Une recherche GitHub pour "tiktok scraper" renvoie . Environ n’ont pas été mis à jour depuis plus d’un an, et au moins .
Si vous avez déjà cloné un dépôt populaire de TikTok scraper, passé une heure à vous battre avec les dépendances, puis obtenu zéro résultat — vous n’êtes pas seul. Le TikTok scraper le plus étoilé sur GitHub, drawrowfly/tiktok-scraper, affiche encore plus de 5 000 étoiles. Pourtant, son suivi des problèmes regorge de fils comme et — les deux signalant zéro sortie. Chez Thunderbit, j’ai suivi pendant des mois l’état des dépôts de TikTok scraping, et le constat est sans ambiguïté : ces outils cassent vite, et la plupart ne sont jamais corrigés. Cet article est le guide de survie pratique que j’aurais aimé avoir lorsque j’ai commencé à évaluer ces dépôts. Nous allons voir ce qui fonctionne encore, ce qui est mort, quoi faire à la place, et comment arrêter de perdre des heures sur du code déjà obsolète avant même que vous ne le trouviez.
Pourquoi la plupart des TikTok Scrapers sur GitHub cassent (et cassent encore)
TikTok n’est pas une cible de scraping classique. Son interface web évolue sans cesse. Contrairement à une page produit e-commerce statique ou à une liste d’annuaire, TikTok fait tourner les endpoints, met à jour le fingerprinting anti-bot, change ses méthodes de rendu des pages et introduit de nouvelles exigences de session et de jetons — parfois en l’espace de quelques semaines après le dernier changement.
Les mainteneurs open source sont des bénévoles. Quand TikTok déploie une mise à jour qui casse le chemin de requête du scraper, le dépôt peut rester inutilisable pendant des jours, des semaines, voire définitivement. Ce n’est pas une critique envers les mainteneurs — c’est un décalage structurel entre une plateforme très financée qui bouge vite et des développeurs non rémunérés qui ont un travail à côté.
Même les meilleurs dépôts de TikTok scraper fonctionnent dans un cycle cassé/réparé. Si vous comptez en utiliser un, il vous faut une stratégie pour l’évaluer, le dépanner et prévoir une solution de secours.
Les défenses anti-bot de TikTok : à quoi vous êtes confronté
- Limitation du débit. Les détaillent explicitement des quotas de requêtes, même pour les intégrations approuvées. Les scrapers non officiels atteignent ces limites bien plus vite.
- Protection par cookies et session. Les dépôts modernes comme exigent un
ms_token; les dépôts plus anciens comme montrenttt_webid_v2dans leurs exemples ; documentemsToken,ttwid,X-BogusetA_Bogus. TikTok vérifie si votre requête ressemble à une vraie session de navigation. - Fingerprinting du navigateur. Les expliquent pourquoi les sites comparent les en-têtes, les cookies, les signatures TLS et les caractéristiques du navigateur exposées par JavaScript au trafic d’un vrai utilisateur. Leur couvre Canvas, WebGL, WebRTC, les polices et les signaux d’exécution. Le fingerprinting, c’est un peu comme si TikTok vérifiait la carte d’identité de votre navigateur : si le navigateur, les cookies, le timing et la signature réseau ne concordent pas, la requête paraît factice avant même qu’un contenu ne soit renvoyé.
- Détection comportementale. Des sur le scraping de TikTok mentionnent souvent que des sessions Playwright fraîchement créées déclenchent des CAPTCHA. Des publications communautaires de décrivent de plus en plus une détection basée sur le timing des actions et la qualité des interactions, pas seulement sur la réutilisation d’IP.
- Paramètres de requête chiffrés/signés. Evil0ctal documente
X-BogusetA_Bogus; d’anciens gists communautaires tournent autour de la signature d’URL et de la génération de jetons. TikTok attend de plus en plus que les requêtes arrivent avec les mêmes « tampons » que ceux portés par son propre trafic navigateur/application. - CAPTCHA et flux de vérification. L’existence de et de confirme que le CAPTCHA fait toujours partie de la surface anti-bot.
Pourquoi les mainteneurs open source ne peuvent pas suivre
Le cycle de vie est toujours le même. Un développeur crée un TikTok scraper. Il devient viral sur GitHub. TikTok le corrige. Le mainteneur le répare… ou passe à autre chose.
Deux dépôts illustrent parfaitement ce schéma :
- drawrowfly/tiktok-scraper affiche encore 5 052 étoiles et 889 forks, mais son . C’est le TikTok scraper à expression exacte le plus étoilé sur GitHub, et il ressemble à un artefact historique : très visible, très crédible, mais plus maintenu.
- davidteather/TikTok-Api affiche . Son montre une maintenance réelle en avril 2025, juillet 2025, octobre 2025 et avril 2026 — avec notamment des correctifs pour le crawling des vidéos utilisateur et de nouveaux contrôles de proxy/session. Mais même ce projet plus sain avertit ouvertement que TikTok bloque les requêtes et que les utilisateurs peuvent avoir besoin de proxies, de Playwright et d’une logique de session personnalisée.
