

« J’ai besoin des prix, des descriptions et des données de variantes de 14 boutiques Shopify concurrentes — et il me faut tout ça pour vendredi. » Voilà le message qu’un de nos utilisateurs nous a envoyé la semaine dernière. Faites le calcul : environ 4 000 pages produits. À la main, en copiant-collant ? Autant abandonner tout de suite.
Quiconque a déjà tenté de récupérer les données d’une boutique Shopify — prix, images, descriptions, variantes, avis — connaît la galère. On dénombre aujourd’hui plus de 2,8 millions de boutiques Shopify en activité, et pas une seule ne vous tend un bouton « exportez tout, c’est cadeau ». Le contexte explique pourtant cette demande : 72 % des entreprises surveillent activement la tarification de leurs concurrents, et côté gestion de catalogue, les prestataires e-commerce estiment que publier manuellement un seul produit — avec ses variantes et ses images — réclame 15 à 30 minutes. Étalez ce chiffre sur quelques centaines de références : votre semaine est déjà engloutie.
Les extensions Chrome dédiées au scraping Shopify se sont donc imposées comme un réflexe dans la trousse à outils e-commerce — pour la veille concurrentielle, la prospection de produits en dropshipping, la migration de catalogue, et bien d’autres usages. Le souci, c’est que la majorité des articles « top des scrapers » se contentent d’empiler des cases de fonctionnalités, sans jamais montrer ce qu’il advient réellement quand on les lâche sur de vraies vitrines. Mon approche est l’inverse : j’ai mis huit extensions à l’épreuve sur de vraies boutiques, je me suis cogné à de vrais dispositifs anti-bot, et j’ai trié les outils qui livrent des données produits riches de ceux qui restent collés à la surface.
Pourquoi une extension Chrome Shopify Scraper est devenue incontournable pour les équipes e-commerce
Une boutique Shopify, c’est une mine de données produits à forte valeur commerciale. Sauf que, vu de l’extérieur, aucun fichier CSV ne vous attend en téléchargement. Vous n’avez que la vitrine. Pour la convertir en renseignement exploitable, il faut un scraper — et les usages dépassent de loin le simple « récupérer une liste de noms de produits ».
La vraie question à se poser : de quelles données avez-vous besoin, et au service de quel flux de travail ? Voyons comment les usages e-commerce les plus répandus se traduisent en champs concrets.
Veille tarifaire sur la concurrence
Ce qu’il vous faut : titres des produits, prix, prix barrés et tarification au niveau de chaque variante. C’est la matière première d’une tarification dynamique : ne pas se limiter au montant affiché par un concurrent, mais comprendre sa mécanique de remises, sa façon de monter des packs, ses ajustements selon la taille ou la couleur.
Prospection de produits pour le dropshipping
Ce qu’il vous faut : titres, l’intégralité des images (et pas seulement les vignettes), descriptions complètes et dates de publication. Un tri par date de mise en ligne la plus récente vous met sur la piste des produits en train de décoller ou tout juste lancés, avant que le marché ne s’en empare.
Import de catalogue vers votre propre boutique
Ce qu’il vous faut : titres, HTML du corps, toutes les images, variantes, SKU et prix — de préférence dans un CSV directement importable dans Shopify. Et là, attention : tous les outils ne génèrent pas un fichier propre.
Estimation du rythme des ventes
Ce qu’il vous faut : titres des produits et quantités en stock, relevés à intervalles réguliers. En photographiant les niveaux de stock dans le temps, vous déduisez la vitesse d’écoulement des produits chez un concurrent — un indicateur imparfait, mais précieux quand les chiffres de ventes réels restent hors d’atteinte.
Génération de leads (repérer les propriétaires de boutiques)
Ce qu’il vous faut : nom de la boutique, e-mail de contact, numéro de téléphone, et parfois les applications ou la pile technique sur laquelle elle tourne. Les équipes commerciales bâtissent ainsi des listes de prospection découpées par niche ou par technologie.
Un repère synthétique pour s’y retrouver :
| Cas d’usage | Champs de données clés nécessaires | Flux de travail recommandé |
|---|---|---|
| Étude des prix concurrents | Titre, prix, prix barré, prix des variantes | Extraire la page de listing + enrichissement des sous-pages pour les variantes |
| Recherche de produits en dropshipping | Titre, prix, images (toutes), description, date de publication | Extraction des sous-pages + tri par date de publication la plus récente |
| Import de catalogue dans votre boutique | Titre, HTML du corps, images, variantes, SKU, prix | Extraction complète des sous-pages → export en CSV compatible Shopify |
| Estimation des ventes | Titre, quantité en stock (dans le temps) | Extraction programmée → suivi dans Google Sheets |
| Génération de leads (propriétaires de boutiques) | Nom de la boutique, e-mail, téléphone, applications utilisées | Extraction des pages de contact + extracteurs d’e-mails/téléphones |
Ma méthode pour départager ces 8 extensions Chrome Shopify Scraper
J’ai installé les huit extensions et je les ai soumises au même protocole : un panel identique de vraies boutiques Shopify — des publiques, des protégées par Cloudflare, et d’autres dont le products.json était désactivé. Pas question de me contenter de relever des fiches techniques. Ce que je voulais observer, c’est le comportement réel de chaque outil au moment où l’on clique sur « scrape » sur une page de collection Shopify en direct.
Huit critères ont structuré l’évaluation, chacun choisi pour ce qu’il révèle dans le contexte Shopify :
| Critère | Pourquoi c’est important pour le scraping Shopify |
|---|---|
| Facilité de configuration | Un dropshipper non technique peut-il commencer à extraire des données en moins de 5 minutes ? |
| Champs de données extraits | Récupère-t-il le titre, le prix, les images, les descriptions, les variantes ET les avis — ou seulement des données de surface ? |
| Enrichissement des sous-pages | Peut-il extraire une page de listing puis visiter automatiquement chaque page produit pour récupérer les détails complets ? |
| Gestion de la pagination | Peut-il extraire au-delà de la première page de produits (clic sur la pagination ou défilement infini) ? |
| Résistance aux bots | Gère-t-il les Turnstiles de Cloudflare ou la protection anti-bot de Shopify sans casser ? |
| Formats d’export | CSV, Excel, Google Sheets, Airtable, Notion, CSV prêt pour Shopify ? |
| Extraction programmée/récurrente | Peut-il surveiller automatiquement les prix ou les variations de stock au fil du temps ? |
| Transparence tarifaire | Limites de l’offre gratuite, système de crédits, forfait fixe — et ce que vous obtenez réellement |
Voyons maintenant, à l’aune de cette grille, comment chaque outil se comporte.
