
Kerron sulle pienen salaisuuden: internet on käytännössä maailman suurin kirjasto, mutta suurin osa kirjoista on teipattu kiinni. Juttelen päivittäin yrittäjien, markkinoijien ja myyntitiimien kanssa, jotka tietävät, että verkkosivuilla piilee aarretta—tuotespeksit, kilpailijoiden hinnat, asiakasarvostelut, yhteystiedot—mutta se, miten teksti saadaan ulos? Siinä kohtaa homma usein jumittaa. Olen ollut SaaS- ja automaatiomaailman etulinjassa vuosia, ja olen nähnyt kaiken mahdollisen “kopioi–liitä-maratonin” ja “tee-se-itse Python -seikkailun”. Hyvä uutinen: kun haluat poimi tekstiä verkkosivulta, se on nykyään helpompaa (ja huomattavasti vähemmän tuskallista) kuin koskaan—kiitos uusien ai web scraper -työkalujen ja fiksumpien selainlaajennusten.
Tässä oppaassa käyn läpi kaikki käytännölliset tavat, jotka tiedän—perinteisestä kopioi–liitä-menetelmästä aina edistyneisiin tekoälyratkaisuihin, kuten Thunderbit (jep, se on meidän tiimin tuote, mutta kerron rehellisesti myös plussat ja miinukset). Olitpa taulukkolaskennan velho, koodia suoltava kehittäjä tai vain kyllästynyt siristelemään verkkosivuja, löydät vaiheittaisen tavan, joka sopii tarpeisiisi. Avataan ne digitaaliset kirjat ja haetaan teksti talteen.
Mitä tarkoittaa tekstin poimiminen verkkosivulta?
Kun puhumme “tekstin poimimisesta verkkosivulta”, tarkoitamme käytännössä sitä, että sivulta kerätään näkyvä (ja joskus myös piilossa oleva) tieto ja viedään se muotoon, jota voi hyödyntää—esimerkiksi taulukkoon, tietokantaan tai vaikka siistiksi Word-dokumentiksi. Kaikki verkkosivun teksti ei kuitenkaan ole samanlaista:
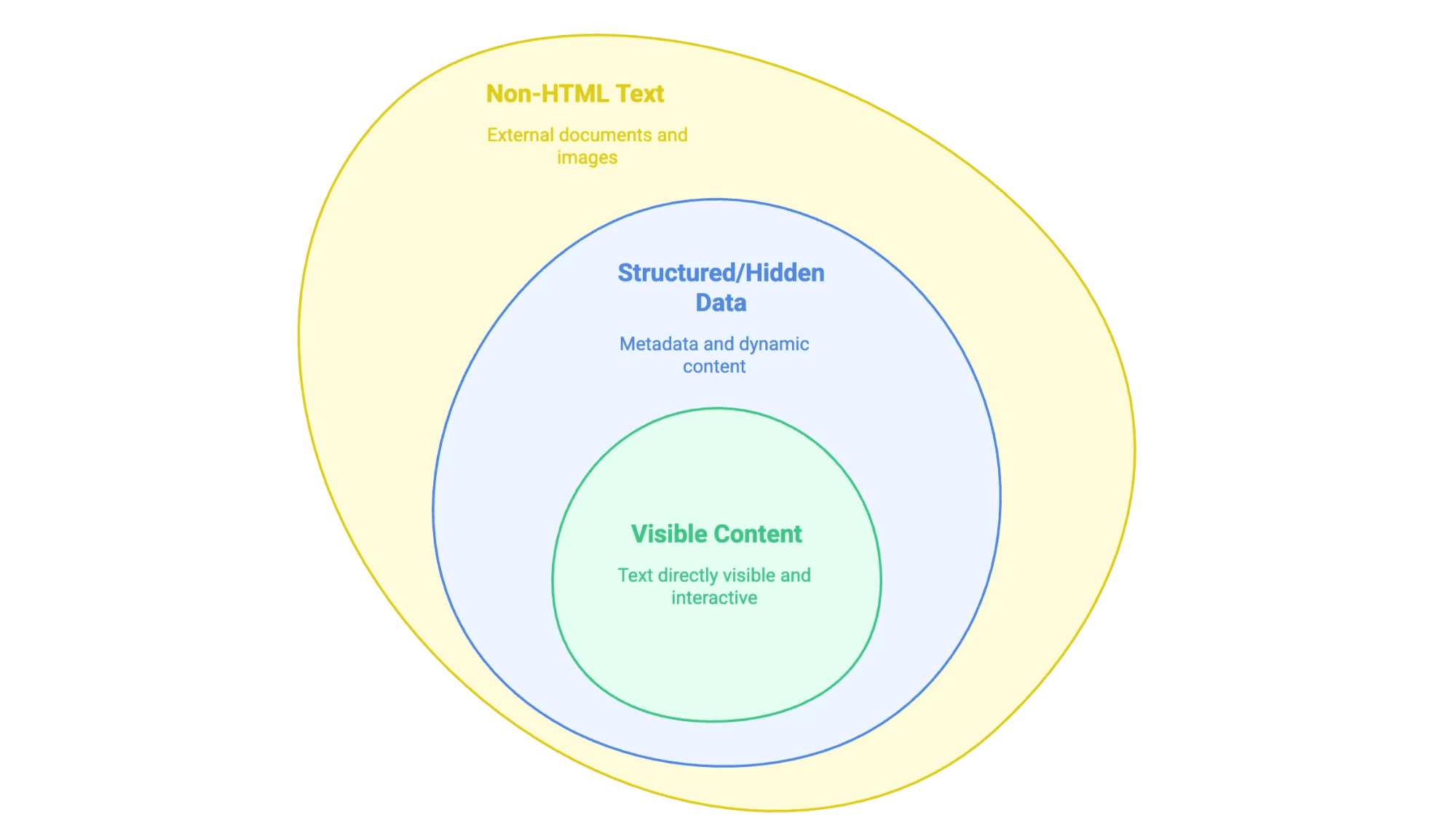
- Näkyvä sisältö: Teksti, jonka voit maalata hiirellä—leipäteksti, otsikot, listat, taulukot, tuotekuvaukset, blogipostaukset jne.
- Rakenteinen tai piilotettu data: Esimerkiksi
