
La scorsa settimana ho perso 40 minuti a debuggare uno script Python perfettamente valido, che funzionava senza problemi su tre siti di test — per poi scoprire che il quarto era protetto da Cloudflare. Lo scraper continuava a restare in loop sulla pagina "Checking your browser…" e a restituire solo HTML di challenge. Ti è mai capitata una cosa del genere?
Se ti sei scontrato con questo muro, non sei certo il solo. usano oggi Cloudflare, inclusi su internet. Questo fa di Cloudflare l’ostacolo più comune per chiunque voglia raccogliere dati dal web — che si tratti di lead generation, monitoraggio prezzi, ricerche immobiliari o analisi competitiva.
Il problema è che molte guide elencano tutte le tecniche di bypass in modo piatto, senza dirti quale provare per prima nel tuo caso specifico. Questa guida segue un approccio diverso: un albero decisionale ordinato, stime oneste sull’affidabilità e un percorso no-code che la maggior parte degli articoli ignora del tutto.
- Difficoltà: da principiante a intermedio (a seconda del metodo scelto)
- Tempo richiesto: circa 10–30 minuti per il percorso no-code; variabile per i metodi basati su codice
- Cosa ti serve: browser Chrome (per il percorso no-code), eventualmente Python 3.9+ (per i metodi con codice) e un URL di destinazione
Cos’è la protezione Cloudflare (e perché blocca il tuo scraper)?
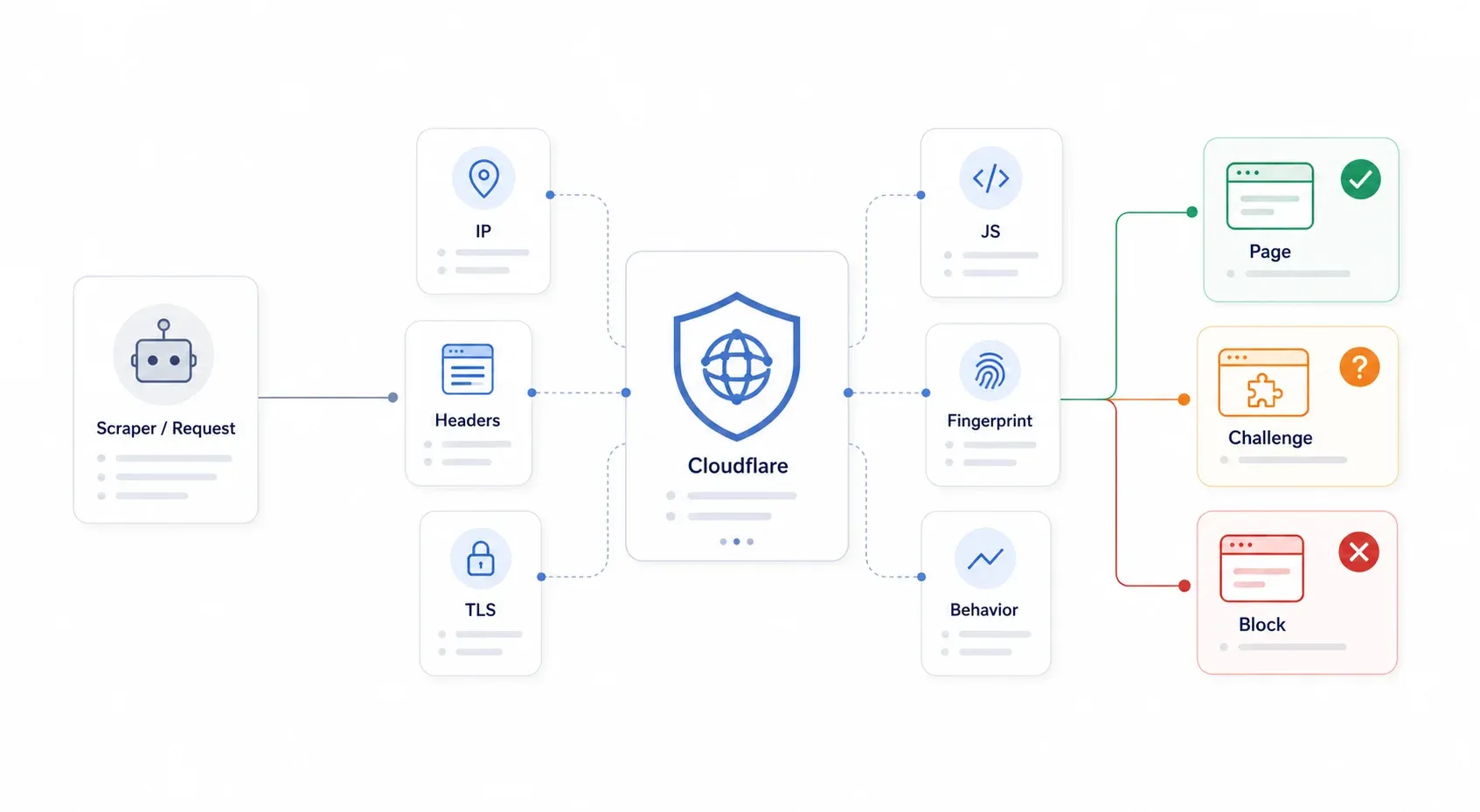
Cloudflare è un reverse proxy che si mette in mezzo tra i visitatori e il server originale del sito. Ogni richiesta passa prima dall’edge di Cloudflare, che decide se mostrare la pagina, sottoporre il visitatore a una verifica oppure bloccarlo del tutto. Il punto chiave da capire è questo: Cloudflare non deve per forza sapere che il tuo scraper è malevolo. Gli basta classificare la richiesta come abbastanza automatizzata o sospetta.
Il sistema di di Cloudflare usa un approccio a più livelli — non un solo lucchetto, ma una vera batteria di controlli di sicurezza. Valuta reputazione IP, header HTTP, fingerprint TLS, esecuzione JavaScript, browser fingerprinting e pattern comportamentali. Quando la tua libreria Python requests manda una GET a una pagina protetta da Cloudflare, fallisce su più livelli insieme: handshake TLS non coerente, nessuna esecuzione JavaScript, niente cookie, nessun browser fingerprint. Ecco perché il semplice spoofing degli header non basta più da anni.
I sintomi più comuni che vedrai sono: 403 Forbidden, 503 con "Checking your browser…", 1020 Access Denied, loop infiniti di challenge, widget Turnstile che non si risolvono e pagine HTML di verifica al posto del JSON atteso.
