

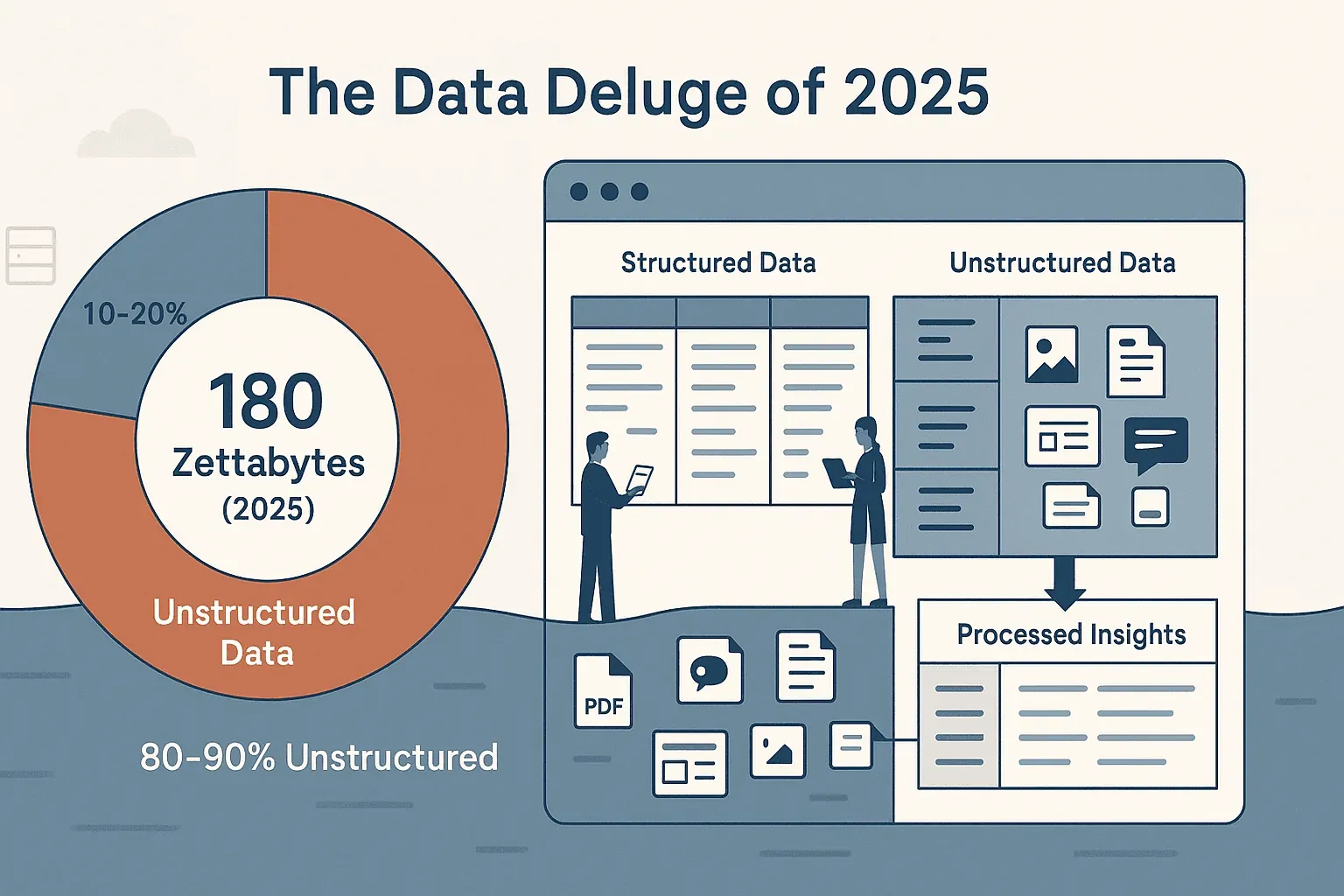
Se hai mai provato a raccogliere dati da un sito web — che sia per trovare lead commerciali, confrontare i prezzi dei concorrenti o semplicemente mettere ordine in un catalogo prodotti caotico — sai bene che il web non è stato pensato per un copia e incolla semplice. La quantità di dati online è enorme: IDC e Statista stimavano il datasphere globale a circa 180 zettabyte nel 2025, e siamo già sulla buona strada per arrivare a circa 221 zettabyte nel 2026. Il problema più grande non è il volume, ma la struttura: circa l’80% di quei dati è non strutturato, nascosto in pagine web, PDF, immagini e feed dinamici. La maggior parte dei team aziendali — me compreso — ha passato fin troppo tempo a lottare con questo caos, per poi ritrovarsi con fogli di calcolo raffazzonati e una sensazione di déjà vu.
