

Le catalogue d'Amazon, c'est près de 2 millions de vendeurs partenaires et des centaines de millions d'articles. Quiconque a déjà recopié à la main des titres de produits, des prix, des notes et des ASIN dans un tableur connaît la corvée — et la vitesse à laquelle elle vire à l'absurde.
Je travaille chez Thunderbit, où nous bâtissons un extracteur Web IA, ce qui m'amène à passer pas mal de temps à observer comment les gens récupèrent des données sur le web. Mais pour cet article, j'ai voulu tenter ce qu'aucun autre comparatif ne propose : installer et lancer pour de vrai sept extensions Chrome sur Amazon, les éprouver sur les mêmes pages, et vous livrer sans détour ce qui fonctionne, ce qui coince, et la niche de chaque outil. J'ai noté chaque extension sur huit critères directement issus des frustrations que je croise sur les forums et chez nos propres utilisateurs : détection de champs par IA, extraction de sous-pages, risque de blocage, offres gratuites, options d'export, et le reste. Vendeur Amazon, marketeur, ou simplement las du copier-coller : ce guide est pour vous.
Essayer Thunderbit pour le scraping Amazon
Pourquoi extraire des données produit Amazon, au départ ?
Première question : qui extrait vraiment des données d'Amazon, et dans quel but ?
La réponse tient en une phrase : à peu près tous ceux qui vendent, commercialisent ou étudient des produits en ligne. Amazon le dit lui-même, plus de 60 % des ventes sur sa boutique viennent de vendeurs indépendants — des vendeurs qui s'épient en permanence. Voici les cas d'usage que je rencontre le plus souvent :
| Cas d’usage | Qui le fait | Ce qu’ils obtiennent |
|---|---|---|
| Surveillance des prix des concurrents | Vendeurs, équipes pricing, agences | Données de prix et de disponibilité en temps réel pour les produits concurrents |
| Recherche produit et suivi des tendances | Vendeurs Amazon, analystes marché | Repérer les catégories en hausse, les nouveaux entrants et les évolutions de la demande |
| Analyse du sentiment des avis | Vendeurs de marque blanche, équipes de marque | Réclamations récurrentes, lacunes fonctionnelles et opportunités |
| Génération de leads (contacts vendeurs) | Équipes wholesale, agences | Noms de vendeurs, vitrines et coordonnées |
| Suivi du catalogue et des stocks | Opérations e-commerce, protection de marque | Suivre les niveaux de stock, les modifications d’annonces et les vendeurs non autorisés |
| Optimisation des mots-clés et des fiches | Propriétaires de marque, opérateurs de marketplace | Données de termes de recherche, texte des fiches et mots-clés concurrents |
Et le retour sur investissement n'a rien d'abstrait. Les études de cas d'Amazon elles-mêmes le montrent : les ventes trimestrielles de thefitguy ont grimpé de plus de 40 % après une optimisation sur les meilleurs termes de recherche, appuyée sur des données structurées. De son côté, une étude de Parseur chiffre à plus de 9 heures par semaine le temps que les salariés consacrent à de la saisie répétitive. Automatiser ne serait-ce qu'une fraction de cela, c'est récupérer un temps précieux pour ce qui compte : décider.
Qu’est-ce qui fait une bonne extension Chrome de scraping Amazon ? Mes critères de test
Toutes les extensions Chrome ne se valent pas — et la plupart des comparatifs mélangent allègrement APIs, applications desktop et extensions de navigateur, comme si c'était interchangeable. Ça ne l'est pas. Voici la grille que j'ai appliquée, et ce que chaque critère justifie :
- Facilité de prise en main — Un utilisateur sans bagage technique peut-il sortir un résultat en moins de 5 minutes ? (Les forums confirment que c'est une préoccupation de premier plan.)
- Détection de champs par IA — L'outil repère-t-il seul les champs produit, ou faut-il configurer les sélecteurs à la main ? (Aucun comparatif concurrent n'en fait une catégorie à part entière.)
- Extraction des sous-pages / pages de détail — Pouvez-vous enrichir les données d'une fiche avec celles de la page produit, dans un seul et même flux ?
- Gestion du risque de blocage / anti-bot — Comment l'outil compose-t-il avec la détection agressive d'Amazon ? (Le principal irritant remonté sur les forums.)
- Gestion de la pagination — Sait-il enchaîner automatiquement plusieurs pages de résultats ?
- Offre gratuite / tarification — Qu'obtenez-vous concrètement sans sortir la carte bleue ? (Les utilisateurs réclament explicitement des options gratuites, et aucun concurrent n'y répond vraiment.)
- Options d'export — CSV, Excel, Google Sheets, Airtable, Notion ?
- Planification et automatisation — Peut-on le faire tourner en récurrent ?
J'ai mis chaque extension à l'épreuve sur les résultats de recherche Amazon US et sur les pages de détail produit, avec les mêmes requêtes et les mêmes conditions.

Extraction pilotée par IA vs extraction par sélecteurs : pourquoi c’est crucial pour Amazon
Il y a une distinction qu'aucun autre comparatif d'extracteurs Amazon ne pose — alors que c'est pourtant elle qui détermine la quantité de maintenance que votre extracteur va réclamer.
La plupart des extracteurs en extension Chrome marient des sélecteurs CSS à des champs de données. Vous (ou le modèle fourni par l'outil) pointez l'élément HTML qui correspond au « prix » ou au « titre », et l'extracteur récupère ce qui s'y loge. Le hic ? Amazon retouche son HTML et son CSS au quotidien — ce qui casse les extracteurs. Sur les forums, les utilisateurs décrivent les noms de classes hachés ou changeants comme un mode d'échec classique.
Voici comment se positionnent les trois grandes approches :
| Approche | Fonctionnement | Quand Amazon change la mise en page |
|---|---|---|
| Basée sur des sélecteurs (traditionnelle) | L’utilisateur mappe manuellement les sélecteurs CSS vers les champs | Casse — l’utilisateur doit reconfigurer |
| Basée sur des modèles | Recettes préconstruites pour les pages Amazon | Casse jusqu’à ce que le développeur mette le modèle à jour |
| Pilotée par IA (par ex. Thunderbit) | L’IA lit le contenu de la page et détecte automatiquement les champs | S’adapte automatiquement — sans maintenance |
Sur les sept extensions que j'ai passées au banc, une seule — Thunderbit — fait de la détection de champs par IA son mode de configuration par défaut. Les autres reposent sur des sélecteurs ou des modèles, donc sur davantage de maintenance dès qu'Amazon retouche ses pages, ce qui arrive inévitablement. Bien saisir cette distinction vous épargnera beaucoup de déconvenues plus tard.
