

Vous avez besoin, à l'instant même, du dernier prix affiché par un concurrent, d'une série de leads encore chauds ou de la publication qui déclenche toutes les conversations. Le souci : vos « données » datent de la semaine passée. Le temps de mettre la main sur l'information utile, le marché a déjà bougé. Miser sur des données mises en cache et vieillissantes revient à arriver à une vente flash quand les rayons sont déjà vides. C'est exactement ce que le web crawling en direct vient corriger : récupérer la donnée en temps réel, au moment où elle apparaît. Ce n'est plus un avantage annexe, mais ce qui fait la différence pour garder une longueur d'avance.
Après plusieurs années à construire des outils SaaS et d'automatisation, j'ai vu à quel point un crawler en direct peut changer le quotidien d'une équipe. Thunderbit réunit aujourd'hui plus de 100 000 utilisateurs à travers le monde, dont une large part travaille en temps réel plutôt que par lots. Avec Thunderbit, notre objectif était simple : rendre le crawling en direct assez accessible pour que n'importe qui, même sans expérience, capte les données web les plus fraîches en quelques clics. Ce guide explique ce qu'est réellement le crawling en direct, ce qui en fait un levier sérieux et comment vous lancer dès aujourd'hui, sans une ligne de code.
Un crawler en direct, qu'est-ce que c'est exactement ?
Partons de la définition. Un crawler en direct est un outil qui va chercher la donnée directement sur le site, en temps réel, à chaque exécution. Pensez à la différence entre un direct télévisé et une rediffusion. Beaucoup d'extracteurs web classiques reposent sur des téléchargements espacés ou des instantanés mis en cache, ce qui vous laisse systématiquement en retard d'un cran. Le crawler en direct, lui, ouvre la page à l'instant T, lit ce qu'elle contient et récupère l'information la plus récente au moment où elle surgit.
Certains parlent de « live crawler escort » ou de « live escort crawler », formulations qui évoquent davantage un agent de terrain au service de vos tableurs. L'idée reste la même : ces outils ne se contentent jamais de données périmées. Ils s'appuient sur l'automatisation de navigateur ou la navigation dans le cloud pour lire le contenu tel qu'un humain le verrait, éléments dynamiques compris : JavaScript, défilement infini, fenêtres surgissantes. Baisse de prix, publication qui décolle, nouveau contact à qualifier : vous travaillez toujours sur la donnée la plus fraîche disponible (dataprocorp.tech Pricing).
Deux approches à distinguer :
- Crawling statique : l'équivalent d'une photo prise chaque jour d'un site. Utile pour l'archivage, sans intérêt dès qu'il faut réagir à l'actualité.
- Crawling en direct : l'équivalent d'un flux vidéo continu. Ce que vous voyez correspond à ce qui se passe maintenant.
Sur des marchés qui bougent vite, l'écart pèse lourd. Même quelques heures de décalage se traduisent par des occasions ratées ou des décisions déjà dépassées (dataprocorp.tech Pricing).
Ce que le crawling en direct apporte concrètement aux entreprises
Pourquoi ce sujet compte-t-il autant pour les ventes, le marketing, les opérations et le reste ? Parce que la donnée en temps réel débouche sur de meilleures décisions. Le briefing 2024 du MIT CISR sur l'entreprise temps réel l'a chiffré : les sociétés du quartile supérieur en la matière affichaient 62 % de croissance du chiffre d'affaires en plus et 97 % de marge bénéficiaire en plus que celles du quartile inférieur, un écart tout sauf marginal (MIT CISR).