Estrai dati da qualsiasi sito web con l'IA Get Started Free
Ecco perché sono ossessionato dal crawling efficiente dei siti web. In questa guida ti mostrerò un approccio pratico, passo dopo passo, per eseguire il crawl di qualsiasi sito — senza codice e senza stress — usando Thunderbit, il nostro web crawler basato sull’IA. Che tu lavori nelle vendite, nelle operations o sia semplicemente stufo dell’inserimento manuale dei dati, ti mostrerò come gestire layout complessi, paginazione, sottopagine e persino come estrarre dati da PDF e immagini. Trasformiamo il caos del web nel tuo prossimo vantaggio competitivo.
Che cosa significa eseguire il crawl di un sito web in modo efficiente?
Partiamo dalle basi: fare crawling di un sito web significa usare uno strumento automatizzato (pensa a un assistente robotico) per visitare sistematicamente le pagine web ed estrarre le informazioni che ti interessano — nomi, prezzi, email, specifiche dei prodotti, quello che vuoi. Un crawling efficiente non riguarda solo la velocità; riguarda la precisione, il minimo sforzo manuale e la capacità di gestire gli ostacoli reali del web come paginazione, sottopagine e dati non strutturati (Wikipedia).
Cosa distingue un crawl efficiente da una maratona di copia e incolla? Ecco ciò che conta davvero:
- Velocità: recuperare centinaia di pagine o record in minuti, non in ore.
- Precisione: prendere esattamente i dati che ti servono, senza perdere voci o introdurre refusi.
- Automazione: lasciare che lo strumento gestisca le attività ripetitive, come cliccare “Avanti” o seguire i link alle pagine di dettaglio.
- Resilienza: adattarsi a layout complessi, contenuti dinamici e persino ai cambiamenti nella struttura del sito.
- Configurazione minima: niente codice, niente lotta con i selettori, niente manutenzione continua.
Il mondo reale non è fatto di tabelle perfette. I siti moderni hanno infinite scroll, navigazione in più passaggi, richieste di accesso e dati nascosti in PDF o immagini. Un crawling efficiente significa superare tutto questo — così spendi meno tempo nel lavoro ripetitivo e più tempo ad analizzare e agire (AIMultiple).
