

Il web sta crescendo a un ritmo che, a dirla tutta, è persino difficile da immaginare. Ogni giorno escono miliardi di nuove pagine, prodotti, recensioni e dataset — alimentando di tutto, dalla ricerca di mercato all’addestramento dell’AI, fino al tuo prossimo shopping su Amazon. Da persona che ha passato anni nel mondo SaaS e dell’automazione, ho visto con i miei occhi quanto i dati giusti possano fare la differenza tra una decisione aziendale azzeccata e una sbagliata. Ma c’è un problema: raccogliere, aggiornare e dare senso a tutta questa mole di dati web è sempre più complicato, non meno. I web scraper tradizionali arrancano, mentre le aziende cercano un modo più furbo e più rapido per trasformare Internet in insight concreti. Ed è qui che entra in scena il cloud crawler: uno strumento che sta rivoluzionando, quasi senza far rumore, il modo in cui le organizzazioni scoprono e sfruttano i dati web su larga scala.
Quindi, che cos’è davvero un cloud crawler? In cosa si distingue dai web scraper che magari già conosci? E perché team che vanno dalle vendite alle operations stanno puntando su questa tecnologia per restare competitivi in un mondo guidato dai dati? Vediamolo insieme, facciamo chiarezza sui termini più in voga e scopriamo come i cloud crawler — soprattutto la soluzione di Thunderbit — stanno cambiando le regole del gioco per le aziende moderne.
Cos’è un cloud crawler? Il passo successivo nella scoperta dei dati
Estrai dati da qualsiasi sito web usando l’AI Get Started Free
Spieghiamolo in modo semplice: un cloud crawler non è soltanto un web scraper che gira nel cloud. È più simile a un motore di scoperta dei dati: un sistema intelligente basato sul cloud, pensato per trovare, estrarre e analizzare automaticamente enormi quantità di dati da tutto Internet. Mentre un web scraper tradizionale recupera informazioni da poche pagine (spesso una alla volta e di solito da un solo dispositivo), un cloud crawler lavora a un livello completamente diverso. Funziona su potenti data center cloud, esplorando migliaia o persino milioni di pagine in parallelo, e può gestire di tutto, dai testi alle immagini fino ai PDF — indipendentemente da quanto il sito di destinazione sia complesso o grande.
Pensa così: se un web scraper è come un singolo bibliotecario che copia qualche brano da un libro, un cloud crawler è una squadra di supercomputer che scansiona insieme tutti i libri della biblioteca, tagliando, organizzando e analizzando i contenuti mentre procede. Il risultato? Le aziende ottengono dati più ricchi, più aggiornati e davvero utilizzabili — senza i colli di bottiglia dell’hardware locale o della fatica manuale (Sitebulb, Octoparse).
Cloud crawler vs web scraper tradizionale: qual è la vera differenza?
Se hai mai usato un web scraper, conosci già il concetto base: lo punti verso una pagina, definisci ciò che ti serve e lasci che estragga i dati. Ma quando il web diventa più grande e più complesso, il vecchio approccio inizia a mostrare i suoi limiti. Ecco come si confrontano cloud crawler e web scraper tradizionali:
| Caratteristica/Aspetto | Web Scraper Tradizionale | Cloud Crawler |
|---|---|---|
| Distribuzione | Funziona sul tuo dispositivo locale o server | Funziona nel cloud (data center remoti) |
| Scalabilità | Limitata dalla potenza del tuo computer | Massivamente parallela: migliaia di pagine alla volta |
| Velocità | Più lento, soprattutto nei lavori grandi | Elaborazione batch ad alta velocità |
| Manutenzione | Richiede aggiornamenti frequenti, si rompe quando il sito cambia | Basato sul cloud, si aggiorna automaticamente, meno fragile |
| Tipi di dati | Di solito testo, a volte immagini | Testi, immagini, PDF, layout complessi |
| Accesso | Legato al tuo dispositivo/rete | Accessibile ovunque, da qualsiasi dispositivo |
| Pianificazione | Manuale o automazione di base | Pianificazione avanzata, attività ricorrenti |
| Ideale per | Progetti piccoli, siti semplici | Esigenze di dati su larga scala, frequenti o complesse |
I cloud crawler sono pensati per il web moderno, dove i dati sono ovunque e velocità e scalabilità non sono negoziabili (GPTBots, Octoparse).