Voici les usages qui reviennent le plus souvent, fonction par fonction :
| Cas d’usage | Équipes/Fonction | Exemple d’avantages/données collectées |
|---|---|---|
| Surveillance des prix des concurrents | Ventes/e-commerce | Suivre les prix et promotions en temps réel pour une tarification dynamique (promptcloud.com Pricing) |
| Extraction de leads/contacts | Ventes/Marketing | Extraire des coordonnées récentes (nom, e-mail, téléphone) depuis des annuaires ou LinkedIn (Thunderbit Blog) |
| Analyse des réseaux sociaux et des tendances | Marketing/Produit | Surveiller les hashtags, sujets tendance et sentiments au fil de leur apparition (promptcloud.com Pricing) |
| Mise à jour des catalogues produits | E-commerce/Opérations | Garder les fiches à jour (prix, descriptions, stock) (datadwip.com Pricing) |
| Données de pipeline commercial | Ventes | Constituer automatiquement des listes de prospects en extrayant des annuaires d’entreprises (Thunderbit Blog) |
| Annonces immobilières | Immobilier | Regrouper les nouvelles annonces et les mises à jour de prix dès leur publication (promptcloud.com Pricing) |
Le fil rouge est toujours le même : une donnée plus rapide et plus juste nourrit des décisions plus rapides et meilleures. Les équipes cessent de deviner, repèrent les tendances dès leur émergence et agissent avant que la concurrence n'ait compris ce qui se jouait. Le crawling en direct transforme, à la volée, des pages web brutes en information exploitable (cisr.mit.edu).
Thunderbit : le crawling en direct sans barrière technique
Extrayez des données de n’importe quel site web avec l’IA Get Started Free
Vient l'objection classique : « Tout cela est bien beau, mais je ne suis pas développeur. Comment je fais concrètement ? » C'est précisément la question que nous avons voulu régler avec Thunderbit.
Thunderbit est une extension Chrome propulsée par l'IA qui rend le crawling en direct aussi simple que de commander à emporter, et souvent plus rapide. Ce qui le distingue :
- Aucun code : installez l'extension, ouvrez le site voulu, et laissez l'IA de Thunderbit s'occuper du reste.
- Champs suggérés par l'IA : un clic suffit, Thunderbit analyse la page et propose automatiquement les meilleures colonnes (« Nom », « Prix », « E-mail »…) (Thunderbit Blog).
- Crawling des sous-pages : l'information est cachée derrière des liens ? Thunderbit ouvre chaque sous-page (fiches produit, profils de contact…) et rassemble le tout dans un seul tableau.
- Modèles instantanés : pour les sites très fréquentés (Amazon, Zillow, LinkedIn…), des modèles prêts à l'emploi vous évitent toute configuration.
- 34 langues prises en charge : de quoi outiller sereinement les équipes internationales (Thunderbit Blog).
- Export gratuit : envoyez vos résultats vers Excel, Google Sheets, Airtable, Notion, CSV ou JSON, sans frais (Thunderbit Blog).
L'atout majeur reste le temps de prise en main : même en partant de zéro, vous êtes opérationnel en quelques minutes. Un utilisateur le résume ainsi : « Je n'ai qu'à cliquer sur deux boutons, et les données sont prêtes en un rien de temps. La précision est impressionnante » (trustpilot.com).
Thunderbit face aux outils traditionnels
Il existe évidemment d'autres façons d'extraire des données web en direct. Côté ingénierie, vous pouvez développer votre propre crawler avec Selenium, toujours activement maintenu (la version v4.4x est sortie en 2026), ou Beautiful Soup, ou vous tourner vers des options IA plus récentes : Browser Use pour piloter la navigation en langage naturel, Firecrawl pour une extraction URL-vers-Markdown compatible avec les LLM. Tout cela fonctionne, à condition d'être à l'aise avec le code, les protections anti-bot et les proxys. Si ce programme ne vous emballe pas, la suite est pour vous.
| Aspect | Outils traditionnels (Python/Selenium) | Crawler IA Thunderbit |
|---|---|---|
| Configuration et niveau requis | Code nécessaire, mise en place de l’environnement | Pas de code : installez et lancez (Thunderbit Blog) |
| Temps de configuration | De plusieurs heures à plusieurs jours | Quelques minutes |
| Fraîcheur des données | Instantanés, parfois périmés | En direct, à la seconde près (dataprocorp.tech Pricing) |
| Contenu dynamique | Difficile (nécessite du code supplémentaire) | Intégré, gère JavaScript et le défilement (Thunderbit Blog) |
| Adaptabilité | Casse si le site change | L’IA s’adapte automatiquement (dataprocorp.tech Pricing) |
| Maintenance | Élevée (correctifs fréquents) | Faible (l’IA gère la plupart des changements) (dataprocorp.tech Pricing) |
| Format de sortie | HTML brut, nettoyage manuel | Tableaux structurés, prêts à être exportés (Thunderbit Blog) |
| Intégrations | Code personnalisé requis | Export direct vers Sheets, Airtable, Notion, CSV, JSON (Thunderbit Blog) |
Le verdict tient en une phrase : sauf à vouloir vous découvrir une passion pour l'écriture de scripts de web scraping, Thunderbit reste le meilleur choix pour un utilisateur métier qui vise des résultats rapides et fiables.
