

Setelah menjalankan lebih dari seribu scrape dengan Simplescraper, saya berhenti menghitung keberhasilan dan mulai mencatat kegagalan. Pergeseran itu — dari "apakah berhasil?" menjadi "kenapa kali ini rusak?" — mengajari saya lebih banyak daripada halaman dokumentasi mana pun.
Simplescraper adalah ekstensi Chrome yang solid untuk mengambil data dari situs web tanpa menulis kode. Dengan 60.000 pengguna di Chrome Web Store dan antarmuka point-and-click yang benar-benar mudah dipakai, alat ini memang layak masuk ke toolkit scraping no-code. Tapi inilah yang tidak diceritakan siapa pun di halaman landing: kalau Anda ingin hasil yang konsisten dan andal dalam skala besar, Anda harus paham di mana visual scraper mulai rapuh. Sebuah survei 2025 menemukan bahwa pekerja menghabiskan lebih dari sembilan jam seminggu untuk input data berulang — dan itu persis jenis masalah yang mendorong orang memakai alat seperti Simplescraper. Tapi kalau Anda tidak paham kekhasan alat ini, sembilan jam itu malah habis untuk debugging, bukan untuk kerja yang berguna. Artikel ini membahas lima praktik terbaik yang saya rangkum dari pengalaman operasional nyata: mengatasi kegagalan pemilihan elemen, memilih mode scraping yang tepat, memaksimalkan paket gratis, menghindari blokir, dan tahu kapan harus beralih.

Apa Itu Simplescraper (dan Mengapa Praktik Terbaik Itu Penting)
Simplescraper adalah ekstensi Chrome yang memungkinkan Anda memilih elemen di halaman web secara visual — judul produk, harga, gambar, info kontak — lalu mengekstraknya menjadi data terstruktur tanpa menulis satu baris kode pun. Anda arahkan kursor, klik, lalu alat ini membangun "recipe" yang bisa dipakai ulang di halaman serupa.
Model intinya bekerja seperti ini:
- Pemilihan elemen visual: Klik apa yang ingin Anda ambil. Simplescraper otomatis mendeteksi pola berulang (daftar produk, hasil pencarian, lowongan pekerjaan).
- Recipes: Simpan pengaturan ekstraksi untuk dipakai lagi nanti atau dijalankan pada batch URL.
- Dua mode scraping: Browser (lokal, berjalan di Chrome Anda) dan Cloud (berjalan di server Simplescraper, tanpa pengawasan).
- Integrasi: Ekspor ke Google Sheets, Airtable, webhook, Zapier, Make, CSV, dan JSON.
- Ekstraksi AI: Fitur yang lebih baru, Smart Extract, yang menghasilkan selector CSS dari prompt skema.
Target penggunanya luas — marketer, tim sales, operator e-commerce, peneliti — siapa pun yang perlu mengambil data terstruktur dari situs web tanpa menyewa developer. Dan untuk halaman yang sederhana, Simplescraper bekerja cepat.
