Qu’est-ce qu’un Amazon Web Scraper ?
Un Amazon Web Scraper est un outil ou un logiciel malin conçu pour extraire automatiquement des données depuis . Ces données peuvent inclure les informations produit, les prix, les avis, le stock disponible et bien plus encore. Son objectif principal est de collecter de grands volumes de données pour l’étude de marché, la comparaison des prix ou l’analyse concurrentielle. Vous pouvez aussi récupérer les avis utilisateurs pour la recherche de mots-clés, afin de mieux cerner les points forts et les points faibles des produits.
Fonctionnalités clés d’un Amazon Web Scraper
- Extraction automatisée des données : dites adieu au copier-coller manuel, une tâche fastidieuse. Un extracteur Web peut récupérer automatiquement les données dont vous avez besoin sur les pages web.
- Extraction personnalisable : vous pouvez configurer l’extracteur pour récupérer des champs de données précis selon vos besoins, ce qui permet une analyse ciblée.
- Export des données : exportez facilement les données extraites vers des formats courants comme Excel, CSV ou JSON pour une analyse plus poussée avec différents outils de données.
- Mises à jour régulières : définissez des intervalles d’extraction pour garder votre base de données de produits Amazon à jour et garantir la fraîcheur des données.
- Extraction d’avis : bien souvent, il faut extraire les points forts et les points faibles depuis la section des avis pour l’analyse concurrentielle.

Pourquoi utiliser un Amazon Web Scraper ?
Amazon est un acteur majeur du e-commerce mondial, connu pour son immense catalogue de produits, ses prix compétitifs et une expérience d’achat fluide. La plateforme permet aux entreprises de toucher des clients potentiels partout dans le monde et d’élargir leur portée commerciale. Les consommateurs considèrent Amazon comme une référence pour leurs achats en ligne, ce qui en fait un environnement de vente fiable pour les marchands. En plus, le réseau logistique d’Amazon permet aux entreprises de s’appuyer sur des livraisons rapides et efficaces, ce qui améliore la satisfaction client. Amazon propose aussi plusieurs outils marketing pour accroître la visibilité des produits et les ventes, comme les publicités sponsorisées et les promotions de marque.
Pour les entreprises e-commerce, analyser les données de vente sur Amazon est essentiel. Grâce à un Amazon Web Scraper, elles peuvent collecter des données pour mieux comprendre les tendances du marché et le comportement des consommateurs, optimiser leurs stratégies produits et la gestion des stocks. Cela peut aider les entreprises à se développer efficacement sur la plateforme Amazon, à augmenter leurs ventes et la notoriété de leur marque, pour une croissance durable. Voici comment vous pouvez utiliser un Amazon Web Scraper pour l’analyse :
Étude de marché
-
Sélection des SKU
Choisir le bon SKU (Stock-Keeping Unit) est essentiel pour réussir dans l’e-commerce, car cela influence l’assortiment des produits, l’efficacité de la chaîne d’approvisionnement et la gestion des stocks. Avec un Amazon Web Scraper, vous pouvez extraire des données précises à partir de millions de produits afin d’analyser les tendances de vente et les préférences des clients. Par exemple, en extrayant les données des pages produit Amazon, vous pouvez facilement accéder à des informations clés comme les prix, le nombre d’avis et les notes des vendeurs pour une analyse de marché approfondie. Ces données aident à déterminer si un SKU a un potentiel commercial et à identifier quels produits performent le mieux. En comparant les produits d’une même catégorie, les entreprises peuvent affiner leur sélection, augmenter les stocks des SKU populaires et réduire ceux des articles qui se vendent lentement, ce qui améliore la rotation des stocks.
-
Identifier les tendances clients
En extrayant un grand volume d’avis produits, de notes et de retours clients, un extracteur Web peut vous aider à repérer rapidement les évolutions de la demande. Par exemple, en analysant les données d’avis, vous pouvez identifier les caractéristiques que les consommateurs apprécient le plus dans un produit, comme « prix abordable » ou « durabilité ». Ces informations sont essentielles pour le développement produit, la stratégie tarifaire et la stratégie marketing. De plus, l’extraction des données sur la fréquence d’achat et les tendances de vente dans le temps peut vous aider à anticiper les fluctuations saisonnières et à planifier à l’avance les opérations de stock et de marketing.

Analyse concurrentielle
-
Surveillance des prix
Dans un environnement concurrentiel, surveiller les prix est indispensable pour les entreprises e-commerce. Un Amazon Web Scraper peut vous aider à extraire des données produit en temps réel afin de suivre les variations de prix des concurrents et de maintenir des tarifs compétitifs. Cette fonctionnalité est particulièrement utile pour mettre en place des stratégies de tarification dynamique. En collectant des informations sur des produits similaires, les entreprises peuvent créer des modèles de prix flexibles qui ajustent automatiquement les tarifs en fonction de la demande du marché, des niveaux de stock et des prix des concurrents afin de maximiser les profits.
-
Extraction d’avis
n’influencent pas seulement les ventes d’un produit, ils reflètent aussi les évolutions de la demande du marché. Un Amazon Web Scraper peut aider les entreprises à collecter un grand volume de retours clients. Les extracteurs Web basés sur l’IA peuvent faciliter la synthèse et l’analyse des sentiments afin de mieux comprendre les opinions des utilisateurs sur vos produits et ceux de vos concurrents, ce qui vous permet d’ajuster rapidement la conception produit ou les stratégies marketing.
Comparaison des coûts
En utilisant un Amazon Web Scraper, les entreprises peuvent collecter des données sur les prix, les frais de livraison et les promotions de produits similaires pour une comparaison des coûts complète. L’analyse de ces données aide les entreprises à optimiser leur structure de coûts, à éviter les dépenses inutiles et à augmenter leurs marges bénéficiaires. Pour les entreprises à la recherche de fournisseurs sur Amazon, cela fournit aussi des informations sur les frais de livraison et les prix de vente de différents vendeurs, réduisant les coûts et garantissant une tarification compétitive sur le marché, tout en améliorant au final la marge brute.
Essayez l’IA pour l’extraction de données Web
Essayez-le ! Vous pouvez cliquer, explorer et lancer le workflow pendant que vous regardez.
Pourquoi utiliser l’IA pour extraire des données produits Amazon ?
Avec les progrès rapides de l’IA, les outils Amazon Web Scraper pilotés par l’IA ouvrent une nouvelle ère de l’extraction de données, en apportant de nombreux avantages par rapport aux méthodes traditionnelles. L’IA rend non seulement la collecte de données plus efficace et plus précise, mais elle abaisse aussi considérablement la barrière technique, offrant ainsi des opportunités plus innovantes aux entreprises e-commerce.
Simple à utiliser pour les non-techniciens
Pour les utilisateurs sans profil technique, les outils Amazon Web Scraper assistés par l’IA offrent une grande simplicité d’usage. Contrairement aux extracteurs traditionnels qui exigent du codage manuel et des appels API, il suffit aux utilisateurs d’indiquer leurs besoins d’extraction et de sélectionner les noms de colonnes souhaités. L’IA génère automatiquement des plans d’extraction et des suggestions adaptés, en éliminant les tracas liés à la programmation et aux réglages complexes. Cette fonctionnalité conviviale aide les équipes e-commerce à obtenir efficacement des données sans avoir recours à des spécialistes techniques, ce qui améliore la productivité de l’équipe et permet aux collaborateurs non techniques d’utiliser facilement des outils avancés de collecte de données.
Rapide et efficace
automatise le processus d’extraction de données, ce qui augmente fortement la vitesse et l’efficacité de l’extraction. Il peut traiter rapidement des structures de sites complexes et du contenu dynamique, capturer avec précision les données ciblées, réduire les interventions manuelles et améliorer la précision globale de l’extraction. De plus, peut réduire considérablement les coûts opérationnels et optimiser les flux de travail, permettant aux entreprises d’obtenir des données de haute qualité à moindre coût et d’apporter un support plus précis à la prise de décision.
Analyse intelligente et suggestions
Par rapport aux extracteurs Web traditionnels, offre l’avantage d’une automatisation intelligente des workflows. Les outils d’IA peuvent automatiquement catégoriser les données, les résumer et fournir des insights. Par exemple, les entreprises peuvent utiliser l’IA pour classer automatiquement différents produits dans des catégories prédéfinies ou analyser de grands volumes d’avis afin d’en extraire des mots-clés et des tendances de sentiment, ce qui les aide à mieux comprendre les retours clients et à optimiser leurs produits. L’IA peut aussi générer des rapports personnalisés à partir des données extraites, en produisant automatiquement des analyses de marché pour aider les entreprises à identifier rapidement les caractéristiques de produits populaires et les opportunités de marché potentielles.
Sortie intelligente et options d’export
Utiliser un Amazon web scraper basé sur l’IA permet une sortie de données plus intelligente. Les méthodes de codage traditionnelles ne produisent généralement que des fichiers CSV, tandis que les outils d’IA prennent en charge le format CSV et peuvent exporter automatiquement les données extraites vers des plateformes collaboratives comme Google Sheets et Notion, ce qui facilite grandement l’analyse et le partage des données. Par exemple, vous pouvez importer directement les données dans Google Sheets pour une analyse en temps réel ou les intégrer à des outils de collaboration d’équipe, garantissant ainsi une circulation fluide de l’information entre les services. Cette méthode intelligente d’export des données permet aux équipes de prendre des décisions plus rapidement, améliorant la flexibilité globale de l’entreprise et sa réactivité.
Extraction avec : l’
est un outil d’extraction Web piloté par l’IA, récemment lancé, puissant et complet, conçu pour répondre à vos besoins en données. Avec Thunderbit, les utilisateurs peuvent facilement collecter des données depuis Amazon, qu’il s’agisse des détails produit, des variations de prix ou des avis clients, puis les transformer rapidement en insights métier exploitables. Voici comment Thunderbit peut aider les entreprises e-commerce à renforcer leur compétitivité.
Commencez par visiter le et ajoutez l’ Thunderbit à votre navigateur Chrome. Connectez-vous avec votre compte Google ou une autre adresse e-mail.
 Ensuite, vous pouvez utiliser l’extracteur Web intégré de Thunderbit ou pour . Voici comment faire :
Ensuite, vous pouvez utiliser l’extracteur Web intégré de Thunderbit ou pour . Voici comment faire :
Option 1 : utiliser l’extracteur Web préconfiguré de Thunderbit
a conçu et optimisé différents extracteurs Web préconfigurés selon les besoins des utilisateurs, y compris un module d’extraction spécialement dédié à Amazon. Ces outils disposent de modèles préétablis pour la structure complexe des données Amazon et permettent de collecter de grandes quantités de données, ce qui vous évite de concevoir vous-même la logique d’extraction et accélère le processus pour une collecte plus rapide et plus efficace.