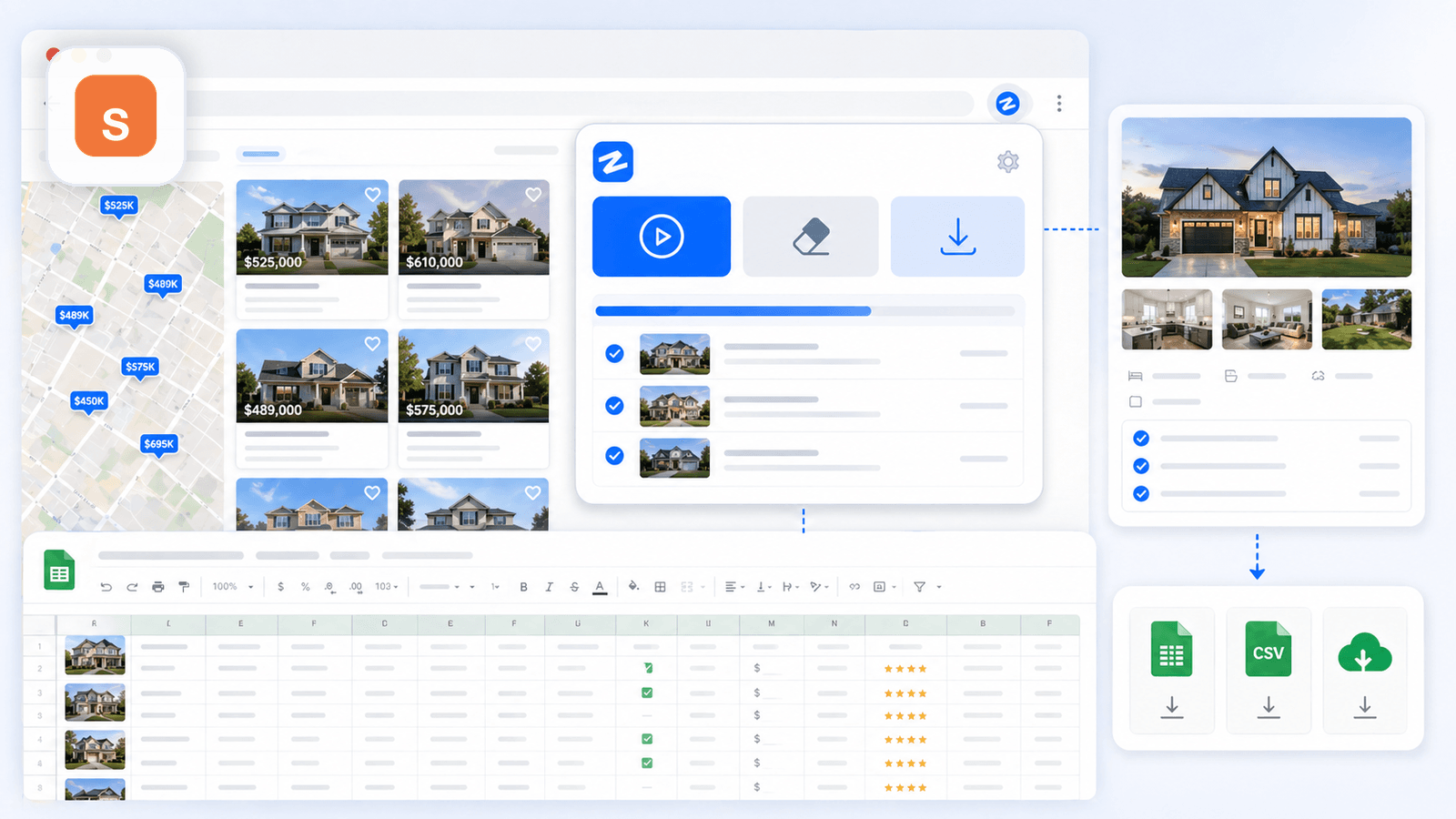
1. Thunderbit — Le scraper Shopify propulsé par l’IA, conçu pour ceux qui ne codent pas
Thunderbit, c’est l’outil que nous développons en interne, pensé pour les profils métier qui veulent des données produits détaillées sans toucher au code, sans paramétrer de sélecteurs CSS, sans y consacrer vingt minutes de préparation. Sur une boutique Shopify, le flux tient véritablement en deux clics : vous ouvrez une page de collection, vous cliquez sur « Suggestion de champs IA », et l’IA parcourt la page pour proposer des colonnes (titre, prix, image, etc.). Un clic sur « Extraire », et la page de listing est bouclée.
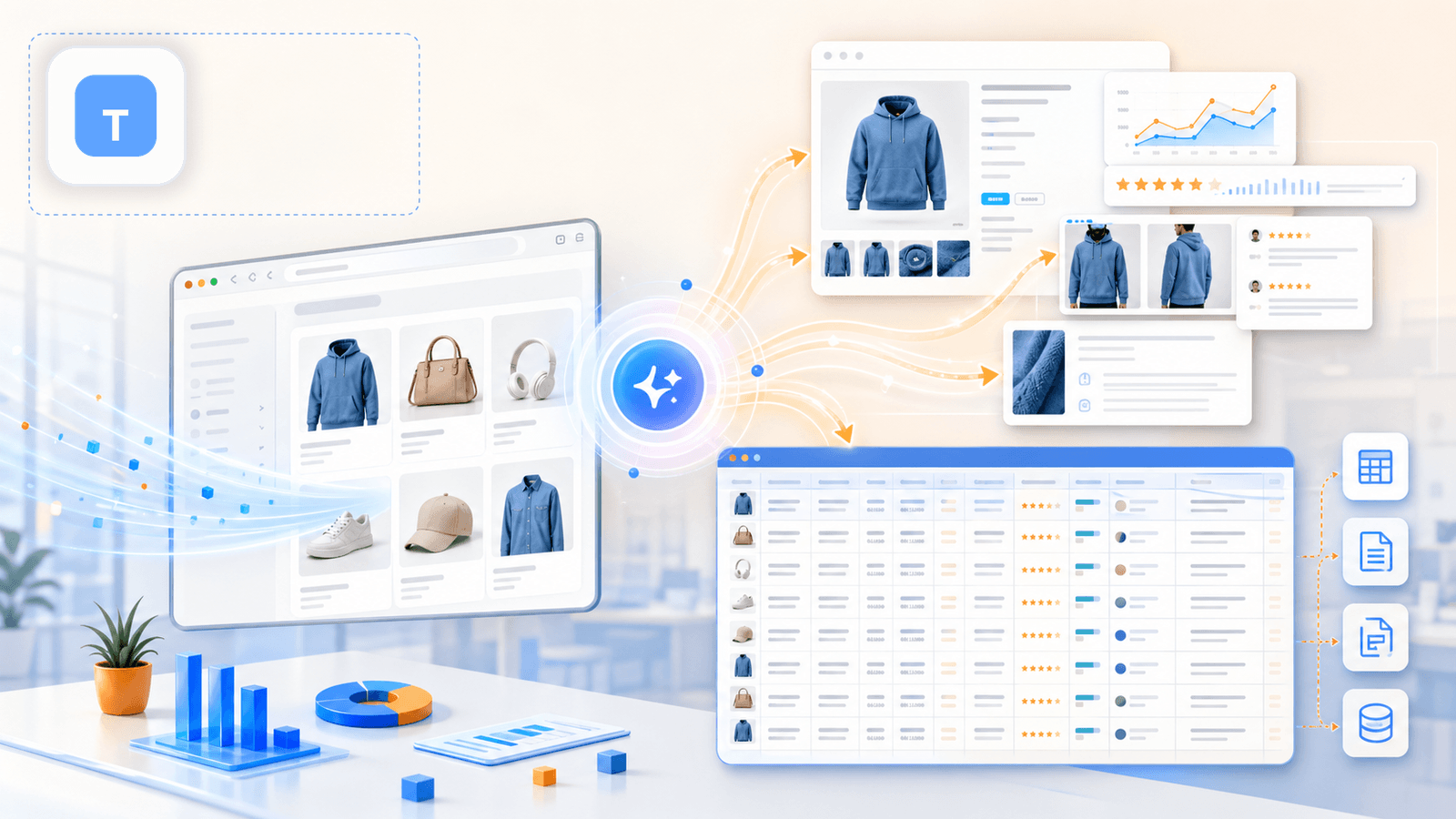
Mais le vrai facteur de différenciation — celui que la plupart des comparatifs passent sous silence — se joue dans l’étape suivante.
Enrichissement des sous-pages : la fonctionnalité qui fait basculer le résultat
Une fois la page de listing extraite, un clic sur « Extraire les sous-pages » suffit. L’IA de Thunderbit ouvre alors chaque URL produit l’une après l’autre et vient compléter votre tableau initial avec les informations des pages détail : descriptions intégrales, galerie complète d’images, options de variantes, SKU, nombre d’avis, et le reste. C’est précisément cette étape qui fait passer un tableau anémique au rang de jeu de données réellement exploitable pour l’analyse concurrentielle.
J’y reviens plus bas, dans une section entièrement dédiée, avec une comparaison avant/après à l’appui.
Points forts pour le scraping Shopify
- Suggestion de champs IA lit la page Shopify et génère automatiquement la bonne structure de colonnes — aucun sélecteur CSS, aucune configuration manuelle
- Extraction des sous-pages complète les données manquantes des pages de listing (descriptions complètes, options de variantes, galeries d’images, avis)
- Mode de scraping cloud pour une extraction rapide et massive sur les boutiques publiques ; mode navigateur pour les boutiques protégées par Cloudflare ou nécessitant une connexion
- Gestion de la pagination (par clic et défilement infini)
- Extraction programmée pour un suivi continu des prix et des stocks — décrivez simplement le planning en langage naturel (par exemple : « tous les lundis à 9 h »)
- Extracteurs gratuits d’e-mails et de numéros de téléphone pour les cas de génération de leads
- Export vers Excel, Google Sheets, Airtable, Notion, CSV, JSON — y compris des formats adaptés à l’import Shopify
- Invite IA de champ vous permet d’ajouter des consignes personnalisées par colonne (par exemple : « classer en 3 types de produits » ou « traduire la description en anglais »)
Ses limites
- La tarification basée sur des crédits implique qu’une extraction à très grande échelle (des dizaines de milliers de produits) suppose un forfait payant
- Le traitement par l’IA ajoute quelques secondes par ligne par rapport aux scrapers fondés sur des modèles, sur des pages vraiment simples
Tarification
- Niveau gratuit : 6 pages (ou jusqu’à 10 avec l’essai gratuit), exports gratuits
- Starter : 15 $/mois (environ 14 €/mois), 500 crédits/mois
- Forfaits Professionnels : de 38 $/mois (environ 35 €/mois, 3 000 crédits) jusqu’à 249 $/mois (environ 230 €/mois, 20 000 crédits)
- Règles des crédits : 1 ligne de sortie = 1 crédit pour le scraping web ; 1 ligne de sortie = 2 crédits pour le scraping de sous-pages ; les exports sont toujours gratuits
Idéal pour : les équipes e-commerce non techniques qui visent les données produits Shopify les plus complètes avec un minimum de paramétrage — et qui veulent garder leurs concurrents à l’œil sur la durée.