Le schéma est simple :
- Un dépôt de TikTok scraper obsolète est probablement mort.
- Un dépôt de TikTok scraper actif est probablement encore fragile.
- La seule vraie différence, c’est de savoir si quelqu’un est encore là pour corriger la casse ce mois-ci.
La checklist vitale des dépôts en 60 secondes : comment évaluer n’importe quel TikTok Scraper sur GitHub
Avant de cloner quoi que ce soit, passez cette checklist en revue. Elle prend moins d’une minute et vous évite des heures de frustration.
| Signal | 🟢 Sain | 🟡 Risqué | 🔴 Mort |
|---|---|---|---|
| Dernier push significatif | < 3 mois | 3–12 mois | 12 mois et plus |
| Nombre d’issues ouvertes | Faible, les issues récentes obtiennent des réponses | File qui grossit avec un peu d’activité du mainteneur | Beaucoup de signalements « cassé/bloqué/ne fonctionne pas » sans réponse |
| Plaintes récentes des utilisateurs | Surtout des questions de configuration | Mélange de configuration et de pannes | Répétition de « zéro sortie », « 403 », « ça marche encore ? » |
| Modèle actuel d’authentification/session | Flux session/cookie documenté | Modèle à jetons mais documenté | Repose sur d’anciens endpoints web sans guide d’authentification actuel |
| Surface d’installation | Installation reproductible et testée | Quelques étapes manuelles | Vieilles dépendances, aucune note de configuration moderne |
| CI/tests | Des tests existent et sont à jour | Des tests existent, couverture peu claire | Pas de tests ou actions obsolètes |
| Pertinence du périmètre de données | Correspond à votre besoin réel | Ne couvre qu’une partie du cas d’usage | Résout un tout autre problème |
Comment vérifier chaque signal en moins de 60 secondes
- Date du dernier push : regardez l’en-tête du dépôt sur GitHub. S’il est indiqué « last pushed 2 years ago », passez votre chemin.
- Issues ouvertes : cliquez sur l’onglet Issues. Parcourez les titres les plus récents. Cherchez
not working,403,blocked,captchaouzero output. - Plaintes des utilisateurs : si les 5 premières issues ouvertes disent toutes en substance « ça ne marche plus », vous avez votre réponse.
- Modèle d’authentification/session : ouvrez le README. Cherchez des consignes actuelles comme
ms_token, la configuration de Playwright ou des notes sur les proxies. Si le README cite des endpoints de 2023, passez à autre chose. - Surface d’installation : vérifiez qu’il existe un fichier de dépendances, un support Docker ou des instructions claires. Si le README dit « npm install » et que la dernière version Node testée est 14, attendez-vous à des problèmes.
- CI/tests : regardez l’onglet Actions. Si les tests échouent ou sont absents, le dépannage devient une loterie.
- Périmètre de données : le dépôt décrit-il vraiment les types de données dont vous avez besoin (profils, métadonnées vidéo, commentaires, hashtags) ? Beaucoup de dépôts ne font que du téléchargement de vidéos, pas de l’extraction de données structurées.
Les signaux d’alerte qui veulent dire « partez »
- Le dépôt est archivé.
- Le README dit « no longer maintained ».
- Le dernier commit fait référence à une version de l’API TikTok datant de plus de 2 ans.
- Les issues sont inondées de signalements « ça ne marche pas » et le mainteneur n’a pas répondu depuis des mois.
- Le dépôt a beaucoup d’étoiles, mais peu de forks récents ou de pull requests.
Astuce : recherchez dans l’onglet Issues is:issue is:open "not working" ou is:issue is:open "403". Si les résultats sont nombreux et récents, le dépôt est probablement cassé.