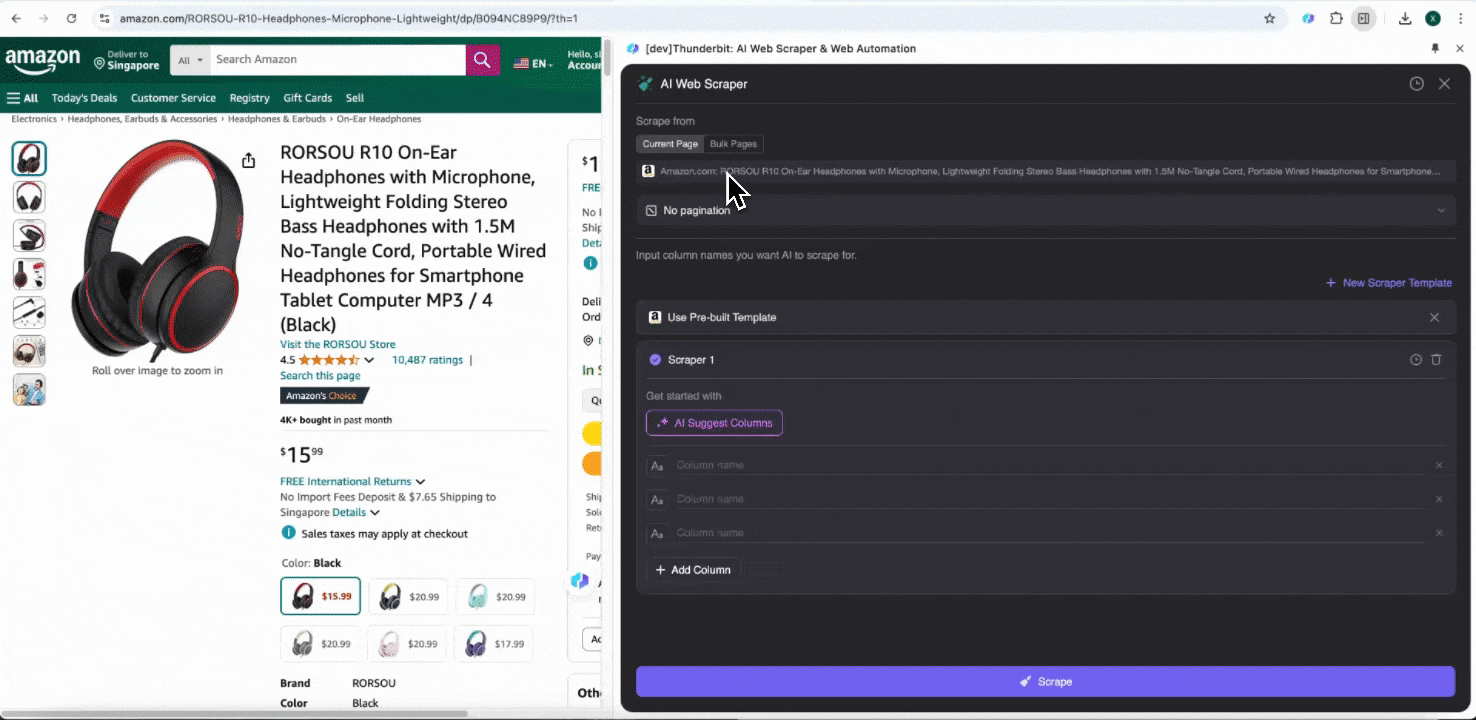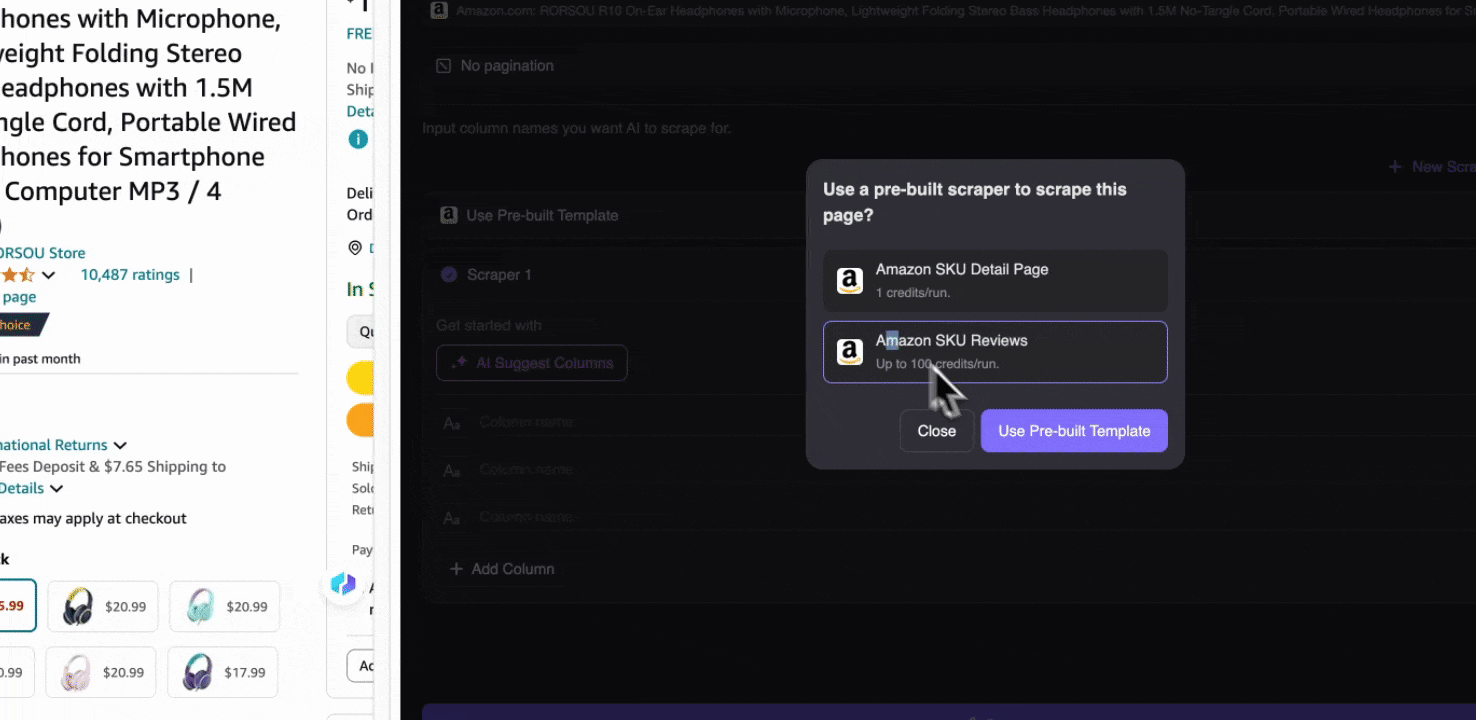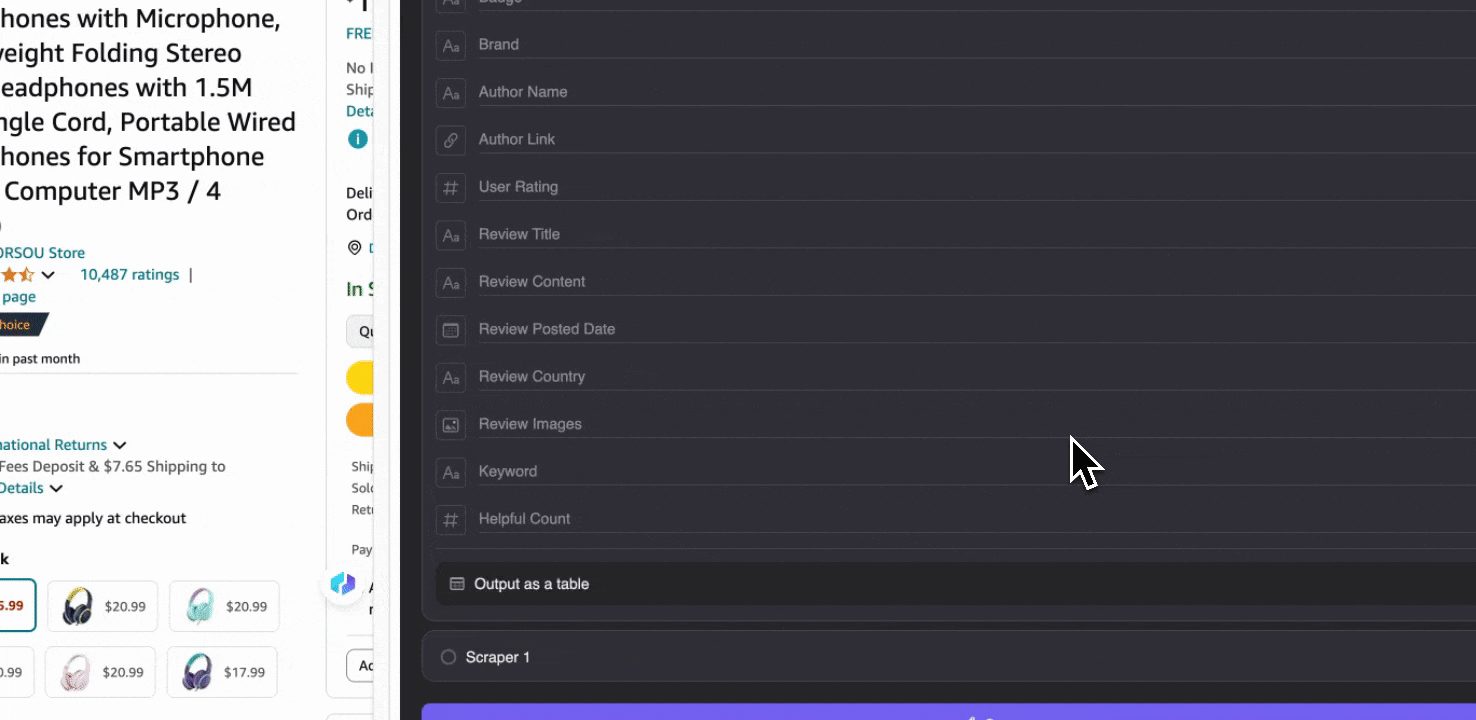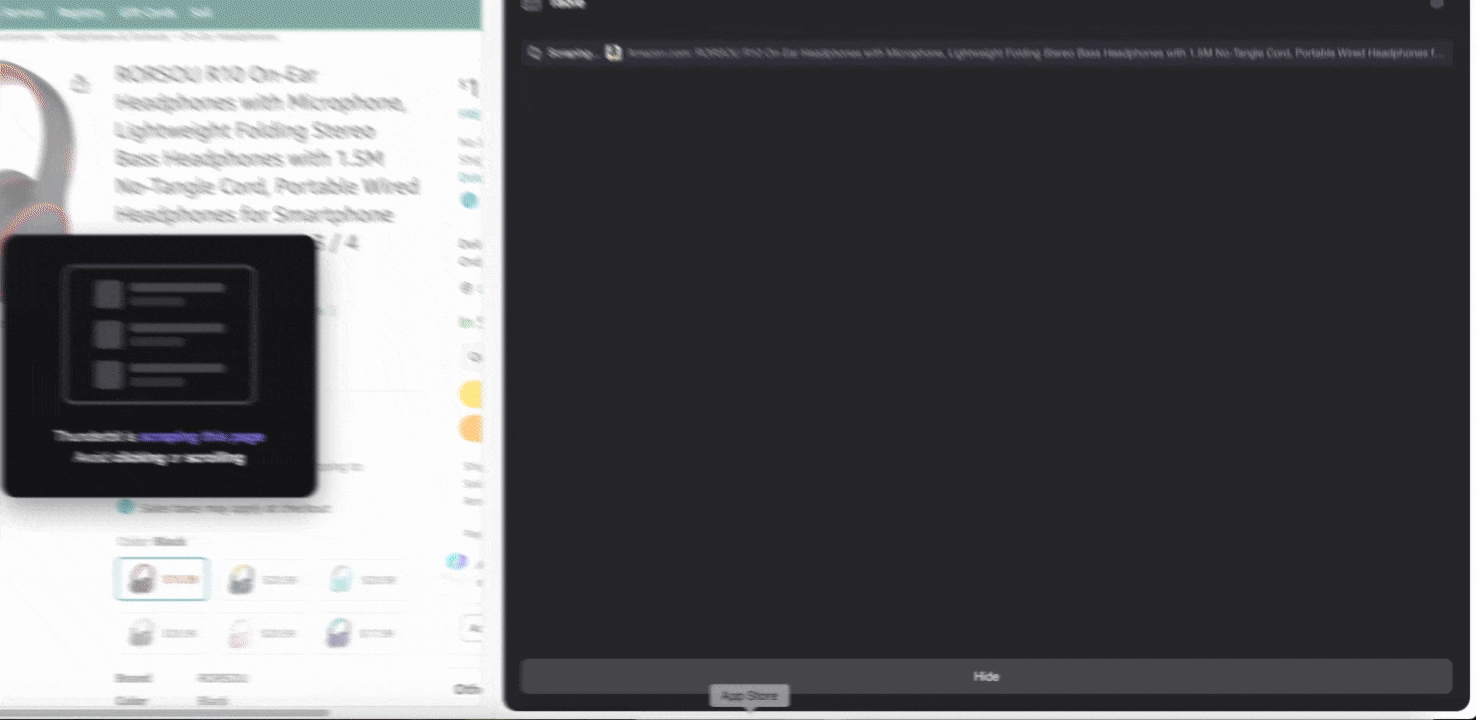
Lorsque vous ouvrez une page Amazon, lancez l’extracteur Web de l’extension Thunderbit. Vous verrez deux extracteurs préconfigurés avec de nombreux noms de colonnes. Il vous suffit de cocher les noms de colonnes que vous souhaitez extraire, et Thunderbit s’occupe du reste.
