

Le web croule sous les données, et en 2026, la course pour convertir ce désordre en valeur métier atteint des sommets. J’ai vu des équipes commerciales, e-commerce et opérations métamorphoser leurs workflows en automatisant ce qui réclamait jadis des heures de copier-coller éreintant. Aujourd’hui, faire l’impasse sur un logiciel d’extraction de données web, ce n’est pas seulement accuser du retard — c’est, le plus souvent, rester englué dans l’enfer des tableurs pendant que vos concurrents en sont déjà à leur deuxième café.
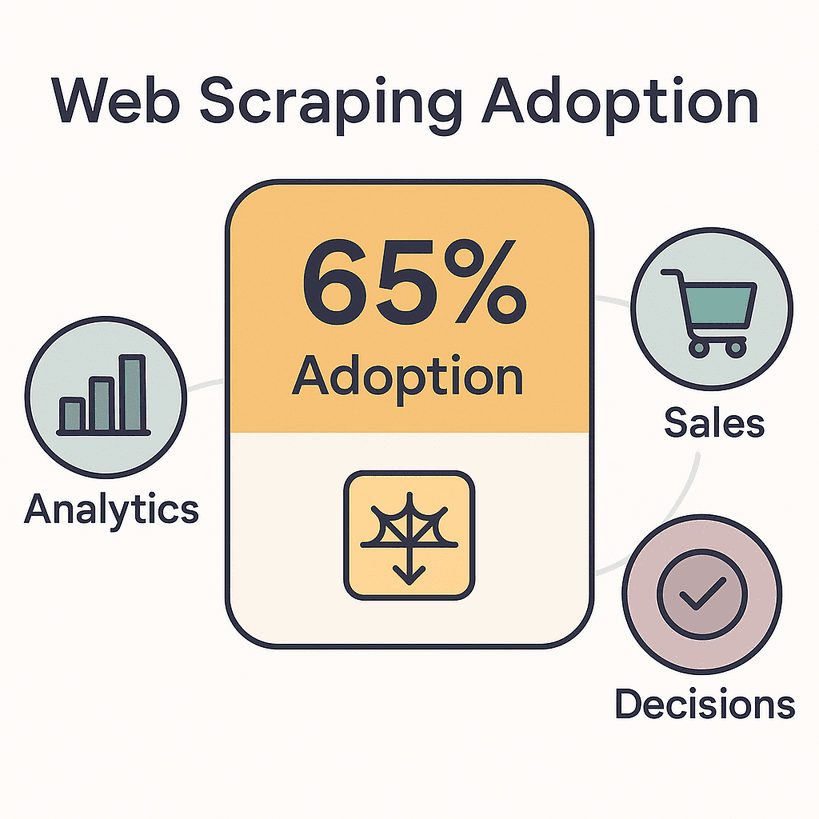
Le constat est sans appel : 65 % des entreprises recourent désormais à des outils d’extraction web pour nourrir leurs analyses, leurs ventes et leurs décisions. Le marché mondial de l’extraction de données web pèse déjà plus d’un milliard de dollars, et sa taille devrait doubler d’ici 2030. Les commerciaux consacrent jusqu’à 70 % de leur temps à des tâches qui n’ont rien à voir avec la vente, comme la saisie de données et la recherche. Autant de temps qui pourrait servir à conclure des affaires — ou, au minimum, à savourer une vraie pause déjeuner.

Alors, quel est le meilleur logiciel d’extraction de données web en 2026 ? J’ai disséqué les cinq outils qui font la différence pour des équipes de toutes tailles et de tous niveaux techniques. Que vous soyez un non-développeur qui veut simplement cliquer et lancer, ou un développeur en quête d’une souplesse maximale, vous trouverez forcément chaussure à votre pied.
Qu’est-ce qui fait un bon logiciel d’extraction de données web ?
L’extraction de données : définition et mode d’emploi en 2025 Get Started Free
Disons-le clairement : tous les extracteurs Web ne se valent pas. Le meilleur logiciel d’extraction de données web en 2026 se reconnaît à sa capacité à rendre l’extraction rapide, fiable et accessible à tous — pas seulement à celles et ceux qui pensent en Python.