Essayer Thunderbit pour le scraping Shopify
2. Instant Data Scraper — L’auto-détection sans la moindre configuration
Instant Data Scraper est une extension Chrome gratuite qui s’appuie sur des heuristiques pour repérer automatiquement les données tabulaires d’une page web. Rien à régler : vous ouvrez une page de collection Shopify, vous cliquez sur l’icône de l’extension, et elle tente de détecter puis d’afficher les données produit dans un tableau.
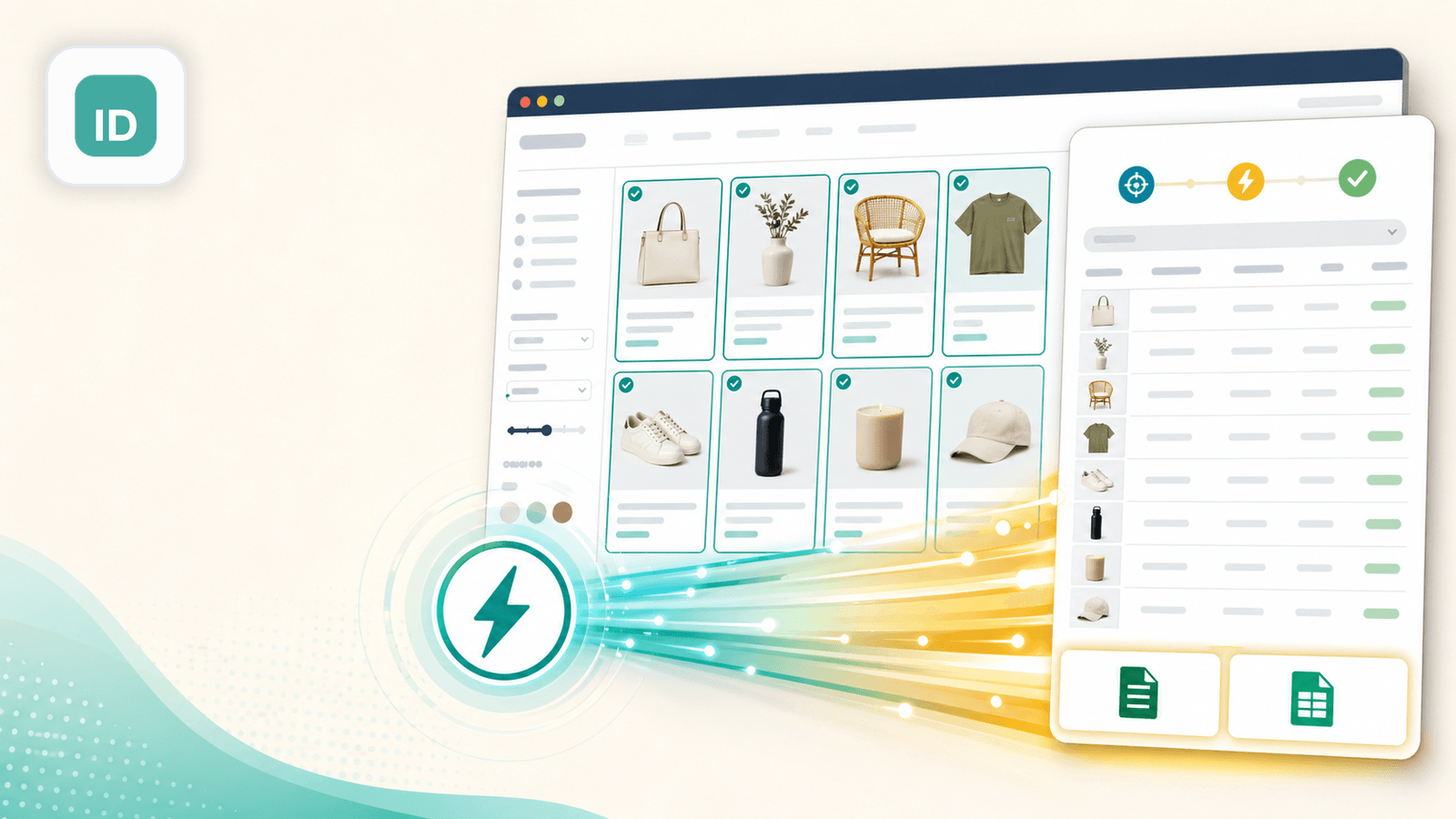
À l’usage, elle s’en sort très bien sur les pages de collection Shopify standard sous le thème Dawn, ramenant en quelques secondes titres, prix et URL des vignettes. Sur des boutiques à la mise en page atypique, elle a parfois ramassé des liens de navigation ou du contenu de pied de page au lieu des produits — d’où la nécessité de relire le résultat à l’œil avant de l’exploiter.
Points forts pour le scraping Shopify
- Totalement gratuit, sans limite d’utilisation
- L’auto-détection supprime le temps de configuration — pratique pour des exports rapides et ponctuels
- Prend en charge la pagination (peut cliquer automatiquement sur la « page suivante »)
- Export vers CSV et XLSX
Ses limites
- L’auto-détection est inégale sur les boutiques Shopify à la mise en page non standard
- Aucun enrichissement des sous-pages : vous obtenez ce qui se trouve sur la page de listing (titre, prix, miniature), mais pas les descriptions complètes, variantes ou avis
- Pas d’IA pour nettoyer, étiqueter ou transformer les données
- Pas de planification, pas de scraping cloud
- Pas d’export direct vers Google Sheets, Airtable ou Notion
Tarification
- Entièrement gratuit
Idéal pour : toute personne qui cherche un export rapide, gratuit et sans réglage des données visibles d’une page de listing Shopify standard.
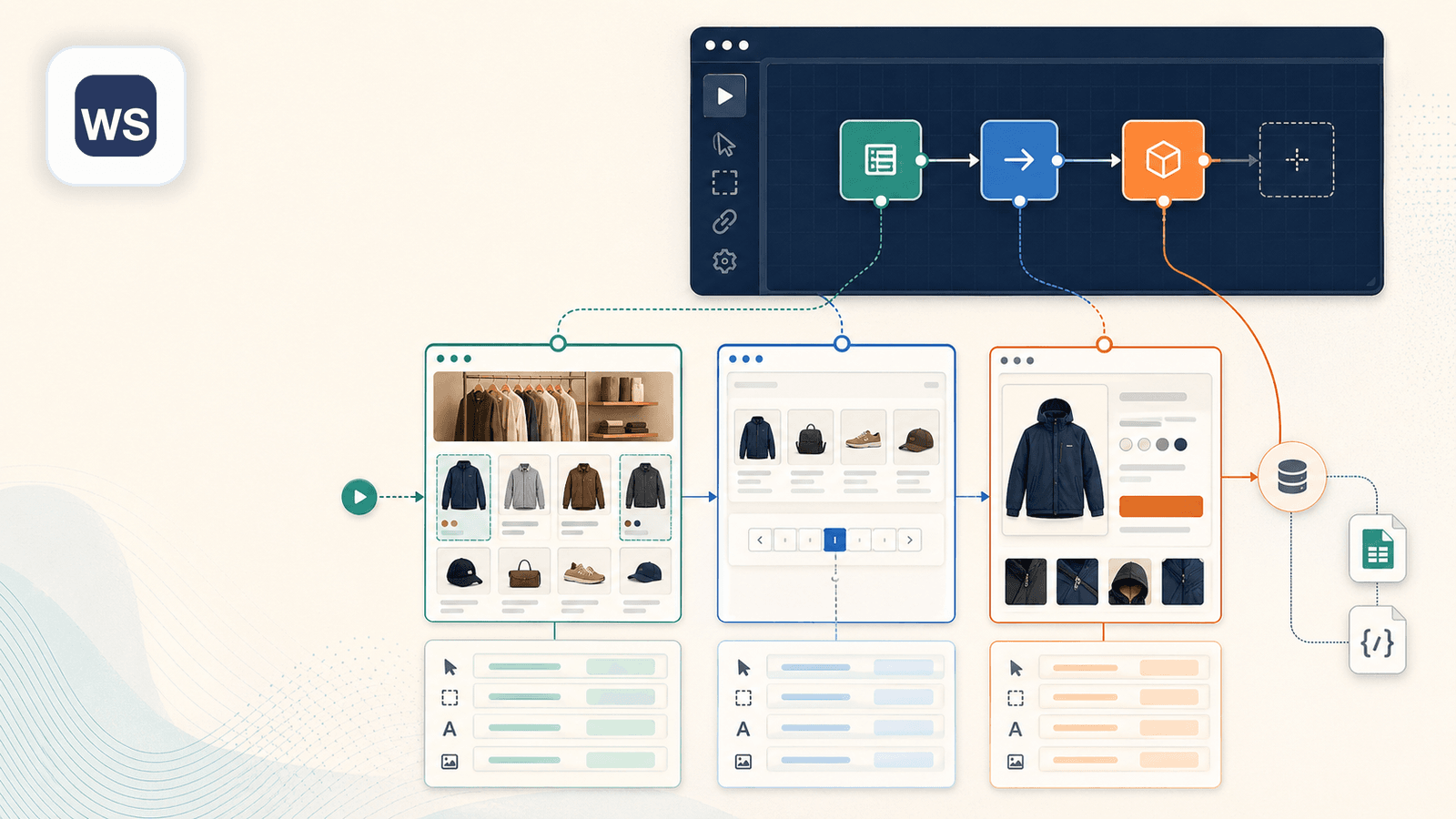
3. Web Scraper — Le constructeur visuel de sitemaps
Web Scraper (webscraper.io), c’est l’extension Chrome historique en point-and-click pour bâtir des « sitemaps » — autrement dit des recettes d’extraction où vous désignez les éléments de la page et définissez un parcours d’extraction. Sur Shopify, vous construiriez un sitemap en pointant les titres de produits, les prix, les images, avant de poser les règles de pagination et de suivi des liens.