Perché il crawling efficiente dei siti web è importante per vendite e operations
Perché i team aziendali tengono così tanto al web crawling? Perché i dati giusti — consegnati in fretta — possono fare la differenza nella tua prossima campagna, nel lancio di un prodotto o nel trimestre di vendita. Ecco alcuni dei casi d’uso più comuni (e con il miglior ROI) che vedo ogni settimana:
| Caso d'uso | Vantaggio & ROI | Risultato di esempio |
|---|---|---|
| Generazione di lead | Riempie più rapidamente il funnel di vendita, fa risparmiare ore nella ricerca dei prospect, riduce gli errori manuali | Estrae 5.000 lead mirati durante la notte, avvia le campagne 2 settimane prima, aumenta gli appuntamenti del 30% |
| Monitoraggio dei prezzi dei concorrenti | Consente il dynamic pricing, reagisce ai cambiamenti di mercato in tempo reale, protegge i margini | Un retailer aggiorna i prezzi ogni giorno e registra un aumento delle vendite del 4% |
| Estrazione del catalogo prodotti/inventario | Mantiene gli annunci aggiornati, riduce l'inserimento manuale dei dati, evita sovrapproduzione o prezzi errati | Il team e-commerce aggiorna 10.000 SKU al giorno, riducendo il tempo di aggiornamento del 90% |
| Ricerca di mercato e analisi delle recensioni | Ottiene insight su larga scala su sentiment e trend dei clienti, individua opportunità prima dei concorrenti | Analizza oltre 10.000 recensioni, identifica nuove opportunità di prodotto, migliora il messaggio di marketing |
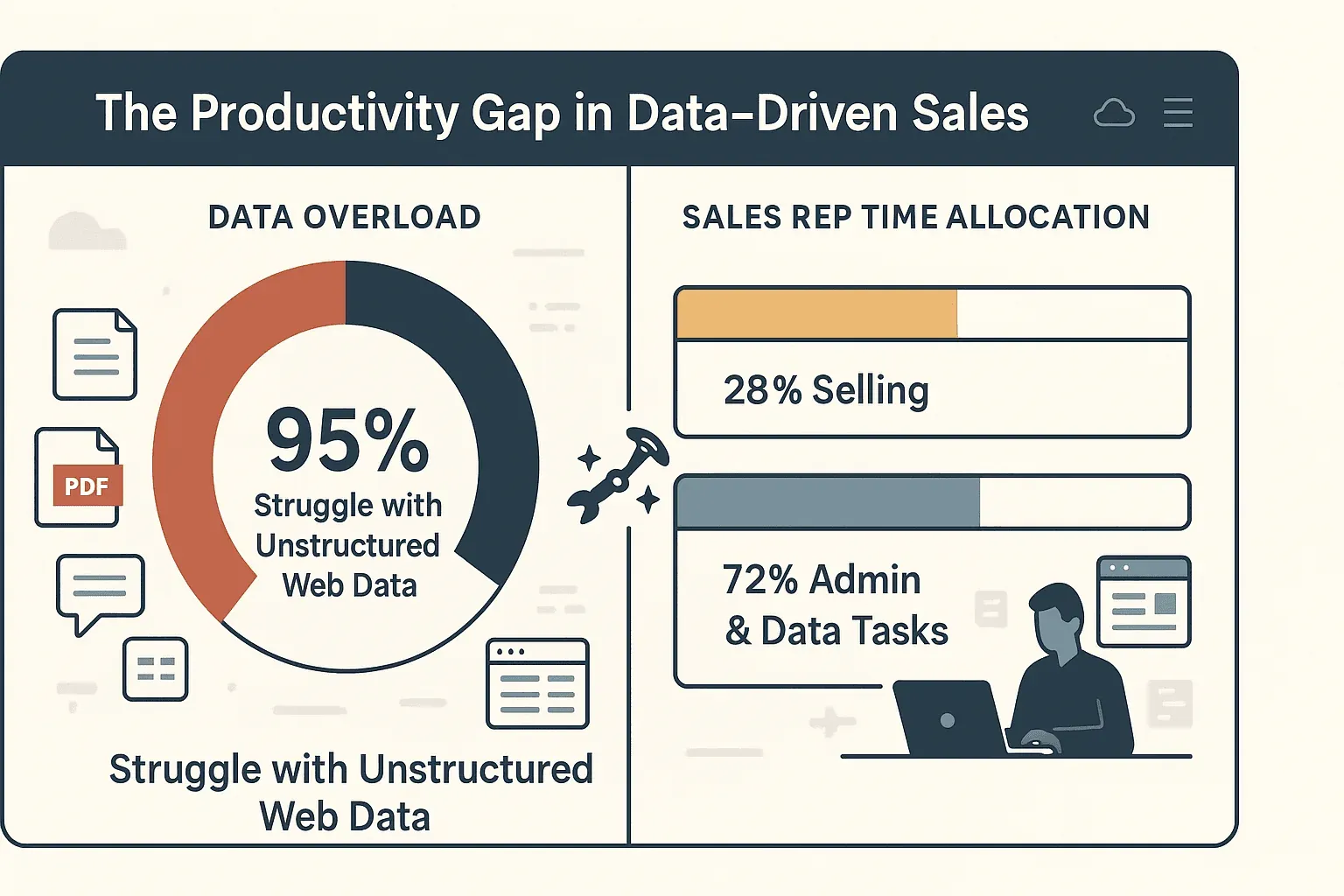
In sintesi? Un crawling efficiente significa decisioni più rapide e intelligenti — e molto meno tempo passato a copiare e incollare. Infatti, il 95% delle aziende ammette di avere difficoltà a usare i dati web non strutturati, e i commerciali dedicano solo il 28% del loro tempo alla vendita vera e propria. Il resto si perde nell’inserimento manuale dei dati e nelle attività amministrative.
