CRMの価値って、結局は入れるデータのクオリティで決まりますよね。そして実は“使えるデータ”って、高いお金を払って外部データベースを買うより、公開Webサイトの中にゴロゴロ転がっていることが多いんです。
Web抽出ツールを使えば、その雑多でバラバラなWebデータを、扱いやすいスプレッドシート形式にサクッと整えてくれます。良いツールならコード不要で、早ければ数分で終わります。
私はこれまで、リードリスト作成、競合価格の追跡、商品カタログの収集など、実際の案件でこうしたツールを使ってきました。この記事では、ビジネス用途で「これはちゃんと使えた」と感じた12個を、使いやすい順に並べて紹介します。
なぜWeb抽出はビジネスに必須なのか
ぶっちゃけ、Webって世界最大の(そして一番散らかった)データベースです。2026年の今、このカオスを“洞察”に変えられる会社が一歩抜け出しています。でも、データドリブンな企業は同業他社より生産性が5%高く、利益率も6%高いとされています。誤差じゃなくて、ちゃんと差が出てる数字です。
Web抽出ツール(web page extractor や web extracting solution と呼ばれることもあります)は、その差を生む“縁の下の力持ち”。営業チームなら、公開ディレクトリ、SNS、企業サイトから情報を抽出して、狙いを絞った見込み客リストを作成できます。古いリードリストを買ったり、インターンがコピペ地獄で途中離脱しないことを祈ったりする必要はありません()。マーケやECチームは、Web抽出で競合価格の追跡、在庫状況の監視、商品のベンチマークをリアルタイムで実行できます。たとえばJohn Lewisは、Webスクレイピングによる価格最適化だけで売上が4%伸びたとしています()。
メリットは数字だけじゃありません。Web抽出はとにかく時間を節約できるし(自動化で「何百時間も節約できた」という声も)、ヒューマンエラーも減らせます()。オペレーション部門なら、昔はインターンが何週間もかけていた収集作業を、スクレイパーで継続的に回せるようになって、面倒なコピペに吸われていた時間を取り戻せます()。さらにAI搭載の抽出ツールなら、非エンジニアでもWebサイトを分析用の構造化データに変換できます()。
結論として、2026年にWeb抽出を使っていないなら、洞察も売上機会も取りこぼしている可能性が高いです。
トップ12のWeb抽出ツールを選んだ基準
Web抽出ツールって本当に山ほどあります。なので私はいろいろ触ったうえで、次の観点で12個に絞り込みました。
- 使いやすさ: 非エンジニアでも、コードを書かずにすぐ始められるか。直感的なノーコード/ローコードを優先()。
- AI機能: 抽出項目の自動検出、サイト遷移の処理、自然言語での指示など、AIでスクレイピングがラクになるか()。
- 自動化・スケジュール: 定期実行や監視ができて、放っておいても回るか()。
- エクスポート/連携: Excel、Google Sheets、Airtable、Notionなどへ簡単に出せるか。ワークフロー連携も加点()。
- スケールと信頼性: 1ページでも数千ページでも耐えられるか。レビューも参考にしました。
- ビジネス用途の適合: 開発者向けだけでなく、営業・マーケ・EC・オペレーションで使われやすいか。
AI搭載の新顔もあれば、昔からの定番もあります。共通しているのは、Webを自社のビジネス用データベースに変えるために作られていること。しかも、面倒はできるだけ少なく。
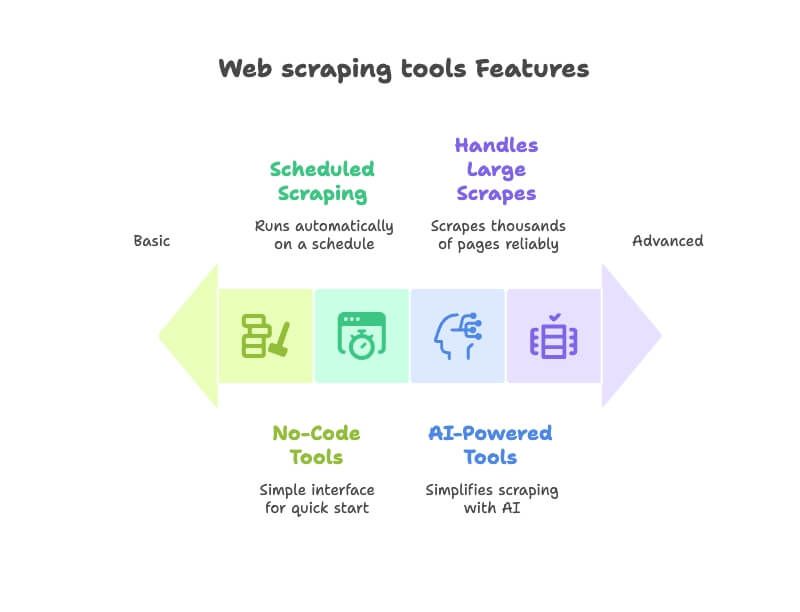
ざっくり比較:Web抽出ツール一覧
まずは、今回紹介する12ツールをパッと見で比較できる表です。
| Tool | AI Automation | Ease of Use | Best Use Case |
|---|---|---|---|
| Thunderbit | あり – AIが項目を提案し、ページ遷移も自動処理 | とても簡単(Chrome拡張、コード不要) | 非エンジニアがリードや価格などを“数分で”抽出したいときに最適。 |