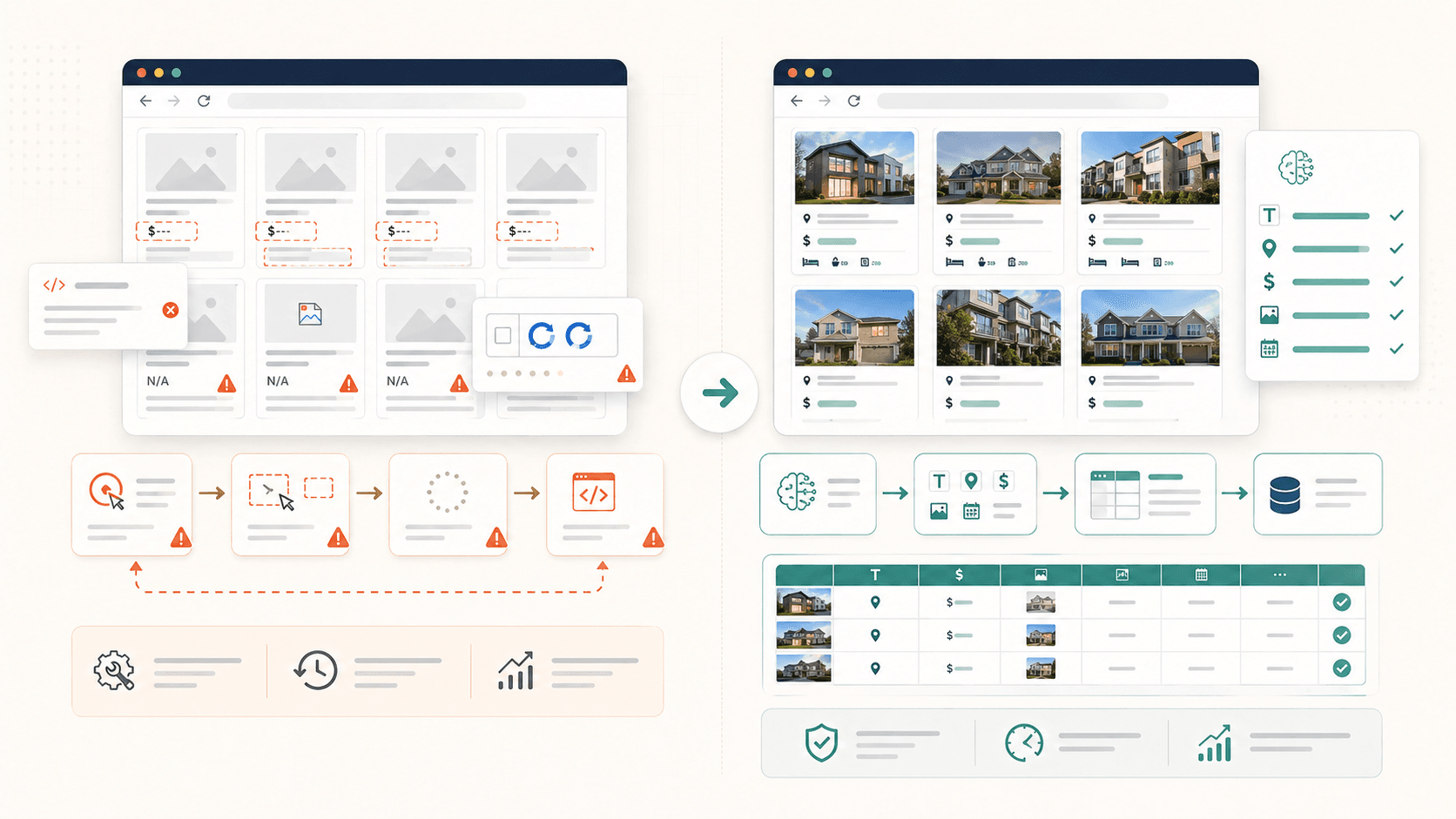
Lalu, kenapa praktik terbaik itu penting? Karena begitu Anda melangkah melewati daftar produk sederhana atau halaman direktori yang rapi, friksi mulai muncul. Konten dinamis, perlindungan anti-bot, gambar yang dimuat malas, struktur HTML bertingkat — inilah kondisi nyata yang memisahkan pengalaman yang bikin frustrasi dari yang produktif. Mengetahui pendekatan yang tepat sejak awal menghemat berjam-jam trial and error.
Praktik Terbaik 1: Apa yang Harus Dilakukan Saat Simplescraper Gagal Memilih Elemen
Ini adalah frustrasi paling umum yang saya lihat. Anda klik sebuah elemen, Simplescraper menyorotnya, Anda merasa aman — lalu hasilnya ternyata kehilangan setengah data Anda. Foto kosong. Bio hilang. Lokasi lenyap.
Pendiri Simplescraper sendiri mengakui sejak awal bahwa "the element/css selector still ain't 100%." Kejujuran itu menyegarkan, tapi tidak menyelesaikan scrape yang rusak pada pukul 11 malam hari Rabu.