<meta>-tagien metadata, JSON-LD-skriptit tai JavaScriptin lataama sisältö, joka ilmestyy vasta klikkauksen tai scrollauksen jälkeen. - Ei-HTML-teksti: PDF:t, Word-tiedostot ja jopa kuvat, joissa on tekstiä (kuten skannatut sopimukset tai infografiikat), jotka on linkitetty tai upotettu sivustolle.
Oleellista on tietää, mitä tyyppiä olet hakemassa—koska jokainen vaatii hieman eri lähestymistavan.
Miksi tekstiä poimitaan verkkosivuilta? Hyödyt ja käyttötapaukset yrityksille
Rehellisesti: harva poimii tekstiä verkkosivuilta huvikseen (ellei harrasta todella erikoisia harrastuksia). Yritykset tekevät sitä, koska tuotto näkyy suoraan viivan alla. web scraper -ohjelmistomarkkina ylitti miljardin dollarin vuonna 2024, ja kasvu jatkuu. Tässä syyt:
| Tiimi | Esimerkkikäyttö | Hyöty |
|---|---|---|
| Myynti | Poimi hakemistoista liidejä ja yhteystietoja | Nopeampi ja laadukkaampi prospektointi |
| Markkinointi | Kerää kilpailijoiden blogit ja SEO-data | Sisältöaukkojen analyysi, trendien tunnistaminen |
| Operatiivinen toiminta | Seuraa hintoja eri verkkokaupoissa | Dynaaminen hinnoittelu, varastoseuranta |
| Kiinteistöt | Kokoa ilmoituksia ja kohdetietoja yhteen | Markkina-analyysi, liidien hankinta |
| Asiakastuki | Kerää arvosteluja ja foorumien Q&A:ta | Sentimenttianalyysi, ongelmien varhainen havaitseminen |
Muutama käytännön esimerkki:

- Liidien generointi: Eräs ravintolatarvikeyritys rakensi prospektilistoja minuuteissa päivien sijaan.
- Kilpailijaseuranta: John Lewisin kaltaiset jälleenmyyjät kasvattivat myyntiä 4 % kerätyn hintadatan avulla.
- SEO-analyysi: Tiimit poimivat meta-tageja ja avainsanoja strategian tueksi.
Ja tekoälypohjaisilla työkaluilla yritykset säästävät 30–40 % datankeruun ajasta verrattuna perinteisiin menetelmiin—käytännössä sama työ, mutta vähemmän säätöä.