| Octoparse | 限定的(テンプレ中心、AIなし) | 多くの人にとって簡単(ドラッグ&ドロップのビジュアル操作) | ログインやページ送りを含むカスタム抽出を、コードなしで細かく制御したい分析担当向け。 |
| Browse AI | 一部あり – クリック操作で「ロボット」を作成 | 簡単(ノーコード、クラウド) | 価格や掲載情報などを定期監視し、アラートや連携で運用したい場合。 |
| WebScraper.io | なし(手動設定) | 中程度(拡張機能+サイトマップ設定) | 複数階層サイトをビジュアルに抽出。手順設定を厭わないユーザー向け。 |
| ScraperAPI | 該当なし(APIサービス。プロキシ等をAPIで処理) | コーディングが必要(API連携) | 大規模抽出を行う技術チーム向け。プロキシやCAPTCHA対策込みで高スループット。 |
| Data Miner | なし | とても簡単(拡張機能+ワンクリックテンプレ) | テーブル/リスト中心のページから、単発で素早くCSV/Excelへ出したいとき。 |
| Simplescraper | なし(AI補助機能は一部あり) | 簡単(クリック操作でレシピ作成) | ノーコード抽出+連携が強み。Google Sheets/Airtable/APIへ流し込みたい場合に便利。 |
| Instant Data Scraper | あり – テーブルを自動検出 | とても簡単(クリックだけ、設定不要) | HTMLの表やリストを、誰でも無料で即時抽出(とにかく早く取りたいとき)。 |
| ScrapeStorm | あり – AIが要素を判別 | 簡単(ビジュアルUI、クロスプラットフォーム) | コードなしで大規模/複雑な案件を回したい場合(スケジュール実行も可)。 |
| Apify | 一部あり – 既製の「actor」ボットが豊富 | 中程度(Web UI、必要ならコード) | 既製または自作スクリプトで、クラウド上のスケーラブルな抽出・自動化を実現。 |
| ParseHub | なし(スクリプト不要だが手動設定) | 基本用途なら簡単(ビジュアル編集、デスクトップアプリ) | 動的サイト(AJAX等)や複雑サイトを、ノーコードで抽出したいとき。 |
| OutWit Hub | なし | 簡単(デスクトップGUI) | 小規模案件で、オフライン抽出やコンテンツ収集・アーカイブをしたい場合。 |
多くのツールは無料枠またはトライアルがあり、サブスクも段階制です。ここでは価格よりも機能と用途に焦点を当てています。
Thunderbit:誰でも使えるAI搭載Web抽出ツール

最初はThunderbitから。はい、自社プロダクトです。でもちょっとだけ聞いてください。Web抽出の世界は「自分でスクレイパーを組む」から「AIに欲しいものを伝えるだけ」へ、確実にシフトしています。Thunderbitは、私が見てきた中で(そして開発にも関わった中で)単なる“クローラー”じゃなく、AIデータアシスタントとして本当に使える手触りがあった最初のツールです。
なら、XPathやCSSセレクタ、正規表現で頭を抱える必要はありません。「このページからタイトル・著者・日付を取って」みたいに、自然な日本語/英語で要件を書けばAIがやってくれます()。「AI Suggest Fields」を押すと、ページを読み取って列候補を提案し、サブページやページネーションまで自動で追いかけます()。
しかもThunderbitは、ただ“取る”だけで終わりません。抽出しながら整形・変換・分類・翻訳までできます。電話番号の表記ゆれを揃える、説明文を要約する、商品名を翻訳する…みたいなことも、短い指示を足すだけ。終わったらExcel、Google Sheets、Airtable、Notionへそのまま出力できます()。
一番の違いは、セットアップ不要・学習コストほぼゼロなところ。Chrome拡張なので数秒で使い始められます。プラグインも設定も専門用語もいりません。だからこそ、スピード重視の営業・マーケ・オペレーションに刺さりやすいです()。無料枠で一連の流れを試せて、有料プランも多くのチームにとって現実的な価格帯です。
AIでのWeb抽出がどれだけラクになるか体感したいなら、して試してみてください。たぶん、コピペ作業には戻れなくなります。
