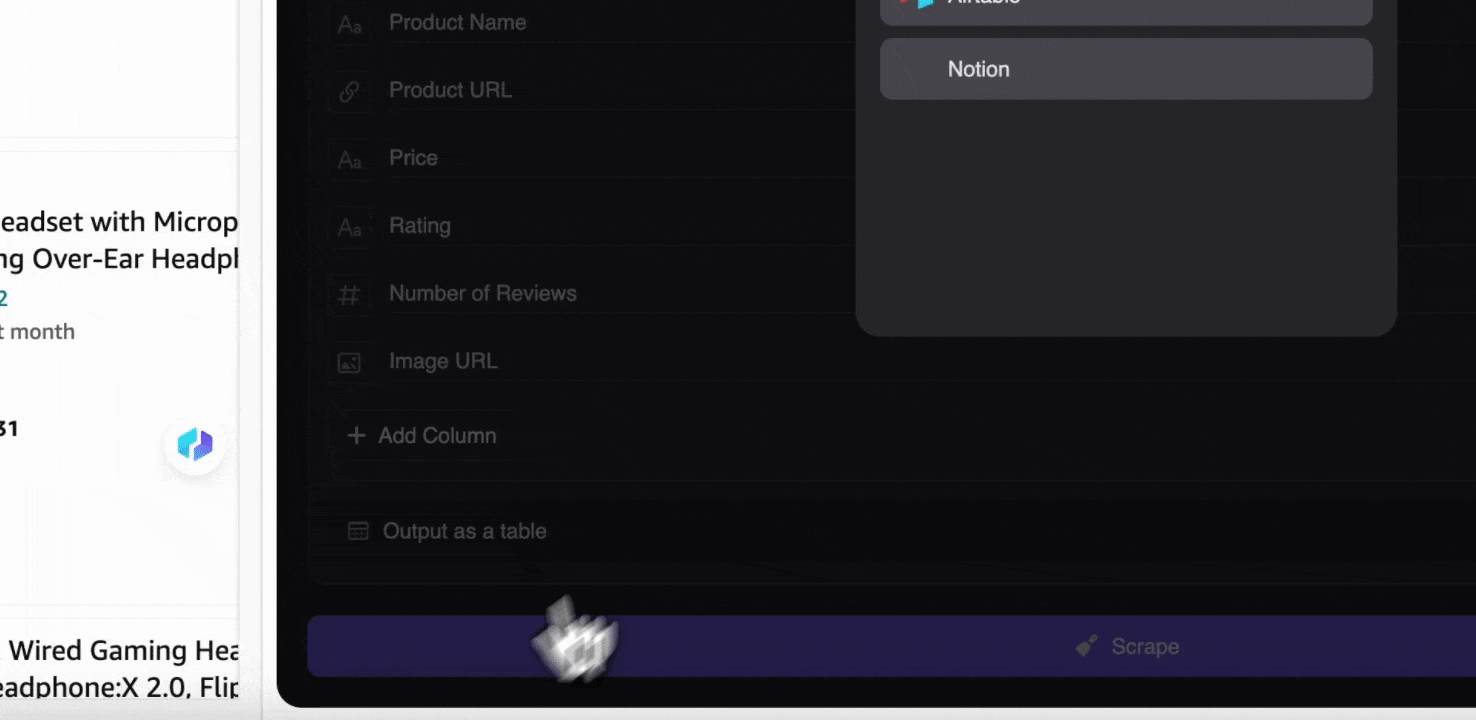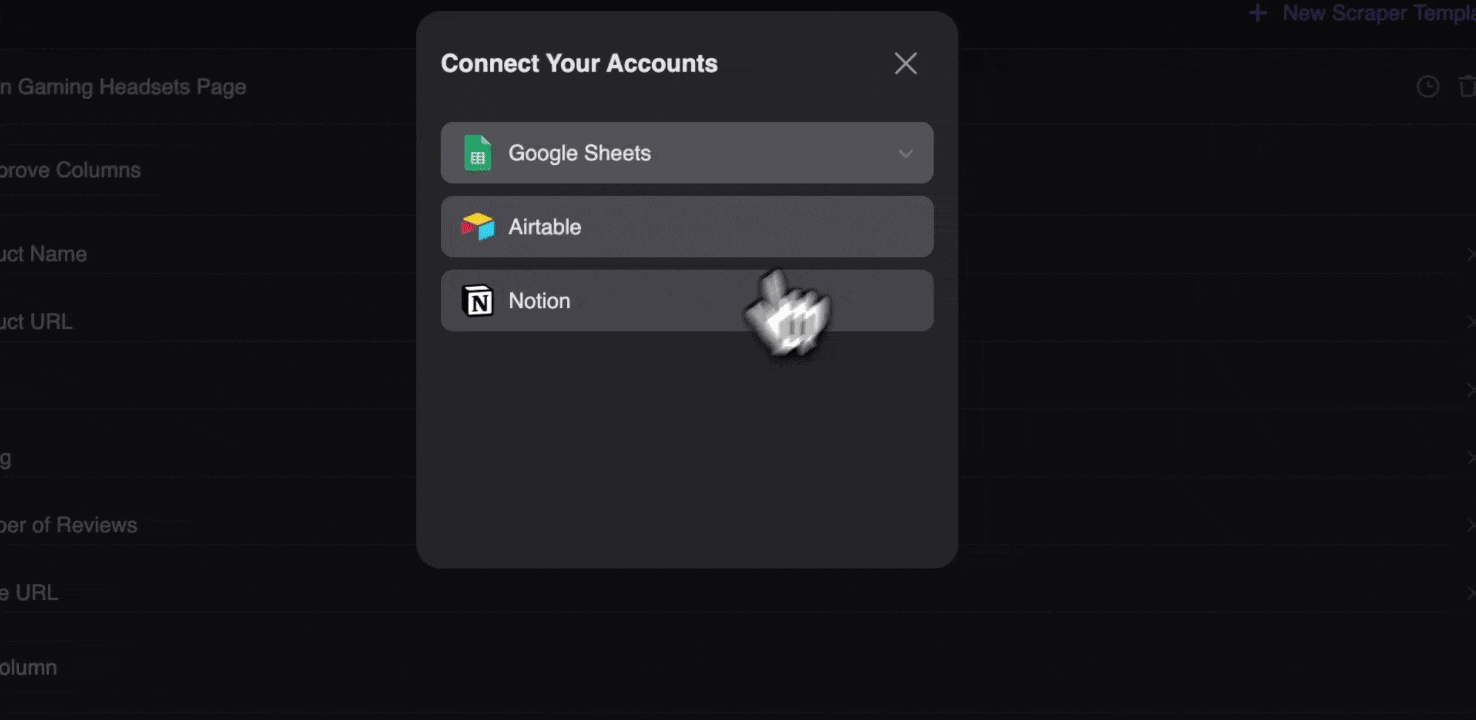
AIでAmazonのSKUデータを2クリックでスクレイピング
従来型ウェブスクレイパーでのスクレイピング
最新のAIツール以外にも、軽量なコードやAPIを使った従来型のウェブスクレイパーツールでAmazonの商品データを取得できます。
ScraperAPI: APIでAmazonの商品データをJSON形式で取得する
ScraperAPIは、Amazonから商品詳細、レビュー、検索結果、価格情報を取得し、構造化されたJSON形式で返す効率的なAmazonデータ収集APIを提供しています。APIを使ったスクレイピング方法は以下のとおりです。
ステップ1: Python環境を準備する
まず、Python 3.8以降がインストールされていることを確認してください。その後、Pandasのような一般的な分析ライブラリや、requests、BeautifulSoup のようなウェブスクレイピング用ライブラリをインストールします。これらのライブラリを使うと、Webページからデータを簡単に抽出できます。
ステップ2: ScraperAPIのアカウントを作成する
ScraperAPIのWebサイト にアクセスして無料アカウントを作成し、APIキーを取得します。このキーを使って、コードからScraperAPIにアクセスできます。
ステップ3: コードを準備する
ローカルに専用ディレクトリを作成し、Pythonスクリプトを書いてデータスクレイピングを実装します。基本的な流れは次のとおりです。
- Amazonの検索URLを取得する: Amazonで対象の商品を検索し、検索結果ページのURLをコピーします。
- リクエストを構築する: ScraperAPIは検索結果の最初の5ページを自動でループします。各ページのURLは、ベースURLに &page= と該当ページ番号を追加して作成します。
- リクエスト送信とデータ解析: get() メソッドを使ってScraperAPIにリクエストを送ります。リクエストが成功し、ステータスコード200が返ったら、ページ内容を解析して目的のASIN(Amazon標準商品番号)を抽出します。
- 詳細な商品データを取得する: 構造化データのエンドポイントを呼び出せば、各ASINの詳細な商品情報を取得でき、さらに分析できます。
ステップ4: 追加のチュートリアルを参照する
より詳しい使い方については、ScraperAPI公式ブログのチュートリアル を参照してください。
ScrapFly: ブロックを回避し、大規模にスクレイピングする
Amazonのデータをスクレイピングする際には、IPブロック、CAPTCHA、動的コンテンツの読み込みなどのアンチスクレイピング対策が、スクレイパー開発者にとって大きな課題になります。ScrapFlyは、こうした回避機構を突破するための強力なAPIを提供し、スムーズなデータ取得を支援します。
ScrapFlyの主な機能は次のとおりです。
