
Let me tell you a secret: I used to think web scraping was reserved for hackers in hoodies or data scientists with more monitors than sense. But these days, extracting data from a website is as common in business as grabbing your morning coffee—except, thankfully, it doesn’t require you to know Python or drink three espressos before noon. In fact, with the rise of AI web scraper tools, even folks who think “HTML” is a new sandwich at Subway can pull structured data from the wild web.
If you’ve ever found yourself copying and pasting rows of product info, sales leads, or price lists into a spreadsheet, you’re not alone. Nearly 73% of companies are now using web scraping for market insights and competitor tracking. And with the web scraping software market projected to hit $2.49 billion by 2032, it’s clear: web data extraction isn’t just for the tech elite anymore. So, whether you’re a sales pro, a marketer, or just someone who wants to stop doing data entry by hand, this guide is for you. I’ll walk you through the basics, compare traditional and AI-powered approaches, and show you how to get started—no hoodie required.
Web Scraper Basics: What Does It Mean to Scrape Data from a Website?
Let’s start simple. A web scraper is just a tool (or script, or Chrome extension) that automatically collects data from websites. Think of it as a super-speedy intern who never complains about repetitive tasks. Instead of you copying and pasting information row by row, a web scraper does it all in seconds, and it doesn’t even ask for a coffee break.
There are two main flavors of data you’ll encounter:
- Structured data: This is the neat, spreadsheet-ready stuff—think tables of product names, prices, or emails. It’s organized, labeled, and easy to analyze.
- Unstructured data: This is the wild west—blog posts, reviews, images, or anything that doesn’t fit neatly into rows and columns. Most web scraping projects aim to turn unstructured data into structured data, so you can actually use it.
If you’ve ever copied a table from a website into Excel, congratulations—you’ve done manual web scraping. Now imagine doing that for 10,000 pages. (Don’t actually do it. That’s what web scrapers are for.)
Why Scrape Data from Websites? Key Business Benefits
So, why bother scraping data in the first place? Here’s the short answer: businesses run on data, and the web is the world’s biggest database. Whether you’re in sales, marketing, ecommerce, or real estate, web data extraction can give you a serious edge.
Here are some of the most common business use cases:
| Use Case | Description | Example ROI/Benefit |
|---|---|---|
| Lead Generation | Collecting contact info, emails, or company lists from directories or social sites | Sales teams save hours and find more qualified leads |
| Price Monitoring | Tracking competitor prices, stock levels, or promotions in real time | Retailers adjust prices dynamically, boosting sales by 4% |
| Market Research | Aggregating reviews, news, or social sentiment to spot trends | Marketers tailor campaigns to real-time consumer insights |
| Competitor Analysis | Monitoring rival product catalogs, launches, or content | Businesses react faster to market changes |
| Real Estate Intelligence | Scraping property listings, prices, and availability | Agents and investors spot opportunities ahead of the market |
In fact, 25–30% of retailers in the UK and Europe use dynamic pricing strategies powered by competitor price-scraping. And companies like John Lewis and ASOS have seen measurable sales boosts by leveraging web data for smarter decisions.
Traditional Web Scraper Tools: How Do They Work?
Let’s rewind to the “classic” way of scraping data—before AI started flexing its muscles. Traditional web scrapers are usually scripts (often written in Python) or browser extensions that follow a set of rules to grab the data you want.