Points forts pour le scraping Shopify
- Le générateur visuel de sélecteurs offre plus de contrôle que les outils d’auto-détection
- Peut suivre les liens vers les sous-pages (pages détail produit) — mais vous devez configurer manuellement les sélecteurs parent-enfant dans le sitemap
- Gère la pagination avec une configuration correcte
- Scraping gratuit dans le navigateur ; plans cloud payants disponibles (à partir de 50 $/mois, environ 46 €/mois)
- Export vers CSV ; les plans cloud prennent en charge Google Sheets et d’autres formats
Ses limites
- La configuration prend plus de temps : monter un sitemap avec ses sélecteurs parent-enfant m’a demandé une quinzaine de minutes pour une boutique Shopify inédite
- L’extraction des sous-pages exige une configuration manuelle des sélecteurs de liens et des sitemaps enfants — on est loin de l’enrichissement en un clic
- Les sitemaps cèdent dès qu’une boutique Shopify retouche sa mise en page ou ses classes CSS
- La courbe d’apprentissage est plus rude que celle des alternatives propulsées par l’IA
Tarification
- Extension navigateur : gratuite
- Plans cloud : Project 50 $/mois (environ 46 €/mois), Professional 100 $/mois (environ 92 €/mois), Scale à partir de 200 $/mois (environ 185 €/mois)
Idéal pour : les utilisateurs techniques qui veulent piloter finement leur parcours d’extraction et n’ont aucune appréhension à monter la recette eux-mêmes.
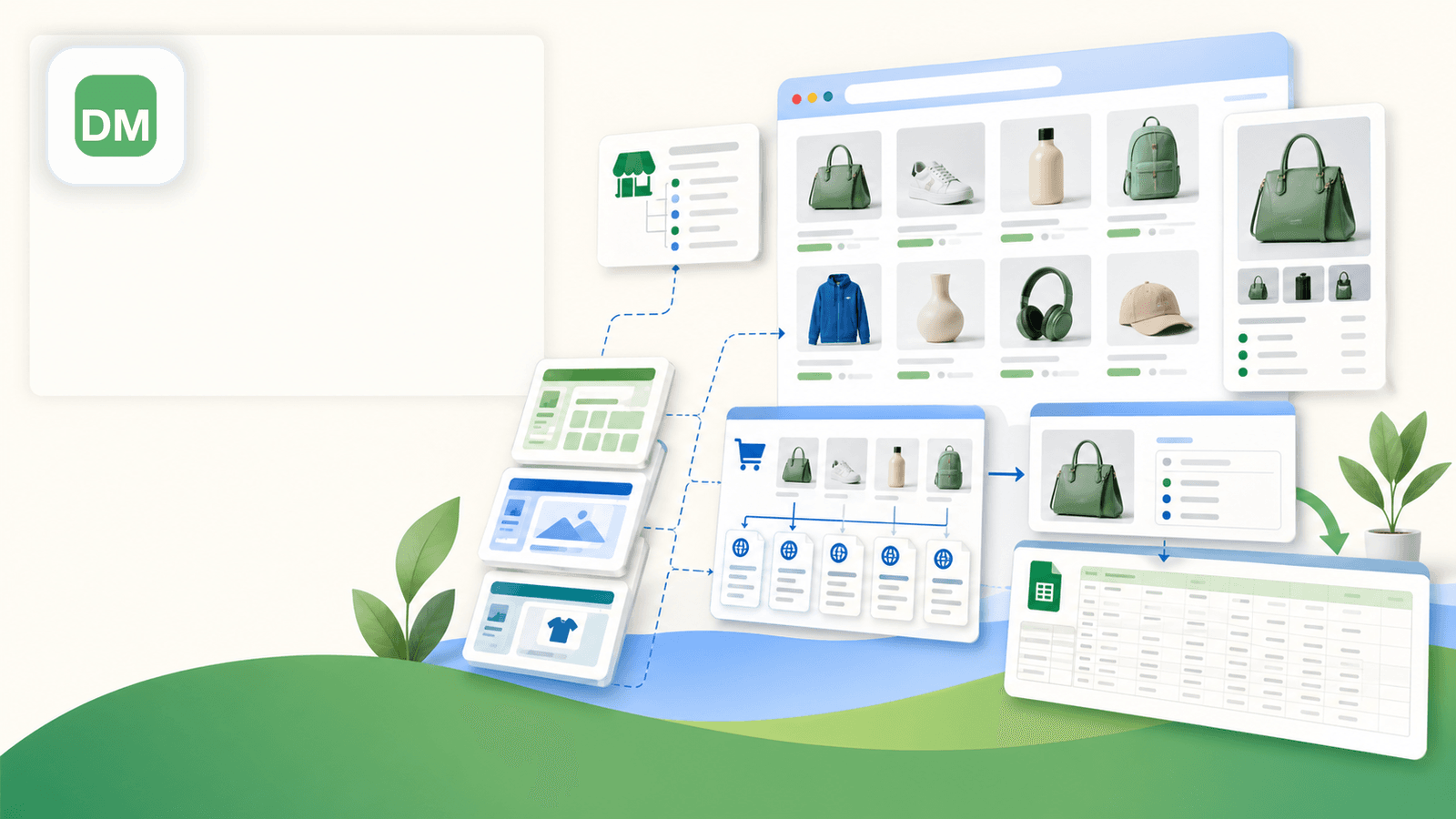
4. Data Miner — Le scraper qui carbure aux recettes
Data Miner (dataminer.io) fonctionne sur le principe des « recettes » — des modèles d’extraction, préconstruits ou faits maison, que vous appliquez à une page. Une bibliothèque publique de recettes existe : vous pouvez donc dénicher un modèle Shopify partagé par un autre utilisateur, ou composer le vôtre en sélectionnant les éléments de la page.
Points forts pour le scraping Shopify
- La bibliothèque de recettes peut contenir des modèles Shopify prêts à l’emploi partagés par d’autres utilisateurs
- Générateur visuel de recettes pour les configurations d’extraction personnalisées
- Gère la pagination via la configuration de la recette
- Exporte vers CSV, Excel, Google Sheets et TSV
- Flux de travail de crawl pour visiter les pages détail après les pages de liste
Ses limites
- L’offre gratuite plafonne à 500 pages/mois
- Les recettes reposent sur des sélecteurs CSS : elles lâchent dès qu’une boutique change de mise en page
- Aucune suggestion de champs ni transformation de données par l’IA
- Pas de flux d’enrichissement des sous-pages en un clic — il faut une recette de crawl distincte pour les pages détail
- Des crawls programmés existent, mais la planification n’est pas des plus intuitives
Tarification
- Gratuit : 500 pages/mois
- Solo : 19,99 $/mois (environ 18 €/mois)
- Small Business : 49 $/mois (environ 45 €/mois)
- Business : 99 $/mois (environ 91 €/mois)
- Business Plus : 200 $/mois (environ 185 €/mois)
Idéal pour : les utilisateurs qui aiment travailler à partir de modèles et veulent une bibliothèque de recettes pour gagner du temps de configuration sur les sites courants.