Étape par étape : Thunderbit en tant que crawler en direct
Envie de voir le crawling en direct à l'œuvre ? Voici comment récupérer des données en temps réel sur n'importe quel site avec Thunderbit, sans jargon ni configuration pesante.
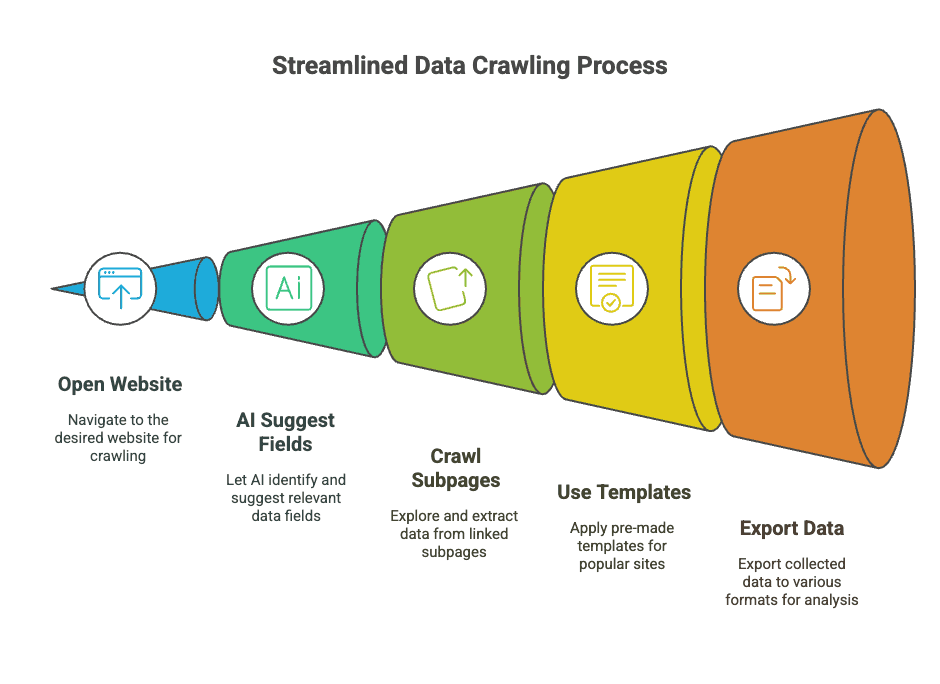
Étape 1 : installez Thunderbit et ouvrez le site cible
Commencez par ajouter l'extension Chrome Thunderbit à votre navigateur. Comptez une petite minute, sauf si votre Wi‑Fi tourne à l'énergie hamster. Une fois l'extension en place, ouvrez le site à crawler. Thunderbit fonctionne sur tout site que votre navigateur sait afficher : si vous parvenez à vous connecter et à le voir, Thunderbit aussi.
Essayez gratuitement le crawler en direct Thunderbit
Étape 2 : cartographiez les données avec les champs suggérés par l'IA
C'est ici que l'IA entre en scène. Cliquez sur Champs suggérés par l'IA dans Thunderbit. L'outil analyse la page et propose les meilleures colonnes à extraire : « Nom », « Prix », « Stock », « E-mail » ou tout autre champ pertinent (Thunderbit Blog).
Rien n'est figé : vous ajustez, renommez ou complétez ces champs à votre guise. Pour aller plus loin, ajoutez des instructions sur mesure pour chacun, du type « formater les numéros de téléphone en E.164 » ou « catégoriser les produits par type ».
Étape 3 : extrayez les données en direct en un clic
Une fois vos champs définis, cliquez sur Extraire. Thunderbit crawle alors la page en temps réel, en suivant la pagination ou le défilement infini si nécessaire. Si vous avez activé le crawling des sous-pages, l'outil ouvre chaque élément lié (détails de produit, profils…) et verse ces informations dans votre tableau (Thunderbit Blog).