Kegagalan Pemilihan yang Umum Terjadi (dan Kenapa Itu Terjadi)
Ada empat pola yang paling sering menjatuhkan Simplescraper:
- Gambar yang dimuat malas: Elemen gambar secara harfiah belum ada di halaman sampai Anda menggulir ke sana. Kalau Anda melakukan scrape sebelum scroll, kolom gambar akan kosong.
- Kontainer bertingkat atau dikelompokkan: Deteksi otomatis Simplescraper berusaha sangat presisi, yang kadang berarti hanya mengambil satu bagian halaman, bukan seluruh kumpulan yang berulang. Pengguna melaporkan tabel yang "tidak mau memilih semua baris sekaligus."
- Konten JavaScript dinamis: Elemen yang dirender setelah halaman awal selesai dimuat via React, Vue, atau panggilan AJAX memang belum ada ketika scraper bertindak terlalu cepat.
- Paginasi infinite scroll: Data yang Anda cari belum dimuat ke HTML karena harus scroll atau klik "load more."
Langkah Troubleshooting yang Praktis
Sebelum beralih ke selector manual, coba ini:
- Gulir seluruh halaman terlebih dahulu. Ini memaksa gambar dan konten yang dimuat malas masuk ke DOM.
- Gunakan "Include Similar" saat jumlah item dalam daftar terlihat terlalu sedikit. Dokumentasi Simplescraper sendiri merekomendasikan ini untuk konten yang dikelompokkan.
- Tunggu render halaman penuh untuk situs yang banyak memakai JavaScript. Beri beberapa detik ekstra sebelum memulai scrape.
- Mulai dari sampel kecil. Pastikan jumlah baris di 2-3 halaman sebelum berkomitmen ke batch 500 halaman.
Beralih ke Selector CSS Manual
Kalau pemilihan visual terus gagal, saatnya turun ke manual. Ini langkah yang membedakan pengguna biasa dari pengguna yang efektif.
Alurnya seperti ini:
- Klik kanan elemen yang Anda inginkan di Chrome → Inspect.
- Di DevTools, identifikasi class name atau data attribute elemen tersebut (misalnya
.product-card .priceatau[data-test="location"]). - Di Simplescraper, buka tab Edit Properties dan tempel selector Anda.
- Uji selector dengan menjalankan scrape kecil.
Tips untuk selector yang kuat:
- Utamakan class name (
.listing-title) daripada selector berbasis posisi (div:nth-child(3)) - Gunakan data attribute jika tersedia — biasanya lebih stabil saat situs diperbarui
- Hindari path yang terlalu dalam dan mudah rusak ketika struktur HTML situs berubah
Alternatif AI: Biarkan Thunderbit Mendeteksi Field Secara Otomatis
Saya akan jujur — tim saya membangun Thunderbit secara khusus karena kami lelah dengan masalah yang persis seperti ini. Fitur "AI Suggest Fields" milik Thunderbit membaca struktur halaman dan merekomendasikan kolom serta logika ekstraksi secara otomatis. Tidak perlu pengetahuan CSS. AI menyesuaikan diri dengan tata letak setiap situs, termasuk konten bertingkat dan gambar yang dimuat malas.
Kalau Anda menghabiskan lebih dari beberapa menit per scrape untuk debugging selector, ada baiknya mencoba pendekatan yang sama sekali berbeda.
Praktik Terbaik 2: Memilih Antara Cloud Scraping dan Browser Scraping
Kebanyakan pengguna Simplescraper memilih mode secara default — biasanya mode yang pertama kali mereka coba — tanpa memikirkan apakah mode itu cocok untuk use case mereka. Ini menyebabkan kegagalan yang seharusnya bisa dicegah.
Kapan Menggunakan Browser Scraping (Lokal)
- Halaman yang butuh login: LinkedIn, dashboard CRM, alat internal — apa pun yang berada di balik autentikasi memerlukan sesi browser aktif Anda.