5. Simplescraper — L’extracteur tout en légèreté
Simplescraper (simplescraper.io), c’est une extension Chrome épurée doublée d’un scraper cloud, qui mise tout sur la simplicité. Vous cliquez sur les éléments de données d’une page Shopify, Simplescraper en déduit les sélecteurs CSS et récupère les données correspondantes.
Points forts pour le scraping Shopify
- Interface propre et minimaliste — rapide à prendre en main
- Scraping cloud disponible pour les tâches programmées et en volume
- Accès API pour les développeurs qui veulent intégrer les données extraites dans leurs flux de travail
- Export vers CSV, JSON, Google Sheets, Airtable et via webhooks
- Concept de deep scraping pour suivre les liens vers les pages détail
- Flux de travail compatibles avec la connexion pour les boutiques sensibles aux sessions
Ses limites
- Approche manuelle basée sur les sélecteurs — pas d’IA pour détecter automatiquement les champs
- L’extraction des sous-pages nécessite une configuration supplémentaire
- Communauté plus réduite et moins de modèles prêts à l’emploi que Web Scraper ou Data Miner
- Offre gratuite : 100 crédits (1 page rendue en JS = 2 crédits)
- La tarification des offres payantes est moins transparente sur le site officiel que chez la plupart des concurrents
Tarification
- Gratuit : 100 crédits
- Plans payants : des sources tierces indiquent Plus à environ 39 $/mois (environ 36 €/mois), Pro à environ 70 $/mois (environ 65 €/mois), Premium à environ 150 $/mois (environ 139 €/mois) (selon les données de tarification G2)
Idéal pour : les utilisateurs qui veulent un scraper cloud moderne, léger et bien intégré, et qui se passent volontiers de la détection de champs par IA.
6. Octoparse — L’extension Chrome adossée à une application de bureau
Octoparse (octoparse.com) est avant tout une application de bureau, complétée d’une extension Chrome. Elle réunit un générateur de flux visuel et des modèles préconstruits pour les sites populaires, dont un tutoriel d’extraction spécifique à Shopify.

Points forts pour le scraping Shopify
- Modèles Shopify préconstruits pour les tâches d’extraction courantes
- Puissante application desktop avec des fonctionnalités avancées : rotation d’IP, extraction programmée, extraction cloud
- Gère très bien la pagination, le défilement infini et le contenu chargé en AJAX
- La meilleure gestion anti-bot documentée de cette sélection, prise en charge automatique des CAPTCHA comprise
- Export vers CSV, Excel, JSON, HTML, XML, bases de données et Google Sheets
Ses limites
- L’extension Chrome seule reste bridée — l’essentiel des fonctions avancées passe par l’application desktop
- L’application desktop impose une courbe d’apprentissage plus rude avec son générateur de flux visuel
- L’offre gratuite est restreinte ; un usage réellement utile suppose un forfait payant
- Configuration plus lourde que les outils purement Chrome — peu adaptée à un scraping express en cinq minutes
- L’application desktop n’existe que sous Windows/Mac (rien qui tourne uniquement dans le navigateur)
Tarification
- Forfait gratuit disponible
- Basic : 39 $/mois (environ 36 €/mois)
- Standard : environ 83 $/mois (environ 77 €/mois en mensuel), environ 75 $/mois (environ 69 €/mois en annuel)
- Professional : environ 299 $/mois (environ 277 €/mois en mensuel), environ 208 $/mois (environ 192 €/mois en annuel)
- Enterprise : sur devis
Idéal pour : les équipes qui réclament un scraping de niveau entreprise avec rotation d’IP, gestion anti-bot et tâches cloud récurrentes — et que l’usage d’une application desktop ne rebute pas.
7. Bardeen — Le scraper qui pense automatisation avant tout
Bardeen (bardeen.ai) est une plateforme d’automatisation du navigateur qui mêle scraping web et orchestration de flux de travail. On y crée des « playbooks » capables d’extraire des données puis de les acheminer vers d’autres applications — sur le mode « si j’extrais ceci, alors je l’envoie à mon CRM ».

Points forts pour le scraping Shopify
- Automatisation des flux de travail au-delà du scraping : extraire des données Shopify → enrichir → envoyer au CRM ou au tableur dans un seul playbook
- Intégrations avec plus de 100 applications (Google Sheets, Airtable, Notion, HubSpot, Slack, etc.)
- Fonctionnalités propulsées par l’IA pour l’extraction et la classification des données
- Fonctionne dans le navigateur — aucune application desktop nécessaire
- Automatisations basées sur l’heure et la date pour la planification
Ses limites
- Outil d’automatisation avant tout, et non scraper dédié — ses fonctions d’extraction restent moins poussées que celles des outils spécialisés
- La construction de playbooks peut dérouter ceux qui veulent juste récupérer une liste de produits
- Offre gratuite limitée à 100 crédits
- L’enrichissement des sous-pages et la gestion de la pagination s’avèrent moins intuitifs que dans les scrapers dédiés
- Surdimensionné si votre seul besoin est d’extraire des données, sans automatisation en aval
Tarification
- Gratuit : 100 crédits
- Basic : 10 $/mois (environ 9 €/mois), 100 crédits/mois
- Premium : 50 $/mois (environ 46 €/mois), 1 000 crédits/mois (~40 $/mois, environ 37 €/mois, à l’année)
- Enterprise : sur devis
- Modèle de crédits : 1 crédit par ligne de scraper, 3 crédits par ligne d’enrichissement
Idéal pour : les équipes qui veulent extraire des données Shopify pour les propulser aussitôt dans des applications en aval (CRM, tableurs, Slack), au sein d’un même flux automatisé.
8. Listly — Le convertisseur de listes en tableur
Listly (listly.io) a été taillé pour une mission précise : transformer les listes et tableaux des pages web en données prêtes pour un tableur. Vous cliquez sur l’extension depuis une page de collection Shopify, et Listly cherche à détecter la liste de produits pour l’exporter sous forme de feuille de calcul.

Points forts pour le scraping Shopify
- Interface extrêmement simple — pensée pour l’extraction de listes en un clic
- Très bon pour détecter les structures de listes répétitives (comme les grilles de produits)
- Export direct vers Excel et Google Sheets
- Fonction d’extraction groupée pour traiter plusieurs URL d’un coup
- Planification disponible sur les forfaits Business
Ses limites
- Limité à ce que l’outil détecte automatiquement sur la page — aucune configuration de champs personnalisés
- Aucun enrichissement des sous-pages — exporte uniquement les données au niveau de la page de listing
- A du mal avec les thèmes Shopify non standards ou les boutiques avec un rendu JavaScript lourd
- L’offre gratuite est très limitée (10 URL/mois)
- Options d’export limitées par rapport aux concurrents (principalement Excel et Sheets)
Tarification
- Gratuit : 10 URL/mois, extraction de base sur 1 page, téléchargement Excel, export Google Sheet
- Light : 30 $/mois (environ 28 €/mois ; 187,20 $/an, soit environ 173 €/an)
- Business : 90 $/mois (environ 83 €/mois ; 993,60 $/an, soit environ 920 €/an) — ajoute extraction avancée, extraction groupée, planification, défilement/clic automatique, API bêta
Idéal pour : les utilisateurs qui veulent le trajet le plus court entre une page de collection Shopify et un tableur — et qui n’ont pas besoin de données produits approfondies.