Vous voyez les lignes se remplir en direct pendant que Thunderbit travaille, un peu comme du pop-corn qui éclate, en nettement plus utile.
Étape 4 : exportez vers Excel, Google Sheets ou Notion
Le crawl terminé, place à l'exploitation. Thunderbit vous laisse tout exporter, sans frais, vers Excel, Google Sheets, Airtable, Notion, CSV ou JSON (Thunderbit Blog). Choisissez le format, et vos données en direct sont prêtes pour l'analyse, le reporting ou le partage.
Quelques réglages pour aller plus loin
Vous voulez tirer davantage de Thunderbit ? Voici des conseils accumulés au fil du temps, parfois à mes dépens :
- Programmez vos crawls : le planificateur de Thunderbit déclenche les extractions automatiquement (par exemple « tous les lundis à 9 h »). Parfait pour la surveillance continue des prix ou le rafraîchissement des leads (Thunderbit Blog).
- Exploitez les sous-pages : quand les détails se nichent derrière des liens (les coordonnées d'un profil, par exemple), activez le crawling des sous-pages. Thunderbit visite chaque lien et fusionne les informations supplémentaires.
- Personnalisez les instructions de champ : pour les données complexes, ajoutez des consignes IA sur mesure, comme catégoriser des produits ou reformater le texte pendant l'extraction.
- Vérifiez les modèles instantanés : pour les sites populaires, regardez d'abord s'il existe un modèle en un clic avant de configurer les champs à la main.
- Ménagez les sites : n'extrayez pas plus vite que nécessaire. Une programmation et des délais raisonnables préservent les serveurs (scrapingapi.ai Pricing).
- Cloud ou navigateur : pour les sites publics, le mode Cloud avance très vite (jusqu'à 50 pages en parallèle). Pour les sites qui exigent une connexion, le mode Navigateur fait tourner Thunderbit dans votre propre session.
Rester dans les clous : sécurité et conformité
Une remarque courte mais essentielle : respectez toujours les conditions d'utilisation des sites et la vie privée. Avant de crawler, consultez le fichier robots.txt du site et ses conditions d'utilisation (scrapingapi.ai Pricing). Certains sites limitent l'accès automatisé ou la cadence de crawl. Thunderbit fournit des réglages pour espacer les requêtes et planifier les exécutions, mais l'usage responsable relève de vous.
- Respectez la vie privée et la loi : ne collectez que des données publiques et évitez de récupérer des informations personnelles sans consentement. Si vous extrayez des e-mails ou des numéros de téléphone, veillez à respecter le RGPD ou le CCPA (scrapingapi.ai Pricing).
- Jouez le jeu du web : réservez les données à des usages commerciaux légitimes et ne saturez pas les serveurs. La transparence et la conformité réduisent le risque juridique et profitent à tout le monde.
Franchir les obstacles les plus fréquents
Explorez le blog Thunderbit pour plus d’astuces Get Started Free
Le crawling en direct ne se déroule pas toujours sans accroc. Voici les difficultés qui reviennent, et la manière dont Thunderbit vous aide à les traiter :
- Mesures anti-bot : certains sites déploient des CAPTCHA ou bloquent des adresses IP. Thunderbit imite la navigation humaine (surtout en mode Navigateur) et gère les relances. Pour les CAPTCHA les plus tenaces, une résolution manuelle sera parfois nécessaire.
- JavaScript et pages dynamiques : là où les extracteurs classiques calent, Thunderbit tourne dans un vrai navigateur et prend donc en charge nativement scripts, AJAX et défilement infini.
- Refonte de mise en page : quand un site change de présentation, les extracteurs classiques cassent souvent. L'IA de Thunderbit s'adapte automatiquement à la plupart des changements ; un clic sur « Améliorer les champs avec l'IA » suffit au besoin (dataprocorp.tech Pricing).
- Qualité des données : Thunderbit nettoie et structure les données pendant l'extraction, mais vérifiez toujours un échantillon avant l'export.
- JavaScript lourd : sur les sites très complexes, alternez entre les modes Cloud et Navigateur, ou changez d'URL si c'est possible.