- Ekstraksi cepat satu kali: Anda sudah ada di halamannya, Anda hanya ingin datanya sekarang.
- Menghemat kredit gratis: Browser scraping tidak menghabiskan kredit cloud.
Konsekuensinya: komputer Anda harus tetap menyala, dan pekerjaan besar akan jauh lebih lambat dibanding cloud.
Kapan Menggunakan Cloud Scraping
- Halaman publik (listing e-commerce, direktori, situs properti) yang tidak memerlukan login.
- Pemantauan terjadwal: Berjalan tanpa pengawasan secara berulang.
- Pekerjaan batch: Hingga 5.000 URL dalam satu batch cloud.
- Pengiriman integrasi: Push otomatis ke Google Sheets, Airtable, atau webhook.
Konsekuensinya: cloud scraping menghabiskan kredit — 2 per halaman yang mendukung JavaScript, 1 per halaman non-JS — dan paket gratis 100 kredit cepat habis.
Kerangka Keputusan
| Skenario | Mode yang Direkomendasikan | Alasannya | Risiko Jika Salah |
|---|---|---|---|
| Halaman yang membutuhkan login (LinkedIn, dashboard) | Browser | Butuh sesi autentikasi Anda | Mode cloud mentok di halaman login |
| Listing produk e-commerce publik | Cloud | Lebih cepat, berjalan tanpa pengawasan | Mode browser mengikat mesin Anda |
| Pemantauan rutin terjadwal | Cloud | Berjalan tanpa Anda | Browser mengharuskan Anda hadir |
| Situs dengan anti-bot kuat (Amazon, Yelp) | Browser (fallback) atau Cloud dengan proxy | Perlu rotasi IP atau reuse sesi | Cloud tanpa proxy cepat diblokir |
| Ekstraksi cepat satu kali | Browser | Langsung, tanpa biaya kredit | Terlalu berlebihan menyiapkan cloud untuk satu halaman |

Bagaimana Thunderbit Menyederhanakan Ini
Di Thunderbit, pilihannya hanya toggle sederhana di dalam antarmuka yang sama. Mode cloud memproses hingga 50 halaman secara bersamaan — tanpa tier berbayar terpisah untuk akses cloud. Mode browser menangani situs yang membutuhkan login tanpa konfigurasi tambahan. Beban mental berupa "saya butuh mode yang mana?" turun drastis ketika kedua mode hidup dalam alur kerja yang sama.
Praktik Terbaik 3: Memaksimalkan Paket Gratis Simplescraper
Kebingungan soal harga itu nyata. Saya pernah melihat posting forum yang mengira "ekstensi Chrome gratis" berarti "semuanya gratis." Padahal tidak. Di sisi lain, saya juga pernah melihat orang mengira Simplescraper mahal karena tier berbayarnya tidak ditampilkan secara menonjol. Kedua asumsi itu tidak membantu.
Apa Saja yang Sebenarnya Termasuk dalam Paket Gratis Simplescraper
Menurut paket Simplescraper saat ini:
- Browser scraping: Tidak terbatas (berjalan lokal di Chrome Anda)
- Kredit cloud: 100 per bulan
- Recipe tersimpan: 3
- Format ekspor: CSV dan JSON
- Yang TIDAK termasuk: Dukungan prioritas, opsi proxy lanjutan, alokasi kredit cloud yang lebih tinggi
Skenario Paket Gratis yang Realistis
Misalnya Anda perlu melakukan scrape 50 halaman produk dari situs e-commerce publik.
- Mode browser (gratis): Anda bisa melakukan ini sepenuhnya gratis. Buka tiap halaman (atau gunakan daftar), jalankan recipe, ekspor ke CSV. Waktu yang dibutuhkan: tergantung kesabaran dan kecepatan internet Anda, tetapi untuk 50 halaman dengan navigasi manual, siapkan 15-30 menit kerja aktif.