Octoparse:カスタム手順を組めるビジュアルWeb抽出
Octoparseは、ビジュアルスクレイピングの王道どころ。デスクトップアプリで、クリック中心のUIが特徴です。Webページ上で欲しいデータを選ぶと、裏側でワークフローを組み立ててくれます()。ログイン、ページ送り、フォーム送信の自動化まで、コードなしで対応できます。
強みは、Amazon、Twitter、LinkedInなどに対応した500以上のテンプレート。テンプレを読み込むだけで抽出を始められるケースも多いです()。より複雑なサイトなら手動モードに切り替えて、各ステップを視覚的に設定できます。クリックやスクロール後に読み込まれるコンテンツにも対応し、プロキシやCAPTCHA対策も用意。クラウド実行でスケジュール運用や大規模実行も可能です。
ただ、上級シナリオに踏み込むほど学習コストは上がります。それでも、非エンジニアやデータ分析担当が、**コードなしで“自分仕様の抽出フロー”**を作りたいなら、Octoparseは堅実な選択肢です()。
Browse AI:ロボットで定期収集・監視できるWeb抽出
Browse AIは発想が面白くて、欲しいデータをクリックで指定して**「ロボット」をトレーニング**すると、似たページから同じ項目を抜けるようになります()。クラウド型・ノーコードなので、スクリプトやサーバー管理は不要です。
特に強いのが自動化とモニタリング。ロボットを定期実行して、データ変化(競合の値下げ、新しい求人掲載など)を検知したら通知できます。よくある用途向けの既製ロボットもあり、そこから微調整して使えるのも便利です()。
ZapierやMake経由で多数のアプリと連携でき、Google Sheetsへの直接出力やAPI/webhookも対応()。定期収集・継続監視を“手放し”で回したいなら、かなり相性がいいです。
WebScraper.io:ブラウザ拡張で作るWebページ抽出

WebScraper.io(通称「Web Scraper」)は、ブラウザ拡張で動くタイプ。サイト内の移動手順と抽出対象を「サイトマップ」として組み立てます()。たとえば「次へボタンでページ送り」「各商品リンクを開いて詳細を取得」みたいに、辿るリンクと抽出要素を定義していく感じです。
コードは書かないものの、要素選択とアクション設定は必要なので、多少の慣れは要ります。多階層の遷移、ページネーション、無限スクロールにも対応(ただし手順は自分で指定)。ブラウザ上で動くので、自分でログインした状態のサイトも抽出できます。
Webページ構造に抵抗がない**“市民データアナリスト”**なら、無料で柔軟に使える頼れる選択肢。サイトマップを自分で組む気があるなら、安定して働いてくれます。
ScraperAPI:開発チーム向けのAPIファーストWeb抽出
クリック操作のUIはいらないから、WebデータをアプリやDBへ直接流し込みたい——そんなチームもあります。ScraperAPIはそのためのAPIファーストなWeb抽出サービスです。URLを渡すとHTMLや抽出結果を返し、プロキシ、地域別IPローテーション、ヘッドレスブラウザ、CAPTCHA対応など面倒な部分を肩代わりします()。
ScraperAPIは50カ国以上・4,000万超のプロキシを運用し、月間360億リクエストを処理するとされています()。信頼性とブロック回避が重要な大規模・自動化スクレイピングに向きます。利用には実装が必要ですが、データパイプラインやプロダクト組み込み用途なら有力候補です。
Data Miner:素早く抜き出すためのChrome拡張

Data Minerは、素早くデータを取りたいビジネスユーザーやリサーチ担当向けのChrome拡張です。クリック操作で抽出できて、テーブルやリストなど定番パターン向けの**レシピ(テンプレ)**も豊富()。
拡張を入れて対象ページを開き、アイコンをクリック。レシピを選ぶか、ページ上の要素を指定して自作します。単発の抽出や急ぎのデータ取得に強く、オンラインディレクトリからリード一覧を抜く営業担当や、競合価格を拾うEC担当などに向いています。
ブラウザ内で完結して、必要なときにサッと使える“オンデマンド抽出”の代表格です。
