
Los motores de búsqueda se han convertido en la portada de internet y, para las empresas modernas, también en la mayor fuente de datos del mundo: la más caótica y, a la vez, la más valiosa. Tanto si estás siguiendo a la competencia, buscando leads o simplemente intentando mantenerte al día con los cambios del mercado, la información que vive dentro de Google, Bing y otros motores de búsqueda es oro puro. Pero aquí está el problema: copiar resultados de búsqueda manualmente es tan entretenido como ver secarse la pintura y tan escalable como un puesto de limonada en mitad de una ventisca.
Ahí es donde entra el scraping de motores de búsqueda. He visto de primera mano cómo los equipos que dominan esta habilidad pueden desbloquear información, automatizar la investigación y adelantarse a la competencia. Pero también he visto a gente toparse con dolores de cabeza legales, obstáculos técnicos y muchos momentos de “¿Por qué Google me ha bloqueado ahora?”. Así que, si estás listo para convertir los motores de búsqueda en tu propio flujo de inteligencia empresarial —sin pisar minas legales ni perder el sueño por los CAPTCHAs—, vamos a ver cómo dominar el scraping de motores de búsqueda en 2026.
¿Qué es el scraping de motores de búsqueda? Una explicación sencilla
Vamos a ponerlo fácil: el scraping de motores de búsqueda es el proceso de usar herramientas automatizadas para extraer datos de resultados de búsqueda, como títulos, URLs, fragmentos y posiciones, de motores como Google o Bing. Imagina tener un becario robot que escribe tu consulta en Google, copia cada resultado y lo pega en una hoja de cálculo por ti. En resumen, eso es el scraping de motores de búsqueda.
En lugar de desplazarte y copiar a mano, un raspador “lee” el HTML de la página de resultados del motor de búsqueda (SERP) y extrae la información que te interesa. Por ejemplo, podrías querer los 100 primeros resultados de Google para “mejor software CRM”, incluyendo el título, la URL y el fragmento de cada uno. Los raspadores avanzados incluso pueden capturar preguntas de “Otras preguntas de los usuarios”, fragmentos destacados, imágenes o emplazamientos de anuncios.
¿Cómo funciona? Por debajo, un raspador envía una solicitud al motor de búsqueda haciéndose pasar por un navegador normal. Después analiza el HTML devuelto y extrae datos estructurados. La clave está en que puedes hacer esto con cientos o miles de consultas en el tiempo que a una persona le llevaría copiar y pegar una sola página de resultados ().
Principales casos de uso empresarial:
- Seguimiento SEO: supervisa la posición de tu sitio web en Google para palabras clave objetivo.
- Investigación de la competencia: ve dónde y cómo aparecen tus rivales en las búsquedas.
- Generación de leads: encuentra directorios, listas o perfiles de LinkedIn para acciones comerciales.
- Estrategia de contenidos: descubre preguntas o temas en tendencia para crear nuevo contenido.
Si alguna vez has buscado en Google el nombre de tu empresa y has anotado lo que ves, has hecho la versión manual. El scraping de motores de búsqueda hace lo mismo, pero a escala y con mucha menos cafeína.