- Mode cloud (paket gratis): Dengan rendering JavaScript diaktifkan, setiap halaman menghabiskan 2 kredit. 50 halaman = 100 kredit. Itu berarti seluruh jatah cloud bulanan Anda habis dalam satu pekerjaan. Tidak ada penjadwalan, tidak ada retry kalau ada yang gagal.
Paket gratis ini memang berguna untuk scrape kecil yang sesekali. Tapi ia cepat habis begitu Anda butuh otomatisasi cloud atau skala lebih besar.
Perbandingan Paket Gratis: Simplescraper vs. Thunderbit
| Fitur | Simplescraper Gratis | Thunderbit Gratis |
|---|---|---|
| Halaman/kredit | Browser tak terbatas + 100 kredit cloud | 6 halaman dengan fitur AI penuh |
| Ekstraksi bertenaga AI | Terbatas (Smart Extract memakai kredit) | AI Suggest Fields penuh sudah termasuk |
| Tujuan ekspor | CSV, JSON | Excel, Google Sheets, Airtable, Notion — semuanya gratis |
| Konfigurasi tersimpan | 3 recipe | Template tersedia |
| Scraping subhalaman | Setup recipe manual | Sudah termasuk dalam hitungan halaman |
Modelnya memang berbeda. Simplescraper memberi Anda scraping lokal tak terbatas dengan cloud yang terbatas. Thunderbit memberi Anda lebih sedikit halaman, tetapi membekali setiap halaman dengan kemampuan AI penuh, plus ekspor gratis ke alat yang benar-benar dipakai kebanyakan tim. Paket gratis Simplescraper cocok jika Anda butuh scraping lokal dasar dan tidak keberatan kerja manual. Tapi kalau Anda ingin ekstraksi bertenaga AI dengan ekspor yang fleksibel, paket gratis Thunderbit lebih bertenaga per halaman.
Praktik Terbaik 4: Cara Menghindari Blokir Saat Scraping
Tidak ada yang memikirkan perlindungan anti-bot sampai mereka menatap dinding CAPTCHA atau dataset kosong. Saat itu, waktu dan mungkin kredit sudah terlanjur habis.
Pencegahan proaktif selalu lebih murah daripada troubleshooting reaktif.
Atur Rate Limit dan Ritme Permintaan Anda
Alasan nomor satu kenapa diblokir: menghajar situs dengan permintaan yang terlalu cepat. Bagi server web, 50 permintaan dalam 10 detik dari satu IP terlihat seperti serangan, bukan seperti peneliti yang penasaran.
Aturan praktis umum:
- Tambahkan jeda 2-5 detik antar permintaan halaman untuk kebanyakan situs komersial.
- Untuk target sensitif (marketplace, situs ulasan), perlambat lagi — 5-10 detik.
- Jika Anda menggunakan API Simplescraper, parameter
waitForSelectordapat membantu memastikan halaman benar-benar selesai dimuat sebelum ekstraksi, yang juga secara alami memperlambat ritme Anda.
Kapan Mengaktifkan Rotasi Proxy
Rotasi proxy mengubah alamat IP Anda di antara permintaan, sehingga Anda terlihat seperti beberapa pengguna berbeda. Anda akan membutuhkannya untuk:
- Amazon, Yelp, TripAdvisor, LinkedIn (sistem anti-bot yang agresif)
- Situs apa pun yang menerapkan rate limit per IP
- Pekerjaan batch besar (ratusan halaman dari satu domain)
Platform Simplescraper mendukung mode proxy termasuk opsi standard, premium, dan residential. Namun, ketersediaan yang tepat di level paket tidak selalu benar-benar jelas dari dokumentasi publik — verifikasi dulu sebelum menganggap paket gratis mencakup target yang sulit. Proxy residential biasanya lebih mahal, tetapi lebih kecil kemungkinannya untuk ditandai.
Menangani Situs yang Banyak Memakai JavaScript
Situs modern yang dibuat dengan React, Vue, atau Angular merender konten setelah halaman awal selesai dimuat. Jika scraper bertindak sebelum JavaScript selesai berjalan, Anda akan mendapat field kosong.