Simplescraper:ノーコードで即戦力のWeb抽出

Simplescraperは名前の通り、シンプルに使える**ノーコードのChrome拡張(+Webアプリ)**です。ページ上でデータを選択して「レシピ」を作り、抽出を実行します()。リンクを辿ってサブページを取ったり、ページネーションに対応したりも可能。さらにワンクリックでAPIエンドポイント化できるのも特徴です。
強みは連携の豊富さ。Google SheetsやAirtableへ直接送れて、Zapierなどにもつなげられます()。クラウド実行やスケジュールにも対応し、「AI Enhance」でGPTを使った整形・分析もできます。
すぐ結果が欲しい+連携も重視するなら、軽量スクレイピングの万能ツールとして便利です。
Instant Data Scraper:表・リストを一瞬で抜くWeb抽出
「今すぐ欲しい。設定はしたくない。」そんなときの鉄板が**Instant Data Scraper(IDS)**です。無料のChrome拡張で、ワンクリックで表形式データを抽出できることで有名()。起動するとページ内のテーブルやリストを自動検出し、ページネーションや無限スクロールも自動で辿ってくれます。
完全無料・登録不要・コード不要・待ち時間なし。営業が急ぎでリード一覧を抜く、学生がWikipediaの表を取る、みたいなライト/緊急用途にぴったりです。検出できれば、数秒で終わります。
ScrapeStorm:AI補助つきのクラウド対応Web抽出
ScrapeStormは、ビジュアルUIとAIアルゴリズムを組み合わせたAI搭載スクレイピングツールです()。URLを入れると、AIが抽出項目(リスト、テーブル、次ページボタン等)を自動判別します。
Windows/Mac/Linuxのクロスプラットフォーム対応で、デスクトップ実行とクラウド実行の両方を提供。スケジュール、並列実行、Excel/CSV/JSON出力、DBアップロードなどにも対応します()。ECや市場調査で人気があり、AIで画像やPDFからの解析にも対応するケースがあります。
大規模・複雑案件で、賢い補助役が欲しいなら検討する価値があります。
Apify:Web抽出のマーケットプレイス+自動化プラットフォーム

Apifyは単体ツールというより、Webスクレイピング&自動化プラットフォームです。スクレイピングやブラウザ自動化を行うスクリプトを**「actor」として実行します。魅力は、用途別に揃った既製actorのマーケットプレイス**()。ECサイトのレビューを全部取りたい、みたいな定番は見つかることが多いです。
開発者ならNode.jsやPythonで自作スクレイパーを書いてクラウドにデプロイできます。スケールしやすく、自動化しやすく、API連携も強い。Webデータを重要資産として扱う組織、つまり継続的な大規模収集やデータパイプライン統合に向きます。
ParseHub:複雑サイトに強いビジュアルWebページ抽出

ParseHubは、複雑で動的なサイトに強いことで知られる**デスクトップアプリ(クラウド実行も可)**です。ブラウザみたいにサイトを操作しながら、データ点をクリックしていくとスクレイパーが組み上がります()。条件分岐、ネスト抽出、AJAXコンテンツなどにも対応します。
他ツールでうまく取れないサイトの“最後の砦”として選ばれることも多く、研究者・アナリスト・小規模事業者に使われています。学習コストはありますが、難しいサイトをコードなしで取りたいなら有力です。
OutWit Hub:コンテンツ収集・アーカイブ向けデスクトップ抽出

OutWit Hubは少し昔ながらですが、デスクトップアプリとして、リンク・画像・メールアドレスなどいろんなコンテンツをまとめて収集して整理するのが得意です()。ブラウザ+スプレッドシートみたいな感覚で、ページを開くとテーブルやリスト、画像などを抽出できます。
フォーラム投稿の一括収集やファイルのまとめダウンロードなど、アーカイブ/リサーチ用途で便利。ローカル実行なので、データを手元で管理したい場合にも向きます。小〜中規模の抽出で、分かりやすいデスクトップUIが欲しい人におすすめです。
どのWeb抽出ツールを選ぶべき?