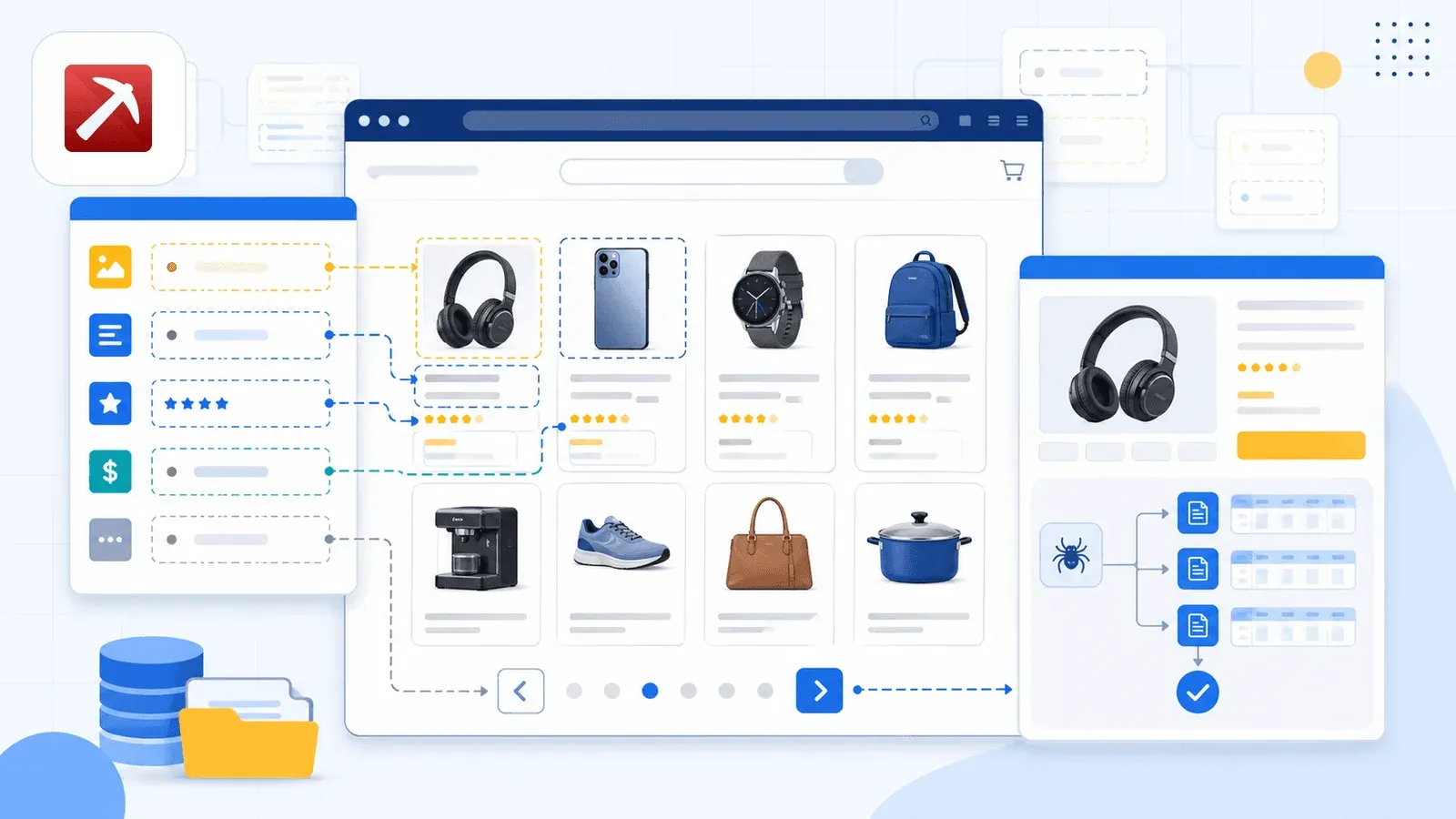
1. Thunderbit — L’extension Chrome de scraping Amazon pilotée par IA
Thunderbit est l'outil que nous avons conçu en interne, et je le précise d'emblée. Mais je le pense aussi en toute honnêteté : c'est le meilleur choix pour les utilisateurs non techniques qui veulent des données Amazon rapides et fiables sans se débattre avec des sélecteurs ou du code.
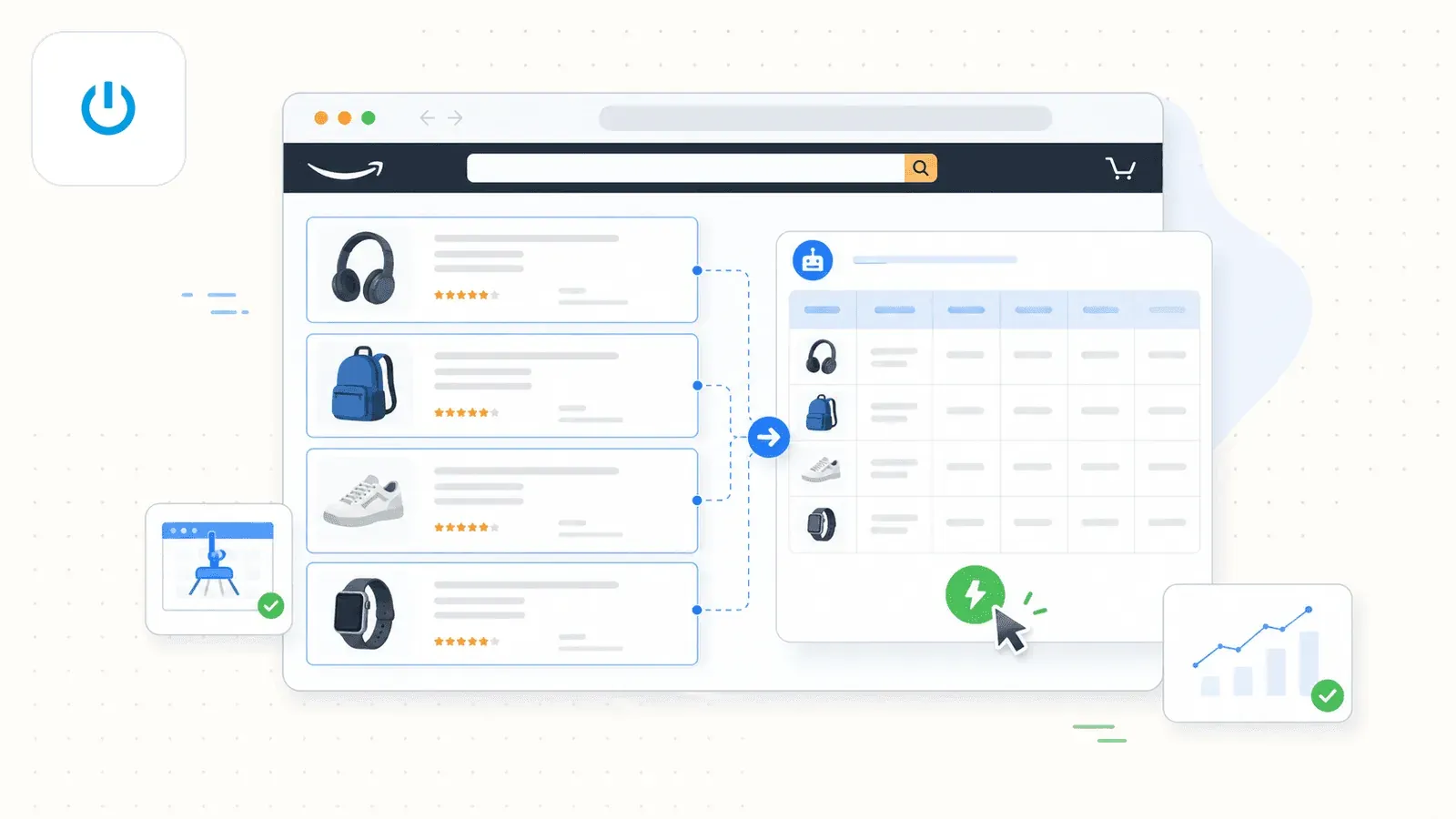
Son atout maître, c'est AI Suggest Fields. Ouvrez une page de résultats de recherche Amazon, cliquez sur le bouton, et l'IA de Thunderbit lit la page pour proposer des noms de colonnes — titre, prix, note, ASIN, nombre d'avis, URL du produit, et bien d'autres. Aucune configuration de votre part. L'IA identifie ce qui figure sur la page et suggère les bons champs avec les bons types de données.

