Firecrawl è diventata una delle API di web scraping più chiacchierate nel mondo degli sviluppatori AI — , il sostegno di Y Combinator e una lista di clienti che include Shopify, Zapier e Apple. Ma dopo aver esaminato documenti sui prezzi, lamentele degli utenti, benchmark indipendenti e modelli di costo reali, la narrativa da prima pagina e l’esperienza concreta sono parecchio lontane.
Questa recensione di Firecrawl non è il solito elenco di funzionalità. Se ti sei registrato, hai fatto qualche test di scraping e ora ti stai chiedendo “quanto mi costerà davvero su larga scala?” — oppure vuoi capire se Firecrawl sia davvero lo strumento giusto per il tuo team — sei nel posto giusto. Ti guiderò nei costi reali (inclusa la trappola della doppia fatturazione che la maggior parte delle recensioni salta), nei punti in cui Firecrawl eccelle davvero, in quelli in cui delude (soprattutto sui siti protetti dai bot) e nei casi in cui uno strumento completamente diverso — comprese opzioni no-code come — è la scelta più sensata. Il mio obiettivo: evitarti una brutta sorpresa sull’estratto conto.
Che cos’è Firecrawl e per chi è pensato?
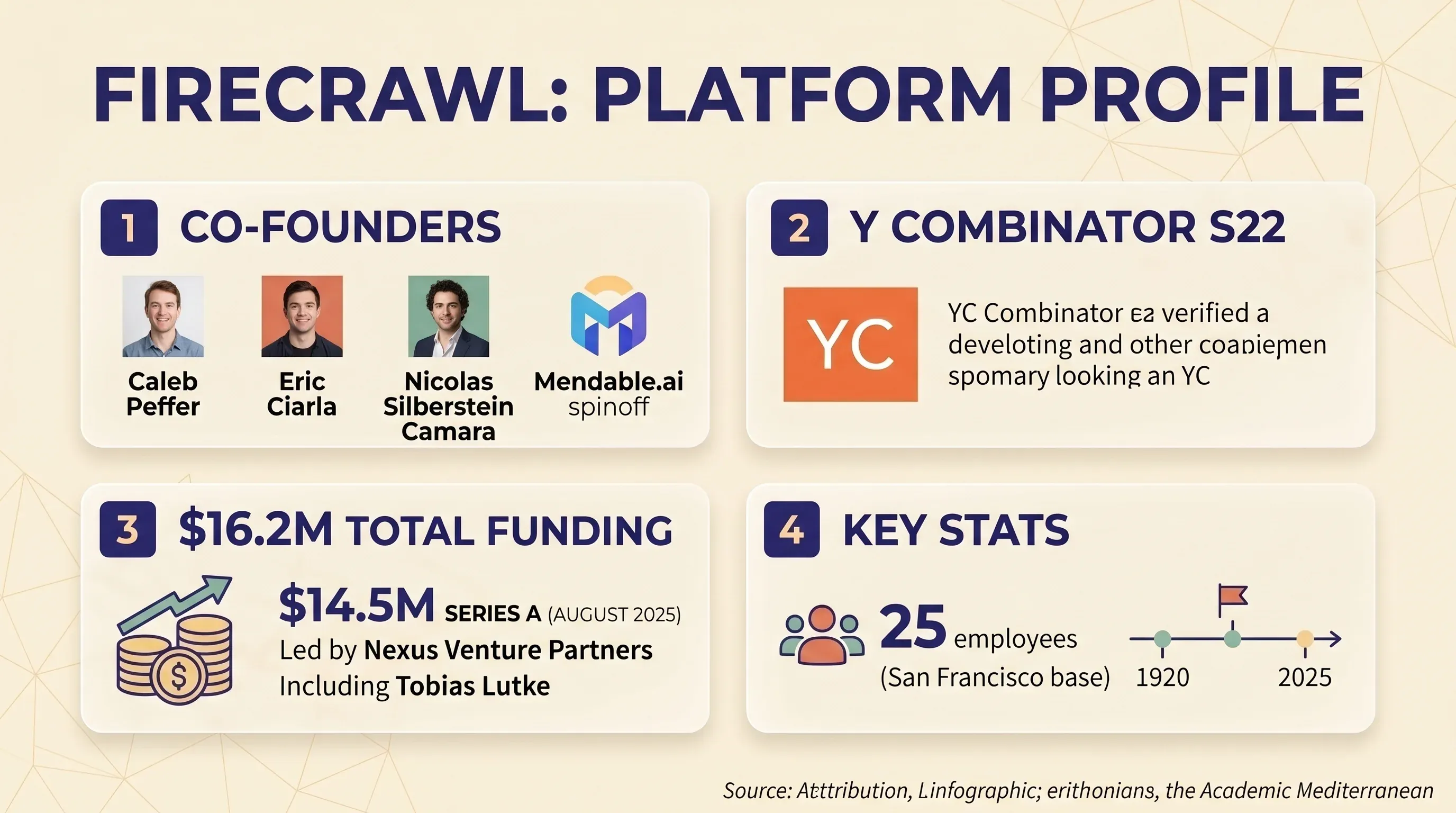
Firecrawl è una piattaforma di web scraping e crawling API-first che trasforma i siti web in markdown pulito o in JSON strutturato. È pensata soprattutto per sviluppatori che costruiscono applicazioni AI e LLM — pensa a pipeline RAG, basi di conoscenza per chatbot e flussi di lavoro per agenti AI. L’azienda è stata fondata da Caleb Peffer, Eric Ciarla e Nicolas Silberstein Camara come spin-off di Mendable.ai. Ha partecipato a e ad agosto 2025 ha raccolto una guidata da Nexus Venture Partners, con la partecipazione del CEO di Shopify Tobias Lutke. Finanziamenti totali: 16,2 milioni di dollari. Il team è composto da 25 persone e ha sede a San Francisco.
Firecrawl offre quattro modalità principali, più due aggiunte più recenti:
| Modalità | Cosa fa |
|---|---|
| Scrape | Converte un singolo URL in markdown, JSON o screenshot |
| Crawl | Esegue il crawling di un URL e di tutte le sue sottopagine |
| Map | Scopre tutti gli URL di un sito in pochi secondi (fino a 100K URL) |
