
La semaine dernière, l’un de nos utilisateurs m’a raconté avoir passé tout un après-midi à recopier des fiches d’installateurs de plomberie depuis SuperPages dans un tableur — 47 lignes en trois heures. Il avait les poignets en feu, ses données étaient pleines de fautes de frappe, et il n’avait toujours pas récupéré la moindre adresse e-mail. Cette histoire m’a vraiment parlé, parce que je suis déjà passé par là moi aussi — et c’est exactement le genre de souci pour lequel nous avons créé pour le régler.
SuperPages est l’un des plus anciens annuaires locaux américains, exploité par Thryv, avec une très large couverture dans les grandes villes et dans plein de secteurs — plombiers, dentistes, avocats, techniciens CVC, et bien plus encore. D’anciennes docs techniques le décrivaient comme une base de données nationale de type pages jaunes avec plus de 11 millions de fiches, et le site affiche encore aujourd’hui énormément de catégories locales très fournies. Le problème n’est pas de trouver des fiches. Le vrai défi, c’est de les transformer en une liste de leads propre et enrichie, sans y laisser ses nerfs ni son après-midi.
D’après le rapport 2024 Sales Trends de HubSpot, les commerciaux ne passent qu’environ 2 heures par jour à vendre réellement — le reste part dans des tâches comme la saisie de données et la recherche. Et 81 % des pros de la vente pensent que l’IA pourrait leur faire gagner du temps sur les tâches manuelles. Ce guide vous montre trois façons de scraper SuperPages pour trouver des leads — de l’IA sans code jusqu’à Python — afin que vous puissiez choisir la méthode qui colle à votre niveau et vous remettre sur ce qui fait vraiment avancer le chiffre d’affaires.
Qu’est-ce que SuperPages, et pourquoi les équipes commerciales l’adorent pour la prospection ?
SuperPages est un annuaire en ligne centré sur les États-Unis, où les entreprises locales sont listées avec leurs coordonnées, leurs catégories, leurs notes et plus encore. Voyez ça comme la version numérique de l’ancien annuaire téléphonique des pages jaunes — sauf qu’ici, la recherche se fait par catégorie et par localisation, avec bien plus de données par fiche.
Voici ce qu’une fiche SuperPages peut généralement contenir :
- Nom de l’entreprise
- Numéro de téléphone
- Adresse postale
- URL du site web (quand elle est disponible)
- Catégorie (par ex. plomberie, droit de la famille, CVC)
- Notes et avis
- Horaires d’ouverture (généralement sur la page de détail)
- Description (page de détail)
La page d’accueil de SuperPages met en avant des catégories populaires comme les services à domicile, les plombiers, les électriciens, les dentistes, les services juridiques, la réparation automobile, les restaurants et les services pour animaux — exactement les segments que les équipes commerciales, agences et prestataires locaux ciblent pour leurs actions de prospection.
En bref, SuperPages est une vraie mine d’or pour toute personne qui prospecte des entreprises locales aux États-Unis. Les données sont structurées, la couverture est large, et les catégories se prêtent très bien à de vraies campagnes commerciales.
Pourquoi scraper SuperPages pour générer des leads ? (Principaux cas d’usage)
Aller sur SuperPages à la main et recopier les données dans un tableur, c’est une vraie perte de temps. Le scraping automatise tout ça et vous donne une liste ciblée et structurée en quelques minutes au lieu de plusieurs heures. Et comme vous contrôlez la recherche (catégorie + ville + mot-clé), le résultat est souvent bien plus pertinent qu’une liste de leads achetée en vrac.
Voici les cas d’usage les plus fréquents que je vois chez nos utilisateurs :
| Cas d’usage | Qui en bénéficie | Exemple |
|---|---|---|
| Génération de leads locaux | Équipes commerciales, agences | Construire une liste de plombiers à Dallas pour de la prospection à froid |
| Analyse concurrentielle | Opérations, marketing | Comparer notes et services entre concurrents sur un marché |
| Cartographie de marché | Développement commercial | Identifier tous les dentistes dans un code postal pour le lancement d’un nouveau produit |
| Recherche de fournisseurs | Achats, opérations | Trouver des fournisseurs dans une région avec téléphone + site web |
| Prospection SEO local | Agences | Repérer les entreprises sans site web ou avec une fiche incomplète |
| Planification commerciale territoriale | Vente terrain | Regrouper les artisans par ville, code postal ou zone de service |
Le marché américain de la génération de leads B2B était estimé à 8,5 milliards de dollars en 2024, avec une projection à 18,2 milliards de dollars d’ici 2034 — autrement dit, la demande pour ce type de données ne ralentit pas. Une liste fraîchement scrapée, ciblée par catégorie et par localisation, peut être plus précise qu’une liste générique achetée, mais elle doit quand même être vérifiée et dédupliquée avant tout contact commercial (on y revient plus bas).
