
אגלה לך סוד קטן: האינטרנט הוא בעצם הספרייה הכי גדולה בעולם—רק שברוב המקרים הספרים שם “מודבקים” ולא באמת נפתחים. כמעט כל יום אני מדבר עם בעלי עסקים, אנשי 마케팅 וצוותי 세일즈 שיודעים שיש זהב בדפי אינטרנט—מפרטי מוצרים, מחירי מתחרים, ביקורות לקוחות, פרטי קשר—אבל כשמגיע הרגע של חילוץ טקסט מאתר? פה מתחיל הבלגן. אני חי שנים בעולם ה‑SaaS והאוטומציה, וראיתי כל “מרתון העתק‑הדבק” וכל “הרפתקת פייתון ביתית” שאפשר לדמיין. החדשות הטובות: היום הרבה יותר קל (והרבה פחות כואב) לחלץ טקסט מאתר, בזכות כלים חדשים של AI Web Scraper ותוספי דפדפן חכמים.
במדריך הזה אעבור איתך על כל שיטה פרקטית שאני מכיר—מהעתקה והדבקה בסיסית ועד פתרונות מתקדמים מבוססי AI כמו Thunderbit (כן, זה מוצר של הצוות שלי, אבל אני אהיה הוגן לגבי היתרונות והחסרונות). בין אם אתה אשף גיליונות, מפתח שאוהב קוד, או פשוט מישהו שנמאס לו לבהות בדפי אינטרנט—תמצא כאן תהליך מסודר שמתאים לצורך שלך. בוא נפתח את “הספרים הדיגיטליים” האלה ונוציא את הטקסט שאתה צריך.
מה זה אומר לחלץ טקסט מאתר אינטרנט?
כשאנחנו אומרים “לחלץ טקסט מאתר”, הכוונה היא לקחת את המידע שמופיע (ולפעמים גם לא מופיע מיד) בדף אינטרנט ולהעביר אותו לפורמט שאפשר לעבוד איתו—כמו גיליון אלקטרוני, מסד נתונים, או אפילו מסמך Word נקי. אבל לא כל טקסט באתר נולד שווה:
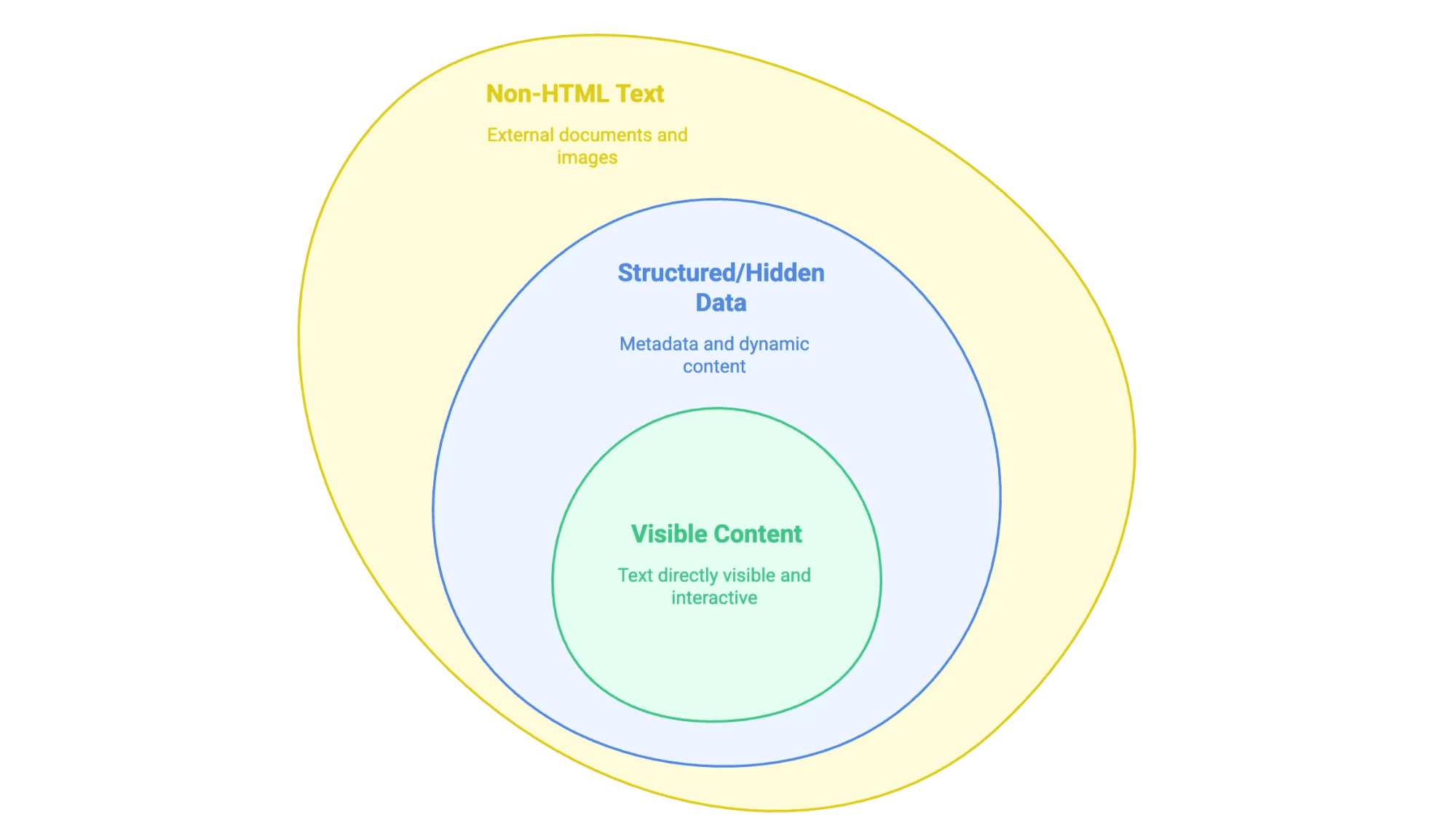
- תוכן גלוי: כל מה שאפשר לסמן עם העכבר—טקסט גוף, כותרות, רשימות, טבלאות, תיאורי מוצרים, פוסטים בבלוג ועוד.
- נתונים מובנים או “מוסתרים”: למשל מטא‑דאטה בתוך תגיות