Dépôts GitHub de TikTok Scraper populaires : état des lieux honnête (2026)
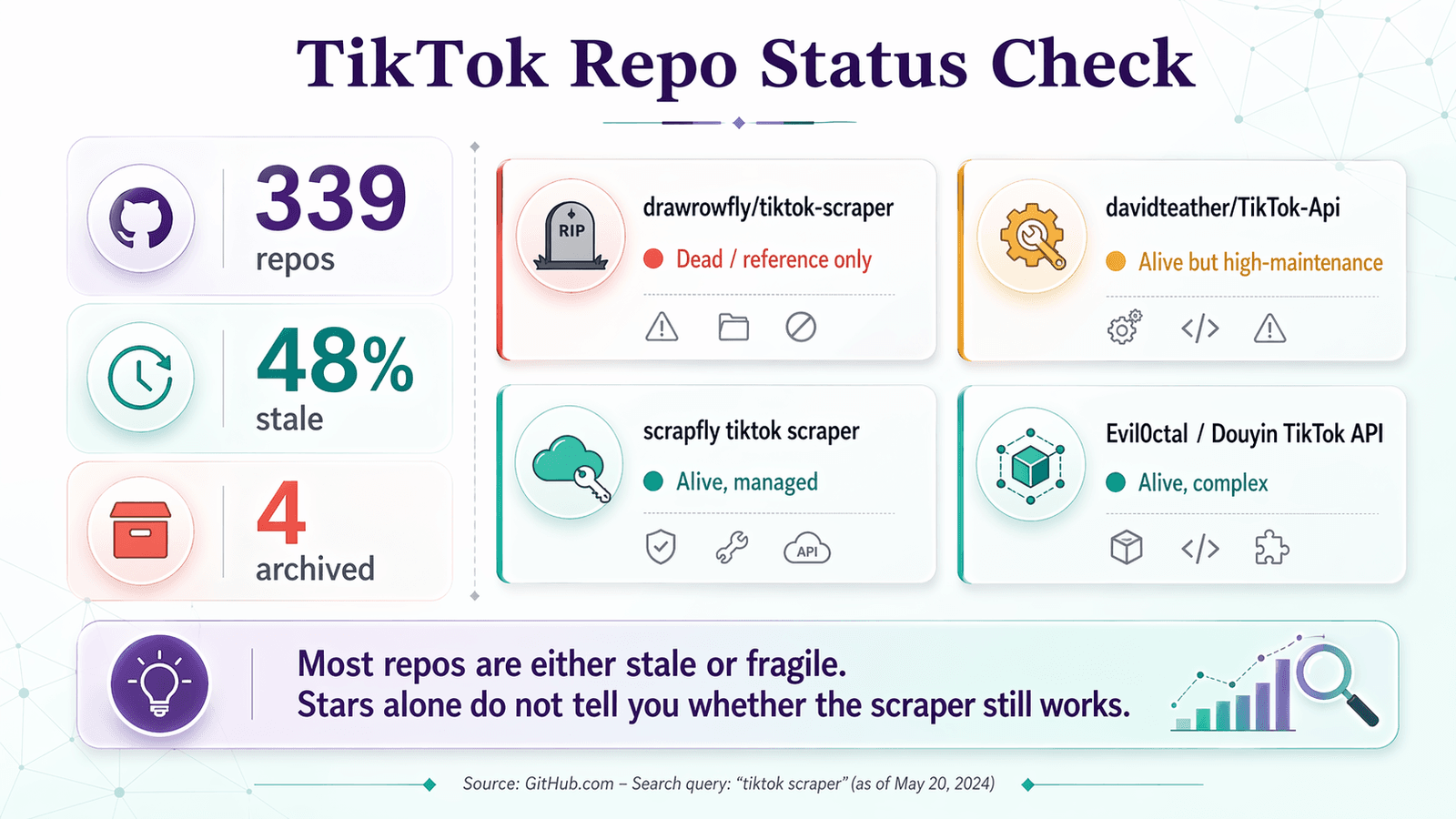
Voici la checklist des dépôts appliquée aux dépôts que vous trouverez réellement en cherchant « tiktok scraper » sur GitHub :
| Dépôt | Dernier push | Étoiles | Issues ouvertes | Verdict | Remarque |
|---|---|---|---|---|---|
| drawrowfly/tiktok-scraper | 2023-05-19 | 5,052 | 58 | 🔴 Mort / référence uniquement | Toujours célèbre, mais trop obsolète pour un usage de production en 2026 |
| davidteather/TikTok-Api | 2026-04-01 | 6,301 | 134 | 🟡 Vivant mais coûteux à maintenir | Le meilleur choix OSS ; attend Playwright, des jetons, souvent des proxies |
| scrapfly/scrapfly-scrapers/tiktok-scraper | 2026-04-21 | 938 (parent) | ~0 (monorepo) | 🟡 Vivant, mais pas du pur OSS | Actuel et utile, mais nécessite une clé API ScrapFly |
| Evil0ctal/Douyin_TikTok_Download_API | 2025-10-12 | 17,397 | 135 | 🟡 Vivant, large, complexe | Projet multiplateforme riche en fonctionnalités ; plutôt une plateforme pour utilisateurs avancés |
| naseif/tiktok-scraper | 2024-07-26 | 107 | 13 | 🟡 Risqué | Petit dépôt avec des plaintes ouvertes sur les infos utilisateur et les flux de hashtags |
| loewehancara1rmyv/Tiktok-scraper | 2026-01-12 | 4 | 0 | 🔴 Trop récent pour être fiable | Dépôt vitrine, pas éprouvé par la communauté |
drawrowfly/tiktok-scraper
Pendant des années, ce scraper/downloader TypeScript était la réponse par défaut à « tiktok scraper github » — il gérait les flux utilisateurs, tendances, hashtags et musique. En 2026, il vaut mieux le considérer comme une documentation historique. Le , et la file d’issues contient encore des signalements non résolus « still working? » et « zero output » datant de 2023–2025. Si vous lisez cet article parce que vous avez cloné ce dépôt et obtenu zéro résultat, vous êtes en bonne compagnie.
davidteather/TikTok-Api
Le wrapper open source TikTok le plus crédible encore vivant en 2026. Il est actif, a des et documente explicitement la configuration de Playwright, l’usage asynchrone, la gestion des jetons, le support des proxies et les fonctions de récupération de session. Mais ce n’est pas un outil de type « clone et ça marche ». Son README lui-même indique que EmptyResponseException signifie généralement que TikTok bloque la requête, et l’ montre des difficultés répétées autour de ms_token, de l’extraction de commentaires cassée, de KeyError: 'ItemModule' et d’échecs spécifiques à certains endpoints. Verdict : vivant, utile, réservé aux développeurs, et lourd à maintenir.