À quoi ressemble le résultat final : exemple de données scrapées depuis SuperPages
Avant de voir comment faire, je veux vous montrer le résultat concret. C’est souvent le morceau que beaucoup de guides oublient — mais si vous investissez du temps, vous devez savoir ce que ça peut vous rapporter.
Voici un exemple de tableau de sortie (données fictives, structure réaliste) :
| Nom de l’entreprise | Téléphone | Adresse | Site web | Catégorie | Note | Horaires | E-mail (enrichi) |
|---|---|---|---|---|---|---|---|
| Sunset Pipe & Drain Co. | +1 213-555-0148 | 1842 W 7th St, Los Angeles, CA 90057 | sunsetpipe.example | Plomberie | 4,6 | Lun-Ven 7h-18h | service@sunsetpipe.example |
| Arroyo HVAC Pros | +1 626-555-0182 | 72 N Fair Oaks Ave, Pasadena, CA 91103 | arroyohvac.example | CVC | 4,8 | Lun-Sam 8h-19h | hello@arroyohvac.example |
| Wilshire Family Dental | +1 323-555-0119 | 4100 Wilshire Blvd, Los Angeles, CA 90010 | wilshiredental.example | Dentistes | 4,4 | Lun-Jeu 9h-17h | appointments@wilshiredental.example |
| Pacific Legal Aid Group | +1 310-555-0173 | 11845 W Olympic Blvd, Los Angeles, CA 90064 | Services juridiques | 4,2 | Lun-Ven 8h30-17h30 | intake@pacificlegal.example | |
| Valley Auto Repair Center | +1 818-555-0198 | 14422 Ventura Blvd, Sherman Oaks, CA 91423 | valleyautorepair.example | Réparation automobile | 4,7 | Lun-Sam 8h-18h | info@valleyautorepair.example |
| Echo Park Pet Grooming | +1 213-555-0166 | 1511 Sunset Blvd, Los Angeles, CA 90026 | echoparkpets.example | Toilettage pour animaux | 4,9 | Mar-Dim 9h-17h | booking@echoparkpets.example |
Quelques points à garder en tête :
- Depuis la page de résultats : nom de l’entreprise, téléphone, adresse partielle, catégorie, note, URL de la fiche.
- Depuis la page de détail de l’entreprise (sous-page) : adresse complète, horaires, description, avis, parfois le site web.
- Grâce à l’enrichissement : adresse e-mail (souvent trouvée seulement sur le site web de l’entreprise ou via des outils d’enrichissement).
- Avec le nettoyage : téléphone au format E.164, état/code postal normalisés, clés de déduplication, URL source et date de scraping.
C’est le genre de résultat que vous pouvez déposer directement dans un CRM, un Google Sheet ou une base Airtable pour attaquer le travail tout de suite.
3 façons de scraper SuperPages pour générer des leads : comparaison rapide

Tout le monde n’a pas le même niveau de confort technique — ni la même patience. Voici donc trois méthodes, côte à côte, pour vous aider à choisir celle qui vous convient :
| Critère | Thunderbit (IA sans code) | Scraper visuel (ex. Octoparse) | Python (Requests + BS4) |
|---|---|---|---|
| Temps de configuration | ~2 min (installer l’extension) | ~15 min (créer le workflow) | ~30 min (installer les bibliothèques, écrire le code) |
| Code requis | Aucun | Aucun | Oui (Python) |
| Gestion de la pagination | Intégrée (clic ou défilement) | À configurer | Code manuel |
| Enrichissement des sous-pages | Scraping des sous-pages en 1 clic | Workflow/boucle séparé(e) nécessaire | Script séparé |
| Anti-blocage | Le Cloud Scraping gère cela | Dépend du plan / add-on proxy | À votre charge (proxies, en-têtes, limites de débit) |
| Options d’export | Excel, Google Sheets, Airtable, Notion, CSV, JSON | CSV, Excel, base de données | Ce que vous codez |
| Idéal pour | Équipes commerciales, agences, non-développeurs | Utilisateurs semi-techniques | Développeurs qui veulent un contrôle total |
Ma recommandation : si vous voulez commencer à scraper dans les 2 prochaines minutes, passez directement à la méthode 1. Si vous aimez les workflows visuels et que la configuration ne vous fait pas peur, essayez la méthode 2. Si vous voulez un contrôle total et que vous maîtrisez Python, foncez sur la méthode 3.
Méthode 1 : scraper SuperPages pour générer des leads avec Thunderbit (IA, sans code)
C’est la voie la plus rapide pour passer de « j’ai une recherche SuperPages » à « j’ai une liste de leads ». Pas de code, pas de constructeur de workflow, pas de configuration de proxy. Je suis peut-être un peu juge et partie — nous avons développé Thunderbit — mais je vais vous montrer exactement comment ça marche pour que vous puissiez vous faire votre propre avis.