-
Collecter les avis SKU Amazon
Cet outil propose des noms de colonnes préconfigurés comme le nom du produit, l’URL du produit, la note globale du produit, le détail des notes, le nombre d’avis, le titre de l’avis, le nom de l’auteur, le contenu de l’avis, le pays de l’avis et les mots-clés. Vous pouvez cocher les colonnes que vous souhaitez extraire, cliquer sur extraire et obtenir rapidement les données d’avis SKU dont vous avez besoin pour l’analyse des avis produits.
-
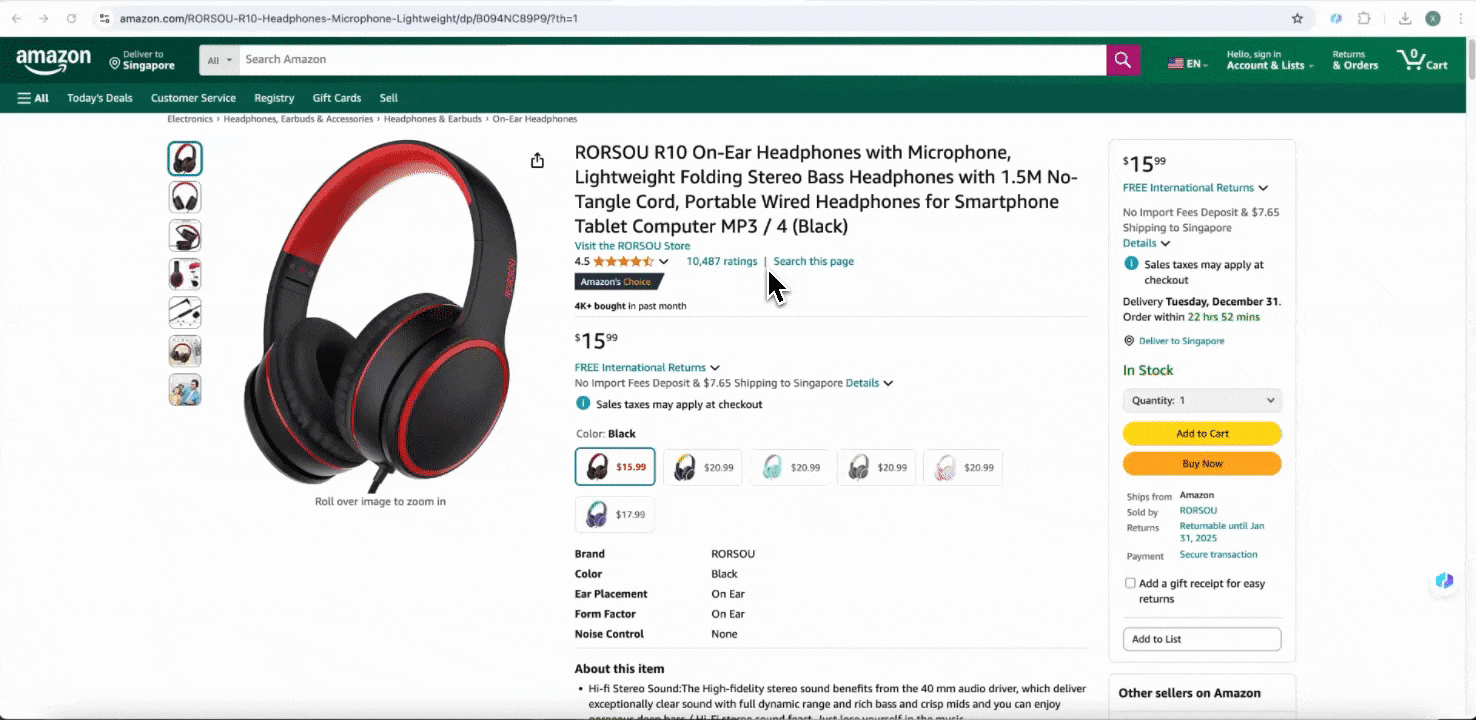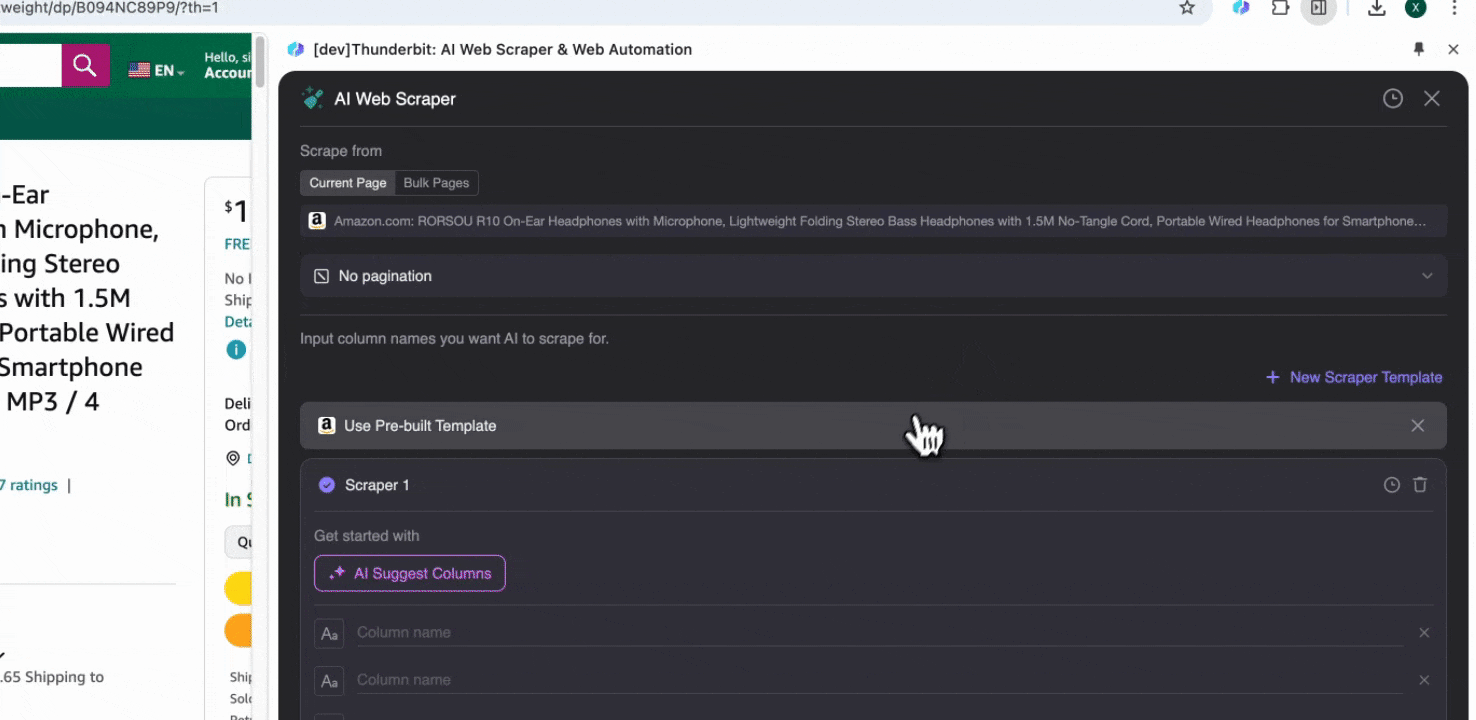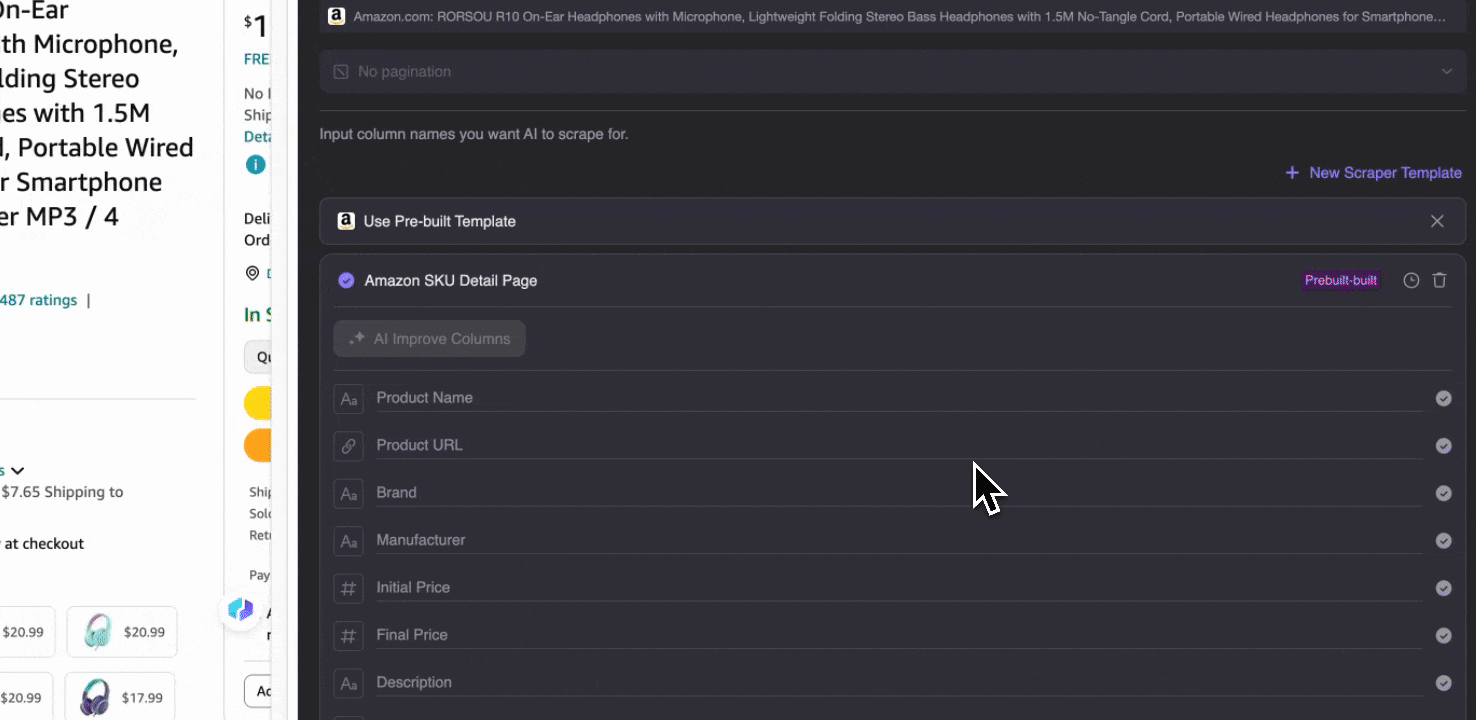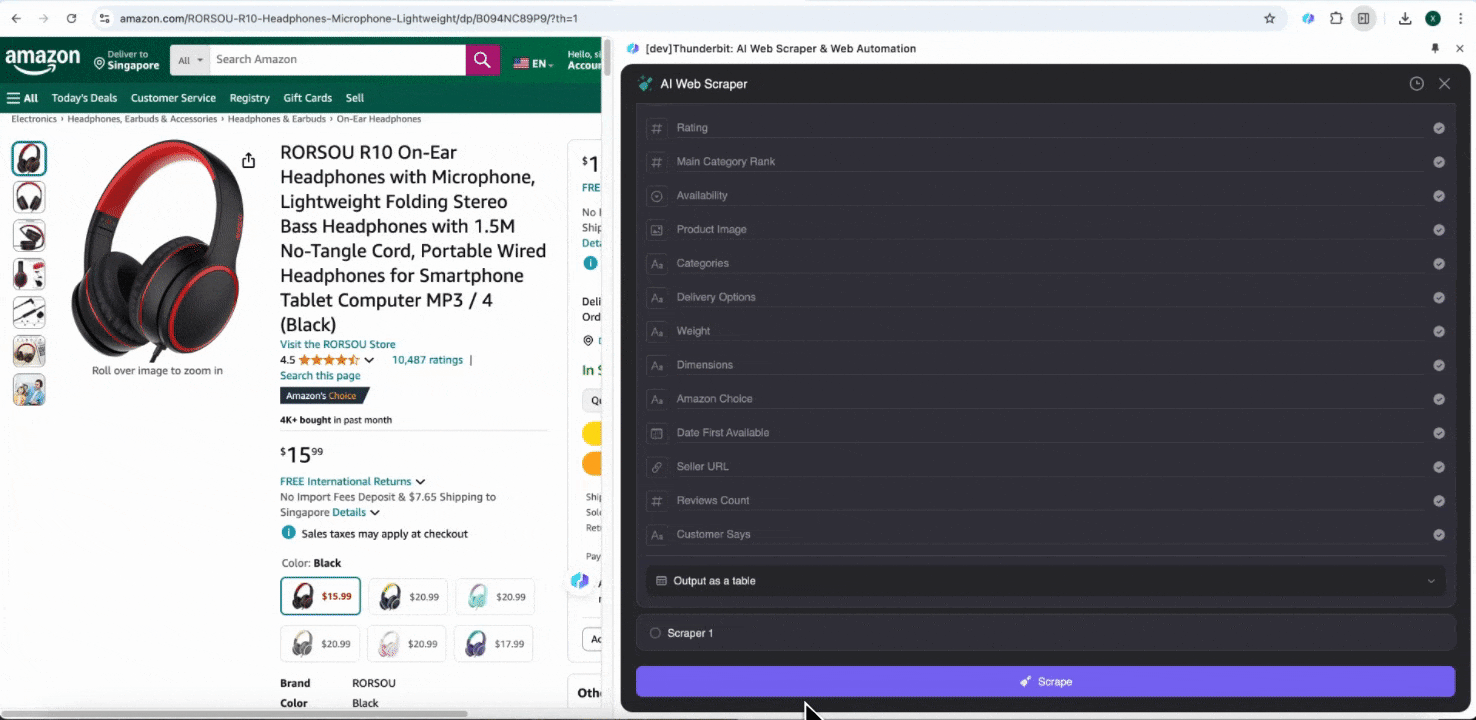
Collecter les détails SKU Amazon