Here’s how the process usually goes:
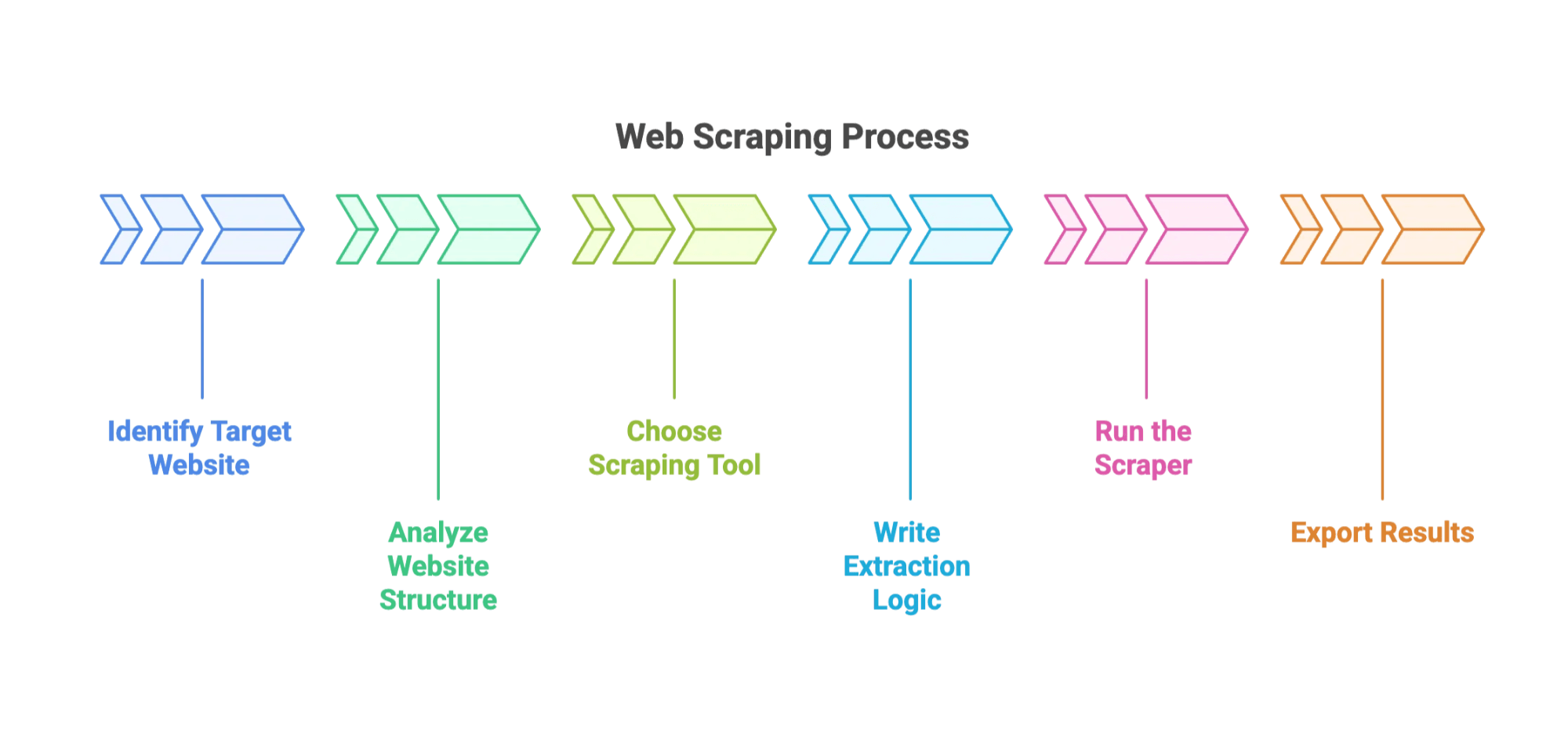
- Identify your target website and data fields.
- Analyze the website’s structure. (This means poking around the HTML with your browser’s Developer Tools. It’s like digital archaeology.)
- Choose your tool: Popular options include BeautifulSoup, Scrapy, or browser plugins.
- Write extraction logic: Tell your tool how to find the data—usually by specifying CSS selectors or XPath.
- Run the scraper: Watch as it collects data across pages.
- Export the results: Usually as CSV, JSON, or straight into Excel.
Step-by-Step: Extracting Data with a Traditional Web Scraper
Let’s say you want to scrape product listings from an e-commerce site. Here’s a beginner-friendly walkthrough:
- Step 1: Install Python and the BeautifulSoup library.
- Step 2: Use your browser to inspect the product page. Find the HTML tags that hold the product name and price.
- Step 3: Write a short script to fetch the page, parse the HTML, and extract the relevant fields.
- Step 4: Loop through multiple pages (handling pagination).