- CAPTCHA persistants : face à un site qui bloque agressivement les bots, envisagez une API officielle ou ralentissez votre rythme d'extraction.
La plupart de ces écueils pèsent bien moins lourd avec Thunderbit qu'avec des scripts codés à la main. Et en cas de blocage, le blog Thunderbit reste là pour vous fournir astuces et solutions.
Ce qu'il faut retenir
Récapitulons. Le web crawling en direct est la voie la plus courte vers des données à la seconde près. Aux ventes, au marketing, aux opérations, ou simple passionné de données comme moi : disposer de l'information la plus fraîche permet de décider mieux, de réduire les paris hasardeux et de creuser l'écart avec la concurrence.
Avec Thunderbit, nul besoin d'être développeur ou data scientist. N'importe qui configure un crawl en direct en quelques minutes, l'automatise et exporte les résultats vers ses outils habituels. Grâce à la détection de champs par l'IA, au crawling des sous-pages et aux modèles instantanés, vous passez moins de temps à manipuler la donnée et plus à en tirer parti.
Un dernier chiffre pour situer l'enjeu : le marché de l'analytique en temps réel pèse environ 1,1 milliard de dollars en 2025, et devrait atteindre 5,3 milliards de dollars en 2032, soit un TCAC de 25,1 %. Le crawling en direct n'est plus une promesse d'avenir, c'est désormais le point de départ. Thunderbit le met à la portée de tous, pour que vous cessiez d'attendre et commenciez à avancer.
Prêt à essayer ? Téléchargez Thunderbit, choisissez un site et mesurez la simplicité du crawling en direct. Pour approfondir, parcourez notre guide pour débutants ou explorez d'autres cas d'usage sur le blog Thunderbit.
Lire le guide pour débutants sur Thunderbit
Bon crawling, et que vos données soient toujours plus fraîches que votre café du matin.
Essayez maintenant le crawler web en direct IA Get Started Free
FAQ
1. Qu'est-ce qu'un crawler en direct et en quoi diffère-t-il des extracteurs web traditionnels ?
Un crawler en direct est un outil qui récupère des données en temps réel sur des sites web dès que vous les demandez. Contrairement aux extracteurs traditionnels, qui suivent un calendrier ou puisent dans des données mises en cache, les crawlers en direct livrent des informations à la seconde près. Ils intègrent souvent de l'IA pour identifier les champs pertinents et naviguer automatiquement dans les pages, ce qui les rend plus rapides et plus accessibles.
2. Pourquoi les données en temps réel sont-elles importantes pour les équipes commerciales et opérationnelles ?
Les données en temps réel aident les équipes à décider sur-le-champ dans des environnements qui évoluent vite. Qu'il s'agisse d'aligner ses prix sur ceux des concurrents, de réagir aux tendances sur les réseaux sociaux ou de suivre les variations de stock, disposer des dernières données permet de rester compétitif, d'éviter les retards et d'augmenter son chiffre d'affaires.
3. Comment l'IA améliore-t-elle le processus de crawling en direct ?
L'IA simplifie le crawling en direct en détectant automatiquement les champs pertinents, en s'adaptant aux changements de mise en page, en gérant la pagination et les sous-pages, et même en transformant les données (traduire du texte, convertir des devises…). Elle ouvre ainsi l'outil aux utilisateurs non techniques et réduit le besoin de configuration manuelle.
4. Quels sont quelques cas d'usage pratiques du crawling en direct ?
Les crawlers en direct servent à surveiller les prix sur les plateformes e-commerce, à extraire des commentaires depuis TikTok ou Twitter, à générer des leads commerciaux depuis LinkedIn, à recueillir des avis clients et à suivre les contenus des concurrents. Ces usages couvrent des secteurs aussi variés que le commerce de détail, l'immobilier, le marketing et la logistique.
5. Comment commencer avec un outil de crawler en direct comme Thunderbit ?
Pour démarrer, installez l'extension Chrome Thunderbit, rendez-vous sur une page web et servez-vous de la fonction « Champs suggérés par l'IA » pour sélectionner les données. Après un clic sur « Extraire », l'outil collecte les données et fournit une sortie structurée, exportable vers des tableurs ou intégrable à des outils comme Google Sheets ou Airtable, sans code requis.