Thunderbit: il modo più semplice per eseguire il crawl di un sito web
Diciamolo chiaramente: la maggior parte degli strumenti di web scraping è pensata per gli sviluppatori, non per gli utenti business. Ecco perché abbiamo creato Thunderbit, un web crawler basato sull’IA che è facile come ordinare da asporto. Ecco cosa rende Thunderbit diverso:
- Prompt in linguaggio naturale: descrivi semplicemente i dati che vuoi (“Raccogli tutti i nomi e i prezzi dei prodotti da questa pagina”) e l’IA di Thunderbit fa il resto.
- Suggerimento campi AI: clicca su “AI Suggest Fields” e Thunderbit analizza la pagina, consiglia le colonne migliori da estrarre e configura il crawler per te.
- Workflow in 2 clic: una volta soddisfatto dei campi, clicca su “Scrape”. Tutto qui: niente codice, niente template, niente lotta con i selettori.
- Gestisce paginazione e sottopagine: Thunderbit rileva e naviga automaticamente liste su più pagine e può seguire i link alle pagine di dettaglio (sottopagine) per arricchire i dati.
- Esportazione immediata: invia i dati direttamente a Excel, Google Sheets, Airtable o Notion — oppure scaricali in CSV/JSON, tutto gratis.
- OCR per PDF e immagini: ti servono dati da un PDF, un’immagine o un documento scannerizzato? L’OCR integrato di Thunderbit estrae e struttura anche quel contenuto.
Thunderbit è pensato per chi non è tecnico — se sai navigare sul web e scrivere una frase, puoi fare crawling di un sito come un professionista. E sì, c’è anche un piano gratuito così puoi provarlo senza rischi.
Prova Thunderbit gratis – inizia subito a fare crawling
Confronto tra soluzioni di crawling dei siti web: Thunderbit vs metodi tradizionali
Mettiamo Thunderbit a confronto con le soluzioni classiche:
| Approccio | Tempo e complessità di configurazione | Competenze richieste | Manutenzione e affidabilità |
|---|---|---|---|
| Copia e incolla manuale | Estremamente elevati, non scalabile | Nessuna, ma soggetto a errori | 100% manuale, da rifare a ogni aggiornamento |
| Codice personalizzato (Python, ecc.) | Configurazione iniziale elevata, ore/giorni per sito | Richiede programmazione | Si rompe con i cambiamenti del sito, necessita di correzioni continue |
| Strumento tradizionale no-code | Media, configurazione point-and-click | Basse/medie | Richiede aggiornamenti per i cambi di layout, non sempre gestisce siti dinamici |
| Thunderbit (basato su IA) | Molto bassa, configurazione in 2 clic | Nessuna | L’IA si adatta ai cambiamenti, manutenzione minima |
Gli strumenti tradizionali possono portarti a metà strada, ma spesso vanno in crisi con i contenuti dinamici, la paginazione o costringono a supervisionare ogni cambiamento. L’IA di Thunderbit legge il sito come farebbe una persona, si adatta ai nuovi layout e gestisce le parti complicate — così non devi farlo tu (Thunderbit Blog).
Passo 1: configurare il crawl del tuo sito con Thunderbit
Iniziare è semplicissimo:
- Installa la Thunderbit Chrome Extension. Registrati per un account gratuito.
- Vai sul sito web di destinazione. Apri la pagina che vuoi sottoporre a crawl — può essere una lista di prodotti, una directory o persino un PDF.
- Apri Thunderbit. Clicca sull’icona di Thunderbit nella barra degli strumenti di Chrome.
- Descrivi i dati che ti servono. Clicca su “AI Suggest Fields” per lasciare che Thunderbit consigli le colonne, oppure scrivi un prompt in linguaggio naturale (per esempio, “Estrai il nome prodotto, il prezzo e l’URL dell’immagine per ogni elemento”).
- Anteprima e modifica. Thunderbit mostra una tabella di anteprima — puoi modificare i nomi dei campi, rimuovere quelli superflui o aggiungere istruzioni personalizzate, se necessario.
Consiglio pratico: nei prompt sii specifico ma conciso. Menziona i dati così come compaiono sul sito (“prezzo”, “indirizzo”, ecc.) e lascia che l’IA di Thunderbit faccia il lavoro pesante.