Voici à quoi ressemble une session de scraping Amazon classique :
- Installez l’extension Chrome Thunderbit, ouvrez une page de résultats Amazon.
- Cliquez sur AI Suggest Fields — l’IA détecte et propose les colonnes.
- Cliquez sur Scrape — les données se remplissent instantanément.
- Pour les pages Amazon les plus fréquentes, vous pouvez aussi dégainer le modèle Amazon Scraper prêt à l’emploi, pour une expérience véritablement en 1 clic.
Ce qui distingue vraiment Thunderbit, c'est l'extraction des sous-pages. Une fois la page de liste extraite, cliquez sur Scrape Subpages — Thunderbit visite chaque URL produit et verse les champs de détail (descriptions complètes, puces, infos vendeur, URLs d'images) dans le même tableau. La plupart des extensions rivales ne le proposent tout bonnement pas.
S'y ajoute un basculement cloud / navigateur. Le mode cloud extrait jusqu'à 50 pages en parallèle pour les annonces publiques. Le mode navigateur, lui, exploite votre propre session Chrome — parfait quand vous êtes connecté à Seller Central ou que vous tenez à rester discret.
La planification se pilote en langage courant : décrivez l'intervalle, l'IA le traduit en calendrier.
Côté export, tout y passe — Excel, Google Sheets, Airtable, Notion, CSV et JSON — et tout est compris dans l'offre gratuite.
Avantages et inconvénients de Thunderbit
Avantages :
- Détection automatique des champs par IA — aucun sélecteur à configurer, aucune maintenance quand Amazon change sa mise en page
- Enrichissement des sous-pages en un clic
- Basculement cloud/navigateur pour plus de souplesse et moins de risque de blocage
- Le plus large éventail d’exports (Sheets, Airtable, Notion, Excel, CSV, JSON)
- Planification en langage naturel
- Modèle Amazon prêt à l’emploi pour des résultats immédiats
Inconvénients :
- Le système à crédits pousse les gros utilisateurs vers un forfait payant
- La détection des champs par IA ajoute une courte étape de traitement (quelques secondes)
- Outil plus récent, donc moins de documentation communautaire que les options plus anciennes
Tarification de Thunderbit
- Offre gratuite : 6 pages (10 avec bonus d’essai), avec les fonctions IA et tous les formats d’export
- Forfaits payants : À partir d’environ 9 $/mois (annuel), soit près de 8 €/mois, pour 500 crédits ; 1 crédit = 1 ligne de sortie
- Consultez la tarification Thunderbit pour les dernières informations
Extraire des pages Amazon grâce à l’IA Get Started Free
2. Instant Data Scraper — L’option gratuite, sans fioritures
Instant Data Scraper est une extension Chrome qui repère automatiquement les données tabulaires d'une page web à l'aide d'algorithmes heuristiques. Présente depuis des années, elle reste l'un des extracteurs gratuits les plus téléchargés du Chrome Web Store.
Sur Amazon, vous l'activez sur une page de résultats et elle tente de détecter seule le tableau de données. Il faut parfois cliquer sur « essayer un autre tableau » si la première détection tombe à côté. Pour des extractions simples et ponctuelles, ça remplit son office.