| Search | Cerca sul web recuperando il contenuto completo delle pagine |
| Extract | Estrazione strutturata con AI tramite prompt o schemi |
| Agent (Research Preview) | Ricerca web autonoma senza specificare URL |
Voglio essere chiaro: Firecrawl è uno strumento per sviluppatori. Richiede chiamate API, conoscenze di programmazione e una certa configurazione tecnica. Se sei un utente business che vuole raccogliere dati da un sito senza scrivere codice, Firecrawl non è pensato per te (torneremo alle alternative più avanti). Ma per i team di sviluppo che costruiscono app AI, la proposta è molto interessante — dati web puliti, pronti per gli LLM, con pochissimi grattacapi infrastrutturali.
Recensione Firecrawl: panoramica dei piani tariffari
In apparenza, i prezzi di Firecrawl sembrano semplici. Ecco cosa compare sulla :
| Piano | Prezzo mensile | Crediti/mese | Concorrenza | Prezzo annuale |
|---|---|---|---|---|
| Free | $0 | 500 (una tantum, non mensili) | 2 | — |
| Hobby | $19/mese | 3.000 | 10 | $16/mese fatturati annualmente |
| Standard | $99/mese | 100.000 | 50 | $83/mese fatturati annualmente |
| Growth | $399/mese | 500.000 | 100 | $333/mese fatturati annualmente |
| Scale | $749/mese | 1.000.000 | 1.000 | $599/mese fatturati annualmente |
Saltano subito all’occhio due cose. I 500 crediti del piano gratuito sono una tantum, non mensili — un dettaglio che molti utenti scoprono solo dopo averli esauriti in una singola sessione di test. E questi livelli tariffari sembrano semplici, ma i costi effettivi dipendono molto dalle funzionalità che usi. Il prezzo indicato è davvero solo il punto di partenza. La fattura reale? Di quello parla la sezione successiva.
Il costo reale di Firecrawl: un calcolatore di crediti per il tuo caso d’uso
Il prezzo è il principale punto dolente per gli utenti reali di Firecrawl — “è dannatamente costoso”, “dovrei stare sul piano da 99 dollari al mese per il mio volume” e “esageratamente costoso” sono citazioni reali da discussioni su Hacker News e Reddit. Il motivo? Esiste un sistema di doppia fatturazione che la maggior parte delle recensioni di Firecrawl ignora completamente.