Come i cloud crawler accelerano la raccolta dati
Qui le cose diventano davvero interessanti. I cloud crawler sfruttano la potenza del cloud computing per elaborare migliaia di pagine web in parallelo. Vuol dire che puoi estrarre l’intero catalogo di un e-commerce, monitorare i prezzi dei competitor su decine di siti o aggregare annunci immobiliari da tutti i principali portali — tutto in una frazione del tempo necessario con uno scraper tradizionale.
Perché è importante? Perché in settori come e-commerce, finanza e real estate, la freschezza dei dati è tutto. Prezzi, disponibilità e trend di mercato possono cambiare minuto per minuto. Aspettare ore o giorni che uno scraper locale finisca, semplicemente, non è un’opzione. I cloud crawler non sono limitati dalla RAM del tuo laptop o dal Wi‑Fi dell’ufficio: si scalano quando serve, così puoi gestire anche i lavori più pesanti senza andare in affanno (Zyte, Octoparse).
I settori che beneficiano di più di questa efficienza includono:
- E-commerce: monitoraggio dei prezzi, aggregazione del catalogo prodotti, analisi delle recensioni
- Real Estate: aggregazione degli annunci, monitoraggio dei trend di mercato, confronto degli immobili
- Finanza: analisi di notizie e sentiment, monitoraggio di azioni/crypto, tracking normativo
- Sales & Marketing: generazione di lead, ricerca sui competitor, individuazione dei trend
E, a dirla tutta, questa è solo la punta dell’iceberg. Se ti servono dati web su larga scala, un cloud crawler è il tuo nuovo miglior alleato.
La soluzione Cloud Crawler di Thunderbit: veloce, flessibile e potente
Per un attimo indosso il cappello di Thunderbit (ok, in realtà non me lo tolgo mai). La modalità cloud scraping di Thunderbit è la nostra risposta alla sfida dei dati moderni: un cloud crawler pensato per utenti business che vogliono risultati, non complicazioni.
Ecco cosa rende il cloud crawler di Thunderbit così speciale:
- Scraping batch ad alta velocità: estrai fino a 50 pagine alla volta, con server cloud in Stati Uniti, Europa e Asia per una copertura globale. Niente più attese mentre il tuo laptop macina una lista infinita.