Rilevamento passivo: cosa controlla Cloudflare prima ancora che la pagina si carichi
Prima ancora che tu veda una pagina, il livello passivo di Cloudflare ha già assegnato un punteggio alla tua richiesta:
- Reputazione IP: gli IP di datacenter, gli intervalli cloud-hosted e i relay proxy noti vengono segnalati. Gli IP residenziali e mobili sono . Le segnalazioni della community nel 2026 descrivono in modo coerente scenari in cui la navigazione residenziale locale passa, mentre ambienti Docker o VPS vengono bloccati.
- Analisi degli header HTTP: Cloudflare confronta User-Agent, Accept-Language, ordine degli header e versione HTTP. Un’incoerenza — per esempio dichiararsi Chrome 136 mentre l’handshake TLS grida "Python" — è un segnale chiarissimo.
- Fingerprinting TLS (JA3/JA4): durante l’handshake TLS, il client rivela un pattern di cipher suite supportate, estensioni e preferenze di protocollo. comprimono tutto questo in un identificatore. Un vero Chrome e uno script Python
requestslasciano “impronte” molto diverse. - Fingerprinting HTTP/2: browser e librerie HTTP differiscono nei frame SETTINGS di HTTP/2, nell’ordine degli pseudo-header e nel comportamento delle priorità. Il lavoro di di Cloudflare va oltre l’identità della singola richiesta e traccia nel tempo i pattern tra richieste successive.
- AI Labyrinth: è la trappola più recente di Cloudflare. Invece di bloccare i crawler sospetti, che sembrano credibili ma consumano risorse del crawler. Il tuo scraper potrebbe persino non accorgersi di essere finito nella trappola.
Rilevamento attivo: le challenge che girano nel tuo browser
Quando i controlli passivi non bastano, Cloudflare passa alle challenge attive:
- Challenge JavaScript: il classico intermezzo "Checking your browser…". I di Cloudflare eseguono script invisibili per identificare le richieste automatiche.
- Turnstile: il sostituto CAPTCHA di Cloudflare. Le includono Managed, Non-Interactive e Invisible. Analizza movimenti del mouse, ambiente del browser, fingerprint TLS e altro — senza per forza mostrare un puzzle visibile.
- Fingerprinting Canvas e WebGL: questi controlli segnalano browser headless che renderizzano in modo diverso rispetto a quelli reali.
- Segnali comportamentali: tempistiche delle richieste, pattern di scroll, sequenze di click. Uno scraper che scarica 50 pagine in 3 secondi senza alcun movimento del mouse non assomiglia affatto a un essere umano.
La conclusione pratica: se Cloudflare è passato a una challenge attiva, i client HTTP puri come requests, httpx o perfino curl_cffi non ce la fanno. Ti serve qualcosa che esegua un vero ambiente browser.
I livelli di protezione Cloudflare: perché lo stesso script funziona su un sito e fallisce su un altro
Questo è il punto che la maggior parte delle guide di bypass ignora completamente. La protezione di Cloudflare non è uniforme. Un sito sul piano gratuito con "Security Level: Medium" è una sfida del tutto diversa da un sito Enterprise con Bot Management e Turnstile attivi. Lo stesso script che passa senza problemi su uno può schiantarsi contro un muro sull’altro.
| Livello Cloudflare | Difese tipiche | Difficoltà di bypass | Cosa funziona di solito |
|---|---|---|---|
| Piano Free (sicurezza bassa) | Bot Fight Mode, regole WAF base, reputazione IP | ⭐ Bassa | Scoperta API interne, curl_cffi con header corretti, sessione browser reale |
| Piano Pro (media) | Super Bot Fight Mode, Managed Challenge, JavaScript detections | ⭐⭐ Media | Sessione browser reale, automazione browser stealth, proxy residenziali |
| Business | WAF più forte, Bot Analytics, challenge più rigorose sui percorsi chiave | ⭐⭐⭐ Medio-Alta | Estrazione tramite sessione browser, persistenza della sessione, proxy residenziali/mobili, API scraping a pagamento |
| Enterprise / Bot Management | Bot score, campi JA3/JA4, regole per endpoint, Turnstile, AI Labyrinth | ⭐⭐⭐⭐ Alta | API interne (se accessibili), strumenti che usano sessioni utente reali, API scraping di livello provider |
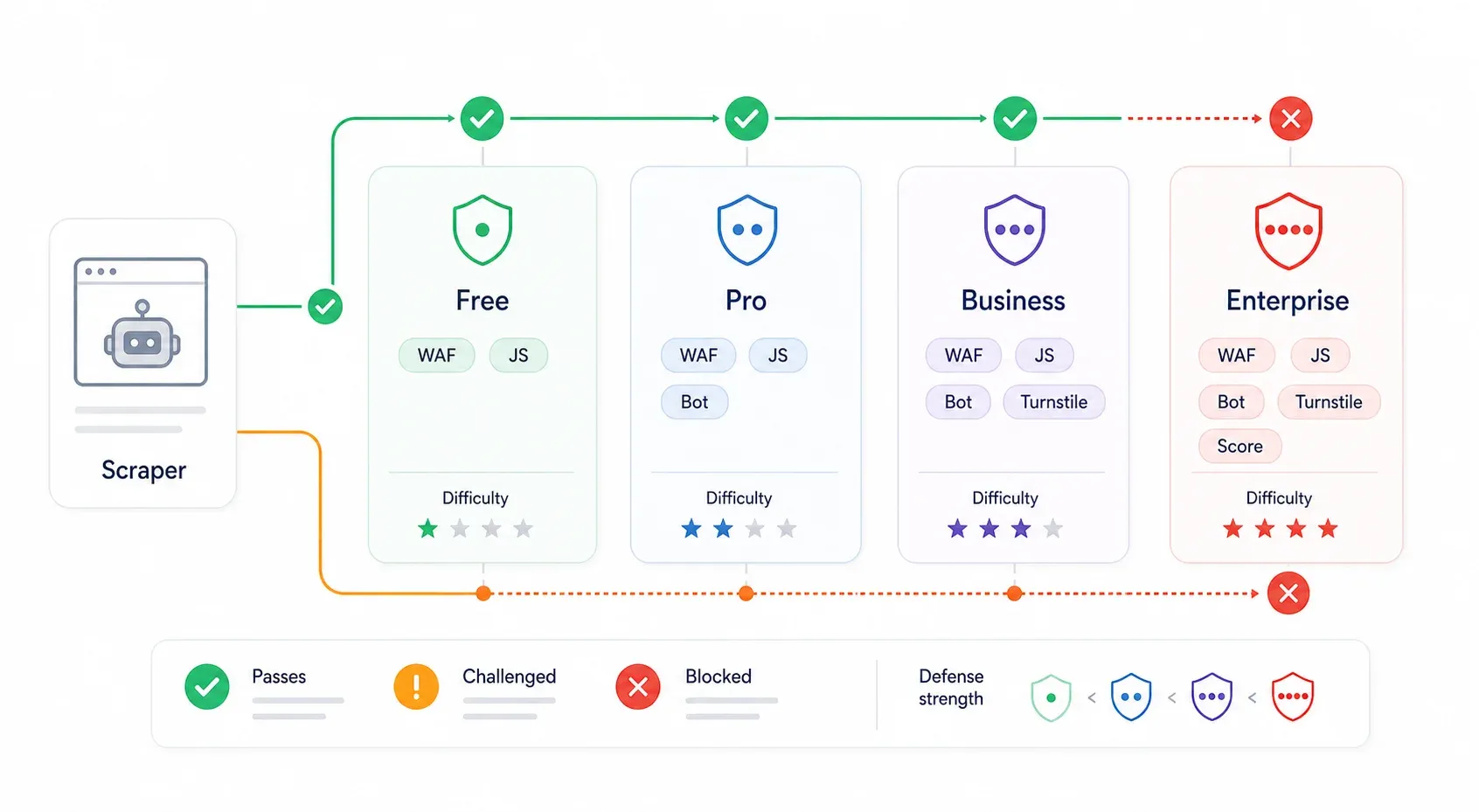
indica Free a $0, Pro a $20/mese, Business a $200/mese e Enterprise con prezzi personalizzati. è il semplice toggle del piano Free; aggiunge più controlli per Pro/Business; Enterprise Bot Management introduce bot score granulari e regole specifiche per endpoint.