- Step 5: Export the data to a CSV file.
It sounds straightforward, but trust me—your first script will probably break at least once. (My first attempt scraped 500 rows of “None” because I misspelled a class name. Oops.)
Common Challenges with Traditional Web Scraper Solutions
Here’s where things get tricky:
- Website changes: Even a tiny tweak in the site’s layout can break your scraper. 10–15% of scrapers break every week due to changes.
- Anti-bot measures: CAPTCHAs, IP bans, and rate limits can stop you cold. You’ll need to handle proxies, delays, and sometimes even solve CAPTCHAs.
- Technical skills required: You need to know some coding and HTML/CSS.
- Maintenance: Scrapers need constant babysitting and updates.
- Messy data: You’ll spend time cleaning up inconsistent formats, missing values, or weird encodings.
For a beginner, this can feel like trying to bake a cake while the recipe keeps changing and the oven occasionally locks you out.
Enter the AI Web Scraper: Making Data Extraction Accessible
Scrape data from any website using AI Get Started Free
Now for the fun part. AI web scrapers are changing the game (oops, almost used the forbidden phrase). Instead of writing code or fiddling with selectors, you can just tell the tool what you want in plain English. The AI figures out the rest.
Thunderbit (that’s us!) is a great example of this new breed. With Thunderbit, you can extract structured data from any website using natural language—no coding required. Whether you’re in sales, marketing, or ecommerce, you can collect the data you need in minutes, not days.
Thunderbit AI Web Scraper: How It Simplifies Data Extraction
Let me walk you through how Thunderbit makes life easier:
- AI Suggest Fields: Just click “AI Suggest Fields” and Thunderbit reads the website, recommends column names, and even suggests how to extract each field.
- Subpage Scraping: Need more details? Thunderbit can visit each subpage (like individual product pages) and enrich your data table automatically.
- Instant Templates: For popular sites like Amazon or Zillow, you can use pre-built templates—no setup needed.
- Free Data Export: Export your data to Excel, Google Sheets, Airtable, or Notion. Download as CSV or JSON. No hidden fees.
- Scheduled Scraping: Set up recurring scrapes to keep your data fresh—great for price monitoring or lead updates.
- AI Autofill: Let AI fill out online forms for you (yes, even that 10-page vendor onboarding form).
- Email, Phone, and Image Extractors: Grab contact info or images in one click.
And the best part? You don’t need to know a lick of code. Thunderbit’s Chrome Extension is available here, and you can learn more on our official website.
Try Thunderbit AI Web Scraper for Free
Comparing Traditional vs. AI Web Scraper Solutions
Let’s see how the two approaches stack up:
| Aspect | Traditional Web Scraper | AI Web Scraper (Thunderbit) |
|---|---|---|
| Ease of Use | Coding or complex setup required | No-code, natural language interface |
| Adaptability | Breaks easily with site changes | AI adapts to layout changes automatically |
| Maintenance | High—needs frequent updates | Low—AI handles most changes |
| Technical Skill | Requires programming and HTML knowledge | Designed for business users |
| Setup Speed | Hours to days | Minutes |
| Data Processing | Manual cleaning needed | AI cleans and structures data automatically |
| Cost | Free (open source), but high time investment | Affordable plans, free export options |
For most business users, especially beginners, AI web scrapers like Thunderbit are the clear winner for speed, simplicity, and reliability. Traditional tools still have a place for highly custom or large-scale projects—but for 95% of use cases, AI is the way to go.
Step-by-Step Guide: How to Scrape Data from a Website as a Beginner
Step 1: Define Your Data Extraction Goals
Before you start, get clear on what you need. Ask yourself:
- What website(s) do I want to scrape?
- What data fields are important? (e.g., product name, price, email, phone)
- How often do I need this data? (One-time or recurring?)
Make a checklist. For example: “I want to collect product names, prices, and ratings from the first 5 pages of XYZ.com.”
Step 2: Choose the Right Web Scraper Tool
Here’s a quick decision flow:
- Are you comfortable with code and want full control? Try a traditional tool like BeautifulSoup or Scrapy.