Cet outil fournit des noms de colonnes préconfigurés comme le nom du produit, l’URL du produit, la marque, le fabricant, le prix initial, le prix final, la description, la note, les catégories, les options de livraison et l’URL du vendeur. Cochez les colonnes que vous souhaitez extraire, cliquez sur extraire et obtenez rapidement les données de détail SKU dont vous avez besoin. Que vous compariez des vendeurs, des fabricants et des options de livraison, que vous réalisiez une étude de marché, que vous évaluiez la compétitivité prix de votre SKU ou que vous compreniez les dernières tendances de vente, ces données de détail SKU vous aideront dans votre analyse.
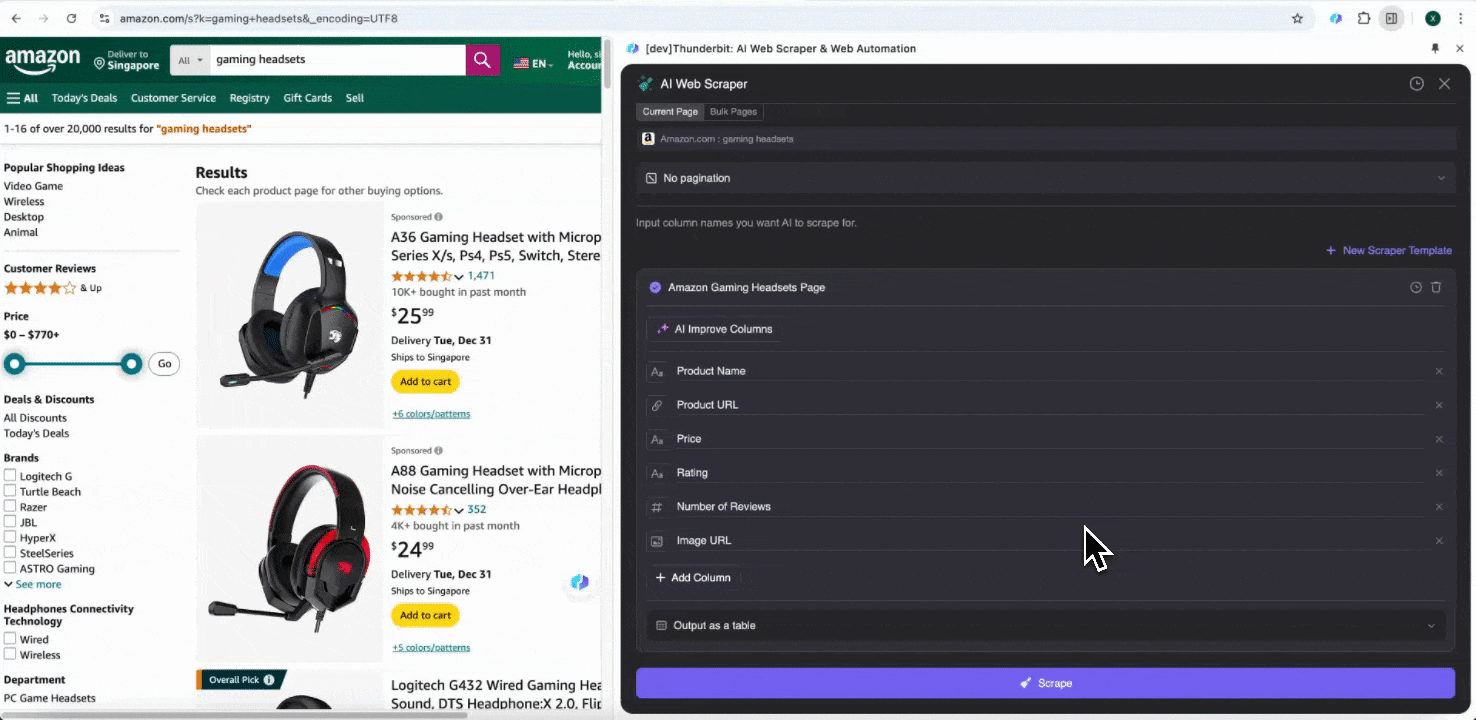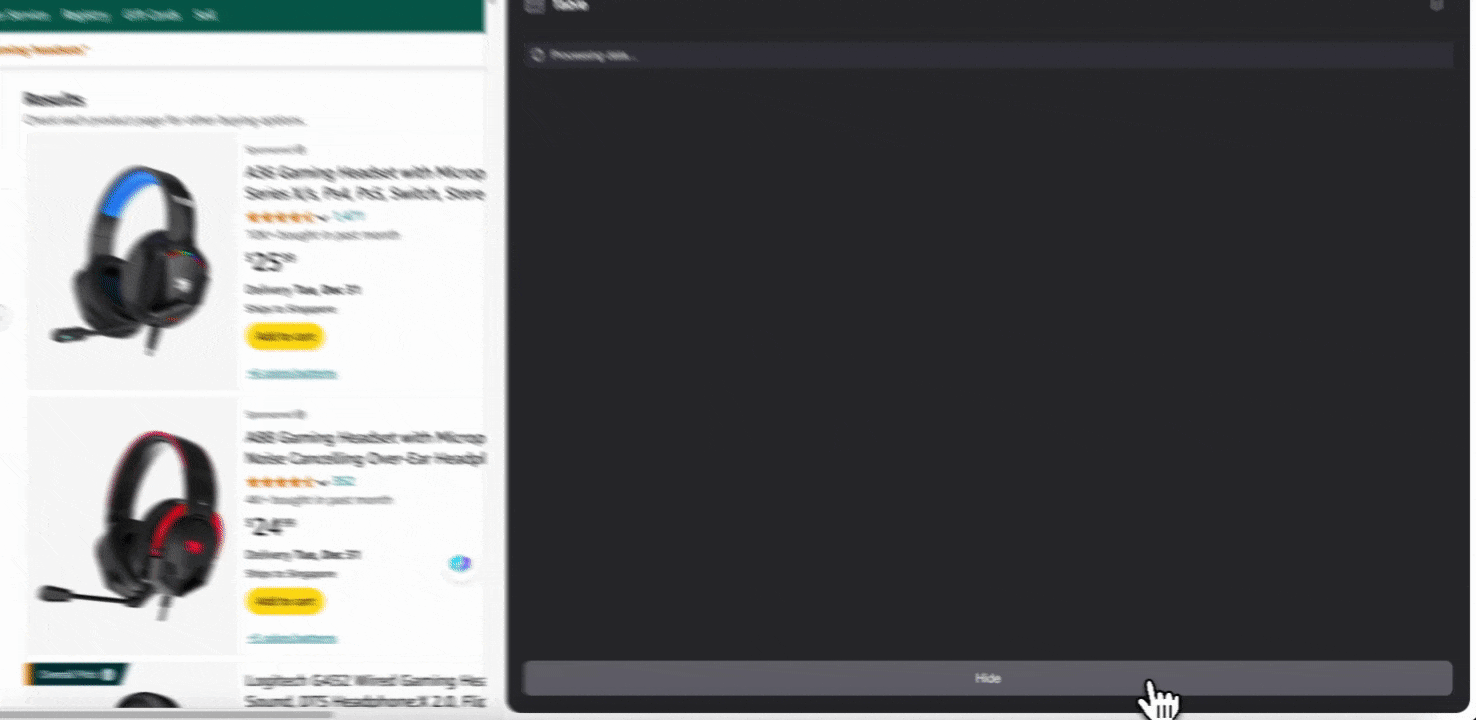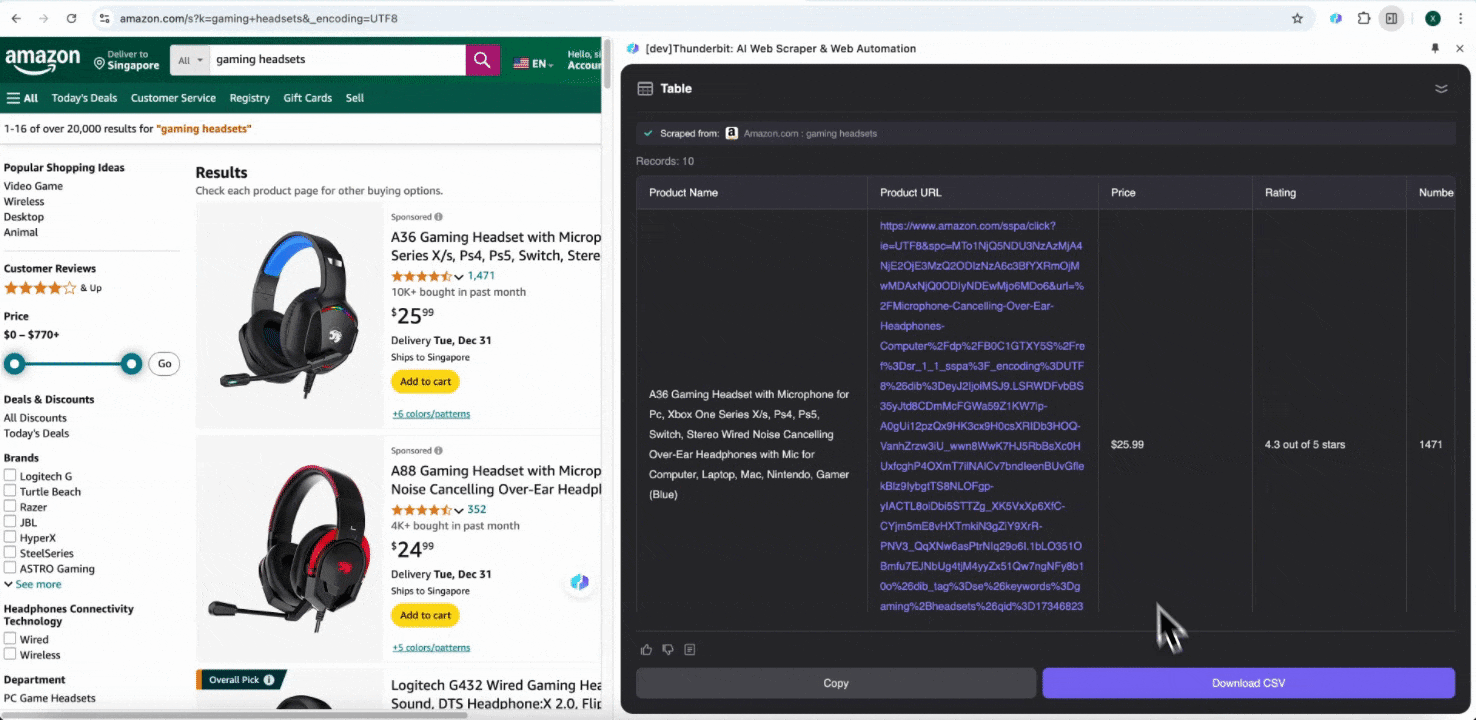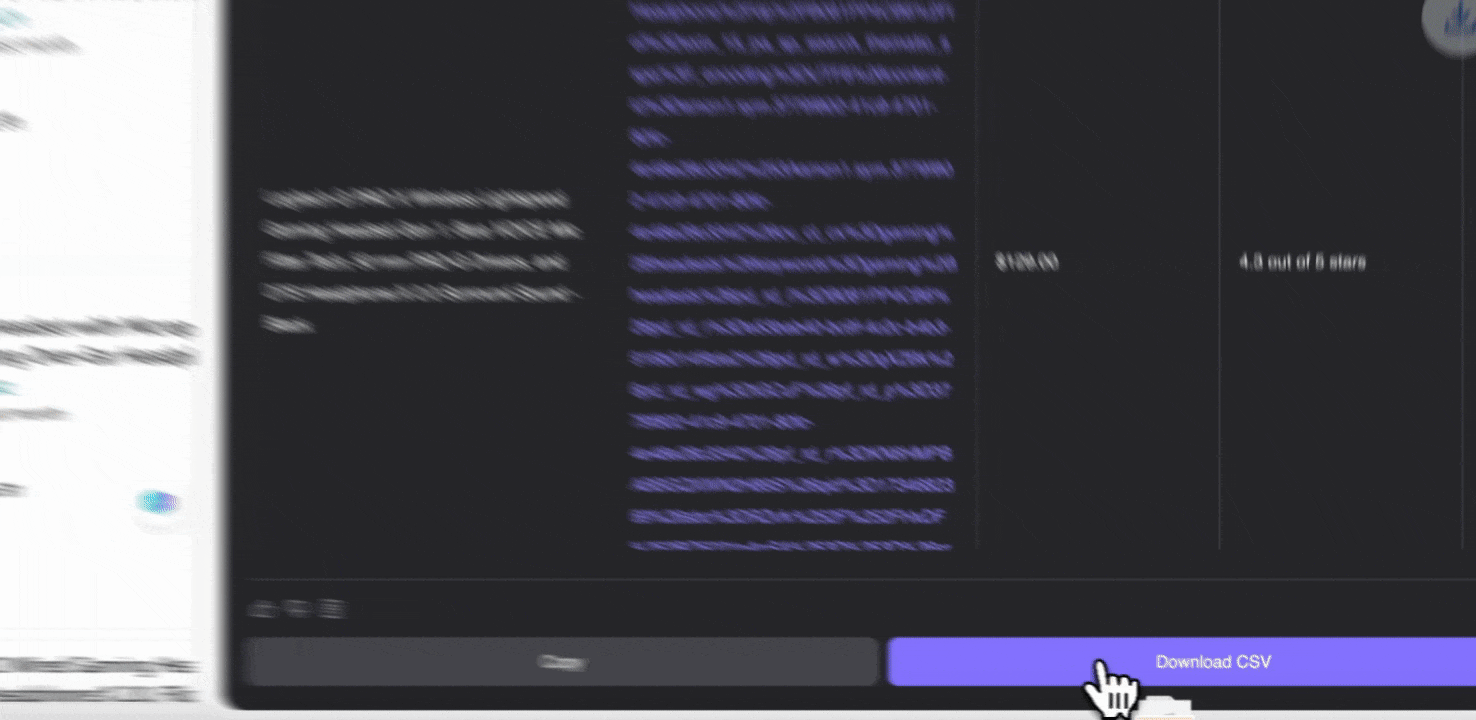
Option 2 : utiliser l’Extracteur Web IA de Thunderbit
Étape 1 : ouvrez et cliquez sur « » dans la barre latérale
Ouvrez le dans votre navigateur Chrome, recherchez ou accédez à la page depuis laquelle vous souhaitez extraire des données, puis cliquez sur l’icône Thunderbit en haut à droite de votre navigateur Chrome pour ouvrir l’extension Thunderbit et cliquer sur « ».
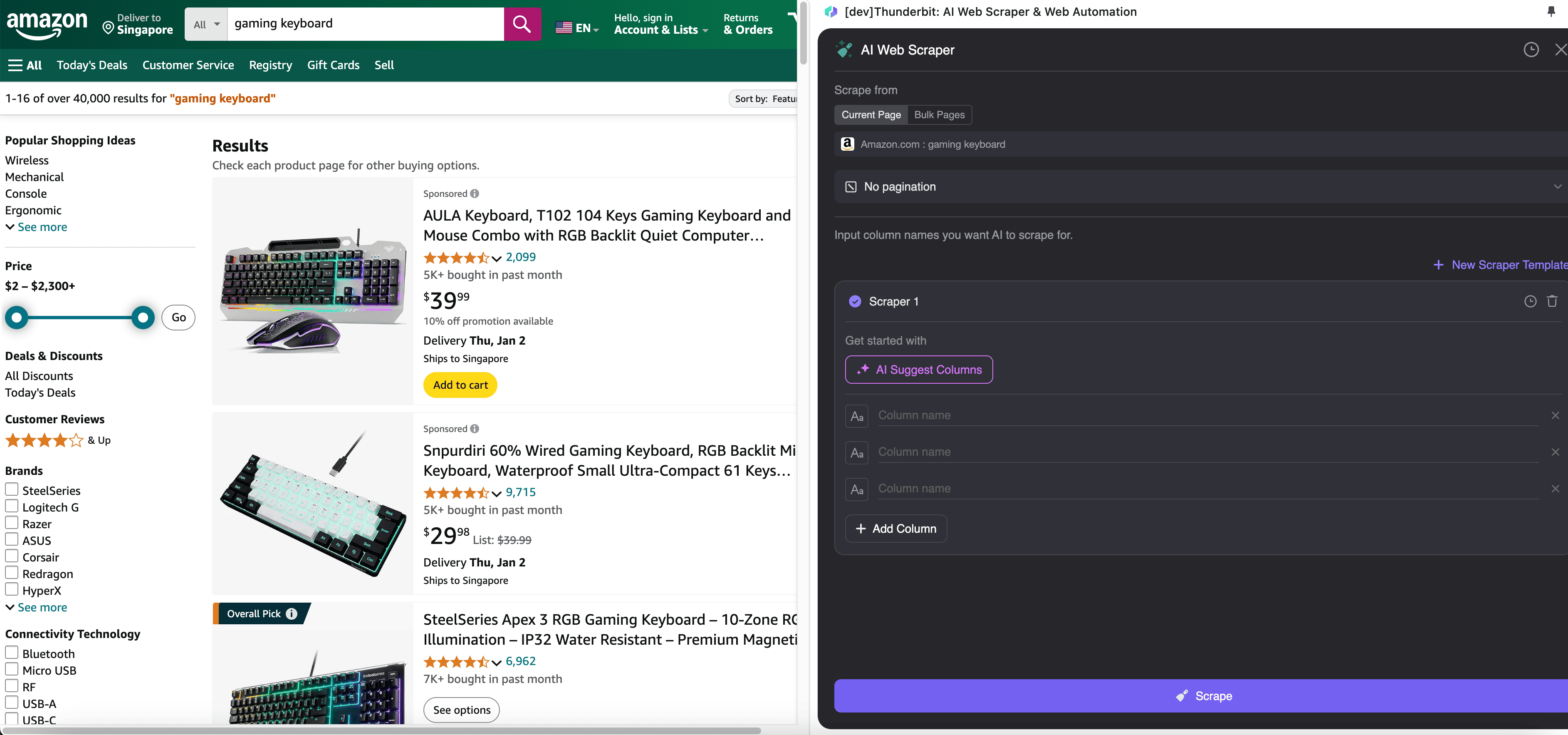
Étape 2 : personnalisez les champs de données que vous souhaitez extraire