Comparaison des 8 extensions Chrome Shopify Scraper
Voici le face-à-face complet. Plutôt que de cocher mécaniquement des cases, j’ai cherché à être précis dans chaque cellule — parce que « prend en charge la pagination » ne recouvre vraiment pas la même réalité d’un outil à l’autre.
| Outil | Facilité de configuration | Champs de données | Enrichissement des sous-pages | Pagination | Gestion anti-bot | Formats d’export | Planification | Offre gratuite / tarification |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | Très facile (piloté par l’IA, 2 clics) | Le plus fort pour les utilisateurs non techniques (l’IA suggère tous les champs pertinents) | Oui — enrichissement en un clic | Oui (clic + défilement infini) | Cloud pour les sites publics, navigateur pour les sites protégés | Sheets, Airtable, Notion, CSV, JSON, Excel | Oui (planification en langage naturel) | 6 pages gratuites ; payant à partir de 15 $/mois |
| Instant Data Scraper | Extrêmement facile (sans configuration) | Bien uniquement pour les données de niveau listing | Non | Oui (détection automatique de la page suivante) | Navigateur uniquement, pas de vraie gestion anti-bot | CSV, XLSX | Non | Gratuit |
| Web Scraper | Moyenne à difficile (sitemap manuel) | Flexible si le sitemap est bien construit | Oui, mais manuel via sélecteurs de liens | Oui (avec configuration du sitemap) | Navigateur en local ; rotation de proxy sur les plans cloud | CSV en local ; formats plus larges sur le cloud | Oui sur les plans cloud | Extension gratuite ; cloud à partir de 50 $/mois |
| Data Miner | Moyenne (basé sur des recettes) | Bon si une recette existe ou a été créée | Oui, mais configuration de crawl en plusieurs étapes | Oui (configuration de la recette) | Principalement côté navigateur | CSV, Excel, Sheets, TSV | Des crawls automatisés existent | 500 pages/mois gratuites ; payant à partir de 19,99 $/mois |
| Simplescraper | Facile à moyenne (basé sur les sélecteurs) | Solide pour une extraction légère | Le deep scraping existe, mais pas en un clic | Oui (défilement infini pris en charge) | Rotation de proxy et prise en charge des connexions | CSV, JSON, Sheets, Airtable, webhooks | Oui | 100 crédits gratuits ; forfaits payants disponibles |
| Octoparse | Plus difficile (application desktop) | Très solide une fois configuré | Oui, via workflows ou modèles | Oui (AJAX, défilement infini) | Le plus fort en anti-bot (rotation d’IP, CAPTCHA) | CSV, Excel, JSON, HTML, XML, bases de données, Sheets | Oui à partir de Standard | Gratuit ; Basic 39 $/mois ; cloud à partir d’environ 83 $/mois |
| Bardeen | Moyenne (créateur de playbooks) | Bon lorsqu’il est relié à une automatisation | Possible dans la logique de workflow, pas centré Shopify | Possible | Fonctionne dans le navigateur, l’anti-bot n’est pas son cœur de métier | CSV, Sheets, Airtable, Notion | Oui via automatisations | 100 crédits gratuits ; Basic 10 $/mois ; Premium 50 $/mois |
| Listly | Très facile (détection de liste en un clic) | Idéal pour les lignes de liste visibles uniquement | Non | Limité à la structure de liste détectée | Minimal | Excel, Sheets, API CSV/JSON sur Business | Oui sur Business | 10 URL/mois gratuites ; Light 30 $/mois ; Business 90 $/mois |
Le verdict express, classé par priorité
Pour les données produits Shopify les plus fouillées avec un minimum de configuration, le duo IA + enrichissement des sous-pages de Thunderbit reste la combinaison gagnante. Pour un export totalement gratuit et expéditif, Instant Data Scraper fait l’affaire sur les pages simples. Pour garder la main sur tout et monter des recettes sans crainte, Web Scraper ou Octoparse vous donnent cette puissance. Et si votre objectif réel est d’extraire → automatiser → envoyer vers un CRM, c’est du côté de Bardeen, plateforme de workflow, qu’il faut regarder.
Extraire la page de listing ne fait que la moitié du chemin : le flux d’enrichissement des sous-pages
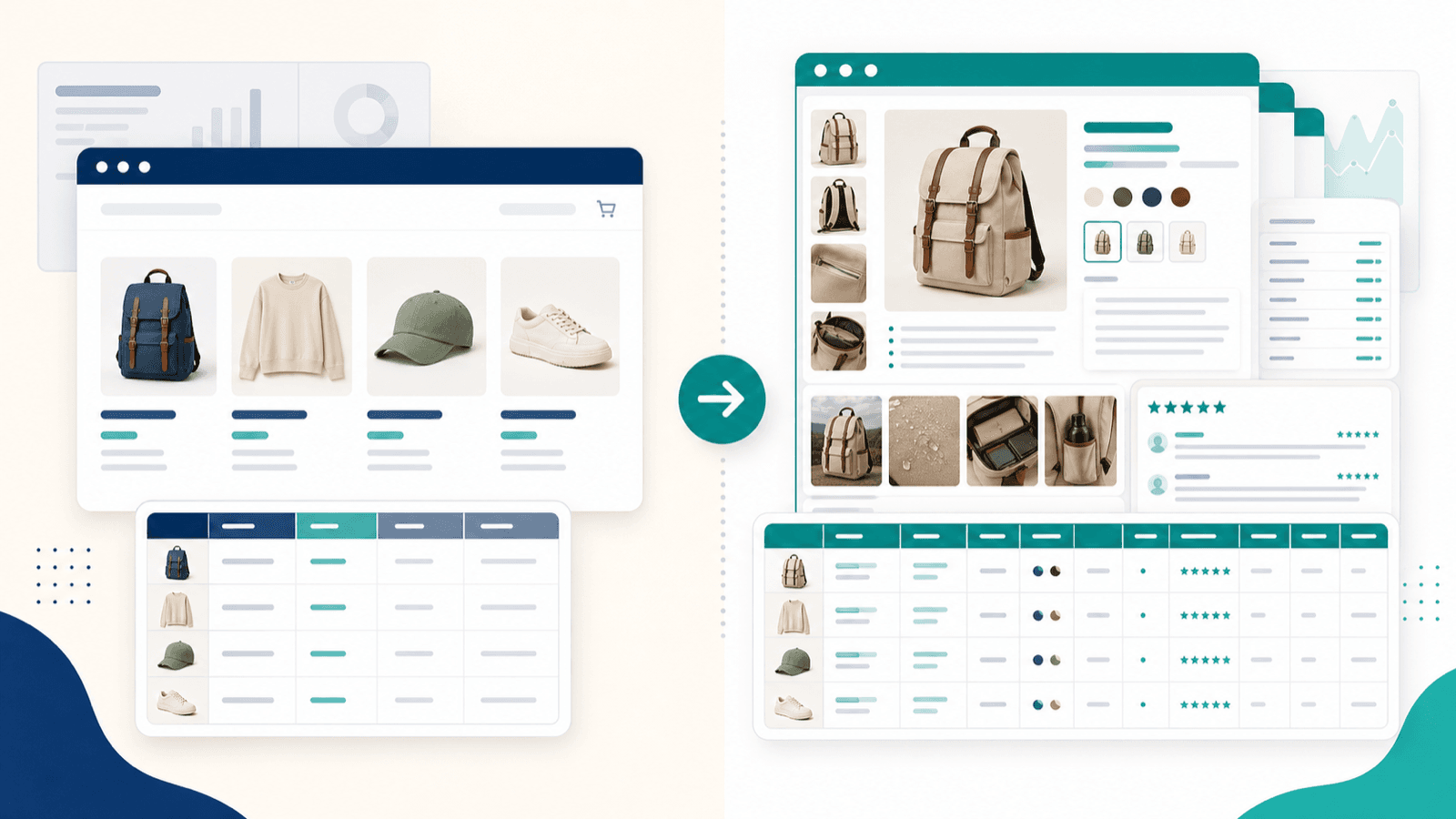
C’est la section qui manque cruellement à tous les autres articles sur les scrapers Shopify — parce qu’elle correspond au plus gros angle mort des contenus concurrents, et qu’elle pointe la frustration n°1 que me remontent les utilisateurs e-commerce.
Quand vous extrayez une page de collection Shopify (la page de listing), vous récupérez du superficiel : titres, prix, vignettes, parfois une description tronquée. Or les champs réellement décisifs pour l’analyse concurrentielle, l’import de catalogue ou la prospection en dropshipping logent sur les pages détail de chaque produit.
Ce que livre la page de listing, et ce qu’ajoute l’enrichissement des sous-pages
| Champ de données | Depuis la page de listing uniquement | Après enrichissement des sous-pages |
|---|---|---|
| Titre du produit | ✅ | ✅ |
| Prix | ✅ | ✅ |
| Image miniature | ✅ | ✅ + toutes les images de la galerie |
| Courte description | ⚠️ Tronquée | ✅ Description HTML complète |
| Variantes (taille, couleur) | ❌ | ✅ |
| SKU / stock | ❌ | ✅ |
| Avis / notes | ❌ | ✅ |
L’écart est colossal.
Un export limité à la page de listing vous laisse avec un tableur creux. Un export enrichi par les sous-pages vous met entre les mains un jeu de données vraiment exploitable pour la veille concurrentielle.
Le fonctionnement de l’extraction des sous-pages dans Thunderbit, étape par étape
- Accédez à la page de collection/liste de la boutique Shopify
- Cliquez sur « Suggestion de champs IA » — Thunderbit lit la page et propose des colonnes (titre, prix, image, lien, etc.)