Voici les critères clés que j’examine (et ce qui pèse le plus pour les utilisateurs métier) :
- Prise en main : un profil non technique peut-il configurer une extraction en quelques minutes ? Pour la plupart des équipes, une interface sans code et pilotée par l’IA est indispensable.
- Diversité des sources : l’outil gère-t-il pages web, PDF, images et contenus dynamiques (défilement infini, AJAX) ? Plus il couvre de sources, mieux c’est.
- Automatisation et planification : peut-on programmer des extractions récurrentes, gérer la pagination et automatiser la navigation entre sous-pages ? L’automatisation marque la frontière entre « on règle une fois pour toutes » et « on règle puis on surveille ».
- Intégration et export : exporte-t-il directement vers Excel, Google Sheets, Notion, Airtable ou via API ? Moins il y a de manipulations à la main, plus votre équipe y gagne.
- Bagage technique requis : l’outil est-il vraiment sans code, ou faut-il ressortir vos notions de regex ? Les meilleurs outils s’adressent aussi bien aux non-développeurs qu’aux utilisateurs aguerris.
- Montée en charge : peut-il extraire des centaines, voire des milliers de pages sans broncher ?
- Support et communauté : la documentation est-elle solide, le support réactif, la base d’utilisateurs active ?
Ces critères ne relèvent pas du simple bonus : ce sont eux qui séparent les outils qui vous font gagner des heures de ceux qui vous en coûtent des jours. En 2026, alors que près de la moitié du trafic internet provient de bots, disposer du bon extracteur constitue un véritable avantage concurrentiel.
Place maintenant au top 5.
Les 5 meilleurs logiciels d’extraction de données web en 2026
- Thunderbit pour une extraction sans code, propulsée par l’IA et multi-sources
- Import.io pour des pipelines de données intégrés au niveau entreprise
- Scrapy pour une souplesse open source pilotée par les développeurs
- Octoparse pour une extraction visuelle sans code avec planification
- ParseHub pour une extraction de données conviviale en pointer-cliquer
1. Thunderbit : le logiciel d’extraction de données web IA le plus simple
Extrayez les données de n’importe quel site web grâce à l’IA Get Started Free
Thunderbit est ma recommandation phare pour quiconque veut extraire des données web sans écrire une seule ligne de code. Oui, je ne suis pas tout à fait impartial — j’ai participé à sa conception. Mais laissez-moi vous exposer les faits : Thunderbit a été pensé pour les utilisateurs métier qui veulent des résultats, pas des migraines.
Qu’est-ce qui distingue Thunderbit ?
- Champs suggérés par l’IA : un clic sur « Champs suggérés par l’IA » suffit ; l’IA de Thunderbit lit la page, recommande quoi extraire et configure l’extracteur à votre place. Ni sélecteurs, ni modèles, ni complications.
- Extraction multi-sources : extrayez non seulement des pages web, mais aussi des PDF et des images. Thunderbit récupère texte, liens, e-mails, numéros de téléphone et images — le tout en deux clics.
- Automatisation des sous-pages et de la pagination : besoin des détails de chaque fiche produit ou profil ? L’extraction de sous-pages de Thunderbit suit les liens, collecte les informations complémentaires et les fond dans votre tableau. Il avale aussi le défilement infini et la pagination avec brio.
- Extraction par lots et programmée : collez une liste d’URL, planifiez des tâches récurrentes et laissez Thunderbit abattre le gros du travail — qu’il s’agisse d’un suivi quotidien des prix ou d’une mise à jour hebdomadaire des leads.
- Export instantané : exportez directement vers Excel, Google Sheets, Airtable, Notion, CSV ou JSON. Finis les marathons de copier-coller.
- Prompts IA personnalisés : envie de catégoriser, traduire ou étiqueter les données en cours d’extraction ? Ajoutez une instruction sur mesure et l’IA de Thunderbit s’en charge.
- Mode cloud ou navigateur : lancez les extractions dans le cloud pour la vitesse (50 pages à la fois) ou en local pour les sites qui exigent une connexion.
Thunderbit est adopté par plus de 30 000 utilisateurs dans le monde, des équipes commerciales aux agents immobiliers en passant par les boutiques e-commerce indépendantes. L’offre gratuite vous laisse extraire jusqu’à 6 pages (ou 10 avec un bonus d’essai), et vous ne payez que ce que vous consommez — un crédit par ligne de sortie.