Une réserve de taille pour 2026, toutefois : la page officielle annonce désormais qu'Instant Data Scraper n'est plus détenu, développé ni maintenu par Web Robots. Traduction : plus de mises à jour, plus de correctifs, plus de nouveautés. Sur un fil Reddit, un utilisateur a rapporté que l'outil gérait les pages récapitulatives mais calait dès que des clics au niveau détail entraient en jeu.
Avantages et inconvénients d’Instant Data Scraper
Avantages :
- 100 % gratuit, sans création de compte
- Léger et rapide sur les tableaux simples
- Prend en charge une pagination basique (clic sur le bouton « Next »)
Inconvénients :
- Pas de détection de champs par IA (s’appuie sur la reconnaissance de motifs, qui peut buter sur la mise en page complexe d’Amazon)
- Pas d’extraction des sous-pages
- Export limité au CSV/Excel
- Pas de planification, pas d’option cloud
- Plus maintenu — il casse quand Amazon change la mise en page, et personne ne le répare
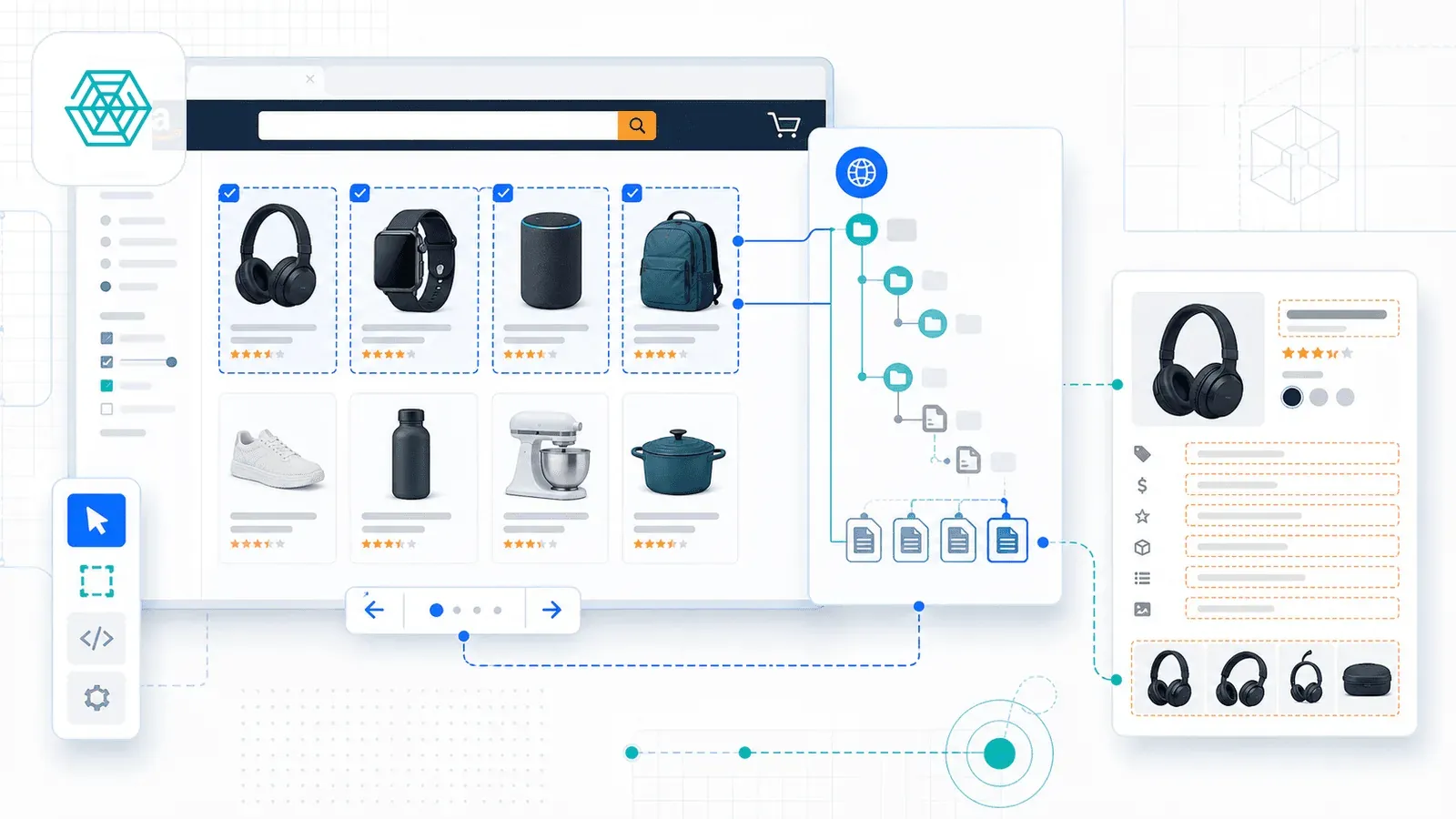
3. Web Scraper — L’extension historique pour la configuration manuelle
Web Scraper compte parmi les extracteurs Chrome les plus installés, articulé autour d'un générateur visuel de sitemap. Vous ouvrez les DevTools, montez un « sitemap » en pointant-cliquant pour fixer les sélecteurs, réglez la pagination, et vous pouvez suivre les liens vers les pages de détail produit.
Web Scraper met aussi à disposition un modèle Amazon Products Listings Scraper dans sa marketplace, qui prend en charge navigation, pagination et extraction des pages produit. Son guide décrit une configuration en 8 étapes : installation, génération des sélecteurs, paramétrage de la pagination, suivi des liens produits, exécution en local ou dans le cloud.
La version cloud, elle, apporte la planification, l'accès API, la rotation des proxys, le contournement des CAPTCHA et l'intégration avec Google Sheets.
Avantages et inconvénients de Web Scraper
Avantages :
- Mature, bien documenté et porté par une communauté active
- Extension navigateur gratuite (usage local illimité)
- Modèles de marketplace pour Amazon
- Option cloud pour monter en charge (planification, rotation d’IP, intégrations)
- Suivi possible des liens vers les pages de détail produit (enrichissement partiel des sous-pages)
Inconvénients :
- Configuration manuelle des sélecteurs imposée — courbe d’apprentissage plus rude pour les profils non techniques
- Pas de détection automatique des champs par IA
- Les modèles peuvent casser quand Amazon met à jour sa mise en page
- Les fonctions avancées sont cantonnées aux forfaits cloud payants
Tarification de Web Scraper
- Gratuit : Extension Chrome, scraping local illimité
- Forfaits cloud : À partir de 50 $/mois (Project), 100 $/mois (Professional), puis 200 $/mois et plus (Scale)
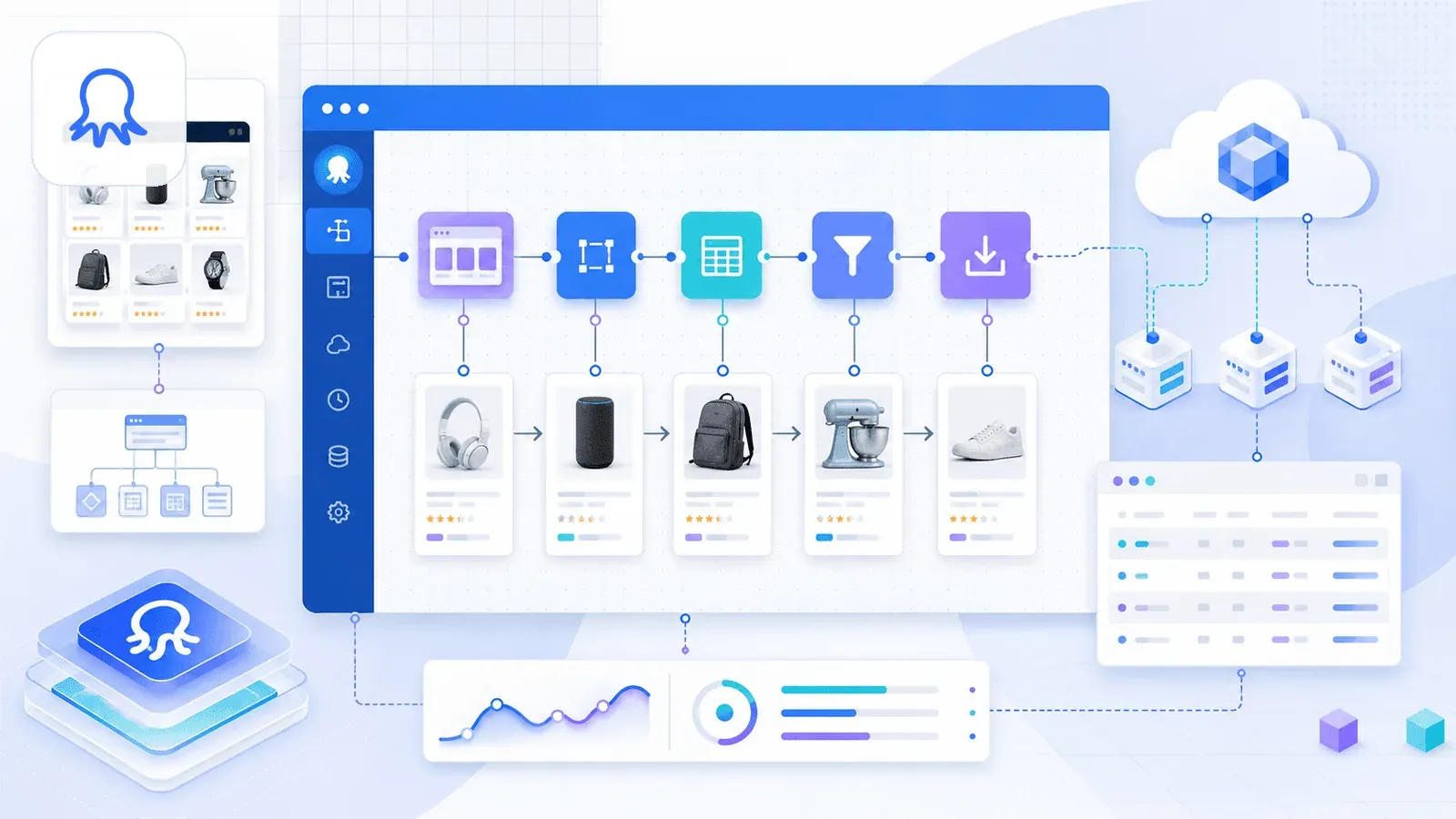
4. Octoparse — La plateforme riche en fonctionnalités (avec une réserve sur l’extension Chrome)
Octoparse est une plateforme de scraping sans code particulièrement musclée, avec des modèles Amazon prêts à l'emploi pour les détails produit, la recherche par mots-clés et les avis. Elle gère le scraping cloud, la planification et les workflows multi-étapes.