- Cliquez sur « Extraire » pour récupérer les données de la page de listing
- Cliquez sur « Extraire les sous-pages » — l’IA visite chaque URL produit et ajoute les données de la page détail (description complète, toutes les images, variantes, avis) au tableau d’origine
- Exportez le tableau enrichi vers Excel, Google Sheets, Airtable, Notion ou CSV
L’ensemble se boucle en quelques minutes pour une collection classique, et vous repartez avec un jeu de données qui vous aurait coûté des heures à constituer à la main.
Essayer l’extraction des sous-pages avec Thunderbit
Quels autres outils gèrent l’enrichissement des sous-pages ?
- Web Scraper : oui, mais via une configuration manuelle du sitemap, sélecteurs de liens et sitemaps enfants à l’appui — comptez 15 à 20 minutes de réglage par boutique
- Octoparse : oui, via le générateur de flux ou des modèles — puissant, mais plus laborieux à configurer
- Data Miner : oui, via des workflows de crawl en plusieurs étapes — rien d’instantané
- Simplescraper : le concept de deep scraping existe, mais reste moins prêt à l’emploi
- Instant Data Scraper, Listly, Bardeen : aucun enrichissement des sous-pages Shopify en un clic documenté
Entre « peut techniquement suivre des liens moyennant 20 minutes de réglage manuel » et « enrichissement en un clic », il y a tout l’écart qui sépare un outil destiné aux ingénieurs du scraping d’un outil pensé pour les opérateurs e-commerce.
Quand products.json de Shopify vous lâche — et pourquoi les extensions Chrome deviennent votre plan B
Si vous avez parcouru d’autres guides sur le scraping Shopify, vous êtes sans doute tombé sur l’astuce /products.json : il suffit d’accoler /products.json à l’URL d’une boutique Shopify pour récupérer des données produit structurées au format JSON. Le point d’accès est bien réel, et quand il répond, il rend de fiers services.
Le fonctionnement de products.json
Les boutiques Shopify exposent un point d’accès API JSON à l’adresse /products.json, qui renvoie des données produits structurées. La pagination passe par ?page=2&limit=250 (250 produits maximum par page).
Les champs généralement renvoyés : title, body_html, vendor, product_type, tags, published_at, variants (avec price, compare_at_price, sku, available) et images.
Ce que products.json laisse de côté
- Aucune donnée d’avis ni de comptage des notes
- Mise en forme des descriptions appauvrie par rapport aux pages rendues
- Les metafields personnalisés sont souvent absents
- Les images au niveau des variantes peuvent manquer de cohérence
- Aucun contenu de merchandising rendu, aucun badge, aucune preuve sociale
Quand products.json se met en panne
J’ai mené des vérifications HTTP directes sur huit vraies vitrines Shopify le 27 avril 2026. Le verdict est parlant :
| Boutique | Résultat |
|---|---|
| kith.com | ✅ Fonctionne — JSON propre |
| colourpop.com | ✅ Fonctionne |
| allbirds.com | ✅ Fonctionne |
| brooklinen.com | ✅ Fonctionne |
| negativeunderwear.com | ✅ Fonctionne |
| gymshark.com | ❌ Bloqué — HTML 403 au lieu de JSON |
| mvmt.com | ⚠️ Partiellement désactivé — page HTML 200, pas de JSON |
| fashionnova.com | ❌ Désactivé — 404 |
Cinq boutiques sur huit renvoyaient un JSON propre. Trois résistaient.
Le même constat revient sur les forums d’utilisateurs : « Pour une raison ou une autre, certaines boutiques Shopify choisissent de ne pas exposer products.json. » Boutiques protégées par mot de passe, configurations d’API sur mesure, domaines sous Cloudflare : autant de cas qui peuvent faire sauter le schéma.
Le filet de sécurité de l’extension Chrome
Quand products.json est aux abonnés absents, un scraper en extension Chrome puise les données directement dans la page rendue (le DOM). C’est tout l’intérêt des scrapers basés sur le navigateur : ils voient et extraient ce que vous voyez à l’écran, indépendamment de la disponibilité de l’API. Les extensions Chrome forment ainsi un plan B fiable — et même un plan A quand vous avez besoin de données rendues comme les avis, le contenu de merchandising ou les galeries d’images complètes.
Protection anti-bot : ce qui se trame vraiment quand vous extrayez des boutiques Shopify
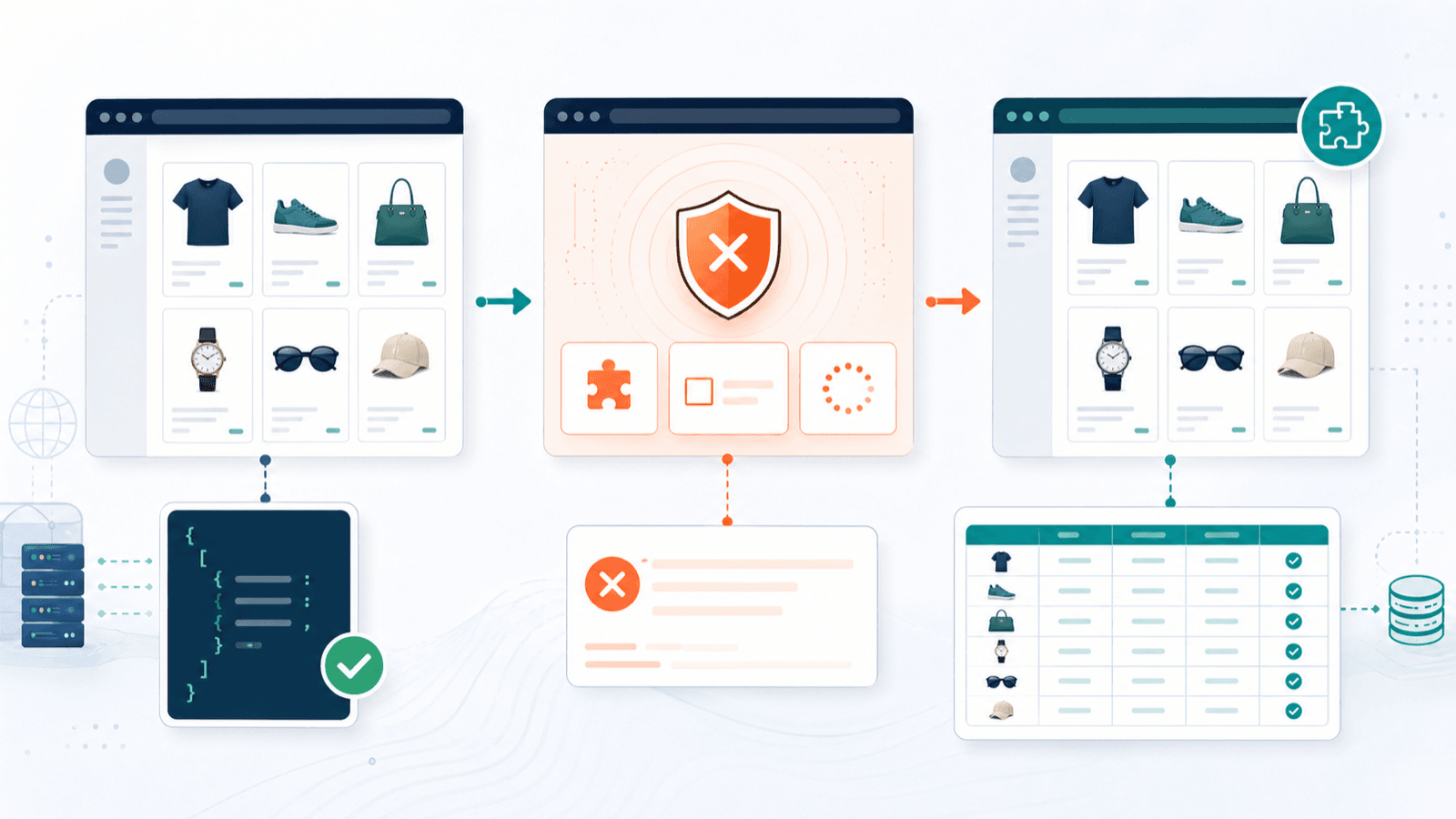
La plupart des articles sur les scrapers Shopify font comme si toutes les boutiques étaient grandes ouvertes. La réalité est tout autre. Store Leads indique que 99,2 % des boutiques Shopify s’appuient sur l’infrastructure Cloudflare. Cela ne signifie pas que chacune bloque agressivement les scrapers, mais que l’armature de blocage, elle, est partout.
Concrètement, le spectre se présente ainsi.