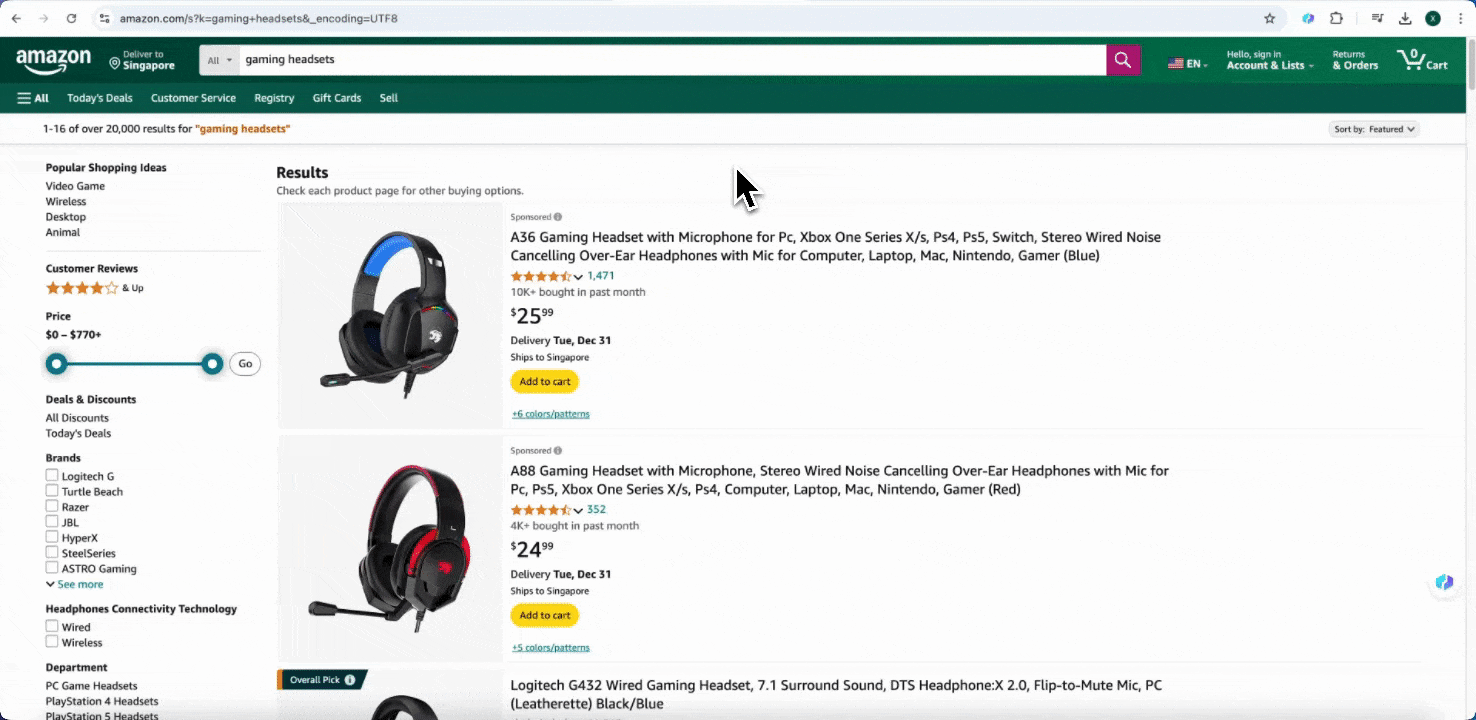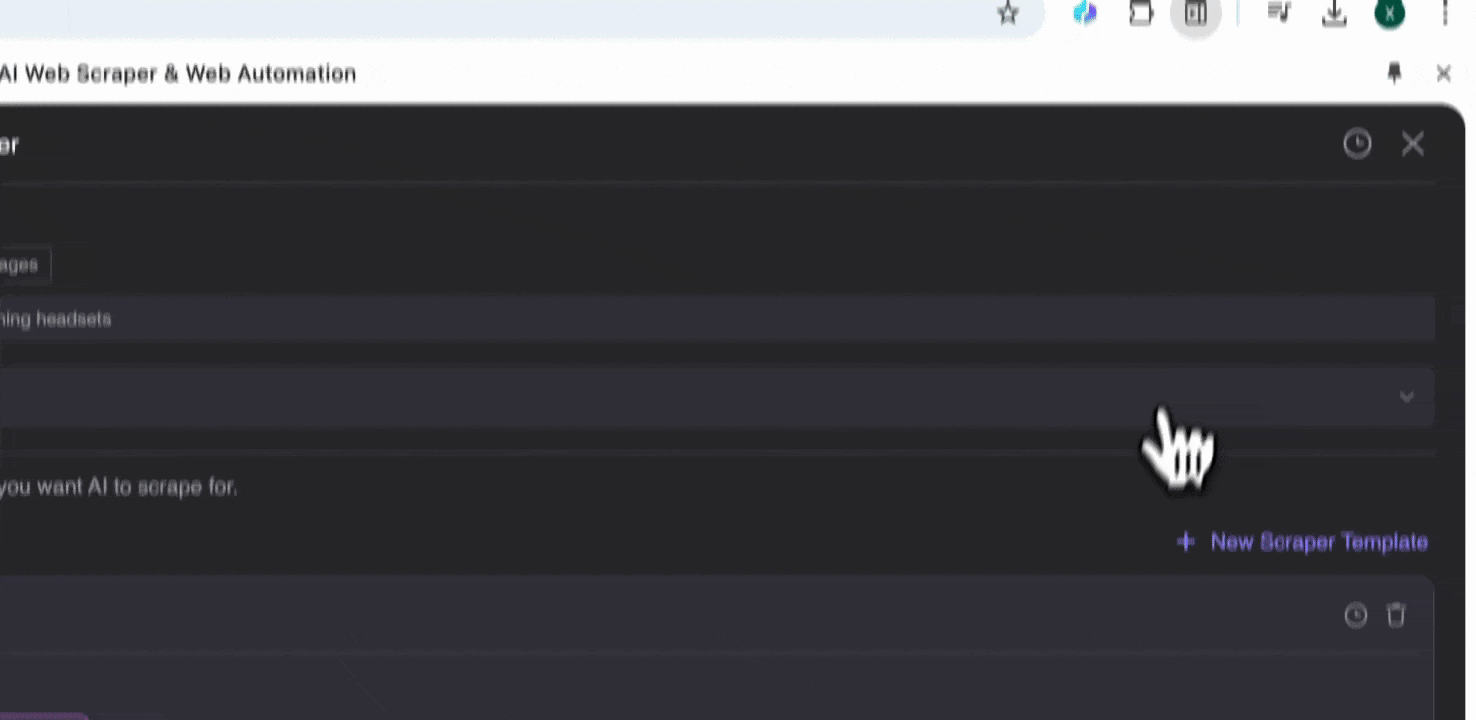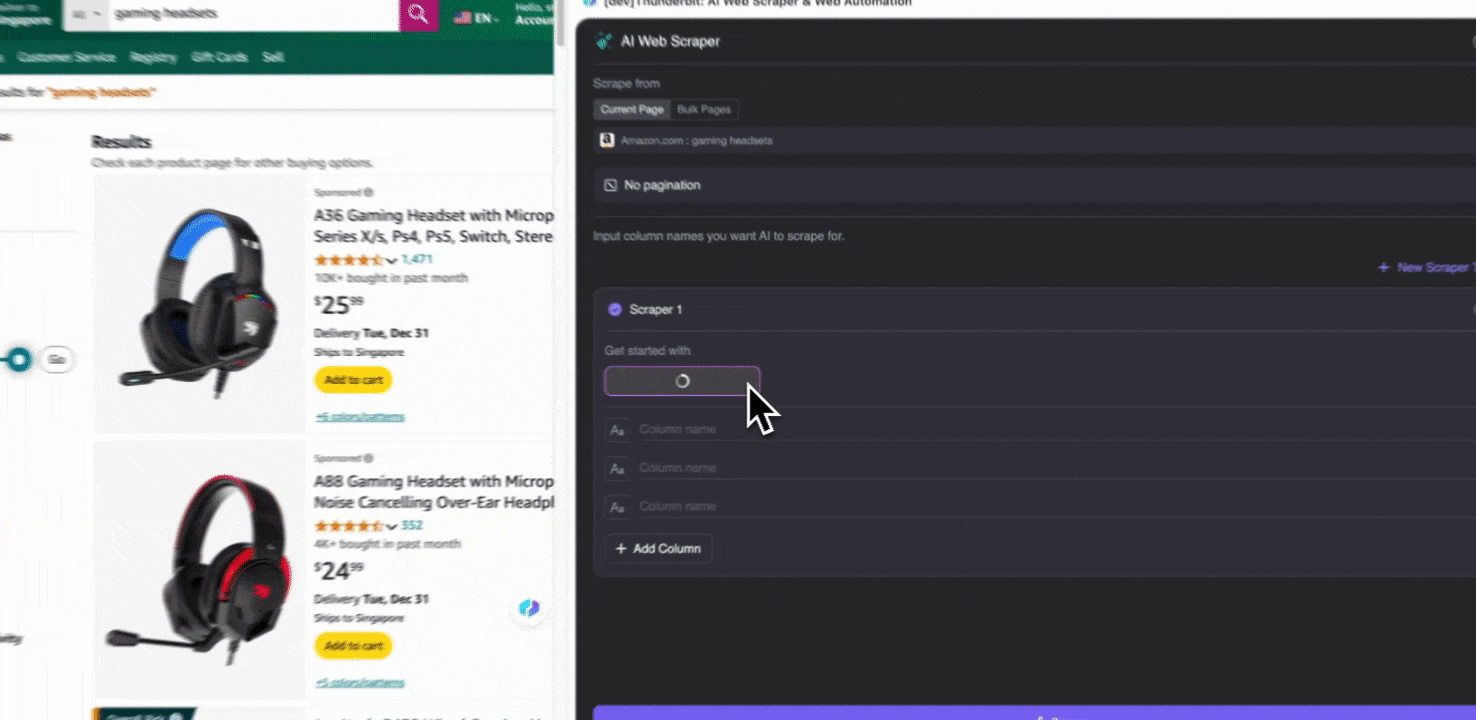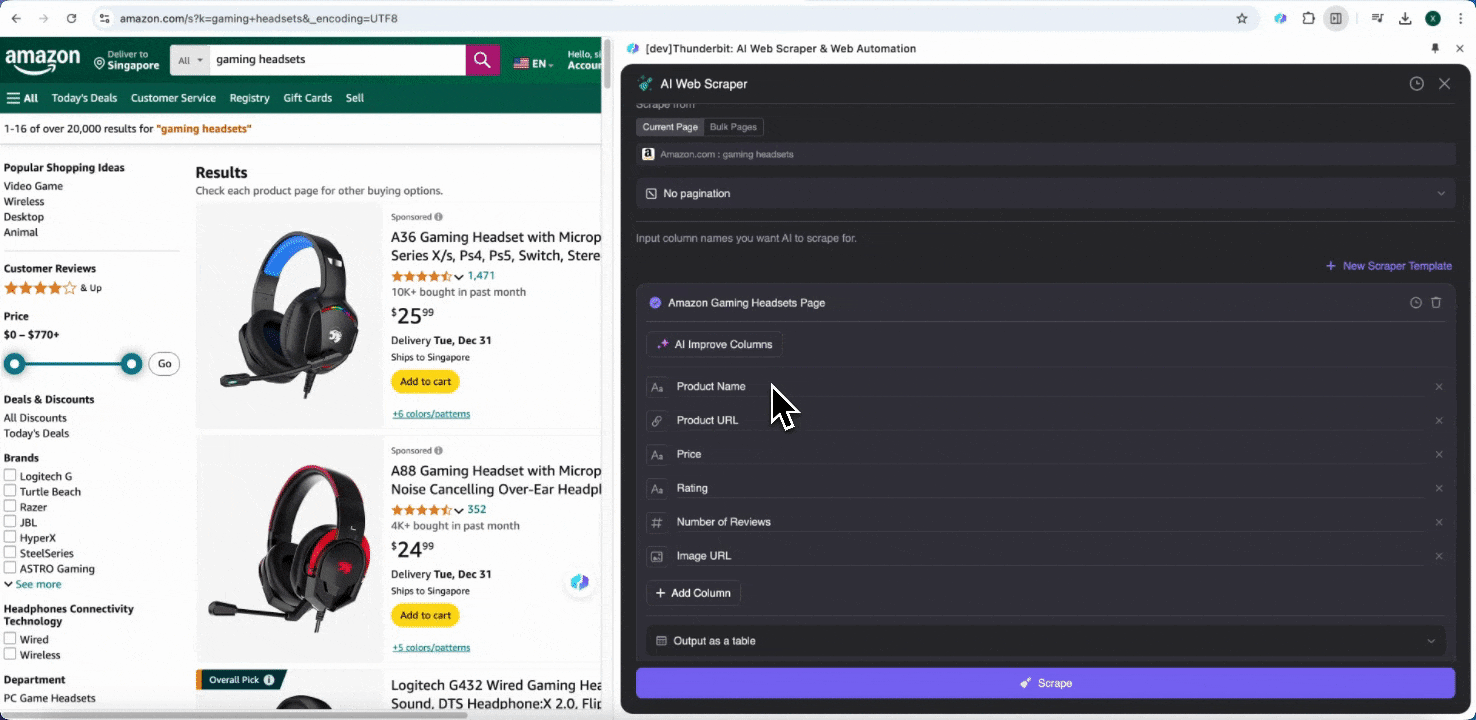
Si vous n’êtes pas sûr des balises de données à utiliser, cliquez sur Suggestion de colonnes IA pour laisser l’IA de Thunderbit générer automatiquement des noms de colonnes fiables. Vous pouvez aussi décrire en langage naturel les libellés de données souhaités et les saisir dans le champ du nom de colonne. Choisissez des icônes pour changer le type de données souhaité, qu’il s’agisse d’une image, d’une URL, d’un texte, d’un nombre ou d’un autre type de données, puis extrayez les données correspondantes.