Manuaaliset menetelmät: verkkosivutekstin kopioinnin perusteet
Aloitetaan helpoimmasta. Joskus tarvitset vain pienen pätkän tekstiä—ilman erikoistyökaluja.
Näin poimit tekstiä käsin
- Kopioi ja liitä: Avaa sivu, maalaa teksti ja paina Ctrl+C (tai hiiren oikea > Kopioi). Liitä sitten dokumenttiin tai taulukkoon.
- Tallenna sivu: Selaimessa Tiedosto > Tallenna sivu nimellä. Tallenna “Webpage, HTML only”, jos haluat raaka-HTML:n, tai joskus .txt-muodossa pelkän tekstin.
- Tulosta PDF:ksi: Käytä selaimen tulostusikkunaa ja valitse “Tallenna PDF:nä”. Avaa PDF ja kopioi teksti (tai käytä PDF-lukijan “Tallenna tekstinä” -toimintoa).
- Kehittäjätyökalut: Hiiren oikea > Tarkista (Inspect) tai F12. Näet HTML-lähteen, löydät meta-tagit tai piilotetun JSONin ja kopioit tarvitsemasi.
Rajoitukset
Manuaalinen poiminta toimii satunnaisiin tarpeisiin, mutta isommassa mittakaavassa se on painajainen. Se on hidasta, virhealtista eikä skaalaudu. Olen nähnyt harjoittelijoiden käyttävän päiviä taulukoiden kopiointiin rivi riviltä—ei kiitos, kukaan ei halua sitä hommaa.
Selainlaajennukset ja verkkotyökalut tekstin poimimiseen
Seuraava taso: selainlaajennukset ja online-työkalut ovat monelle yrityskäyttäjälle se paras “sweet spot”—ei koodausta, ei loputonta säätöä, vaan osoita ja klikkaa.
Miksi näitä kannattaa käyttää?

- Nopeampaa kuin käsin kopiointi
- Ei vaadi ohjelmointia
- Selviää taulukoista, listoista ja joskus myös tiedostoista
- Vienti Exceliin, Google Sheetsiin, CSV:ksi jne.
Käydään läpi suosituimmat vaihtoehdot.
Thunderbit: AI Web Scraper nopeaan ja tarkkaan tekstin poimintaan
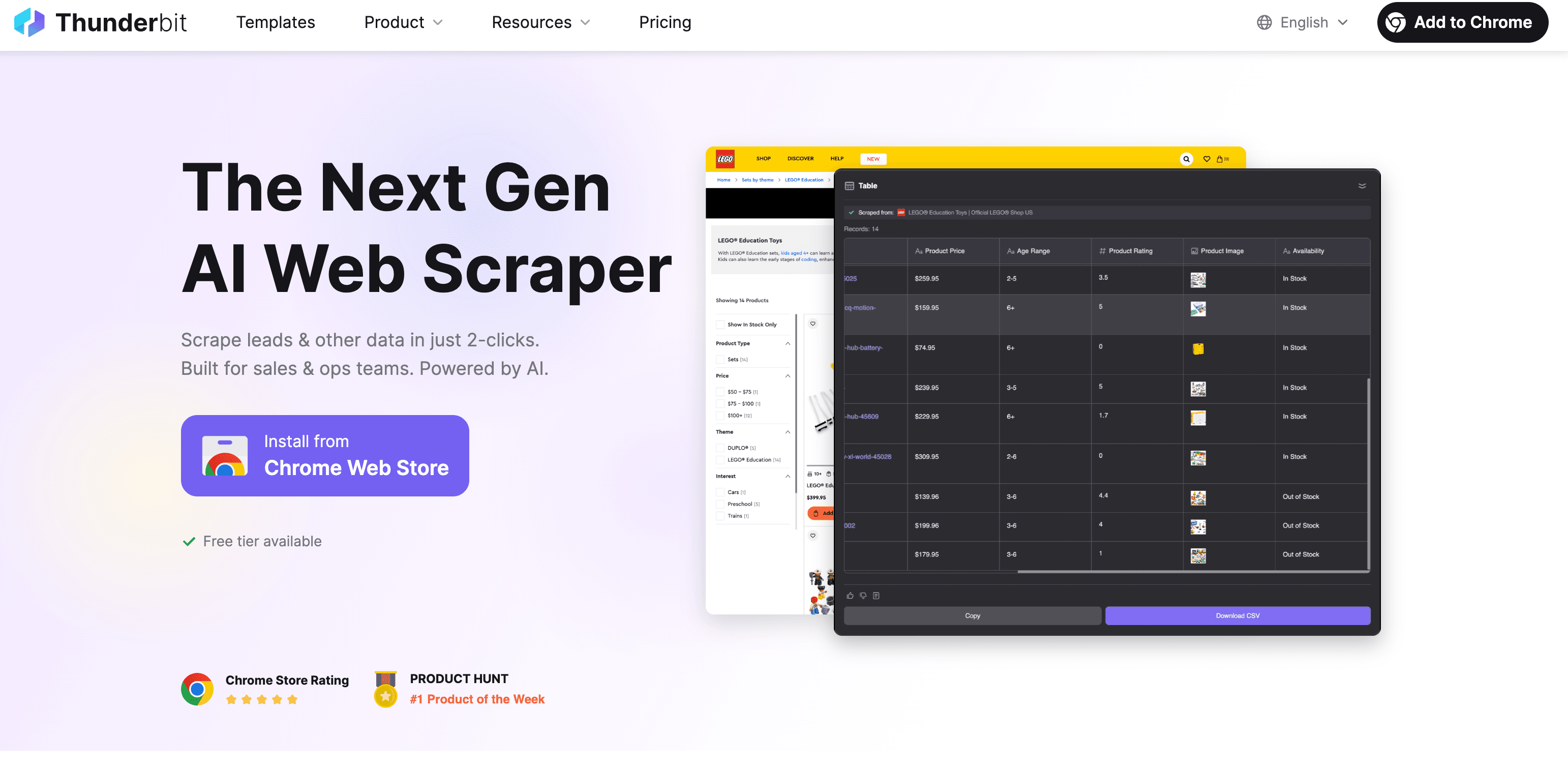
