Extracteur Tumblr
Approuvé par des professionnels dans des entreprises leaders












Débloquez les données Tumblr avec Thunderbit
Extrayez facilement des données Tumblr comme le contenu des posts et le nombre de mentions J’aime.
Obtenez toute l’histoire Tumblr
Les pages de liste Tumblr n’affichent que des extraits. Pour voir l’ensemble du contenu, vous avez besoin du texte complet des posts, des informations sur l’auteur et de toutes les données associées. Thunderbit visite automatiquement chaque sous-page liée, en extrait les détails et les ajoute sous forme de nouvelles colonnes, afin que vous puissiez récupérer facilement post_id, post_date et bien plus encore, sans clics manuels.
Automatisez la collecte de vos données Tumblr
Les données Tumblr évoluent en permanence. Extraire manuellement les mêmes blogs encore et encore est fastidieux. Avec la fonction d’extraction programmée de Thunderbit, vous pouvez mettre en place des tâches récurrentes en pilote automatique. Recevez des données fraîches comme like_count et post_content directement dans Google Sheets, sans lever le petit doigt.
Scrapez des posts Tumblr en deux clics
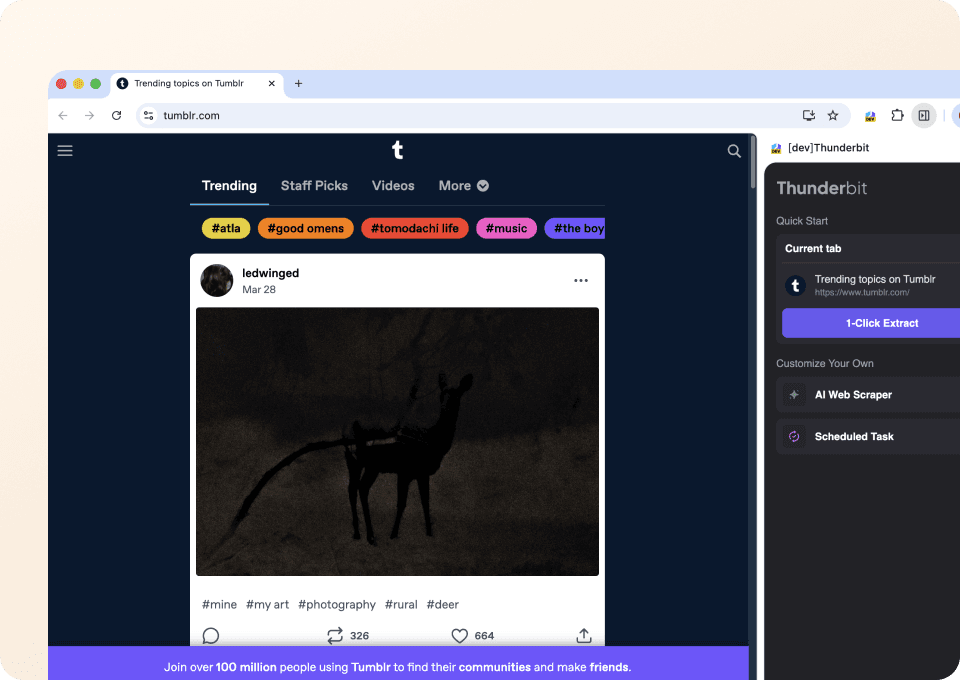
Oubliez le code complexe ou les sélecteurs CSS. Thunderbit vous permet d’extraire des données Tumblr en seulement deux clics. Il suffit de pointer les données souhaitées, et l’IA sémantique de Thunderbit détecte les champs pertinents (comme post_type et post_author), puis les extrait. Aucun code n’est nécessaire pour obtenir les données dont vous avez besoin sur Tumblr.
Pourquoi Thunderbit est-il différent des extracteurs Tumblr traditionnels ?
Extrayez les données Tumblr sans effort, même lorsque les mises en page changent ou évoluent de façon inattendue.
Extracteurs traditionnels
L’ancienne méthodeThunderbit IA
L’approche la plus intelligenteNe nous crois pas sur parole
Découvre ce que nos utilisateurs disent de Thunderbit.






Questions fréquentes
Associés cas d’usage
Explore d’autres cas d’usage de l’extracteur web Thunderbit.
Extracteur Tradera
L’Extracteur Tradera de Thunderbit vous permet de collecter facilement des données à partir des annonces et pages produits de Tradera. Grâce à la suggestion intelligente de champs par l’IA, récupérez noms de produits, prix, catégories, images et descriptions pour vos analyses ou la gestion de votre inventaire. Parfait pour les vendeurs e-commerce, collectionneurs et chercheurs souhaitant obtenir des données structurées depuis Tradera.
En savoir plus ->Extracteur Substack
Obtenez les nombres d’abonnés Substack, les titres d’articles et les descriptions de publication dans un tableau clair — sans code, l’IA se charge de la structuration.
En savoir plus ->Extracteur On the Beach
L’Extracteur On the Beach de Thunderbit vous permet d’extraire en quelques secondes les offres de vacances, les hôtels, les prix, les avis et bien plus encore depuis On the Beach. Profitez des suggestions intelligentes de champs pour collecter et organiser rapidement vos données de voyage, que ce soit pour l’analyse, la comparaison ou la planification. Parfait pour les professionnels du tourisme, les analystes et les organisateurs de séjours.
En savoir plus ->
Extracteur HKTVmall
Récupérez en quelques clics les noms de produits, les prix et même les notes clients depuis les annonces HKTVmall, sans aucune configuration complexe.
En savoir plus ->Extracteur DialIndia
L’Extracteur DialIndia de Thunderbit vous permet de collecter les données des profils d’entreprises et des annuaires de voyage de DialIndia grâce à des suggestions de champs intelligentes par IA. Rassemblez en quelques clics noms d’entreprises, coordonnées, adresses et descriptions pour vos besoins de recherche, de marketing ou de prospection.
En savoir plus ->
Extracteur Pages Blanches
L’Extracteur White Pages de Thunderbit vous permet de collecter rapidement des données issues des annuaires téléphoniques et professionnels White Pages, avec des suggestions de champs intelligentes grâce à l’IA. Rassemblez noms, numéros de téléphone, adresses et sites web pour vos besoins de prospection, de marketing ou de recherche en quelques clics.
En savoir plus ->Prêt à accélérer l’extraction de tes données ?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
L’essai gratuit inclut des crédits illimités pour 8 pages web.