Autres dépôts notables
- : actuel et techniquement pertinent, mais le README exige une
SCRAPFLY_KEY. Il s’agit d’un exemple de code pour une plateforme de scraping managée, pas d’un outil gratuit autonome. - : couvre TikTok et Douyin, documente la logique de signature (
X-Bogus,A_Bogus,msToken) et prend en charge les commentaires, abonnés, playlists, etc. C’est techniquement exigeant et de plus en plus lié à des références d’API payantes. Le suivi des issues montre encore en 2026 des rapports de bugs sur les liens vidéo et les endpoints d’informations utilisateur. Vivant et riche en fonctionnalités, mais complexe. - : plus petit, avec des plaintes ouvertes. Risqué en production.
- : 4 étoiles, 0 issue, trop récent pour être digne de confiance. L’article Medium qui l’a promu le faisait sans esprit critique.
API officielle TikTok vs scrapers GitHub vs outils no-code : un cadre de décision

La plupart des articles concurrents ignorent les voies d’accès officielles de TikTok ou sautent directement de « utilisez GitHub » à « achetez notre service ». Voici une comparaison neutre des trois options :
| Critère | TikTok Research API | Scrapers GitHub | Outils no-code (ex. Thunderbit) |
|---|---|---|---|
| Barrière d’accès | Candidature académique/professionnelle requise ; ~4 semaines pour l’approbation | Clonage Git + configuration | Installation d’une extension de navigateur |
| Périmètre des données | Uniquement les endpoints approuvés (comptes, vidéos, commentaires, boutiques) | Large (profils, vidéos, commentaires, hashtags, boutiques) | Données visibles sur la page (profils, vidéos, engagement, hashtags) |
| Charge de maintenance | Faible (officiel, stable) | Élevée (les dépôts cassent quand TikTok se met à jour) | Aucune (l’IA s’adapte aux changements de mise en page) |
| Risque de bannissement | Aucun (autorisé) | Élevé | Faible (basé sur le navigateur, imite un vrai utilisateur) |
| Coût | Gratuit (si approuvé) | Gratuit (mais chronophage) | Version gratuite disponible ; formules à partir de 15 $/mois |
| Codage requis | Oui (Python/R) | Oui (Python/Node.js) | Non |
| Idéal pour | Chercheurs, universitaires, organisations approuvées | Développeurs à l’aise avec la maintenance | Marketeurs, équipes commerciales, opérations, non-développeurs |
Quand la TikTok Research API a du sens
La de TikTok est la voie officielle la plus propre si vous êtes éligible. Les chercheurs éligibles aux peuvent faire une demande pour étudier le contenu public et les données de compte. Les catégories disponibles comprennent les comptes, les abonnements, les vidéos aimées, les vidéos épinglées, les vidéos repartagées, le contenu, les commentaires et les boutiques.
Le expose des champs comme video_description, view_count, like_count, comment_count, share_count, ainsi que des champs au niveau du commentaire comme text, reply_count et create_time.
Le revers de la médaille : l’éligibilité est limitée aux institutions académiques et aux chercheurs indépendants ou à but non lucratif éligibles dans certaines régions, ainsi qu’aux . Si vous êtes une équipe growth ou une agence avec besoin de données opérationnelles rapides, ce n’est pas votre voie.
TikTok propose aussi une pour les annonces et les données de contenu des annonceurs, utile pour la recherche sur la transparence mais pas pour le scraping général.
Quand un scraper GitHub reste pertinent
Les scrapers GitHub restent utiles pour les développeurs qui ont besoin d’un accès non officiel à des données publiques au-delà du filtre d’approbation de l’API officielle et qui acceptent d’entretenir la stack. Cela inclut des cas d’usage comme le scraping de grilles de profils visibles, de hashtags, de commentaires, de playlists ou de métadonnées vidéo dans un pipeline personnalisé, où forker le dépôt et le corriger est acceptable.
Le bémol honnête : il ne s’agit pas d’une configuration ponctuelle. Même le dépôt le plus fiable de 2026, , dit encore aux utilisateurs qu’ils peuvent avoir besoin de Playwright, de cookies/jetons, de proxies et de factories personnalisées de page/session.
Quand un outil no-code comme Thunderbit a du sens
Pas développeur ? Ou développeur fatigué du cycle casse/répare ? Un outil d’IA basé sur le navigateur est le chemin le plus rapide vers des données TikTok structurées.