Mais une nuance pèse lourd : l'extension Chrome Web Store d'Octoparse s'affiche aujourd'hui sous le nom d'Octoparse AI Web Automation, et précise noir sur blanc qu'elle ne fonctionne qu'avec Octoparse AI Bot sous Windows. En pratique, l'expérience de scraping s'organise donc d'abord autour de la plateforme, pas de l'extension. Si vous cherchez un pur flux « installer et extraire dans Chrome », Octoparse tient davantage de l'application desktop assortie d'un assistant navigateur.
Cela dit, les modèles sont excellents. Vous collez une URL de recherche, Octoparse en extrait automatiquement les données produit, et vous pouvez monter des workflows sur mesure avec sélecteurs point-and-click, pagination et suivi de liens vers les pages de détail.
Avantages et inconvénients d’Octoparse
Avantages :
- Fonctionnalités robustes assorties de modèles Amazon
- Nœuds cloud pour la vitesse, la planification et l’extraction des sous-pages via workflows
- Gère bien la pagination
- Taillé pour les pipelines de scraping complexes et multi-étapes
Inconvénients :
- Toute sa puissance passe par l’application desktop — ce n’est pas une pure expérience d’extension Chrome
- Pas d’auto-suggestion de champs par IA (un produit distinct, Chat4Data, existe, mais c’est une autre extension)
- L’offre gratuite plafonne autour de 50 000 exportations de données/mois, 10 000 lignes par export
- L’interface peut paraître touffue pour un débutant
Tarification d’Octoparse
- Gratuit : Limité (extraction locale, plafond d’export à 50K)
- Standard : Environ 75 à 83 $/mois
- Professional : Environ 208 à 249 $/mois
- Options : Rotation d’IP à 3 $/Go, résolution de CAPTCHA à 2 à 2,50 $ par 1 000
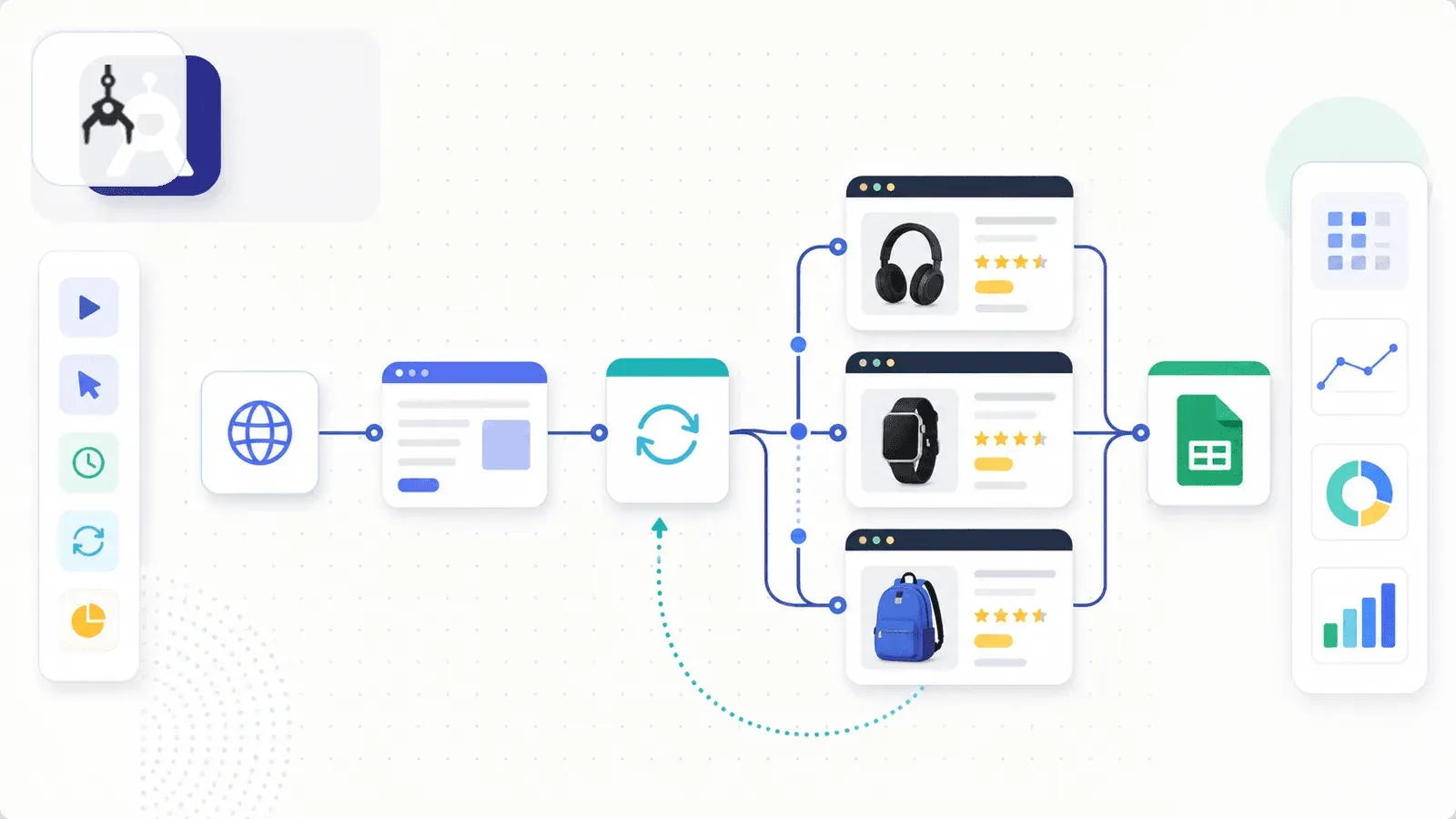
5. Axiom.ai — Le constructeur de bots no-code
Axiom.ai est une extension Chrome pour créer des bots d'automatisation navigateur via un éditeur visuel no-code. C'est moins un extracteur dédié qu'un outil d'automatisation généraliste, mais il propose des modèles de scraping Amazon et des guides d'extraction d'ASIN.
Vous montez un bot (ou partez d'un modèle) qui parcourt les URLs produit listées dans une Google Sheet, visite chaque page, en extrait les données via des sélecteurs point-and-click, puis renvoie les résultats dans la Sheet. La planification arrive sur les forfaits payants, et les exécutions cloud sont désormais ouvertes dès 1 bot dans le cloud sur Starter et Pro, jusqu'à 20 bots cloud simultanés sur Ultimate.