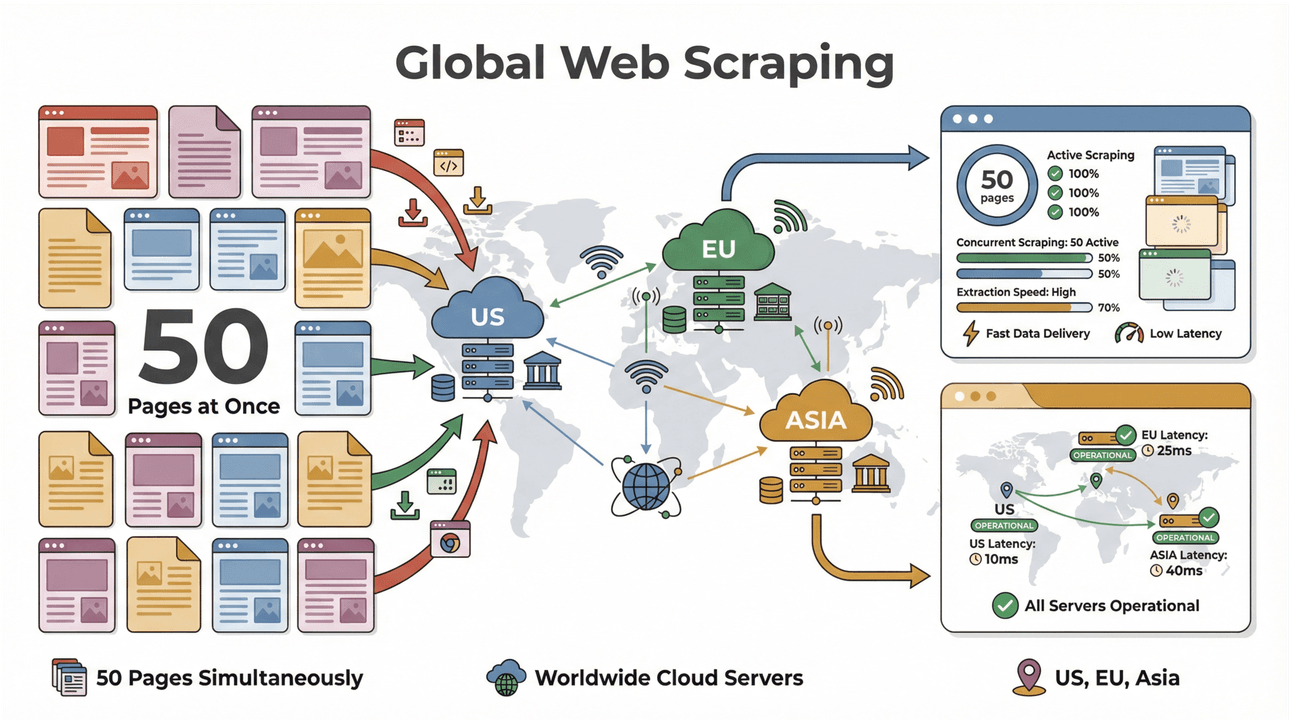
- Supporto per pagine complesse: l’AI di Thunderbit gestisce tutto, dai siti e-commerce dinamici ai PDF più ostici, fino all’estrazione delle immagini. Se è sul web, Thunderbit probabilmente può estrarlo (Thunderbit).
- Crawling delle sottopagine: devi arricchire i dati con dettagli da sottopagine, come specifiche prodotto o biografie degli autori? L’AI di Thunderbit può visitare ogni sottopagina e unire i risultati nel tuo dataset principale (Thunderbit).
- Strutturazione intelligente dei dati: usa “AI Suggest Fields” per far analizzare il sito a Thunderbit e ricevere una proposta delle colonne migliori — senza codice e senza creare template.
- Esporta ovunque: invia i dati direttamente a Excel, Google Sheets, Airtable o Notion. Oppure scaricali in CSV/JSON — scegli il formato più adatto al tuo flusso di lavoro (Thunderbit).
- Nessuna manutenzione richiesta: l’AI di Thunderbit si adatta ai cambiamenti del sito, quindi non devi correggere continuamente scraper che si rompono (Thunderbit).
E sì, puoi provare tutto questo con un piano gratuito — così non devi fidarti solo della mia parola.
Prova gratis Thunderbit Cloud Scraper
Deploy del cloud crawler: cloud o locale — qual è la scelta giusta per te?
Uno dei vantaggi principali dei cloud crawler è la flessibilità di deployment. Con un crawler tradizionale (locale), sei legato a un dispositivo specifico, a una rete specifica e spesso anche a parecchie complicazioni di configurazione. Se il computer va in sospensione o cade la connessione, lo scraping si interrompe. Per scalare devi comprare più hardware o eseguire più script.
I cloud crawler ribaltano completamente lo scenario:
- Nessun hardware speciale richiesto: tutto il lavoro pesante avviene nel cloud. Puoi avviare scraping massivi da un Chromebook, un Mac o persino dal telefono.
- Accesso ovunque: sei in viaggio? Lavori da remoto? Nessun problema: il tuo cloud crawler è sempre disponibile.
- Scalabilità semplice: devi estrarre 10.000 pagine invece di 100? Ti basta aumentare la dimensione del job, senza coinvolgere l’IT.