Nous avons conçu comme un extracteur Web IA qui fonctionne sous forme d’extension Chrome. Sur TikTok, il lit n’importe quelle page visible (profil, vidéo, hashtag, résultats de recherche), propose des colonnes via « AI Suggest Fields » et vous permet de cliquer sur « Scrape » pour extraire des données structurées. La documente des champs comme la date de publication, la durée de la vidéo, les likes, les partages, les enregistrements, les commentaires, les vues et les hashtags. Le montre comment collecter les vignettes de publication, les URL, les légendes, les identifiants de créateur et les signaux d’engagement depuis les pages de profil. Le couvre l’URL de la vidéo, le nom d’utilisateur du créateur, la description, l’heure de publication, les vues, les likes, les commentaires, les partages, le son/audio et l’URL de l’image de couverture.
Le scraping de sous-pages vous permet d’ouvrir chaque page vidéo depuis une liste de profil et d’enrichir le tableau avec les métriques d’engagement, les légendes et les hashtags — très utile pour les marketeurs qui construisent des bases de données d’influenceurs ou réalisent des audits de contenu concurrentiel.
Pas de maintenance, pas de tri d’installation, pas de configuration anti-bot. L’IA s’adapte automatiquement aux changements de mise en page. L’export est gratuit vers Google Sheets, Excel, Airtable, Notion, CSV ou JSON.
Si vous avez perdu des heures sur des dépôts GitHub cassés, c’est une vraie alternative — pas un argumentaire forcé.
Triage d’installation : corriger les 5 échecs de configuration GitHub les plus courants pour TikTok Scraper
Les échecs d’installation sont le troisième point de douleur le plus cité dans les forums sur le scraping TikTok, et aucun grand guide n’explique vraiment comment les résoudre. Voici ce qui se passe.
Conflits de version Node.js
Problème : de nombreux anciens dépôts de TikTok scraper (surtout drawrowfly/tiktok-scraper) ont été construits pour Node.js 14–16. Si vous utilisez Node 20+, npm install peut échouer silencieusement ou produire des binaires incompatibles.
Solution : utilisez nvm (Node Version Manager) pour installer et basculer vers la bonne version :
1nvm install 16
2nvm use 16
3npm installSi le dépôt ne précise pas de version Node, vérifiez le champ engines dans package.json ou regardez la configuration CI.
Problèmes de dépendances Python et configuration de Playwright
Problème : nécessite et Playwright avec des binaires de navigateur spécifiques. Les utilisateurs obtiennent des erreurs comme « browser not found » ou des conflits de dépendances.
Solution : utilisez toujours un environnement virtuel, puis installez explicitement les navigateurs Playwright :
1python -m venv .venv
2source .venv/bin/activate # Sous Windows : .venv\Scripts\activate
3pip install TikTokApi
4python -m playwright installSi playwright install échoue, vérifiez que le gestionnaire de paquets de votre système n’indique pas de dépendances système manquantes (par ex. libnss3 sur Ubuntu).
Erreurs de permissions sous Linux/Ubuntu
Problème : exécuter sudo pip install corrompt l’environnement Python système et provoque des problèmes de dépendances en cascade.
Solution : n’utilisez jamais sudo pip install. Créez toujours d’abord un environnement virtuel :
1python3 -m venv .venv
2source .venv/bin/activate
3pip install -r requirements.txtCela isole les dépendances du scraper de votre Python système.
Problèmes de chemin et d’encodage sous Windows
Problème : l’invite de commande Windows (CMD) a des problèmes d’encodage et des limites de longueur de chemin qui cassent les installations de scrapers, surtout quand Playwright télécharge les binaires de navigateur dans des dossiers très imbriqués.
Solution : utilisez WSL (Windows Subsystem for Linux) ou Git Bash à la place de CMD. WSL vous donne un environnement Linux complet dans Windows :
1wsl --install
2# Ouvrez ensuite un terminal WSL et suivez les étapes d’installation LinuxLe raccourci Docker : éviter entièrement les problèmes de dépendances
Problème : tout ce qui précède.
Solution : si Docker vous est familier, conteneurisez l’environnement du scraper. Un Dockerfile de base pour un TikTok scraper en Python ressemble à ceci :
1FROM python:3.11-slim
2RUN apt-get update && apt-get install -y libnss3 libatk-bridge2.0-0 libdrm2 libxcomposite1 libxdamage1 libxrandr2 libgbm1 libasound2
3RUN pip install TikTokApi playwright && python -m playwright install --with-deps chromium
4WORKDIR /app
5COPY . .
6CMD ["python", "scrape.py"]Cela garantit un environnement reproductible, quel que soit votre OS hôte. Si le scraper fonctionne dans Docker, toute panne en dehors de Docker est un problème d’environnement, pas de code.
Arbre de dépannage :
- Le dépôt peut-il exécuter son propre exemple avec succès ? → Si non, vérifiez la version d’exécution.
- Version d’exécution correcte ? → Vérifiez l’installation du navigateur/Playwright.
- Navigateur installé ? → Vérifiez les jetons/cookies.