Olen tässä vähän puolueellinen, mutta Thunderbit on rakennettu tekemään verkkotekstin poiminnasta yhtä helppoa kuin ruoan tilaamisesta. Käytännössä se toimii niin, että data extractor -logiikka on piilotettu taustalle, ja sinä keskityt vain siihen, mitä haluat talteen.
Vaihe vaiheelta: poimi teksti Thunderbitilla
- Asenna Chrome-laajennus: Lataa Thunderbit Chrome Web Storesta.
- Avaa verkkosivu: Siirry sivulle, jolta haluat poimia tekstiä.
- Klikkaa “AI Suggest Fields”: Thunderbitin tekoäly skannaa sivun ja ehdottaa poimittavia kenttiä (sarakkeita)—esim. tuotteen nimi, hinta, kuvaus jne.
- Tarkista ja muokkaa: Voit säätää ehdotuksia tai lisätä omia kenttiä.
- Klikkaa “Scrape”: Thunderbit kerää datan, tarvittaessa myös alasivuilta tai sivutetuista listoista.
- Vie data: Lataa Exceliin, Google Sheetsiin, Airtableen, Notioniin tai CSV/JSON-muodossa. Viennistä ei veloiteta erikseen.
Poimi verkkosivun teksti Thunderbitilla
Mikä tekee Thunderbitista erilaisen?
- Tekoäly ehdottaa kentät: Ei tarvitse säätää selektoreiden tai koodin kanssa—AI nappaa olennaisen.
- Alasivut ja sivutus: Haluatko jokaisen tuotteen tiedot kategoriasta? Thunderbit klikkaa läpi automaattisesti.
- Poimii PDF:istä, kuvista ja dokumenteista: PDF-manuaali tai tuotespeksikuva? Thunderbitin sisäänrakennettu OCR poimii tekstin myös niistä.
- Monikielinen tuki: Toimii 34 kielellä (Klingonia odotellaan vielä).
- Ilmainen datan vienti: Data ei jää maksumuurin taakse.
- Käyttökohteet: Tuotekuvaukset, yhteystiedot, blogisisällöt, liidilistat—mikä vain.
Näin poimit Amazon-tuotteet ja arvostelut vuonna 2025 tekoälyn avulla Get Started Free
Haluatko nähdä käytännössä? Katso lisää oppaita Thunderbit Blogista, kuten How to Scrape Amazon Products and Reviews in 2025 using AI.