Faciles à extraire
- Boutiques publiques sans protection Cloudflare agressive
- Boutiques avec products.json activé
- Boutiques sous thèmes Shopify standard (structure DOM cohérente)
Plus coriaces à extraire
- Boutiques protégées par Cloudflare (défis CAPTCHA, Turnstiles)
- Boutiques exigeant une connexion ou protégées par mot de passe
- Boutiques Shopify Plus dotées de couches de sécurité personnalisées
- Boutiques appliquant un rate limiting agressif
La façon dont chaque outil affronte les scénarios anti-bot
| Scénario | Approche la plus adaptée | Outils qui le gèrent |
|---|---|---|
| Boutique publique, sans anti-bot | Scraping cloud (rapide) | Thunderbit (mode cloud), Instant Data Scraper, la plupart des autres |
| Boutique protégée par Cloudflare | Scraping dans le navigateur (utilise votre session) | Thunderbit (mode navigateur), Web Scraper, Octoparse |
| Boutique nécessitant une connexion / privée | Scraping dans le navigateur avec votre session connectée | Thunderbit (mode navigateur), Web Scraper, Simplescraper |
| products.json désactivé | Extraction depuis le DOM de la page rendue | Toutes les extensions Chrome (c’est leur point fort) |
Les deux modes cloud/navigateur de Thunderbit prennent ici tout leur sens. Le mode cloud assure la vitesse pour l’extraction massive des boutiques publiques. Le mode navigateur s’appuie sur votre vraie session Chrome dès que la protection anti-bot l’impose. Cette souplesse m’a tiré d’affaire sur gymshark.com, où les requêtes cloud se faisaient bloquer alors que le mode navigateur tournait sans accroc.
Scraping Shopify programmé : suivre prix et stocks dans la durée
L’extraction ponctuelle a son utilité. Mais les équipes opérationnelles e-commerce ont surtout besoin d’une intelligence concurrentielle continue — pas d’un cliché figé. Variations de prix, mouvements de stock, lancements de produits : tout cela bouge en permanence. Un utilisateur l’a formulé très simplement sur un forum : « Ce serait bien plus utile de voir leur niveau de stock actuel, avec des instantanés qui montrent sa diminution. »
Et pourtant, presque aucun article concurrent n’évoque le scraping programmé ou récurrent. Un angle mort manifeste.
Le fonctionnement de la surveillance programmée Shopify
- Configurez une extraction récurrente d’une collection ou de pages produit d’un concurrent
- À chaque exécution, les données partent vers Google Sheets (ou Airtable), constituant une série temporelle de prix et de stocks
- Exploitez ces données pour suivre : baisses ou hausses de prix, ruptures de stock, ajouts de produits, tendances saisonnières
Mettre en place une extraction programmée avec Thunderbit
Avec Thunderbit, l’opération frôle la simplicité déconcertante.
Vous décrivez le planning en langage naturel (par exemple : « tous les lundis à 9 h »), vous saisissez les URL de la boutique Shopify, puis vous cliquez sur « Planifier ». Thunderbit exécute l’extraction de lui-même et exporte vers la destination choisie. Ni cron, ni code, ni planificateur tiers.
La prise en charge de la planification, outil par outil
| Outil | Planification ? |
|---|---|
| Thunderbit | Oui — planification en langage naturel |
| Instant Data Scraper | Non |
| Web Scraper | Oui — sur les plans cloud |
| Data Miner | Des crawls automatisés existent, mais ce n’est pas la planification la plus simple |
| Simplescraper | Oui |
| Octoparse | Oui — à partir de Standard |
| Bardeen | Oui — via des automatisations basées sur l’heure et la date |
| Listly | Oui — sur le forfait Business |
Dès lors que le suivi concurrentiel continu fait partie de votre flux de travail, c’est un facteur de différenciation de premier ordre. La plupart des extensions Chrome gratuites en sont tout bonnement dépourvues.
Quelle extension Chrome Shopify Scraper colle à votre cas d’usage ?

Plutôt qu’une conclusion passe-partout du genre « choisissez celle qui vous parle le plus », voici une matrice de décision calée sur des cas d’usage bien définis :
| Cas d’usage | Meilleure recommandation | Pourquoi |
|---|---|---|
| Étude des prix concurrents | Thunderbit | Listing + enrichissement des sous-pages + planification = flux de travail complet sur les prix |
| Export ponctuel rapide | Instant Data Scraper | Le chemin gratuit le plus rapide quand vous n’avez besoin que des données visibles de la liste |
| Import de catalogue dans votre boutique Shopify | Thunderbit | Données complètes des sous-pages + export CSV/Excel adapté à l’import Shopify |
| Suivi continu des prix/stocks | Thunderbit ou Octoparse | La planification no-code la plus simple vs la planification de type entreprise la plus robuste |
| Génération de leads (contacts des propriétaires de boutiques) | Thunderbit | Extracteurs d’e-mails/téléphones intégrés + export structuré |
| Automatisations complexes en plusieurs étapes | Bardeen | Extraire, enrichir et pousser vers les applications aval dans un seul workflow |
| Utilisateurs techniques qui veulent un contrôle total | Web Scraper ou Octoparse | Meilleur contrôle manuel des sélecteurs, du flux et de la logique d’extraction |
Conclusion
En 2026, la question du scraping Shopify n’est plus de savoir si vous pouvez obtenir des données produits — mais à quel point votre flux de travail est profond, rapide et reproductible. La plupart des articles du genre s’arrêtent à la page de listing. La vraie valeur, elle, se niche dans l’enrichissement des sous-pages, la surveillance programmée et la gestion des aléas anti-bot que les vraies boutiques Shopify vous réservent.
Pour voir à quoi cela ressemble en conditions réelles — d’une page de collection à un jeu de données entièrement enrichi en quelques clics — testez Thunderbit. Et si Thunderbit ne correspond pas tout à fait à votre besoin, Instant Data Scraper reste un excellent point de départ gratuit pour les tâches simples, tandis que Web Scraper et Octoparse s’adressent parfaitement aux utilisateurs techniques en quête de contrôle.
Bon scraping — et que vos données produits soient toujours complètes, structurées et riches en variantes.
Essayer Thunderbit pour le scraping Shopify Get Started Free
FAQ
1. Est-il légal de scraper des données depuis des boutiques Shopify ?
Les données produits publiques d’une boutique Shopify sont, en règle générale, accessibles à quiconque visite le site. Cela étant, la légalité dépend de votre juridiction, des conditions d’utilisation de la boutique et de l’usage que vous faites des données. Extraire des prix publics à des fins d’analyse concurrentielle est une pratique répandue ; recopier intégralement du contenu pour le republier comporte nettement plus de risques. Ceci n’est pas un conseil juridique — consultez un professionnel pour votre cas précis.
2. Puis-je extraire des boutiques Shopify qui exigent une connexion ou un mot de passe ?
Oui, à condition d’utiliser un scraper basé sur le navigateur qui s’appuie sur votre session Chrome connectée. Les scrapers cloud, eux, n’atteignent généralement pas les pages derrière une connexion. Le mode navigateur de Thunderbit, Web Scraper (en local) et les workflows de connexion de Simplescraper prennent tous en charge ce scénario.
3. Combien de produits puis-je extraire d’une boutique Shopify en une seule fois ?
Tout dépend de l’outil et du forfait. Le point d’accès products.json de Shopify pagine à 250 produits par page. Le mode cloud de Thunderbit traite jusqu’à 50 pages d’un coup. Les offres gratuites de la plupart des outils plafonnent les pages, les lignes ou les crédits — vérifiez donc les limites de votre forfait avant de lancer une grosse opération.
4. Quelle est la différence entre scraping cloud et scraping navigateur pour Shopify ?
Le scraping cloud s’exécute sur des serveurs distants — plus rapide, mieux taillé pour les boutiques publiques sans protection anti-bot. Le scraping navigateur passe par votre session Chrome locale, ce qui lui permet de composer avec les boutiques sous Cloudflare, exigeant une connexion ou sensibles à la région. Thunderbit propose les deux modes, et le choix se joue le plus souvent sur la capacité de la boutique à bloquer ou non les requêtes distantes.
5. Puis-je exporter directement les données Shopify extraites vers Google Sheets ou Airtable ?
Oui, mais tous les outils ne le permettent pas. Thunderbit exporte gratuitement vers Google Sheets, Airtable, Notion, Excel, CSV et JSON. Data Miner et Listly prennent en charge Google Sheets. Simplescraper prend en charge Sheets et Airtable. Octoparse prend en charge Google Sheets sur ses offres premium. Bardeen s’intègre avec Sheets, Airtable et Notion. Instant Data Scraper, lui, n’exporte qu’en CSV et XLSX, sans intégration directe avec Sheets.
En savoir plus