- ローテーション対応の住宅用プロキシ: IPアドレスを自動で切り替え、IPブロックを防ぎます。
- JavaScriptレンダリング: 動的コンテンツの読み込みに対応し、JavaScriptでレンダリングされたWebページをスクレイピングできます。
- フルブラウザ自動化: ブラウザを操作して、スクロール、入力、クリックを行えます。
- フォーマット変換: HTML、JSON、テキスト、Markdownとして取得できます。
わずか数行のコードで、ScrapFlyを使ってAmazonデータをスクレイピングできます。簡単な例を示します。
import scrapfly_sdk
# クライアントを作成する
client = scrapfly_sdk.ScraperClient(api_key="your_api_key")
# リクエストを送信する
response = client.scrape(url="<https://www.amazon.com/s?k=product_name>")
# 返却データを取得する
print(response.json())
ScrapFlyを使えば、スクレイパーはAmazonのさまざまなアンチスクレイピング機構に対応でき、データ取得の成功率を高められます。シンプルな商品情報の取得から、複雑なレビュー分析まで、ScrapFlyは非常に実用的なツールです。より詳しい使い方については、ScrapFlyの公式チュートリアル を参照してください。
Pythonでスクレイピングする: 従来のコーディング手法
コードに慣れている技術系ユーザーなら、Pythonコードを書いてAmazonの商品データをスクレイピングすることもできます。参考用に簡単な例を示します。
ステップ1: 前提条件を整える
まず、プロジェクト専用のフォルダを作成します。
mkdir amazonscraper
次に、このフォルダ内に必要なライブラリをインストールします。
pip install beautifulsoup4
pip install requests
これで、好きな名前のPythonファイルを作成します。ここにコード本体を記述していきます。ここでは amazon.py という名前にします。
ステップ2: 対象ページにGETリクエストを送る
requests ライブラリを使って、対象ページにGETリクエストを送ってみましょう。
import requests
from bs4 import BeautifulSoup
target_url = "<https://www.amazon.com/s?k=gaming+headsets&_encoding=UTF8>"
headers = {
"accept-language": "en-US,en;q=0.9",
"accept-encoding": "gzip, deflate, br",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7"
}
response = requests.get(target_url, headers=headers)
ステップ3: Amazonの商品データをスクレイピングする