Après avoir rempli les noms de colonnes initiaux, vous pouvez choisir Améliorer les colonnes avec l’IA pour laisser l’IA optimiser davantage vos entrées. Vous pouvez aussi ajouter des instructions détaillées pour adapter l’extraction à vos besoins. Par exemple, vous pouvez demander à ce que la colonne du type de produit classe les produits en catégories homme, femme, enfant et autres. Thunderbit classera alors chaque entrée de données de cette colonne dans les quatre catégories que vous avez définies. Vous pouvez également demander à Thunderbit de convertir tous les prix de la colonne des prix dans la devise souhaitée au taux de change actuel, afin d’obtenir facilement les valeurs nécessaires à votre analyse sans vous soucier des incohérences de devise.
Enfin, vous pouvez personnaliser la quantité de données souhaitée. Pour les pages produit Amazon, vous pouvez activer la pagination par clic et sélectionner le nombre de pages à extraire. Thunderbit tournera automatiquement les pages et extraira toutes les données de chaque page.
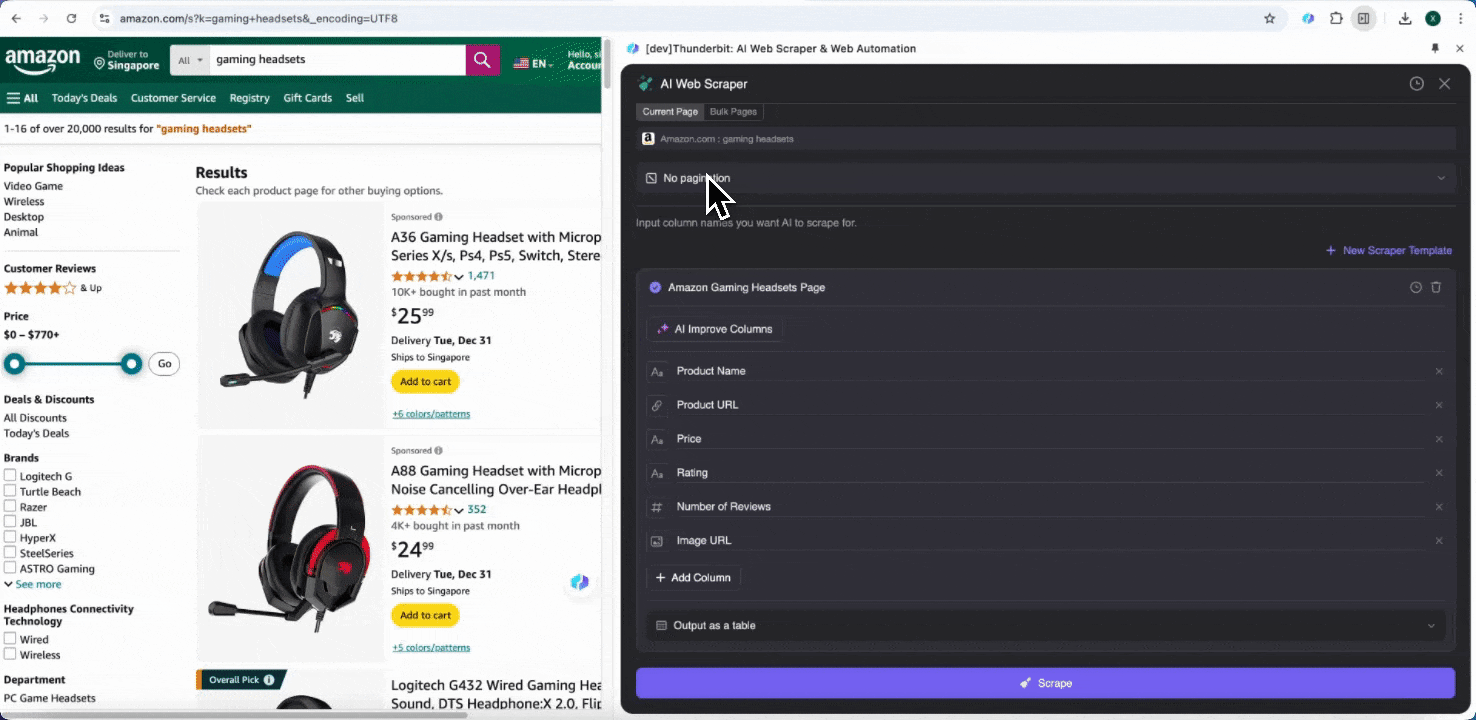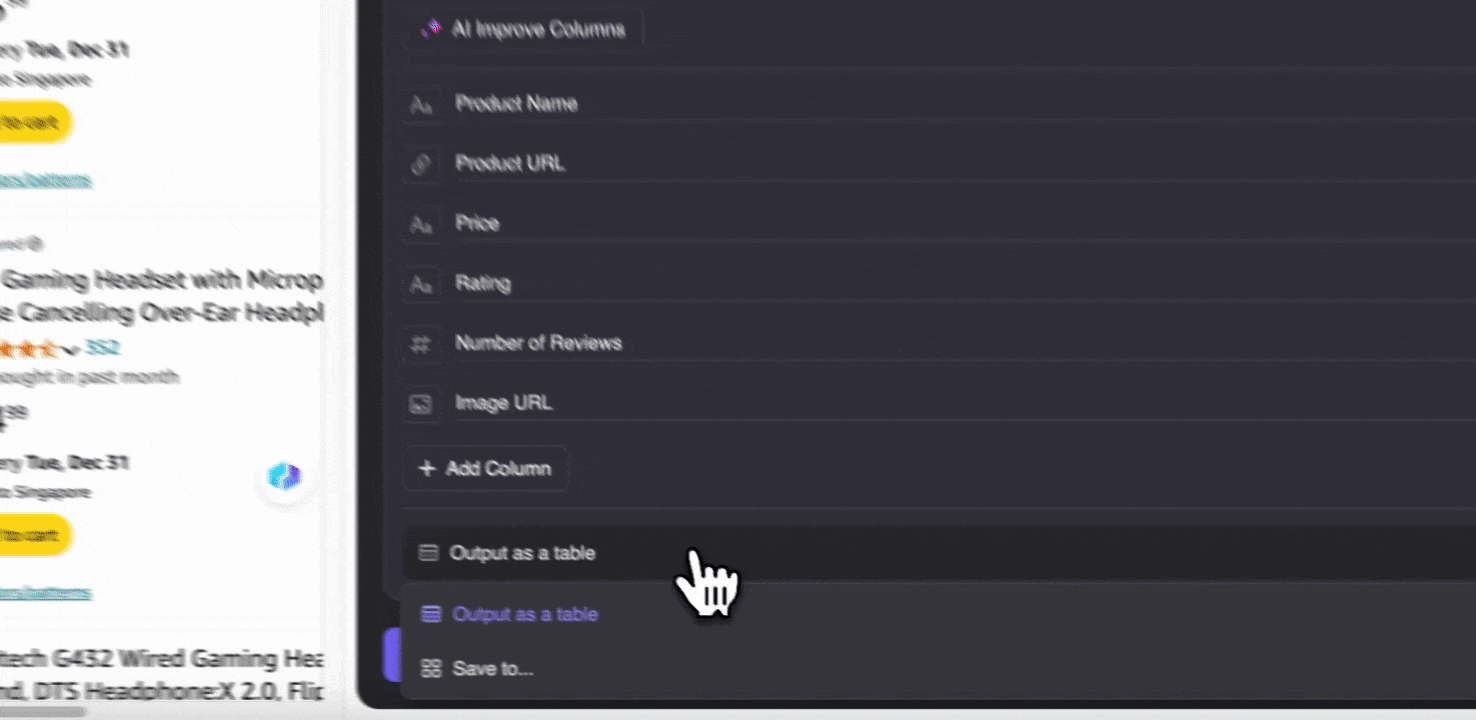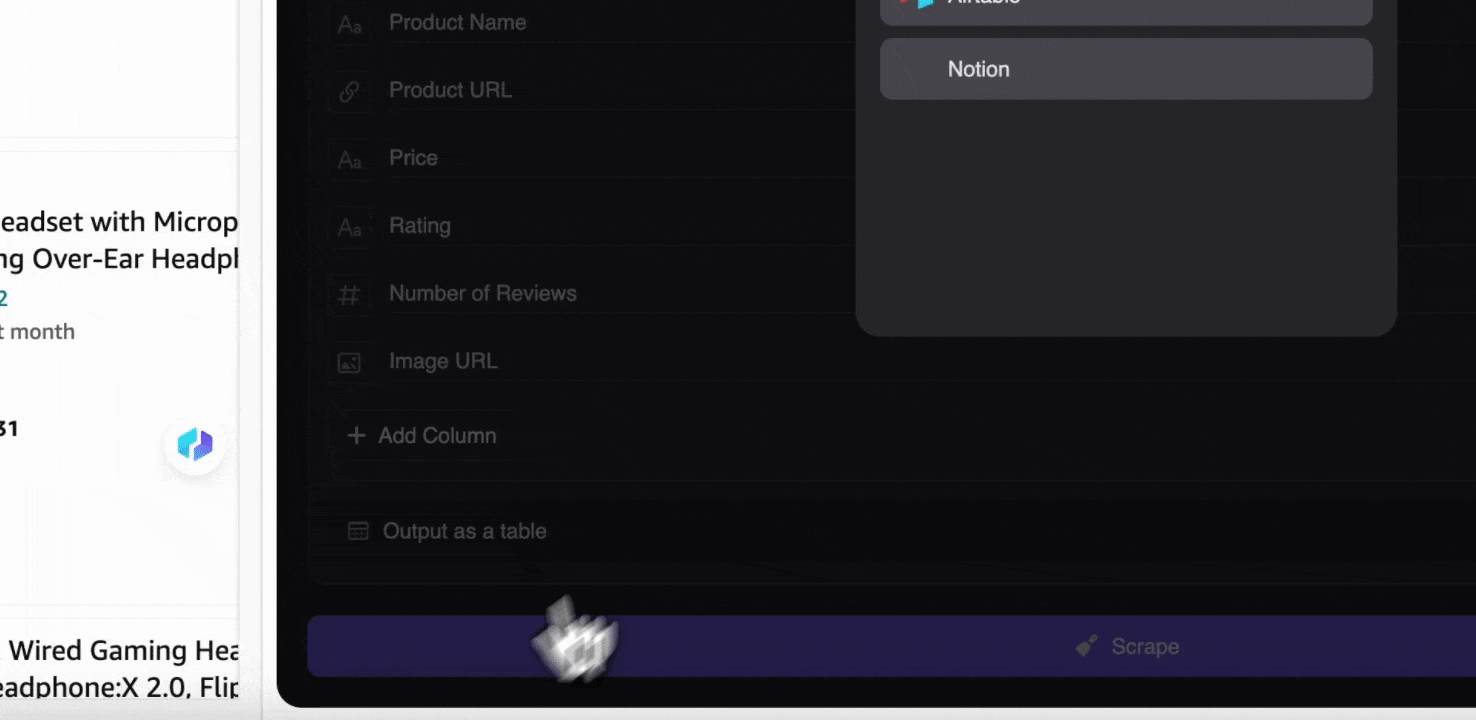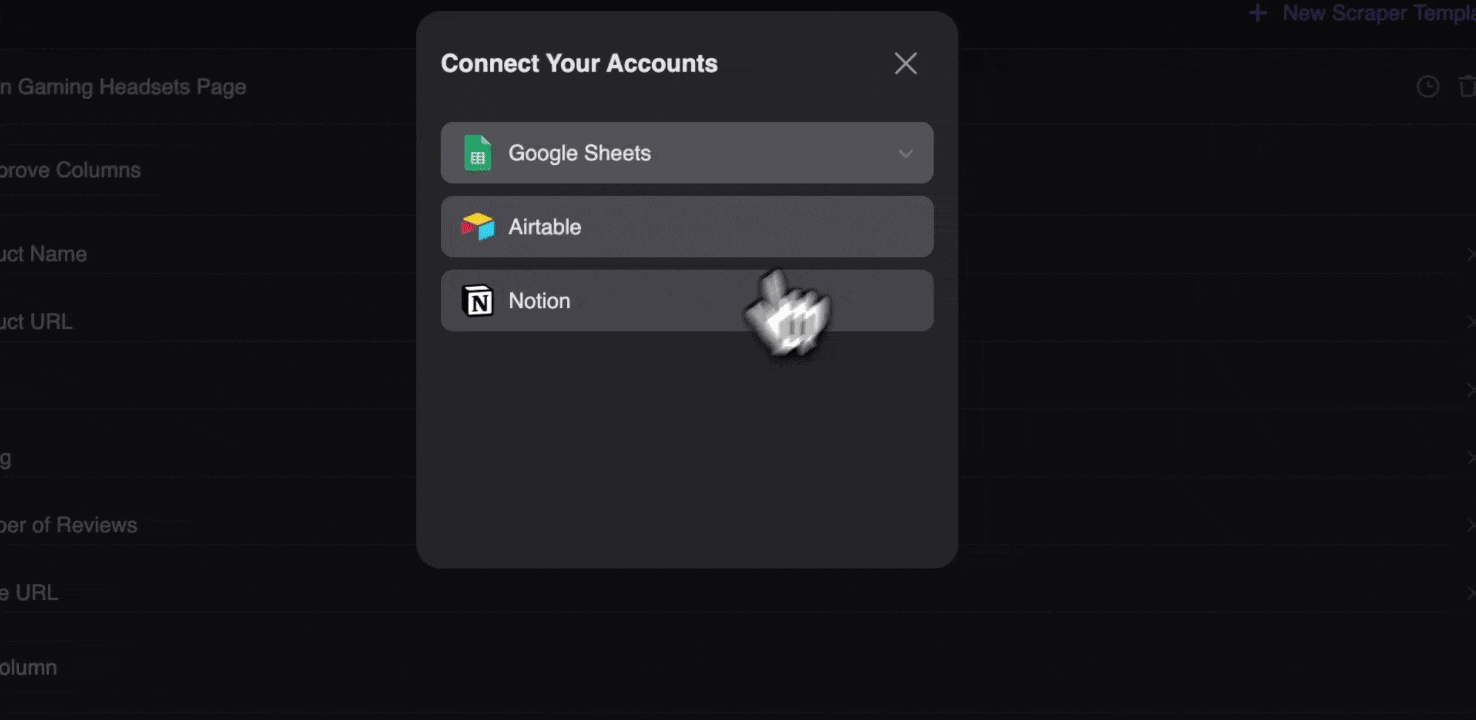
Étape 3 : téléchargez les données extraites ou exportez-les sous forme de tableau
Avec l’extension d’extracteur Web Thunderbit, vous pouvez . Choisissez une sortie sous forme de tableau, puis téléchargez le fichier CSV en local, ou sélectionnez , Notion ou Airtable. Connectez-vous à votre compte et exportez directement vers ces plateformes de collaboration et de gestion de fichiers en ligne.
Extraction avec un extracteur Web traditionnel
En plus des outils d’IA les plus récents, vous pouvez aussi utiliser des extracteurs Web traditionnels, avec du code léger et des API, pour extraire des données produits Amazon.
: récupérer les données produits Amazon au format JSON via API
ScraperAPI propose une API efficace pour la collecte de données Amazon, qui vous aide à extraire les détails produit, les avis, les résultats de recherche et les informations de prix depuis Amazon, puis à les restituer dans un format JSON structuré. Voici comment utiliser l’API pour l’extraction.
Étape 1 : configurez l’environnement Python
Commencez par vérifier que Python 3.8 ou une version ultérieure est installé. Ensuite, installez des bibliothèques d’analyse courantes comme Pandas et des bibliothèques d’extraction Web comme requests et BeautifulSoup. Ces bibliothèques vous aident à extraire facilement les données des pages web.
Étape 2 : créez un compte ScraperAPI
Rendez-vous sur le pour créer un compte gratuit et obtenir votre clé API. Vous pouvez utiliser cette clé pour accéder à ScraperAPI dans votre code.
Étape 3 : préparez le code
Créez localement un dossier dédié et écrivez un script Python pour mettre en place l’extraction de données. Voici un flux de travail de base :
- Obtenir l’URL de recherche Amazon : recherchez le produit souhaité sur Amazon et copiez l’URL de la page de résultats.
- Construire les requêtes : ScraperAPI boucle automatiquement sur les cinq premières pages de résultats de recherche. L’URL de chaque page est construite en ajoutant &page= et le numéro de page correspondant à l’URL de base.
- Envoyer les requêtes et analyser les données : utilisez la méthode get() pour envoyer des requêtes à ScraperAPI. Si la requête aboutit (code de statut 200), analysez le contenu de la page pour extraire l’ASIN (Amazon Standard Identification Number) souhaité.
- Obtenir les données produit détaillées : en appelant le point de terminaison des données structurées, vous pouvez obtenir des informations détaillées pour chaque ASIN afin d’approfondir l’analyse.
Étape 4 : consultez d’autres tutoriels
Pour des guides d’utilisation plus détaillés, consultez le pour en savoir plus.
: éviter le blocage et extraire à grande échelle
Lors de l’extraction de données Amazon, les techniques anti-extraction comme le blocage d’IP, les CAPTCHA et le chargement dynamique du contenu posent souvent des défis aux développeurs d’extracteurs. ScrapFly fournit une API puissante pour contourner ces mécanismes anti-extraction et garantir une collecte fluide des données.
Les principales fonctionnalités de ScrapFly incluent :
- : changement automatique des adresses IP pour éviter le blocage.
- : gestion du chargement dynamique du contenu et extraction des pages rendues en JavaScript.