Difficulté : Débutant
Temps nécessaire : ~5 minutes pour un scraping complet par catégorie/ville
Ce qu’il vous faut : navigateur Chrome, extension Chrome Thunderbit (la version gratuite suffit)
Étape 1 : installer Thunderbit et ouvrir SuperPages
Rendez-vous sur la et installez l’extension Thunderbit. Ça prend environ une minute. Une fois installée, ouvrez une page de résultats SuperPages — par exemple, cherchez « Plumbers in Los Angeles, CA » sur superpages.com.
Vous devriez voir l’icône Thunderbit dans la barre d’outils du navigateur et un panneau latéral prêt à servir.
Étape 2 : cliquer sur « AI Suggest Fields » pour détecter automatiquement les colonnes
Ouvrez le panneau latéral Thunderbit et cliquez sur « AI Suggest Fields ». L’IA de Thunderbit lit la page et propose automatiquement des colonnes en fonction de ce qu’elle repère — généralement le nom de l’entreprise, le téléphone, l’adresse, le site web, la catégorie, la note et l’URL de la fiche.
Vous pouvez modifier, ajouter ou supprimer des colonnes avant de scraper. Vous voulez ajouter une colonne perso comme « A un site web ? » ou « Zone de service ? » Il suffit d’écrire une consigne en anglais simple dans le Field AI Prompt. Par exemple, vous pouvez demander à une colonne de « formater le téléphone en +1XXXXXXXXXX » ou de « classer en résidentiel vs commercial ».
Vous devriez maintenant voir un aperçu du tableau avec vos colonnes déjà configurées dans le panneau Thunderbit.
Étape 3 : cliquer sur « Scrape » et regarder les données se remplir
Cliquez sur le bouton bleu « Scrape ». Thunderbit extrait toutes les fiches de la page en cours et remplit votre tableau ligne par ligne. Pour une page de résultats SuperPages classique, ça prend environ 30 à 45 secondes.
Thunderbit gère automatiquement la pagination — il détecte les boutons « Next » ou le défilement infini et continue jusqu’à la fin des pages ou jusqu’à votre limite. Si vous scrapez beaucoup de résultats (par exemple, tous les plombiers d’une grande ville), passez en mode Cloud Scraping, qui peut traiter jusqu’à 50 pages en même temps sans monopoliser votre navigateur.
Étape 4 : utiliser le scraping des sous-pages pour enrichir chaque fiche
La page de résultats vous donne les bases, mais le vrai bonus — horaires, descriptions complètes, avis, parfois l’e-mail — se trouve sur la page de détail de chaque entreprise. Cliquez sur « Scrape Subpages » et Thunderbit visite chaque page de détail, puis récupère des colonnes enrichies comme les horaires, la description, l’URL du site web et toute info de contact visible.
C’est une opération en un clic. Pas de workflow séparé, pas de réglage compliqué. Les données enrichies s’ajoutent directement à votre tableau existant.
Étape 5 : exporter vos leads vers Excel, Google Sheets, Airtable ou Notion
Quand vos données vous conviennent, cliquez sur Export. Thunderbit vous permet d’envoyer vos leads directement vers :
- Google Sheets (pratique pour préparer un CRM et partager)
- Airtable (tableaux de pipeline légers)
- Notion (bases de recherche)
- Excel / CSV (imports CRM)
- JSON (transmission aux développeurs)
Toutes les options d’export sont gratuites. Si vous alimentez HubSpot ou Salesforce, l’export en CSV ou vers Google Sheets est généralement le chemin le plus rapide.
Astuce : scrapez par catégorie + ville plutôt qu’avec des recherches trop larges à l’échelle d’un État. « Emergency plumbers Dallas TX » vous donnera une liste plus ciblée et plus exploitable que « plumbers Texas ». Ajoutez une colonne « URL source » et « Date de scraping » pour garder une bonne traçabilité.
Méthode 2 : scraper SuperPages avec un outil de scraping visuel (exemple Octoparse)
Les outils de scraping visuel comme Octoparse se placent entre les deux : pas de code, mais plus de configuration que Thunderbit. Octoparse propose même un modèle SuperPages prêt à l’emploi pour les usages simples.
Difficulté : Intermédiaire
Temps nécessaire : ~20–30 minutes pour la configuration + le scraping
Ce qu’il vous faut : un compte Octoparse (plan gratuit disponible, avec limitations)
Étape 1 : créer une nouvelle tâche et charger l’URL SuperPages
Ouvrez Octoparse, cliquez sur « New Task » et collez votre URL de recherche SuperPages (par ex. « https://www.superpages.com/los-angeles-ca/plumbers »). Le navigateur intégré charge la page.