Avantages et inconvénients d’Axiom.ai
Avantages :
- Automatisation no-code polyvalente (pas seulement le scraping)
- Intégration native avec Google Sheets
- Planification et exécutions cloud sur les forfaits payants
- Modèles pour Amazon
- Bien adapté aux workflows multi-étapes au-delà de la simple extraction
Inconvénients :
- Mise en place plus lourde pour une extraction toute simple (conception du bot, configuration de la Google Sheet, tests de boucle)
- Pas de détection de champs par IA
- Pas d’enrichissement des sous-pages en un clic (il faut créer une étape de bot dédiée)
- Export limité à Google Sheets ou CSV
Tarification d’Axiom.ai
- Gratuit : 2 heures d’exécution
- Starter : 15 $/mois
- Pro : 50 $/mois
- Pro Max : 150 $/mois
- Ultimate : 250 $/mois
6. Data Miner — L’extension basée sur des recettes
Data Miner est une extension Chrome centrée sur l'extraction via des « recettes » — des modèles de scraping prédéfinis ou maison. Vous piochez une recette Amazon existante dans la bibliothèque publique, ou vous en composez une en sélectionnant les éléments de la page.
Data Miner gère la pagination grâce à sa fonction Next Page Automation, et offre aussi un flux Crawl Scrape pour visiter des URLs de détail et y appliquer une seconde recette. Ce n'est donc pas « pas d'extraction des sous-pages » — c'est plutôt un processus manuel en plusieurs temps, loin de l'enrichissement en un clic.
Sa principale limite tient à l'offre gratuite : 500 pages/mois, et certains domaines y sont restreints. Les recettes étant spécifiques à chaque site, la documentation de Data Miner prévient : si le site évolue et que le HTML de référence change, la recette tombe en panne.
Avantages et inconvénients de Data Miner
Avantages :
- Simple à lancer dès qu’une recette existe
- Bibliothèque de recettes communautaires
- Prend en charge la pagination et l’exploration des pages de détail (réglage manuel)
- Interface sobre
Inconvénients :
- Offre gratuite plafonnée à 500 pages/mois
- Pas de détection de champs par IA
- Les recettes cassent quand Amazon change la mise en page
- Pas de scraping cloud, pas de planification dans la doc publique
- Export : CSV, Excel, presse-papiers ; Google Sheets sur les forfaits payants
Tarification de Data Miner
- Gratuit : 500 pages/mois
- Payant : 19,99 $, 49 $, 99 $, 200 $/mois avec des limites et fonctionnalités croissantes
7. Helium 10 — La suite d’analyse pour vendeurs Amazon
Helium 10 est une suite complète pour vendeurs Amazon, pas un extracteur Web généraliste. Son extension Chrome (Xray) plaque des données directement sur les résultats de recherche Amazon — estimation des ventes, revenus, tendances d'avis, BSR, et bien plus. Elle vise les vendeurs Amazon en phase de recherche produit, pas l'extraction brute de page.
Helium 10 propose bien un forfait gratuit en 2026, mais l'accès à l'extension Chrome y reste bridé. L'extension exporte les résultats en CSV ou Excel et prend en charge des flux via le presse-papiers.

Avantages et inconvénients d’Helium 10
Avantages :
- Analyses Amazon très poussées (estimations de ventes, données de mots-clés, tendances BSR)
- Adopté par des vendeurs professionnels
- Données cloud et planification pour le suivi des mots-clés et des classements
- Forfait gratuit disponible (limité)
Inconvénients :
- Ce n’est pas un extracteur général — impossible d’extraire des champs personnalisés sur n’importe quelle page
- Plus onéreux que les outils centrés sur le scraping
- Formats d’export restreints (CSV, Excel)
- Pas de détection de champs par IA, pas d’enrichissement des sous-pages au sens du scraping
Tarification d’Helium 10
- Gratuit : Accès limité, extension Chrome comprise
- Starter : 49 $/mois
- Platinum : 229 $/mois
- Diamond : 359 $/mois
Comparatif des extensions Chrome de scraping Amazon : la vue complète côte à côte
Voici le tableau comparatif, sans complaisance. J'ai rectifié quelques hypothèses des premières versions après des tests concrets et une vérification en 2026 :
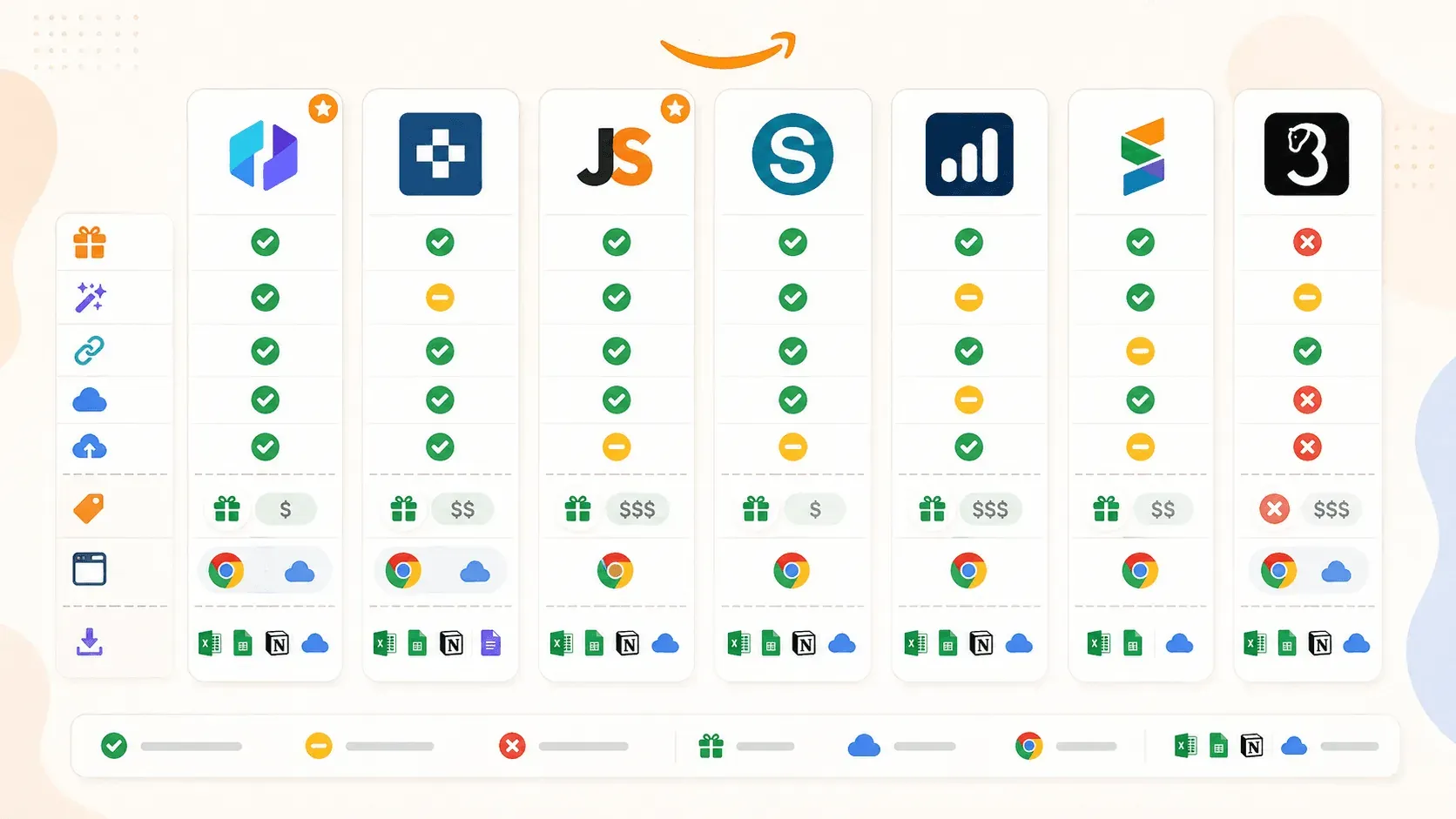
| Fonctionnalité | Thunderbit | Instant Data Scraper | Web Scraper | Octoparse | Axiom.ai | Data Miner | Helium 10 |
|---|---|---|---|---|---|---|---|
| Catégorie principale | Extension d’extracteur IA | Extracteur heuristique gratuit | Extracteur basé sur sélecteurs/modèles | Plateforme de scraping no-code | Constructeur de bots d’automatisation navigateur | Extension d’extracteur basée sur des recettes | Superposition pour analyse vendeur |
| Champs auto-suggérés par IA | Oui | Non | Non | Non (Chat4Data séparé) | Non | Non | Non |
| Enrichissement des sous-pages | Oui (1 clic) | Non | Oui (sitemap manuel) | Oui (workflow) | Oui (étape manuelle du bot) | Oui (crawl manuel) | N/A |
| Scraping cloud | Oui | Non | Oui (payant) | Oui (payant) | Oui (payant) | Non | Analytique cloud |
| Planification | Oui | Non | Oui (payant) | Oui (payant) | Oui (payant) | Non | Oui (suivi mots-clés/classements) |