- Jetons/cookies valides ? → Vérifiez si TikTok bloque la session.
- Tout échoue ? → Supposez une casse du dépôt, pas une erreur utilisateur. Changez d’outil.
Bonnes pratiques anti-bannissement pour le scraping TikTok (sans payer de proxies)
Les utilisateurs des forums se plaignent régulièrement des bannissements et de la détection : « ils font bannir vos comptes, ce qui ajoute un coût » et « sans utiliser Apify ou des API payantes coûteuses ». Voici des contournements gratuits et pratiques qui ne nécessitent pas d’abonnement proxy payant.

| Pratique | Difficulté | Coût | Efficacité |
|---|---|---|---|
| Délais aléatoires entre les requêtes (jitter de 2 à 8 s) | Facile | Gratuit | Modérée |
| Rotation des sessions/cookies | Moyen | Gratuit | Modérée |
| Scraping uniquement de pages publiques déconnectées | Facile | Gratuit | Modérée |
Respect de robots.txt + des en-têtes de limitation de débit | Facile | Gratuit | Baseline |
| Randomisation du fingerprint du navigateur headless (Playwright) | Moyen | Gratuit | Élevée |
| Utilisation des endpoints API mobiles de TikTok (détection plus faible) | Difficile | Gratuit | Élevée |
| Rotation de proxies résidentiels | Moyen | 20–100 $/mois | Élevée |
Techniques gratuites qui aident vraiment
Délais aléatoires entre les requêtes. N’envoyez pas les requêtes en boucle serrée. Ajoutez un délai aléatoire de 2 à 8 secondes entre les requêtes. C’est la chose la plus simple à faire :
1import time, random
2time.sleep(random.uniform(2, 8))Réutilisation des sessions et des cookies. Ne créez pas une nouvelle session à chaque requête. Réutilisez les cookies et l’état de session sur un lot de requêtes, puis faites une rotation. C’est exactement pour cela que les dépôts modernes demandent ms_token plutôt que de promettre un scraping sans état.
Scraper des pages publiques déconnectées. qu’il ne prend pas en charge les routes authentifiées par l’utilisateur et ne fonctionne que sur les données visibles lorsque vous êtes déconnecté. Le scraping en mode déconnecté a un profil de détection plus faible que les sessions authentifiées.
Respecter robots.txt. Le bloque de nombreux agents en totalité et n’autorise qu’un ensemble limité de chemins publics pour le crawl général. Ce n’est pas un feu vert pour un scraping agressif, mais le respecter réduit le risque de blacklistage IP immédiat.
Techniques intermédiaires pour augmenter les taux de réussite
Randomisation du fingerprint du navigateur headless. Si vous utilisez Playwright, randomisez la taille de la fenêtre, la chaîne user-agent, le fuseau horaire et la locale à chaque session. Votre scraper semblera ainsi être un utilisateur réel différent à chaque fois, plutôt que le même bot avec une nouvelle IP.
Utilisation des endpoints API mobiles de TikTok. Certains membres de la communauté signalent des taux de détection plus faibles en ciblant des endpoints de type mobile plutôt que l’interface web. C’est plus difficile à implémenter et moins documenté, mais c’est une vraie technique pour les utilisateurs avancés.
Quand vous avez vraiment besoin d’un proxy (et options abordables)
À grande échelle, les techniques gratuites ne suffisent pas. La rotation de proxies résidentiels est l’approche standard pour le scraping TikTok à gros volume. Je ne recommanderai pas ici un service proxy payant précis, mais le conseil général est le suivant : évitez les proxies de datacenter (TikTok les signale agressivement) et cherchez des pools de proxies résidentiels ou mobiles avec rotation par requête.
Autre option : les outils basés sur le navigateur comme contournent entièrement la question des proxies puisqu’ils fonctionnent dans votre propre session de navigateur et imitent un vrai utilisateur. Cela ne les rend pas invulnérables à la détection à grande échelle, mais pour les usages marketing ou recherche habituels (des dizaines à des centaines de pages, pas des millions), c’est une voie bien plus simple.
Quelles données obtenez-vous réellement ? Exemples de sortie réels des TikTok Scrapers
Les utilisateurs veulent savoir quelles données ils vont réellement obtenir avant de s’engager sur un outil — et la plupart des guides passent complètement ce point sous silence. Voici des structures de champs représentatives, fondées sur la documentation source.
Données de profil
| Nom d’utilisateur | Nom affiché | Abonnés | Abonnements | Total des likes | Bio | Vérifié | URL du profil |
|---|---|---|---|---|---|---|---|
| @examplecreator | Jane Doe | 1,240,000 | 312 | 48,700,000 | "Cooking + comedy 🍳" | ✅ | tiktok.com/@examplecreator |
| @travelwithmark | Mark S. | 890,000 | 150 | 22,100,000 | "Travel vlogger 🌍" | ❌ | tiktok.com/@travelwithmark |
| @fitnessmaya | Maya L. | 2,100,000 | 88 | 91,300,000 | "Workouts & wellness" | ✅ | tiktok.com/@fitnessmaya |
Disponible via : scrapers GitHub (TikTok-Api, Evil0ctal), Research API, Thunderbit (à partir des pages de profil visibles).