Por qué el scraping de motores de búsqueda importa para las empresas modernas
Seamos claros: los motores de búsqueda son el pulso del mercado. Los datos que muestran reflejan lo que quiere la gente, quién va ganando y qué está en tendencia. Por eso casi , lo que lo convierte en la categoría más grande de extracción de datos web. Así es como las empresas están usando el scraping de motores de búsqueda para obtener resultados reales:
| Caso de uso (equipo) | Datos recopilados mediante búsqueda | Beneficio / resultado | |---------------------------|-----------------------------------|----------------------------------------------------------------------------------------------------------| | Supervisión SEO (marketing) | Resultados de Google para palabras clave objetivo | Identificar lagunas SEO, ajustar contenidos y proteger el crecimiento del tráfico orgánico | | Análisis de la competencia (operaciones) | Resultados de búsqueda de competidores | Inteligencia en tiempo real; reaccionar a los movimientos de rivales, por ejemplo, bajando precios para impulsar un 4 % las ventas () | | Generación de leads (ventas) | SERPs que muestran clientes potenciales | Crear listas de prospectos en minutos; por ejemplo, más de 900 leads encontrados mediante operadores de Google () | | Estrategia de contenidos (marketing) | Resultados de búsqueda principales, preguntas relacionadas | Contenidos basados en datos, mayor relevancia y mejor ROI de marketing (mejora del 10–20 % con datos externos ()) | | Supervisión de marca (legal/operaciones) | Resultados de búsqueda de marca, imágenes | Detección temprana de problemas de marca, productos falsificados o prensa negativa |
El ROI es real: las empresas que integran datos web externos y IA en su negocio ven . Y con como parte de sus operaciones, el scraping no es solo un pasatiempo de hackers: es una necesidad empresarial.
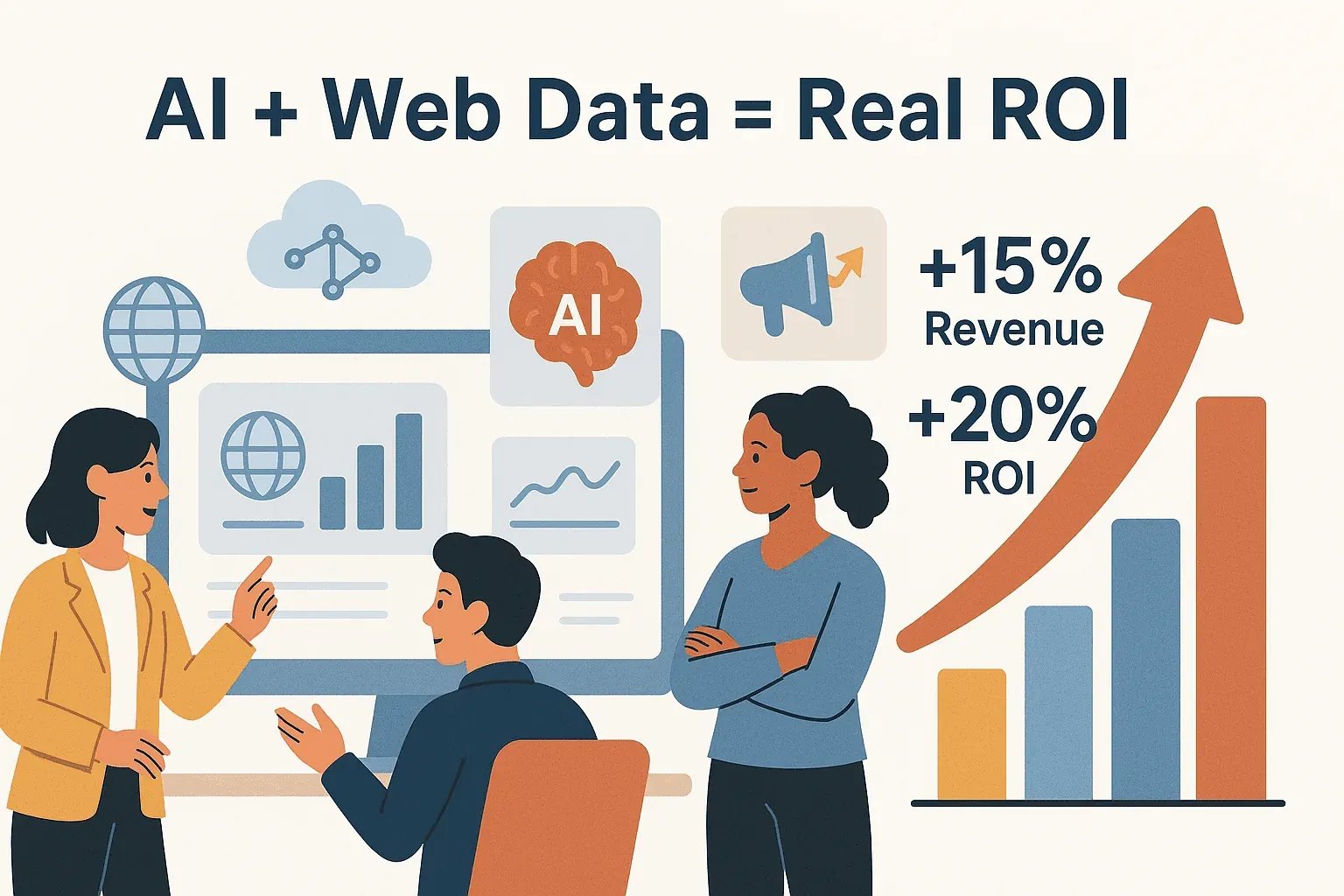
Cómo afrontar los riesgos legales y técnicos en el scraping de motores de búsqueda
Aquí es donde la cosa se pone interesante: hacer scraping de motores de búsqueda es potente, pero también es un campo minado legal y técnico si no tienes cuidado.