| Offre gratuite | Oui (6–10 pages) | Oui (totalement gratuit) | Oui (navigateur uniquement) | Oui (limitée) | Oui (2 h d’exécution) | Oui (500 pages/mois) | Oui (limitée) |
| Modèle Amazon prêt à l’emploi | Oui | Non | Oui | Oui | Oui (guides) | Bibliothèque de recettes | N/A |
| Export vers Sheets/Airtable/Notion | Oui (tout) | CSV/Excel uniquement | CSV, Excel, JSON ; Sheets via le cloud | CSV, Excel, JSON, plus | Google Sheets, CSV | CSV, Excel ; Sheets sur les forfaits payants | CSV, Excel |
Plusieurs constats sautent aux yeux. Thunderbit est la seule extension à conjuguer détection de champs par IA et le plus large choix d'exports dans l'offre gratuite. Instant Data Scraper reste l'option gratuite la plus immédiate, mais elle n'est plus maintenue. Web Scraper et Octoparse impressionnent pour qui accepte d'investir du temps en configuration, mais aucun ne livre une expérience purement « installer et utiliser ». Axiom.ai s'impose pour l'automatisation multi-étapes au-delà du scraping. Data Miner dépanne bien pour faire tourner des recettes existantes, mais son offre gratuite est étriquée. Helium 10, enfin, est un outil de veille vendeur, pas un extracteur généraliste.
Scraping cloud vs navigateur pour Amazon : ce qu’il faut savoir sur le risque de blocage
C'est le sujet que tout le monde contourne. Amazon détecte et bloque activement le scraping automatisé. Des utilisateurs de Reddit signalent l'apparition de CAPTCHA même pour des scrapers à faible volume, et les conditions d'utilisation d'Amazon stipulent explicitement que la licence n'autorise pas « l'utilisation de data mining, de robots ou d'outils similaires de collecte et d'extraction de données ».
Alors, quelle différence concrète entre scraping navigateur et scraping cloud ?
- Scraping navigateur : tourne dans votre propre session Chrome — vrais cookies, état connecté, navigation d'allure naturelle. Plus crédible à faible volume, mais il accapare votre navigateur.
- Scraping cloud : s'appuie sur des serveurs distants pour gagner en vitesse (Thunderbit traite 50 pages d'un coup en mode cloud), mais réclame un contrôle du débit et une rotation des proxys pour passer sous les radars.
Voici la matrice de décision que j'applique :
| Scénario | Mode recommandé | Pourquoi |
|---|---|---|
| Extraire 20 pages produit pour une étude | Navigateur | Faible volume, comportement naturel |
| Suivre 500 SKU concurrents chaque semaine | Cloud | La vitesse compte, données publiques |
| Extraire des données en étant connecté à Seller Central | Navigateur | Nécessite votre session de connexion |
| Export groupé ponctuel d’une catégorie | Cloud | Extraction parallèle pour aller plus vite |
Parmi les sept extensions, le scraping cloud est offert par Thunderbit, Web Scraper (payant), Octoparse (payant), Axiom.ai (payant) et Helium 10 (pour son analytique). Instant Data Scraper et Data Miner, eux, ne fonctionnent qu'en navigateur.
Quelques réflexes pour limiter le risque de blocage : ménagez des intervalles de requête raisonnables, fuyez les extractions aux heures de pointe, et faites tourner les user agents si votre outil le permet. Et ne vous bercez jamais de l'illusion d'un « risque zéro » — gérez-le simplement au mieux.
De la page de liste à la fiche produit : comment fonctionne l’extraction des sous-pages sur Amazon
Ce flux est largement sous-estimé — et aucun comparatif concurrent ne le déroule de bout en bout.
Quand vous extrayez une page de résultats Amazon, vous récupérez des données de synthèse : titres, prix, notes, ASIN et URLs produits. Mais il vous faut souvent aussi les données de la page de détail — descriptions complètes, puces, URLs d'images, infos vendeur, répartition des avis. C'est précisément le rôle de l'extraction des sous-pages.
Avec Thunderbit, le déroulé est le suivant :
- Extrayez la page de résultats Amazon -> vous obtenez un tableau de produits (titre, prix, note, ASIN, URL du produit).
- Cliquez sur "Scrape Subpages" -> Thunderbit visite chaque URL produit et ajoute les champs de détail (description, nombre d’avis, nom du vendeur, URLs d’images, etc.) dans le même tableau.
- Exportez le tableau enrichi vers Google Sheets, Airtable, Notion ou Excel.
L'IA détecte seule la structure des sous-pages et enrichit le tableau sans configuration manuelle. D'expérience, cela fait gagner au moins une heure par lot, comparé à l'ouverture manuelle de chaque page produit pour en recopier les champs.
D'autres outils savent le faire aussi, mais au prix de plus d'efforts :
- Web Scraper : vous montez un sitemap pour suivre les liens produits et fixez les sélecteurs de chaque champ de détail. Ça marche, mais c'est un parcours manuel en plusieurs étapes.
- Octoparse : vous construisez un workflow avec des étapes de suivi de liens. Puissant, mais loin du un clic.
- Axiom.ai : vous concevez une boucle de bot qui visite chaque URL et en extrait les données. Flexible, mais cela suppose de savoir bâtir des bots.