Métadonnées vidéo
| URL de la vidéo | Légende | Vues | Likes | Commentaires | Partages | Musique | Hashtags | Date de publication | Durée |
|---|---|---|---|---|---|---|---|---|---|
| tiktok.com/@ex/video/123 | "Best pasta trick ever 🍝" | 4,200,000 | 312,000 | 8,400 | 21,000 | "Italian Vibes – DJ Marco" | #pasta #cooking #hack | 2026-03-15 | 0:42 |
| tiktok.com/@ex/video/456 | "POV: your cat judges you" | 9,100,000 | 1,100,000 | 23,000 | 55,000 | "Original Sound" | #cat #pov #funny | 2026-04-01 | 0:18 |
| tiktok.com/@ex/video/789 | "Morning routine nobody asked for" | 1,800,000 | 98,000 | 3,200 | 7,500 | "Chill Morning – LoFi" | #routine #morning | 2026-04-10 | 1:02 |
Disponible via : scrapers GitHub (TikTok-Api, Evil0ctal), (les champs incluent video_description, view_count, like_count, comment_count, share_count, music_id, hashtag_names, video_duration), Thunderbit ().
Données de commentaires
| Commentateur | Texte du commentaire | Likes | Horodatage | Réponses |
|---|---|---|---|---|
| @user_abc | "I tried this and it actually works 😂" | 1,200 | 2026-03-16T08:12:00Z | 14 |
| @chef_dan | "Add garlic next time, trust me" | 890 | 2026-03-16T09:45:00Z | 7 |
| @randomfan99 | "This is the content I'm here for" | 340 | 2026-03-16T11:30:00Z | 2 |
Disponible via : scrapers GitHub (TikTok-Api, Evil0ctal), (les champs incluent text, like_count, reply_count, create_time), Thunderbit (à partir des sections de commentaires visibles).
Données de hashtags et de recherche
| Hashtag | URL de la meilleure vidéo | Vues cumulées | Tendance |
|---|---|---|---|
| #pasta | tiktok.com/@ex/video/123 | 4,200,000 | Yes |
| #cooking | tiktok.com/@chef/video/321 | 11,000,000 | Yes |
| #hack | tiktok.com/@tips/video/654 | 2,900,000 | No |
Disponible via : scrapers GitHub (variable selon le dépôt), Thunderbit ().
Remarque : aucun dépôt ne garantit tous les champs à tout moment. Les structures de réponse de TikTok changent, et même les mainteneurs le signalent. Considérez ces exemples comme représentatifs, pas garantis.
Comment extraire les données TikTok en 2 clics avec Thunderbit (étape par étape)
Fatigué du cycle casse/répare ? Voici la voie no-code — la porte de sortie pour tous ceux qui ont essayé les dépôts GitHub sans succès.
- Installez l’.
- Accédez à la page TikTok que vous voulez extraire — un profil, une page de résultats de recherche, une page de hashtag ou une vidéo individuelle.
- Cliquez sur « AI Suggest Fields ». L’IA de Thunderbit lit la page et suggère des colonnes : nom d’utilisateur, abonnés, légende de la vidéo, likes, hashtags, etc.
- Ajustez les champs si nécessaire, puis cliquez sur « Scrape ». Les données se remplissent dans un tableau structuré.
- Utilisez le scraping de sous-pages pour enrichir les données. Ouvrez chaque vidéo depuis une liste de profil et récupérez des champs supplémentaires : légende complète, détails de la musique, nombre de commentaires, nombre de partages.
- Exportez vers Google Sheets, Excel, Airtable ou Notion — entièrement gratuit.
Pas de maintenance, pas de tri d’installation, pas de configuration anti-bannissement. L’IA s’adapte automatiquement aux changements de mise en page de TikTok.
Enrichir les données TikTok avec le scraping de sous-pages
Après avoir extrait une liste de vidéos depuis un profil ou une page de hashtag, cliquez sur « Scrape Subpages » pour que l’IA visite chaque page vidéo et récupère des champs supplémentaires. C’est particulièrement utile pour les marketeurs qui construisent des bases de données d’influenceurs ou mènent des audits de contenu concurrentiel : vous obtenez un tableau complet des données d’engagement au niveau vidéo sans cliquer manuellement sur des dizaines de pages.
Exporter et exploiter vos données TikTok
Thunderbit exporte vers Google Sheets, Excel, Airtable, Notion, CSV ou JSON — gratuitement. Cas d’usage fréquents :
- Déposer les données dans un tableur pour analyser l’engagement.
- Envoyer vers Airtable pour un suivi d’influenceurs de type CRM.
- Alimenter Notion pour la collaboration d’équipe sur la recherche de contenu.
Pour aller plus loin sur la façon dont Thunderbit traite l’extraction de données web, consultez notre ou regardez les tutoriels sur la .