- Want speed, ease, and no code? Go with an AI web scraper like Thunderbit.
If you’re not sure, start with AI. You can always dive deeper later.
Step 3: Set Up and Run Your Data Extraction
Traditional Approach
- Install your tool: Set up Python and the necessary libraries.
- Inspect the website: Use browser DevTools to find the HTML structure.
- Write your script: Define how to find and extract each data field.
- Test on one page: Make sure you’re getting the right data.
- Scale up: Add pagination or loops to cover more pages.
- Export your data: Save as CSV or JSON.
AI Approach (Thunderbit)
- Install Thunderbit Chrome Extension: Download here.
- Open the target website: Navigate to the page you want to scrape.
- Click “AI Suggest Fields”: Thunderbit will read the page and suggest columns.
- Review the preview: Check that the data looks right. Adjust columns if needed.
- Click “Scrape”: Thunderbit collects the data for you.
- Export your data: Download to Excel, Google Sheets, Airtable, or Notion.
For a visual walkthrough, check out our Thunderbit YouTube Channel.
Scrape Website Data with Thunderbit
Step 4: Export and Use Your Data
Once you have your data:
- Export to your favorite tool: Excel, Google Sheets, Airtable, Notion, CSV, or JSON.
- Integrate into your workflow: Use it for sales outreach, price analysis, market research, or whatever your business needs.
- Clean and validate: Even with AI, it’s smart to spot-check your data for accuracy.
Tips for Successful Data Extraction: Avoiding Common Pitfalls
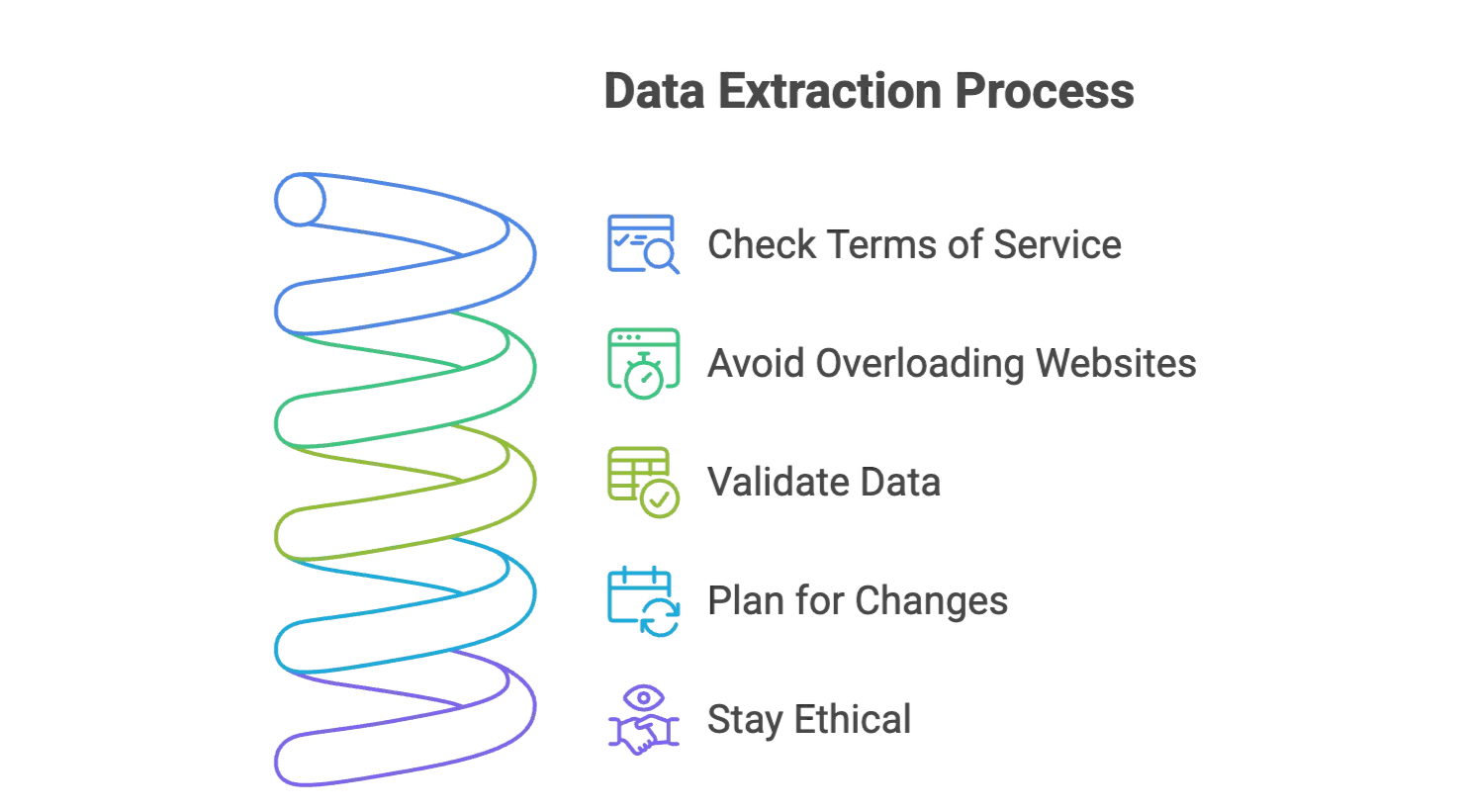
- Check website terms of service: Make sure you’re allowed to scrape the data. Stick to public info and avoid sensitive personal data.
- Don’t overload websites: Add delays between requests (traditional tools) or let Thunderbit handle it for you.
- Validate your data: Always check a sample of your results for accuracy.
- Plan for changes: Websites update all the time. AI scrapers like Thunderbit adapt automatically, but it’s good to monitor for big changes.
- Stay ethical: Only scrape what you need, and give credit if you use the data in reports or publications.
For more tips, see our What Is Data Scraping and How to Do It in 2025 and How to Scrape Any Website Using AI.
Conclusion & Key Takeaways