Strategi:
- Gunakan mode cloud scraping untuk rendering yang lebih baik (cloud Simplescraper bisa menjalankan JavaScript).
- Scroll manual halaman sebelum menjalankan browser scrape untuk memicu konten yang dimuat malas.
- Gunakan
waitForSelectordalam alur kerja berbasis API untuk menjeda sampai elemen target muncul. - Terima kenyataan bahwa beberapa aplikasi single-page yang sangat dinamis memang mungkin berada di luar kemampuan visual scraper untuk ditangani secara andal.
Alternatif Tanpa Repot
Cloud scraping Thunderbit menangani proteksi anti-bot, CAPTCHA, dan rendering JavaScript secara otomatis — tanpa konfigurasi proxy, tanpa penyesuaian delay, tanpa scroll manual. Bagi pengguna yang tidak ingin jadi insinyur DevOps amatir hanya untuk melakukan scrape katalog produk, itu penting. Masalahnya tidak hilang — hanya berpindah ke tanggung jawab orang lain.
Praktik Terbaik 5: Tahu Kapan Simplescraper Sudah Mencapai Batasnya
Saya berharap seseorang menulis bagian ini untuk saya dua tahun lalu.
Ada titik ketika sebuah alat berhenti menjadi penghemat waktu dan mulai menjadi penguras waktu. Mengenali ambang itu lebih awal akan menyelamatkan Anda dari jebakan sunk cost berupa "saya sudah membuat 15 recipe, sekarang tidak bisa pindah."
Batas Praktis Simplescraper
- Aplikasi single-page dinamis yang memuat konten via AJAX tanpa navigasi halaman tradisional
- Infinite scroll yang membutuhkan scroll terus-menerus untuk memuat semua item (bukan paginasi berbasis klik standar)
- Pengayaan subhalaman: scraping halaman listing lalu mengunjungi setiap halaman detail untuk data tambahan. Simplescraper bisa melakukannya dengan batch workflows, tetapi kompleksitas setup-nya cepat meningkat.
- Perubahan tata letak yang merusak recipe yang sudah ada. Saat situs memperbarui struktur HTML-nya, selector CSS yang sudah Anda sesuaikan dengan cermat bisa berhenti bekerja.
Tanda-Tanda Anda Sudah Melewati Kapasitas Alat Ini
Kemungkinan Anda sudah mencapai batas ketika:
- Anda harus mengutak-atik selector CSS secara manual pada setiap scrape karena deteksi otomatis terus gagal
- Recipe rusak setelah pembaruan situs dan harus dibangun ulang
- Anda perlu melakukan scrape puluhan atau ratusan halaman sekaligus tetapi terus mentok pada batas kredit atau kecepatan
- Data subhalaman membutuhkan rantai recipe multi-langkah yang kompleks
- Anda menghabiskan lebih banyak waktu merawat scrape daripada benar-benar memakai data yang diekstrak
Yang terakhir itu adalah sinyal paling jelas. Saat perawatan menjadi pekerjaan utama, dividen kenyamanan no-code sudah hilang.
Beralih ke Workflow Bertenaga AI
Di sinilah saya akan membahas apa yang tim saya bangun dengan Thunderbit, karena alat ini dirancang khusus untuk mode kegagalan yang dijelaskan di atas:

- AI membaca setiap halaman dari awal setiap kali — tidak ada recipe rapuh atau selector CSS yang perlu dirawat. Kalau tata letak situs berubah, AI menyesuaikan pada saat run berikutnya.
- Scraping subhalaman memperkaya tabel data Anda hanya dengan satu klik. Scrap halaman listing, lalu otomatis kunjungi setiap halaman detail untuk field tambahan.
- Scraping terjadwal menggunakan bahasa alami ("setiap Senin pukul 9 pagi") alih-alih mengonfigurasi preset waktu.
- Cloud scraping pada 50 halaman sekaligus untuk kecepatan di situs publik.