<meta>, סקריפטים מסוג JSON‑LD, או מידע שנטען עם JavaScript ומופיע רק אחרי קליק/גלילה. - טקסט שאינו HTML: קבצי PDF, מסמכי Word, ואפילו תמונות עם טקסט (כמו חוזים סרוקים או אינפוגרפיקות) שמקושרים או מוטמעים באתר.
החוכמה היא להבין איזה סוג מידע אתה מחפש—כי לכל סוג מתאימה שיטת חילוץ אחרת.
למה בכלל לחלץ טקסט מאתר? יתרונות עסקיים ושימושים נפוצים
בוא נדבר דוגרי: אף אחד לא מחלץ טקסט מאתרים “בשביל הכיף” (אלא אם זה תחביב ממש מוזר). עסקים עושים את זה כי ה‑ROI ברור. שוק תוכנות ה‑web scraping עבר את מיליארד הדולר ב‑2024, והוא רק ממשיך לצמוח. הנה למה:
| צוות | דוגמה לשימוש | תועלת |
|---|---|---|
| מכירות | איסוף לידים ופרטי קשר ממדריכים | איתור לקוחות פוטנציאליים מהר יותר ועם יותר מידע |
| שיווק | חילוץ פוסטים של מתחרים ונתוני SEO | ניתוח פערי תוכן וזיהוי טרנדים |
| תפעול | מעקב מחירים באתרי מסחר אלקטרוני | תמחור דינמי ומעקב מלאי |
| נדל"ן | איגום מודעות ופרטי נכסים | ניתוח שוק ויצירת לידים |
| תמיכה | איסוף ביקורות לקוחות ושאלות‑תשובות בפורומים | ניתוח סנטימנט וזיהוי מוקדם של בעיות |
כמה דוגמאות מהשטח:

- יצירת לידים: עסק לציוד מסעדות בנה רשימות לקוחות פוטנציאליים תוך דקות במקום ימים.
- מעקב מתחרים: קמעונאים כמו John Lewis הגדילו מכירות ב‑4% בעזרת נתוני מחירים שנאספו.
- ניתוח SEO: צוותים מחלצים תגיות מטא ומילות מפתח כדי לחדד אסטרטגיה.
ובזכות כלים מונעי AI, חברות חוסכות 30%–40% מזמן איסוף הנתונים לעומת שיטות “הדור הישן”.