Étape 2 : détecter automatiquement ou sélectionner manuellement les champs de données
Cliquez sur « Auto-detect » — Octoparse analyse la page et met en évidence les champs qu’il juge pertinents. Vérifiez le panneau Data Preview. D’après mon expérience, la détection automatique récupère souvent la plupart des champs, mais elle peut aussi ramasser des éléments en trop (comme des libellés publicitaires ou du texte de navigation) ou en rater certains. Il faudra sans doute ajouter ou supprimer manuellement quelques champs.
Selon la documentation d’aide d’Octoparse, la détection automatique crée un workflow de base avec pagination et extraction, mais les utilisateurs peuvent devoir ajouter manuellement les données manquantes.
Étape 3 : construire le workflow et configurer la pagination
Cliquez sur « Create workflow ». Octoparse génère une suite d’actions étape par étape. Vérifiez l’étape de pagination — assurez-vous qu’elle clique bien sur « Next » ou charge les résultats supplémentaires. Si vous voulez récupérer les données de chaque page de détail d’entreprise (horaires, e-mail, description), vous devrez ajouter une boucle sur les pages de détail ou une action de sous-page dans le workflow. Cela ajoute de la complexité par rapport à l’approche Thunderbit en un clic.
Étape 4 : exécuter la tâche et exporter les données
Lancez la tâche localement (pour les petits volumes) ou dans le cloud Octoparse (pour les tâches planifiées ou plus volumineuses — le cloud est une fonctionnalité payante). Une fois terminé, exportez en CSV, Excel ou JSON.
Limites à connaître : le plan gratuit d’Octoparse inclut 10 tâches, jusqu’à 50 000 lignes par mois, et l’extraction locale uniquement. Les exécutions cloud, la rotation d’IP, la résolution des CAPTCHA et certaines intégrations d’export nécessitent un plan payant (à partir d’environ 69 $/mois en facturation annuelle).
Méthode 3 : scraper SuperPages avec Python (Requests + BeautifulSoup)
Voici l’option développeur. Contrôle total, responsabilité totale. Si vous êtes à l’aise avec l’écriture et la maintenance de scripts Python, vous aurez ici la plus grande flexibilité — mais aussi le plus de complications.
Difficulté : Avancé
Temps nécessaire : ~30–60 minutes (configuration + code + débogage)
Ce qu’il vous faut : Python 3.x, pip, requests, beautifulsoup4, lxml, un éditeur de code
Étape 1 : configurer votre environnement Python
1python -m venv .venv
2source .venv/bin/activate
3pip install requests beautifulsoup4 lxml pandasÉtape 2 : inspecter la structure HTML de SuperPages
Ouvrez les outils de développement (F12) sur une page de résultats SuperPages. Identifiez les sélecteurs CSS pour le nom de l’entreprise, l’adresse, le téléphone, le site web et le lien vers la page de détail. Gardez en tête que la structure HTML peut changer sans prévenir, ce qui veut dire que vos sélecteurs peuvent casser à tout moment.
Étape 3 : écrire le scraper de fiches et gérer la pagination
Voici un exemple simplifié. Point important : lors de mes tests, une requête directe à SuperPages renvoyait une page de blocage Cloudflare « Attention Required ». Un script Requests naïf peut donc échouer à grande échelle — il vous faudra peut-être du contexte de session navigateur, de la limitation de débit, des tentatives répétées ou des alternatives autorisées.
1import csv, time
2from urllib.parse import urljoin
3import requests
4from bs4 import BeautifulSoup
5BASE_URL = "https://www.superpages.com"
6HEADERS = {
7 "User-Agent": (
8 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
9 "AppleWebKit/537.36 (KHTML, like Gecko) "
10 "Chrome/125.0 Safari/537.36"
11 )
12}
13def fetch(url):
14 resp = requests.get(url, headers=HEADERS, timeout=20)
15 resp.raise_for_status()
16 if "Attention Required" in resp.text or "Cloudflare" in resp.text:
17 raise RuntimeError("Bloqué. Ralentissez ou passez au scraping via navigateur/cloud.")