Come capire in modo approssimativo il livello che stai affrontando: un 403 con blocco brandizzato Cloudflare e nessuno script di challenge spesso indica un rifiuto via WAF o fingerprint. Un div cf-turnstile o uno script challenges.cloudflare.com/turnstile/v0/api.js significa Turnstile. Un intermezzo “Checking your browser” indica una Managed Challenge. Fallimenti limitati a specifici percorsi dopo il caricamento corretto della homepage spesso indicano regole WAF o Bot Management specifiche per endpoint.
Identifica il livello di protezione prima di scegliere l’approccio. Ti risparmia ore di debug.
La decisione “Prova prima questo” per aggirare Cloudflare
Invece di provare metodi a caso, segui un percorso ordinato. Parti da quello più semplice e affidabile, e alza il livello solo se serve:
| Passo | Prova prima questo | Perché | Se fallisce → |
|---|---|---|---|
| 1 | Cerca un’API interna/non documentata | Evita del tutto Cloudflare; è il più veloce e affidabile | Passo 2 |
| 2 | Usa uno strumento no-code con rendering browser integrato (ad es. Thunderbit) | Nessuna configurazione, gestisce automaticamente le challenge JS | Passo 3 |
| 3 | Impersonazione del fingerprint TLS (curl_cffi) | Veloce, leggero, senza bisogno di browser | Passo 4 |
| 4 | Automazione browser stealth (SeleniumBase UC / Puppeteer stealth) | Gestisce challenge JS + fingerprinting | Passo 5 |
| 5 | FlareSolverr + Docker | Open source, adatto ai server | Passo 6 |
| 6 | API scraping a pagamento (ScrapingBee, ZenRows, Scrapfly, ecc.) | Esternalizza del tutto la corsa agli armamenti | — |
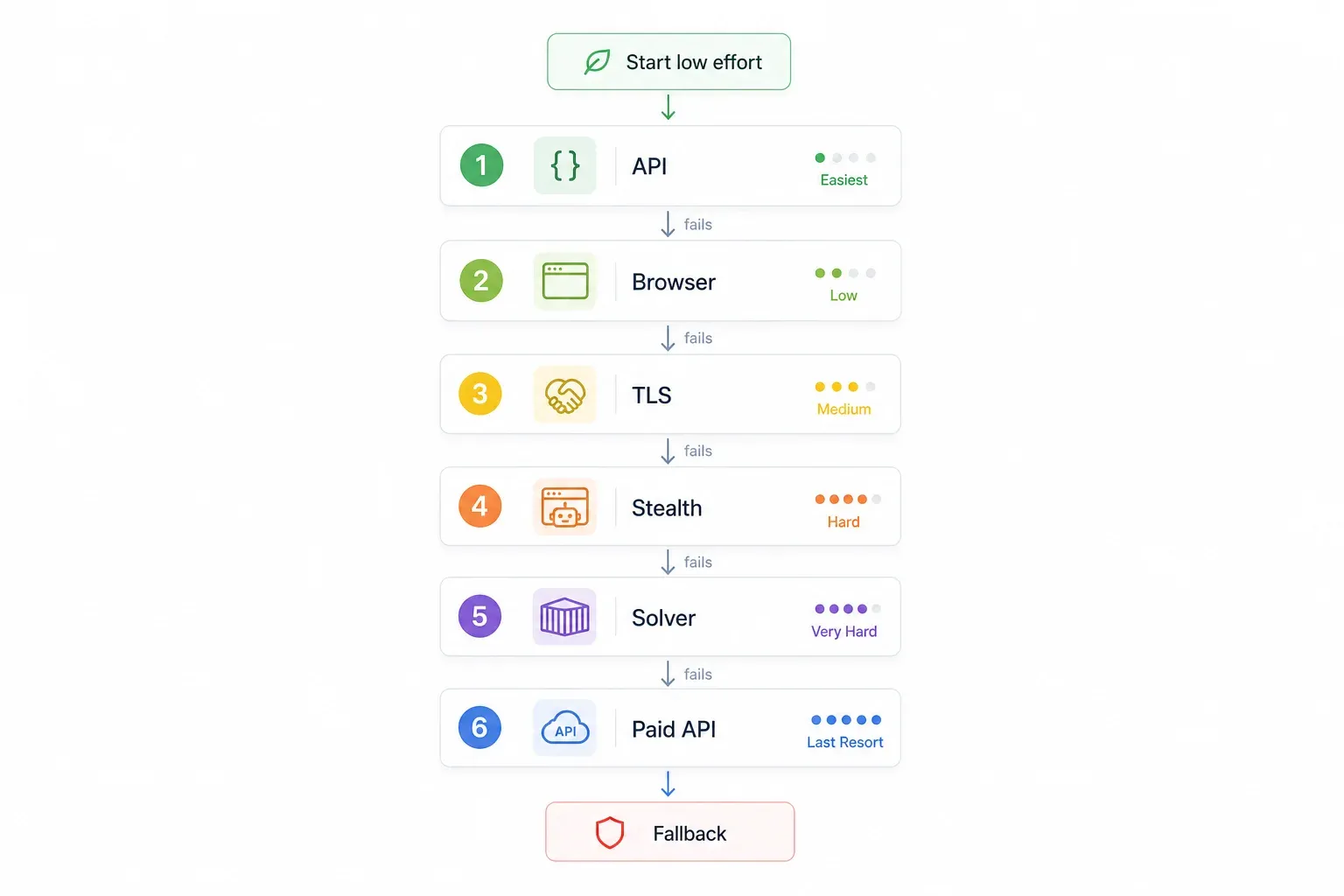
La logica è semplice: prima le soluzioni gratuite e a basso sforzo, poi quelle basate su codice e a pagamento. Vai direttamente al passaggio che corrisponde alla tua situazione.