Pourquoi je l’apprécie autant : Thunderbit est le seul outil où j’ai vu un profil non technique passer de « il me faut ces données » à « voici mon tableur » en moins de cinq minutes. L’interface est réellement plaisante (on s’y est appliqué sans relâche), et l’IA s’adapte aux changements de site, ce qui vous épargne la réparation perpétuelle d’extracteurs cassés.
Idéal pour : les équipes commerciales, e-commerce, opérations, et quiconque veut une extraction sans code, pilotée par l’IA, sans maintenance.
Essayez l’extension Chrome Thunderbit
Parcourez le Thunderbit Blog pour d’autres guides.
2. Import.io : extraction et intégration de données web au niveau entreprise
Import.io tient le haut du pavé pour les entreprises qui ont besoin de données web à grande échelle — et qui veulent les brancher directement sur leurs systèmes métier.
Ce qui distingue Import.io :
- Pipelines prêts pour l’entreprise : Import.io n’est pas un simple extracteur ; c’est une véritable plateforme d’intégration de données web. Pensez « data-as-a-service », avec des flux continus et automatisés.
- IA auto-réparatrice : si un site change, l’IA d’Import.io tente de remapper automatiquement les champs, pour épargner à vos pipelines une panne du jour au lendemain.
- Automatisation robuste : planifiez des extractions à l’heure, à la journée ou selon des intervalles sur mesure. Recevez une alerte au moindre incident ou si les données semblent suspectes.
- Workflows interactifs : gérez les sites avec connexion, formulaires ou navigation en plusieurs étapes. Import.io sait enregistrer et rejouer des séquences complexes.
- Conformité et gouvernance : détection automatisée des données personnelles, masquage et journaux d’audit — essentiel pour les secteurs réglementés.
- API et intégration : déversez les données directement dans Google Sheets, Excel, Tableau, Power BI, des bases de données ou vos propres applications via API.
Import.io équipe des marques comme Unilever, Volvo et RedHat. C’est la référence pour des usages tels que le suivi des prix sur des milliers de sites e-commerce, l’intelligence marché ou l’alimentation de modèles IA/ML en données web fraîches.
Tarifs : Import.io joue dans la catégorie premium, à partir d’environ 299 $/mois (environ 275 €/mois) pour les offres en self-service. Un essai gratuit existe, mais pas d’offre gratuite au long cours. Si les données web sont vitales pour votre activité, le retour sur investissement est au rendez-vous.
Idéal pour : les entreprises et les organisations centrées sur la donnée en quête de fiabilité, d’échelle, de conformité et d’une intégration poussée.
3. Scrapy : framework open source d’extraction web pour développeurs
Scrapy fait référence dans l’open source pour les développeurs qui réclament souplesse et contrôle absolus. Si vous codez en Python — vous ou votre équipe —, Scrapy est l’outil polyvalent de l’extraction web.
Pourquoi les développeurs plébiscitent Scrapy :
- Personnalisation totale : rédigez des spiders (scripts) pour crawler, parser et traiter les données exactement à votre convenance. Gérez des parcours multipages, une logique sur mesure et un nettoyage de données complexe.
- Asynchrone et rapide : l’architecture de Scrapy vise la vitesse et la montée en charge — extrayez des centaines de pages par minute, ou des millions avec des crawlers distribués.
- Extensible : un vaste écosystème de plugins et de middlewares pour les proxies, les navigateurs headless (Splash/Playwright) et les intégrations.
- Gratuit et open source : aucun frais de licence. Exécutez-le sur votre propre matériel ou dans le cloud, et dimensionnez-le selon vos besoins.
- Support communautaire : plus de 55 000 étoiles sur GitHub et une immense base d’utilisateurs. En cas de blocage, quelqu’un a sans doute déjà résolu le problème.
À savoir : Scrapy exige des compétences en Python et une aisance avec la ligne de commande. Pas d’interface graphique en glisser-déposer ici — on est dans le code avant tout. Mais pour les projets sur mesure, les données d’entraînement pour l’IA ou les gros crawls, difficile de trouver mieux.
Idéal pour : les organisations dotées de développeurs en interne, de pipelines de données sur mesure ou de besoins d’extraction complexes à grande échelle.