- Ekspor gratis bawaan ke Google Sheets, Airtable, Notion, dan Excel tanpa konfigurasi webhook.
Simplescraper vs. Thunderbit: Perbandingan Berdampingan
Berikut semuanya dalam satu tempat:

| Kemampuan | Simplescraper | Thunderbit |
|---|---|---|
| Penyiapan field | Selector CSS manual / pemilihan visual | AI Suggest Fields (bahasa Inggris biasa) |
| Pengayaan subhalaman | Bisa lewat batch workflows (setup rumit) | Auto-enrich 1 klik |
| Adaptasi otomatis ke perubahan tata letak | Rusak (perlu perbaikan manual) | AI membaca ulang struktur halaman setiap kali |
| Konkruensi halaman cloud | Batch hingga 5.000 URL (bervariasi حسب paket) | 50 halaman sekaligus |
| Ekspor ke Notion/Airtable | Via webhook (tier berbayar) | Bawaan, gratis |
| Penjadwalan | Preset + kontrol waktu kustom | Deskripsi bahasa alami |
| Penanganan anti-bot / CAPTCHA | Mode proxy tersedia (tergantung paket) | Otomatis, tanpa konfigurasi |
| Paket gratis | 100 kredit cloud + browser tak terbatas + 3 recipe | 6 halaman dengan fitur AI penuh + ekspor gratis |
Singkatnya: Simplescraper unggul untuk ekstraksi sederhana, visual, dan minim setup, di mana penyetelan manual sesekali masih bisa diterima. Thunderbit mengambil alih saat model itu mulai runtuh — menangani interpretasi halaman, adaptasi tata letak, dan kompleksitas alur kerja sehingga Anda tidak perlu melakukannya sendiri.
Tidak ada alat yang secara universal lebih baik. Keduanya berada di titik yang berbeda pada kurva kompleksitas — dan itu wajar.
Ringkasan Cepat: Checklist Praktik Terbaik Simplescraper
Simpan ini untuk sesi scraping Anda berikutnya:
- Selalu uji pada sampel kecil terlebih dahulu. Pastikan jumlah baris dan kelengkapan field di 2-3 halaman sebelum memperbesar skala.
- Scroll halaman sebelum scraping untuk memicu konten yang dimuat malas.
- Gunakan "Include Similar" ketika deteksi daftar terasa terlalu sempit.
- Pilih mode scraping secara sengaja. Browser untuk situs yang butuh login; cloud untuk halaman publik dan pekerjaan terjadwal.
- Atur jeda antar permintaan — minimal 2-5 detik untuk situs komersial, lebih lama untuk target dengan anti-bot kuat.
- Pahami matematika paket gratis Anda. 100 kredit cloud = 50 halaman yang mendukung JavaScript. Rencanakan sesuai itu.
- Simpan recipe hanya untuk halaman yang stabil. Jika situs sering diperbarui, recipe akan rusak.
- Pelajari selector CSS dasar sebagai cadangan. Class name dan data attribute lebih baik daripada selector berbasis posisi.
- Pantau blokir secara proaktif. Jika Anda mendapat hasil kosong atau CAPTCHA, perlambat atau ganti mode.
- Sadar kapan sudah mencapai batas. Saat waktu pemeliharaan melebihi waktu penggunaan data, evaluasi alternatif.
Kesimpulan: Jadikan Setiap Scrape Bernilai
Pelajaran besar dari lebih dari seribu scrape bukan tentang satu alat tertentu. Intinya adalah pendekatan lebih penting daripada software. Memahami kenapa scrape gagal — lazy loading, mode yang salah, anti-bot yang agresif, selector yang rapuh — jauh lebih berharga daripada daftar fitur apa pun.
Simplescraper memang bekerja sangat baik untuk pekerjaan ekstraksi yang sederhana dan jelas. Jika halaman Anda rapi, kebutuhan Anda tidak terlalu besar, dan Anda tidak keberatan sesekali melakukan penyetelan manual — alat ini akan mengantar Anda sampai tujuan.