Un ha riportato che curl_cffi ha superato 16 dei 20 domini testati (80%), FlareSolverr ha coperto circa il 55–70%, e gli aggregatori di proxy a pagamento hanno raggiunto circa il 97% di successo medio — ma lo stesso thread avverte che questi numeri cambiano con gli aggiornamenti di Cloudflare. Considera sempre i tassi di successo come indicativi, non garantiti.
Passo 1: evita lo scontro — trova l’API interna dietro Cloudflare
Quattro thread di forum diversi che ho incrociato consigliano di trovare l’API interna del sito invece di combattere Cloudflare frontalmente. E, sinceramente, è la prima mossa più furba. Se il sito ha un’API interna, aggiri completamente Cloudflare — niente trucchi, niente spoofing del fingerprint, niente plugin stealth.
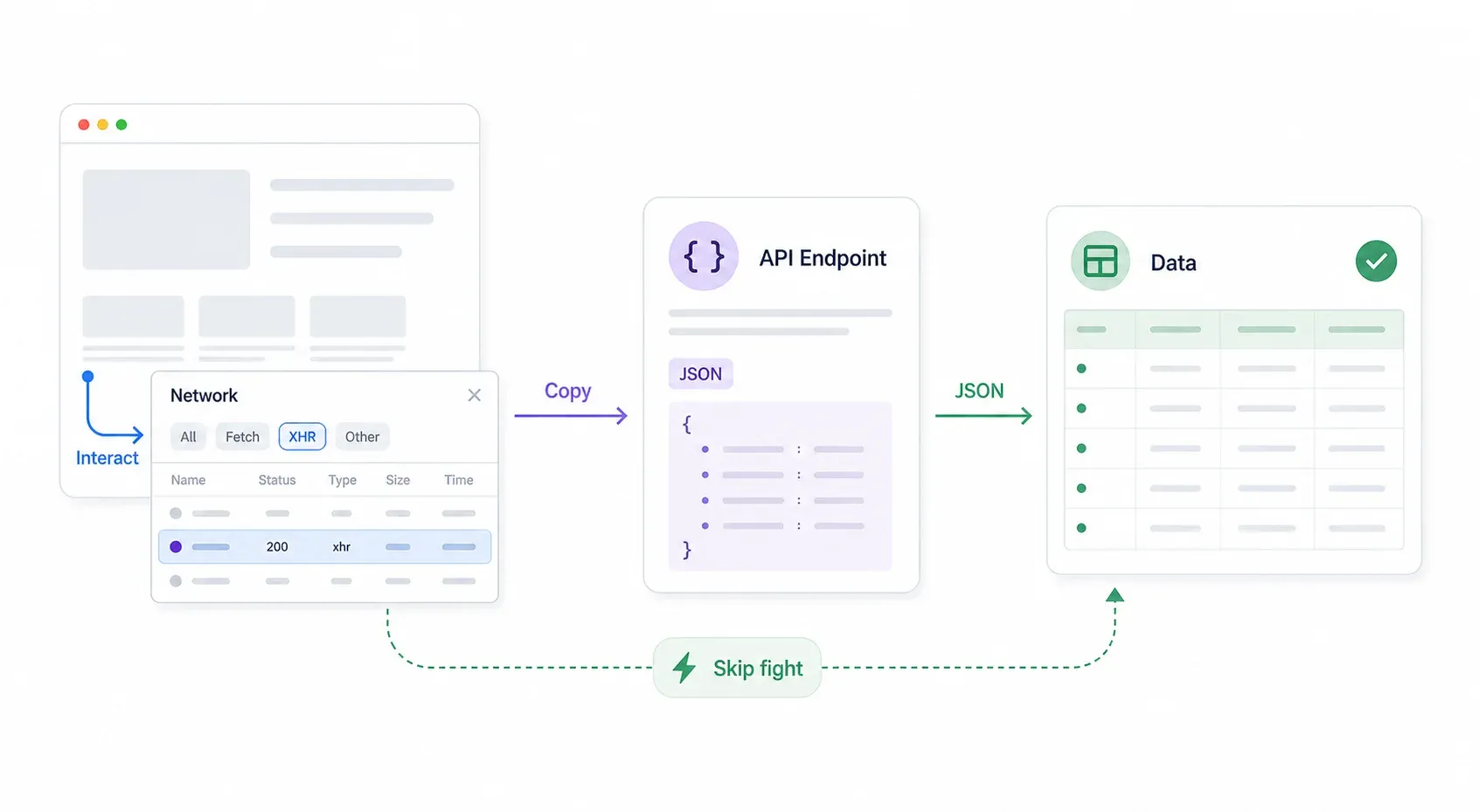
Ecco l’approccio sistematico:
- Apri Chrome DevTools → vai alla scheda Network → filtra per XHR/Fetch.
- Interagisci con la pagina: cerca, filtra, cambia pagina, scorri. Guarda se nella scheda Network compaiono risposte JSON.
- Controlla l’URL della richiesta e gli header. Spesso l’endpoint API non ha la protezione Cloudflare oppure ne ha una più debole rispetto alla pagina frontend.
- Clic destro sulla richiesta → Copy → Copy as cURL. Incollala nel terminale o in Postman e testala.
- Riproduci la richiesta in Python (con
requestsocurl_cffi) usando gli stessi header, cookie e parametri query.
Se l’API restituisce JSON strutturato, potresti non aver bisogno di uno scraper tradizionale. Un ha descritto esattamente questo scenario: un utente bloccato da Cloudflare nonostante curl_cffi ha scoperto che l’unico percorso praticabile era intercettare direttamente la risposta API.
Suggerimento pratico: dopo che il copia-incolla di cURL funziona, inizia a rimuovere gli header non necessari. Header come sec-ch-ua, cookie, token CSRF e referer potrebbero essere indispensabili; i controlli di cache del browser di solito no. Mantieni il fingerprint TLS coerente con il User-Agent quando passi dal cURL del browser al codice.
Limiti: non tutti i siti hanno un’API accessibile. Alcune API richiedono autenticazione, token CSRF, parametri firmati o cookie legati alla sessione. Ma quando funziona, questo è il metodo con successo vicino al 99% e senza manutenzione.