שיטות ידניות: הבסיס של העתקה והדבקה מטקסט באתר
נתחיל מהכי פשוט. לפעמים צריך רק קטע קצר—בלי כלים מיוחדים.
איך לחלץ טקסט ידנית
- העתק‑הדבק: פתח את הדף, סמן את הטקסט ולחץ Ctrl+C (או קליק ימני > Copy). אחר כך הדבק למסמך או לגיליון.
- שמירת הדף כקובץ: בדפדפן עבור ל‑File > Save Page As. שמור כ‑“Webpage, HTML only” כדי לקבל HTML גולמי, או לפעמים כ‑.txt כדי לקבל רק טקסט.
- הדפסה ל‑PDF: השתמש בחלון ההדפסה של הדפדפן ובחר “Save as PDF”. לאחר מכן פתח את ה‑PDF והעתק את הטקסט (או השתמש באפשרות “Save as Text” בקורא PDF).
- כלי מפתחים (DevTools): קליק ימני > Inspect או F12. אפשר לראות את מקור ה‑HTML, לאתר תגיות מטא או JSON מוסתר ולהעתיק את מה שצריך.
מגבלות
חילוץ ידני מתאים לפעם‑פעמיים, אבל לכל דבר מעבר לזה הוא סיוט. זה גוזל זמן, מועד לטעויות, ופשוט לא סקיילבילי. ראיתי מתמחים יושבים ימים ומעתיקים טבלאות שורה‑שורה—אף אחד לא רוצה את התפקיד הזה.
שימוש בתוספי דפדפן וכלים אונליין לחילוץ טקסט מאתרים
רוצה להשתדרג? תוספי דפדפן וכלים אונליין הם נקודת האיזון לרוב המשתמשים העסקיים: בלי קוד, בלי כאב ראש—רק לבחור וללחוץ.
למה להשתמש בכלים כאלה?

- מהיר יותר מהעתקה ידנית
- לא דורש ידע בתכנות
- יודע להתמודד עם טבלאות, רשימות ולעיתים גם קבצים
- ייצוא ל‑Excel, Google Sheets, CSV ועוד
בוא נעבור על האפשרויות הפופולריות.
Thunderbit: AI Web Scraper לחילוץ טקסט מהיר ומדויק
כן, יש לי כאן הטיה—אבל Thunderbit באמת נבנה כדי להפוך חילוץ טקסט מהאינטרנט לפשוט כמו להזמין 배달. כך זה עובד:
שלב‑אחר‑שלב: חילוץ טקסט עם Thunderbit
- התקן את תוסף Chrome: הורד את Thunderbit מחנות התוספים של Chrome.
- פתח את האתר: היכנס לדף שממנו תרצה לחלץ טקסט.
- לחץ על “AI Suggest Fields”: ה‑AI של Thunderbit סורק את הדף ומציע אילו שדות (עמודות) כדאי לחלץ—למשל שם מוצר, מחיר, תיאור ועוד.
- בדיקה והתאמה: אפשר לערוך את ההצעות או להוסיף שדות משלך.
- לחץ על “Scrape”: Thunderbit אוסף את הנתונים—כולל מתתי‑דפים או רשימות עם עמודים מרובים (pagination) אם צריך.
- ייצוא: הורד ל‑Excel, Google Sheets, Airtable, Notion או כ‑CSV/JSON. אין תשלום נוסף על ייצוא.
מה מייחד את Thunderbit?
- הצעת שדות בעזרת AI: אין צורך להתעסק עם selectors או קוד—ה‑AI מזהה מה חשוב בדף.
- תמיכה בתתי‑דפים וב‑Pagination: צריך פרטים מכל דף מוצר בקטגוריה? Thunderbit יכול לעבור ביניהם אוטומטית.
- חילוץ מ‑PDF, תמונות ומסמכים: יש מדריך PDF או תמונת מפרט? ה‑OCR המובנה של Thunderbit יודע להוציא גם משם טקסט.
- תמיכה רב‑לשונית: עובד ב‑34 שפות (קלינגונית עדיין לא, אבל מי יודע).
- ייצוא נתונים בחינם: אין “חומת תשלום” כדי להוציא את הנתונים.
- שימושים נפוצים: תיאורי מוצרים, פרטי קשר, תוכן בלוג, רשימות לידים—מה שתרצה.