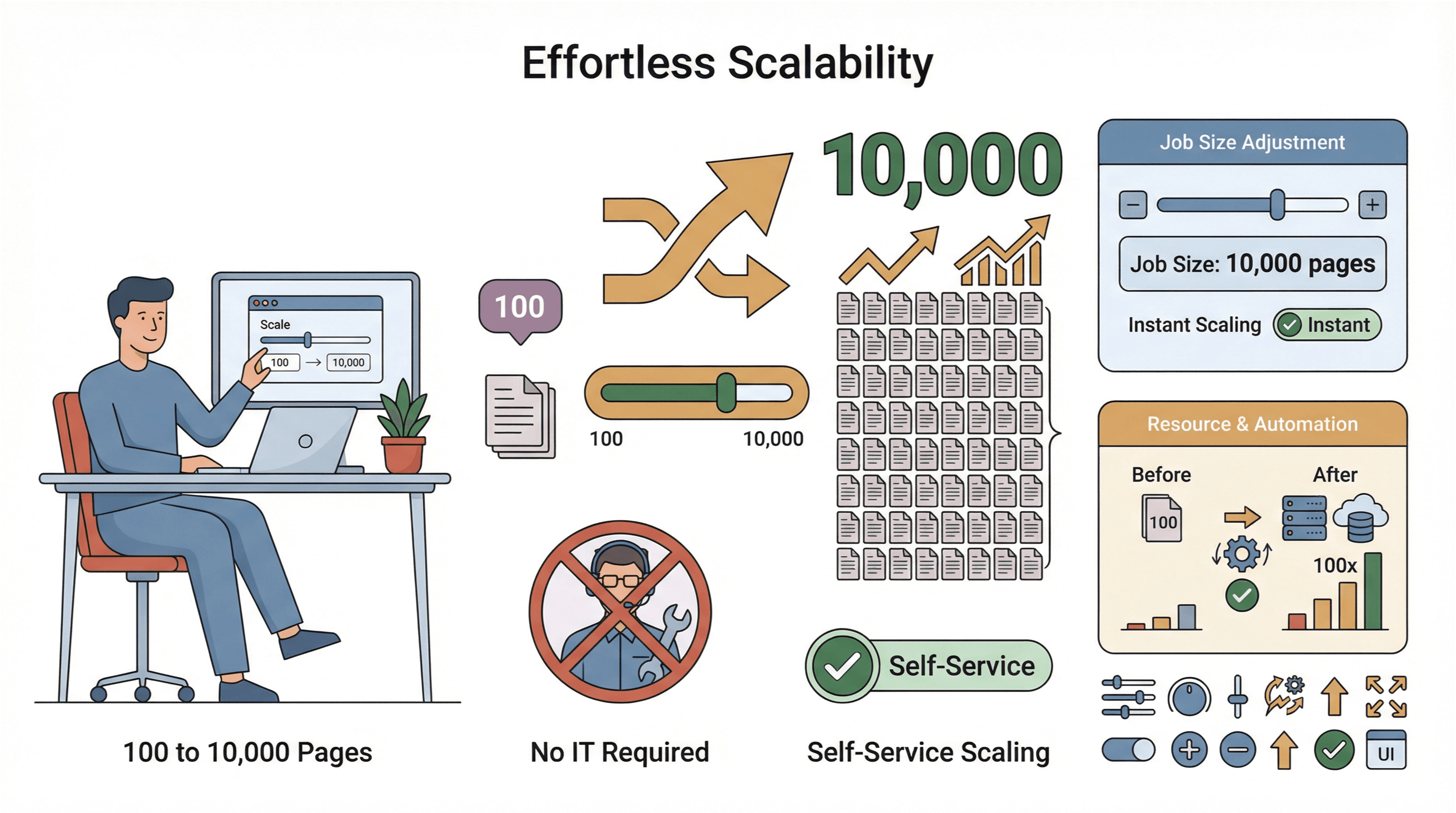
- Raccolta dati globale: con server cloud in più regioni, puoi accedere più facilmente a contenuti con restrizioni geografiche e gestire meglio la compliance (PromptCloud).
Naturalmente, sicurezza e conformità restano sempre priorità fondamentali. I migliori cloud crawler (Thunderbit incluso) usano connessioni crittografate, rispettano i termini dei siti e offrono funzioni che ti aiutano a gestire i dati sensibili in modo responsabile.