12ツールもあると、用途は本当に無限。迷ったときの早見表です。
-
完全初心者/単発でサクッと:
表やリスト中心なら、無料で即使えるInstant Data Scraper。似たページを繰り返し取るならテンプレが多いData Minerも便利です。
-
非エンジニアで、継続運用や連携が必要:
ThunderbitはAI主導で最短ルート。ビジネスユーザーが“早く・頻繁に”結果を出したいときに向きます。Browse AIは監視とアラートが得意。SimplescraperはGoogle Sheets連携やAPI化で、社内アプリへ流し込みたい場合に強いです。
-
複雑サイト/カスタム手順をコードなしで:
OctoparseやParseHubのようなビジュアル系が候補。Octoparseはテンプレが豊富で扱いやすく、ParseHubはより難しい動的サイトに強い。自分でサイトマップを組めるならWebScraper.ioも良い選択です。
-
開発者/データエンジニアでスケール重視:
ScraperAPIはプロダクト組み込みや大規模案件向け。Apifyは既製actorと自作スクリプトで、スケーラブルな基盤を作りたいときに向きます。
-
コンテンツ中心/オフライン運用:
OutWit Hubは、体系的な収集・アーカイブに強く、ローカル実行でプライバシーや管理性を重視したい場合に適しています。
実際のところ、多くのチームは用途に合わせて複数ツールを併用しています。簡単なものはInstant Data Scraper、少し込み入った案件はThunderbitやOctoparse、工業化するならScraperAPIやApify、みたいな使い分けです。ありがたいことに、ほとんどのツールが無料枠やトライアルを用意しているので、試しながら自分たちの最適解を探せます。
まとめ:ビジネスチームのWeb抽出は次の段階へ
Web抽出ツールはここ数年で一気に進化しました。2026年にはかなり一般化していて、最大の流れは**「もっと簡単に、もっと自動化されて、日々の業務フローに自然に溶け込む」**ことです()。AI主導のスクレイパーが増えたことで、複雑で動的なサイトでも専門スキルなしで扱えるようになりました。あるデータエンジニアは「AIスクレイピングが出てから、より速く、より大規模に作業できるようになった。しかもAIでデータクリーニングがワークフローに自動で組み込まれる」と述べています。
もう一つの変化は、抽出・監視・自動化の境界がどんどん曖昧になっていること。Browse AIやThunderbitのように、データを取るだけじゃなく更新を追い、フォーム入力やアラート発火などのアクションまで担うツールが増えています。導入の勢いも本物で、ある主要プラットフォームでは月間アクティブユーザーが1年で140%以上増加したと報告されています()。規模を問わず、多くの企業が「公開Webデータへ(倫理的・合法的に)アクセスできること」が競争力の鍵だと気づき始めています。
ビジネスチームにとってのポイントは、意思決定の主導権を取り戻せること。開発待ちで数週間止まる必要も、勘に頼る必要もありません。このリストのツールは、営業・マーケ・オペレーションなど現場の用途に合わせたUIと機能で、Webデータ活用をぐっと身近にしてくれます。これからはさらに、使いやすいUI、賢いAI、BI/分析基盤との深い統合が進むはずです。
注意点として、各サイトの利用規約やrobots.txtを尊重し、個人情報保護などの法令にも準拠してください。倫理的なスクレイピングがあってこそ、こうした取り組みは長く続けられます。
無料拡張から始めるのも、エンタープライズ級の抽出基盤を構築するのも、今は絶好のタイミングです。Web上の情報を“使える示唆”に変えるWeb抽出の波はもう来ています。ツールを選んで試して、目の前にある価値を掘り起こしましょう。データドリブンな未来は、クリック一つ先です。
よくある質問(FAQs)
1. Web extractorとは何で、なぜビジネスに重要なのですか?
Web extractorは、Webサイトから構造化データを自動収集するツールです。オンライン上の散在情報を“意思決定に使える形”へ変換できるため、生産性向上や収益改善につながり、手作業のデータ収集も不要になります。
2. Web抽出ツールは誰でも使えますか?技術スキルは必要ですか?
多くの最新ツールでは技術スキルは不要です。Thunderbit、Browse AI、Instant Data Scraperなどは、直感的なUIとAI自動化、ノーコードのワークフローで非エンジニア向けに設計されています。
3. 営業・マーケ・オペレーションはWeb抽出で何ができますか?
営業はオンラインディレクトリからリードリストを作成でき、マーケは競合価格を監視でき、オペレーションはデータ収集プロセスを自動化できます。時間短縮、ミス削減、鮮度の高い洞察の獲得に役立ちます。
4. Web抽出ツールを選ぶときのポイントは?
使いやすさ、AI機能、自動化/スケジュール、Google SheetsやAirtableなどとの連携、スケーラビリティ、そして自社の用途(リード獲得、価格監視、アーカイブ等)への適合性を確認しましょう。
5. 無料または低コストのWeb抽出ツールはありますか?
あります。Instant Data Scraperは基本用途なら完全無料です。Thunderbit、Simplescraper、Data Minerなども無料枠が充実しており、必要に応じてアップグレードできます。
Web抽出、AIスクレイピング、サイトをチームの武器に変える方法をもっと知りたい方は、でガイドやTips、現場の事例をご覧ください。