Passo 2: il percorso no-code — aggira Cloudflare con un’estensione browser (Thunderbit)
Tutte le guide concorrenti danno per scontato che il lettore scriva Python o JavaScript. Ma questa keyword attira anche team sales che costruiscono liste di lead, operatori ecommerce che monitorano i prezzi dei competitor e analisti immobiliari che estraggono dati sugli immobili. Queste persone non vogliono avviare container Docker.
Un’estensione Chrome come gestisce in modo naturale molte verifiche di Cloudflare perché gira dentro la tua vera sessione browser. Eredita il fingerprint TLS autentico di Chrome, i tuoi cookie, lo stato di login e i segnali comportamentali — esattamente ciò di cui Cloudflare si fida. Niente plugin stealth, niente xvfb-run, niente comandi da terminale.
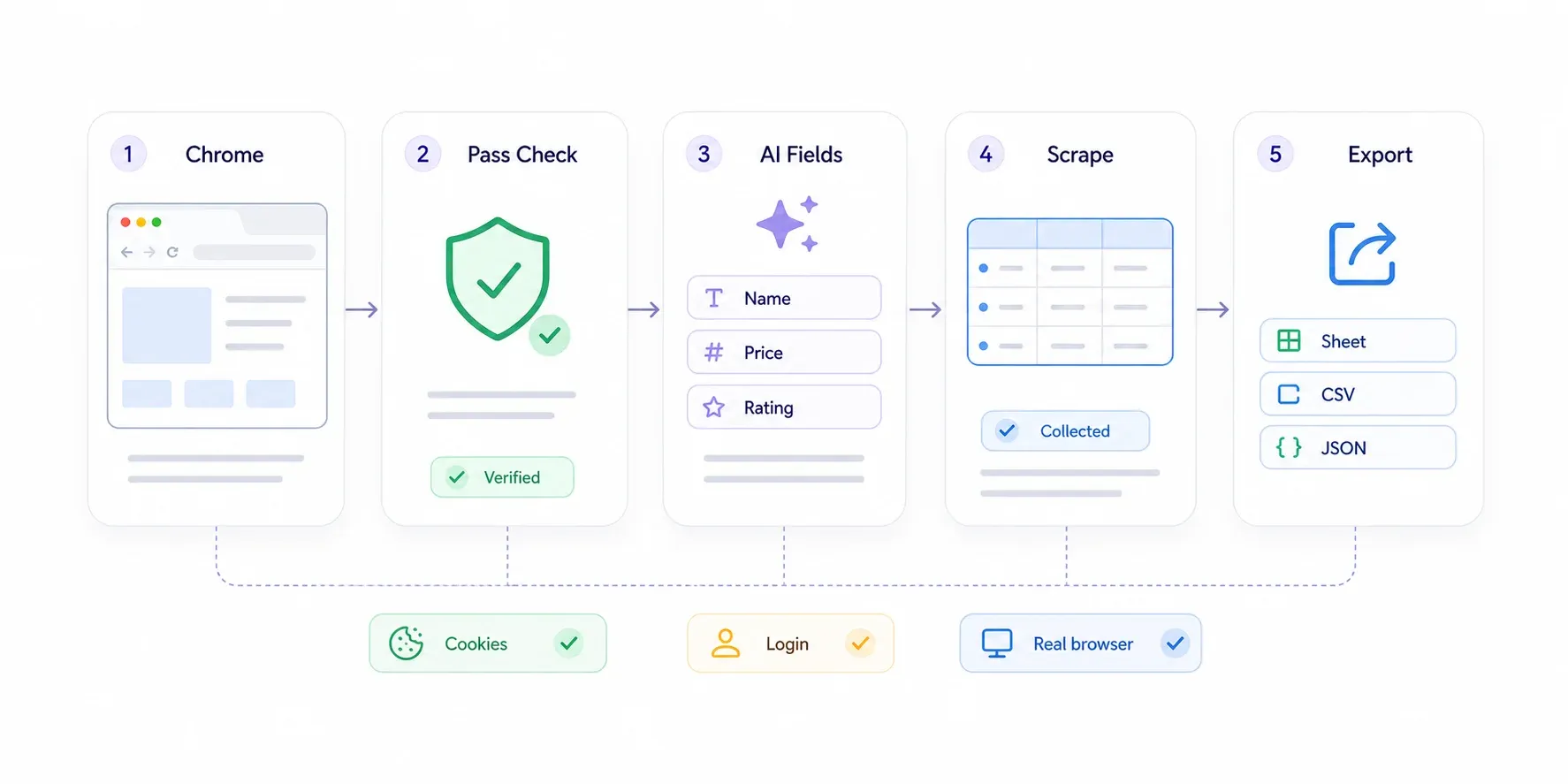
Procedura passo passo
- Installa la dal Chrome Web Store.
- Apri la pagina protetta da Cloudflare in Chrome. Se Cloudflare ti sottopone a una challenge, superala come un normale utente — clicca la checkbox di Turnstile, attendi che la pagina "Checking your browser" sparisca. Sei una persona reale in un browser reale; Cloudflare ti lascia passare.
- Fai clic su "AI Suggest Fields" nella sidebar di Thunderbit. L’IA analizza la pagina e propone colonne dati come "Nome prodotto", "Prezzo", "Valutazione" o qualsiasi altra cosa sia pertinente.
- Rivedi i campi suggeriti. Elimina ciò che non ti serve, aggiungi campi personalizzati descrivendo in inglese semplice ciò che vuoi.
- Fai clic su "Scrape". Thunderbit estrae i dati dalla pagina visibile.
- Esporta in Google Sheets, Excel, Airtable, Notion, CSV o JSON.
Per i siti con paginazione, Thunderbit gestisce sia la paginazione tramite click sia lo scroll infinito. Per le pagine di dettaglio (per esempio, se hai un elenco di link a prodotti e vuoi ottenere le specifiche di ogni singola pagina), usa lo — Thunderbit visita ogni pagina di dettaglio collegata e arricchisce la tua tabella.
Per esperienza, questo workflow richiede circa 5–10 minuti dall’installazione al foglio esportato per un dataset tipico da 50–100 righe.
Quando lo scraping via browser funziona meglio (e quando no)
Voglio essere sincero sui limiti. Lo scraping via browser è vincolato alla velocità della sessione. È ideale per compiti di media scala — da centinaia a poche migliaia di pagine. Se devi fare crawl di milioni di pagine su base programmata, ti serviranno metodi basati su codice o API.
L’opzione Cloud Scraping di Thunderbit può accelerare il processo, arrivando a estrarre fino a 50 pagine alla volta per siti pubblicamente accessibili. E per i flussi da sviluppatore o per volumi maggiori, la di Thunderbit gestisce rendering JavaScript, protezioni anti-bot e rotazione proxy con elaborazione batch fino a .
Ma per l’utente business che estrae lead, dati di prezzo o annunci immobiliari a una scala ragionevole? Questo è spesso l’unico metodo che serve. Niente codice, niente proxy, niente manutenzione.