Impatto reale: come i cloud crawler stanno trasformando le strategie data-driven
Entriamo nel concreto. Perché le aziende stanno passando ai cloud crawler? Perché stanno vedendo un impatto reale e misurabile:
- Analisi di mercato in tempo reale: i retailer usano i cloud crawler per monitorare prezzi e stock dei competitor in tempo reale, abilitando pricing dinamico e reazioni più rapide ai cambiamenti del mercato (Zyte).
- Previsione dei trend di consumo: i brand aggregano recensioni, post sui social e discussioni nei forum per intercettare i trend emergenti e adattare le campagne al volo.
- Sales & Lead Gen: i team commerciali costruiscono liste aggiornate di lead da directory, siti di eventi e persino PDF — alimentando i CRM con contatti freschi e qualificati (Thunderbit).
- Operations & Compliance: le società finanziarie usano i cloud crawler per monitorare aggiornamenti normativi, news e filing in più giurisdizioni — riducendo il rischio e restando un passo avanti ai cambiamenti.
Il filo conduttore? I cloud crawler permettono ai team di muoversi più velocemente, prendere decisioni più intelligenti e superare i concorrenti che sono ancora fermi sulla corsia lenta.
Funzionalità chiave da cercare in un cloud crawler
Scopri prezzi e funzionalità di Thunderbit Get Started Free
Non tutti i cloud crawler sono uguali. Se stai valutando le opzioni, ecco le funzionalità che contano davvero (e in cui Thunderbit eccelle):
- Scalabilità: riesce a gestire migliaia di pagine contemporaneamente? Rallenta quando i job diventano più grandi?
- Facilità d’uso: l’interfaccia è adatta anche a chi non ha competenze tecniche? Puoi impostare uno scraping in pochi clic?
- Supporto multi-formato: testo, immagini, PDF, sottopagine — riesce a gestirli tutti?
- Integrazione: esporta nei tuoi strumenti preferiti (Excel, Sheets, Notion, Airtable)?
- Pianificazione: puoi impostare job ricorrenti per avere dati sempre aggiornati?
- Assistenza AI: offre suggerimenti intelligenti sui campi, arricchimento dei dati e adattamento automatico ai cambiamenti del sito?
- Sicurezza e compliance: dati e credenziali sono protetti? Ti aiuta a rispettare le normative sulla privacy?
Thunderbit soddisfa tutti questi requisiti, diventando una scelta ideale per i team che vogliono potenza senza complicazioni.
Come iniziare: usare un cloud crawler per la tua azienda
Pronto a partire? Ecco come può iniziare un tipico utente business con un cloud crawler come Thunderbit:
- Installa la Thunderbit Chrome Extension: configurazione rapida, senza bisogno dell’IT.
- Scegli il target: apri il sito, l’elenco o il documento che vuoi estrarre.
- Clicca su “AI Suggest Fields”: lascia che l’AI di Thunderbit analizzi la pagina e consigli le colonne migliori da estrarre.
- Personalizza se serve: aggiungi, rimuovi o rinomina i campi in base alle tue esigenze.
- Seleziona la modalità Cloud Scraping: per lavori grandi o siti complessi, passa alla modalità cloud per la massima velocità.
- Avvia lo scraping: Thunderbit elaborerà fino a 50 pagine alla volta nel cloud.
- Controlla ed esporta: visualizza l’anteprima dei risultati, poi esportali in Excel, Google Sheets, Notion o Airtable.
- Programma job ricorrenti: per esigenze continuative, imposta scraping pianificati — i dati si aggiorneranno automaticamente (Thunderbit Docs).
Consiglio pratico: inizia con un job piccolo per prendere confidenza, poi aumenta gradualmente. E non esitare a usare il supporto o la documentazione di Thunderbit: sono lì apposta per aiutarti.
Inizia il cloud crawling con Thunderbit
Il futuro della raccolta dati: cosa c’è dopo per i cloud crawler?
La rivoluzione dei cloud crawler è appena agli inizi. Ecco cosa sto osservando per i prossimi anni:
- Estrazione AI più intelligente: i cloud crawler stanno migliorando nella comprensione del contesto, delle relazioni e persino del sentiment, rendendo i dati raccolti ancora più preziosi (GPTBots).