Ecco la trappola: i piani a crediti di Firecrawl coprono Scrape, Crawl, Map e Search. Ma Extract — l’estrazione strutturata con AI, uno dei principali punti di forza di Firecrawl — funziona con un abbonamento a token completamente separato.
| Piano Extract | Prezzo mensile | Token/anno | Token/mese (circa) |
|---|---|---|---|
| Starter | $89/mese | 18M | ~1,5M |
| Standard | $189/mese | 48M | ~4M |
| Growth | $389/mese | 108M | ~9M |
| Pro | $719/mese | 192M | ~16M |
Quindi una startup con il piano crediti Standard ($99/mese) che ha bisogno anche dell’estrazione paga almeno $99 + $89 = $188/mese — prima ancora di considerare qualsiasi moltiplicatore di crediti. Questa è la trappola della doppia fatturazione che coglie molti di sorpresa.
Moltiplicatori di crediti nascosti che la maggior parte degli utenti non nota
Il titolo “1 credito per pagina” è fuorviante. Ecco quanto costano davvero le funzionalità:
| Funzionalità | Costo in crediti | Moltiplicatore effettivo |
|---|---|---|
| Scrape/Crawl base | 1 credito/pagina | 1x |
| Search | 2 crediti/10 risultati | 2x per set di risultati |
| Estrazione JSON (tramite Scrape) | +4 crediti/pagina | 5x totale |
| Enhanced Mode | +4 crediti/pagina | 5x totale |
| JSON + Enhanced Mode | +8 crediti/pagina | 9x totale |
| Interazioni browser | 2 crediti/minuto | Variabile |
| Modalità Agent (spark-1-mini) | Dinamico, ~100–500/query | 100–500x |
| Modalità Agent (spark-1-pro) | Dinamico, ~200–1.500+/query | 200–1.500x |
E ci sono altri dettagli che contano: i crediti non si accumulano da un mese all’altro. Anche le richieste fallite consumano crediti (gli utenti segnalano un 20–30% di spreco su siti instabili). La modalità Agent non ha alcun estimatore di costo prima dell’esecuzione — imposti un parametro maxCredits, ma in pratica vai un po’ alla cieca. I 500 crediti vitalizi del piano gratuito corrispondono a circa 56 pagine se attivi l’estrazione. Non è una prova gratuita: è solo un assaggio.
Tabella di esempio dei costi mensili per profilo utente
| Profilo utente | Pagine mensili | Funzionalità usate | Consumo crediti stimato | Costo mensile stimato |
|---|---|---|---|---|
| Hobbista / Progetto personale | 500 | Scrape + crawl base | ~500 crediti | $19/mese (piano Hobby) |
| Hobbista + estrazione JSON | 500 | Scrape + Extract | ~2.500 crediti + $89 Extract | $108/mese |
| Startup / App AI | 5.000 | Scrape + Extract + Search | ~30.000 crediti + $89 Extract | $188/mese (Standard + Extract) |
| Enterprise / Data pipeline | 50.000 | Stack completo + Agent | ~250.000–450.000 crediti + $389 Extract | $788–$1.138/mese |
Uno sviluppatore su Hacker News che pagava 190 dollari al mese ha definito l’esperienza “costosa e rifinita a metà” e ha sostituito Firecrawl con 2.700 righe di codice Elixir personalizzato. È un segnale piuttosto forte.
Firecrawl self-hosted: cosa è davvero gratis e cosa è solo cloud
“Posso semplicemente self-hostare Firecrawl gratis?” è una delle domande più frequenti che vedo. La risposta è: in parte sì, ma probabilmente non nel modo che speri.
Firecrawl ha un core open source (licenza AGPL-3.0), ma diverse funzionalità importanti sono disponibili solo nel cloud. Ecco la ripartizione definitiva:
| Funzionalità | Self-hosted (gratis) | Cloud (a pagamento) |
|---|---|---|
| Scrape/Crawl base in markdown | ✅ | ✅ |
| Map (scoperta URL) | ✅ | ✅ |
| Extract basato su LLM | ⚠️ (porta le tue chiavi LLM) | ✅ (gestito) |
| Modalità Agent | ❌ | ✅ |
| Browser Sandbox | ❌ | ✅ |
| Actions/Interact | ❌ | ✅ |
| Anti-bot / rotazione proxy (Fire-engine) | ❌ (usa il tuo IP statico) | ✅ |
| Elaborazione batch | ❌ | ✅ |
| Dashboard / analisi | ❌ | ✅ |
| Infrastruttura gestita | ❌ (richiede Docker + PostgreSQL + Redis) | ✅ |
Fire-engine, il sistema anti-bot proprietario di Firecrawl, è . Gli utenti self-hosted non hanno alcuna capacità anti-bot e devono fornire i propri proxy.