Passo 3: spoofing del fingerprint TLS con curl_cffi (approccio leggero con codice)
Se ti trovi a tuo agio con Python e il percorso no-code non si adatta al tuo workflow, è l’opzione di codice più leggera. È un binding Python attorno a libcurl che può impersonare i fingerprint TLS di browser reali. A differenza di requests o httpx, il tuo handshake TLS sembra provenire da Chrome o Safari.
Nel 2026, i includono chrome136, safari184 e molti profili storici. La libreria ha avuto una , quindi è mantenuta attivamente.
Quando usarlo: siti con protezione Cloudflare Free o Pro che si basano soprattutto sul fingerprinting passivo — niente challenge JavaScript attiva, niente Turnstile.
Esempio base:
1from curl_cffi import requests
2url = "https://example.com/products"
3resp = requests.get(
4 url,
5 impersonate="chrome136",
6 headers={
7 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 },
10 timeout=30,
11)
12print(resp.status_code)
13print(resp.text[:500])Un dettaglio che spesso crea problemi: mantieni coerente il tuo User-Agent con il target di impersonazione. Se stai impersonando Chrome 136, non inviare una stringa User-Agent di Chrome 120. L’incoerenza è un segnale.
Limiti: curl_cffi non esegue JavaScript. Se il sito mostra una challenge "Checking your browser" o un widget Turnstile, questo metodo fallisce. Inoltre non è utile per siti che richiedono uno stato di sessione basato su cookie derivati da una challenge browser. Consideralo un primo tentativo rapido ed economico per protezioni solo passive.
Alternative della stessa famiglia: tls-client e curl-impersonate offrono capacità simili di impersonazione TLS.
Passo 4: automazione browser stealth (Puppeteer Stealth e SeleniumBase UC)
Lo spoofing TLS non basta quando il sito richiede esecuzione JavaScript, challenge attive o Turnstile. A quel punto ti serve un browser completo. Le due opzioni principali:
- SeleniumBase UC Mode (Python): la come un modo per far sembrare l’automazione più umana e aggirare i servizi anti-bot. Include esempi per gestire Cloudflare Turnstile.
- Puppeteer con
puppeteer-extra-plugin-stealth(Node.js): è ancora molto usato, ma . Le segnalazioni della community parlano di fallimenti dovuti a flag di rilevamento CDP (Chrome DevTools Protocol) e a profili browser non coerenti.
Entrambi gli strumenti avviano un vero browser Chromium, ma correggono segnali di automazione rilevabili: navigator.webdriver, metadata WebGL, lista dei plugin e altro ancora.
Suggerimenti di configurazione che contano davvero:
- Usa la modalità headed (non headless). La documentazione di SeleniumBase avverte che UC Mode è rilevabile in modalità headless. Su server Linux, usa un display virtuale.
- Randomizza la dimensione del viewport e il User-Agent, ma mantienili coerenti tra loro e con la geolocalizzazione del proxy.
- Aggiungi ritardi realistici tra le azioni. Un intervallo di 200 ms tra i caricamenti delle pagine urla “bot”.
- Mantieni cookie e profili browser dopo aver superato la challenge iniziale. Non risolvere di nuovo la challenge a ogni richiesta.
- Abbina proxy residenziali per una reputazione IP migliore.
Il rischio di questo approccio è la manutenzione. Gli stack di automazione browser si rompono quando Chrome si aggiorna, Cloudflare introduce un nuovo segnale, un plugin stealth resta indietro oppure il target aggiunge Turnstile specifico per percorso. Un ha rilevato che molte configurazioni stealth-browser falliscono i test fingerprint a causa di combinazioni “franken-fingerprint” — timezone, lingua e geografia del proxy non coerenti.
Questo metodo è potente ma costoso sul piano operativo. Metti in conto tempo per correzioni continue.
Rotazione proxy: perché l’IP conta quanto il fingerprint
Anche con uno stealth browser perfetto, inviare troppe richieste da un singolo IP attiva i rate limit. Cloudflare si fida molto di più degli IP residenziali e mobili rispetto a quelli di datacenter.
- Proxy residenziali: circa nei volumi iniziali del 2026. Più affidabili, ma più costosi.
- Proxy datacenter: più economici, ma .
- Strategia di rotazione: ruota per sessione, non per singola richiesta. La rotazione per richiesta rompe cookie e
cf_clearancelegati alla sessione. Mantieni IP, cookie e fingerprint coerenti all’interno della stessa sessione.
Non esiste un “numero minimo” magico di proxy. Uno scraping di lead a basso volume può funzionare con poche sessioni residenziali stabili; un monitoraggio prezzi ad alto volume può richiedere centinaia di uscite più una logica di retry.
Passo 5: FlareSolverr — il server open source per aggirare Cloudflare
è un proxy server open source che usa Chromium con undetected-chromedriver in un container Docker per risolvere le challenge Cloudflare e restituire cookie/header riutilizzabili. Ha avuto una , quindi è ancora mantenuto attivamente.
Quando usarlo: pipeline di scraping lato server in cui serve un servizio persistente di risoluzione delle challenge — per esempio un job automatico notturno che ha bisogno di cookie cf_clearance freschi.
Come funziona: il tuo scraper invia un URL all’API di FlareSolverr. FlareSolverr apre la pagina in un browser, prova a risolvere la challenge e restituisce HTML e cookie. Puoi poi riutilizzare quei cookie nel tuo normale client HTTP per le richieste successive.
Panoramica di setup: Docker Compose, avvii il container, invii richieste POST all’endpoint API locale. .
Limiti che voglio chiarire subito:
- Non riesce a risolvere in modo affidabile le challenge Turnstile interattive o Enterprise Bot Management.
- e mostrano comportamenti incoerenti: challenge non rilevate, timeout di Turnstile, crash della pagina.
- Richiede infrastruttura Docker e manutenzione continua.
- È pesante in termini di risorse — ogni risoluzione avvia un contesto browser.
Affidabilità stimata: 60–80% sui target con protezione media. Più bassa per Enterprise, più alta per pagine con challenge semplici. Se FlareSolverr non basta, è il momento di valutare API a pagamento.
Passo 6: API scraping a pagamento che gestiscono Cloudflare per te
A volte i conti sono semplici: mantenere in casa un’infrastruttura stealth costa più in ore di engineering di un abbonamento. Le API scraping a pagamento scaricano l’intera corsa agli armamenti su un provider dedicato — tu invii un URL, loro si occupano di fingerprinting, proxy, risoluzione delle challenge e retry.
