Extracteur Substack

Plébiscité par des pros dans des entreprises de premier plan












Débloquez les données Substack avec Thunderbit
Envoyez les données Substack directement vers vos applications
Arrêtez de copier-coller manuellement les détails des publications Substack, comme le nom de l’auteur, le titre de l’article et le nombre d’abonnés. Avec Thunderbit, un seul clic envoie vos données extraites directement vers Google Sheets, Notion ou Airtable. Analysez les tendances des publications et les performances des contenus sans le travail manuel fastidieux.
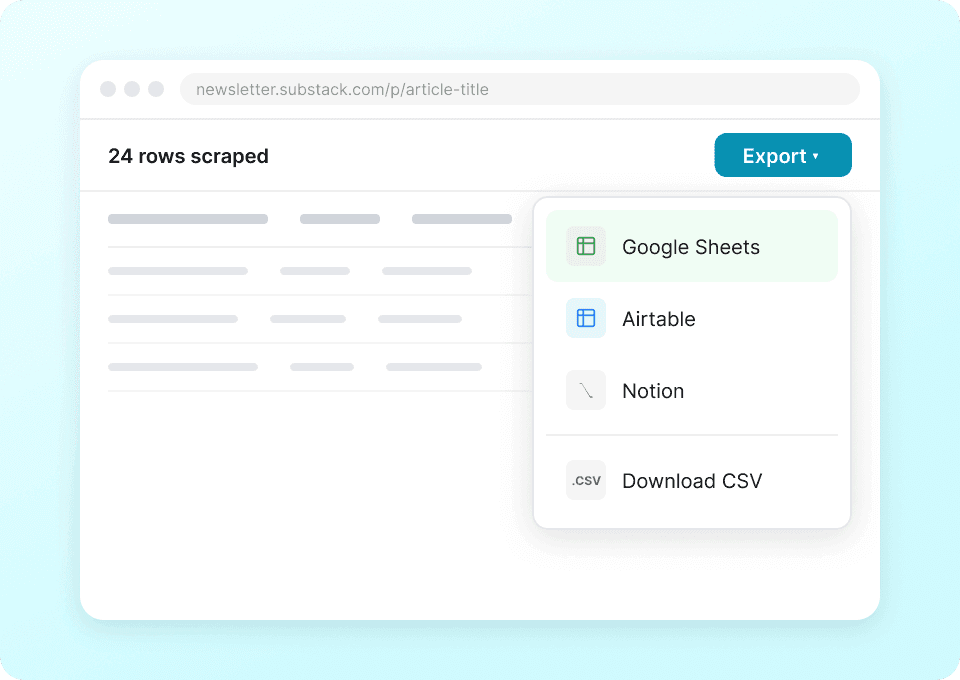
Un seul extracteur pour Substack et bien plus encore
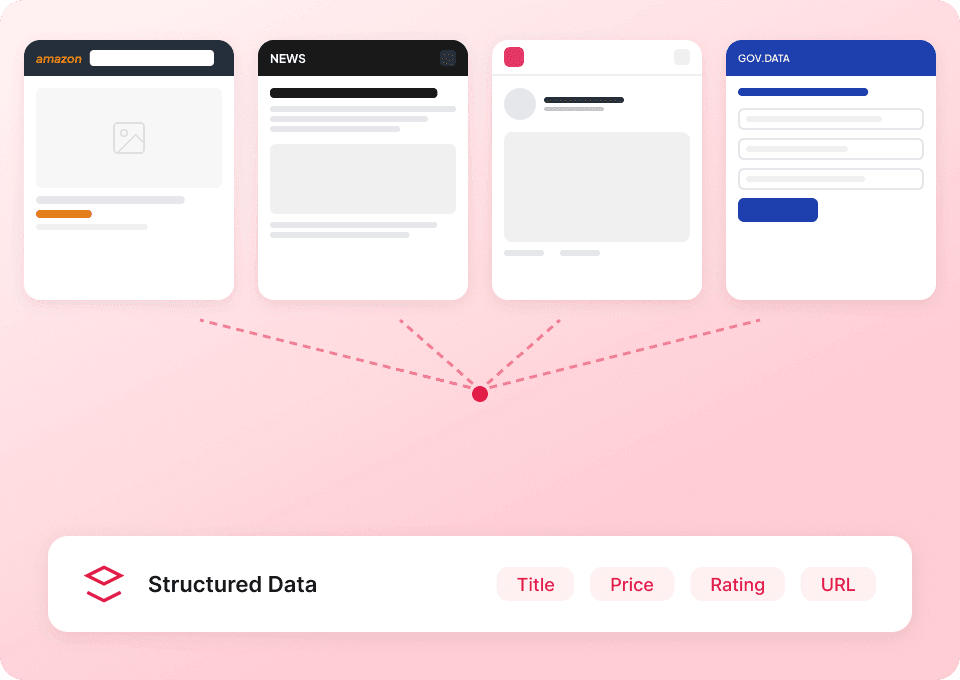
Inutile d’utiliser un extracteur différent pour chaque site web. Thunderbit fonctionne immédiatement avec Substack et inclut plus de 50 modèles prêts à l’emploi pour d’autres plateformes populaires. Extrayez les descriptions de publication, le contenu des articles et bien plus encore, puis utilisez le même outil pour collecter des données partout ailleurs.
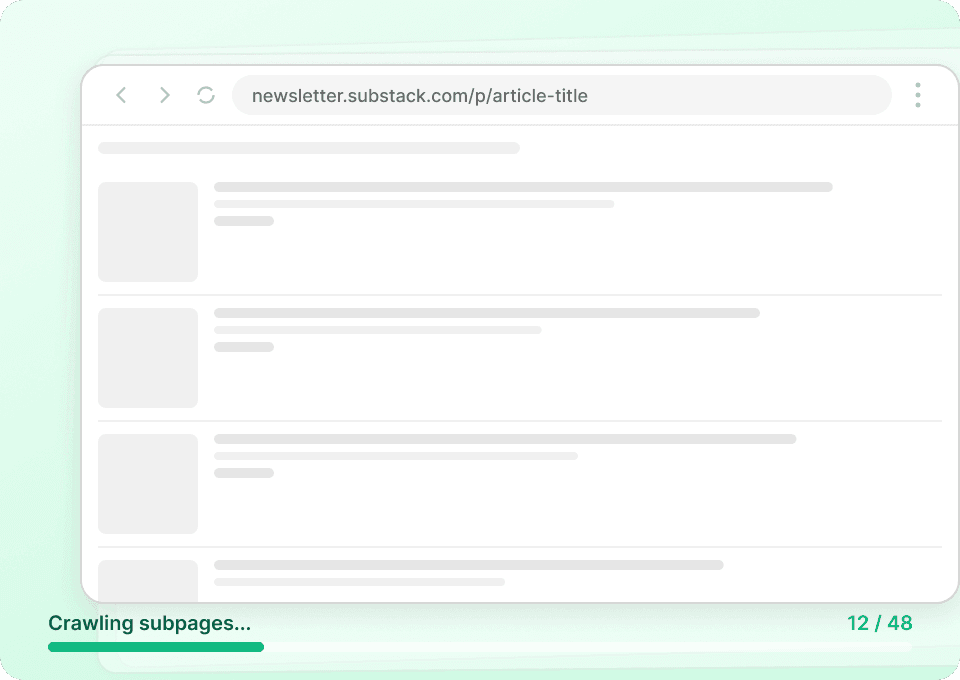
Obtenez l’histoire complète de Substack
Les pages de liste des publications Substack n’affichent que des résumés. Thunderbit visite automatiquement chaque sous-page d’article pour en extraire le contenu complet, vous offrant ainsi un jeu de données exhaustif. Récupérez en une seule fois le titre complet de l’article, le nom de l’auteur, le nom de la publication et le contenu de l’article.
Vous avez du mal à extraire efficacement Substack ?
Découvrez pourquoi Thunderbit surpasse les extracteurs traditionnels pour les données Substack.
Extracteurs traditionnels
L’ancienne façon de faireThunderbit
L’approche la plus intelligenteNe nous croyez pas sur parole
Découvre ce que nos utilisateurs disent de Thunderbit.