- Data Miner : vous passez par la fonction Crawl Scrape pour visiter les URLs sauvegardées et y appliquer une seconde recette. Manuel et tributaire des recettes.
- Instant Data Scraper et Helium 10 : aucun flux d'enrichissement des sous-pages.
Si vous avez régulièrement besoin, sur Amazon, des données de listing comme de détail, l'outil que vous retiendrez devrait rendre ce flux simple — pas seulement faisable.
Le vrai bilan de l’offre gratuite : ce que vous obtenez vraiment sans payer
C'est la question que les forums posent plus que toute autre, et qu'aucun comparatif concurrent ne tranche franchement.
| Extension | Offre gratuite | Ce que vous obtenez gratuitement | Quand il faut passer à la version supérieure |
|---|---|---|---|
| Thunderbit | Oui (6 pages, 10 avec essai) | Suggestion de champs par IA, tous les formats d’export (Excel, Sheets, Airtable, Notion), extracteurs e-mail/téléphone | Besoin de plus de pages ou de scraping programmé |
| Instant Data Scraper | Oui (totalement gratuit) | Détection basique des tableaux, export CSV/Excel | N/A (pas d’offre payante, mais pas de mises à jour non plus) |
| Web Scraper | Oui (navigateur uniquement) | Scraping dans le navigateur, export CSV | Scraping cloud, planification, intégrations |
| Octoparse | Oui (limité) | Environ 50K d’export/mois, extraction locale | Plus d’enregistrements, nœuds cloud |
| Axiom.ai | Oui (2 h d’exécution) | Automatisations de base, Google Sheets | Plus d’exécutions, planification, cloud |
| Data Miner | Oui (500 pages/mois) | Recettes, CSV/Excel, Next Page Automation | Plus de pages, Sheets, fonctions de crawl |
| Helium 10 | Oui (limité) | Accès limité à l’extension Chrome | Xray complet, outils mots-clés, planification |
L'enseignement central : l'offre gratuite de Thunderbit embarque les fonctions IA et tous les formats d'export — là où la plupart des concurrents réservent l'IA ou les exports avancés aux forfaits payants. Instant Data Scraper est intégralement gratuit, mais sans IA, sans sous-pages et sans planification (et il n'est plus maintenu). Helium 10 propose certes un forfait gratuit, mais l'accès à l'extension y est bridé et ce n'est pas un extracteur généraliste.
Ma recommandation selon le besoin :
- « Je veux juste tester » -> Instant Data Scraper (entièrement gratuit) ou l'offre gratuite de Thunderbit
- « Il me faut un scraping régulier et fiable » -> Thunderbit ou les forfaits payants de Web Scraper
- « Vendeur Amazon en quête d'analyses de marché » -> Helium 10
Quelle extension Chrome de scraping Amazon devriez-vous choisir ?
Après avoir éprouvé les sept, voici mon verdict en toute franchise :
- Meilleur choix pour les utilisateurs non techniques qui veulent des résultats rapides, pilotés par IA : Thunderbit. Détection automatique des champs, enrichissement des sous-pages en un clic, le plus large choix d'exports, bascule cloud/navigateur. Pour passer d'une page Amazon à un tableur en moins de deux minutes, c'est la bonne pioche.
- Meilleure option totalement gratuite pour des extractions ponctuelles et rapides : Instant Data Scraper. Sans frais, sans compte, mais fonctions limitées et plus maintenu.
- Meilleur choix pour les utilisateurs à l'aise avec une configuration manuelle : Web Scraper. Générateur de sitemap flexible, bonne option cloud, documentation solide.
- Meilleur choix pour les pipelines de scraping complexes et multi-étapes : Octoparse (desktop + extension) ou Axiom.ai (bots de navigateur). Les deux ont du coffre, mais aucun n'est une pure extension Chrome « installer et utiliser ».
- Meilleur choix pour une extraction simple à base de recettes : Data Miner. Commode pour réutiliser des recettes existantes, mais offre gratuite serrée et pas d'IA.
- Meilleur choix pour l'intelligence vendeur Amazon (pas pour le scraping généraliste) : Helium 10. Conçu pour ça, données propriétaires très riches, mais cher et pas un extracteur généraliste.
Pour voir à quoi ressemble concrètement le scraping Amazon piloté par IA, essayez l'offre gratuite de Thunderbit. Je parie que vous serez surpris de tout ce que quelques clics permettent d'accomplir. Et si Thunderbit ne vous convient pas parfaitement, testez quelques autres outils de cette liste — le moment n'a jamais été aussi propice pour ranger le copier-coller et extraire plus intelligemment.
Pour aller plus loin sur le scraping Amazon, parcourez nos guides sur comment extraire des produits et des avis Amazon, l'extraction des prix Amazon et l'extraction et l'analyse des données de ventes Amazon. Vous pouvez aussi suivre des tutoriels sur la chaîne YouTube Thunderbit.
Essayer le scraping Amazon par IA avec Thunderbit Get Started Free
FAQ
1. Est-il légal d’extraire des données produit Amazon ?
L'extraction de données publiques est généralement tolérée, mais les conditions d'utilisation d'Amazon proscrivent explicitement le data mining et l'extraction automatisée sans accord écrit. Cet article ne vaut pas conseil juridique — vérifiez toujours les conditions d'Amazon avant tout scraping à grande échelle.
2. Amazon peut-il détecter et bloquer les extracteurs sous forme d’extension Chrome ?
Oui. Amazon dispose de systèmes anti-bot capables de déclencher des CAPTCHA, de brider les requêtes ou de bloquer des IP. Adopter des cadences raisonnables, privilégier le scraping navigateur pour les petits volumes et recourir au scraping cloud avec limitation de débit pour les gros volumes permet d'abaisser le risque. Reportez-vous à la section cloud vs navigateur ci-dessus pour une matrice de décision pratique.
3. Quelles données peut-on extraire d’Amazon avec une extension Chrome ?
Les champs courants : titres de produits, prix, notes, nombre d'avis, ASIN, noms des vendeurs, descriptions, URLs d'images, disponibilité et informations de livraison. Des outils pilotés par IA comme Thunderbit savent détecter et suggérer ces champs automatiquement, sans configuration manuelle.
4. Faut-il savoir coder pour utiliser une extension Chrome de scraping Amazon ?
Non — les sept outils testés s'adressent à des utilisateurs non techniques. Certains demandent plus de configuration (Web Scraper, Octoparse, Axiom.ai), d'autres sont quasiment sans réglage (Thunderbit, Instant Data Scraper). Le compromis se joue le plus souvent entre flexibilité et facilité d'usage.
5. Quelle extension Chrome de scraping Amazon a la meilleure offre gratuite ?
L'offre gratuite de Thunderbit inclut la détection de champs par IA et tous les formats d'export (Sheets, Airtable, Notion, Excel, CSV, JSON), là où la plupart des concurrents les réservent aux forfaits payants. Instant Data Scraper est totalement gratuit mais sans IA, sans sous-pages et sans planification. Data Miner offre 500 pages gratuites/mois. Le forfait gratuit d'Helium 10 est limité et centré sur la veille vendeur, pas sur le scraping généraliste.
En savoir plus