4. Octoparse : l’extraction visuelle de données web en toute simplicité
Octoparse a la cote auprès des non-développeurs en quête d’une extraction puissante dotée d’une interface visuelle, en pointer-cliquer.
Pourquoi Octoparse séduit :
- Créateur de workflow visuel : cliquez sur des éléments dans un navigateur intégré, et Octoparse repère automatiquement les motifs. Pas de code, juste cliquer et extraire.
- Gestion des contenus dynamiques : extrait les sites en AJAX, à défilement infini et protégés par connexion. Il simule les clics, les défilements et l’envoi de formulaires.
- Extraction cloud et planification : lancez les tâches dans le cloud (plus rapide, parallélisé) et programmez des tâches récurrentes pour des données toujours actuelles.
- Modèles prédéfinis : des centaines de modèles pour les sites populaires (Amazon, Twitter, Zillow, etc.) vous mettent le pied à l’étrier sur-le-champ.
- Export et API : téléchargez les résultats en CSV, Excel, JSON, ou récupérez les données via API. Intégration avec Google Sheets ou des bases de données.
On décrit souvent Octoparse comme « d’une facilité déconcertante, même pour les débutants ». L’offre gratuite est restreinte, mais les formules payantes (à partir d’environ 83 $/mois, soit environ 76 €/mois) débloquent les exécutions cloud, la planification et un surcroît de vitesse.
Idéal pour : les profils non techniques, les marketeurs, les chercheurs et les petites équipes en quête d’une collecte de données régulière et automatisée, sans coder.
5. ParseHub : une extraction de données simple et accessible au quotidien
ParseHub est un autre chouchou du sans-code, surtout pour les petites entreprises et les freelances désireux d’automatiser leurs tâches de données quotidiennes.
Ce qui fait la force de ParseHub :
- Simplicité du cliquer-sélectionner : désignez les données en cliquant sur les éléments dans une vue navigateur. Bâtissez vos workflows à l’écran — aucun codage requis.
- Gestion des sites JS et dynamiques : extrait les pages gorgées de JavaScript, le contenu à défilement infini et les navigations en plusieurs étapes.
- Exécutions cloud et locales : lancez les extractions sur votre ordinateur ou dans le cloud. Programmez des tâches récurrentes et accédez aux résultats via API (sur les formules supérieures).
- Options d’export : téléchargez les données en CSV, Excel ou JSON. Accès API pour l’automatisation.
- Multiplateforme : disponible sur Windows, Mac et Linux.
L’offre gratuite de ParseHub est limitée (200 pages par exécution), mais les formules payantes (à partir d’environ 189 $/mois, soit environ 174 €/mois) débloquent davantage de puissance, de vitesse et l’accès à l’API.
Idéal pour : les petites entreprises, les freelances et les équipes aux besoins d’extraction simples qui veulent un outil fiable et visuel.
Tableau comparatif : les meilleurs logiciels d’extraction de données web en un coup d’œil
| Outil | Facilité d’utilisation | Sources de données | Automatisation et planification | Intégration et export | Compétences techniques | Tarifs |
|---|---|---|---|---|---|---|
| Thunderbit | Sans code, piloté par l’IA | Web, PDF, images | Sous-pages, pagination, planifié, par lots | Excel, Sheets, Notion, Airtable, CSV, JSON | Aucune | Freemium (paiement par ligne) |
| Import.io | Interface clic-clac | Web (statique/dynamique, connexion) | Auto-réparation, planifié, alertes | API, outils BI, Sheets, Excel, BD | Faible à moyen | 299 $+/mois |
| Scrapy | Code requis | Web, API, (JS via modules additionnels) | Automatisation complète via le code | Tout (via le code) | Développeurs Python | Gratuit (open source) |
| Octoparse | Visuel, sans code | Web (dynamique, connexion) | Planification cloud, modèles | CSV, Excel, JSON, API | Aucune | 83 $+/mois |
| ParseHub | Visuel, sans code | Web (JS, dynamique) | Cloud/local, planifié | CSV, Excel, JSON, API | Aucune | 189 $+/mois |
Comment choisir le meilleur logiciel d’extraction de données web pour votre entreprise
Vous balancez encore ? Voici mon récapitulatif :
- Profils non techniques, résultats rapides : misez sur Thunderbit ou Octoparse. Thunderbit est imbattable pour une extraction instantanée, pilotée par l’IA, et pour la prise en charge de sources multiples (web, PDF, images). Octoparse excelle dans les extractions visuelles et planifiées.