Passo 2: gestire paginazione e sottopagine durante il crawling del sito web
Qui Thunderbit dà davvero il meglio. Nella maggior parte dei casi reali i dati non stanno in una sola pagina — sono distribuiti in elenchi paginati o nascosti in sottopagine.
- Paginazione: Thunderbit rileva automaticamente pulsanti “Avanti”, numeri di pagina o infinite scroll. Quando clicchi su “Scrape”, continua a caricare le pagine finché non ha raccolto tutto — non devi inserire manualmente URL o cliccare pagina per pagina.
- Crawling delle sottopagine: Ti servono più dettagli? Dopo aver estratto l’elenco principale, clicca su “Scrape Subpages”. Thunderbit segue i link (come le pagine prodotto o i profili aziendali), estrae informazioni extra e le unisce alla tua tabella.
Esempio: devi estrarre dati da un sito e-commerce? Thunderbit recupera l’elenco prodotti, poi visita la pagina di dettaglio di ciascun prodotto per prelevare specifiche, recensioni o immagini — tutto in una sola volta.
Best practice: lascia che Thunderbit completi il crawl principale, poi usa lo scraping delle sottopagine per i dati più approfonditi. Vedrai gli aggiornamenti di avanzamento e potrai controllare eventuali record mancanti.
Passo 3: estrazione intelligente dei dati non strutturati con Thunderbit
Non tutti i dati arrivano in tabelle ordinate. Descrizioni prodotto, recensioni o campi in formati misti possono essere un incubo per gli scraper tradizionali. L’IA di Thunderbit affronta il problema alla radice:
- Pulisce e formatta i dati: rimuove i simboli di valuta, interpreta i numeri e suddivide i campi complessi (per esempio, “USD 299 (sconto del 50%!)” diventa “299” e “sconto del 50%”).
- Interpreta testi complessi: estrae informazioni strutturate dai paragrafi (per esempio, trova “Location: New York” in una descrizione di lavoro).
- Classifica e etichetta: aggiunge categorie o tag in base al contenuto (per esempio, “Elettronica” vs “Abbigliamento”).
- Gestisce le incoerenze: si adatta a campi mancanti o cambi di layout, mantenendo i dati allineati e corretti.
- Riassume o traduce: ti serve un riassunto in una frase o una traduzione? Aggiungi un’istruzione personalizzata — anche questo l’IA di Thunderbit può farlo.
Il risultato? Dati puliti e subito utilizzabili — niente più ore passate a sistemare tutto in Excel.
Passo 4: scegliere tra cloud crawling e browser crawling
Thunderbit ti offre due modi di eseguire il crawl, a seconda delle esigenze:
- Browser crawling: gira nel tuo browser Chrome, usando la sessione con cui hai effettuato l’accesso. Perfetto per i siti che richiedono autenticazione o hanno forti protezioni anti-bot. Vedi il crawl mentre avviene e imita la navigazione di una persona.
- Cloud crawling: scarica il lavoro sui server cloud di Thunderbit. Gestisce fino a 50 pagine in parallelo — ottimo per lavori grandi o attività programmate. Puoi chiudere il laptop e lasciare che Thunderbit faccia il lavoro pesante.
Quando usare ciascuno:
- Usa la modalità Browser per siti che richiedono login o quando devi interagire con la pagina.
- Usa la modalità Cloud per siti pubblici, lavori in blocco o quando vuoi velocità e automazione.
Passare da una modalità all’altra è facile: scegli la tua preferenza prima di avviare il crawl.
Passo 5: estrarre dati da documenti e immagini usando l’OCR
A volte i dati che ti servono sono intrappolati in PDF, immagini o documenti scannerizzati. L’OCR (Optical Character Recognition) integrato di Thunderbit cambia le regole del gioco:
- PDF: estrae tabelle, email o testo da report, fatture o cataloghi.
- Immagini: recupera testo da screenshot, etichette di prodotto o persino infografiche.
- Moduli scannerizzati: automatizza l’inserimento dati da ricevute, contratti o biglietti da visita.
Ti basta indicare a Thunderbit l’URL del PDF o dell’immagine, e lui ne estrae e struttura il contenuto — senza bisogno di software separato. Puoi anche combinare l’OCR con prompt IA per estrazioni avanzate (“Trova tutti gli indirizzi email in questo PDF”).