Per chi ha ancora senso il self-hosting
Il self-hosting funziona se sei uno sviluppatore che vuole una semplice pipeline da crawl a markdown e ti senti a tuo agio a gestire Docker Compose con 5+ servizi. Requisiti minimi: 4 GB di RAM, 2 core CPU, più chiavi API LLM per l’estrazione ($0,01–$0,10/pagina) ed eventuali servizi proxy, se servono. Tutto considerato, i costi del self-hosting si aggirano tra $90 e $340 al mese — spesso quindi comparabili ai piani cloud a volumi moderati.
Perché gli utenti sono frustrati dalla versione self-hosted
I feedback reali degli utenti dipingono un quadro piuttosto duro. Molte discussioni su Reddit e GitHub descrivono la versione self-hosted che peggiora nel tempo, mentre le funzionalità migrano verso il cloud. Un utente ha riassunto la situazione in modo brutale: l’azienda “cerca di spingere tutti a pagare ora e rende inutile la versione self-hosted”. La community ha persino creato un fork firecrawl-simple per risolvere alcuni problemi. Se conti sul self-hosting come soluzione gratuita di lungo periodo, regola le aspettative: è un buon punto di partenza per sperimentare, ma non sostituisce il prodotto cloud a pagamento su larga scala.
Prestazioni anti-bot di Firecrawl: dove funziona e dove no
Questa è la sezione che conta di più se ti stai chiedendo: “Firecrawl funzionerà davvero sui siti che devo scrappare?”
La risposta breve: dipende interamente da quanto bene quei siti sono protetti.
I numeri dei benchmark
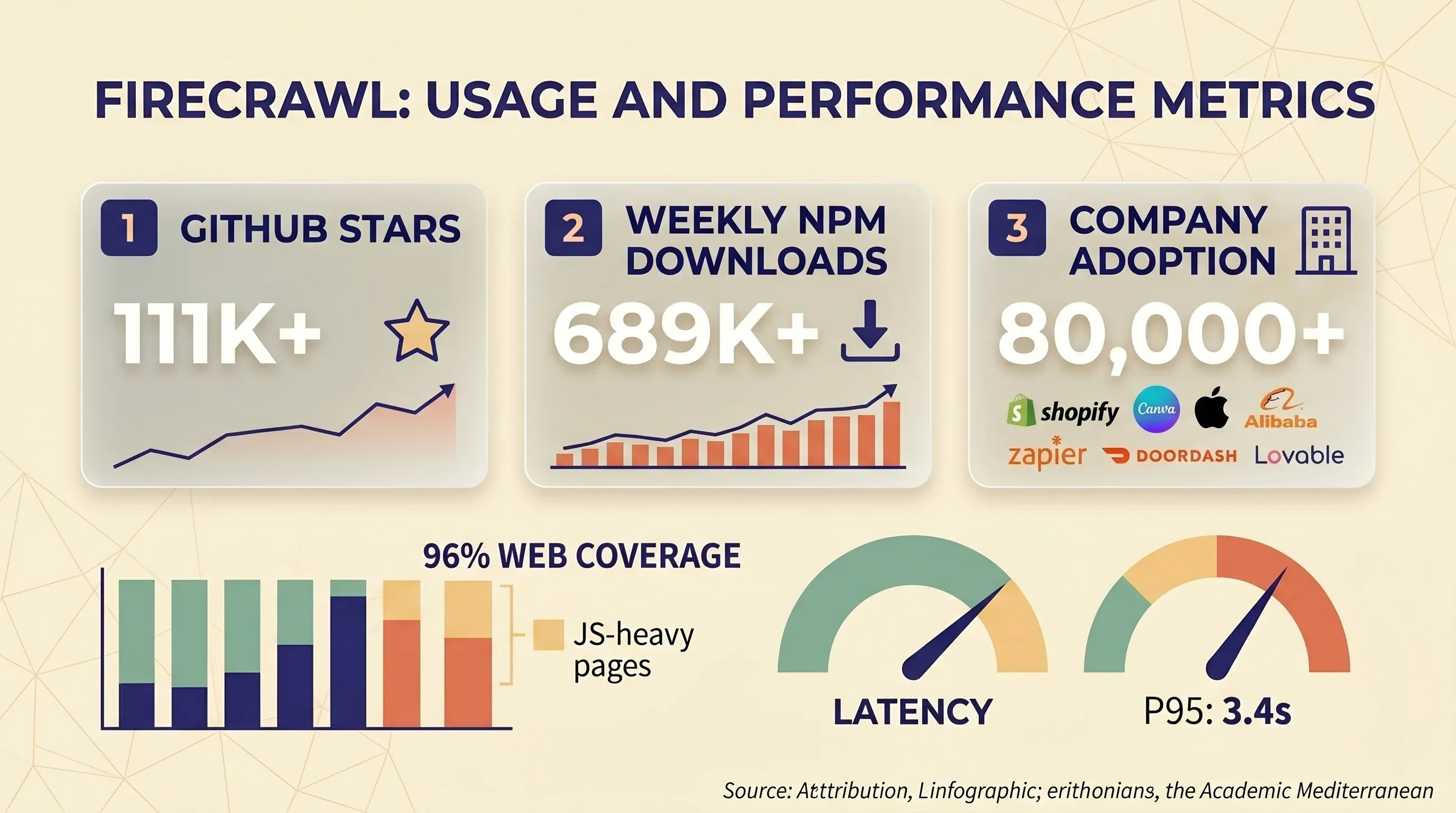
ha testato in modo indipendente 10 API di web scraping contro 15 siti fortemente protetti dai bot. Risultati di Firecrawl:
| Provider | Tasso di successo (2 req/s) | Tasso di successo (10 req/s) |
|---|---|---|
| Zyte | 93,14% | 89,2% |
| ScrapFly | 91,8% | 88,5% |
| Bright Data | 88,7% | 84,9% |
| Firecrawl | 33,69% | 26,69% |
Firecrawl si è classificata su 10 provider nei siti protetti. Il suo tempo di risposta rapido (7,92 secondi in media) si spiega in parte con una strategia “fail fast” — restituisce gli errori rapidamente invece di ritentare.