Consideraciones legales:
- ¿Es legal? En general, hacer scraping de resultados públicos de búsqueda es legal (), pero violar los términos de servicio (ToS) de un motor de búsqueda puede hacer que bloqueen tu IP o enviarte un requerimiento de cese y desistimiento. Los tribunales de EE. UU. han dictaminado que acceder a datos públicos no es un delito (véase ), pero incumplir los ToS es un asunto contractual.
- Privacidad de los datos: si extraes datos personales, aunque sean públicos, puedes encontrarte con problemas de RGPD o CCPA. Cíñete a información pública que no sea personal y revisa siempre qué estás recopilando ().
- robots.txt: no es vinculante legalmente, pero sí un estándar del sector. Si robots.txt dice “no scraping”, tómalo como una señal de alto ().
Riesgos técnicos:
- CAPTCHAs y bloqueos de IP: más del se deben a defensas anti-bot. Google y Bing usan límites de frecuencia, CAPTCHAs y bloqueos de IP para frenar bots.
- Cambios de diseño: a los motores de búsqueda les encanta retocar su HTML. Los raspadores con reglas fijas se rompen cuando cambia la estructura.
- Detección de user-agent: los motores de búsqueda sirven HTML distinto a móvil y escritorio. Si tu raspador parece “demasiado bot”, pueden marcarlo o mostrarte datos diferentes.
 Consejos para evitar problemas:
Consejos para evitar problemas: - Haz scraping despacio, añade retrasos aleatorios y usa proxies rotativos.
- Usa cadenas de user-agent realistas (hazte pasar por Chrome, no por un robot de 1999).
- Revisa robots.txt y los ToS antes de hacer scraping.
- No recopiles ni revendas datos personales.
- Sigue de cerca los cambios legales: las leyes de privacidad se están endureciendo ().
Móvil vs. escritorio: diferencias clave en el scraping de motores de búsqueda
Aquí va una curiosidad: hacer scraping de Google en el móvil no es lo mismo que hacerlo en el portátil. ¿Por qué? Porque los motores de búsqueda sirven diseños, funciones e incluso posiciones distintas según el dispositivo.
Diferencias clave:
- Diseño: las SERPs de escritorio suelen tener más columnas, paneles laterales y fragmentos enriquecidos. En móvil, todo va en una sola columna y se ven menos resultados a la vez.
- Estructura HTML: Google en escritorio usa contenedores como
<div class="g">, mientras que en móvil usa atributos comodata-vedodata-sncf(). Los raspadores necesitan lógica de análisis distinta para cada caso. - Funciones de la SERP: en móvil aparecen más resultados de imágenes y vídeo, y más paquetes locales; en escritorio hay más fragmentos destacados y paneles laterales ().
- Paginación: en escritorio suelen usarse páginas numeradas (
&start=10), mientras que en móvil puede haber desplazamiento infinito o un botón de “Más resultados” (). - Diferencias de ranking: alrededor del , y .