18 return BeautifulSoup(resp.text, "lxml")
19def parse_listing(card):
20 name_el = card.select_one(".business-name, a.business-name, h2 a, h3 a")
21 phone_el = card.select_one(".phones, .phone, [class*=phone]")
22 address_el = card.select_one(".street-address, .adr, [class*=address]")
23 website_el = card.select_one("a.track-visit-website, a[href*='http']")
24 rating_el = card.select_one(".rating, [class*=rating]")
25 detail_url = urljoin(BASE_URL, name_el.get("href")) if name_el and name_el.get("href") else ""
26 return {
27 "business_name": name_el.get_text(" ", strip=True) if name_el else "",
28 "phone": phone_el.get_text(" ", strip=True) if phone_el else "",
29 "address": address_el.get_text(" ", strip=True) if address_el else "",
30 "website": website_el.get("href", "") if website_el else "",
31 "rating": rating_el.get_text(" ", strip=True) if rating_el else "",
32 "detail_url": detail_url,
33 }
34def scrape_search(search_url, pages=3):
35 all_rows = []
36 for page in range(1, pages + 1):
37 page_url = f"\{search_url\}?page=\{page\}"
38 soup = fetch(page_url)
39 cards = soup.select(".result, .organic, [class*=result]")
40 if not cards:
41 break
42 for card in cards:
43 all_rows.append(parse_listing(card))
44 time.sleep(5)
45 return all_rows
46if __name__ == "__main__":
47 rows = scrape_search("https://www.superpages.com/los-angeles-ca/plumbers", pages=2)
48 with open("superpages_leads.csv", "w", newline="", encoding="utf-8") as f:
49 writer = csv.DictWriter(f, fieldnames=sorted({k for row in rows for k in row}))
50 writer.writeheader()
51 writer.writerows(rows)Étape 4 : scraper les pages de détail pour enrichir les données
Écrivez une fonction séparée pour visiter chaque URL de page de détail et extraire les horaires, l’e-mail, la description et les avis. Cela implique de gérer les limites de débit, les erreurs et potentiellement des proxies — tout cela est à votre charge.
Étape 5 : enregistrer les données en CSV ou JSON
Utilisez les modules csv ou json de Python. Vous devrez aussi écrire votre propre logique de déduplication, de nettoyage et d’export.
Pièges courants :
- SuperPages peut bloquer les requêtes avec Cloudflare ou d’autres systèmes anti-bot similaires (confirmé lors de mes tests).
- Les sélecteurs ci-dessus sont volontairement larges, car le balisage de SuperPages peut changer.
- Ne partez pas du principe que les pages de résultats contiennent des e-mails. C’est presque jamais le cas.
- Un scraper de production nécessite une vérification des robots.txt/CGU, une limitation de débit, des tentatives avec backoff, une journalisation structurée et une capture des erreurs.
Si vous voulez aller plus loin sur le scraping Python, consultez notre guide sur le web scraping avec Python ou notre tutoriel BeautifulSoup.
Des données brutes aux vrais leads : le pipeline complet (scraper → nettoyer → vérifier → CRM)
C’est ici que la plupart des guides s’arrêtent — et c’est là que la vraie valeur commence. Le scraping vous donne une matière première. La transformer en une vraie liste de leads exploitable demande encore quelques étapes.
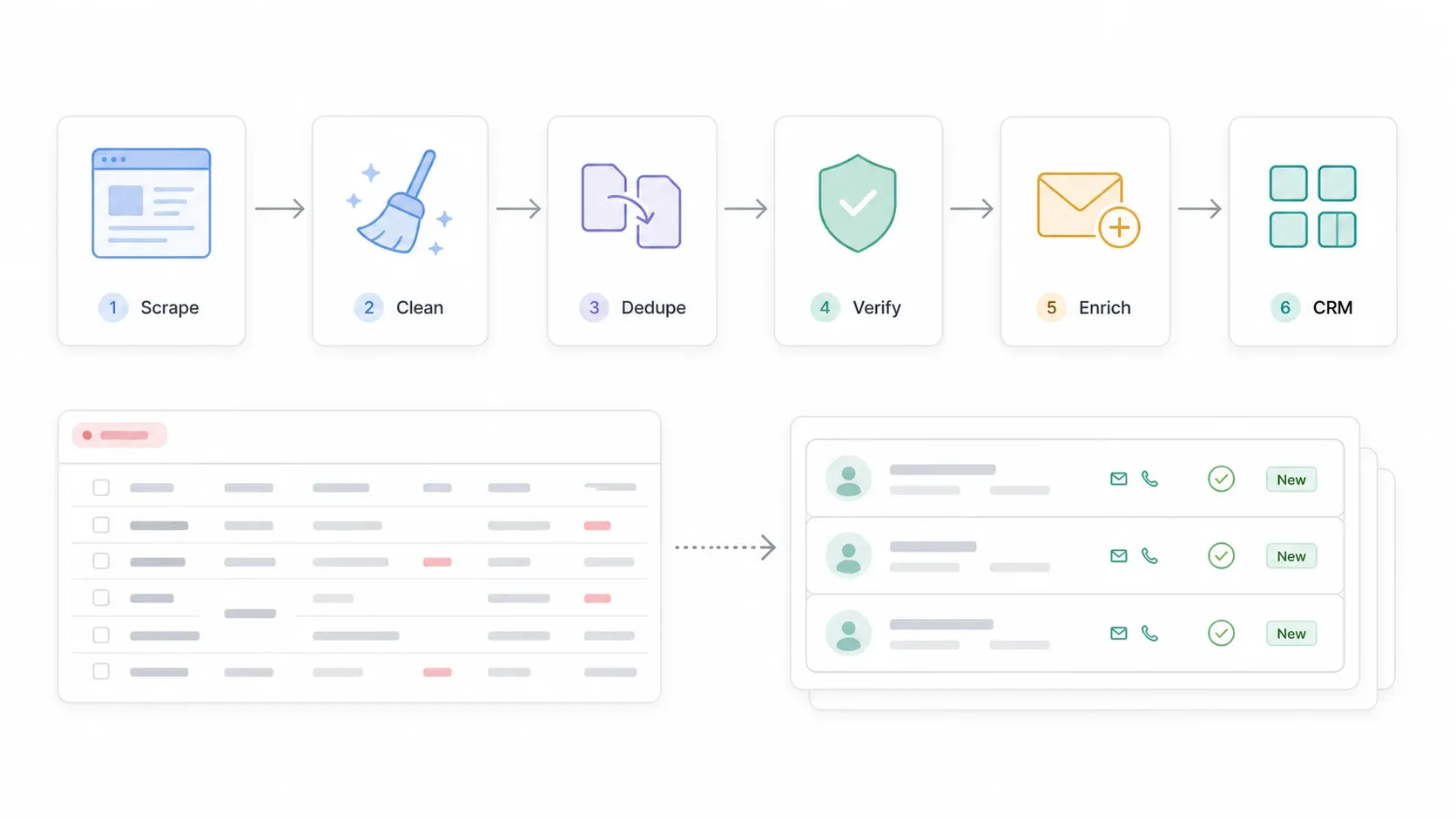
Le pipeline ressemble à ça :