Web scraping has come a long way—from the days of hand-coded scripts to today’s AI-powered, beginner-friendly tools. The main differences?

- Traditional scrapers offer control but require coding, maintenance, and patience.
- AI web scrapers like Thunderbit make data extraction accessible to everyone, with natural language commands, instant previews, and robust features like subpage and scheduled scraping.
If you’re new to web scraping, don’t be intimidated. The tools have never been easier, and the business value is undeniable. Whether you’re looking to generate leads, monitor prices, or just stop copying and pasting, AI web scrapers are your new best friend.
So, next time you find yourself staring at a mountain of web data, remember: you don’t need a PhD in computer science—or even a hoodie. Just a clear goal, the right tool, and maybe a good cup of coffee.
Ready to try it yourself? Install Thunderbit and see how easy web data extraction can be.
Curious for more? Check out the Thunderbit Blog for deep dives on scraping Amazon, Google, PDFs, and more. Happy scraping!
Try Thunderbit AI Web Scraper Now Get Started Free
FAQs
Q1: Is web scraping legal? A: Yes, scraping public data is generally legal in many countries. However, always check a website’s terms of service and avoid scraping sensitive or personal data.
Q2: Can I scrape websites that require login? A: Yes, but it’s more complex and may violate site policies. You’ll need session handling or authenticated scraping tools, and it’s important to review legal implications.
Q3: How can I scrape data from JavaScript-heavy websites? A: Use tools that support dynamic rendering, like headless browsers or AI scrapers that simulate human interactions and parse JavaScript-rendered content.
Q4: What are the best practices to avoid getting blocked? A: Use rate-limiting, random delays, user-agent rotation, and avoid scraping aggressively. AI-based scrapers often handle these strategies automatically.
Read More
-
Understanding Web Scraping Legality: Global Insights & Stats Overview of legal guidelines, industry stats, and ethical best practices.
-
State of web scraping report 2025 Trends, market growth, and the role of AI in web data extraction (2024–2025).
-
What Is A Robots.txt File? A Guide to Best Practices and Syntax Learn how to interpret robots.txt files to guide ethical and legal scraping.