איך לבצע Scrape למוצרים וביקורות באמזון ב‑2025 בעזרת AI Get Started Free
רוצה לראות את זה בפעולה? כנס ל‑Thunderbit Blog למדריכים כמו How to Scrape Amazon Products and Reviews in 2025 using AI.
תוספי דפדפן וכלים אונליין נוספים
כדאי להכיר גם כמה כלים נוספים שאולי תפגוש:
- Web Scraper (webscraper.io): חינמי ובשיטת point‑and‑click, אבל דורש זמן לימוד. מתאים לאנליסטים טכניים—צריך להגדיר “sitemaps” ו‑selectors. תומך ב‑pagination, אבל לא ב‑PDF או תמונות. עוד פרטים כאן.
- CopyTables: פשוט מאוד—מעתיק טבלאות HTML ללוח ההעתקה או ל‑Excel. מעולה לשליפה מהירה של טבלה חד‑פעמית, אבל עובד דף‑דף ורק על טבלאות. כאן רואים איך זה עובד.
- ScraperAPI (ScraperAPI Pricing): מיועד למפתחים. שולחים URL ומקבלים HTML (כולל טיפול בפרוקסים וחסימות), אבל עדיין צריך לפרסר את הטקסט לבד. קרא עוד.
מתי לבחור איזה כלי?
- Thunderbit: כשחשוב לך מהירות, עזרה של AI ותמיכה בפורמטים שונים (כולל PDF/תמונות).
- Web Scraper: כשנוח לך “לשחק” עם הגדרות ואתה רוצה יותר שליטה.
- CopyTables: כשצריך רק טבלה—ומהר.
- ScraperAPI: כשאתה בונה scraper משלך בקוד.
Web scraping אוטומטי: פתרונות תכנות לחילוץ טקסט מאתרים
אם אתה מפתח (או יש לך אחד בהישג יד), כתיבת scraper משלך נותנת שליטה מלאה. זה התהליך הבסיסי:
- שליחת בקשת HTTP: שימוש ב‑
requestsשל Python או דומה כדי להביא את הדף. - פענוח HTML: שימוש ב‑
BeautifulSoup,lxmlאוScrapyכדי לאתר את הטקסט הרצוי. - חילוץ וייצוא: שליפת הטקסט, ניקוי ושמירה ל‑CSV, JSON או מסד נתונים.
דוגמה: Python + Beautiful Soup
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
for qt in quotes:
print(qt)
יתרונות וחסרונות
- יתרונות: גמישות מקסימלית, אפשר להתמודד עם כל אתר/סוג נתונים, אינטגרציה למערכות שלך.
- חסרונות: דורש ידע בתכנות, תחזוקה שוטפת, והתמודדות עם מנגנוני אנטי‑בוט.
מתי זה מתאים
- צריך לחלץ אלפי (או מיליוני) דפים.
- האתר מורכב (התחברות, טפסים מרובי שלבים).
- רוצים לשלב scraping ישירות באפליקציה או בתהליך עבודה.
חילוץ טקסט מפורמטים שאינם HTML: PDF, מסמכי Word ותמונות
אתרים הם לא רק HTML—יש בהם PDF, מסמכי Word ותמונות עם טקסט חשוב. כך ניגשים לזה:
- PDF מבוסס טקסט: השתמש בכלים כמו Adobe Acrobat, או בספריות כמו
PDFMinerאוPyPDF2כדי לחלץ טקסט. - PDF סרוק: השתמש ב‑OCR (זיהוי תווים אופטי) כמו Tesseract, Google Cloud Vision API או AWS Textract.
מסמכי Word/Excel
- Word: שימוש ב‑
python-docxלקריאת קבצי .docx. - Excel: שימוש ב‑
openpyxlאוpandasלקבצי .xlsx.
תמונות
- כלי OCR: Tesseract בקוד פתוח, או שירותי ענן לדיוק גבוה יותר. תמונות איכותיות (150–300 DPI) נותנות תוצאות טובות יותר.
הגישה של Thunderbit
ה‑“Image/Document Parser” מאפשר להעלות או לקשר ל‑PDF/תמונה/מסמך, וה‑AI מחלץ את הטקסט (ואפילו מציע עמודות אם הוא מזהה טבלה). אין צורך לקפוץ בין כלים—מתייחסים לקבצים כמו לכל דף אינטרנט.