Recherche SuperPages → Scraper les fiches → Scraper les pages de détail / sites web → Exporter vers Google Sheets ou CSV → Nettoyer les téléphones, adresses, catégories → Dédupliquer → Vérifier les e-mails / téléphones → Enrichir les contacts manquants → Importer dans le CRM → Prospection conforme
Déduplication : supprimer les fiches en double
SuperPages affiche souvent la même entreprise dans plusieurs catégories. Si vous avez scrapé « plumbers » et « drain cleaning » dans la même ville, vous aurez des doublons.
- Clé principale de déduplication : numéro de téléphone normalisé + adresse postale normalisée.
- Secondaire : domaine + ville.
- Solution de secours : nom de l’entreprise + code postal (à vérifier manuellement pour les franchises).
Dans Google Sheets, utilisez =UNIQUE(A:H) pour des correspondances exactes sur toute la ligne, ou créez une colonne d’aide comme =LOWER(REGEXREPLACE(B2&C2,"[^a-zA-Z0-9]","")) pour repérer les quasi-doublons. Dans Excel, utilisez Données > Supprimer les doublons.
Nettoyage des données : standardiser les téléphones, adresses et formats
- Formatez les numéros de téléphone en E.164 (pour les États-Unis : +1 suivi de 10 chiffres). C’est le format attendu par la plupart des CRM et composeurs automatiques. Vous pouvez utiliser un Field AI Prompt dans Thunderbit pour appliquer ce format automatiquement pendant le scraping.
- Normalisez les adresses : développez les abréviations, complétez les codes postaux manquants, séparez en colonnes rue/ville/État/code postal si besoin.
- Supprimez les artefacts HTML, les espaces inutiles et les paramètres de suivi des URL.
- Ajoutez les colonnes
source_directory,source_urletscraped_atpour assurer la traçabilité.
Vérification des e-mails et des téléphones avant la prospection
N’envoyez pas un cold email à toutes les adresses extraites. La vérification protège la réputation de votre domaine d’envoi et garde un faible taux de rebond.
- Vérification des e-mails : ZeroBounce (à partir d’environ 39 $ pour 2 000 crédits, plus 100 crédits gratuits par mois) ou Bouncer (8 $ pour 1 000 crédits, crédits sans date d’expiration) sont de bonnes options.
- Validation des téléphones : Twilio Lookup propose gratuitement le formatage et la validation ; l’affichage de l’identifiant d’appelant coûte 0,01 $ par requête.
- Les extracteurs gratuits d’e-mails et de numéros de téléphone de Thunderbit peuvent récupérer les coordonnées manquantes sur les pages de fiches.
Enrichissement : trouver des contacts quand SuperPages n’affiche pas d’e-mail
Beaucoup de fiches SuperPages n’affichent aucun e-mail — surtout sur la page de résultats. Voici quoi faire :
- Scrapez les pages Contact, À propos ou le pied de page du site web de l’entreprise. Le scraping des sous-pages de Thunderbit ou l’Email Extractor peuvent le faire en masse.
- Utilisez des outils d’enrichissement comme Apollo, BetterContact, Icypeas ou Prospeo. Attention toutefois : pour les petites entreprises locales (une plomberie à deux personnes, un dentiste indépendant), les grosses bases B2B sont souvent vides. L’extraction depuis le site web marche généralement mieux dans ce cas.