ここで、対象ページ から何を抽出するかを決めます。
# リクエストが成功したか確認する
if response.status_code == 200:
# ページ内容を解析する
soup = BeautifulSoup(response.content, 'html.parser')
# すべての商品リストを取得する
products = soup.find_all('div', {'data-component-type': 's-search-result'})
# 各商品を順に処理して詳細を抽出する
for product in products:
# 商品タイトルを抽出する
title = product.h2.text.strip()
# 商品価格を抽出する
price = product.find('span', 'a-price')
if price:
price = price.find('span', 'a-offscreen').text.strip()
else:
price = "価格はありません"
# 商品評価を抽出する
rating = product.find('span', 'a-icon-alt')
if rating:
rating = rating.text.strip()
else:
rating = "評価はありません"
# 商品詳細を表示する
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Rating: {rating}")
print("-" * 40)
else:
print(f"ページの取得に失敗しました。ステータスコード: {response.status_code}")
FAQ
1. amazon.com をスクレイピングするのは合法ですか?
はい、Amazonの公開データのスクレイピングは合法です。多くのWebサイトと同様に、Amazonは商品一覧やその他の公開情報を誰でも閲覧できるようにしています。公開されているデータをスクレイピングして収集しても、Amazonの利用規約に違反することはありません。
2. Thunderbitは無料で試せますか?
はい、Thunderbitには無料のページ抽出・データ抽出機能があります。一部の高度な機能は有料の場合がありますが、基本的なデータ抽出機能は通常無料です。
3. Amazonからどんなデータをスクレイピングできますか?
Amazonからは、商品タイトル、価格、説明、レビュー、評価、販売者情報など、さまざまなデータをスクレイピングできます。これらのデータは、市場調査、価格モニタリング、競合分析に役立ちます。
4. Amazonデータはどのくらいの頻度でスクレイピングすべきですか?
頻度は、何のデータを追跡したいかによって異なります。価格や競合の動きを監視するなら、毎日または毎週のスクレイピングがよいでしょう。商品詳細のように比較的変化の少ない情報なら、月1回程度でも十分な場合があります。
さらに詳しく知る
AI Web Scraperを試す Get Started Free