Il benchmark più ampio e continuo di assegna a Firecrawl un tasso di successo complessivo del 65,4% (sopra la media del settore del 59,5%), con risultati solidi sui target facili ma deboli su quelli protetti.
Suddivisione della difficoltà dei siti: target facili, medi e difficili
| Difficoltà | Esempi di siti | Tasso di successo Firecrawl | Raccomandazione |
|---|---|---|---|
| Facile | Blog, documentazione, pagine SaaS pubbliche | 85–98% | Usa Firecrawl con fiducia |
| Media | Cataloghi prodotti, siti di news con protezione bot di base, Etsy, Realtor.com | 53–65% | Testa con attenzione, aspettati fallimenti |
| Difficile | Amazon, LinkedIn, Instagram, pagine con forte uso di Cloudflare | 0–33% | Non affidarti a Firecrawl — usa provider anti-bot dedicati |
I siti protetti da Cloudflare sono il punto di fallimento più segnalato. Diversi issue su GitHub documentano il problema: il rilevamento basato sulle impronte digitali di Cloudflare blocca Firecrawl anche quando viene usata la rotazione degli IP. Gli utenti self-hosted sono colpiti ancora più duramente, perché non hanno l’infrastruttura proxy di Fire-engine.
Cosa fare quando Firecrawl non basta
Per i siti fortemente protetti, gli utenti in genere si affidano a servizi proxy dedicati come ScrapFly o Bright Data, oppure a tool con browser headless e configurazioni stealth personalizzate. Se sei un utente business che non vuole occuparsi di rotazione proxy o di calcoli sui tassi di successo, strumenti no-code come gestiscono le protezioni anti-bot dietro le quinte — tu devi solo cliccare e ottenere i dati.
Pro e contro di Firecrawl: un riepilogo onesto
Cosa fa bene Firecrawl
- Output markdown pulito e pronto per gli LLM — sempre ben formattato, con una struttura corretta delle intestazioni. È davvero il punto di forza principale di Firecrawl.
- Zero overhead infrastrutturale per gli utenti cloud — niente configurazione del browser, gestione proxy o setup di browser headless.