Muita selainlaajennuksia ja verkkotyökaluja
Mainitaan nopeasti muutama työkalu, joihin saatat törmätä:
- Web Scraper (webscraper.io): Ilmainen ja “point-and-click”, mutta vaatii opettelua. Sopii teknisemmille analyytikoille—joudut rakentamaan “sitemapit” ja selektorit. Hoitaa sivutuksen, mutta ei PDF:iä tai kuvia. Lisätietoja täällä.
- CopyTables: Erittäin yksinkertainen—kopioi HTML-taulukot leikepöydälle tai Exceliin. Täydellinen nopeisiin kertapoimintoihin, mutta toimii vain yksi sivu kerrallaan ja vain taulukoille. Katso miten se toimii.
- ScraperAPI (ScraperAPI Pricing): Kehittäjille. Lähetät URL:n, saat HTML:n takaisin (proxyjen ja blokkien käsittely mukana), mutta tekstin jäsentäminen jää sinulle. Lue lisää.
Milloin mitäkin kannattaa käyttää?
- Thunderbit: Kun haluat nopeutta, tekoälyapua ja tukea useille formaateille (myös PDF/kuvat).
- Web Scraper: Kun tykkäät säätää ja haluat enemmän kontrollia.
- CopyTables: Kun tarvitset vain taulukon—heti.
- ScraperAPI: Kun rakennat oman scrapperin koodilla.
Automaattinen web scraping: ohjelmointiratkaisut verkkosivutekstin poimintaan
Jos olet kehittäjä (tai sinulla on sellainen lähellä), oman scrapperin koodaaminen antaa täyden kontrollin. Perusprosessi näyttää tältä:
- Lähetä HTTP-pyyntö: Hae sivu esimerkiksi Pythonin
requests-kirjastolla. - Jäsennä HTML: Käytä
BeautifulSoup-,lxml- taiScrapy-työkaluja löytääksesi halutun tekstin. - Poimi ja vie: Kerää teksti, siivoa se ja tallenna CSV/JSON-muotoon tai tietokantaan.
Esimerkki: Python + Beautiful Soup
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
for qt in quotes:
print(qt)
Plussat ja miinukset
- Plussat: Maksimaalinen joustavuus, toimii lähes mille tahansa sivulle ja datatyypille, helppo integroida omiin järjestelmiin.
- Miinukset: Vaatii ohjelmointiosaamista, jatkuvaa ylläpitoa ja botinestoihin varautumista.
Milloin tämä on järkevää?
- Tarvitset dataa tuhansilta (tai miljoonilta) sivuilta.
- Sivusto on monimutkainen (kirjautumiset, monivaiheiset lomakkeet).
- Haluat upottaa scrappauksen suoraan sovellukseesi tai työnkulkuun.
Tekstin poiminta ei-HTML-muodoista: PDF:t, Word-dokumentit ja kuvat
Verkkosivut eivät ole pelkkää HTML:ää—niissä on PDF:iä, Word-tiedostoja ja kuvia, joissa on arvokasta tekstiä. Näin pääset käsiksi niihin:
PDF:t
- Tekstipohjaiset PDF:t: Käytä esimerkiksi Adobe Acrobatia tai kirjastoja kuten
PDFMinertaiPyPDF2. - Skannatut PDF:t: Käytä OCR-työkaluja (Optical Character Recognition) kuten Tesseract, Google Cloud Vision API tai AWS Textract.
Word/Excel-dokumentit
- Word:
python-docxlukee .docx-tiedostoja. - Excel:
openpyxltaipandas.xlsx-tiedostoille.
Kuvat
- OCR-työkalut: Tesseract avoimeen lähdekoodiin, pilvipalvelut parempaan tarkkuuteen. Parhaiten toimivat hyvälaatuiset kuvat (150–300 DPI).
Thunderbitin tapa
“Image/Document Parser” -toiminnolla voit ladata tai linkittää PDF:n, kuvan tai dokumentin, ja tekoäly poimii tekstin (ja voi jopa ehdottaa sarakkeita, jos se tunnistaa taulukon). Ei tarvitse hyppiä työkalusta toiseen—käsittele tiedostoja kuin mitä tahansa verkkosivua.
Kaikkien menetelmien vertailu: mikä ratkaisu sopii sinulle?