Namun, jika Anda merasa lebih sering melawan alatnya daripada memakainya — debugging selector, membangun ulang recipe yang rusak, mengonfigurasi proxy, scroll halaman manual — itu bukan kegagalan pribadi. Itu sinyal bahwa Anda sudah melampaui apa yang bisa ditangani oleh visual scraping saja.
Kalau ini terdengar familiar, coba paket gratis Thunderbit — enam halaman dengan fitur AI penuh, ekspor gratis ke Sheets, Airtable, dan Notion. Bandingkan dengan alur kerja Anda saat ini dan lihat mana yang paling cocok. Terkadang praktik terbaik justru adalah tahu kapan harus memakai alat yang berbeda sama sekali.
FAQ
Apakah Simplescraper gratis untuk digunakan?
Ya, Simplescraper punya paket gratis yang mencakup browser scraping lokal tak terbatas, 100 kredit cloud per bulan, 3 recipe tersimpan, dan ekspor CSV/JSON. Halaman cloud yang mendukung JavaScript menghabiskan 2 kredit per halaman, jadi 100 kredit itu mencakup sekitar 50 halaman dalam mode cloud. Paket berbayar mulai dari $39/bulan (Plus) untuk 6.000 kredit dan $70/bulan (Pro) untuk 15.000 kredit.
Apakah Simplescraper bisa menangani situs web yang banyak memakai JavaScript?
Kadang bisa. Mode cloud Simplescraper dapat merender JavaScript, dan alat ini mengiklankan dukungan untuk aplikasi single-page. Namun, SPA yang kompleks dengan rendering dinamis berat, infinite scroll, atau sistem anti-bot yang agresif masih bisa menghasilkan hasil yang tidak lengkap. Menggunakan mode cloud dengan waktu tunggu yang sesuai meningkatkan keandalan, tetapi situs yang sangat dinamis tetap menjadi tantangan bagi visual scraper mana pun.
Apa perbedaan antara cloud scraping dan browser scraping di Simplescraper?
Browser scraping berjalan lokal di browser Chrome Anda — memakai sesi aktif Anda (bagus untuk situs yang butuh login), tidak menghabiskan kredit, tetapi mengharuskan komputer tetap menyala. Cloud scraping berjalan di server Simplescraper — lebih cepat, tanpa pengawasan, mendukung penjadwalan dan integrasi, tetapi menghabiskan kredit per halaman dan tidak bisa mengakses halaman di balik login pribadi Anda.
Kapan saya harus beralih dari Simplescraper ke alternatif seperti Thunderbit?
Sinyal paling jelas adalah ketika waktu pemeliharaan melebihi waktu penggunaan data. Jika Anda rutin memperbaiki selector yang rusak setelah pembaruan situs, mengonfigurasi proxy secara manual, membangun ulang recipe, atau menghabiskan lebih banyak waktu untuk troubleshooting daripada menganalisis data hasil ekstraksi, berarti Anda sudah melampaui kapasitas yang bisa disediakan scraping visual manual secara efisien. Alat seperti Thunderbit yang memakai AI untuk menginterpretasi struktur halaman setiap kali dijalankan menghilangkan sebagian besar beban pemeliharaan itu.
Bagaimana cara menghindari blokir saat scraping dengan Simplescraper?
Tiga praktik utama: Pertama, atur ritme permintaan dengan jeda 2-5 detik antar halaman (lebih lama untuk situs dengan anti-bot kuat seperti Amazon atau Yelp). Kedua, gunakan mode browser sebagai fallback untuk situs yang agresif memblokir IP cloud — sesi browser Anda terlihat lebih seperti trafik normal. Ketiga, aktifkan rotasi proxy untuk pekerjaan batch besar pada target sensitif, meski pastikan dulu opsi proxy apa saja yang termasuk dalam paket Anda sebelum mengandalkannya.
Pelajari Lebih Lanjut