- Ampie integrazioni con framework — LangChain, LlamaIndex, CrewAI, AutoGPT, Dify, , Flowise (oltre 7 integrazioni per pipeline AI).
- Scoperta URL veloce tramite endpoint Map — 2–3 secondi per una sitemap completa.
- Core open source con — trasparenza e contributi della community.
- Supporto al server MCP con il modello FIRE-1 per i flussi di lavoro degli agenti AI.
- su pagine molto pesanti in JavaScript (SPA in React, Vue, Angular).
Dove Firecrawl mostra i suoi limiti
- Prezzi doppi (crediti + abbonamento Extract separato) creano sorprese in fattura che nessuno si aspetta.
- Moltiplicatori di crediti gonfiano i costi reali da 5 a 9 volte rispetto al prezzo dichiarato.
- Prestazioni anti-bot: ultima in classifica nel benchmark Proxyway ( contro il leader al 93,14%).
- La modalità Agent consuma crediti in modo imprevedibile, senza stimatore prima dell’esecuzione.
- Anche le richieste fallite consumano crediti — spreco del 20–30% sui siti instabili.
- La versione self-hosted non include Agent, Browser Sandbox, anti-bot Fire-engine e dashboard.
- Nessuna soluzione CAPTCHA nativa — una lacuna importante rispetto a Bright Data e Zyte.
- Non accessibile agli utenti non tecnici — richiede conoscenze di programmazione e API.
- I 500 crediti del piano gratuito sono vitalizi, non mensili — insufficienti per test significativi.
Oltre gli strumenti per sviluppatori: alternative no-code che le recensioni di Firecrawl non menzionano mai
Ogni recensione di Firecrawl che ho letto lo confronta solo con altri strumenti per sviluppatori — Crawl4AI, Scrapy, Playwright, Apify. Ha senso se sei uno sviluppatore. Ma una grossa fetta di chi cerca soluzioni di web scraping non è tecnica: team sales che costruiscono liste di prospect, operazioni ecommerce che monitorano i prezzi dei concorrenti, marketer che raccolgono dati sui contenuti, agenti immobiliari che tengono d’occhio gli annunci.
Questa è una lacuna che vale la pena colmare.
Tabella di confronto delle alternative a Firecrawl
| Strumento | Ideale per | Serve codice? | Output pronto per LLM | Prezzo di partenza |
|---|---|---|---|---|
| Firecrawl | Sviluppatori che costruiscono app AI | Sì (API) | ✅ Markdown/JSON | $19/mese |
| Crawl4AI | Sviluppatori che vogliono free/OSS | Sì (Python) | ✅ Markdown | Gratis |
| Apify | Sviluppatori che hanno bisogno di scala + marketplace | Sì (SDK) | ⚠️ Con configurazione | $39/mese |
| Thunderbit | Utenti business (no-code) | No (estensione Chrome) | ✅ Dati strutturati | Piano gratuito disponibile |
| ScrapingBee | Sviluppatori che hanno bisogno di proxy | Sì (API) | ❌ HTML grezzo | $49/mese |
| Bright Data | Team dati enterprise | Sì (API/SDK) | ⚠️ Con configurazione | $500+/mese |
Perché Thunderbit è la scelta di riferimento per i team non tecnici
Lavoro nel team Thunderbit, quindi lo dico con trasparenza. Thunderbit merita di essere in questo confronto perché risolve un problema diverso da Firecrawl, per un pubblico diverso, senza richiedere codice.
Il flusso di lavoro di Thunderbit è in due clic: apri l’, clicchi “AI Suggest Fields”, poi clicchi “Scrape”. L’AI legge la pagina, suggerisce le colonne giuste ed estrae i dati strutturati in una tabella. Niente chiavi API, niente selettori, niente programmazione. Puoi esportare gratuitamente in Excel, Google Sheets, Airtable o Notion.
Differenziatori chiave per gli utenti business:
- Arricchimento delle sottopagine — apri le pagine di dettaglio e recuperi automaticamente altri campi
- AI che si adatta ai cambiamenti di layout — nessuna manutenzione quando un sito cambia design
- Etichettatura e traduzione dati integrate — utili per dataset multilingue
- Template istantanei per siti popolari (Amazon, Zillow, LinkedIn, ecc.)