Consejos prácticos:
- Configura el user-agent de tu raspador para que coincida con el dispositivo objetivo (iPhone/Android para móvil, Chrome para escritorio).
- En móvil, usa un navegador sin interfaz para emular el desplazamiento y el tamaño del viewport ().
- Prueba tu raspador en ambos dispositivos: no asumas que una sola configuración sirve para todo.
Thunderbit: la forma más fácil de extraer datos de motores de búsqueda
Ahora bien, si estás pensando “esto suena complicado”, no estás solo. Precisamente por eso construimos . Thunderbit es una extensión de Chrome con IA que hace que el scraping de motores de búsqueda sea tan fácil como hacer clic dos veces: sin código, sin quebraderos de cabeza con selectores y sin mantenimiento.
¿Qué hace especial a Thunderbit?
- Sugerencia de campos con IA: la IA de Thunderbit analiza la página y sugiere exactamente qué campos extraer (como “Título”, “URL” y “Fragmento”). Se acabó adivinar selectores CSS.
- Scraping de subpáginas y paginación: ¿quieres ir más allá de la primera página? Thunderbit puede hacer clic en “Siguiente” o desplazarse automáticamente, e incluso visitar la URL de cada resultado para enriquecer tu tabla con información adicional.
- Prompts en lenguaje natural: puedes describir lo que quieres en español sencillo (“Extrae la fecha del fragmento” o “Traduce al español”), y la IA de Thunderbit se encarga de hacerlo.
- Sin código y basado en navegador: funciona directamente dentro de Chrome, así que puedes extraer cualquier página de motor de búsqueda que veas, con contenido dinámico, scroll infinito, lo que sea.
- Exportación gratuita de datos: exporta tus resultados a Excel, Google Sheets, Airtable o Notion, sin muros de pago ni complicaciones.
Thunderbit cuenta con la confianza de en Chrome Web Store, desde equipos de ventas y profesionales de marketing hasta fundadores en solitario.
Guía paso a paso: hacer scraping de motores de búsqueda con Thunderbit
¿Listo para probarlo tú mismo? Así puedes pasar de cero a héroe de los datos de motores de búsqueda en cuatro pasos:
Paso 1: instala y configura Thunderbit
- Ve a la y haz clic en “Añadir a Chrome”.
- Regístrate o inicia sesión (empezar es gratis).
- Fija el icono de Thunderbit en tu barra de herramientas para acceder fácilmente.
- Concede los permisos cuando se te soliciten: Thunderbit necesita leer las páginas que quieres extraer.
Paso 2: configura tu plantilla de scraping de motores de búsqueda
- Abre Google (o el motor de búsqueda que prefieras) y ejecuta tu consulta.
- Haz clic en el icono de Thunderbit para abrir la barra lateral.
- Pulsa “AI Suggest Fields”. La IA de Thunderbit analizará la página y sugerirá columnas como “Título”, “URL” y “Fragmento”.
- Revisa y ajusta los campos según lo necesites. ¿Quieres extraer la fecha o filtrar anuncios? Añade un campo personalizado o ajusta el prompt de la IA (por ejemplo, “Extrae solo resultados orgánicos”).
- Para necesidades avanzadas, añade un Field AI Prompt (como “Traduce el fragmento al francés” o “Resume en 10 palabras”).
Paso 3: lanza el scraping y recopila datos
- Haz clic en “Scrape”. Thunderbit extraerá los datos de la página actual.
- ¿Necesitas más resultados? Activa el scraping de paginación: Thunderbit hará clic en “Siguiente” o se desplazará según sea necesario, recopilando resultados de varias páginas.
- ¿Quieres más detalle? Usa el scraping de subpáginas para visitar la URL de cada resultado y extraer información adicional, como correos de contacto o metatags.
- Supervisa el progreso en el panel de Thunderbit. Si te encuentras con un CAPTCHA, prueba a cambiar al modo navegador o reduce la velocidad de scraping.