השוואה בין כל השיטות: איזו פתרון חילוץ טקסט מתאים לך?
השוואה מהירה כדי לבחור נכון:
| שיטה | קלות שימוש | סקייל | רמת ידע טכני | סוגי נתונים נתמכים | הכי מתאים ל |
|---|---|---|---|---|---|
| ידני (העתק‑הדבק) | קל מאוד | נמוך | ללא | טקסט גלוי בלבד | משימות חד‑פעמיות וקטנות |
| תוספי דפדפן/כלים | קל–בינוני | בינוני | נמוך–בינוני | HTML וחלק מהטבלאות | משתמשים לא טכניים, משימות קטנות‑בינוניות |
| כלי AI (Thunderbit) | קל מאוד | גבוה | ללא | HTML, PDF, תמונות ועוד | משתמשים עסקיים, תוכן מעורב |
| תכנות (קוד) | קשה | גבוה מאוד | גבוה | כל סוג (עם הספריות הנכונות) | מפתחים, פרויקטים בקנה מידה גדול |
| חילוץ לא‑HTML (OCR) | בינוני | נמוך–בינוני | בינוני | PDF, תמונות, מסמכים | כשקבצים/תמונות הם העיקר |
אם אתה רוצה את המסלול המהיר, הגמיש והכי פחות מלחיץ—במיוחד לשימוש עסקי—כלי AI כמו Thunderbit הם בחירה מצוינת. אבל אם אתה צריך שליטה מלאה או עובד בקנה מידה עצום, ייתכן שעדיף לבנות פתרון בקוד.
נקודות מפתח: מתחילים לחלץ טקסט מאתרים כבר היום
- האינטרנט מלא בטקסט בעל ערך, אבל לא תמיד קל להגיע אליו.
- שיטות ידניות מתאימות למשימות קטנות מאוד, אבל לא מתרחבות.
- תוספי דפדפן ו‑AI Web Scraper כמו Thunderbit הופכים חילוץ טקסט למהיר, מדויק ונגיש לכולם—בלי קוד.
- לתוכן שאינו HTML (PDF, תמונות), חפש כלים עם OCR ופענוח מסמכים מובנים.
- בחר את השיטה לפי היכולות של הצוות, היקף הפרויקט וסוגי הנתונים שאתה צריך.
נסו את Thunderbit AI Web Scraper בחינם
חילוץ נעים—ושיהיו לך כמה שפחות ימים של Ctrl+C. עם הכלים הנכונים, איסוף נתונים מהאינטרנט יכול להפוך לתהליך חלק ואוטומטי שמפנה זמן לעבודה חשובה יותר. במקום שעות אינסופיות של העתקה והדבקה—פתרונות חכמים ויעילים במרחק קליק. הגיע הזמן לצאת מהטחינה הידנית ולאמץ דרך עבודה פרודוקטיבית יותר.
שאלות נפוצות
ש1: האם אפשר לבצע scraping מכל אתר?
ת1: לא תמיד. יש אתרים שחוסמים scrapers או שיש להם תנאי שימוש שאוסרים scraping. תמיד כדאי לבדוק את מדיניות האתר לפני שמתחילים.
ש2: עד כמה מדויקים Web Scrapers מבוססי AI?
ת2: כלים מבוססי AI כמו Thunderbit בדרך כלל מדויקים מאוד, אבל בדפים מורכבים או דינמיים במיוחד ייתכן שתידרש התאמה קלה.
ש3: האם צריך לדעת לתכנת כדי להשתמש בכלי web scraping?
ת3: לא. כלים כמו Thunderbit ותוספי דפדפן נוספים מיועדים גם למשתמשים לא טכניים ולא דורשים ידע בקוד.
ש4: אילו סוגי נתונים אפשר לחלץ מ‑PDF או מתמונות?
ת4: כלי OCR יכולים לחלץ טקסט, טבלאות ולעיתים גם מידע “מוסתר” מקבצי PDF סרוקים ומתמונות—מה שהופך את כלי חילוץ נתונים להרבה יותר גמיש.
לקריאה נוספת
- The definitive guide to text scraping
- How to Scrape Any Website Using AI
- Learn How to Use AI for Web Scraping
נסו AI Web Scraper Get Started Free