Per gli sviluppatori che vogliono un’alternativa via API, Thunderbit offre anche gli endpoint con prezzi più semplici rispetto al sistema doppio crediti/token di Firecrawl. Non sostituirà Firecrawl per chi sviluppa pipeline LLM. Ma per team sales, ecommerce, marketing e operations che hanno bisogno di dati strutturati senza scrivere codice, è la strada più rapida ed economica.
Build vs buy: quando Firecrawl si ripaga da solo e quando no
“Stavo pensando di scrivere il mio web scraper… più semplice di Firecrawl ma almeno più economico.” Molti utenti sollevano questo punto. Invece di un’opinione soggettiva, ecco un framework decisionale strutturato.
Tabella del framework decisionale
| Fattore | Costruire su misura (Scrapy/Playwright) | Acquistare Firecrawl Cloud | Usare Thunderbit (No-Code) |
|---|---|---|---|
| Tempo di setup | 10–40+ ore | ~30 minuti | ~5 minuti |
| Manutenzione continua | Alta (i selettori si rompono) | Quasi nulla (gestito) | Nulla (l’AI si adatta) |
| Gestione anti-bot | Manuale (proxy, header, retry) | Integrata (parziale — debole sui siti protetti) | Integrata (modalità browser + cloud) |
| Costo a 1K pagine/mese | $50–150 (server + proxy) | $19–$108 (dipende dalle funzionalità) | $0–$15 |
| Costo a 50K pagine/mese | $500–$1.500 (infrastruttura) | $399–$1.138 | $39–$249 |
| Output pronto per LLM | Richiede codice personalizzato | Integrato (markdown/JSON) | Tabelle strutturate (esportabili) |
| Ideale per | Controllo totale, siti di nicchia, team DevOps | Sviluppatori AI/LLM, pipeline RAG | Sales, ecommerce, marketing, operations |
Per la maggior parte delle organizzazioni, sviluppare una soluzione personalizzata costa rispetto alle API nell’arco di tre anni. Il punto di pareggio in cui una soluzione costruita internamente diventa più economica è approssimativamente oltre 10 milioni di pagine al mese — una scala che pochissimi team raggiungono davvero.
Il verdetto onesto: quale strada fa per te?
Firecrawl si ripaga quando:
- Il tuo team già programma in Python/JS e ha bisogno di markdown pulito per pipeline LLM/RAG
- I tuoi target sono per lo più non protetti o poco protetti
- Vuoi un’infrastruttura gestita senza overhead DevOps
- Il volume resta sotto ~50K pagine/mese
Firecrawl non si ripaga quando:
- Sei un utente business che esegue estrazioni senza un team di sviluppo → Thunderbit è più semplice e più veloce
- I tuoi target sono fortemente protetti (Amazon, LinkedIn, siti molto dipendenti da Cloudflare) → Bright Data o Zyte
- Ti serve una fatturazione prevedibile su larga scala → i moltiplicatori di crediti rendono i costi imprevedibili
- Vuoi self-hosting con tutte le funzionalità → Agent, Browser Sandbox e Fire-engine sono solo cloud
Costruire su misura ha senso solo quando:
- Il tuo team ha capacità DevOps dedicate
- Sei su una scala enorme (oltre 10 milioni di pagine/mese)
- Ti serve pieno controllo sulla gestione di siti di nicchia o particolari
- Sei a tuo agio con la manutenzione continua dei selettori
Recensione Firecrawl: tabella comparativa affiancata
Ecco tutto a confronto:
| Strumento | Tipo | Ideale per | Serve codice | Gestione anti-bot | Output pronto per LLM | Opzione self-host | Prezzo di partenza |
|---|---|---|---|---|---|---|---|
| Firecrawl | API | Sviluppatori AI/LLM | Sì | Debole sui siti protetti | ✅ Markdown/JSON | ✅ (limitato) | $19/mese |
| Crawl4AI | Libreria Python | Sviluppatori OSS-first | Sì | Nessuna (fai da te) | ✅ Markdown | ✅ | Gratis |
| Apify | Piattaforma cloud | Scala + marketplace | Sì | Media | ⚠️ Con configurazione | ✅ | $39/mese |
| Thunderbit | Estensione Chrome + API | Utenti business, no-code | No | Integrata | ✅ Dati strutturati | ❌ | Piano gratuito |
| ScrapingBee | API | Sviluppatori focalizzati sui proxy | Sì | Forte | ❌ HTML grezzo | ❌ | $49/mese |
| Bright Data | API + rete proxy | Team dati enterprise | Sì | La migliore (~99,9%) | ⚠️ Con configurazione | ❌ | $500+/mese |
Verdetto finale: Firecrawl ne vale la pena?