Come confrontarle:
| Provider | Supporto Cloudflare | Rendering JS | Proxy residenziali | Output strutturato | Modello di prezzo |
|---|---|---|---|---|---|
| ScrapingBee | Sì | Sì | Sì | Solo HTML | Crediti per richiesta |
| ZenRows | Sì (afferma >99% di successo) | Sì | Sì (premium) | HTML, alcuni parsing | CPM con moltiplicatori |
| Scrapfly | Sì (include CF, Akamai, DataDome) | Sì | Sì | HTML, alcuni parsing | Basato su crediti |
| Browserless | Sì | Sì (headless Chrome) | Sì (integrati) | HTML, screenshot | Basato su unità |
| Thunderbit API | Sì | Sì | Sì | JSON/CSV strutturati con schema IA | Piano gratuito + piani a pagamento |
Quando ha senso: scraping ad alto volume, esigenze di affidabilità di livello enterprise, oppure quando il team non vuole mantenere l’infrastruttura di scraping. Fascia di costo: circa 30–500+ $/mese per usi piccoli o medi, con crescita fino a livelli enterprise.
La Thunderbit API merita una menzione a parte perché restituisce dati strutturati, non solo HTML grezzo. Il suo può elaborare fino a 50 URL per richiesta e restituire JSON/CSV basati su uno schema alimentato dall’IA — utile se ti servono dati puliti, già pronti per l’analisi, invece di HTML da parsare a mano.
Classifica onesta dell’affidabilità: cosa funziona davvero e cosa si rompe
Ho monitorato segnalazioni della community, issue GitHub e dichiarazioni dei vendor durante tutto il 2025–2026. Quello che segue è un confronto sincero. Sono stime indicative, non benchmark di laboratorio:
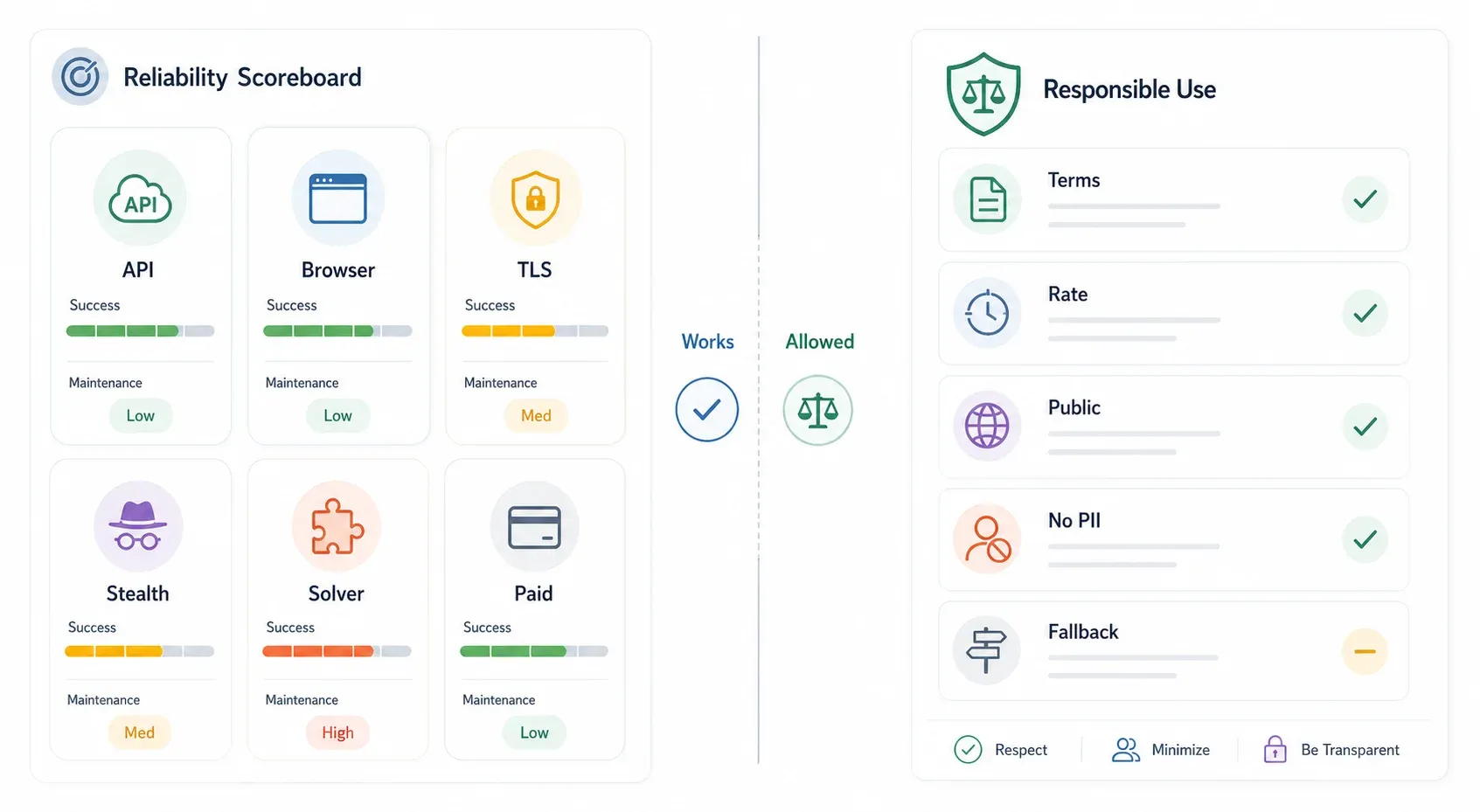
| Metodo | Tasso di successo stimato | Impegno di manutenzione | Si rompe quando… | Fascia di costo |
|---|---|---|---|---|
| API interna (se esiste) | ~90–99% | Basso | L’API cambia, viene aggiunta l’autenticazione, i token diventano firmati | Gratis |
| Estensione browser (Thunderbit) | ~85–95% (sessione reale) | Basso (l’IA si adatta ai cambi di layout) | Il sito richiede un flusso di autenticazione speciale, Turnstile aggressivo per azione | Piano gratuito disponibile |
curl_cffi / spoofing TLS | ~70–85% | Medio (aggiornamenti fingerprint) | Cloudflare aggiorna i controlli JA3, serve una challenge JS attiva | Gratis |
| Puppeteer + plugin stealth | ~70–90% | Alto (gli aggiornamenti del plugin arrivano in ritardo) | Rilevamento CDP, nuovi segnali fingerprint, headless detection | Gratis + costo proxy |
| FlareSolverr | ~60–80% | Alto (Docker, drift delle dipendenze) | Protezione di livello Enterprise, interazione con Turnstile | Gratis + costo infrastruttura |
| API scraping a pagamento | ~85–95% | Basso (gestita dal provider) | Il provider non è aggiornato; budget superato | circa 30–500+ $/mese |
La colonna più importante non è il tasso di successo — è “Si rompe quando”. Ogni metodo ha il suo modo di fallire. La strategia migliore è scegliere il metodo meno impegnativo che funziona sul tuo target e avere sempre un piano di fallback.