- Intégration entreprise, conformité et montée en charge : Import.io est votre meilleur pari. Il a été conçu pour des pipelines de données continus, fiables et profondément intégrés.
- Développeurs, projets sur mesure ou crawls massifs : Scrapy s’impose. Il faut maîtriser Python, mais en contrepartie vous obtenez une souplesse sans limite.
- Petites entreprises, freelances ou tâches du quotidien : ParseHub est une solution solide et conviviale pour une extraction en pointer-cliquer et une automatisation modérée.
Quelques repères pour bien choisir :
- Accordez l’outil aux compétences techniques de votre équipe et à vos besoins en données.
- Pesez la complexité des sites à extraire (contenu dynamique ? connexion ?).
- Anticipez l’usage des données — export direct vers Sheets ou intégration API poussée ?
- Démarrez par un essai gratuit ou une offre freemium pour éprouver des cas réels.
- Ne négligez jamais la valeur d’un bon support et d’une documentation soignée.
Commencer à extraire avec Thunderbit
Conclusion : libérer de la valeur métier avec le meilleur logiciel d’extraction de données web
Les données web sont le carburant des décisions métier les plus avisées en 2026. Le bon logiciel d’extraction peut vous faire gagner des heures, réduire les erreurs et offrir à votre équipe un vrai temps d’avance — que vous constituiez des listes de prospects, surveilliez les concurrents ou alimentiez votre moteur analytique.
En résumé :
- Thunderbit est l’extracteur sans code le plus simple et le plus piloté par l’IA pour les utilisateurs métier.
- Import.io est la solution de niveau entreprise pour des pipelines de données continus et intégrés.
- Scrapy est la boîte à outils open source des développeurs en quête d’un contrôle total.
- Octoparse et ParseHub rendent l’extraction visuelle sans code accessible à tous.
La plupart de ces outils proposent un essai gratuit ou une offre freemium — alors mettez-les à l’épreuve. Automatisez les corvées, débloquez de nouveaux enseignements et laissez votre équipe se concentrer sur ce qui compte vraiment.
Bonne extraction — et que vos données soient toujours fraîches, structurées et prêtes à passer à l’action.
FAQ
1. À quoi sert un logiciel d’extraction de données web ?
Un logiciel d’extraction de données web automatise la récupération d’informations depuis des sites web, des PDF et des images. On y recourt pour la génération de leads, le suivi des prix, la veille marché, l’agrégation de contenu, et bien plus encore.
2. L’extraction de données web est-elle légale ?
L’extraction web est légale dès lors qu’elle porte sur des données publiquement accessibles et qu’elle respecte les conditions d’utilisation du site ainsi que les lois sur la vie privée. Vérifiez toujours les règles du site et exploitez les données de manière responsable.
3. Faut-il savoir coder pour utiliser un logiciel d’extraction de données web ?
Pas forcément ! Des outils comme Thunderbit, Octoparse et ParseHub ont été conçus pour les non-développeurs. Pour des projets plus complexes ou sur mesure, des outils pour développeurs comme Scrapy peuvent s’avérer nécessaires.
4. Comment exporter des données extraites vers Excel ou Google Sheets ?
La plupart des extracteurs modernes (Thunderbit, Octoparse, ParseHub) proposent un export en un clic vers Excel, Google Sheets, CSV, voire une intégration directe avec Notion et Airtable.
5. Un logiciel d’extraction de données web peut-il gérer les sites dynamiques ou protégés par connexion ?
Oui — les meilleurs outils comme Import.io, Octoparse et ParseHub savent gérer les contenus dynamiques (AJAX, défilement infini) et les sites protégés par connexion. Thunderbit prend lui aussi en charge l’extraction depuis des pages dynamiques et des sous-pages.
Envie de voir à quoi ressemble l’extraction web moderne ? Téléchargez l’extension Chrome de Thunderbit ou explorez le Thunderbit Blog pour d’autres conseils, tutoriels et analyses approfondies sur l’extraction de données propulsée par l’IA.
Essayez l’Extracteur Web IA Get Started Free