Questions fréquemment posées
Liés cas d’usage
Explore d’autres cas d’usage de l’extracteur web Thunderbit.

Extracteur United Airlines
Cliquez simplement pour collecter les données de vol United Airlines, comme le numéro de vol, l’heure d’arrivée et l’aéroport de départ — Thunderbit IA s’occupe du reste.
En savoir plus ->
Extracteur UNIQLO
Collectez en quelques clics les données produits UNIQLO, comme les noms, les prix et les tailles disponibles, grâce à l’extension Chrome de Thunderbit.
En savoir plus ->
Extracteur Amarillas.com
L’Extracteur Amarillas.com de Thunderbit vous permet d’extraire des données structurées depuis Amarillas.com, y compris les listes de motels et de restaurants. Grâce aux suggestions de champs alimentées par l’IA, récupérez rapidement les noms d’entreprises, adresses, numéros de contact, notes et avis pour vos besoins de recherche, de marketing ou de prospection.
En savoir plus ->
Extracteur UpCity
L’Extracteur UpCity de Thunderbit vous permet de récupérer les données des listes d’agences publicitaires et des avis de prestataires sur UpCity. Grâce aux suggestions de champs intelligentes par IA, collectez rapidement noms d’agences, localisations, évaluations, coordonnées et avis détaillés pour vos analyses ou recherches. Parfait pour les marketeurs, chercheurs et entrepreneurs souhaitant obtenir des données structurées d’UpCity.
En savoir plus ->Extracteur Tradera
L’Extracteur Tradera de Thunderbit vous permet de collecter facilement des données à partir des annonces et pages produits de Tradera. Grâce à la suggestion intelligente de champs par l’IA, récupérez noms de produits, prix, catégories, images et descriptions pour vos analyses ou la gestion de votre inventaire. Parfait pour les vendeurs e-commerce, collectionneurs et chercheurs souhaitant obtenir des données structurées depuis Tradera.
En savoir plus ->
Extracteur Rakuten Travel
L’Extracteur Rakuten Travel de Thunderbit vous permet de collecter facilement les données des listes et fiches d’hôtels sur Rakuten Travel. Grâce aux suggestions intelligentes de champs, récupérez rapidement noms d’hôtels, tarifs, évaluations, types de chambres et équipements pour vos recherches ou l’organisation de voyages. Parfait pour les agences de voyage, les chercheurs et les entreprises qui ont besoin de données structurées sur le secteur du tourisme.
En savoir plus ->Prêt à booster votre extraction de données ?
Rejoins plus de 100 000 professionnels qui utilisent déjà Thunderbit pour automatiser leurs workflows de web scraping.
L’essai gratuit offre des crédits illimités pour 8 pages web.