Firecrawl è uno strumento solido per un caso d’uso specifico: team di sviluppo che costruiscono app LLM, pipeline RAG o agenti AI e hanno bisogno di dati web puliti su scala moderata, con familiarità verso flussi di lavoro basati su API. La qualità dell’output markdown è davvero ai vertici, e le integrazioni con framework (LangChain, LlamaIndex, CrewAI) sono mature. Se il tuo team lavora già in Python o JavaScript e i siti target non sono fortemente protetti dai bot, Firecrawl può farti risparmiare parecchio tempo di ingegneria.
Però i lati negativi sono reali. Il sistema di prezzi doppio (crediti + abbonamento Extract separato) crea sorprese concrete in fattura. Il sui siti protetti significa che non puoi affidarti a Firecrawl per Amazon, LinkedIn o target molto dipendenti da Cloudflare. La versione self-hosted non include abbastanza funzionalità da poter essere considerata una vera alternativa gratuita. E se sei un utente non tecnico — qualcuno che lavora in sales, ecommerce o marketing — Firecrawl non è proprio pensato per te.
Prova i 500 crediti gratuiti di Firecrawl per vedere se la qualità dell’output si adatta alla tua pipeline. Ma prima di sottoscrivere un piano a pagamento, stima i costi mensili reali usando il calcolatore qui sopra. Se sei un utente business che ha solo bisogno di dati strutturati dai siti senza scrivere codice, parti invece dal — in pochi minuti sarai già a estrarre dati, non in ore. Puoi provare subito la oppure dare un’occhiata a per vedere cosa scala meglio per il tuo team. Per guide video, il offre demo passo passo.
FAQ
Quanto costa Firecrawl per pagina scrappata?
Uno scrape o crawl base costa 1 credito per pagina. L’estrazione JSON aggiunge 4 crediti/pagina (5 totali). Enhanced Mode aggiunge altri 4 (fino a 9 totali). Search costa 2 crediti ogni 10 risultati e la modalità Agent può consumare da 100 a oltre 1.500 crediti per query. In più, la funzione Extract richiede un abbonamento a token separato a partire da $89 al mese. Consulta la sezione del calcolatore dei costi qui sopra per stime realistiche in base al profilo utente.
È possibile self-hostare Firecrawl gratuitamente?
Sì, il core open source (AGPL-3.0) è gratuito da self-hostare. Ma perdi la modalità Agent, Browser Sandbox, anti-bot/rotazione proxy (Fire-engine è closed source), l’elaborazione batch e la dashboard di gestione. Dovrai portare le tue chiavi LLM per l’estrazione e gestire da solo Docker, PostgreSQL e Redis. Il self-hosting funziona per pipeline base da crawl a markdown, ma non sostituisce il prodotto cloud in produzione su larga scala.
Firecrawl è adatto per scrappare Amazon, LinkedIn o altri siti protetti?
Il mostra Firecrawl con un tasso di successo del 33,69% sui siti fortemente protetti dai bot — ultimo su 10 provider testati. Funziona bene sulle pagine non protette (blog, documentazione, siti SaaS — 85–98% di successo), ma non è affidabile per le principali piattaforme ecommerce o social. Per questi target, valuta provider anti-bot dedicati come Bright Data o Zyte, oppure strumenti no-code come Thunderbit che gestiscono le protezioni anti-bot dietro le quinte.
Qual è la migliore alternativa a Firecrawl per utenti non tecnici?
è la migliore alternativa no-code. È un’estensione Chrome in cui clicchi “AI Suggest Fields” e poi “Scrape” — niente chiamate API, niente codice, niente selettori. I dati si esportano gratuitamente in Excel, Google Sheets, Airtable o Notion. È pensato per team sales, ecommerce, marketing e operations che hanno bisogno di dati web strutturati senza coinvolgere uno sviluppatore.
Firecrawl offre una prova gratuita?
Firecrawl offre senza richiedere carta di credito. Bastano per testare le funzionalità base di scrape/crawl su poche pagine, ma non sono sufficienti per l’uso in produzione — soprattutto se attivi l’estrazione (che consuma 5 crediti per pagina). I crediti non si rinnovano ogni mese nel piano gratuito.
Scopri di più