Tässä nopea vertailu valinnan helpottamiseksi:
| Menetelmä | Helppokäyttöisyys | Skaalautuvuus | Tarvittava tekninen osaaminen | Tuetut datatyypit | Sopii parhaiten |
|---|---|---|---|---|---|
| Manuaalinen (kopioi–liitä) | Erittäin helppo | Matala | Ei mitään | Vain näkyvä teksti | Kertaluonteiset, pienet tarpeet |
| Selainlaajennukset/työkalut | Helppo–kohtalainen | Keskitaso | Matala–keskitaso | HTML, osa taulukoista | Ei-tekniset käyttäjät, pienet–keskisuuret työt |
| AI-työkalut (Thunderbit) | Erittäin helppo | Korkea | Ei mitään | HTML, PDF:t, kuvat, ym. | Yrityskäyttö, sekasisältö |
| Ohjelmointi (koodi) | Vaikea | Erittäin korkea | Korkea | Mikä tahansa (oikeilla kirjastoilla) | Kehittäjät, suuret projektit |
| Ei-HTML-poiminta (OCR) | Kohtalainen | Matala–keskitaso | Keskitaso | PDF:t, kuvat, dokumentit | Kun tiedostot/kuvat ovat keskiössä |
Jos haluat nopeimman, joustavimman ja vähiten stressaavan tavan—etenkin yrityskäyttöön—tekoälytyökalut kuten Thunderbit ovat vaikeita voittaa. Jos taas tarvitset täydellisen kontrollin tai scrappaat valtavassa mittakaavassa, oma koodiratkaisu voi olla järkevä.
Yhteenveto: aloita tekstin poimiminen verkkosivuilta jo tänään
- Verkko on täynnä arvokasta tekstidataa, mutta sen irrottaminen ei aina ole suoraviivaista.
- Manuaaliset keinot toimivat pieniin tarpeisiin, mutta eivät skaalaudu.
- Selainlaajennukset ja AI Web Scraper -työkalut kuten Thunderbit tekevät tekstin poiminnasta nopeaa, tarkkaa ja kaikkien saavutettavaa—ilman koodausta.
- Ei-HTML-sisällölle (PDF:t, kuvat) kannattaa valita työkalu, jossa on sisäänrakennettu OCR ja dokumenttien jäsentäminen.
- Valitse menetelmä tiimisi osaamisen, projektin koon ja tarvitsemasi datatyypin mukaan.
Kokeile Thunderbit AI Web Scraperia ilmaiseksi
Mukavia scrappaushetkiä—ja toivottavasti Ctrl+C -päiviäsi on jatkossa mahdollisimman vähän. Oikeilla työkaluilla verkkodatan poiminnasta tulee sujuva, automatisoitu prosessi, joka vapauttaa aikaa tärkeämpään tekemiseen. Ei enää loputtomia kopioi–liitä-tunteja, vaan fiksut ja tehokkaat ratkaisut käden ulottuvilla. Kohti tuottavampaa arkea ilman manuaalista raatamista.
UKK
K1: Voinko poimia dataa miltä tahansa verkkosivulta?
V1: Ei aina. Osa sivustoista estää scrappauksen tai kieltää sen käyttöehdoissaan. Tarkista aina sivuston käytännöt ensin.
K2: Kuinka tarkkoja tekoälypohjaiset web scrapperit ovat?
V2: Tekoälypohjaiset scrapperit kuten Thunderbit ovat yleensä hyvin tarkkoja, mutta monimutkaiset tai erittäin dynaamiset sivut voivat vaatia pientä hienosäätöä.
K3: Tarvitsenko koodaustaitoja web scraping -työkalujen käyttöön?
V3: Et. Thunderbitin ja monien muiden selainlaajennusten idea on palvella myös ei-teknisiä käyttäjiä ilman koodausta.
K4: Mitä dataa voin poimia PDF:istä tai kuvista?
V4: OCR-työkalut voivat poimia tekstiä, taulukoita ja jopa piilossa olevaa sisältöä skannatuista PDF:istä ja kuvista, mikä tekee datankeruusta monipuolisempaa.
Lue lisää
- The definitive guide to text scraping
- How to Scrape Any Website Using AI
- Learn How to Use AI for Web Scraping
Kokeile AI Web Scraperia Get Started Free