- : contrôle des navigateurs pour faire défiler, saisir du texte et cliquer sur les éléments.
- : extraction en HTML, JSON, texte ou Markdown.
Avec seulement quelques lignes de code, vous pouvez utiliser ScrapFly pour extraire des données Amazon. Voici un exemple simple :
1import scrapfly_sdk
2# Create a client
3client = scrapfly_sdk.ScraperClient(api_key="your_api_key")
4# Send a request
5response = client.scrape(url="<https://www.amazon.com/s?k=product_name>")
6# Get the returned data
7print(response.json())En utilisant ScrapFly, votre extracteur peut gérer les différents mécanismes anti-extraction d’Amazon, ce qui augmente le taux de réussite de l’extraction de données. Qu’il s’agisse d’une simple extraction d’informations produit ou d’une analyse d’avis plus complexe, ScrapFly est un outil très pratique. Pour des guides d’utilisation plus détaillés, consultez le .
Extraction avec Python : méthodes de codage traditionnelles
Pour les personnes à l’aise avec le code, vous pouvez aussi essayer d’écrire du Python pour extraire des données produits Amazon. Voici un exemple simple pour vous guider.
Étape 1 : préparez les prérequis
Commencez par créer un dossier dédié pour votre projet.
1mkdir amazonscraperPuis installez les bibliothèques nécessaires dans ce dossier.
1pip install beautifulsoup4
2pip install requestsCréez maintenant un fichier Python avec le nom de votre choix. Ce sera le fichier principal dans lequel nous conserverons notre code. Je l’appelle amazon.py.
Étape 2 : envoyez une requête GET à la page cible
Faisons une requête GET vers notre page cible à l’aide de la bibliothèque requests.
1import requests
2from bs4 import BeautifulSoup
3target_url = "<https://www.amazon.com/s?k=gaming+headsets&_encoding=UTF8>"
4headers = {
5 "accept-language": "en-US,en;q=0.9",
6 "accept-encoding": "gzip, deflate, br",
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36",
8 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7"
9}
10response = requests.get(target_url, headers=headers)Étape 3 : extrayez les données produits Amazon
Nous devons maintenant décider de ce que nous allons extraire de la .
1# Check if the request was successful
2if response.status_code == 200:
3 # Parse the page content
4 soup = BeautifulSoup(response.content, 'html.parser')
5 # Find all product listings
6 products = soup.find_all('div', {'data-component-type': 's-search-result'})
7 # Iterate over each product and extract details
8 for product in products:
9 # Extract product title
10 title = product.h2.text.strip()
11 # Extract product price
12 price = product.find('span', 'a-price')
13 if price:
14 price = price.find('span', 'a-offscreen').text.strip()
15 else:
16 price = "Prix non disponible"
17 # Extract product rating
18 rating = product.find('span', 'a-icon-alt')
19 if rating:
20 rating = rating.text.strip()
21 else:
22 rating = "Note non disponible"
23 # Print product details
24 print(f"Title: \{title\}")
25 print(f"Price: \{price\}")
26 print(f"Rating: \{rating\}")
27 print("-" * 40)
28else:
29 print(f"Echec de la récupération de la page. Code de statut : \{response.status_code\}")FAQ
1. Est-il légal d’extraire des données de ?
Oui, l’extraction des données publiques d’Amazon est légale ! Comme beaucoup d’autres sites web, Amazon met ses fiches produits et autres informations publiques à la disposition de tous les visiteurs. Vous pouvez extraire et collecter librement ces données accessibles publiquement sans enfreindre les conditions d’utilisation d’Amazon.
2. Puis-je essayer Thunderbit gratuitement ?
Oui, Thunderbit propose des fonctionnalités gratuites d’extraction de pages et de données. Certaines fonctionnalités avancées peuvent être payantes, mais les capacités de base d’extraction de données sont .
3. Quelles données puis-je extraire d’Amazon ?
Vous pouvez extraire une grande variété de données depuis Amazon, notamment les titres de produits, les prix, les descriptions, les avis, les notes et les informations sur les vendeurs. Ces données peuvent être précieuses pour l’étude de marché, la surveillance des prix et l’analyse concurrentielle.
4. À quelle fréquence dois-je extraire les données Amazon ?
La fréquence dépend du type de données que vous recherchez. Si vous surveillez les prix ou l’activité des concurrents, vous voudrez peut-être extraire les données quotidiennement ou chaque semaine. Pour des informations plus stables, comme les détails produit, une extraction mensuelle peut suffire.
En savoir plus