Paso 4: exporta y utiliza tus datos
- Cuando termines, previsualiza tus datos en la vista de tabla de Thunderbit.
- Exporta directamente a Excel, Google Sheets, Airtable o Notion, o descárgalos como CSV/JSON.
- Usa tus datos para informes SEO, listas de leads, seguimiento de competidores o lo que necesite tu negocio.
Crear estrategias de scraping dinámicas con IA
La web cambia rápido, especialmente los motores de búsqueda. Por eso la IA de Thunderbit está diseñada para adaptarse:
- Gestiona cambios de diseño: si Google modifica su HTML, la IA de Thunderbit normalmente puede adaptarse, identificar nuevos patrones y mantener el flujo de datos ().
- Prompts en lenguaje natural: describe lo que necesitas en español sencillo; Thunderbit puede extraer, etiquetar, traducir o resumir datos al vuelo.
- Transformación de datos sobre la marcha: ¿quieres clasificar los resultados como “comerciales” o “informativos”? Añade un prompt y Thunderbit los etiquetará mientras hace el scraping.
- Mejora continua: la IA de Thunderbit se vuelve más inteligente con el tiempo, así que tu estrategia de scraping evoluciona al ritmo de la web.
Consejos profesionales para mantenerte flexible:
- Actualiza regularmente los prompts de tus campos a medida que cambien tus necesidades.
- Programa scrapes recurrentes para un seguimiento continuo.
- Combina el scraping con APIs oficiales, como Google Trends, para obtener información más completa.
Aplicaciones reales: poner los datos del scraping de motores de búsqueda a trabajar
Así es como los equipos están usando el scraping de motores de búsqueda para generar impacto real en el negocio:
- Análisis de tendencias de mercado: extrae “Otras preguntas de los usuarios” y sugerencias de autocompletado para detectar tendencias emergentes antes que tus competidores.
- Supervisión de competidores: configura scrapes diarios de palabras clave principales y detecta nuevos rivales o cambios de precios antes de que afecten a tus resultados.
- Generación de leads: extrae Google para listas del sector y luego usa el scraping de subpáginas para recopilar información de contacto de cada resultado.
- Rendimiento SEO: sigue tus posiciones y las de la competencia, detecta caídas y ajusta el contenido rápidamente.
- Inteligencia publicitaria: extrae anuncios de búsqueda para ver qué ofertas y mensajes están usando tus competidores.
Un caso concreto: un minorista usó datos extraídos de precios de la competencia para bajar los suyos y logró un . Otra agencia creó una lista de más de 900 leads en un día usando operadores de búsqueda de Google y scraping, algo que a mano habría llevado semanas ().
Tendencias futuras: el panorama cambiante del scraping de motores de búsqueda
¿La única constante en el scraping de motores de búsqueda? El cambio. Esto es lo que viene:
- Resultados de búsqueda impulsados por IA: Google cambió el nombre de SGE a AI Overviews en mayo de 2024, y a abril de 2026 aparecen en aproximadamente el 48 % de todas las búsquedas de Google, frente al 31 % de febrero de 2025. Google también incorporó AI Mode en Chrome el 16 de abril de 2026, y la experiencia de IA de Bing ahora vive bajo Copilot Search. Las SERPs son cada vez más conversacionales y menos predecibles en su estructura, así que los raspadores deben gestionar bloques de respuestas de IA, chips de citas y paneles de preguntas de seguimiento junto con los clásicos enlaces azules ().
- Defensas anti-bot más fuertes: según el , el tráfico automatizado ya representa más del 53 % de todo el tráfico web, y los bad bots en concreto suponen el 37 %. Espera más CAPTCHAs, fingerprinting y muros de acceso, especialmente en SERPs de alto valor.
- Plataformas de scraping sin código e impulsadas por IA: herramientas como Thunderbit están haciendo que el scraping sea accesible para todo el mundo, no solo para desarrolladores.