- Supporto per nuovi tipi di dati: aspettati una gestione migliore di video, audio e contenuti interattivi, non solo testo e immagini statiche.
- Automazione più profonda: dalla pianificazione automatica agli alert in tempo reale, i cloud crawler diventeranno sempre più autonomi per gli utenti business.
- Compliance più avanzata: con l’evoluzione delle leggi sulla privacy, i cloud crawler integreranno più strumenti per aiutare i team a restare dalla parte giusta delle normative.
- Integrazione con strumenti BI e AI: pipeline dirette dai cloud crawler verso analytics, dashboard e piattaforme di machine learning.
In breve, i cloud crawler sono destinati a diventare la spina dorsale della strategia digitale delle aziende — alimentando tutto, dai lanci di prodotto alle previsioni basate sull’AI (Thunderbit Blog).
Conclusione: perché i cloud crawler sono essenziali per le aziende moderne
In sintesi: il web sta esplodendo di dati e i vecchi metodi per raccoglierli non riescono più a stare al passo. I cloud crawler rappresentano la prossima evoluzione: offrono velocità, scalabilità e intelligenza che i web scraper tradizionali semplicemente non possono eguagliare. Strumenti come Thunderbit rendono possibile per qualsiasi team, tecnico o non tecnico, sfruttare tutto il potenziale dei dati web — con decisioni più intelligenti, reazioni più rapide e un vantaggio competitivo reale.
Se sei pronto a lasciare alle spalle lo scraping manuale e i processi lenti, è il momento giusto per scoprire cosa può fare un cloud crawler per la tua azienda. Prova la modalità cloud scraping di Thunderbit e scopri quanto può essere semplice — e potente — la scoperta dei dati moderna. E se vuoi approfondire, dai un’occhiata al Thunderbit Blog per guide, consigli ed esempi pratici.
FAQ
1. Che cos’è un cloud crawler in parole semplici?
Un cloud crawler è uno strumento basato sul cloud che scopre, estrae e analizza automaticamente grandi quantità di dati dal web. A differenza dei scraper tradizionali che girano sul tuo dispositivo locale, i cloud crawler operano in potenti data center, offrendo enorme scalabilità e velocità.
2. In cosa un cloud crawler è diverso da un normale web scraper?
I cloud crawler funzionano nel cloud, gestiscono migliaia di pagine contemporaneamente, supportano tipi di dati complessi come immagini e PDF e non richiedono manutenzione o hardware locale. I scraper tradizionali sono limitati dalla potenza del tuo dispositivo e sono più adatti a lavori piccoli e semplici.
3. Quali sono i principali vantaggi di usare un cloud crawler?
I cloud crawler offrono raccolta dati ad alta velocità e su larga scala, supporto per siti complessi, accesso facile da ovunque e funzionalità avanzate come pianificazione ed estrazione con AI. Sono ideali per le aziende che hanno bisogno rapidamente di dati freschi e utilizzabili.
4. Come funziona il cloud crawler di Thunderbit per gli utenti business?
Il cloud crawler di Thunderbit ti permette di configurare uno scraping in pochi clic, senza scrivere codice. Puoi estrarre dati da siti web, PDF e immagini, arricchirli con l’AI ed esportarli direttamente in Excel, Google Sheets, Notion o Airtable. È pensato per utenti non tecnici che vogliono risultati, non complessità.
5. Il cloud crawling è sicuro e conforme alle leggi sulla privacy?
Sì, i principali cloud crawler come Thunderbit usano connessioni crittografate e best practice di sicurezza dei dati. Assicurati sempre di estrarre solo dati pubblicamente disponibili e di rispettare i termini di servizio dei siti e le normative sulla privacy.
Pronto a scoprire cosa può fare un cloud crawler? Scarica Thunderbit e inizia oggi stesso a esplorare il mondo della raccolta dati su larga scala basata sul cloud.
Prova oggi il cloud crawler di Thunderbit Get Started Free
Scopri di più