- Combinez plusieurs annuaires. Scrapez SuperPages, Yellow Pages et Google Maps pour la même catégorie/ville, puis fusionnez et dédupliquez. Le croisement des sources permet d’obtenir des fiches plus complètes.
Si vous avez déjà essayé de faire passer une liste de PME locales dans Apollo pour obtenir surtout des cases vides, vous n’êtes pas seul. C’est pour ça que l’approche centrée sur le site web est si importante pour ce public.
Import CRM : intégrer les leads dans HubSpot, Salesforce ou Google Sheets
- HubSpot : allez dans Data Management > Data Integration > Import data > Quick import (contacts uniquement). Téléversez votre fichier
.csvou.xlsx. Le guide d’import de HubSpot explique le mapping des champs. - Salesforce : utilisez le Data Import Wizard. Préparez un CSV, mappez les champs source vers les champs Salesforce, puis lancez l’import.
- Google Sheets / Airtable / Notion : Thunderbit exporte directement vers ces trois outils — pas besoin de passer par un CSV.
Conseil : mappez vos colonnes scrapées aux champs CRM avant l’import. Quelques minutes de préparation vous feront gagner des heures de nettoyage manuel plus tard.
SuperPages vs autres annuaires d’entreprises locales : où trouver les meilleurs leads ?
SuperPages est un très bon point de départ, mais ce n’est pas le seul annuaire utile à scraper. Voici comment il se compare :
| Annuaire | Volume de leads | Champs disponibles | Fraîcheur des données | Difficulté anti-scraping | Idéal pour |
|---|---|---|---|---|---|
| SuperPages | Important (focus États-Unis) | Nom, téléphone, adresse, site web, catégories, notes | Modérée | Moyenne | Services à domicile, artisans, PME |
| Yellow Pages | Important (focus États-Unis) | Similaire à SuperPages | Modérée | Moyenne | Prospection locale générale |
| Google Maps | Très important (global) | Nom, téléphone, adresse, site web, avis, horaires, photos | Élevée (mise à jour par le propriétaire) | Élevée (anti-bot agressif) | Données locales les plus à jour |
| Yelp | Important (focus États-Unis) | Nom, téléphone, adresse, avis, fourchette de prix | Élevée | Élevée | Restaurants, retail, services |
| Manta | Moyen | Nom, téléphone, adresse, estimations de revenus, effectif | Modérée | Faible | Prospection B2B (revenus/effectif) |
| BBB | Moyen | Nom, téléphone, adresse, accréditation, plaintes | Modérée | Faible | Entreprises fiables et vérifiées |
Sources : page d’accueil SuperPages, article VLDB sur SuperPages, documentation Google Places API, documentation Yelp Places API, page d’accueil Manta, guide BBB.
Thunderbit fonctionne sur toutes ces sources — y compris avec des modèles instantanés pour des sites populaires comme Google Maps et SuperPages — pour que vous puissiez appliquer le même workflow à plusieurs sources et fusionner vos listes de leads. D’après mon expérience, la meilleure approche consiste souvent à scraper deux ou trois annuaires pour la même catégorie/ville, puis à dédupliquer. Les doublons comblent les trous et donnent une vue plus complète.
Pour aller plus loin sur le scraping d’autres annuaires, consultez nos guides sur les , les et les .
Conseils juridiques et éthiques pour scraper des leads SuperPages
Je ne suis pas avocat, et ceci ne constitue pas un conseil juridique — mais j’ai passé assez de temps dans ce domaine pour savoir qu’ignorer la conformité est le moyen le plus rapide de se brûler. Voici le résumé pratique.
Données commerciales publiques vs données personnelles
Les fiches d’entreprise — nom de la société, téléphone professionnel, adresse professionnelle, site web professionnel — sont généralement considérées comme des données commerciales publiques. C’est différent des données personnelles de consommateurs au sens du RGPD ou du CCPA. Mais « public » ne veut pas dire « sans règles ». Vérifiez toujours les Conditions d’utilisation du site.
Les Conditions d’utilisation de SuperPages (mises à jour en juillet 2019) incluent une clause « Data Mining Prohibited » : les utilisateurs ne peuvent pas utiliser de bots, crawlers, spiders ou outils similaires pour collecter ou extraire des données sans le consentement préalable de Thryv. L’article présente des méthodes et des workflows, mais vous devez lire ces conditions et obtenir les autorisations nécessaires avant tout scraping à grande échelle.