- Cambios regulatorios: las leyes de privacidad se están endureciendo. Los reguladores instan a las plataformas a combatir el scraping no autorizado, especialmente de datos personales ().
- Enfoques híbridos: combinar scraping con APIs oficiales, como Google Custom Search, podría convertirse en la norma para garantizar cumplimiento y fiabilidad.
- Búsqueda por voz, visual y con IA: a medida que la búsqueda se expande a asistentes de voz y herramientas visuales, aparecerán nuevas fronteras para el scraping (piensa en extraer resultados de Google Lens o respuestas por voz).
Cómo mantenerte por delante:
- Usa herramientas que evolucionen con la web (como Thunderbit).
- Sé ético: haz scraping con respeto, evita datos personales y minimiza la carga en los servidores.
- Supervisa las novedades legales y técnicas.
- Céntrate en la calidad e integración de los datos: el scraping es solo el comienzo; el valor real está en el análisis y la acción.
Conclusión y puntos clave
El scraping de motores de búsqueda ya no es solo un truco de hackers: es una habilidad imprescindible para cualquier empresa que quiera seguir siendo competitiva, estar orientada a los datos y moverse con agilidad. La clave está en hacerlo con inteligencia: entender el panorama legal y técnico, usar herramientas adaptativas como y vincular siempre tus datos con resultados empresariales reales.
Esto es lo que debes recordar:
- El scraping de motores de búsqueda convierte resultados públicos en inteligencia empresarial accionable.
- Los beneficios son enormes: información más rápida, mejores leads, estrategia más inteligente y ROI medible.
- Pero debes hacer scraping de forma responsable: respeta los límites legales, adáptate a los desafíos técnicos y prioriza la calidad.
- Thunderbit facilita el inicio a cualquiera, con detección de campos impulsada por IA, scraping de subpáginas y paginación, y flujos de trabajo sin código.
- El futuro es dinámico: abraza la IA, cumple las normas y deja que tu estrategia de scraping evolucione.
¿Listo para ver lo que el scraping de motores de búsqueda puede hacer por tu negocio? , prueba a extraer tus palabras clave principales y convierte los motores de búsqueda del mundo en tu propia ventaja competitiva. Y si quieres más consejos, análisis profundos o guías prácticas, visita el .
Preguntas frecuentes
1. ¿Es legal el scraping de motores de búsqueda?
En general, hacer scraping de resultados públicos de búsqueda es legal, pero violar los términos de servicio de un motor de búsqueda puede hacer que bloqueen tu IP o te envíen un requerimiento de cese y desistimiento. Evita extraer datos personales y revisa siempre robots.txt y los ToS antes de empezar ().
2. ¿Cuál es la diferencia entre hacer scraping de resultados móviles y de escritorio?
Las SERPs de móvil y escritorio difieren en diseño, estructura HTML, funciones y, a veces, incluso en posiciones. Hacer scraping de ambas requiere cadenas de user-agent y lógica de análisis distintas ().
3. ¿Cómo hace Thunderbit más fácil el scraping de motores de búsqueda?
Thunderbit usa IA para sugerir campos, gestionar subpáginas y paginación, y permite usar prompts en lenguaje natural para extracciones personalizadas, todo dentro de tu navegador y sin necesidad de programar ().
4. ¿Cuáles son los principales riesgos técnicos en el scraping de motores de búsqueda?
Los CAPTCHAs, los bloqueos de IP y los cambios de diseño son los mayores riesgos. Haz scraping despacio, usa proxies y elige herramientas que se adapten a los cambios, como Thunderbit.
5. ¿Cuál es el futuro del scraping de motores de búsqueda?
Espera más resultados de búsqueda impulsados por IA, medidas anti-bot más fuertes y leyes de privacidad en evolución. Las herramientas que combinan IA, flujos sin código y cumplimiento normativo, como Thunderbit, liderarán el camino.
Feliz scraping, y que tus resultados de búsqueda estén siempre estructurados, sean accionables y vayan un paso por delante de la competencia.
Saber más