Passo 6: esportare e usare i dati raccolti
Una volta completato il crawl, è il momento di mettere quei dati al lavoro:
- Opzioni di esportazione: scarica in CSV o JSON, oppure esporta direttamente su Google Sheets, Excel, Airtable o Notion. Tutti i formati sono gratuiti — anche nel piano base.
- Vendite e CRM: importa gli elenchi di lead nel tuo CRM, avvia campagne di outreach o arricchisci i contatti esistenti.
- Marketing e analisi: analizza i prezzi dei concorrenti, monitora i trend di mercato o visualizza i dati in dashboard.
- Operations e inventario: controlla le giacenze, aggiorna i cataloghi o attiva alert per cambiamenti importanti.
- Automazione: usa integrazioni (come Zapier o Google Apps Script) per automatizzare follow-up, reportistica o arricchimento dei dati.
L’output strutturato di Thunderbit ti permette di passare dal crawl all’azione in pochi minuti, non in giorni.
Inizia a fare crawling con Thunderbit AI
Conclusione e punti chiave
Fare il crawl di un sito web in modo efficiente non è solo il sogno di un tecnico: è un superpotere per il business. Con Thunderbit, chiunque può:
- Configurare un crawl in pochi secondi usando il linguaggio naturale o i campi suggeriti dall’IA.
- Gestire siti complessi con paginazione, sottopagine e contenuti dinamici — senza codice.
- Estrarre dati puliti e strutturati da pagine web disordinate, PDF e immagini.
- Scegliere la modalità migliore (browser o cloud) in base a velocità, scala e sicurezza.
- Esportare i dati all’istante verso i tuoi strumenti e flussi di lavoro preferiti.
Sono finiti i giorni del copia e incolla infinito e degli scraper che si rompono. Scarica Thunderbit, prova un crawl gratuito e scopri quanto tempo (e quanta sanità mentale) puoi risparmiare. Il tuo prossimo grande insight — o la tua prossima vittoria commerciale — potrebbe essere a un clic di distanza.
Vuoi altri consigli e approfondimenti? Dai un’occhiata al Thunderbit Blog per tutorial, casi d’uso e le ultime novità sul web crawling basato sull’IA.
FAQ
1. Qual è la differenza tra web crawling e web scraping?
Il web crawling consiste nel navigare sistematicamente i siti web per scoprire pagine e link, mentre il web scraping riguarda l’estrazione di dati specifici da quelle pagine. Thunderbit unisce entrambe le cose — trova, naviga ed estrae le informazioni che ti servono.
2. Thunderbit può gestire siti web che richiedono login?
Sì! Usa la modalità Browser di Thunderbit per fare crawling su siti che richiedono autenticazione. Utilizza la tua sessione Chrome connessa, così puoi accedere ai dati dietro login o paywall (sempre nel rispetto dei termini di servizio del sito).
3. Come gestisce Thunderbit la paginazione e l'infinite scroll?
Thunderbit rileva e naviga automaticamente liste paginate e pagine con infinite scroll. Clicca “Avanti”, scorre o carica altri contenuti finché tutti i dati non vengono acquisiti — senza configurazione manuale.
4. Quali tipi di dati può estrarre Thunderbit?
Thunderbit può estrarre testo, numeri, date, URL, email, numeri di telefono, immagini e persino dati da PDF e immagini usando l’OCR. Puoi personalizzare i campi e usare prompt IA per strutturazione e pulizia avanzate.
5. Thunderbit è gratuito?
Thunderbit offre un piano gratuito che ti consente di eseguire il crawl di un numero limitato di pagine. Tutti i formati di esportazione (CSV, Excel, Google Sheets, Airtable, Notion) sono inclusi gratuitamente. I piani a pagamento partono da 15 $/mese per volumi più alti e funzioni avanzate.
Pronto a fare crawling in modo più intelligente, non più faticoso? Prova Thunderbit oggi stesso e lascia che l’IA faccia il grosso del lavoro per il tuo prossimo progetto di dati web. Scopri di più
- Come fare il crawl di un sito web? Guida per principianti
- Come fare il crawl di siti web: guida passo dopo passo per principianti
- Come fare il crawl di tutti i link di un sito web: guida completa
Prova gratuitamente l'Estrattore Web AI Get Started Free