Conformité de la prospection : bases de CAN-SPAM et du TCPA
Si vous utilisez les e-mails scrapés pour de la prospection à froid, le guide CAN-SPAM de la FTC indique que vous devez :
- Ne pas utiliser d’en-têtes faux ou trompeurs
- Ne pas utiliser d’objets de mail trompeurs
- Identifier le message comme une publicité lorsque c’est requis
- Inclure une adresse postale physique valide
- Fournir un mécanisme de désinscription clair et le respecter rapidement
Si vous utilisez les numéros de téléphone scrapés pour des appels commerciaux, vérifiez le National Do Not Call Registry et respectez les règles du TCPA — surtout pour les appels automatisés, les messages préenregistrés et les SMS. La FTC a annoncé en 2024 des changements visant à renforcer la protection contre les pratiques trompeuses de télémarketing B2B et les appels frauduleux assistés par IA.
Checklist rapide de conformité
- ✅ Ne scraper que des données professionnelles publiques
- ✅ Lire les Conditions d’utilisation de SuperPages et obtenir l’autorisation quand c’est nécessaire
- ✅ Vérifier les contacts avant la prospection
- ✅ Inclure une option de désinscription dans les e-mails
- ✅ Respecter robots.txt et les limites de débit
- ✅ Tenir des listes DNC et des listes de suppression e-mail
- ⚠️ Éviter de scraper des données personnelles/de consommateurs
- ⚠️ Ne pas revendre des données brutes scrapées sans analyse juridique
Choisissez votre méthode et commencez à construire votre liste de leads
Scraper SuperPages pour générer des leads, ce n’est pas juste extraire des lignes d’une page web. La vraie valeur vient du pipeline complet : scraper, nettoyer, dédupliquer, vérifier, enrichir, importer et prospecter dans les règles.
Petit récapitulatif :
- Thunderbit est la solution la plus rapide pour les équipes commerciales, les agences et les non-développeurs. Deux clics pour scraper, un clic pour enrichir via les sous-pages, export gratuit vers Google Sheets, Airtable, Notion ou Excel. Essayez gratuitement.
- Octoparse est un bon outil de workflow visuel pour les utilisateurs semi-techniques qui veulent plus de contrôle sur la configuration.
- Python offre aux développeurs une flexibilité totale — mais avec la maintenance, les soucis d’anti-blocage et aucun enrichissement natif.
- Et n’oubliez pas : le même workflow s’applique à Yellow Pages, Google Maps, Yelp, Manta et BBB. Scrapez plusieurs sources, fusionnez, dédupliquez, et vous obtiendrez la liste de leads locale la plus complète possible.
Si vous voulez voir Thunderbit en action, consultez notre pour des démos, ou regardez les pour voir ce qui colle à votre équipe.
Maintenant, transformez ces pages d’annuaires en pipeline — et que vos numéros soient toujours bien formatés et vos e-mails toujours vérifiés.
FAQ
Est-il légal de scraper SuperPages pour générer des leads ?
Le scraping de données publiques d’annuaires d’entreprises à des fins de recherche B2B est courant, mais les Conditions d’utilisation de SuperPages interdisent le data mining sans le consentement préalable de Thryv. Consultez toujours les conditions du site, obtenez les autorisations nécessaires et respectez les règles de prospection comme CAN-SPAM et TCPA. Cet article présente des méthodes et workflows à titre pédagogique — à vous de les utiliser dans le respect des règles.
Quelles données puis-je obtenir depuis SuperPages ?
Un scraping classique fournit le nom de l’entreprise, le téléphone, l’adresse, le site web, la catégorie, les notes, les horaires et les descriptions. Les e-mails sont rarement visibles sur la page de résultats — il faut généralement visiter la page de détail de l’entreprise ou son propre site web (via le scraping des sous-pages ou un extracteur d’e-mail) pour les trouver.
Puis-je scraper SuperPages sans coder ?
Oui. Des outils comme Thunderbit (extension Chrome IA) et Octoparse (scraper visuel) permettent de scraper SuperPages sans écrire une seule ligne de code. Thunderbit est l’option la plus rapide — installez l’extension, ouvrez une recherche SuperPages, cliquez sur « AI Suggest Fields », puis sur « Scrape ».
Comment gérer la pagination lors du scraping de SuperPages ?
Thunderbit gère automatiquement la pagination — il détecte les boutons « Next » ou le défilement infini et continue. Octoparse demande de configurer une étape de pagination dans le workflow. En Python, vous devez écrire la logique de boucle à la main (incrémentation des pages, détection de la dernière page).
Comment obtenir des e-mails à partir des fiches SuperPages ?
La plupart des fiches SuperPages n’affichent pas d’e-mail sur la page de résultats. Utilisez le scraping des sous-pages de Thunderbit pour visiter chaque page de détail, ou utilisez le Email Extractor gratuit sur le site web de l’entreprise. Pour les trous restants, essayez des outils d’enrichissement comme Apollo, BetterContact ou Prospeo — même si, pour les petites entreprises locales, l’extraction depuis le site web marche souvent mieux que les grosses bases B2B.
En savoir plus