Non esiste una soluzione permanente. Cloudflare si aggiorna continuamente. La corsa agli armamenti è reale.
Consigli per restare sotto il radar di Cloudflare, qualunque metodo tu usi
Indipendentemente dal metodo scelto, alcune abitudini ti aiutano a restare fuori dal radar di Cloudflare più a lungo:
- Rispetta i rate limit. Inserisci ritardi realistici tra le richieste — almeno 2–5 secondi per una navigazione simile a quella umana. Martellare il sito a velocità macchina è il modo più rapido per farsi bloccare.
- Mantieni coerente il fingerprint. User-Agent, fingerprint TLS, versione del browser, timezone, locale e geografia dell’IP devono raccontare la stessa storia. Un User-Agent Chrome 136 da un IP tedesco con locale
en-USe handshake TLS Python è una contraddizione. - Riutilizza cookie e sessioni dopo aver superato una challenge. Non risolvere la challenge ad ogni richiesta.
- Non cambiare IP a metà sessione. Cloudflare traccia la continuità della sessione.
- Usa IP residenziali o mobili quando il caso d’uso e il budget lo giustificano.
- Monitora i soft block: HTML di challenge dove ti aspettavi JSON, tabelle vuote, redirect al login o pagine che sembrano sospettosamente honeypot di .
- Evita le ore di punta del traffico quando gli operatori del sito possono irrigidire le regole WAF.
- Prepara percorsi di fallback: prima API → poi sessione browser → poi provider a pagamento.
Per gli utenti Thunderbit in particolare, l’IA si adatta automaticamente ai cambi di layout della pagina, così passi meno tempo a mantenere selettori CSS e più tempo a usare davvero i dati.
Una nota rapida sugli aspetti legali ed etici
Non è il focus di questo articolo, ma è troppo importante per saltarlo.
Lo scraping di dati pubblicamente disponibili ha — il ragionamento CFAA in hiQ v. LinkedIn è sopravvissuto al rinvio della Corte Suprema, anche se le parti hanno raggiunto un accordo nel 2022 e il quadro completo è complesso. Più recentemente, nel 2025 per presunto scraping di commenti degli utenti, e più avanti nello stesso anno.
Nell’UE, il GDPR si applica ogni volta che sono coinvolti dati personali, e l’ introduce obblighi specifici sullo .
Regole pratiche di buon senso:
- Controlla sempre i Termini di Servizio del sito.
- La protezione Cloudflare è un segnale che il proprietario del sito vuole controllare l’accesso automatizzato — rispetta questa intenzione.
- Evita di raccogliere dati personali senza una base legittima.
- Per workflow commerciali o ad alto volume, preferisci API ufficiali, dati con licenza o autorizzazione scritta quando disponibili.
- In caso di dubbio, consulta un legale per il tuo caso d’uso e la tua giurisdizione.
Thunderbit è pensato per casi d’uso business legittimi — lead generation, monitoraggio prezzi, ricerche di mercato — usando dati accessibili pubblicamente.
Conclusione: cosa provare prima e cosa provare dopo
Il vero risparmio di tempo in tutto questo articolo non è uno strumento o uno snippet di codice — è identificare il livello di protezione prima di iniziare. Solo questo ti evita ore di debug su un metodo che non avrebbe mai funzionato.
Da qui parti:
- Cerca un’API interna (è gratuita, veloce e spesso trascurata).
- Se sei un utente business che non scrive codice, prova la — la tua vera sessione browser è il miglior alleato contro Cloudflare.
- Se sei uno sviluppatore e il target usa solo fingerprinting passivo, prova
curl_cffi. - Passa a browser stealth, FlareSolverr o API a pagamento solo quando i metodi più semplici non funzionano.
Nessun metodo è permanente. Combina lo strumento giusto per la tua scala con un piano di fallback, e passerai molto meno tempo a fissare pagine 403.
Se vuoi approfondire, sul blog di Thunderbit abbiamo scritto di , e . E se vuoi vedere l’estensione in azione, dai un’occhiata al per i video tutorial.
FAQ
1. Si può aggirare completamente la protezione Cloudflare?
Nessun singolo metodo garantisce il 100% di successo, soprattutto contro Bot Management di livello Enterprise con Turnstile, fingerprinting JA4 e AI Labyrinth. Gli approcci più affidabili combinano fingerprint browser reali con una buona reputazione IP. Trovare un’API interna è l’approssimazione più vicina a un bypass “completo”, perché evita Cloudflare del tutto — ma non tutti i siti ne hanno una.
2. È legale aggirare Cloudflare nello scraping?
Dipende dalla tua giurisdizione, dai Termini di Servizio del sito e dai dati che stai raccogliendo. Lo scraping di dati pubblicamente disponibili ha una giurisprudenza favorevole in alcuni contesti negli Stati Uniti (hiQ v. LinkedIn), ma aggirare controlli tecnici di accesso, violare i ToS o raccogliere dati personali senza una base legittima può creare rischi legali. Per workflow commerciali, preferisci API ufficiali o dati con licenza quando disponibili, e consulta un legale se hai dubbi.
3. Qual è il modo più semplice per aggirare Cloudflare senza programmare?
Le estensioni browser come , che funzionano dentro la tua vera sessione Chrome, gestiscono automaticamente le challenge Cloudflare — interagisci con il sito come un normale utente, poi lasci che l’estensione estragga ed esporti i dati. Niente Python, niente Docker, niente configurazione proxy.
4. Perché il mio scraper funziona su alcuni siti Cloudflare ma non su altri?
Il livello di protezione di Cloudflare varia molto in base al piano (Free, Pro, Business, Enterprise) e alla configurazione. Un metodo che funziona contro semplici challenge JavaScript su un sito Free può fallire contro Turnstile o Bot Management completo su un sito Enterprise. Identifica sempre prima il livello di protezione — verifica se stai vedendo un semplice controllo JS, una Managed Challenge o un widget Turnstile — prima di scegliere l’approccio di bypass.
5. Quanto spesso si rompono i metodi di bypass di Cloudflare?
I metodi basati su codice, come plugin stealth e spoofing TLS, possono degradare nel giro di poche settimane o mesi sui target più difficili, man mano che Cloudflare aggiorna il rilevamento. Le API a pagamento e gli strumenti che usano vere sessioni browser tendono a essere più resilienti perché si adattano a livello di infrastruttura o sessione utente. Le API interne si rompono di rado, a meno che il sito non ridisegni il backend o cambi il modello di autenticazione. La strategia più sicura nel lungo periodo è avere più metodi di fallback invece di dipendere da un solo approccio.
Scopri di più