Rester dans la légalité : conditions d’utilisation de TikTok et conformité du scraping
La position juridique de TikTok est claire. La de la plateforme indique que ses Conditions d’utilisation interdisent les scripts automatisés qui collectent des informations ou interagissent avec le service de manière non autorisée, et mentionnent explicitement le contournement des restrictions d’accès. Les de TikTok interdisent également les tentatives trompeuses d’obtenir des informations via des scripts automatisés ou du web crawling.
Conseils pratiques :
- Limitez-vous aux données publiquement disponibles. Ne scrapez pas de contenu privé ou protégé par connexion.
- Respectez les limites de débit. Ne surchargez pas les serveurs de TikTok.
- Respectez les lois sur la protection des données. Le RGPD et le CCPA s’appliquent toujours si vous collectez, stockez ou analysez des données personnelles.
- Utilisez la Research API lorsque vous y êtes éligible. C’est l’option la plus sûre du point de vue conformité.
- Ceci n’est pas un avis juridique. Consultez un professionnel pour votre situation précise.
Pour en savoir plus sur le cadre légal, consultez notre guide sur les .
Que faire quand votre dépôt GitHub de TikTok Scraper meurt
Version courte :
- Exécutez toujours la checklist des dépôts en 60 secondes avant de cloner n’importe quel TikTok scraper depuis GitHub. La plupart des dépôts sont déjà morts.
- Comprenez vos options. API officielle, scrapers GitHub et outils no-code servent chacun des utilisateurs et des cas d’usage différents.
- Si vous passez par GitHub, prévoyez du temps pour le dépannage d’installation et la configuration anti-bannissement. Attendez-vous à une maintenance continue.
- Sachez quelles données vous obtiendrez réellement avant de vous engager sur un outil. Vérifiez les champs de sortie, pas seulement le nombre d’étoiles.
- Si vous n’êtes pas développeur (ou si vous en avez assez des dépôts cassés), essayez un outil no-code comme — deux clics, données structurées, export gratuit.
Les données TikTok dont vous avez besoin sont accessibles. La vraie question est de savoir si vous voulez passer votre temps à maintenir un scraper ou à utiliser réellement les données. Choisissez l’approche qui correspond à votre niveau et à votre cas d’usage, et ne laissez pas un dépôt GitHub mort vous faire perdre un après-midi de plus.
FAQ
Existe-t-il encore des TikTok Scrapers sur GitHub qui fonctionnent en 2026 ?
Oui, mais la liste est courte. est l’option open source la plus crédible, avec une maintenance active en avril 2026. est aussi vivant, mais plus complexe. Le dépôt le plus étoilé, drawrowfly/tiktok-scraper, n’a pas été mis à jour depuis mai 2023 et est de fait mort. Exécutez toujours la checklist des dépôts avant d’investir du temps dans un dépôt.
Est-il légal de scraper TikTok ?
Les Conditions d’utilisation de TikTok interdisent explicitement le scraping automatisé. Les données visibles publiquement se situent dans une zone grise juridique qui varie selon la juridiction. La voie la plus sûre est l’ officielle pour les chercheurs éligibles. Si vous scrapez des données publiques, limitez-vous au contenu accessible publiquement, respectez les limites de débit et conformez-vous au RGPD/CCPA. Ceci n’est pas un avis juridique — consultez un professionnel pour votre situation.
Puis-je scraper TikTok sans coder ?
Oui. Des outils d’IA basés sur le navigateur comme vous permettent d’extraire des données TikTok structurées (profils, métadonnées vidéo, hashtags, métriques d’engagement) sans écrire une seule ligne de code. La TikTok Research API exige aussi très peu de code pour les candidats approuvés. Pour les non-développeurs, les outils no-code sont la voie la plus rapide et la plus fiable.
Quelles données puis-je obtenir avec un TikTok scraper ?
Les types de données courants incluent les informations de profil (nom d’utilisateur, abonnés, bio, statut vérifié), les métadonnées vidéo (légende, vues, likes, commentaires, partages, musique, hashtags, durée, date de publication), les commentaires (texte, likes, horodatage, réponses) et les données de hashtags/recherche (meilleures vidéos, vues cumulées, statut tendance). Les champs exacts dépendent de l’outil et de la méthode — voyez la section des exemples de sortie ci-dessus pour plus de détails.
Pourquoi mon TikTok scraper continue-t-il d’être bloqué ?
TikTok utilise plusieurs couches de défense anti-bot : limitation du débit, protection par cookies/session, fingerprinting du navigateur, détection comportementale, paramètres de requête chiffrés et flux CAPTCHA. Les causes courantes de blocage incluent l’envoi de requêtes trop rapides, l’utilisation d’une session propre/nouvelle pour chaque requête, l’exécution d’un navigateur headless avec des fingerprints par défaut ou l’usage de proxies de datacenter. Voir plus haut la section sur les bonnes pratiques anti-bannissement pour des contournements gratuits et payants.